Linux 正则表达式:从 shell 展开到 grep、sed、awk 的可靠模式
上一部分处理的是“文件怎样被组织、传递和恢复”。文件进入排查、清洗和自动化流程后,我们面对的常常不再是单个路径,而是成千上万行文本:日志里哪些请求失败了,配置里哪些行真正生效,命名是否符合约定,脚本该把“没有找到”还是“搜索失败”交给下一步。
正则表达式能把一组字符串的共同结构写成模式。不过,真正让人出错的往往不是某个符号没背熟,而是忽略了模式由谁解释。命令行先经过 shell,模式可能再进入 grep、sed、awk 或 find;每一层都有自己的引号、通配和正则方言。只要顺序错一层,屏幕上看似正确的 *、?、括号和反斜杠,传到工具手里就可能已经变了。
我们从解释时序开始,再学习 POSIX BRE 与 ERE,最后把模式放进真实文本工具中。所有输出都来自受控容器里的小语料,示例会同时说明“为什么这样匹配”和“什么条件下不能这样推断”。
先分清两种模式语言:glob 与正则
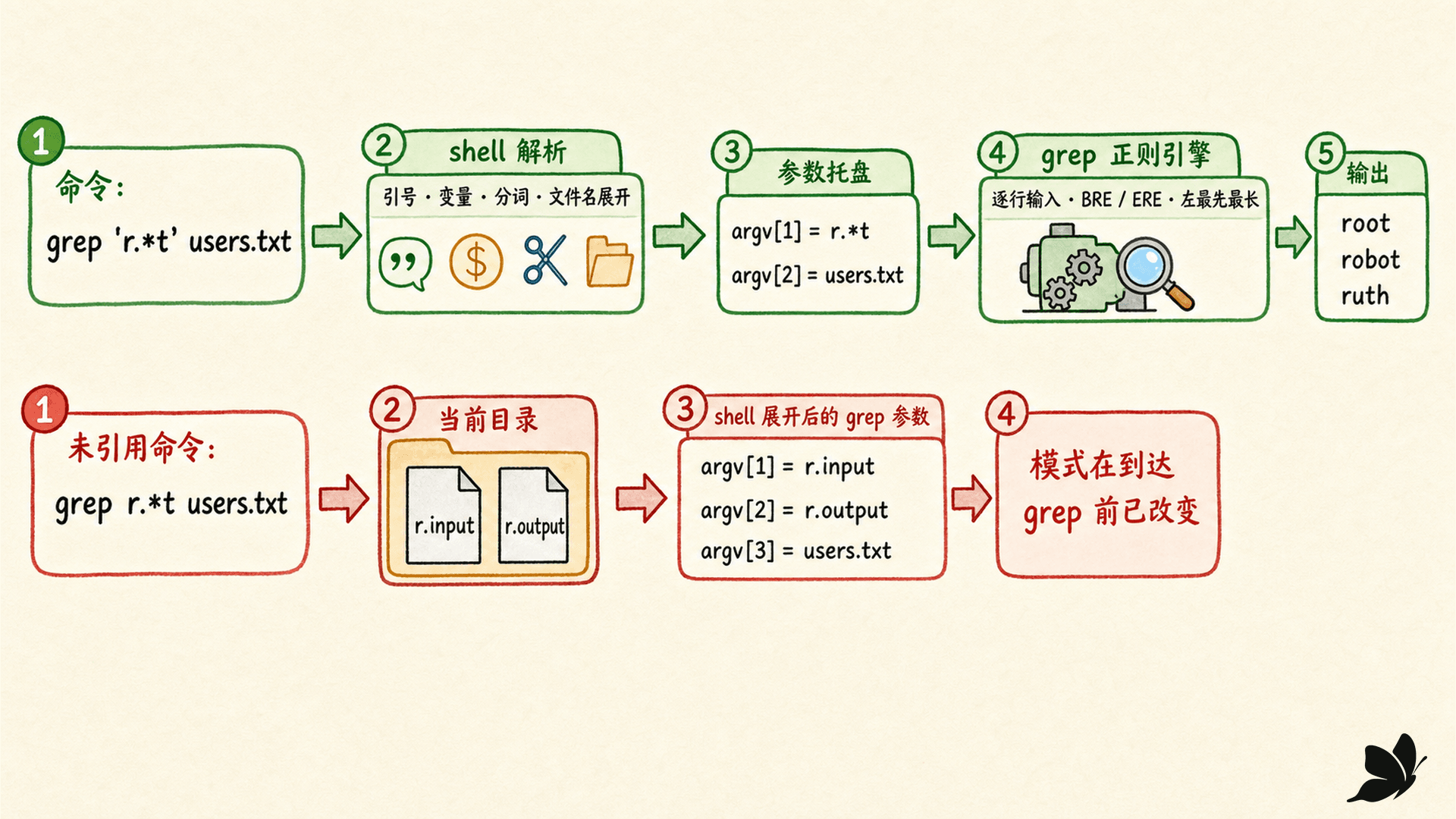
shell glob 匹配文件名,并在命令启动前展开
glob 是 shell 的文件名模式。Bash 看到未引用的 *、? 或方括号后,会在当前目录中寻找匹配的路径,再把一个词替换成零个、一个或多个文件名参数。随后命令才启动。
最常见的三个符号是:
*匹配任意长度的文件名片段,也可以是空片段。?匹配恰好一个字符。[abc]匹配集合中的一个字符。
假设目录中存在 r.input 与 r.output:
bash
printf 'argv=<%s>\n' r.*t真实输出是:
text
argv=<r.input>
argv=<r.output>这里没有任何正则引擎参与。shell 把 r.*t 当成文件名模式,先展开成两个参数。如果写成:
bash
printf 'argv=<%s>\n' 'r.*t'输出才是字面参数 argv=<r.*t>。单引号的作用不是“启用正则”,而是阻止 shell 改写这段字符,把解释权留给后面的命令。
glob 没有匹配时还受 shell 配置影响。Bash 默认通常保留原词;开启 nullglob 后会删除这个词,开启 failglob 后会直接报错。脚本不能把“未匹配 glob 一定原样传递”当成跨环境承诺。以点开头的文件默认也要显式匹配开头的点,除非改变 dotglob 等选项。
1
目录中有 r.input 和 r.output,执行未引用的 grep r.*t users.txt 时,最先解释星号的是谁?
2
给模式加单引号会把 glob 自动转换成正则表达式。
正则描述字符串集合,grep 默认逐行检查
正则表达式不是文件名展开。它描述哪些字符串符合某种结构,由收到模式的工具在自己的输入对象上执行。对普通 grep 来说,输入对象通常是一行文本:工具读取一条记录,寻找该行中是否存在能完成模式的片段,匹配成功就选择整行。
这带来三个直接结论:
grep 'r.*t' users.txt中,shell 把r.*t原样交给 grep,grep 才把.和*当正则符号。- 模式默认不要求覆盖整行。模式
root会选中root、root:x:0:0和chroot所在的行。 - 普通 grep 的模式不能直接跨越换行。换行是记录边界,不是
.可以吞掉的普通字符。
glob 与正则中最容易混淆的是 *。glob 的 * 自己就表示“任意字符串”;正则的 * 是重复运算符,只控制它左边紧邻的那个正则单元。于是,正则里要表达“任意字符重复任意次”,需要写 .*:点号先给出“任意一个字符”,星号再让它重复零次或多次。
find -name '*.log' 还有一层值得留意:引号阻止 shell 展开,但 find -name 收到后仍按 shell 风格模式匹配 basename。它并没有因为被引用就变成正则。
3
关于 grep 的普通文本匹配,哪些说法正确?
4
要把 r.*t 原样交给 grep 当正则,哪种写法边界最清楚?
从最小单元开始读模式
字面量、点号与锚点处理的是字符和位置
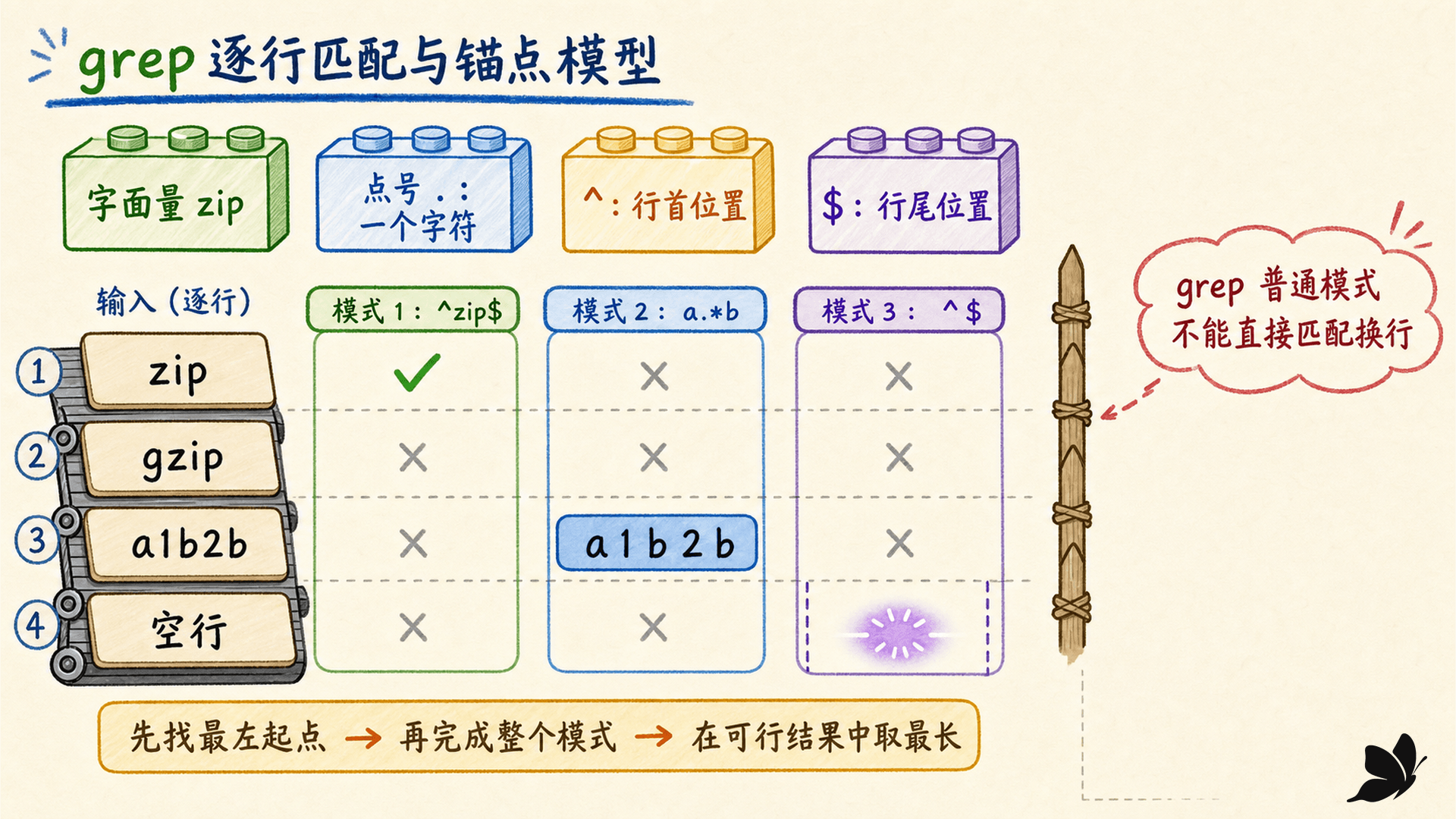
大多数字符在正则里只代表自己。模式 error 依次匹配 e、r、r、o、r,这就是字面量。遇到有特殊含义的字符时,通常要反斜杠转义,或用方括号把它放回字面语境。例如 ERE 中的 \. 匹配点号本身,而 . 匹配一个任意字符。
点号会消耗一个字符。模式 .zip 能在 gzip 中匹配 gzip,却不能在只有三个字符的 zip 中从头完成四字符匹配。它是否匹配编码错误由实现决定;在普通行模式中也不匹配记录分隔的换行。
^ 和 $ 是零宽锚点。它们约束位置,不消耗字符:
bash
grep '^zip' names.txt # 行首紧接 zip
grep 'zip$' names.txt # zip 紧邻行尾
grep '^zip$' names.txt # 整行恰好是 zip
grep '^$' names.txt # 行首立即到行尾,也就是空行整行匹配还可以用 grep -x 'zip'。-x 的价值是表达意图:读命令的人不必检查两端锚点是否漏写。需要匹配字面 ^ 或 $ 时,不要把它们放在锚点位置裸写;明确转义更容易移植和审阅。
5
模式 ^$ 为什么能匹配空行?
6
正则中的点号与 shell glob 中的问号都常表示一个任意字符,但它们由不同解释器在不同阶段处理。
方括号一次选择一个字符
方括号表达式描述一个字符位置允许出现什么。[bg]zip 表示先匹配 b 或 g 中的一个,再匹配 zip。它不是“匹配字符串 bg”,也不是“从集合中选任意多个”。
如果 ^ 紧跟左方括号,它会把集合取反:
text
[0-9] 一个范围中的字符
[^0-9] 一个不在该范围中的字符
[._-] 点、下划线或连字符中的一个
[]a] 右方括号或字母 a
[-a] 连字符或字母 a取反类仍然必须消耗一个字符,所以 [^0-9]* 可以匹配零个或多个非数字字符,但单独的 [^0-9] 不能在空字符串上成功。^ 不在集合第一个位置时通常表示字面符号。连字符放在首尾最容易表达字面量;右方括号要成为成员时通常放在集合开头。
很多元字符在方括号中失去外部含义。[.*] 匹配一个点号或星号,并不表示“任意字符重复”。不过,方括号内部仍有范围、字符类、等价类和排序符号等自己的语法,不能简单认为“里面所有字符都绝对普通”。
7
模式 [^0-9] 能匹配哪些输入位置?
8
要在方括号集合里稳定表达字面连字符,哪种做法最清楚?
locale 决定范围、字符类和大小写的语义
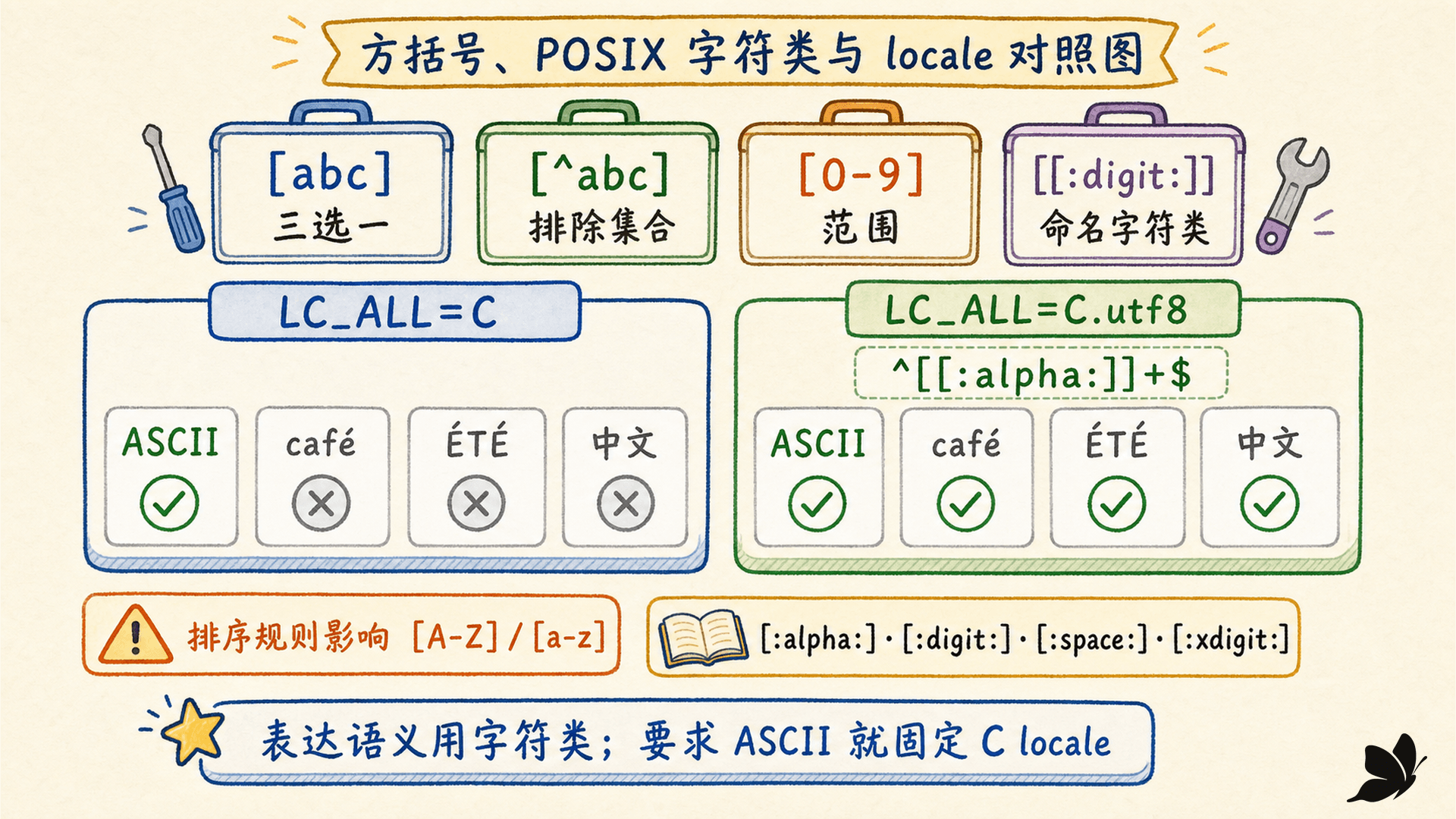
[A-Z]、[a-z] 看似直观,实际会受排序规则影响。在 LC_ALL=C 下,它们按传统 ASCII 顺序解释;其他 locale 可能有不同的排序元素和等价关系。GNU grep 明确把非 C locale 中的范围行为视为不应随意假设的区域。
POSIX 命名字符类通常更适合表达语义:
注意双层方括号:字符类名字是 [:alpha:],它必须位于外层方括号表达式中,完整写成 [[:alpha:]]。
隔离实验对同一份语料执行:
bash
LC_ALL=C grep -En '^[[:alpha:]]+$' multilingual.txt
LC_ALL=C.utf8 grep -En '^[[:alpha:]]+$' multilingual.txt真实结果是:
text
C:
1:ASCII
C.utf8:
1:ASCII
2:café
3:ÉTÉ
4:中文这不是谁“更正确”,而是契约不同。只允许 ASCII 标识符时,显式使用 LC_ALL=C 并写出 ASCII 规则;要表达自然语言字母时,使用合适的 UTF-8 locale 与字符类,并用真实样本测试。grep -i 的大小写折叠也受 locale 影响,不能把英语的一一映射推给所有字符。
9
若格式规范明确只接受 ASCII 大写字母,最可审阅的做法是什么?
10
[[:alpha:]] 在所有 locale 下都只等价于 ASCII 的 A 到 Z 和 a 到 z。
用重复、连接、选择和分组组装结构
重复运算符只控制前一个正则单元
以 ERE 为例,常用重复运算符是:
“前一个单元”可能是字面字符、点号、方括号表达式或括号分组。ab+ 控制的只有 b,因此匹配 ab、abb、abbb;(ab)+ 控制整个分组,因此匹配 ab、abab、ababab。
零次是很多误判的来源。colou?r 接受 color 和 colour;[[:digit:]]* 也接受完全没有数字的空片段。如果字段必须至少有一位数字,应使用 ERE 的 [[:digit:]]+,或 BRE 的对应写法,而不是星号。
区间能比连续堆叠问号更清楚地表达上下界。不要把很大的重复上限当作“更严格”;过大的计数会增加资源开销,某些实现还有可移植上限。
11
ERE 模式 ab+ 能匹配下列哪一项?
12
若字段必须包含 2 到 4 位十进制数字,哪些写法表达了这个次数约束?
连接高于选择,重复又高于连接
相邻正则自动连接。ERROR[[:space:]]+[[:digit:]]+ 表示先出现 ERROR,再出现至少一个空白,最后出现至少一位数字。连接不需要额外运算符。
ERE 的 | 表示选择,优先级低于连接。模式:
text
^warn|error$实际分组是:
text
(^warn)|(error$)它会接受任何以 warn 开头的行,也接受任何以 error 结尾的行,而不是只接受整行 warn 或 error。若目标是两个完整单词,应写:
text
^(warn|error)$从高到低记住三层就够用:重复、连接、选择。括号可以覆盖默认优先级,并定义子表达式。复杂模式不要靠目测猜结合顺序;先给每个选择分支加括号,再逐层移除确实多余的括号。
13
ERE ^cat|dog$ 的实际含义是什么?
14
在传统 ERE 中,重复运算符的优先级高于连接,连接又高于选择。
空匹配、贪婪与左最先最长不是一回事
有些模式可以不消耗任何字符:空正则、锚点、x* 在零次重复时都能产生空匹配。空匹配并不代表“没有发生匹配”。它是位于字符之前、字符之间或字符之后的一个有效位置。
实验中,awk 对 ABC 执行空正则的全局替换:
bash
awk 'BEGIN { x="ABC"; gsub(//, "|", x); print x }'真实输出是:
text
|A|B|C|四个竖线对应三个字符形成的四个空位置。工具必须在空匹配后推进,否则全局替换可能永远停在同一位置。不同工具对“只输出匹配片段”时的空匹配有专门规则,不能仅凭肉眼推演输出条数。
传统 POSIX 匹配选择可以概括为“左最先、整体最长”:先选择最靠左、能让完整模式成功的起点;起点相同时,再选择可行的最长整体匹配。于是 a.*b 在 a1b2b 中从第一个 a 开始,并延伸到最后一个仍能完成模式的 b。
“贪婪”是解释重复行为的方便说法,但不要把它误解成某个量词可以破坏后续模式。.* 仍要为后面的 b 留出能够完成匹配的位置。也不要直接把 PCRE 的懒惰量词 *? 搬到普遍部署的 grep -E;工具版本、标准版本和实现支持必须单独确认。
15
传统最长匹配下,a.*b 在 a1b2b 中输出哪个片段?
16
能匹配空字符串的模式,在全局替换中不需要任何推进规则。
选对方言:BRE、ERE、固定字符串与 PCRE
BRE 与 ERE 主要区别在符号何时需要反斜杠
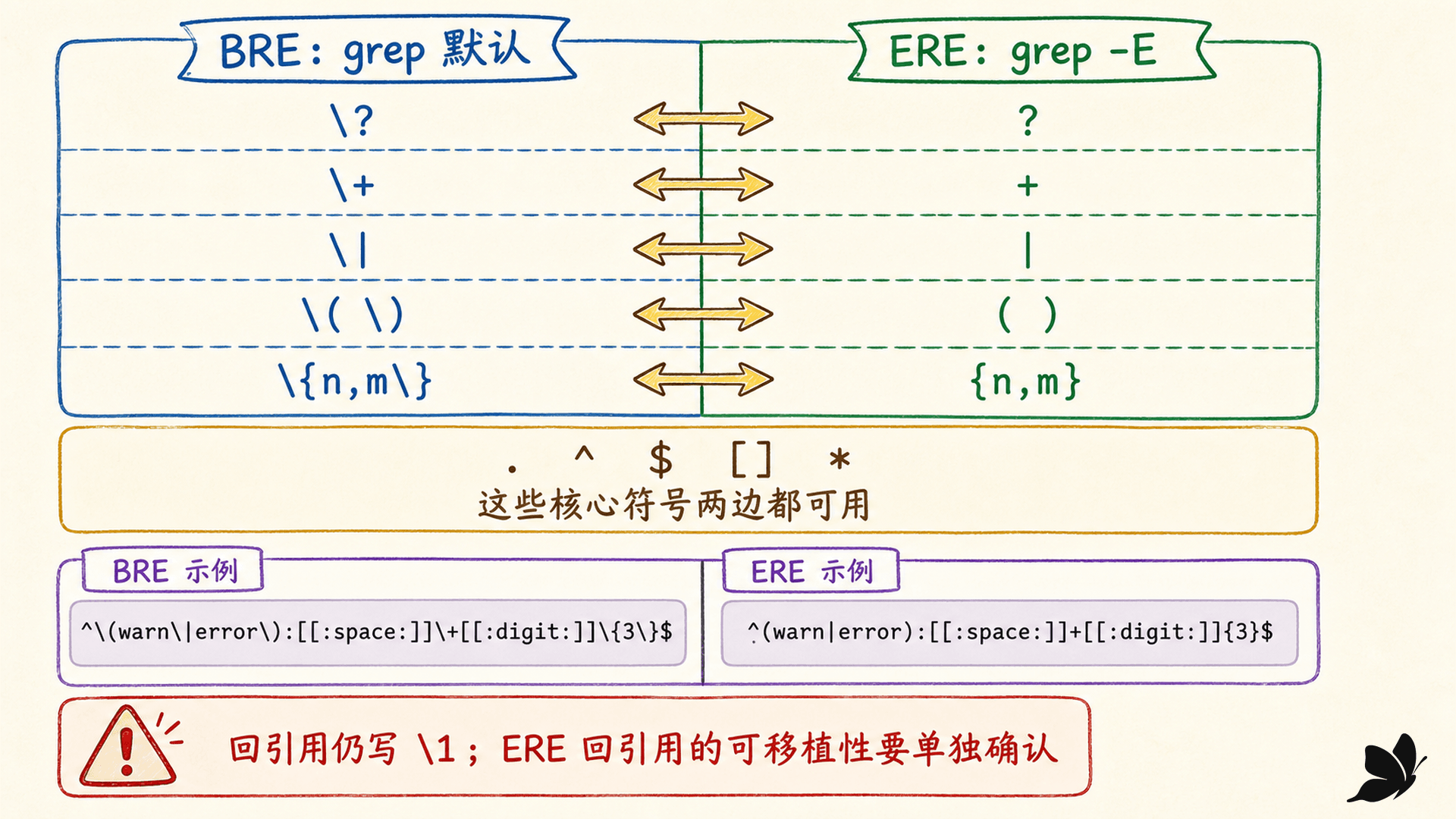
GNU grep 默认把模式解释为 BRE,grep -E 使用 ERE。两者共享字面量、点号、锚点、方括号和星号。最常见差异集中在分组、选择、问号、加号和区间:
这里要加两层可移植性说明。第一,GNU grep 的 BRE 支持 \?、\+、\|,但它们不是所有 POSIX BRE 实现都可靠支持的核心写法;需要这些能力时,grep -E 更清楚。第二,反斜杠不是越多越安全。在 ERE 中,+ 是重复元字符,\+ 反而匹配字面加号。
同一个意图的实测对照:
bash
grep 'ab\{2,\}' corpus.txt
grep -E 'ab{2,}' corpus.txt两条命令都选出 abb 与 abbb。方言改变的是记法,不应凭记法外观推断一个引擎“更强”。跨工具复制模式时,先写下源工具和目标工具各自使用的方言,再做转换。
17
要在 ERE 中匹配字面加号,哪种写法正确?
18
GNU BRE 的 ^\\(ab\\)\\1$ 转成 GNU ERE 后,最接近哪一项?
grep 的四个入口解决四类问题
GNU grep 提供四个主要入口:
- 默认或
-G:BRE。 -E:ERE,POSIX 标准入口。-F:固定字符串,不把模式当正则。-P:PCRE,需要 GNU grep 构建支持,不能当作 POSIX 通用能力。
如果目标只是找字面 a+b、IP 片段或错误码,先用 grep -F。这既避免元字符误解,也通常能走更直接的固定字符串算法。需要选择、分组和次数约束时再切换 -E。已有 BRE 脚本不必为了“看起来现代”盲目改写,但新增复杂规则使用 ERE 通常更易读。
-P 适合确实依赖 PCRE 功能并能控制部署环境的任务,例如某些前后查找或特定 Unicode 属性。它的匹配选择、回溯行为和资源风险与 POSIX ERE 不完全相同。命令在一台环境运行成功,不能证明精简系统、BusyBox 或另一版 grep 同样支持。
旧命令名 egrep 等价于 grep -E 的历史入口,但新脚本直接写 grep -E 更能暴露方言选择,也减少不同发行环境的兼容疑问。
19
哪些场景优先使用 grep -F 更合理?
20
grep -P 属于所有 POSIX grep 都必须支持的通用接口。
shell 引号与工具语法形成多层解析
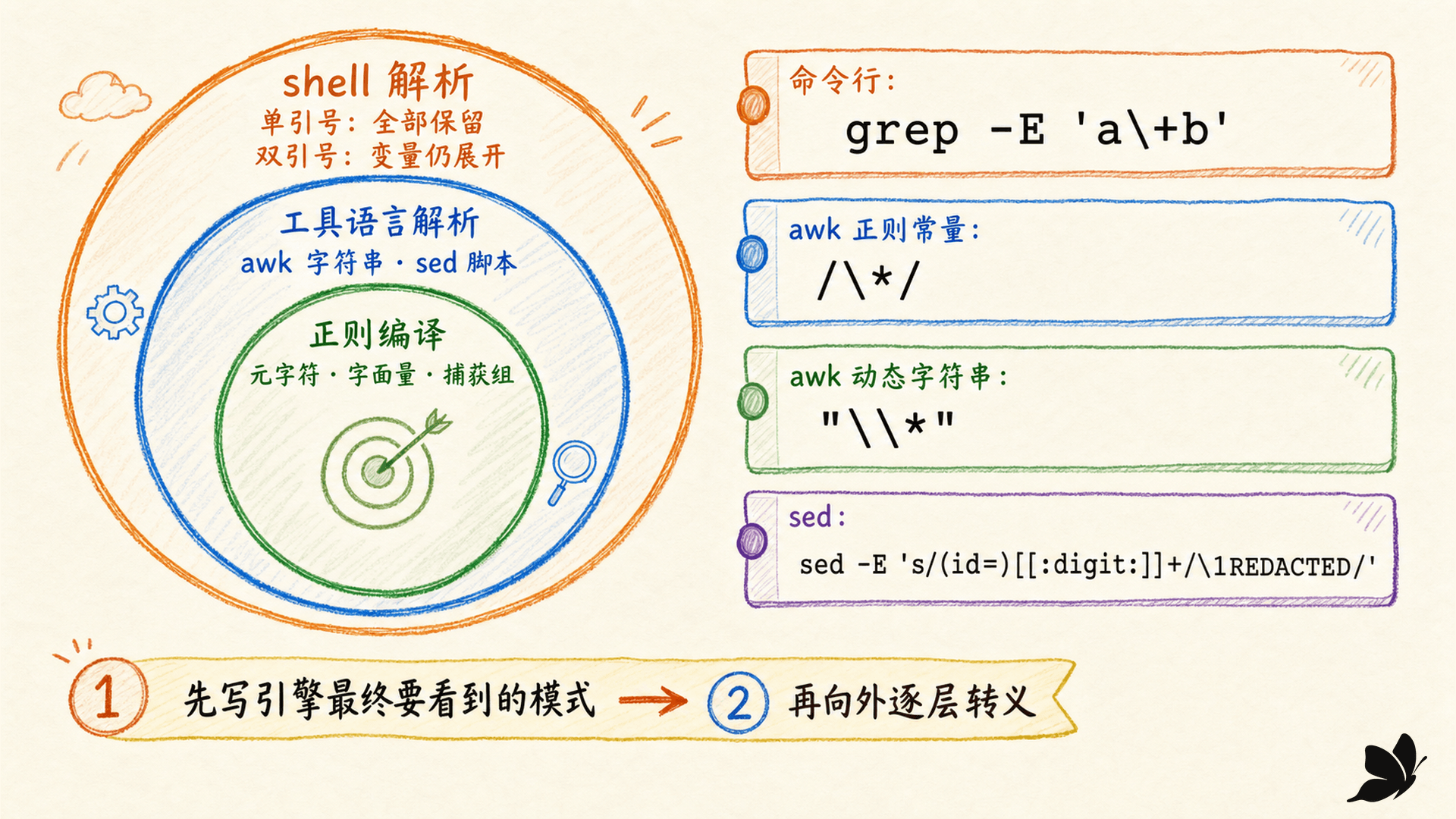
写模式时,先问“正则引擎最终应该看到什么”,再向外处理工具字符串和 shell 引号。
在命令行里,单引号是默认选择:
bash
grep -E '^[[:alpha:]_][[:alnum:]_]*$' names.txtshell 不处理其中的美元符号、星号、反斜杠或空格,整段成为一个参数。双引号会抑制文件名展开和分词,但仍展开 $variable、命令替换和部分反斜杠,因此只有确实要把变量插进模式时才使用,并且要重新审查注入的字符是否应被当成正则。
awk 还可能再多一层。正则常量:
awk
/\*/表示匹配字面星号。动态正则字符串则写:
awk
"\\*"awk 先把字符串中的双反斜杠变成一个反斜杠,再把 \* 交给正则编译器。若整个 awk 程序又放在 shell 双引号中,解析层继续增加。最稳妥的方法不是凭感觉堆反斜杠,而是逐层写出每一层收到的实际字符串。
21
命令行模式不需要变量展开时,为什么通常优先使用单引号?
22
awk 动态正则字符串为何常比斜杠包围的正则常量多一层反斜杠?
把 grep 当成可组合的搜索工具
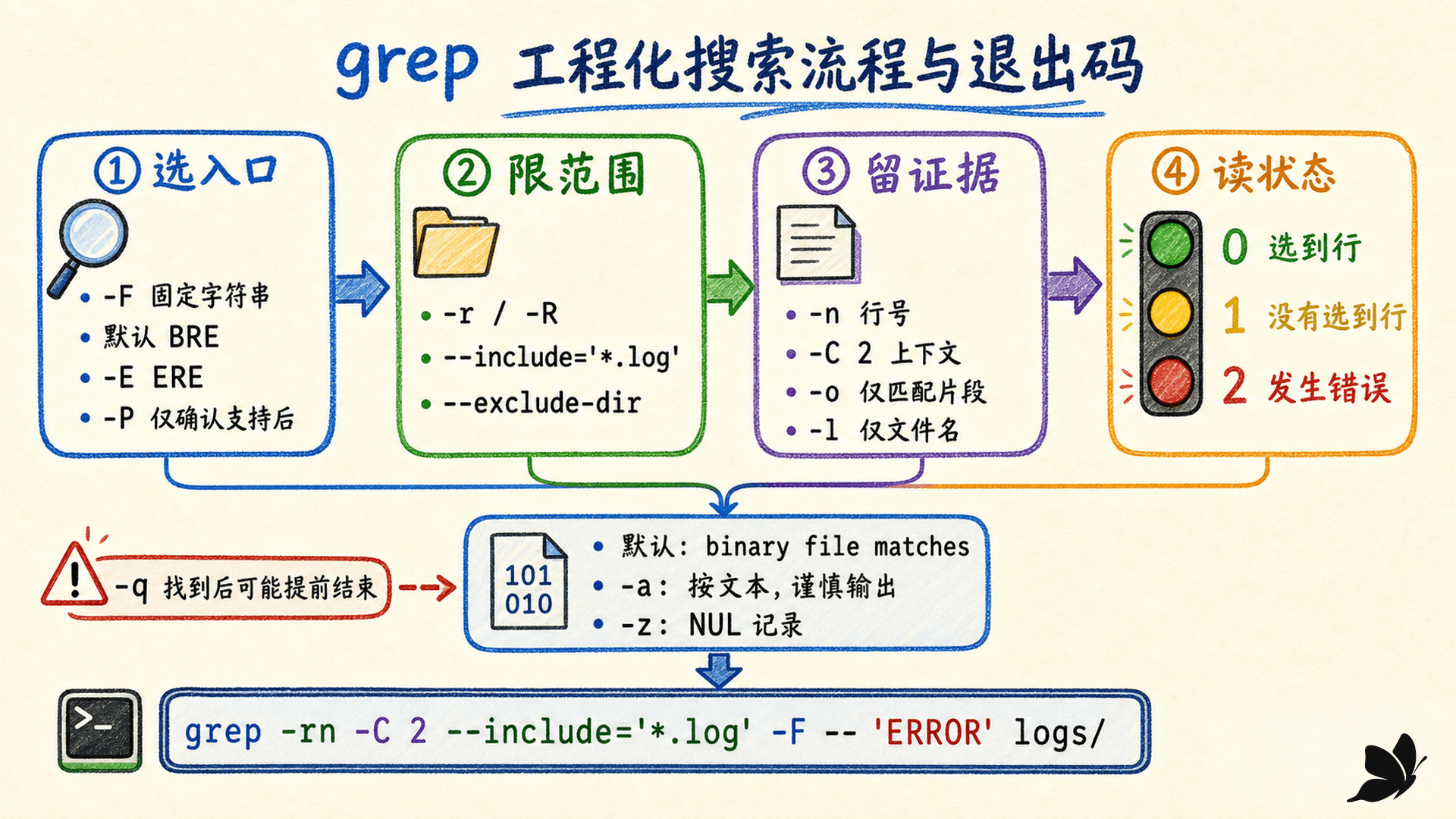
先控制选择,再控制输出
grep [选项] 模式 [文件...] 的表面形式很短,可靠使用时应把选项分成几组。
第一组改变“哪些行算选中”:
-i忽略大小写,行为受 locale 影响。-v反转选择,只输出不匹配的行。-x要求整个记录匹配。-w要求匹配片段形成单词边界;单词字符包括字母、数字和下划线,它不等价于给任意模式简单加两个锚点。-e pattern明确增加模式,适合模式以连字符开头或需要多模式。-f file从文件读取模式,每行一个;空模式文件匹配不到任何内容。
第二组改变“怎样留下证据”:
-n加行号,-H强制显示文件名,-h隐藏文件名。-o只输出非空匹配片段,每个片段单独一行。-c输出选中行数,不是每行中的匹配次数。-l只列出有选中行的文件,-L列出没有选中行的文件。-m N在每个输入达到 N 条选中行后停止。-A N、-B N、-C N分别给出后文、前文和双向上下文。
上下文输出中,匹配行字段通常用冒号分隔,非匹配上下文用连字符分隔,不连续的组用 -- 分开。这个小差异能让脚本或读者分辨哪行是真正命中,不能把上下文里的 ERROR 旁边所有行都当成匹配结果。
模式或文件名可能以 - 开头时,使用 -- 终止选项:
bash
grep -n -F -- '-Xmx' jvm.options23
哪些 grep 选项主要改变输出形态,而不是模式方言?
24
grep -c 输出的数字通常表示什么?
退出码是搜索结果的一部分
grep 的正常状态不是简单的“零成功、非零失败”:
隔离实验得到:
text
match=0 no_match=1 invalid_regex=2因此脚本应显式分流:
bash
if grep -q -F -- 'READY' service.log; then
printf '%s\n' '服务已经就绪'
else
rc=$?
case $rc in
1) printf '%s\n' '尚未出现就绪标记' ;;
*) printf '%s\n' '搜索过程出错' >&2; exit "$rc" ;;
esac
fi-q 找到第一条匹配后立即返回,适合条件判断,却有两个边界。第一,它不会证明文件剩余部分可读;GNU grep 在已经找到匹配后,即使之后本可能遇到错误,也可能返回 0。第二,管道上游继续写数据时,grep 提前关闭管道可能让上游收到 SIGPIPE;开启 pipefail 后,整条管道状态可能因此非零。
开启 set -e 的脚本还要把“无匹配是业务分支”放进 if、case 或显式状态处理,避免状态 1 让脚本在分流前退出。
25
grep 返回 1 时,最准确的解释是什么?
26
grep -q 返回 0 足以证明整个输入都成功读完且没有任何后续错误。
递归、二进制和 NUL 需要单独设计
递归搜索时,-r 与 -R 的差异落在符号链接:-r 跟随命令行直接给出的符号链接,但跳过遍历中遇到的其他符号链接;-R 会跟随全部符号链接。后者可能进入意外目录、重复树或跨越挂载边界,不能只因为“大写更彻底”就默认使用。
--include、--exclude、--exclude-dir 使用的是文件名 glob,不是 grep 正则,而且也要引用以防 shell 提前展开:
bash
grep -rn -C 1 --include='*.log' --exclude-dir='.git' -F -- 'ERROR' tree/真实输出的一组片段是:
text
tree/service/app.log-1-2026-07-16 INFO boot
tree/service/app.log:2:2026-07-16 ERROR id=42
tree/service/app.log-3-2026-07-16 INFO retry
--
tree/archive/old.log:1:2026-07-15 ERROR id=7GNU grep 遇到 NUL 或当前 locale 下的非法编码时,可能把输入判断为二进制,默认只报告 binary file matches。可选策略有:
-a或--binary-files=text:强制按文本处理。它可能把控制字节送到终端,面对未知数据时应输出到受控管道或文件。-I或--binary-files=without-match:把二进制视为没有匹配。-z:把 NUL 作为输入与输出记录的终止符,适合 NUL 分隔数据。-Z:只把输出文件名后的分隔符改成 NUL,常与-l、xargs -0配合。
-z 与 -Z 只差大小写,职责却不同。文件名可以含换行但不能含 NUL,所以传递任意文件名时应使用 NUL 通道,不能依赖逐行切分。
27
关于 grep 的递归和 NUL 选项,哪些说法正确?
28
未知二进制文件中发现匹配后,为什么不应随意用 grep -a 直接输出到终端?
捕获与回引用:先确认工具支持什么
grep、sed 与 awk 的捕获能力并不对称
括号有两个常见作用:改变优先级,以及建立子表达式。回引用 \1 表示“再次匹配第一个子表达式刚才匹配到的具体文本”,不是“再次执行第一个模式”。
GNU grep 中:
bash
grep '^\(ab\)\1$' corpus.txt
grep -E '^(ab)\1$' corpus.txt都实测选中 abab。第一条是 BRE 分组,第二条使用 GNU ERE 回引用。需要注意:POSIX ERE 不把回引用作为可移植基线,另一实现可以拒绝或给出不同边界。grep 也不会单独输出某个捕获组;-o 输出的是整个非空匹配片段。
sed 的回引用同时出现在搜索模式和替换串中:
bash
sed -n -E '/^ERROR/s/(id=)[[:digit:]]+/\1REDACTED/p' corpus.txt真实输出:
text
ERROR 2026-07-16 id=REDACTED替换串里的 \1 取第一个组,未转义的 & 代表整个匹配。两者都属于替换语法,不能把 & 放回搜索模式后期待同样作用。
POSIX awk 使用 ERE,但不要在 awk 正则里假设 \1 是回引用。match() 可通过 RSTART 与 RLENGTH 给出整体匹配;GNU awk 的 match(text, regex, array) 捕获数组和 gensub() 的分组替换是扩展。要写可移植 awk,优先通过字段、substr() 或多个明确步骤拆出内容。
29
sed 替换串中的未转义 & 表示什么?
30
因为 GNU grep -E 实测支持回引用,就可以推断所有 POSIX ERE 工具都必须支持。
性能风险取决于引擎和模式特征
“正则一定会灾难性回溯”和“grep 永远线性”都过于绝对。GNU grep 对普通固定模式和许多无回引用的 BRE/ERE 使用高效自动机与固定字符串算法;这些路径与典型 PCRE 回溯引擎并不相同。
当模式包含回引用时,自动机无法一般化地表达“再次出现完全相同的任意子串”,GNU grep 会进入更慢的匹配路径。模糊分组、层叠重复和很大的区间计数也可能增加时间或内存。PCRE 中,像嵌套的 (a+)+ 配合失败尾部,可能产生大量候选回溯;但不能据此把所有 .* 都称作灾难性回溯。
实用审查顺序是:
- 能用
-F就不用正则。 - 能用明确字符类和锚点,就少用无边界的
.*。 - 删除不必要的捕获与回引用。
- 避免让两个可重复部分争夺同一片输入,例如多个相邻、嵌套的宽泛重复。
- 用上限明确的小样本、超时和资源限制做性能测试,不拿生产大文件直接试错。
- 固定工具版本、方言与 locale,记录最坏输入而不是只测成功样本。
安全审查还要考虑输入控制权。内部短日志与攻击者可提交的长字符串是两种风险模型;相同模式在前者可接受,在后者可能成为资源消耗入口。
31
哪些做法能降低正则性能失控的概率?
32
什么时候谈灾难性回溯最准确?
同一模式进入 sed、awk 与 find 后会改变语境
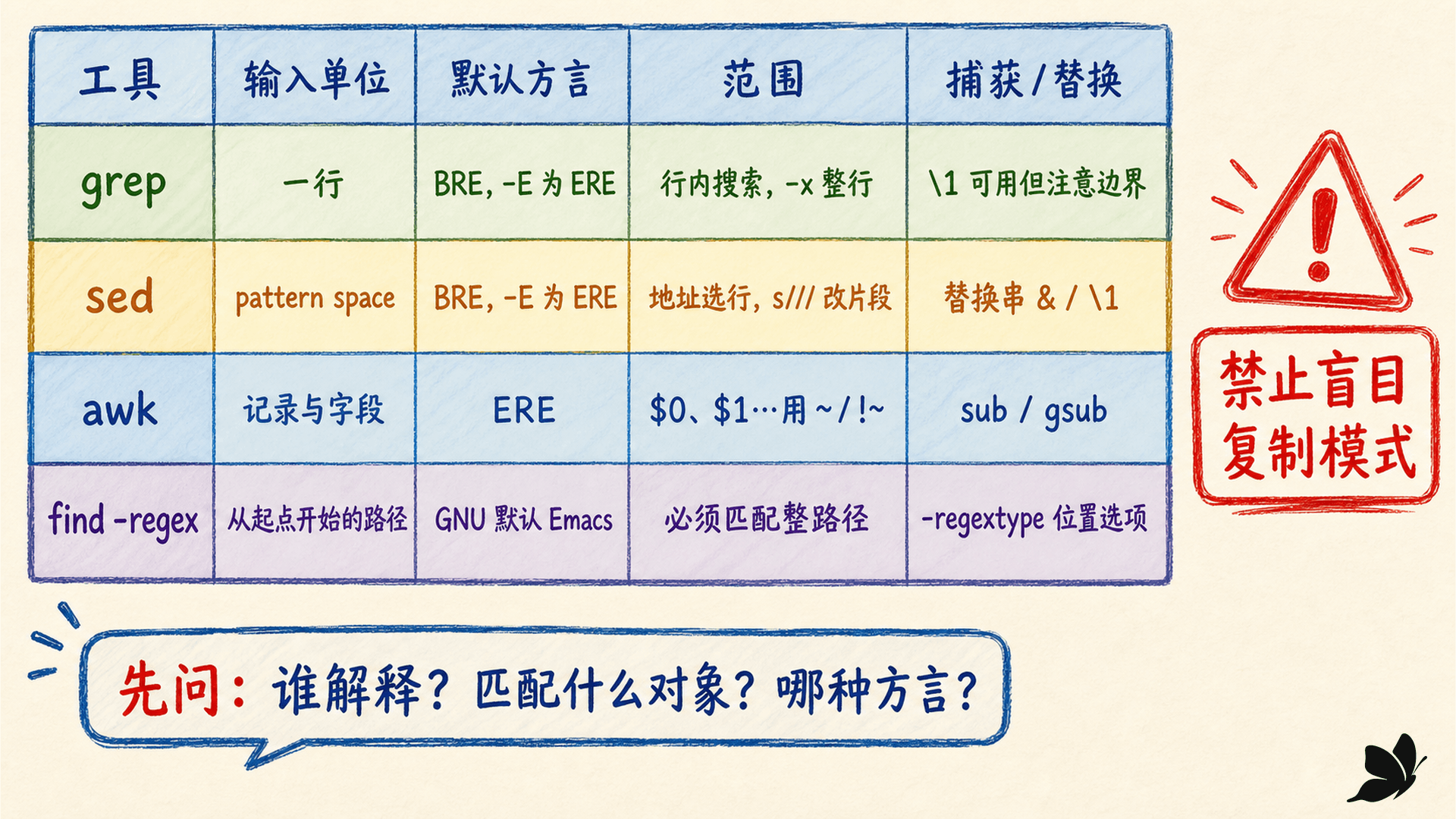
sed 先用地址选 pattern space,再执行动作
sed 默认逐行读取输入到 pattern space,按脚本执行命令,再把结果写到标准输出。一个常见结构是:
text
[地址]动作正则地址 /ERROR/ 选择含有匹配的 pattern space,动作 d 删除,p 打印,s 替换:
bash
sed '/^[[:space:]]*#/d' config.ini
sed -n '/^ERROR/p' app.log
sed -E '/^ERROR/s/(id=)[[:digit:]]+/\1REDACTED/' app.logsed 默认正则是 BRE,-E 切换 ERE。s/regexp/replacement/ 默认只替换当前 pattern space 中第一个匹配,末尾 g 才替换全部:
bash
sed 's/:/%/' data.txt
sed 's/:/%/g' data.txt分隔符不必是斜杠。路径含大量斜杠时,s#/old/path#/new/path# 更易读。无论选择哪个分隔符,正则、替换串和分隔符的转义是三套相关但不同的规则。
默认 pattern space 不含输入换行,所以普通 sed 模式也逐行工作。N 可以把下一行连同换行读入 pattern space,此时模式才可能接触内部换行。跨行 sed 脚本应把 pattern space 的状态变化写清楚,不能把单行例子直接扩大。
33
sed 的 s/old/new/g 中,末尾 g 改变了什么?
34
sed 正则地址只决定哪些 pattern space 执行动作,动作本身仍要单独阅读。
awk 用记录、字段和 ~ 组合条件
awk 默认把每行作为一条记录 $0,再按字段分隔规则得到 $1、$2 等字段。斜杠包围的正则单独作为 pattern 时,相当于检查 $0:
bash
awk '/^ERROR/ { print NR, $0 }' app.log对任意字符串或字段使用 ~ 与 !~:
bash
awk '$2 ~ /^(WARN|ERROR)$/ { print $1, $2 }' app.log
awk '$0 !~ /^[[:space:]]*(#|$)/ { print }' config.ini隔离语料的真实结果展示了两个条件:
text
match: ERROR 2026-07-16 id=42
no-digit: café
no-digit: 中文这里第一条用 $0 ~ /^ERROR/,后两条要求整条记录不含数字且匹配 café|中文。awk 的正则是 ERE 风格;不要给分组括号加 BRE 风格反斜杠。
动态正则适合把参数传进程序:
bash
awk -v pat='^ERROR' '$0 ~ pat { print }' app.log但 pat 是字符串,会先经过 shell 与 awk 字符串层。外部输入若被当作正则,就拥有元字符能力;如果用户想查固定文本,应自行转义元字符,或改用 index($0, needle) 做字面查找。
35
awk 表达式 $2 !~ /ERROR/ 表示什么?
36
用户输入只应做字面子串查找时,awk 中哪种思路更稳妥?
find 的 -regex 匹配整条遍历路径
GNU find 有三类容易混淆的入口:
-name pattern:用 shell 风格模式匹配 basename。-path pattern:用 shell 风格模式匹配从启动点得到的路径。-regex expression:用正则匹配从启动点得到的整条路径。
“整条路径”意味着 find ./tree -regex 'app\.log' 不会只因为某个 basename 是 app.log 就成功。隔离实验中这条命令没有输出;写成:
bash
find ./tree \
-regextype posix-extended \
-regex '.*/[^/]+\.log' \
-print才得到:
text
./tree/archive/old.log
./tree/service/app.log启动点也是候选路径的一部分。find tree 产生的路径以 tree/ 开头,find ./tree 则以 ./tree/ 开头;模式必须与实际形式一致。
GNU find 默认 -regex 方言是 Emacs 风格,不应假设它等同于 grep -E。-regextype posix-extended 可以显式选择 ERE,而且它是位置选项,只影响其后出现的测试。模式仍应放在单引号中,防止 shell 抢先解释星号和方括号。
37
关于 GNU find 模式,哪些说法正确?
38
find ./tree -regex 'app\\.log' 没有输出,最可能的原因是什么?
构造和调试正则:一次只增加一个约束
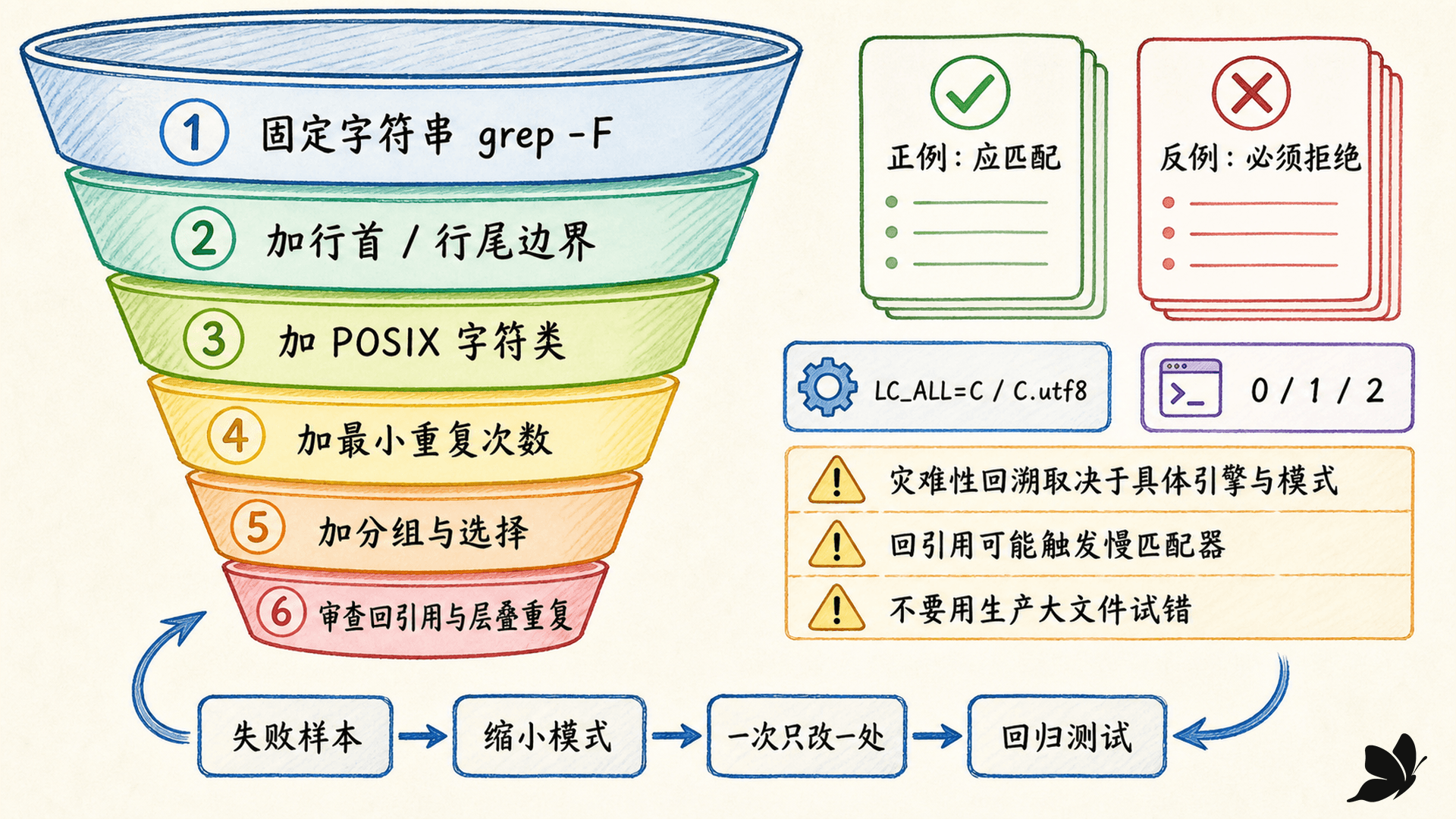
先证明固定核心,再逐步泛化
直接写一条长正则,很难判断失败来自输入、引号、方言、locale 还是模式本身。更可靠的顺序是从最小、可证明的核心开始。
假设目标是识别这种日志行:
text
ERROR 2026-07-16 id=42可以分六步构造:
bash
#步骤1:固定核心存在吗
grep -Fn -- 'ERROR' app.log
#步骤2:只允许行首 ERROR
grep -n '^ERROR' app.log
#步骤3:加固定日期骨架
grep -En '^ERROR[[:space:]][[:digit:]]{4}-[[:digit:]]{2}-[[:digit:]]{2}' app.log
#步骤4:加字段名和至少一位数字
grep -En '^ERROR[[:space:]][[:digit:]]{4}-[[:digit:]]{2}-[[:digit:]]{2}[[:space:]]id=[[:digit:]]+' app.log
#步骤5:最后才锁定行尾
grep -En '^ERROR[[:space:]][[:digit:]]{4}-[[:digit:]]{2}-[[:digit:]]{2}[[:space:]]id=[[:digit:]]+$' app.log每一步只改变一个假设,并立即看新增的正例和反例。这样发现“末尾还有 request_id 字段”时,你知道失败来自最后的 $,而不是日期字符类。
正则只检查文本形状,不会验证日期真的存在。2026-99-99 也满足两位月日骨架。需要日历语义时,先用正则提取候选,再交给日期解析器验证。把所有业务规则塞进一个模式,通常会降低可读性,还可能增加性能风险。
39
构造复杂日志模式时,为什么先用 grep -F 验证固定核心?
40
模式中的两位月份和两位日期足以证明日期在日历上真实存在。
正例、反例、边界例和环境构成测试矩阵
只准备“应该成功”的样本,会让过宽模式看起来很完美。至少准备四组:
- 正例:必须匹配,例如标准格式、允许的最短值和最长值。
- 反例:必须拒绝,例如缺字段、错误分隔符、多余前后缀。
- 边界例:空行、只有一个字符、最大重复次数、行尾没有换行。
- 环境例:
LC_ALL=C与目标 UTF-8 locale、不同工具版本、BRE 与 ERE 入口。
一个最小测试文件可以同时放中文、重音字母、ASCII、空行和相似但错误的日志。运行时不要只看输出,还要保存命令、版本、locale 和退出码:
bash
printf '%s\n' \
'ERROR 2026-07-16 id=42' \
'ERROR 2026/07/16 id=42' \
'ERROR 2026-07-16 id=' \
'prefix ERROR 2026-07-16 id=42' > cases.txt
LC_ALL=C grep -En "$pattern" cases.txt
rc=$?
printf 'status=%s\n' "$rc"这里双引号是有意的:变量要展开成模式参数,同时整体保持一个参数。前提是 pattern 本来就被授权成为正则。如果它来自只应字面查找的外部输入,应改用 grep -F -- "$needle"。
每修一个问题,都把触发问题的输入加入回归集。正则测试不是“看一次颜色高亮”,而是一个有预期结果、状态断言和环境记录的可重复过程。
41
一套可靠的正则测试语料应包含哪些内容?
42
变量 needle 只代表用户要查找的字面文本时,哪条命令更符合意图?
排错时沿解释链反向检查
一条命令“没有输出”至少有五种可能:
- shell 把未引用模式展开了。
- 使用了错误方言,例如把 ERE 裸括号交给默认 BRE。
- 模式只匹配子串,但你误以为锚点覆盖了整个选择分支。
- locale 改变了字符类、范围或忽略大小写。
- 工具匹配的是不同对象,例如
find -regex的整路径,不是 basename。
可以按下面的诊断表逐层缩小:
不要在原模式上同时改引号、方言和量词。先把输入缩成一条,再把模式缩成一个固定片段;确认成功后,一次恢复一个条件。这个顺序看起来慢,实际比随机增删反斜杠更快,因为每次变化都有可解释结果。
43
find -regex 没有结果,而 basename 明明符合规则,首先应检查什么?
44
面对一条没有输出的 grep 命令,哪些检查应优先进行?
一次完整的受控实操:从语料到清理证据
为了让这些规则落到可复现证据上,我们在一次性 Debian 容器中建立 /tmp/welearn-ch19,只在该目录生成文本、日志、特殊文件名和二进制样本。工具版本是 GNU grep 3.8、GNU sed 4.9、GNU findutils 4.9.0 与 mawk 1.3.4;可用 locale 是 C 和 C.utf8。
语料包含:
text
zip
gzip
ab
abb
abbb
abab
a+b
ERROR 2026-07-16 id=42
warn: 404
error: 503
café
中文
abc123
a1b2b我们不是为了展示“命令能跑”,而是逐个验证假设:
bash
#测试1:BRE 与 ERE 区间得到相同目标集合
grep -n 'ab\{2,\}' corpus.txt
grep -En 'ab{2,}' corpus.txt
#测试2:固定字符串不解释加号
grep -Fn 'a+b' corpus.txt
#测试3:整行结构、分组、选择与字符类
grep -En '^(warn|error):[[:space:]]+[[:digit:]]{3}$' corpus.txt
#测试4:BRE 分组与回引用
grep -n '^\(ab\)\1$' corpus.txt
#测试5:sed 地址加捕获替换
sed -n -E '/^ERROR/s/(id=)[[:digit:]]+/\1REDACTED/p' corpus.txt
#测试6:awk 的匹配和不匹配条件
awk '$0 ~ /^ERROR/ {print "match:", $0}
$0 !~ /[[:digit:]]/ && $0 ~ /café|中文/ {print "no-digit:", $0}'
关键真实输出为:
text
BRE ab\{2,\}: abb, abbb
ERE ab{2,}: abb, abbb
fixed a+b: a+b
BRE backref: abab
sed: ERROR 2026-07-16 id=REDACTED
awk: match: ERROR 2026-07-16 id=42
no-digit: café
no-digit: 中文
find: ./tree/archive/old.log
./tree/service/app.log二进制样本 head<NUL>needle 默认只报告二进制文件匹配;加 -a -n 后显示原始 NUL,说明强制文本输出为什么要谨慎。NUL 记录测试:
bash
printf 'red\0blue\0' | grep -z 'blue' | od -An -tx1得到 62 6c 75 65 00,也就是 blue 后紧跟 NUL。这个结果验证的是记录分隔,不是普通换行文本。
最后,容器内部删除 /tmp/welearn-ch19 并确认路径不存在,输出:
text
removed:/tmp/welearn-ch19容器用 --rm 运行,返回后按名称检查没有残留容器。清理不是装饰步骤:它证明测试作用域确实受控,后续复跑不会误用上一次的文件、locale 产物或目录状态。
45
这组隔离实操为什么同时准备正例、反例、UTF-8 字符、空行和 NUL?
46
完成匹配测试后删除受控目录并确认容器消失,可以防止后续复跑继承旧状态。
最后的判断顺序:先确定解释者,再写模式
遇到文本匹配任务,可以按下面的顺序做决定:
- 先确定输入对象:文件名、整条路径、一行、awk 字段,还是 sed pattern space。
- 再确定解释者:shell glob、
grep -F、BRE、ERE、PCRE,或工具自己的正则方言。 - 在命令行给模式加合适的引号,让 shell 只完成你授权的展开。
- 从固定核心开始,逐次加入锚点、字符类、重复、分组和选择;每次只增加一个约束。
- 明确 locale。自然语言字符类使用目标 UTF-8 locale,ASCII 协议显式固定
LC_ALL=C。 - 同时准备正例、反例、空值、长度边界和异常编码;记录工具版本、命令、输出与 0/1/2 状态。
- 跨工具复制模式前重新检查方言、匹配范围和捕获语法。
grep的一行、sed 的 pattern space、awk 的记录和find -regex的整路径不是同一个对象。 - 面对外部可控长输入,审查回引用、嵌套宽泛重复和大区间计数;设置资源上限,并优先采用固定字符串或结构化解析器。
正则表达式的价值不在于把规则压成最短的一行,而在于让文本结构可读、可测、可移植。只要每次都能回答“谁先解释、匹配什么、使用哪种方言、失败状态是什么”,那些看起来密集的符号就会变成一条可以逐层验证的判断链。
47
把一个 grep 模式复制到 find -regex 前,最先要重新确认什么?
48
一条可维护的正则规则应留下哪些证据?