OCR 与人工数据:把模型接成一套能交付的识别系统
走到课程最后,我们不再单独讨论某个算法,而是把前面学过的模型、数据、评估和工程方法装进同一套系统。OCR(Optical Character Recognition,光学字符识别)很适合承担这个角色:输入看起来只是一张图片,真正要交付的却可能是文字、坐标、阅读顺序、表格结构、字段值和置信度。
这也解释了为什么 OCR 演示往往很惊艳,真实项目却很容易卡住。模型在一张干净截图上读对几个字,只能证明识别器会工作;它还没有回答拍照歪斜怎么办、漏检怎样发现、表格如何恢复、低置信结果由谁复核、敏感票据保存多久。一个可用系统必须把这些问题一起回答。
这一章会沿着完整链路向前走:先定义输出,再拆分检测、矫正、识别与后处理;随后讨论 CTC、版面分析、数据采集、人工合成、分组切分和多层指标;最后用票据与街景案例完成课程收束。你会看到,模型只是流水线中的一个部件,数据协议和反馈闭环同样决定最终质量。
本章中的“人工数据”主要指程序生成的合成样本,以及从真实样本变换得到的数据增强样本。它不等于虚假数据,也不意味着可以跳过真实验证。合成数据适合补覆盖、控变量和降低标注成本;是否有效,最终仍要由独立的真实场景测试集决定。
先定义 OCR 到底要交付什么
“把图里的字读出来”不是一个足够明确的需求。手机扫描、仓库条码旁的序列号、街道路牌和财务票据都叫 OCR,但它们的输入分布、输出粒度与容错方式完全不同。项目开始时如果只写“准确率达到 95%”,团队很快会发现彼此说的不是同一件事。
从业务动作倒推输出合同
我们先问结果会被谁使用。若用户只想搜索一份扫描 PDF,按自然阅读顺序输出段落文本可能已经够用;若财务系统要自动报销,就还需要发票号码、金额、日期、币种等字段,并保留它们在页面上的位置;若要做街景导航,文字必须和空间位置绑定,单独输出字符串没有意义。
一个较完整的 OCR 结果可以写成下面这类结构:
json
{
"document_id": "receipt_20260715_0042",
"pages": [
{
"page_index": 0,
"orientation": 0,
"quality_flags": ["轻微反光"],
"regions": [
{
"polygon": [[81, 66], [526, 59], [530, 122], [84, 128]],
"text": "应付金额 ¥128.00",
"confidence": 0.93,
"reading_order": 7,
"role": "total_amount"
}
]
}
],
"review_required": false
}这里至少有六类信息:文档标识、页码与方向、区域几何、转写文本、结构角色、置信度与复核状态。它们分别服务追踪、重排、可视化、检索、业务入库和风险控制。OCR 输出因此更像一份带空间结构的预测记录,而不是一段复制出来的纯文本。
先写允许错什么,再选模型
不同字符的错误成本并不相同。海报正文中把“的”认成“地”可能只影响搜索;付款账号错一位却可能造成资金风险。可以在需求阶段建立错误成本表:哪些字段必须逐字符正确,哪些允许人工修订,哪些只用于召回候选,哪些失败时宁可拒识也不能猜。
拒识是正式输出,不是系统崩溃。当图像太糊、字段缺失或多个候选分数接近时,返回“需要复核”通常比输出一个看似确定的错误答案更可靠。后续阈值、人工队列和指标设计都要从这个输出合同出发。
1
财务团队要用 OCR 自动读取付款账号。项目启动时最先应补充哪项定义?
OCR 是检测、矫正、识别和结构恢复的流水线
一张原始图像到可用数据之间,通常要经过多个模块。不同系统会合并或替换其中某些步骤,但下面这条链路足以帮助我们定位问题:
- 输入质检:判断分辨率、模糊、反光、裁切缺失和文件损坏;
- 方向与几何矫正:处理整页旋转、文本行方向、透视和页面弯曲;
- 文本或版面检测:找到文字行、词、段落、表格、图片等区域;
- 区域裁剪与归一化:把检测多边形展开成识别器容易读取的图像;
- 文字识别:把字符图像或整条文本行转成字符序列;
- 语言与格式后处理:结合词典、字段规则和上下文修正候选;
- 版面与业务结构恢复:建立阅读顺序、表格单元格、键值对和字段类型;
- 置信路由:自动通过、重试、换模型或进入人工复核。
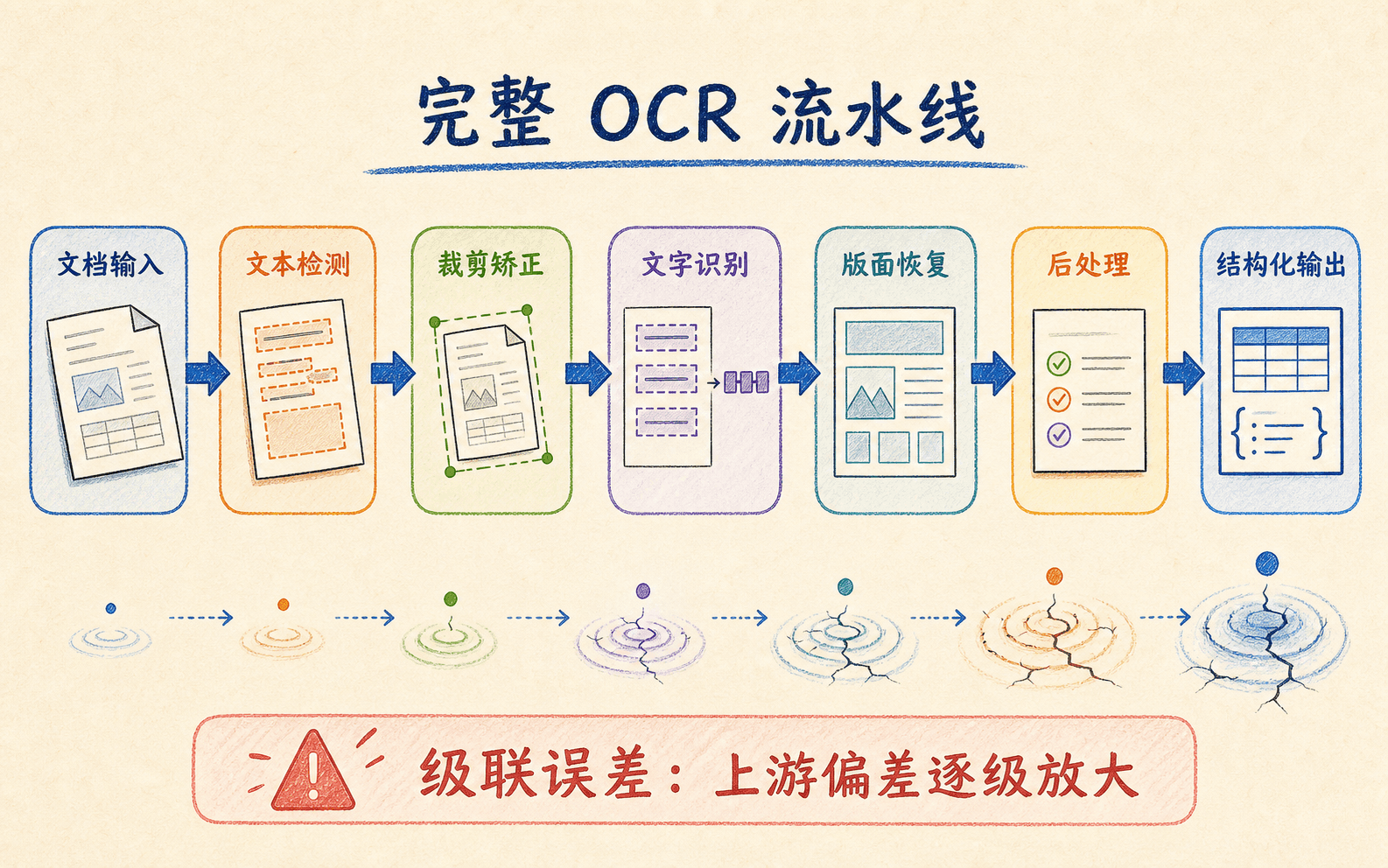 OCR 是级联系统:前一步遗漏或裁错的内容,后面的识别模型通常无法凭空补回。
OCR 是级联系统:前一步遗漏或裁错的内容,后面的识别模型通常无法凭空补回。
模块化不等于每一步都必须是独立模型
经典系统往往把字符切分、单字符分类和词典纠错分开。现代系统可以直接识别整行文字,也可以用联合模型同时检测和识别;视觉语言模型还可能直接输出结构化结果。模块边界发生了变化,但“输入在哪一步变坏、错误在哪一步产生”仍然需要可观测。
如果一个端到端模型只返回最终 JSON,就应额外记录中间证据,例如检测框、字符或 token 置信度、裁剪图、阅读顺序和拒识原因。否则字段错了以后,我们很难判断是页面没摆正、区域没找到、字符没读对,还是后处理把正确结果改坏。
上游误差会改变下游看到的数据
流水线不是把几个独立准确率相乘那么简单。检测框切掉一部分字符后,识别器面对的已不是训练时的完整文本行;透视矫正把笔画拉伸以后,字符分布也会改变。上游模块的输出就是下游模块的输入分布,因此模块评估除了使用完美标注裁剪,还要使用真实上游预测裁剪。
2
为了让 OCR 流水线可调试,下列哪些中间结果值得保存或抽样记录?
输入质检与几何矫正先决定问题难度
很多被归因于“识别模型不够强”的问题,实际来自输入。拍照票据可能旋转 90 度,纸张边缘形成梯形,折痕让文本行弯曲,顶灯又在金额处留下反光。若这些变化远超识别器训练分布,继续调分类头的收益通常很小。
质检要输出可行动的原因
输入质检可以检查长宽、有效分辨率、模糊、过曝、阴影、裁切完整度和文字占比。一个二元“好/坏”标签不够实用,最好给出原因和建议:
放大不会凭空恢复已经丢失的笔画。对无法恢复的信息,系统应拒识或请求新输入,而不是依靠锐化生成一个更像文字的图案。
整页方向、文本行方向和透视不是一回事
整页方向分类回答页面是 0、90、180 还是 270 度;文本行方向还要处理同页横排、竖排或倒置印刷;透视矫正则根据四边形或页面曲面,把斜拍区域映射回近似正视图。三类问题的标签与变换不同,不能用一个“旋转增强”笼统代替。
对扫描文档,二值化、去噪和倾斜校正可能有效;对彩色街景,过度二值化反而会抹掉浅色笔画。预处理必须用真实验证集做消融:固定识别器,逐项打开矫正,比较总体和困难切片,而不是默认步骤越多越好。
 输入校正的目标不是把页面“美化”,而是让后续检测与识别面对更稳定、可解释的几何和对比度。
输入校正的目标不是把页面“美化”,而是让后续检测与识别面对更稳定、可解释的几何和对比度。
3
只要把低分辨率文字图片放大四倍,模型就一定能恢复原本缺失的笔画信息。
从滑动窗口到现代文本检测器
滑动窗口是理解检测任务的好入口。我们在图像金字塔的不同尺度上移动窗口,把每个局部区域交给“有文字/无文字”分类器,再合并重叠响应。它把一个位置未知的问题,转换成许多位置已知的分类问题。
经典方法为什么有教学价值
设图像宽高为 ,窗口宽高为 ,水平和垂直步长都是 。单一尺度上大约要评估:
步长越小,位置覆盖越密,计算量也越大;加入多个尺度后,窗口数进一步增加。经典系统会用手工特征、级联分类器、全卷积共享计算和非极大值抑制减少开销。这个过程清楚展示了召回、精度与计算成本的权衡。
现代检测器直接预测区域
现代文本检测器通常让卷积网络或 Transformer 在整图特征上直接预测文本概率图、边界框、多边形、字符区域或文本之间的连接关系。EAST 一类方法直接回归有方向的词或文本行几何;CRAFT 通过字符区域与字符间连接处理弯曲或不规则文字;分割式检测器可以从像素概率图恢复任意形状区域。
这类方法不会真的把每个窗口独立送入分类器,因而能共享大量计算,也更容易同时覆盖位置和尺度。滑动窗口仍可用于受控的小目标扫描、候选验证或解释历史思路,但不应被描述成现代 OCR 唯一或默认的文本检测方案。
 经典方法依赖人工候选与规则,现代检测器直接学习文本区域;两者仍需用任务里的形状、速度和数据规模来取舍。
经典方法依赖人工候选与规则,现代检测器直接学习文本区域;两者仍需用任务里的形状、速度和数据规模来取舍。
检测标签粒度要和识别器匹配
检测可以标字符、词、文本行或段落。英文单词之间有明显空格,词级框较自然;中文街景常按文本行标注;弯曲招牌可能需要多边形。若识别器按整行读取,检测器却把每个字切成独立小框,后续还得重新分组,错误会转移到排序与合并环节。
重叠框合并也要谨慎。普通非极大值抑制可能把相邻两行文字误当成重复框;弯曲文字的矩形 IoU 又不能充分反映轮廓。阈值、几何表示和匹配协议应与具体标注规范一起确定。
4
关于滑动窗口与现代文本检测,下列哪项表述最准确?
字符分类与整行识别是两种建模粒度
检测到文字区域以后,系统还要把图像变成字符序列。经典做法先通过连通域、投影直方图或规则切出单字符,再对每个字符分类。它在固定表格、等宽数字和字符间隔清楚的场景中仍然实用,因为每一步都容易检查。
问题出在切分边界。连笔手写会让两个字粘在一起,破损印刷会把一个字拆成几块;中文偏旁也可能被误当成独立字符。只要切分错了,后面的分类器即使对完美单字有 99.9% 准确率,也无法还原缺失或多出的字符。
整行识别把切分变成隐变量
现代序列识别器通常输入一张归一化文本行图像,沿宽度方向提取特征序列,再直接输出不定长字符。常见结构包括卷积编码器加循环网络、卷积编码器加 CTC、注意力解码器,以及视觉 Transformer 加自回归解码器。它们不要求人工给出每个字符的精确边界。
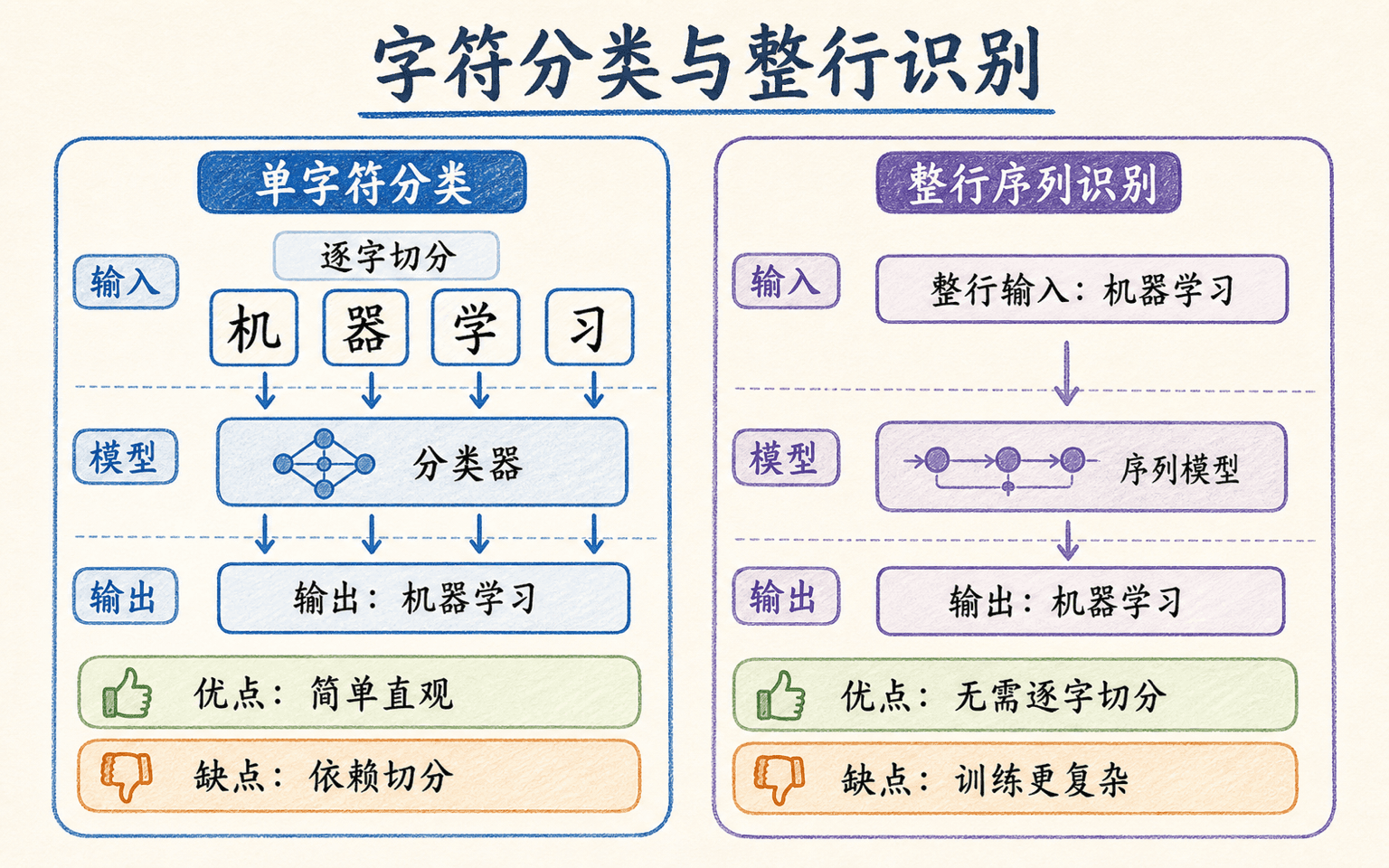 单字符方案依赖可靠切分,整行模型把切分与识别联合起来,但需要处理变长对齐和语言上下文。
单字符方案依赖可靠切分,整行模型把切分与识别联合起来,但需要处理变长对齐和语言上下文。
选择粒度时可以看四个条件:
- 字符是否天然分隔,例如表格里的单格数字;
- 输出长度是否固定,例如六位验证码或可变长地址;
- 字符集有多大,是否包含中文、生僻字和多语言混排;
- 业务是否需要字符坐标,还是只要整行文本。
归一化不能破坏字符形状
识别器常把文本行缩放到固定高度,宽度按比例变化,再用 padding 或动态 batch 对齐。若强行把所有文本压成同样宽度,长行会被横向挤扁,短行会被拉宽,字符形状随长度系统性改变。训练和推理应使用相同的 resize、padding 和字符集规则,并明确未知字符如何表示。
字符集不是越大越好。加入大量部署中不会出现的字符会增加混淆;字符集太小又会把合法字符变成未知。可以按语言、场景和字段类型路由不同识别器,也可以使用统一多语言模型,但必须在目标切片上验证成本与收益。
5
一批手写地址存在大量连笔和字符粘连,哪种方案更能直接减少切分错误传播?
CTC 在不知道字符边界时学习对齐
CTC(Connectionist Temporal Classification)的核心问题是:输入特征有 个时间步,目标只有 个字符,而且我们不知道每个字符对应哪些时间步。只要 ,CTC 就可以把所有能折叠成目标文本的对齐路径加起来,直接最大化目标序列概率。
blank 让长度不同的序列可以对齐
在原字符表 之外,CTC 增加一个 blank 符号 。模型在每个时间步输出 上的概率。路径 的条件概率常写为:
折叠函数 先合并连续重复标签,再删除 blank。例如路径:
text
票 票 ∅ 据 据 ∅折叠后是“票据”。目标文本 的概率是所有可折叠为 的路径概率之和:
训练损失取负对数:
前向—后向动态规划让我们不必枚举指数数量的路径。对于连续相同字符,例如“人人”,路径中要用 blank 把两次“人”分开,否则连续重复会被折叠成一个字符。
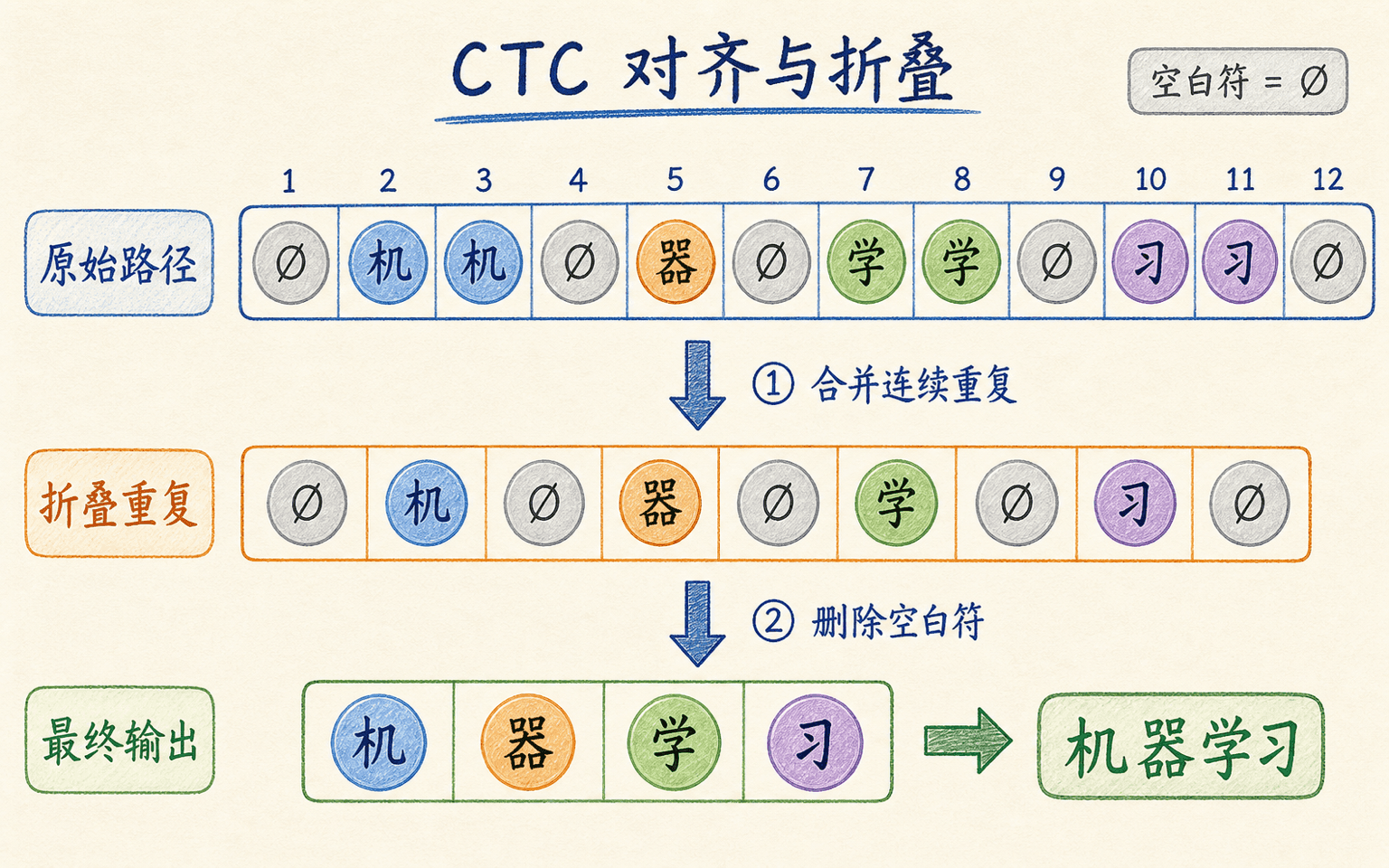 CTC 把所有能折叠成目标文本的合法路径概率相加,因此训练时不需要逐帧字符边界。
CTC 把所有能折叠成目标文本的合法路径概率相加,因此训练时不需要逐帧字符边界。
贪心解码和前缀束搜索回答不同问题
贪心解码在每个时间步取概率最大的符号,再执行折叠。它速度快,但“每一步最可能的路径”不保证对应“总概率最大的文本”,因为同一文本可以由许多路径共同贡献概率。
前缀束搜索保留若干高分前缀,累计不同对齐路径的概率,还可以加入语言模型、词典或字段规则。它通常更准,也会增加延迟。票据金额、产品编码等场景要谨慎使用通用词典:语言先验可能把一个视觉上罕见但合法的编号,改成常见单词。
可把解码分数写成视觉模型、语言模型和长度项的组合:
与 必须在独立验证集上调,不能用测试集挑选。对于结构强的字段,正则表达式、校验位或有限状态约束往往比通用语言模型更可控。
6
关于 CTC,下列哪些说法正确?
语言后处理与版面分析负责恢复“怎么读”
字符识别正确不等于文档可用。双栏论文若按横向坐标排序,会把左右栏交错;票据若只输出纯文本,就无法知道“128.00”是应付金额、税额还是折扣;表格若丢失行列关系,后续统计也无法使用。
后处理应保留视觉证据
后处理可以使用语言模型、领域词典、字段类型、日期与金额格式、校验位和跨字段一致性。例如合计金额应与明细求和近似一致,身份证号码有固定长度与校验规则。这些约束能重新排序候选,也能触发复核。
但规则不能静默覆盖原预测。建议同时保留 raw_text、normalized_text、改写原因与候选分数。这样既能审计,也能区分“识别器读错”和“规则改错”。对于人名、地址、产品码和多语言文本,词典外内容本来就常见,强制纠成词典内词会造成系统性偏差。
版面分析建立空间层级
版面模型通常要识别标题、段落、页眉、页脚、列表、表格、图片、印章和选择框,并推断阅读顺序与包含关系。输出可以组织成树或图:页面包含区域,表格包含行列和单元格,单元格再关联文字块。
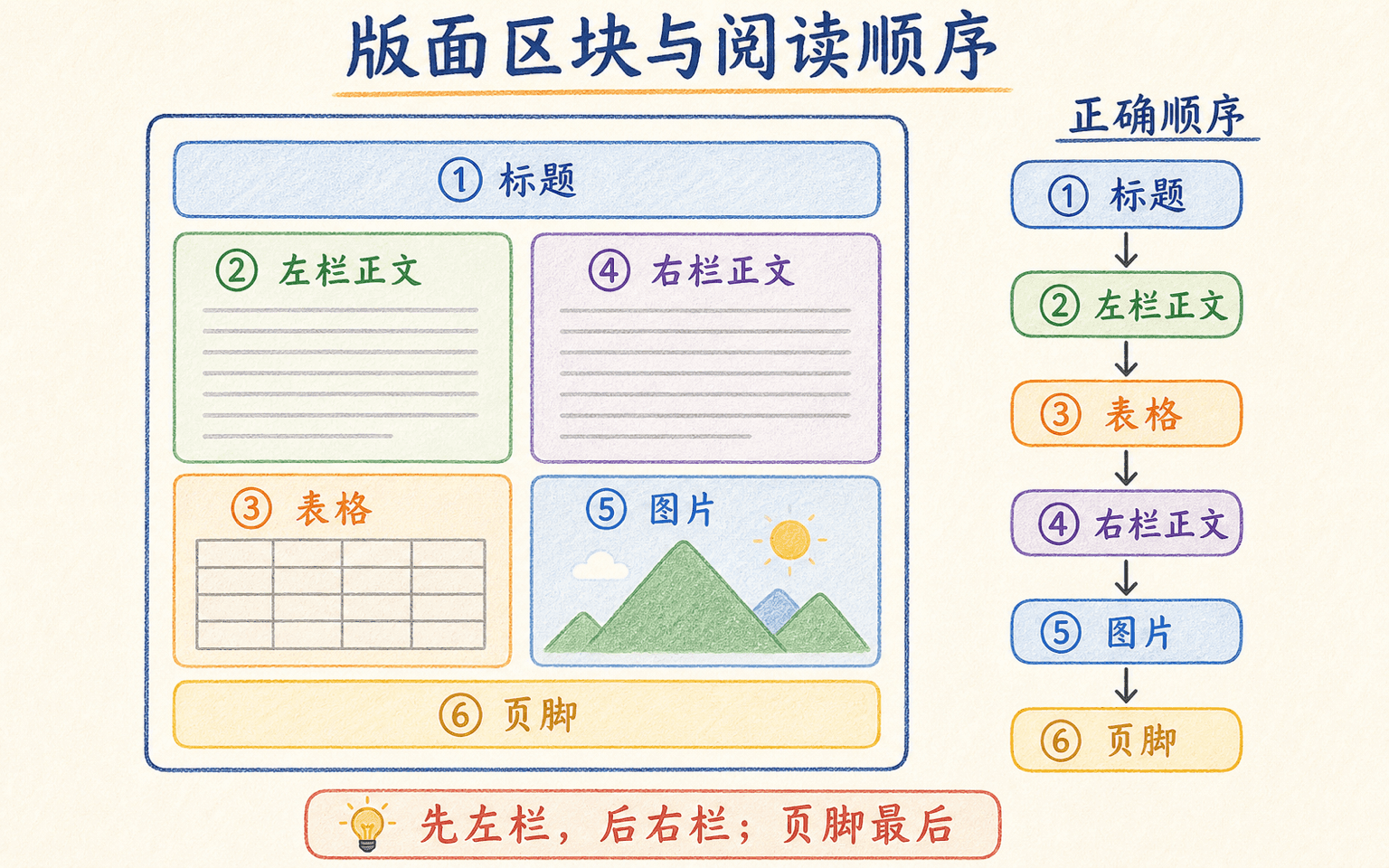 识别出每个字还不够:版面分析要恢复区块类型、层级和阅读顺序,才能得到可用的结构化文档。
识别出每个字还不够:版面分析要恢复区块类型、层级和阅读顺序,才能得到可用的结构化文档。
常见错误包括:
- 把跨页表格拆成无关的两张表;
- 把页眉页脚插进正文中间;
- 合并距离近但语义无关的两栏;
- 漏掉跨行单元格,造成列错位;
- 文本都识别正确,却给出错误阅读顺序。
因此版面评估不能只算字符误差。还要检查区域类型、阅读顺序、表格结构和字段关系。最终任务若是问答或报销,最好再测一次下游任务成功率。
7
CTC 识别器输出的原始文本建议保存在字段 ____ 中,而规则或语言模型改写后的结果另存,以便审计。
数据采集和标注协议先于大规模标注
OCR 数据不只是“图片 + 字符串”。检测需要多边形,识别需要规范化转写,版面任务需要区域类型与关系,业务抽取还要字段标签。若协议没有先写清,同一张图会被不同标注员用不同粒度处理,模型学到的是标注差异。
采样要覆盖部署条件和失败条件
先列出部署维度,再分层采样。票据可以按商户模板、打印设备、拍摄手机、光照、折痕、语言、金额格式和时间分布;街景可以按城市、天气、昼夜、文字尺寸、招牌材质、视角、遮挡与脚本类型。常见场景保证总体性能,长尾与高风险场景单独保留足够样本。
公开数据集适合做基线,却不能自动代表自己的业务。NIST 手写数据库提供按书写者采集的表单与字符,适合研究手写识别;场景文字数据集则更贴近自然背景。使用任何外部数据都要核对许可、字符集、采集方式和标签定义。
把“怎么算对”写成可执行规范
一份标注协议至少应回答:
字符规范化尤其容易埋雷。训练标签把全角数字转成半角,而测试答案保留全角,会产生不属于模型视觉能力的差异;金额中千位分隔符是否保留,也必须前后一致。
质量控制要能发现分歧
先标一小批试运行样本,计算区域 IoU、转写一致率和字段一致率。高风险或困难样本由两人独立标注,再仲裁分歧;普通样本可以抽检。每次协议变更都要版本化,并说明旧标签如何迁移。
不要只抽查容易样本。可以按标注员、数据来源、置信度、字符长度和图像质量分层抽检。模型上线后的高损失样本与人工退回样本,也应回流到标注审计,而不是直接加入训练集。
8
一份可执行的 OCR 标注协议通常应明确哪些内容?
人工合成与数据增强要补覆盖,不要制造新偏差
OCR 很适合人工生成数据,因为文字内容、字体和几何位置都可以程序控制,标签几乎同步产生。经典场景文字工作会把渲染文字贴到自然背景上,并考虑局部表面方向、颜色、边框和阴影;整词识别也曾用大规模合成词图训练模型。
这不等于“可以生成无限数据,所以数据问题解决了”。模型会学习合成器的规律。若背景永远干净、字体只有常用印刷体、透视只向一个方向、模糊核和真实相机不同,那么数量再多也只是重复错误分布。
合成器是一套可采样的数据模型
可以把合成过程拆成五层:
- 文本层:从真实业务语料、格式模板和字符频率中采样;
- 字形层:选择覆盖授权、语言和字重的字体,模拟印刷缺损或手写差异;
- 布局层:决定字符间距、行距、对齐、曲线、表格和字段位置;
- 场景层:选择纸张、招牌、自然背景、阴影、遮挡与材质;
- 成像层:模拟透视、镜头畸变、运动模糊、压缩、噪声、曝光和分辨率。
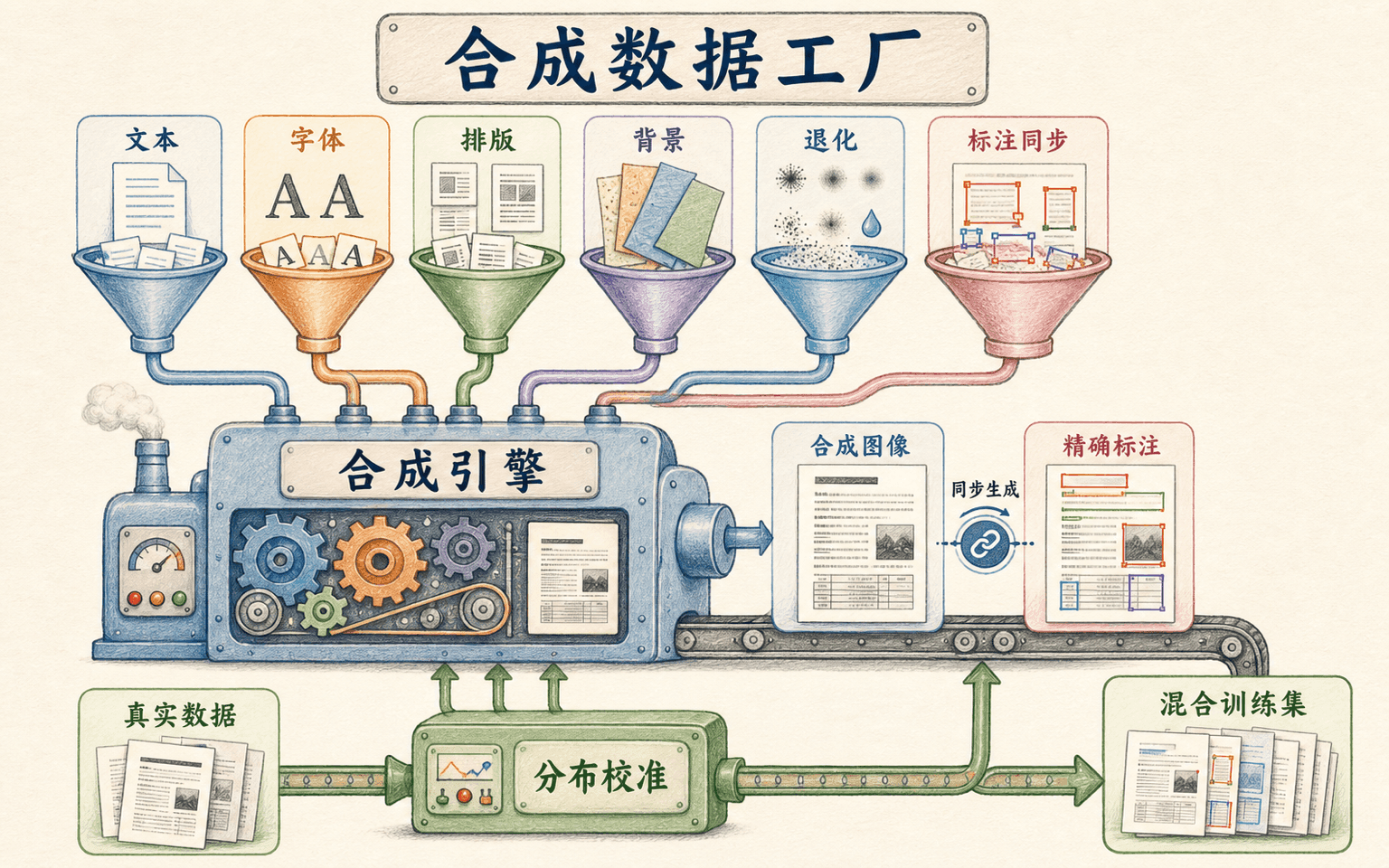 合成数据把内容、外观、退化与标签同步生成;真实数据仍要负责校准合成器没有覆盖的分布差异。
合成数据把内容、外观、退化与标签同步生成;真实数据仍要负责校准合成器没有覆盖的分布差异。
每个随机参数都应来自真实数据统计或明确假设。比如部署照片中文字高度主要在 12–60 像素,合成器却大量产生 200 像素大字,训练吞吐虽高,对真实小字帮助有限。
数据增强不能改变标签语义
增强是在真实样本上做近似保持标签的变换。轻度亮度变化、压缩、模糊、透视和遮挡常用于拍照 OCR,但强度要符合部署范围。对数字 6 旋转 180 度可能变成 9,水平翻转文字也不再保留原标签;随意裁剪会把字符截断,却仍沿用完整转写。这些都属于标签破坏。
增强最好在训练时在线采样,并保存随机种子或策略版本以便复现。验证集和测试集通常保持真实原貌;若要评估某种退化,应建立独立压力测试切片,而不是随机改写正式测试集。
用真实验证集测量域差距
一个实用实验矩阵是:仅真实训练、仅合成训练、合成预训练后真实微调、真实与合成混合训练。四组都在同一份按来源隔离的真实验证集上比较,并按字体、尺寸、光照和设备切片。
如果合成训练损失很低,真实验证 CER 却高,说明域差距没有被数量填平。此时应检查合成器覆盖、降低合成占比、加入少量真实标注微调,或学习更贴近真实的退化过程。合成数据越多并不自动越好,分布接近和信息增量才是关键。
9
只要合成 OCR 样本的标签自动生成且完全正确,持续增加同一种合成样本就一定会改善真实场景效果。
按文档来源切分数据,先堵住泄漏
OCR 样本之间往往高度相关。同一张原图可以裁出几十个文本行,同一商户模板可以产生上万张票据,同一作者可以写出许多字符。如果随机把这些小样本分到训练和测试,测试集就会出现训练数据的近亲,指标会虚高。
分组键应追溯到共同来源
切分顺序应是:先确定不可跨集合的分组键,再分训练、验证和测试,最后只对训练组做裁剪、合成和增强。常见分组键包括:
- 文档 OCR:原始文档、模板、扫描批次或供应商;
- 手写识别:书写者;
- 街景文字:拍摄序列、同一地点、同一视频或同一招牌;
- 票据识别:商户、门店、模板版本、设备和时间窗口;
- 合成数据:背景原图、字体集合或生成种子族。
若先增强再随机切分,一张原图的轻微旋转版可能进训练,压缩版进测试。模型几乎见过相同像素,测试不再代表新输入。
测试集回答“上线后会遇到什么”
随机分组测试衡量同一总体中的新文档;时间外推测试衡量未来月份;新模板测试衡量未见商户或版式;跨设备测试衡量新相机。可以同时保留多套测试,但要分别命名,不能把它们混成一个数字。
验证集用于选模型、阈值、增强强度和解码参数。测试集应在决策冻结后使用;反复查看测试错误并据此修改系统,等价于把测试集变成验证集。发布前还可保留一个访问受限的最终验收集。
10
同一张票据裁出 30 个文本行,并为每行生成多个模糊版本。最安全的切分方式是什么?
检测、识别、端到端和业务指标要分层报告
OCR 没有一个能概括全部质量的“准确率”。检测器可能框得准却读不对,识别器在完美裁剪上很强却受真实漏检拖累,最终字段还可能被版面排序或规则改坏。分层指标能告诉我们损失发生在哪里。
检测看区域匹配与阈值权衡
预测多边形和标注多边形通常先按 IoU 或特定比赛协议匹配,再计算精确率与召回率:
高置信阈值会减少误检,也可能漏掉小字;低阈值提高召回,却把纹理当成文字。除单点 外,还应查看 PR 曲线、不同 IoU 阈值和文字尺寸切片。不可辨认区域要按协议标为 ignore,不能临时决定是否计分。
识别看编辑距离,不只看整行全对
设替换、删除、插入字符数分别为 ,参考文本字符数为 ,字符错误率为:
将字符换成词,就得到 WER。整行准确率要求一行所有字符都正确,对长文本很严格;CER 能区分“只错一个字”和“整行读乱”。中文分词不稳定时,CER 往往比 WER 更易解释,但规范化规则必须固定。
端到端要同时满足位置与文字
文本 spotting 的一个预测只有在区域匹配、转写也满足协议时才算正确。这样可以暴露“识别器在标注裁剪上很好,真实检测框却让它失败”的差距。文档任务还需评估阅读顺序、表格结构、键值关系或字段级完全正确率。
最终还要看业务指标,例如自动通过率、人工修改字符数、高风险字段误放行率、平均复核时长和每千页成本。自动通过率不能脱离质量:阈值调得很低可以让更多文档自动通过,也会把错误送进业务系统。
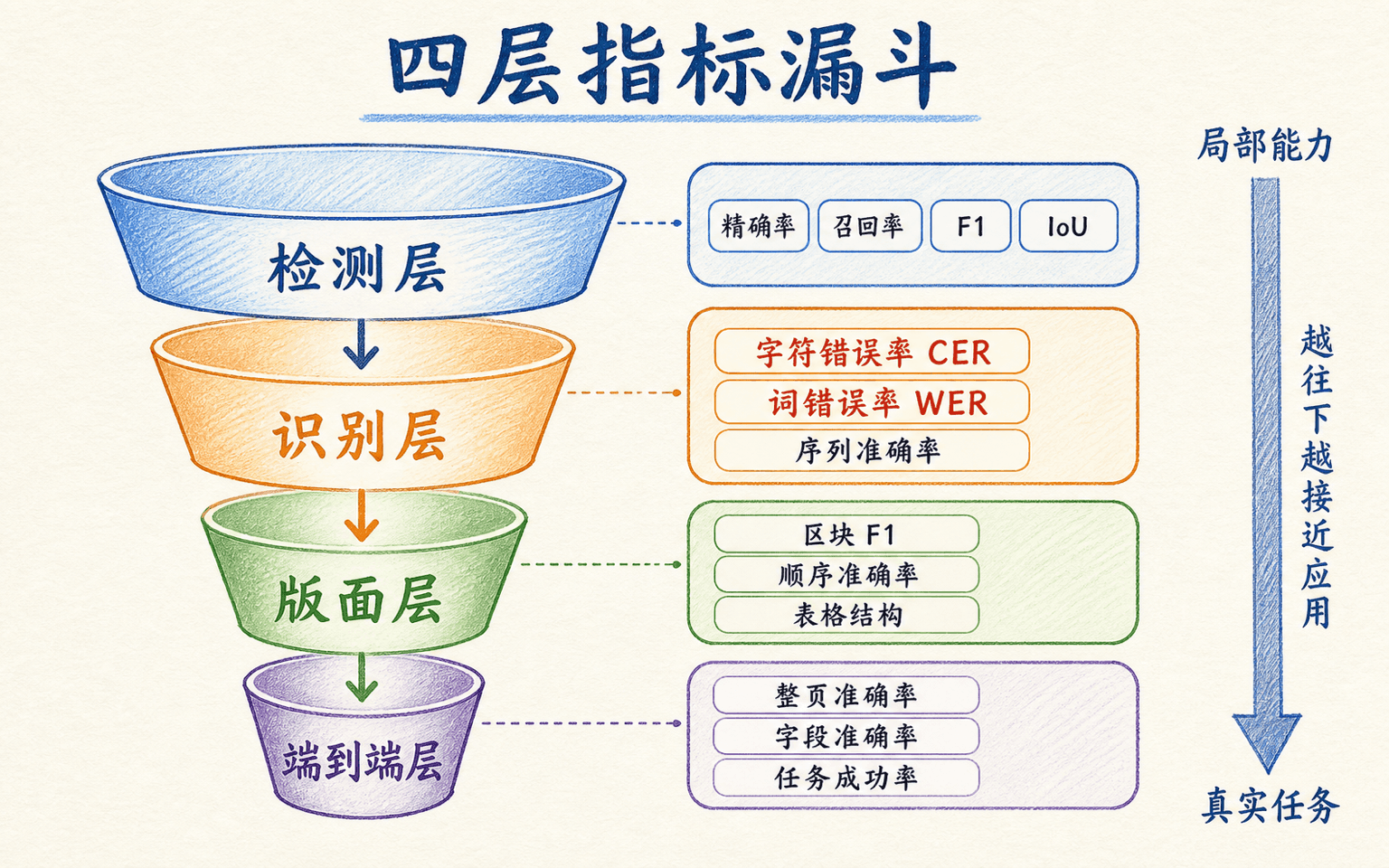 分层指标负责定位问题,端到端指标负责判断系统是否真的可用;两类证据不能互相替代。
分层指标负责定位问题,端到端指标负责判断系统是否真的可用;两类证据不能互相替代。
11
评估一套票据 OCR 系统时,哪些指标应分层保留?
误差分析与天花板实验决定下一笔投入
当端到端指标不够好时,最差的做法是凭感觉把所有模型都换大。先从真实失败样本中抽取一批,建立互斥或可统计的错误标签:输入不可读、方向错误、检测漏框、框不完整、行序错误、字符替换、语言后处理误改、字段映射错等。
错误桶要同时看数量和成本
假设 500 个失败字段中,字符识别占 210 个,检测漏框占 120 个,字段映射占 90 个,其他占 80 个。不能只按数量排序:若 90 个字段映射错误都发生在付款账号,它们的业务成本可能最高。
可以为每个桶记录:样本数、业务损失、主要切片、复现条件、置信度分布和可行动方案。每轮修改只选择一到两个假设做实验,避免多个模块一起变化后无法归因。
用 oracle 输入测模块上限
天花板实验把某个模块暂时替换成真值,观察端到端指标最多能提升多少。例如:
这个实验表明,方向模块即使做到完美也只有 0.5 个百分点空间;检测与识别更值得优先投入。它不是说方向永远不重要,而是针对当前数据和指标给出上限。
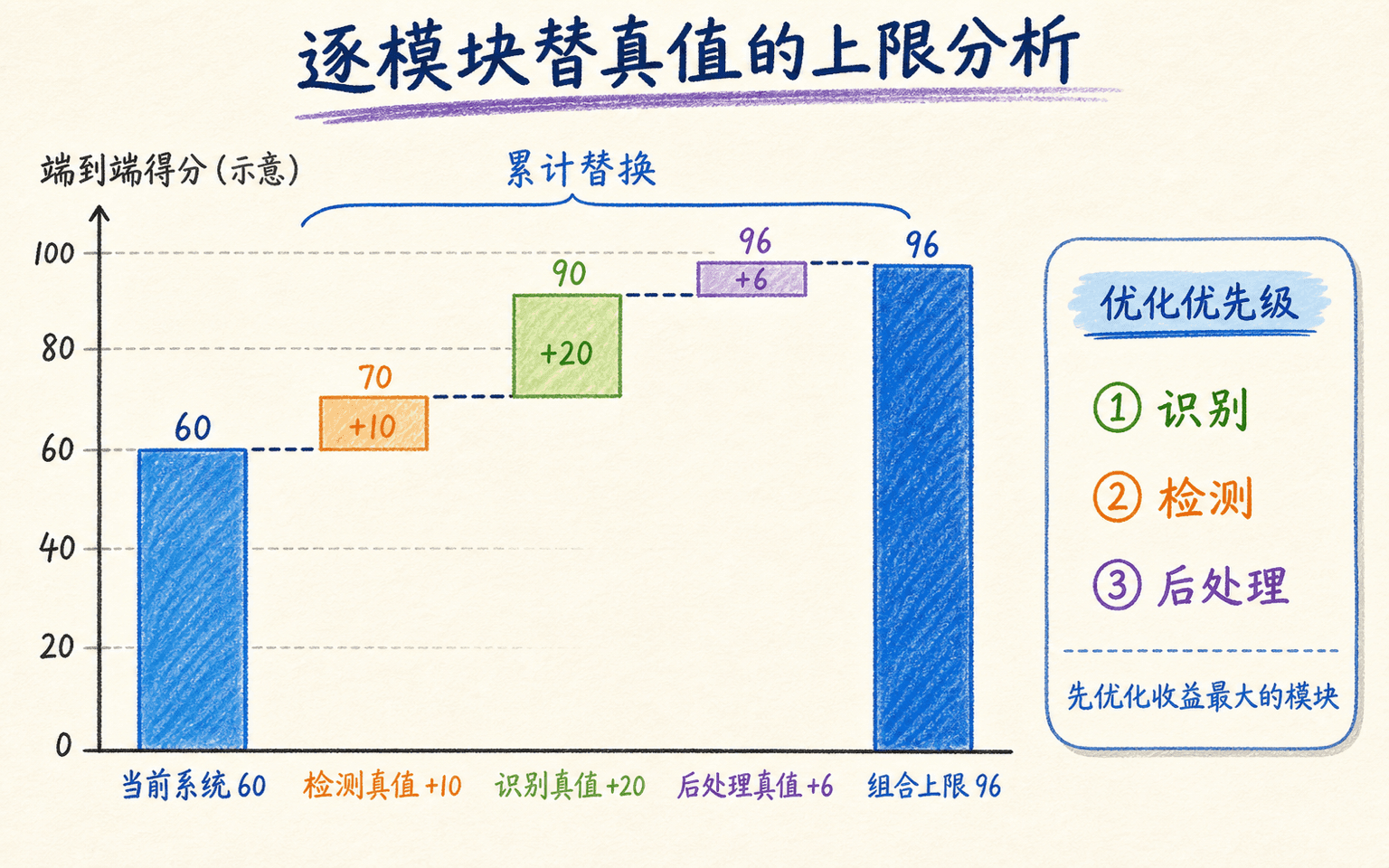 上限分析比较“如果这个模块完美,端到端还能提升多少”,用真实收益为优化工作排序。
上限分析比较“如果这个模块完美,端到端还能提升多少”,用真实收益为优化工作排序。
模块单测和真实串联测试要同时做
识别器在真值裁剪上的 CER 测它自身能力;识别器在预测裁剪上的 CER 测它对检测误差的鲁棒性。两者差距大时,可以改进检测,也可以用带边界抖动的裁剪训练识别器。类似地,字段抽取既要在真值文本上测,也要在真实 OCR 文本上测。
每轮迭代要重新检查关键切片,防止总体提升掩盖高风险群体退化。若新后处理降低平均 CER,却把大量罕见人名纠成常见名字,它并不是可接受改进。
12
把当前检测框替换成真值框后,端到端准确率只从 92.0% 升到 92.3%。这最直接说明什么?
上线还要回答延迟、吞吐、隐私与人工复核
离线准确率通过后,OCR 才进入系统工程阶段。手机取景框要求几百毫秒内返回提示,夜间批量归档可以等待数小时;两者可能使用不同分辨率、批量大小、模型和重试策略。
延迟和吞吐要按真实负载测
至少报告 P50、P95、P99 端到端延迟,以及每秒页数或文本行数。平均延迟会掩盖长尾。测量应包括图片解码、上传下载、方向矫正、检测、识别、后处理和队列等待,不只统计 GPU 推理时间。
批处理通常提高吞吐,却增加等待和显存占用;动态 batch 可以在时间窗口内合并请求。长文档还要限制并发页数,防止一个大 PDF 阻塞其他任务。模型量化、蒸馏和输入缩放都可能提速,但需重新检查小字、罕见字符和置信度校准。
置信度用于路由,不是天然概率
检测分数、字符分数和字段一致性可以组合成风险分数,但神经网络 softmax 的 0.95 不一定意味着 95% 样本正确。可在验证集上做可靠性图、温度缩放或分桶校准,并针对高风险字段设置单独阈值。
人工复核界面应展示原图局部、模型候选、低置信字符和规则冲突,支持快速确认与修改。随机抽样一部分高置信结果也很重要,否则系统只会收到低置信反馈,难以发现“高置信地错”。
隐私从采集到反馈都要限制
票据、证件和医疗文档可能包含姓名、账号、地址与健康信息。系统应明确传输和存储加密、区域与租户隔离、最小权限、日志脱敏、原图留存期限、删除机制和第三方处理边界。用于训练的人工修订数据要重新经过授权与脱敏,不能把复核界面的敏感内容默认汇入训练库。
部署监控除延迟和错误率外,还要观察输入分布、拒识率、人工修改率、字段缺失率和分切片质量。标签延迟存在时,先监控可即时获得的代理信号,等复核真值到达后再计算正式指标。
13
关于生产 OCR 的置信路由和人工复核,下列哪些做法合理?
用票据和街景案例走完端到端闭环
下面不再孤立介绍模块,而是从需求、数据、模型、指标和上线策略各走一遍。两个案例共享 OCR 基础,却会做出不同设计。
票据案例:目标是字段可靠入库
一家企业要处理手机拍摄的小票与发票,输出商户、日期、总额、税额、币种和明细表。高风险是总额与日期错误,要求低置信结果进入人工复核,并保留字段来源区域供审计。
先确定字段 schema、允许格式与错误成本。总额必须同时返回原始文本、标准化数值、页面多边形和置信度;无法确定币种时不允许默认为人民币。
数据按商户与模板版本分组,并按时间留出未来模板测试集。标注页面边界、文本行、转写、表格单元格和目标字段,协议统一全半角、千位分隔符与负数写法。
流水线先做页面质检与透视矫正,再检测文本行并识别。版面模块恢复明细表,字段模块结合空间邻近、关键词和格式约束产生候选,但保留视觉原始结果。
合成器重点补罕见币种、不同金额格式和低频字体,增强模拟折痕、阴影与压缩。所有方案都在真实新商户验证集上比较,并保留只用真实数据的基线。
票据中语言规则很强,但不能让规则掩盖视觉错误。例如明细求和与总额相差一分钱可能来自四舍五入,也可能是漏行;系统应记录冲突并给出证据,而不是擅自把总额改成计算值。
街景案例:目标是找到并读出开放词汇文本
街景系统要识别招牌与路牌,文本可能倾斜、弯曲、被树枝遮挡,也会混合中文、数字和英文。输出是多边形、转写、脚本类型和地理关联;允许普通广告牌偶发漏检,但交通指示牌属于高优先级切片。
数据按拍摄轨迹和地点分组,避免同一招牌的连续帧跨训练与测试。测试按昼夜、天气、文字高度、倾角、遮挡和脚本类型切片。
检测器预测旋转或任意形状多边形,文本行裁剪经几何展开后进入多语言整行识别器。未知脚本或极低清晰度结果允许拒识。
解码器对普通自然语言使用轻量语言先验,对门牌号、路线编号和店名降低词典约束,避免把开放词汇强行改成熟词。
端到端评估要求位置与转写同时正确,同时单独报告小字召回、交通牌召回、混合脚本 CER 和单张图 P95 延迟。
两个案例使用相似的检测与识别技术,却不会共享同一套阈值、后处理和指标。票据强调字段一致性与审计,街景强调开放词汇、多形状检测和空间召回。系统设计应服从输出合同,而不是反过来让业务迁就某个模型。
14
为什么票据 OCR 和街景 OCR 不应直接共用同一套解码约束与通过阈值?
把整门课收束成一张机器学习系统地图
OCR 案例看似属于计算机视觉,实际把整门课的关键方法都调动起来了。我们可以沿着一条“问题—数据—模型—评估—部署”的链路回看它们。
前面学过的算法怎样进入同一系统
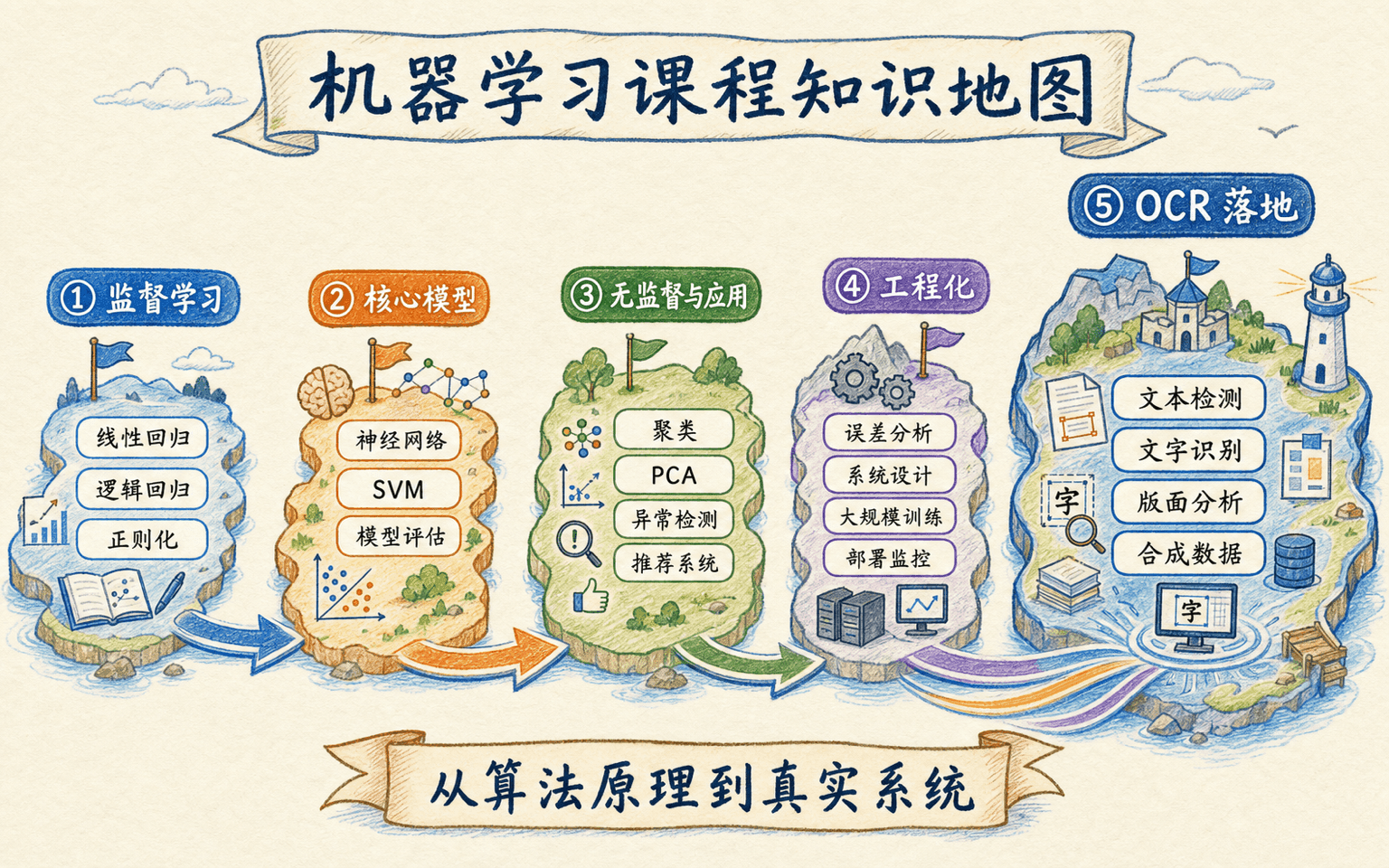 18 个章节不是孤立算法清单,而是一条从问题定义、模型学习、系统评估到真实场景落地的完整路线。
18 个章节不是孤立算法清单,而是一条从问题定义、模型学习、系统评估到真实场景落地的完整路线。
算法名称不是地图中心。中心是可验证的决策循环:定义目标,建立基线,切分数据,测量误差,提出假设,做受控实验,再把通过的变化安全上线。OCR 中换检测器、加合成数据或调解码权重,都应进入这套循环。
可以继续学习的几条路线
如果你想继续做视觉与 OCR,可以学习卷积网络、Vision Transformer、目标检测、实例分割、序列建模和多模态文档理解,并亲手复现一个小型文本检测—识别系统。
如果你更关心数据,可以深入主动学习、弱监督、合成数据评估、数据版本和标注质量控制。一个很好的练习是:固定模型,只改采样和标注协议,量化真实测试集上的收益。
如果你关心生产系统,可以继续学习模型服务、可观测性、校准、漂移检测、隐私安全、灰度发布和人工反馈闭环。目标不是做出一次性 demo,而是让模型在输入变化、服务故障和业务规则更新时仍可追踪、可回滚。
如果你准备读论文,建议每篇都问五个问题:它解决的输入分布是什么,标签从哪里来,和什么基线比较,测试是否真正隔离,提升能否覆盖额外计算与数据成本。这样读新架构时,就不会只记住模型名字。
用一个小项目完成自己的收束
选一个边界清楚的任务,例如识别快递单号、读取书脊标题或提取课程表。先用现成 OCR 建基线,再收集 100–500 个有来源标识的真实样本;按来源切分,定义两层以上指标,做一次错误桶分析,只针对最大瓶颈改一项。最后写清延迟、失败返回和复核方式。
做到这里,你得到的不只是一个 OCR 结果。你已经完成一次小型机器学习系统开发:把问题变成可测目标,把数据变成受控实验,把模型变成可运营服务。这套工作方法可以迁移到图像、文本、推荐、异常检测和更多现实任务中。
15
完成一个小型 OCR 收束项目时,哪些步骤最能体现本课程的方法?