Linux 文本处理:先定记录、字段与键,再组合可靠流水线
上一部分解决了“怎样准确选中一段文本”。真正进入清洗、统计和自动化后,正则只是其中一个零件。我们还要回答:一条记录在哪里结束,字段怎样分隔,排序比较哪一段,两个表用什么键对应,失败状态由谁负责。
很多脆弱命令都有同一个问题:先把工具串起来,跑出结果后才猜每一步做了什么。可靠的顺序恰好相反。先写清数据契约,再给每一步安排一个单一职责;先用小语料证明边界,再把流水线放到更大输入上。
本篇从观察和计数开始,逐步进入排序、字段运算、sed、awk、统一差异与补丁。示例来自一次性 Debian 沙盒,输入同时包含中文、空字段、非相邻重复、CRLF、缺少尾换行和带换行文件名。我们不只看“命令能不能跑”,还会解释输出为什么成立、在哪些输入上会失效。
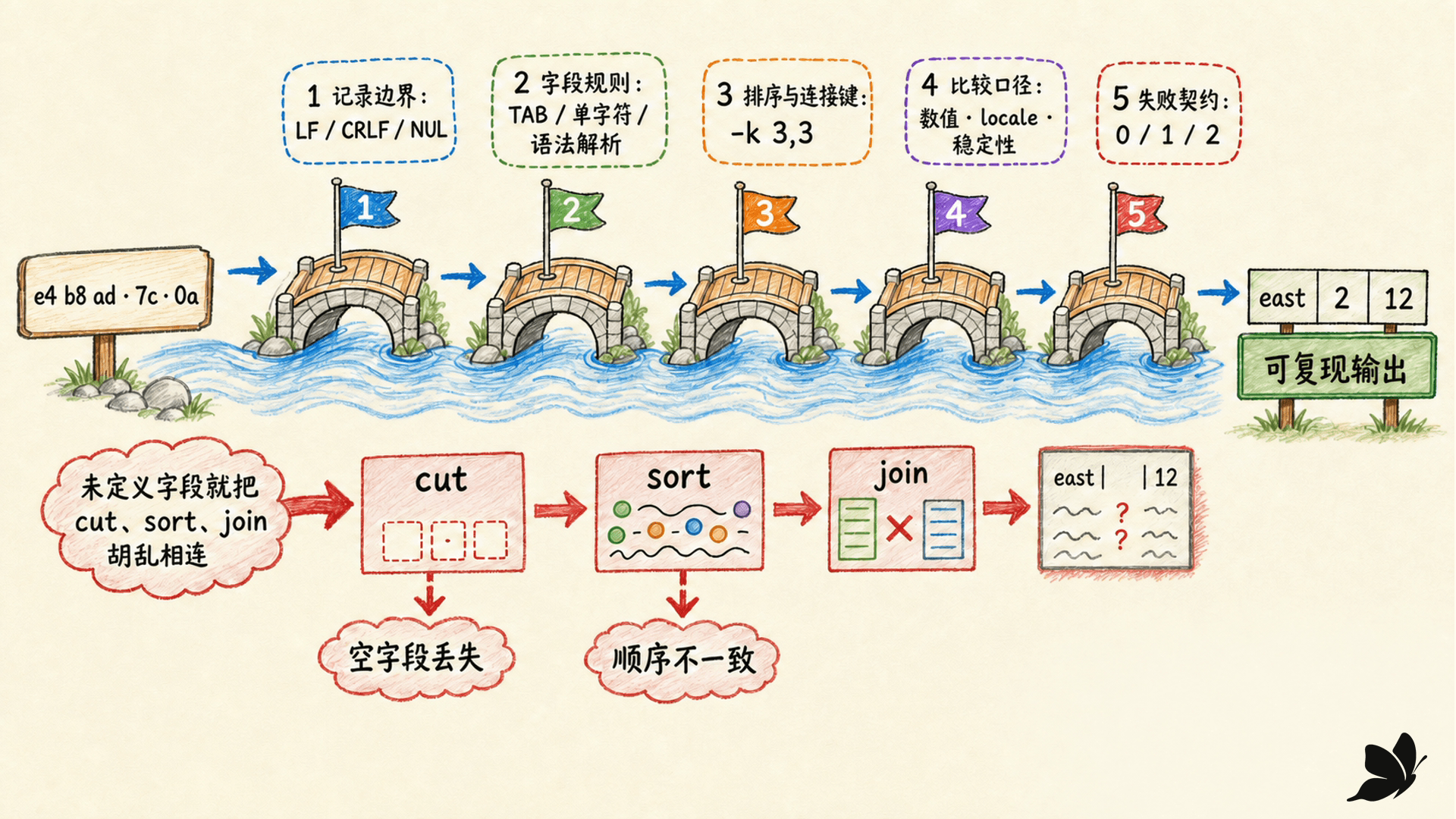
动手前先写下五个契约
一条文本流水线至少有五项隐含约定:
我们可以把一条流水线写成逐步收窄的契约:
text
字节流
→ 按记录终止符切成记录
→ 按字段规则解析字段
→ 校验字段数和数据类型
→ 明确排序键与 locale
→ 变换、连接或聚合
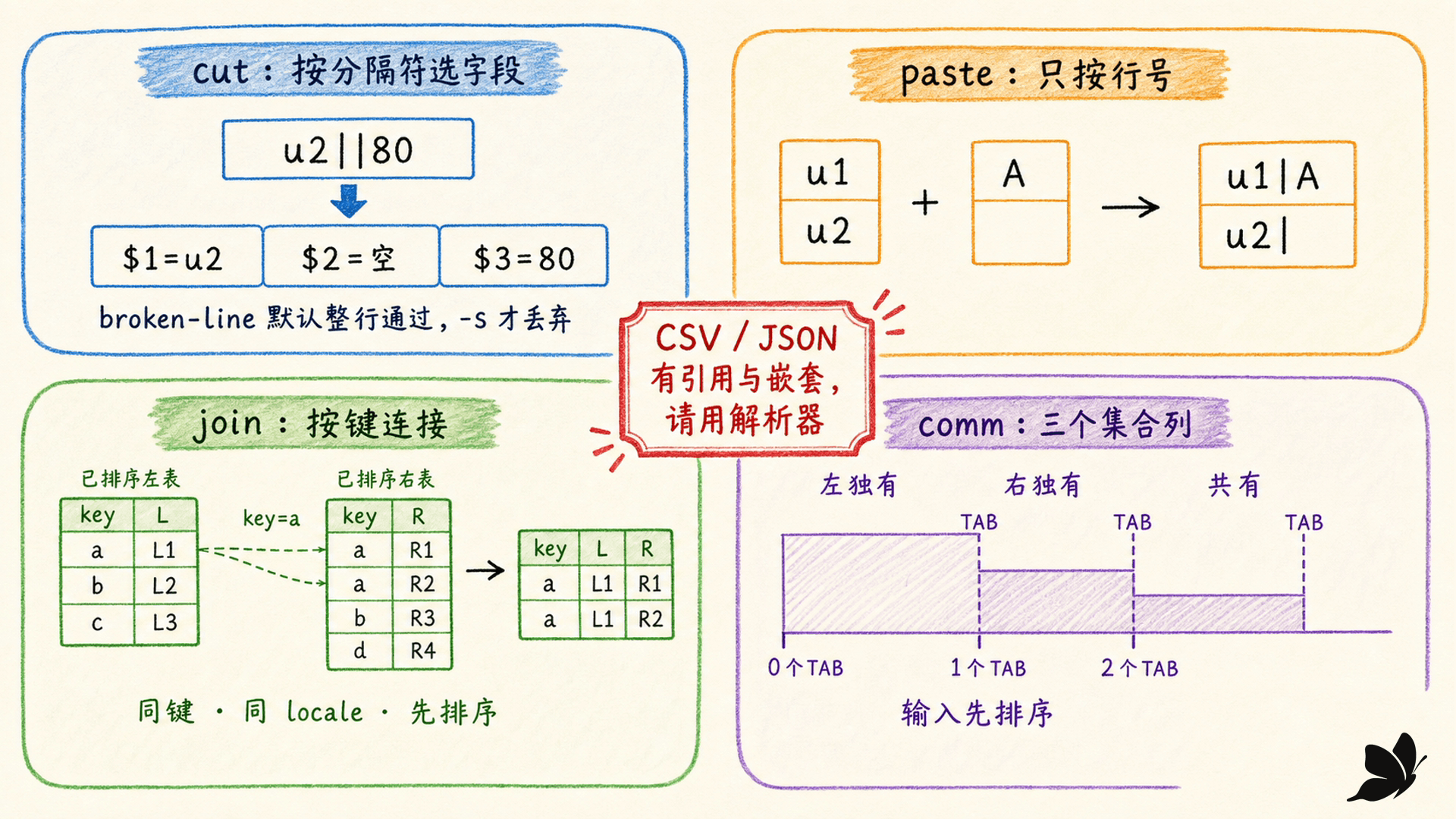
→ 输出新的记录契约与退出状态“文本”只表示数据能以字符形式表示,并不保证它天然按行、空格或逗号安全可切。CSV 可以在引号字段中包含逗号和换行,JSON 有嵌套对象与转义字符串,任意文件名甚至可以包含换行。工具选择必须服从数据结构。
一条好流水线不只是最终输出正确。它还应让中间记录可检查、让坏输入显式失败、让 locale 和临时目录可复现,并说明输出将交给谁继续解析。
1
一份竖线分隔数据要按第三字段数值排序,最先应该确认什么?
2
哪些输入不能默认按普通换行和空白直接切分?
先看清输入:cat、tac、nl、wc、head 与 tail
cat、tac、nl:复制、反转与编号承担不同职责
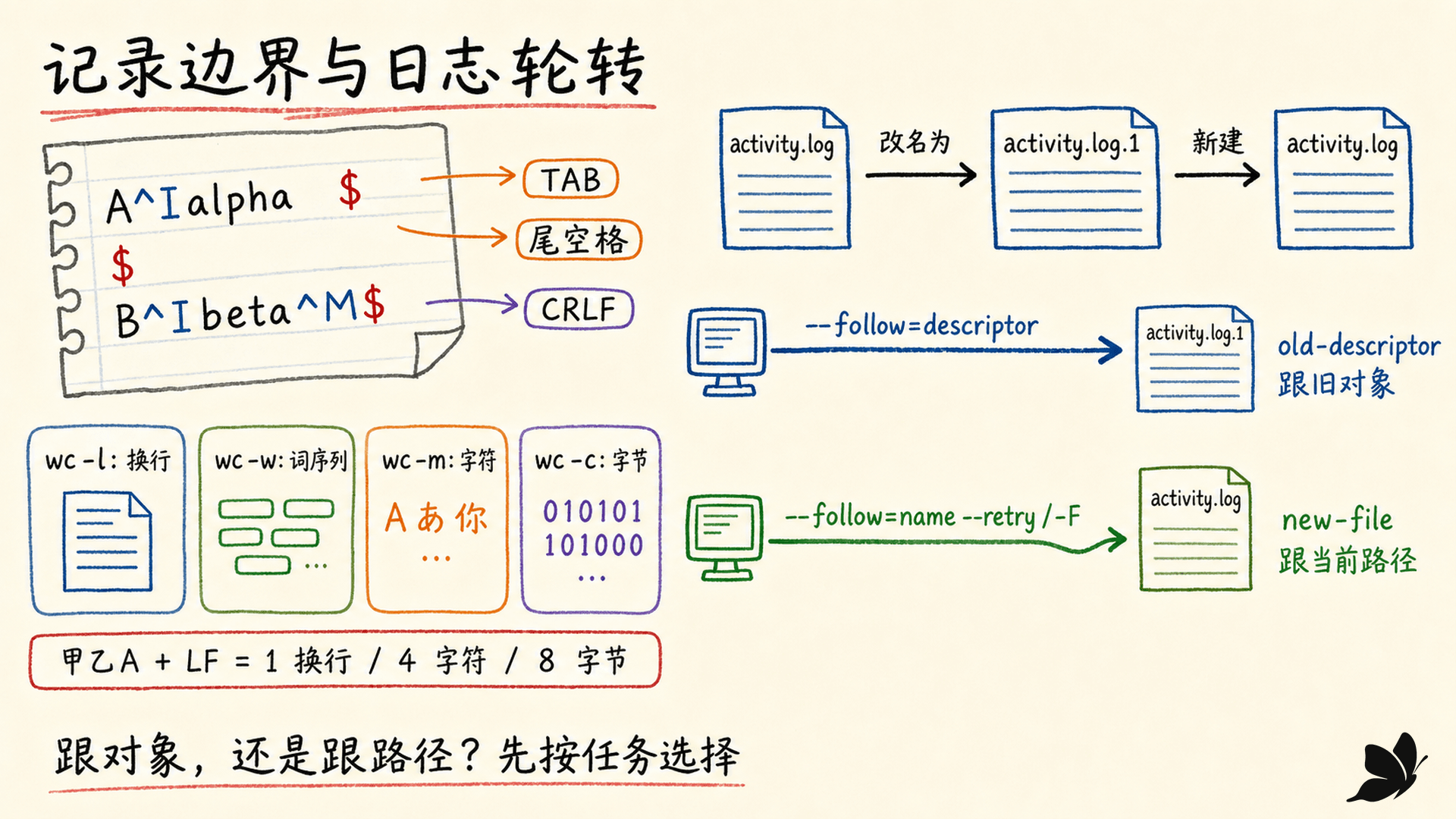
cat 的核心动作是把输入依次复制到标准输出。它适合连接少量已知文件,也适合用 -A 检查普通显示隐藏掉的字符:
bash
cat -A visible.txt受控语料的真实输出是:
text
A^Ialpha $
$
B^Ibeta^M$^I是 TAB。$标记记录末尾,因此alpha后的两个空格可以被看见。^M$表示 CR 后跟 LF,常见于 CRLF 文本。
cat -n 给所有输出行编号,cat -b 只给非空行编号。若编号规则本身是任务重点,nl 更明确:默认只编号非空正文行,nl -ba 给所有行编号,还能控制起始值、宽度、编号格式和逻辑页段。
tac 则把记录顺序反转。它默认仍以换行为记录分隔符,不是把每个字符倒过来。没有尾换行时,反转后的第一条输出也没有尾换行,后续提示或命令输出可能直接贴在它后面。这正好提醒我们:行尾终止符属于数据契约。
3
cat -A 显示的行尾美元符号一定是文件中真实保存的字符。
4
要给空行也编号,哪条命令最直接?
wc:行、词、字符、字节是四个不同问题
wc 默认输出换行数、词数和字节数。常用选项是:
在 C.utf8 下,甲乙A 加一个 LF 的结果是 1 个换行、4 个字符、8 个字节。另一个文件视觉上有三段文字,但结尾没有 LF,wc -l 只得到 2。
脚本只需要单个计数时,应明确写一个选项:
bash
lines=$(wc -l < access.log)重定向避免输出文件名,单一计数在 GNU 实现中也不会带前导对齐空格。更重要的是,变量名应叫 newline_count 或明确说明它数的是 LF,而不是笼统称作“记录数”。
5
一个文件含三段文字,但最后一段后没有 LF,wc -l 最可能输出什么?
6
在 UTF-8 文本中,哪些计数可能彼此不同?
head 与 tail:取样、区间和持续跟踪
head -n 20 file 取前 20 条换行记录,tail -n 20 file 取后 20 条。GNU 语法中的正负号很有用:
bash
head -n -5 file # 除最后 5 行外的所有行
tail -n +6 file # 从第 6 行开始直到结尾按字节取样用 -c。它适合协议头或固定字节检查,不适合随意截 UTF-8 字符,因为切点可能落在一个多字节字符中间。
持续观察日志时,要先决定跟踪对象:
tail -f log默认按已打开的文件描述符跟踪。文件被重命名后,它仍能看到旧对象后续追加的数据。tail --follow=name --retry log按路径名字反复打开。GNU 的tail -F是这个组合的便捷写法,更适合“旧文件改名、新建同名文件”的轮转方式。
受控轮转实验中,按描述符的输出是 before-rotate,old-descriptor,按名字跟踪的输出是 before-rotate,new-file。这里没有谁绝对正确:服务排障想追踪当前路径通常选 -F;想看一个已经打开对象的剩余写入则按描述符。
7
日志通过重命名旧文件并新建同名路径轮转时,通常应选哪种跟踪方式?
8
tail -c 1 对任何 UTF-8 文本都能返回最后一个完整字符。
sort:排序前先固定 locale、字段和相等规则
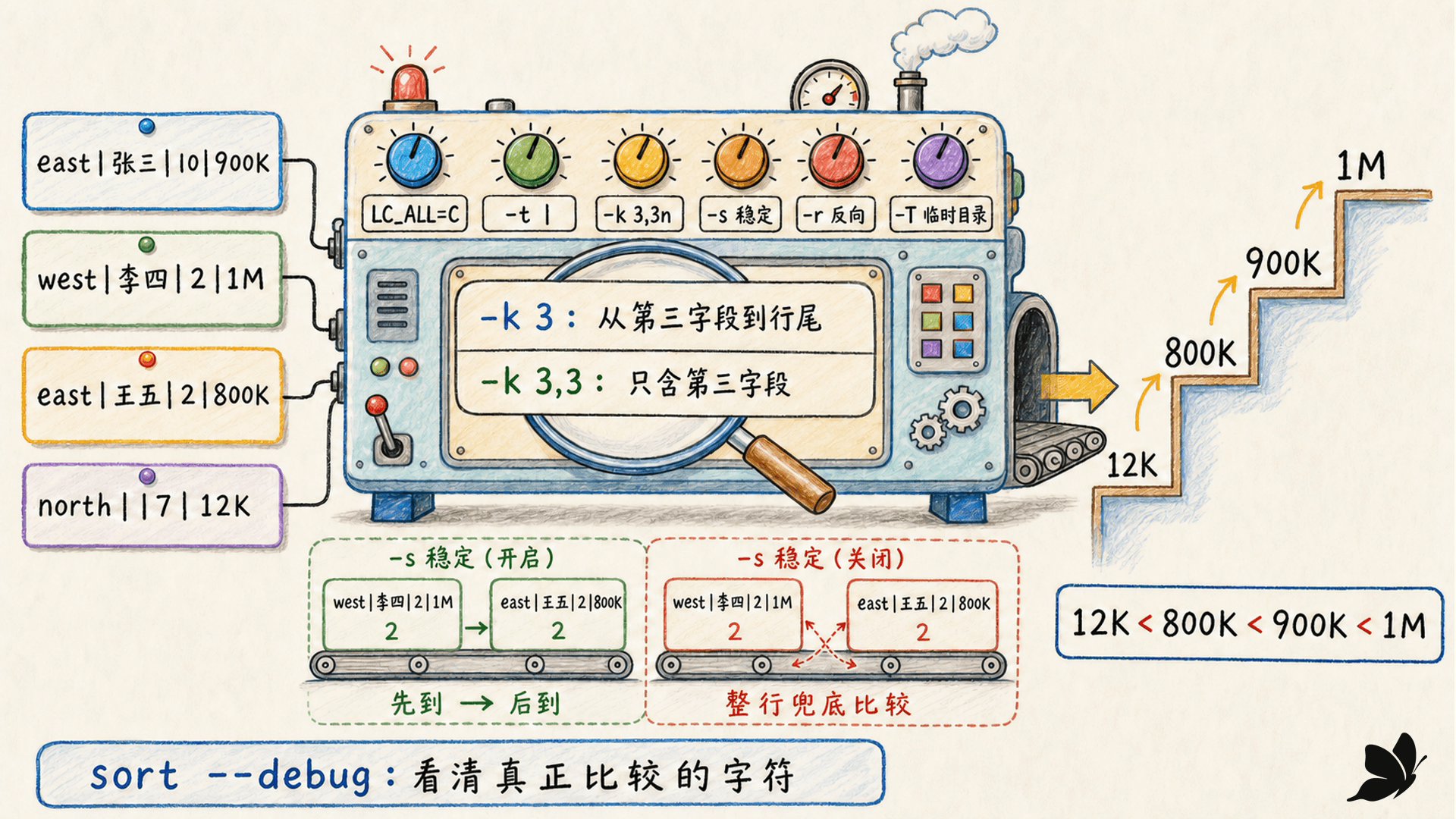
locale 是比较算法的一部分
sort 默认比较整行,具体字符次序由 LC_COLLATE 决定;哪些字符属于空白又受 LC_CTYPE 影响,数值中的小数点和千位分隔符受 LC_NUMERIC 影响。于是,同一文件在不同环境下可能得到不同次序。
机器之间要可复现的协议型数据,常见做法是显式固定:
bash
LC_ALL=C sort input.txtC locale 通常按字节序给出简单、可预测的顺序。自然语言名单若需要符合用户习惯,就应选择明确存在的目标 UTF-8 locale,并让排序、join 和 comm 全程使用同一设置。
不要把排序后的“看起来合理”当作证据。可以用:
bash
LC_ALL=C sort --debug -t '|' -k 3,3n records.psv--debug 会标出真正参与比较的字符,并向标准错误解释规则。它特别适合定位前导空白、空字段和键结束位置。
9
两个文件准备交给 join,怎样减少 locale 引起的不一致?
10
sort 的默认字符顺序在所有 locale 中都等于 UTF-8 字节顺序。
-t 与 -k:一个键必须写清开始和结束
常见格式是:
bash
sort -t '|' -k 3,3n -k 1,1 records.psv-t '|'把单个竖线设为字段分隔符,连续两个竖线会产生空字段。-k 3,3n只用第三字段按数值比较。- 第一个键相等后,再用
-k 1,1比较第一字段。
只写 -k 3 并不表示“第三字段”,而是从第三字段开头一直延伸到行尾。精确的单字段键应写成 -k 3,3。字符位置还能写为 -k 2.3,2.5;位置从 1 开始,结束位置是包含式。
键相等时,GNU sort 默认还会比较整行作为最终兜底,因此原相对顺序可能改变。-s 或 --stable 禁用这次兜底:
bash
LC_ALL=C sort -s -t '|' -k 3,3n records.psv如果输入先后代表事件顺序、优先级已由前一步确定,稳定排序很关键。若你本来就需要确定的次级顺序,显式添加第二个键比依赖整行兜底更清楚。
11
要只按第三个竖线字段排序,正确的键范围是哪一个?
12
启用 sort -s 后,相等键记录会保持原来的相对顺序。
数值、人类数字、去重与临时空间
sort 有多种比较口径,不能互相替代:
sort -u 按当前比较规则判断“相等”。例如 02 apple 与 2 banana 交给 sort -n -u 时,数值键都等于 2,只保留一条;而 sort -n | uniq 的 uniq 比较完整相邻行,会保留两条。两者只在比较口径一致时才等价。
大输入可能产生临时文件。TMPDIR 或 -T directory 指定位置,-S size 设置初始内存缓冲,但单行仍可能超过该大小。受控实验把临时目录设在 /tmp/welearn-ch20/sorttmp,用 1 KiB 缓冲排序 5000 条逆序数字,结果首尾为 1 和 5000,命令结束后临时目录为空。
13
哪些做法能让一次多字段排序更可审阅?
14
为什么 sort -n -u 可能丢掉文本不同的两行?
uniq:它消除的是相邻重复组
uniq 读取顺序不变,只把连续相等的记录视作一个组。输入:
text
alpha
beta
alpha
alpha
gamma
beta直接运行 uniq -c,计数仍是 1 alpha、1 beta、2 alpha、1 gamma、1 beta。第一、第三位置的 alpha 没有相邻,因此属于两个组。
若目标是全局频次,需要先按与 uniq 相同的比较口径排序:
bash
LC_ALL=C sort repeated.txt | uniq -c | sort -nr常用选项还有:
-d只输出发生重复的组。-u只输出只出现一次的组。-f n比较时跳过前 n 个空白字段。-s n再跳过 n 个字符。-i忽略大小写,但仍受 locale 影响。
如果记录已经按时间排序,直接 uniq 可以压缩“连续相同状态”;若要全局去重,排序会改变事件顺序,应先确认这个代价是否允许。
15
输入 a、b、a 直接交给 uniq,输出是什么?
16
为全局去重而先 sort,可能破坏原事件顺序。
字段工具:cut、paste、join 与 comm 不是同一种“拼表”
cut:分清字节、字符和字段
cut 的三个入口是:
bash
cut -b 1-8 file # 字节位置
cut -c 1-8 file # 字符位置接口
cut -d '|' -f 2,4 file # 字段位置编号从 1 开始。-f 默认分隔符是 TAB,-d 只接受一个分隔字符。它不会理解“任意连续空白”,也不会把多个字符组成的 :: 当成一个分隔 token。
字段模式有两个容易忽略的行为:
- 连续分隔符产生空字段,例如
u2||80的第二字段为空。 - 不含分隔符的
broken-line默认整行通过;加-s才只输出真正被分隔的记录。
字符接口也不能盲信版本和实现。受控环境中的 GNU coreutils 9.1 对 甲乙A 执行 LC_ALL=C.utf8 cut -c1,真实字节是单独的 e7,并不是完整的“甲”三个字节。脚本若要按 Unicode 字符或用户感知字素切片,应先验证实现,复杂文本直接换用支持 Unicode 的语言库。
17
cut -d '|' -f2 遇到完全没有竖线的记录时,默认怎样处理?
18
只要使用 cut -c,就一定能安全截取任意版本中的 UTF-8 字符。
paste:它只相信行位置
paste left right 把两个文件的第一行、第二行依次并排,默认用 TAB 分隔。若右文件只有一行:
text
left: u1 right: A
u2执行 paste -d '|' left right 得到:
text
u1|A
u2|它不会查 ID,也不会验证两边行数。只有当两份数据已经共享严格的行序契约时,位置拼接才可靠。paste -s 则把一个文件的连续行串到同一输出行,可用于把小列表变成分隔序列,但它也不理解字段内转义。
19
两个文件的记录顺序可能不同,但都有唯一 ID,应该优先用哪类方法?
join:先按同一键、同一规则预排序
join 对相等键的两条输入记录输出一条组合记录。默认连接第一字段、以连续空白分字段;用 -t '|' 后按单个竖线分字段:
bash
LC_ALL=C sort -t '|' -k 1,1 people.psv > people.sorted
LC_ALL=C sort -t '|' -k 1,1 roles.psv > roles.sorted
LC_ALL=C join -t '|' -1 1 -2 1 people.sorted roles.sorted-1、-2 分别选择左右文件的键字段。预排序必须使用相同字段、分隔符、忽略大小写设置和 locale。可加 --check-order 让乱序输入显式失败。
默认只输出两边都有的键。外连接式需求可以组合:
bash
join -t '|' -a 1 -a 2 -e MISSING -o auto people.sorted roles.sorted-a 1 -a 2保留两边未配对记录。-e MISSING填补输出模板中的缺失字段。-o auto根据表头式字段宽度输出一致列数。
重复键不是自动报错。一个人键 a 对应两个角色时,会生成两个匹配对;若左右都重复,结果数量可能成倍增加。连接前要先检查键唯一性:
bash
cut -d '|' -f1 people.sorted | uniq -d20
join 报输入乱序,首先应核对什么?
21
join 遇到重复键时,只会任意保留一条记录。
comm:三个列是集合关系,不是 diff 补丁
comm file1 file2 比较两个已按相同 LC_COLLATE 排序的文件,默认输出三列:
- 第一列:只在左文件。
- 第二列:只在右文件,前置一个 TAB。
- 第三列:两边都有,前置两个 TAB。
-1、-2、-3 抑制对应列。例如共同集合是 comm -12 a b,只在左侧是 comm -23 a b。正常完成时,是否存在差异不改变退出状态;它与 diff 的状态契约不同。
22
关于 comm,哪些说法正确?
字符变换与切片:tr、split、csplit
tr:映射的是字符集合,不是字符串
tr 只从标准输入读取并写到标准输出,常见模式是:
bash
tr '[:lower:]' '[:upper:]' # 对应位置映射
tr -d '[:digit:]' # 删除集合中的字符
tr -s ' ' # 把连续空格压成一个
tr -d '\r' # 删除 CR,前提是已确认它们都应删除-s 压缩的是最后指定集合中的连续字符,不是压缩任意重复单词。字符类与范围受 locale 影响,多字节 locale 下的补集 -c 更要谨慎。tr 也不是 Unicode 大小写折叠、正规化或繁简转换工具。
把 CRLF 转成 LF 看似可以 tr -d '\r',但这会删除所有 CR,包括字段内容中的合法 CR。更稳的做法是先确认文件格式,只在行尾执行有边界的转换,并保留原件或输出到新文件。
23
tr -s ' ' 的作用是什么?
24
tr '[:lower:]' '[:upper:]' 等价于完整的 Unicode 大小写转换库。
split 与 csplit:一个按数量,一个按内容边界
split 按连续大小切分:
bash
split -l 1000 input chunk- # 每片 1000 条记录
split -b 100M archive chunk- # 每片固定字节数
split -C 100M input chunk- # 尽量保留完整行且不超过大小按字节切可能劈开一条记录或一个多字节字符;-C 尽量保留完整行,但单条记录本身超过限制时仍会拆分。文件后缀应设计成排序后就是原顺序,连接前可校验哈希或 cmp。
csplit 按行号或正则上下文切:
bash
csplit -s -f part- -b '%02d.txt' sections.txt \
'/^== beta ==/' '/^== gamma ==/'匹配行默认成为下一片的开头。/regexp/ 创建输出,%regexp% 跳过对应区段,{n} 或 {*} 重复上一个模式。模式不存在通常是错误,默认会删除已经产生的片段;是否需要 -k 保留失败现场应按排错策略决定。
受控实验把 5 行按每 2 行切成三片,顺序连接与原输入完全一致;再按三个标题用 csplit 切片,三个片段首行正好是各自标题,连接结果也一致。这证明选择内容边界能保留语义段落。
25
要按每个章节标题切分长文本,优先选择哪个工具?
26
验证切片可重建时,哪些动作有用?
sed:按记录进入 pattern space,再按脚本顺序编辑
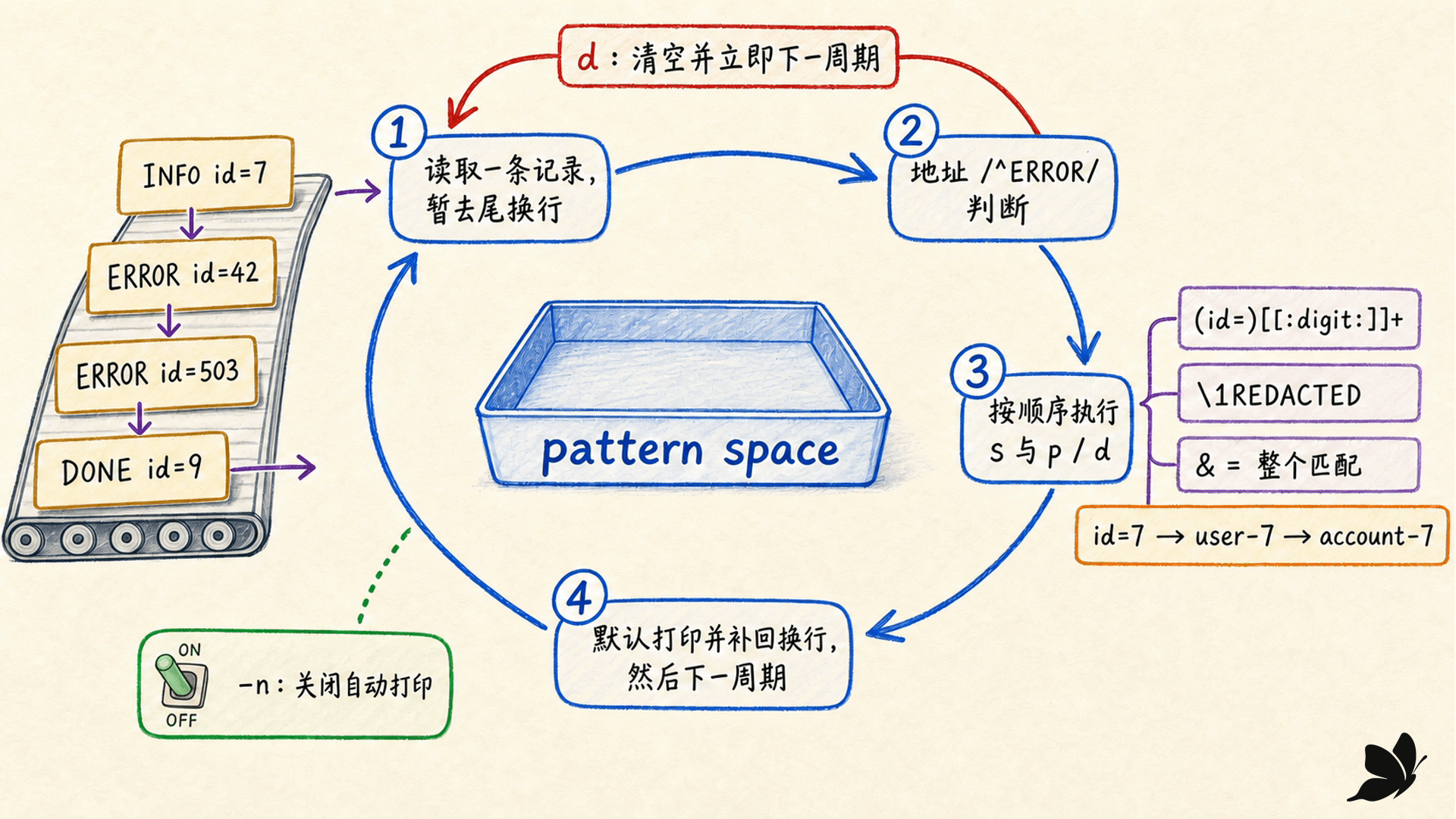
周期与地址:先决定哪些记录执行命令
sed 的默认周期可以概括为:
- 读取一条输入记录,移除尾部换行,放入 pattern space。
- 从前到后执行脚本中的命令;带地址的命令只在地址匹配时执行。
- 若没有
-n,周期末自动打印 pattern space,并补回输出换行。 - 清空 pattern space,读取下一条记录。
地址可以是行号、范围、正则或末行:
bash
sed -n '5p' file # 第 5 行
sed -n '3,7p' file # 第 3 至 7 行,包含两端
sed -n '/^ERROR/p' file # 匹配地址
sed -n '/^ERROR/!p' file # 地址取反
sed -n '$p' file # 最后一行默认自动打印加显式 p 会得到双份输出,因此筛选通常用 -n 加 p。d 删除 pattern space 并立即开始下一周期,后续命令不会再执行;这与“把内容换成空字符串后继续执行”不同。
27
sed -n '/^ERROR/p' 为什么不会打印非 ERROR 行?
28
sed 的 d 命令执行后,本周期剩余命令仍会继续运行。
替换、分组、引用与命令顺序
替换语法是:
bash
sed -E 's/(id=)[[:digit:]]+/\1REDACTED/' events.txt- 第一个分隔符之间是正则。
- 第二段是替换文本。
\1引用第一个捕获组;替换文本中的&表示整个匹配。- 末尾
g表示替换当前 pattern space 中所有不重叠匹配;没有g只替换第一个。 - 分隔符不必是斜杠。路径很多时,
s#/old/#/new/#g更易读。
地址与替换可以组合:
bash
sed -n -E '/^ERROR/{s/(id=)[[:digit:]]+/\1REDACTED/;p}' events.txt脚本命令按顺序操作同一个 pattern space:
bash
printf 'id=7\n' |
sed -E 's/id=([0-9]+)/user-\1/; s/user-/account-/'真实结果是 account-7。第二条 s 看到的是第一条已经改过的 user-7。调试多命令脚本时,最好先拆成多次 -e 或脚本文件,每加一步就检查中间输出。
29
sed 替换文本中的反斜杠一表示什么?
30
两个 sed 替换命令写在同一脚本中时,第二个命令读取什么?
脚本文件、就地编辑与跨行边界
规则多时用脚本文件比转义一条长命令更清楚:
bash
sed -E -f clean.sed input.txt > output.txt先写到新文件并检查,再替换原件。sed -i 会直接修改文件,备份后缀、符号链接行为和不同实现的选项语法并不完全一致,不应成为第一次试规则的方式。
普通周期一次处理一行。N 可以把下一行追加进 pattern space,H/G/x 在 pattern 与 hold space 之间传递内容,但复杂跨行语法会快速变得难审查。若任务已经变成嵌套结构、带引号字段或状态机,换 awk、专用解析器或常规编程语言更合适。
sed 也会对无尾换行做实现相关的输出修补。若换行是否存在本身是协议要求,应使用字节工具或专门验证器,不要以终端外观推断。
31
准备运行复杂 sed 清洗规则时,哪些做法更稳妥?
awk:把输入看成记录与字段,再执行模式—动作
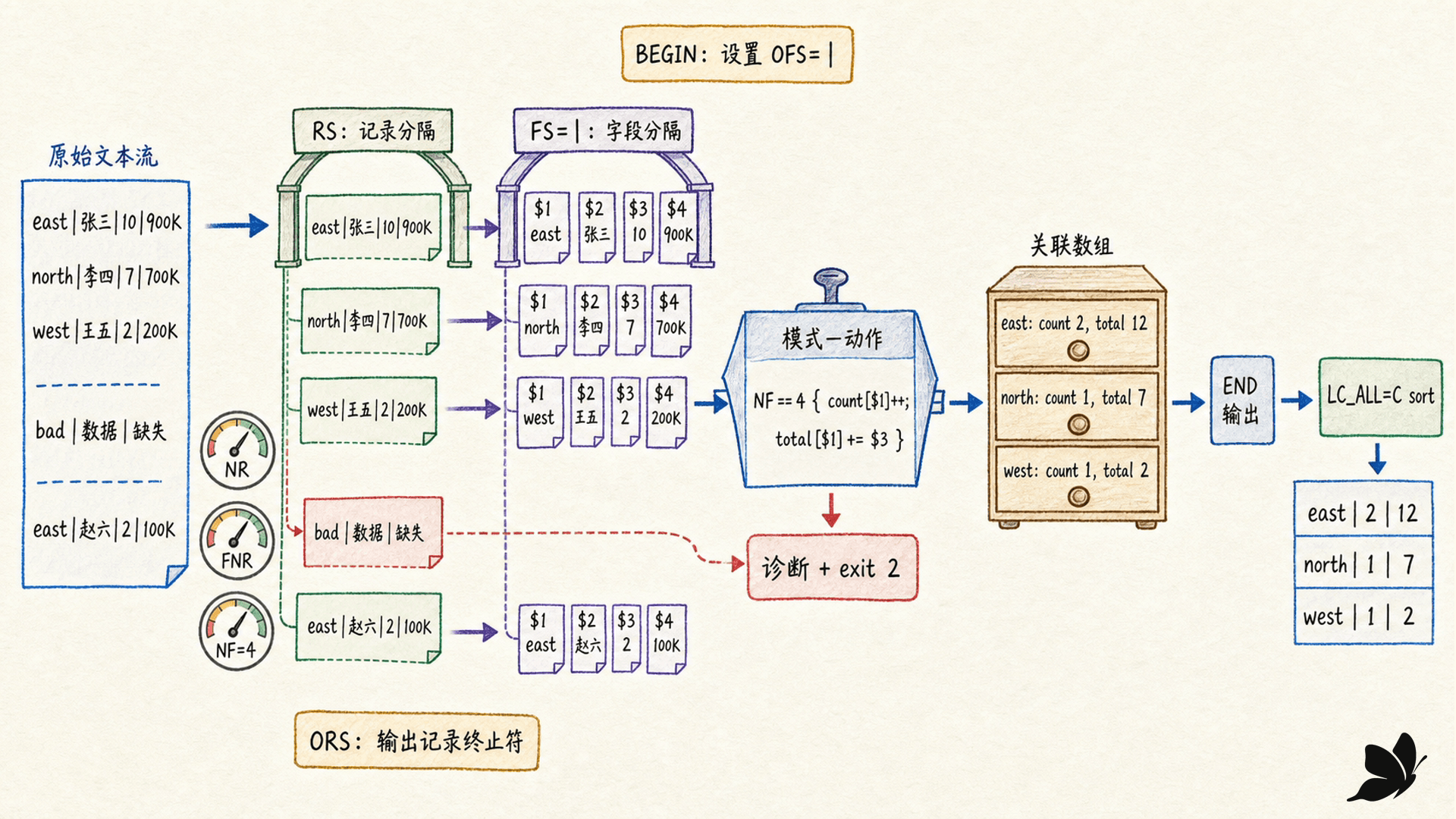
RS、FS、OFS、ORS 定义输入输出结构
awk 先用 RS 切输入记录,再用 FS 切每条记录的字段:
$0是当前完整记录。$1到$NF是字段。NF是当前记录字段数。NR是所有输入累计记录号,FNR是当前文件记录号。
默认 RS 是换行,默认 FS 是一个特殊的空格值:它折叠连续空格、TAB 和换行式空白,并忽略首尾空白。若明确设 FS="|",每个竖线都是独立分隔符,连续竖线就保留空字段。
bash
awk -F '|' 'BEGIN { OFS="|" } NF == 4 { print $1, $3 }' records.psvOFS 是 print a,b 中字段之间的输出分隔符,ORS 是每次 print 后的输出记录分隔符。修改字段值后再引用 $0,awk 会用 OFS 重建记录,所以输出分隔符应提前固定。
段落处理可以写:
bash
awk 'BEGIN { RS=""; FS="\n"; OFS="=>"; ORS="<END>\n" }
{ print $1, NF }' paragraphs.txt空行组分隔记录,每一段里的换行再分字段。由此可见,“一行一条、空格一列”只是默认模型,不是 awk 的上限。
32
awk 中哪个变量表示当前记录的字段数?
33
awk 默认 FS 为空格时,连续多个空格一定产生多个空字段。
模式—动作、字符串与数值转换
awk 程序由模式和动作组成:
awk
pattern { action }模式可以是正则、比较表达式、范围或省略。省略模式表示每条记录都执行;省略动作表示打印整条记录。常见写法:
bash
awk -F '|' '$1 == "ERROR" && $3 + 0 >= 10 { print $2, $4 }' events.psv
awk -F '|' '$4 ~ /timeout/ { print NR, $0 }' events.psv数值与字符串比较要小心。awk 值可能带数值、字符串或“数值字符串”属性;隐式转换取决于值怎样产生。受控实验中,程序内赋值 raw="010" 与数值 10 比较为假,与字符串 "10" 也为假;显式 (raw + 0) == 10 才为真。更危险的是,"10x" + 0 在 mawk 中得到 10,坏后缀被静默忽略。
所以清洗外部输入时先校验,再转换:
awk
$3 ~ /^-?[[:digit:]]+([.][[:digit:]]+)?$/ {
value = $3 + 0
}若校验失败,应写诊断到标准错误并设置非零退出状态,而不是把它当零加入总和。
34
为什么不应直接把任意第三字段写成 total += $3?
35
哪些都可以成为 awk 的模式?
BEGIN、END 与聚合:把状态留在一次扫描里
BEGIN 在读取第一条输入前运行,适合设置分隔符、打印表头或初始化配置;END 在输入耗尽后运行,适合输出总计:
bash
awk -F '|' '
BEGIN { OFS="|" }
NF == 4 {
count[$1]++
total[$1] += $3
}
END {
for (region in total)
print region, count[region], total[region]
}
' records.psv | LC_ALL=C sort真实结果是:
text
east|2|12
north|1|7
west|1|2关联数组的遍历顺序不应当作排序承诺,因此需要确定输出顺序时,再明确交给 sort,或在支持的实现中使用经过确认的排序扩展。
错误处理也应进入聚合程序:
awk
NF != 4 {
print "bad record at", NR > "/dev/stderr"
bad = 1
next
}
END { if (bad) exit 2 }这样 Shell 可以通过 pipefail 看见数据校验失败,而不是只得到一个看似完整的总计。
36
awk 关联数组聚合结果为什么还常接一次 sort?
37
在 END 中根据坏记录标志 exit 2,可以让外层脚本区分成功聚合与输入校验失败。
diff 与 patch:差异是可执行变更,不只是视觉对比
统一差异与退出状态
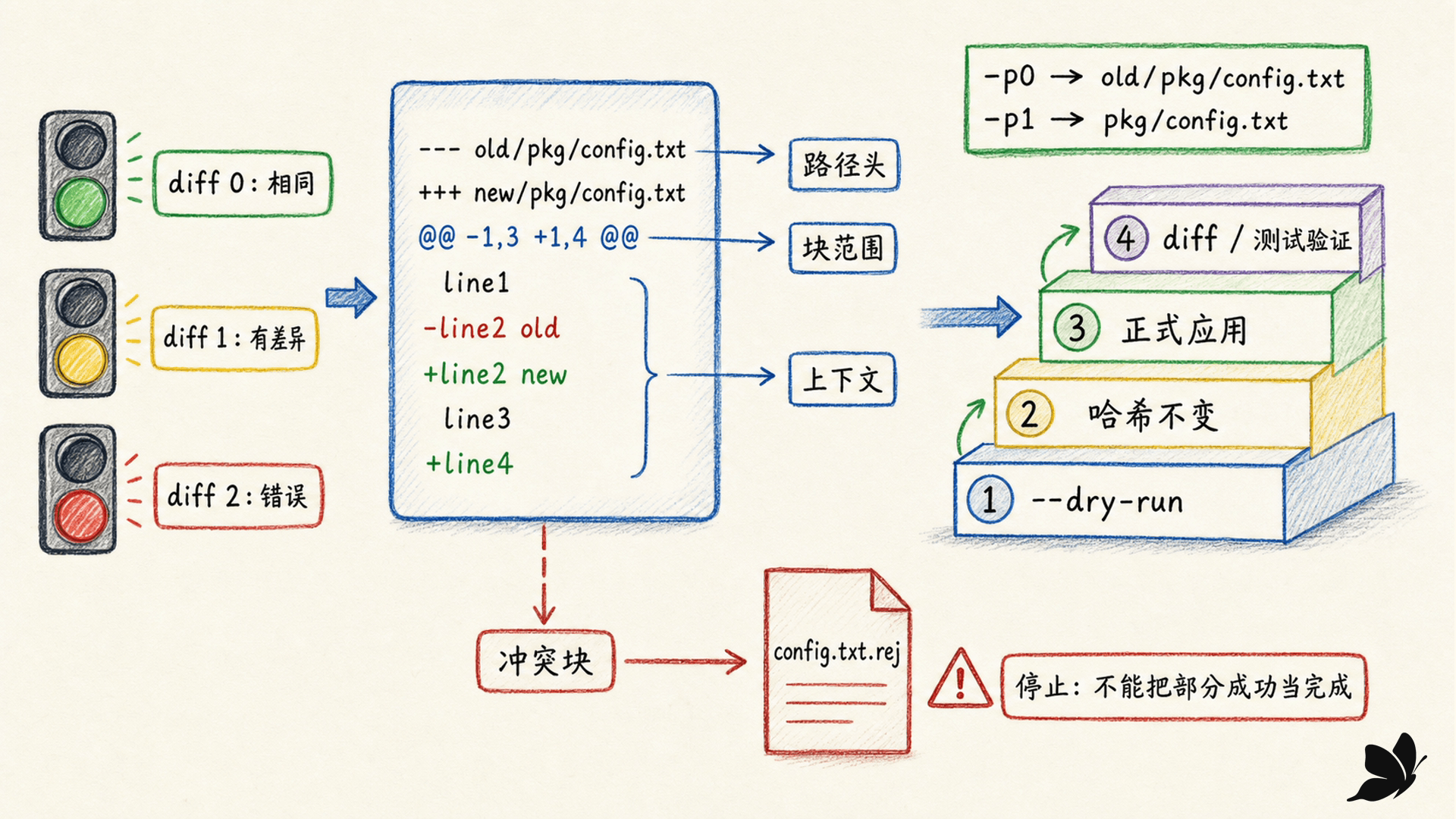
diff 的状态要按契约解释:
受控实验对相同、不同和缺失文件分别得到 0,1,2。因此下面这种检查不能把任何非零都叫故障:
bash
if diff -u old new > change.patch; then
echo '没有变化'
else
status=$?
if [ "$status" -eq 1 ]; then
echo '已生成差异'
else
echo '比较失败' >&2
exit "$status"
fi
fi统一差异包含:
diff
--- old/pkg/config.txt
+++ new/pkg/config.txt
@@ -1,3 +1,4 @@
line1
-line2 old
+line2 new
line3
+line4---、+++ 是旧/新路径,@@ 描述旧、新范围。前导空格是上下文,减号是删除,加号是新增。上下文既方便人审阅,也帮助 patch 在目标中定位块。
38
diff 返回 1 通常表示什么?
39
统一差异中的哪些内容会影响应用?
先 dry-run,再核对 -p 路径与失败块
补丁头若是 old/pkg/config.txt 和 new/pkg/config.txt,在包含 pkg/ 的工作目录运行:
bash
patch --batch --dry-run -p1 < change.patch-p1 剥掉首个路径组件,把两条头路径都解析为 pkg/config.txt。-p0 则不剥离。选择 -pN 不是背固定答案,而是逐段数差异头,并确认当前工作目录下解析后的相对路径确实存在。
--dry-run 打印预测结果而不修改文件。受控实验在干跑前后计算目标 SHA-256,得到 dry-run-unchanged=yes;确认后正式应用,目标变为 line1,line2 new,line3,line4。
若上下文已经改成别的内容,应用返回 1 并生成 config.txt.rej。失败块意味着自动定位没有可靠结果;应停止、审阅 .rej 与当前文件,重新生成或人工合并。增加模糊匹配虽可能让命令通过,却也提高把变更贴到错误位置的风险。
安全流程是:
- 检查差异头和目标版本。
- 在受控副本或干净工作树执行
--dry-run --batch。 - 核对预计修改的每个路径和块。
- 正式应用后再次
diff、测试或构建。 - 检查
.rej、备份文件和退出状态,不以“屏幕没红字”判成功。
40
差异头是 old/pkg/a.conf,工作目录中目标是 pkg/a.conf,应先尝试哪种剥离层级?
41
patch 生成 .rej 后,只要其他块成功,就可以把整个更新视为完成。
让流水线可靠:状态、locale、编码、换行与 NUL
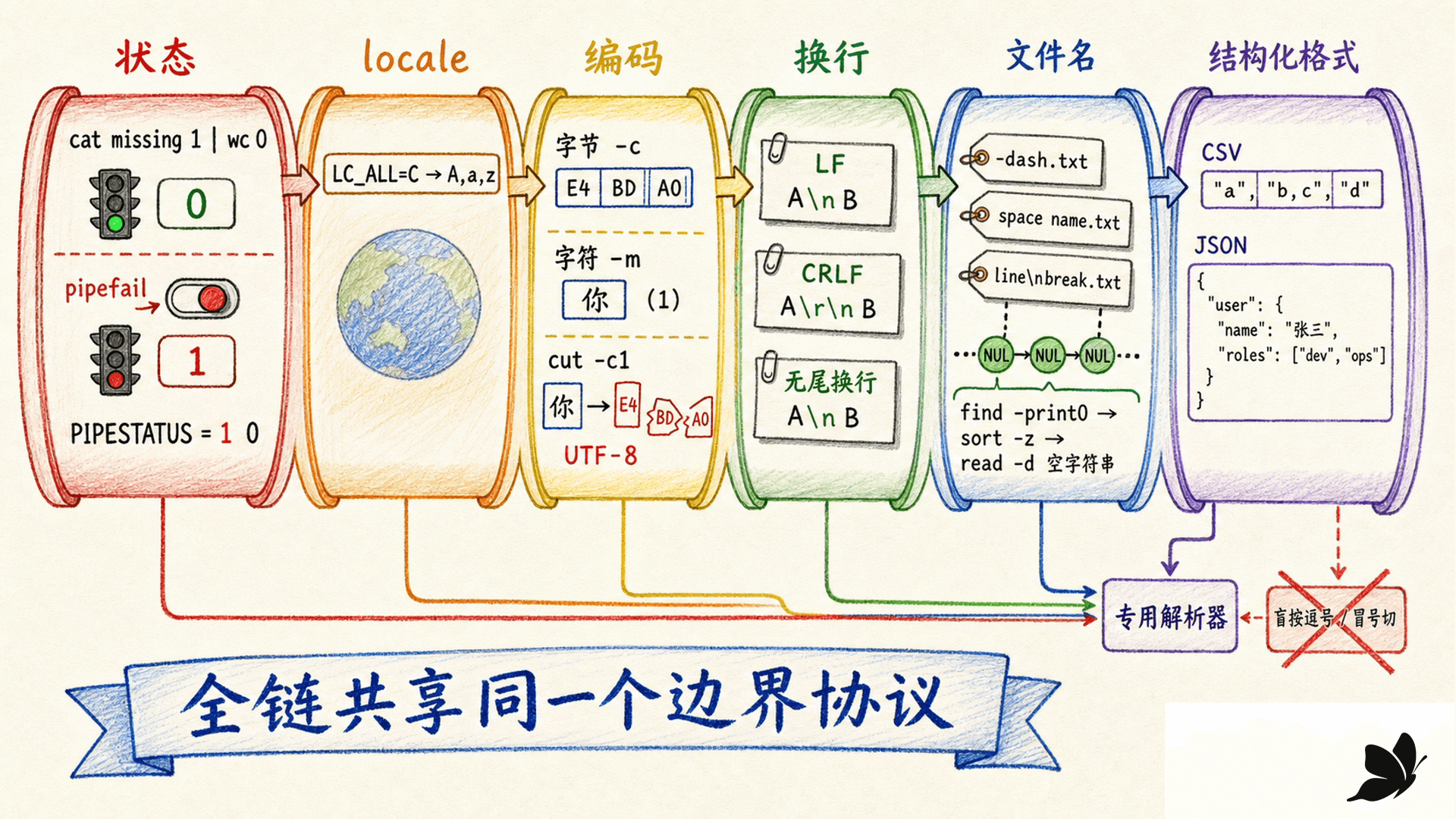
默认只看最后状态,pipefail 才把前段失败带出来
Shell 默认把流水线状态设为最右命令的状态:
bash
cat definitely-missing 2>/dev/null | wc -lcat 失败,但 wc 正常读到空输入并输出 0,所以默认整条管道状态是 0。Bash 中:
bash
set -o pipefail启用后,若任一阶段失败,管道返回最右侧非零状态。受控实验得到:
text
without pipefail: 0
with pipefail: 1
PIPESTATUS: 1 0但 pipefail 不是“所有非零都算故障”的替代品。grep 无匹配返回 1、diff 有差异返回 1,可能是业务结果。脚本要在工具边界处把状态翻译成自己的契约,再交给外层。
set -e 也不是万能错误处理器,它在条件、逻辑列表和管道中的行为有例外。关键脚本应显式检查容易出现业务非零的命令,并给错误输出保留上下文。
42
cat 缺失文件后接 wc -l,默认管道为何可能返回 0?
43
启用 pipefail 后,任何返回 1 的 grep 或 diff 都应无条件作为系统故障。
固定 locale,也要验证编码、CRLF 与无尾换行
LC_ALL=C 常用于机器流水线,因为它一次覆盖其他 locale 分类,排序、字符类和诊断更可复现。但它把许多非 ASCII 数据视作普通字节,不能替代编码验证。
可靠入口通常要明确:
- 文件声称使用什么编码,非法字节怎样处理。
- 记录终止符是 LF 还是 CRLF,是否允许最后一条没有终止符。
- TAB、空格和不换行空格是否同属字段分隔。
- 输出要保留原换行风格,还是统一为明确的新格式。
cat -A、od -An -tx1、file 可以帮助观察,但不能单独证明语义。比如 cat -A 看见 ^M$ 只能证明字节存在;是否删除 CR 要由格式契约决定。
按字节截取可能制造非法 UTF-8,按显示列宽又受宽字符和组合字符影响。若任务涉及用户可见字符、emoji、组合附加符或正规化,应使用支持 Unicode 属性和字素簇的库。
44
固定 LC_ALL=C 能保证什么?
45
发现 CRLF 后,删除所有 CR 前应确认哪些条件?
文件名与二进制:整条链都要支持 NUL
Linux 路径名不能包含 NUL,但可以包含空格、TAB、换行和前导连字符。于是:
bash
find tree -type f -print | while read file; do ...; done不是任意文件名安全协议。正确方向是从生产者到消费者全程用 NUL:
bash
find tree -type f -print0 |
LC_ALL=C sort -z |
while IFS= read -r -d '' file; do
printf '%q\n' "$file"
done受控语料包含 -dash.txt、space name.txt 和名字中真实换行的文件,NUL 流完整保留了三个对象。若中间任一工具不支持 -z,协议就在那一步断裂,应换工具或改设计。
NUL 也常被文本工具用来表示记录边界,但二进制文件不能因此自动变成文本。样本 left 00 right 0a 中,普通逐行工具可能保留 NUL、报告二进制输入或产生难显示输出。压缩包、图像、数据库页应交给对应格式解析器。
46
为什么 find -print0 后面不能随意接一个只按换行读入的工具?
47
只要某个二进制文件中含有换行,就适合用普通行工具完整解析。
何时停止切文本,改用结构化解析器
CSV:逗号不总是分隔符,换行不总是记录末尾
下面是合法意图明确的 CSV:
csv
id,name,note
1,"张三","杭州,值班"
2,"李四","他说""收到"""第二行的 note 中有逗号,但仍是一个字段;第三行用两个双引号表示字段内的字面双引号。引用字段还可以包含 CRLF,使一条逻辑记录跨物理行。
因此:
bash
cut -d ',' -f3 file.csv
awk -F ',' '{print $3}' file.csv只适用于你自己定义且明确禁止引号、嵌入逗号和换行的“逗号分隔简化格式”,不适用于通用 CSV。通用输入应使用理解引号、转义、表头和编码的 CSV 库;解析后再把所需字段转成简单 TSV 或 NUL 流交给命令行工具。
48
CSV 字段中允许逗号和换行时,为什么不能直接 awk -F,?
JSON:冒号和逗号属于嵌套语法
JSON 值可以是对象、数组、字符串、数字、布尔或 null。字符串中的冒号、逗号、引号和反斜杠都有转义规则:
json
{"user":{"name":"张三,值班"},"roles":["ops","oncall"]}用 cut -d ':' 或 sed 's/.*"name"://' 无法可靠处理字段顺序、空白、嵌套、转义和同名键。正确做法是先用 JSON 解析器验证语法并选择路径,再输出清晰的记录格式。对自动化来说,“遇到坏 JSON 立即非零退出”通常比勉强提取一段字符串更有价值。
同样的判断适用于 XML、YAML、日志协议、邮件 MIME 和配置语言。只要格式有嵌套、引用、转义或多行字段,就应优先使用理解语法的解析器。
49
从嵌套 JSON 中稳定读取 user.name,最佳策略是什么?
一次完整实操:从脏记录到补丁验证
这次实操使用一次性 debian:bookworm-slim 容器,所有写入都在 /tmp/welearn-ch20。环境中包含 GNU coreutils 9.1、GNU sed 4.9、mawk 1.3.4、GNU diffutils 3.8;patch 没有安装进系统,而是把包索引、下载包和解包目录全部定向到受控路径。
语料覆盖:
- ASCII、中文、TAB、尾空格、空行与 CRLF。
- 空字段、缺字段、非相邻重复和无尾换行。
- 不同连接键、重复键、排序大小后缀。
- 日志重命名轮转、补丁冲突。
- 空格、换行、前导连字符文件名与 NUL 字节。
关键验证结果:
text
wc: UTF-8 样本 = 1 换行 / 4 字符 / 8 字节
tail descriptor = before-rotate,old-descriptor
tail name = before-rotate,new-file
sort -h = 12K < 800K < 900K < 1M
uniq direct = 非相邻重复仍分开
cut -c1 = e7(该版本截断了 UTF-8)
split/csplit = 连接后与原输入完全一致
diff status = 相同 0 / 有差异 1 / 错误 2
patch dry-run = SHA-256 未变化
patch conflict = 状态 1,并产生 config.txt.rej
pipeline = 默认 0 / pipefail 1 / PIPESTATUS 1 0完整流程没有修改宿主文件或系统目录。脚本末尾删除 /tmp/welearn-ch20 并输出 removed:/tmp/welearn-ch20,容器由 --rm 销毁;返回后检查没有同名容器,宿主也不存在该路径。
为什么清理必须写进测试:排序临时文件、旧补丁副本和上一次语料都会改变下一轮结果。明确生命周期,才能证明输出来自当前命令,而不是残留状态。
50
这组实操为什么故意加入空字段、CRLF、无尾换行和带换行文件名?
51
测试结束删除受控目录并确认容器消失,有助于下一次复跑不继承旧状态。
最后用一条判断链组织文本工具
面对新的文本任务,可以按下面的顺序做决定:
- 识别格式。 普通行文本、TSV、CSV、JSON、路径列表还是二进制?有语法就先用语法解析器。
- 定义记录。 LF、CRLF、NUL、段落还是固定长度?最后一条是否必须有终止符?
- 定义字段。 单字符、TAB、连续空白、固定宽度还是解析后的属性?空字段与缺字段怎样区分?
- 定义键与比较。 写出确切
-k start,end、数值口径、稳定性和 locale;连接两边使用同一规则。 - 一次只做一种变化。 先筛选,再规范字段,再排序,再连接或聚合;保留中间小样本。
- 验证坏输入。 缺字段、非法数值、无尾换行、CRLF、UTF-8 错误、重复键、空输入都要有预期。
- 处理状态。 记录每个工具的 0/1/2 含义;需要时启用
pipefail,但在边界处翻译业务非零。 - 控制副作用。 临时目录、输出文件和补丁都先落到受控副本;
patch先干跑,sed先写新文件。 - 保持协议贯通。 文件名使用 NUL,就让全链支持 NUL;输出声明 TSV,就不要中途混入诊断文本。
- 清理并复跑。 删除受控产物,从空状态再执行一次,确认结果不依赖残留。
文本工具真正强的地方,不是把十个命令挤进一行,而是每个工具都能接收清楚的输入契约、完成一个可验证动作,再交付清楚的输出契约。只要记录、字段、键、locale 和状态都写得出来,一条长流水线就不再是猜谜,而是一组可以逐段证明的变换。
52
拿到陌生数据后,哪一步应排在编写 sort、cut 或 awk 命令之前?
53
一条可维护的文本流水线应留下哪些证据?