支持向量机:从最大间隔到可靠的核分类流程
有些分类数据只需要一条直线就能分开,但“能分开”还不够。假设两类样本之间有一条宽阔的空带,我们可以把决策边界画在空带中央,也可以紧贴其中一类。两条线在训练集上的准确率同为 100%,遇到轻微测量误差时,后者却更容易翻转预测。
支持向量机(Support Vector Machine,SVM)从这件事出发:寻找决策边界时,同时考虑分类错误和边界两侧的安全距离。线性不可分时,它允许少量样本进入间隔或落到错误一侧;边界需要弯曲时,它通过核函数在隐式特征空间里学习线性超平面。这样一来,最大间隔、正则化、凸优化、核方法和工程调参就连成了同一条线。
不过,SVM 也很容易被几句口号讲歪。“间隔越大一定越好”忽略了噪声与表示方式,“核就是随便找个相似度”忽略了正半定条件,“支持向量少所以总是省内存”也不符合大量样本贴近边界时的现实。本章会从几何定义推到可运行的 scikit-learn 流程,并把这些边界条件讲清楚。
本章主要讨论二分类的 C-SVM,标签写成 。多分类、类别不平衡和概率校准会在后半部分单独处理。SVM 的原生输出是决策分数,不应默认解释为概率。
从“分对”走到“留出余量”
线性分类器先计算一个实数分数:
再根据符号给出类别:
满足 的点构成决策超平面。在二维里它是一条直线,在三维里是一个平面,更高维时仍称为超平面。向量 垂直于超平面, 决定它沿法向方向平移到哪里。
若训练数据线性可分,通常不止一个超平面能把两类完全分开。SVM 会比较这些候选边界离最近训练样本有多远,并选择最小距离最大的那个。离边界最近的样本像撑住一条走廊的支点,后来被称为支持向量。
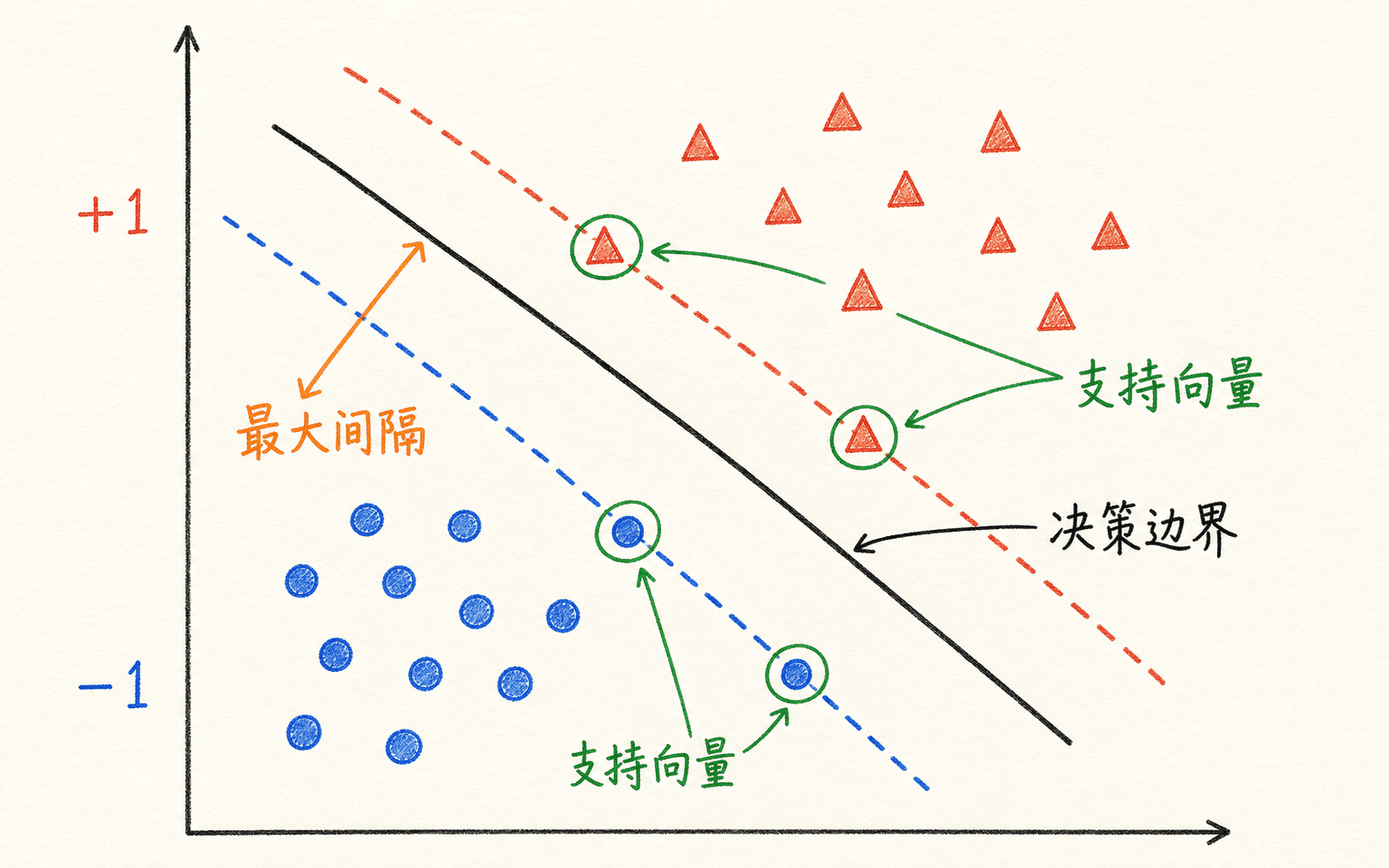
SVM 不只要求分对,还希望离最近样本留出尽可能大的几何余量。
这个直觉有一个明确的适用范围:它描述的是给定特征表示、给定训练样本与给定损失权衡下的间隔。训练集上的空带更宽,常常意味着对小扰动更稳定,但不自动保证测试误差更低。一个被错误标注的孤立点,就可能迫使硬间隔边界旋转并压缩整条空带。真实 SVM 因此通常使用软间隔,让“边界平滑”和“训练违规”共同进入目标函数。
还要区分“离边界远”和“概率更高”。 的绝对值能表示样本在当前分数尺度上离边界多远,却没有天然的概率单位。把 同时乘以 10,分类边界和预测符号都不变,原始分数却放大了 10 倍。下一节会用两种间隔把这个问题拆开。
1
两条直线都能把训练样本完全分开。最大间隔分类器优先选择哪一条?
函数间隔与几何间隔不是同一个量
对样本 ,函数间隔定义为:
若 ,分类符号正确;若它小于 0,样本被分错。数值越大,样本在当前参数尺度上的分数越靠正确一侧。整个训练集的函数间隔取最小值:
问题在于,函数间隔不是几何距离。将 和 同时乘以正数 ,超平面 完全不变,函数间隔却乘以 。因此,直接“最大化函数间隔”没有意义:只要不停放大参数,就能让目标无限增大。
几何间隔把这个缩放除掉:
它是带符号的垂直距离。正确一侧为正,错误一侧为负,而且对 的同比例缩放保持不变。训练集几何间隔仍取最小值:
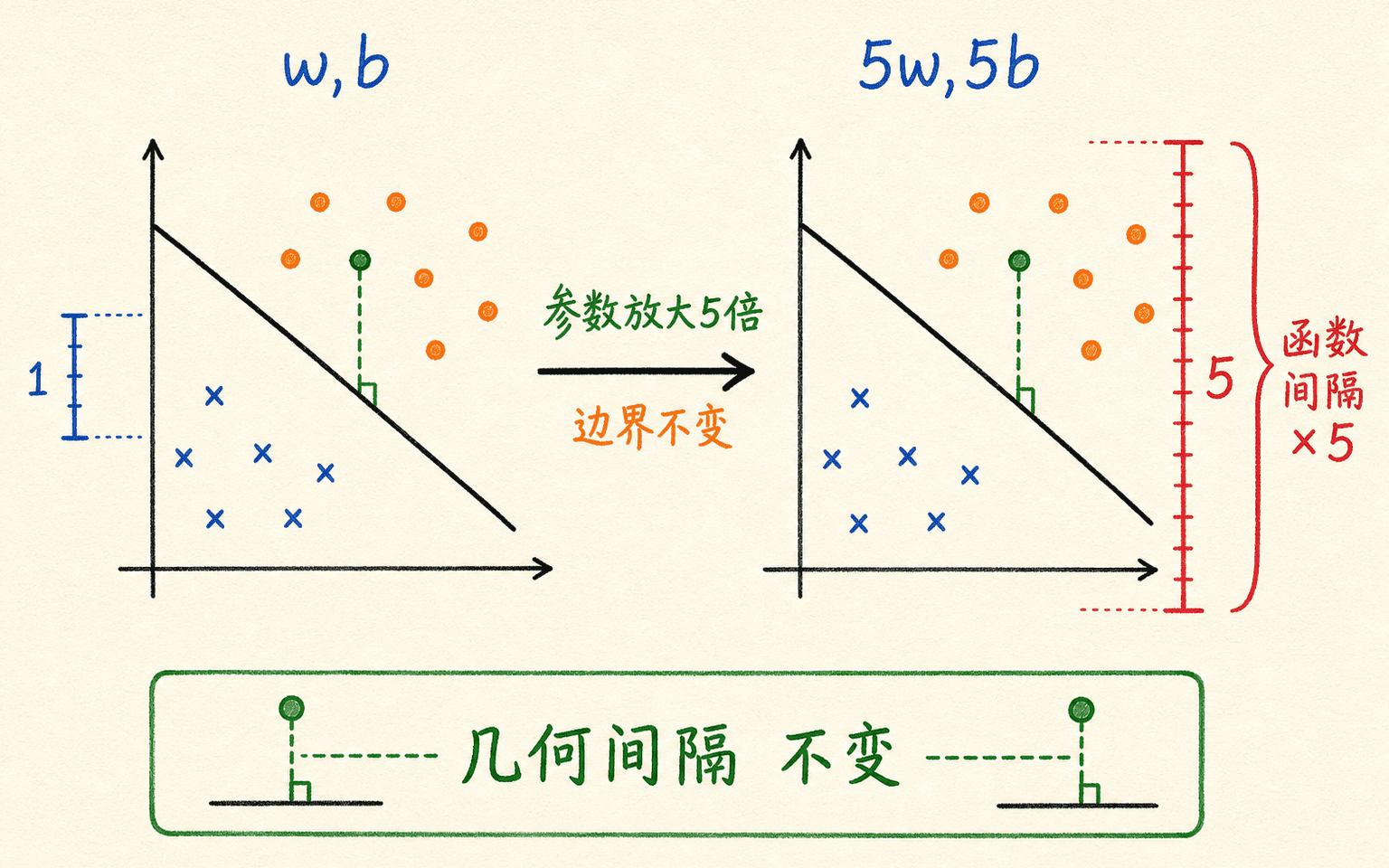
函数间隔依赖参数尺度,几何间隔才对应样本到边界的真实距离。
你可以把 看成指向正类一侧的单位法向量。一个样本沿这个方向投影到超平面,走过的长度就是几何间隔的绝对值。这样一来,“最大间隔”就不再是一句视觉描述,而是最大化训练集中最小的带符号垂直距离。
后面常把函数间隔规范成 1,即要求最靠近边界的正确样本满足 。这只是在利用参数可缩放性选定统一刻度,不是声称现实距离等于 1。规范化以后,单侧几何间隔是 ,两条间隔边界之间的总宽度是 。
2
把 w 和 b 同时乘以正数 5 时,决策超平面不变;函数间隔乘以 5,而几何间隔 ____。
硬间隔把几何目标写成凸优化
先考虑理想情况:两类样本完全线性可分,而且我们愿意要求每个训练样本都在正确的间隔边界之外。利用上一节的缩放自由度,把最小函数间隔固定为 1,可得到硬间隔 SVM:
为什么最小化范数等于最大化间隔?规范化后,两条间隔边界分别是:
它们到中央决策面 的距离都是 。因此,最大化间隔带宽 ,等价于最小化 。写成平方并乘以 不改变最优解,却让求导更整齐。
这个问题的目标函数是凸二次函数,约束是仿射不等式,所以不存在“换个随机初值就掉进另一个更差局部极小值”的问题。只要可行解存在,标准凸优化方法就能寻找全局最优解。
硬间隔的限制也很直接:
- 只要一个样本无法被当前特征线性分开,约束集合就可能为空;
- 一个远离本类的错误标签能显著扭转边界;
- 即使训练数据可分,追求零违规也未必适合有测量误差的目标分布;
- 换一种特征尺度或特征表示,几何距离本身就会改变。
硬间隔不是“SVM 的完整定义”,而是理解最大间隔几何的起点。工程库中的常用分类器通常求软间隔问题;把 设得极大也不等于得到数值上稳定、泛化上更好的硬间隔解。
3
在线性可分训练集上,硬间隔 SVM 通过最小化参数范数来最大化两条间隔边界之间的几何宽度。
软间隔用松弛变量给现实数据留出口
现实数据经常重叠、含噪或带错标。软间隔为每个样本加入松弛变量 :
记录样本违反间隔约束的程度:
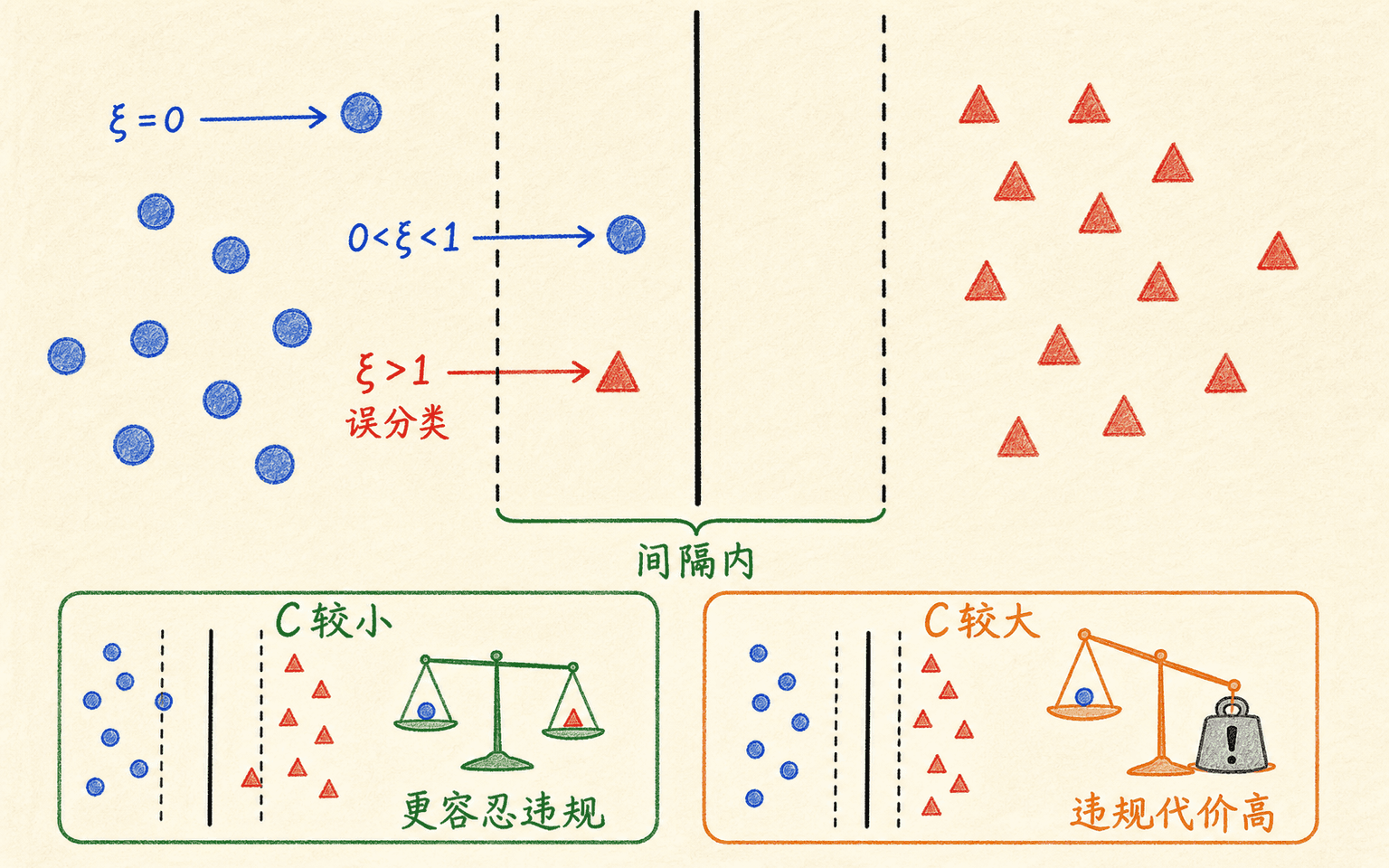
C 控制违反间隔的代价,不是一个孤立的“模型复杂度”按钮。
参数 决定单位违规要付出多大代价。 增大时,优化器通常更不愿意容忍间隔违规,可能用更复杂、更窄的边界去照顾困难样本; 减小时,范数惩罚相对更强,边界通常更平滑,也允许更多样本进入间隔。这里应使用“通常”而不是“一定”:最终结果还受数据、核参数、类别权重和目标函数具体实现影响。
把约束消掉,可以看到熟悉的 hinge loss:
hinge loss 不只惩罚分错的样本,也惩罚“虽然分对但离边界不足 1”的样本。已经在正确间隔外的点损失为 0;继续把它推得更远不会降低经验损失。
别脱离缩放约定比较 C
教材和软件可能使用不同的目标缩放。例如另一种常见写法是:
对本节这两条精确写法,把第一条目标整体乘以 ,可得 。若另一个实现使用平均损失、平方 hinge、正则化截距或不同样本权重,换算就会变化。因此,不要看到两个项目都写着 ,就认定正则化强度相同;先核对目标函数和样本数缩放。
4
某样本满足 y·f(x)=-0.3。按 hinge loss=max(0,1-y·f(x)),它的损失是多少?
支持向量由 KKT 条件解释得更准确
“离边界最近的点是支持向量”适合建立第一层直觉,但到了软间隔,支持向量还包括落在间隔带内和分错的样本。更准确的说法来自对偶系数 与 KKT 互补条件。
软间隔 C-SVM 的每个样本都有:
若加入类别权重或样本权重,上界会变成该样本对应的 。常见位置关系可以概括为:
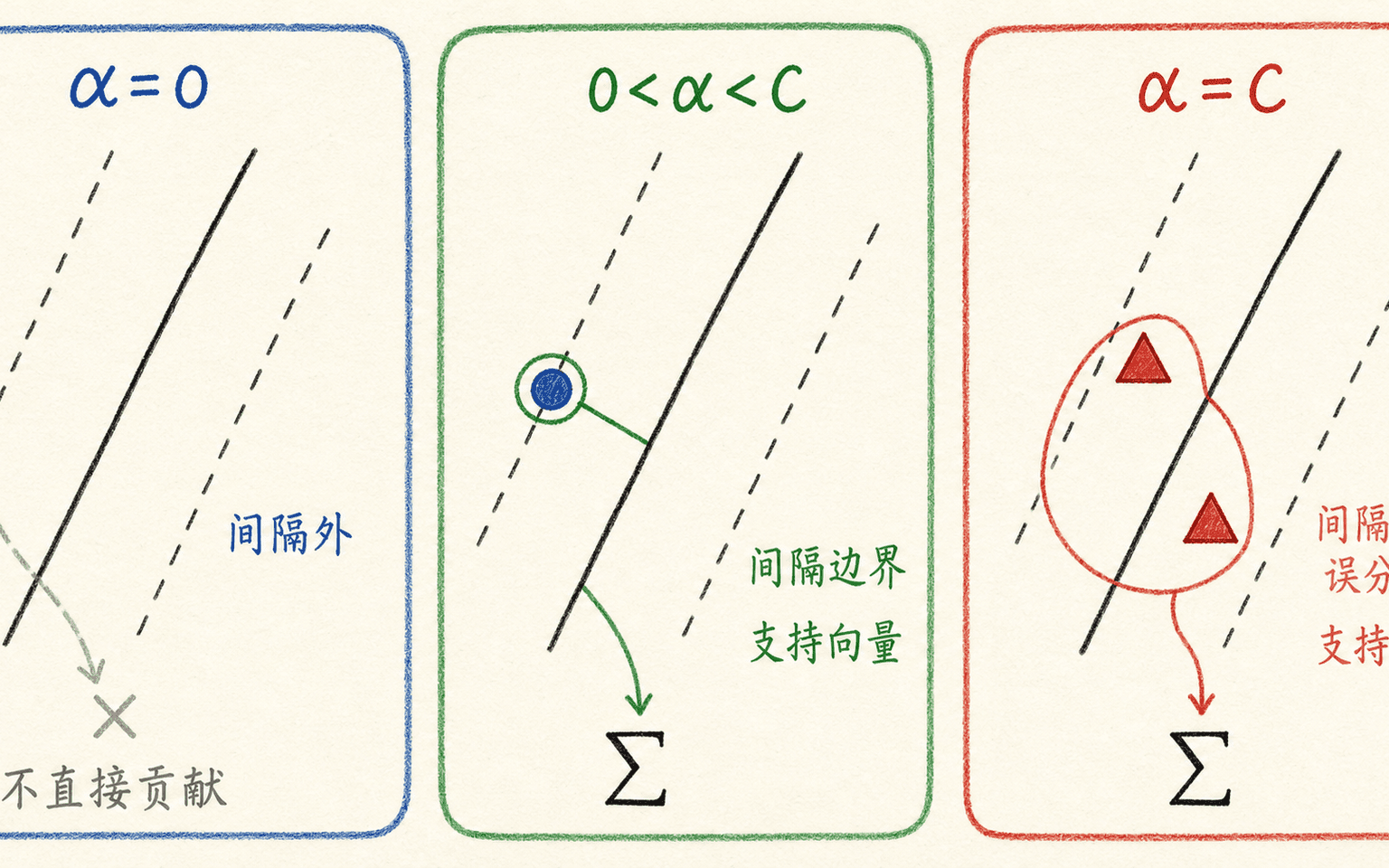
支持向量由约束是否活跃来定义,不只是肉眼看起来离边界很近。
核心互补关系可以直观写成:
当 时,对应间隔约束处于活跃状态,样本会进入最终决策函数;当一个样本安全地待在间隔外时,它的约束不活跃,通常有 。这就是“多数远处样本不直接决定边界”的数学原因。
但不要把“非支持向量不重要”理解成可以在训练前随意删除它们。是否成为支持向量,是在给定全部训练数据、核和超参数后求解出来的结果。删除样本可能改变最优边界,原来远处的点也可能变成新的边界支点。
支持向量比例还是很有用的诊断信号。若绝大多数训练样本都成为支持向量,可能表示类别严重重叠、 与 让边界过于局部、标签噪声较多,或者当前特征根本无法形成清楚间隔。它不是单独的好坏指标,但能解释为什么核 SVM 的模型体积和预测延迟没有想象中小。
5
关于软间隔 SVM 的支持向量,哪些说法正确?
对偶问题把样本内积变成模型核心
在线性硬间隔情形,对原问题建立拉格朗日函数并消去 、,会得到只含样本系数的对偶问题。软间隔只是在系数上增加上界,常用最大化形式为:
在线性情形,。求得 后:
预测分数也能写成:
只有 的支持向量需要参与求和。更关键的是,训练和预测都只通过样本对的内积接触特征。若先做特征映射 ,我们需要的是:
只要能直接高效计算 ,就不必显式构造可能极高维甚至无限维的 。这就是核技巧。
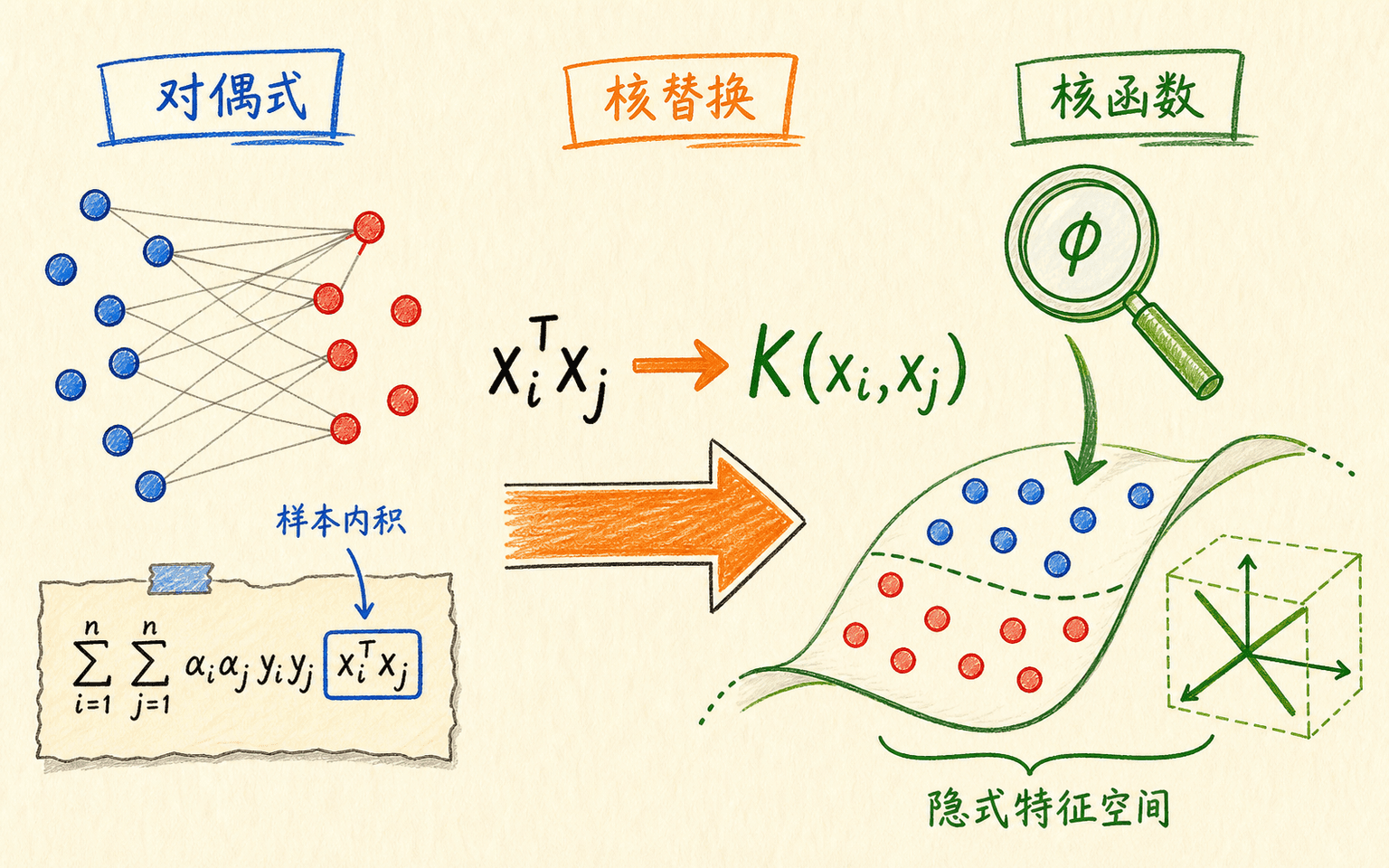
核技巧让模型直接计算特征空间内积,而不必显式展开全部新特征。
核不等于任意相似度
“核可以理解成相似度”只是一层直觉,不是充分条件。对任意有限样本集,核矩阵
应当对称且正半定,即对任意向量 满足:
这样它才能对应某个特征空间里的内积,并保持标准 SVM 对偶问题的凸性。一个函数即使在语义上“看起来越像值越大”,也可能不满足这个条件。设计自定义核时,最好从已知有效核出发,通过非负加权和、乘积或明确的特征映射构造,而不是把任意业务相似度直接塞进求解器。
对偶形式也带来代价:训练要反复访问样本两两之间的核值。样本数为 时,完整核矩阵有 个元素。即使实现采用缓存和分块,不显式永久保存整张矩阵,时间与内存压力仍会随样本数快速增加。
6
只要一个函数能表示业务上的相似程度,就一定可以直接作为标准 SVM 的有效核函数。
线性、多项式与 RBF 核表达不同的先验
核函数不是给模型换一个外壳,而是在规定“哪些输入关系可以被线性超平面利用”。常用的三种核各有清楚的结构。
线性核
线性核没有引入非线性映射,得到的还是原特征空间中的线性边界。它适合高维稀疏文本、词袋特征,以及样本很多而非线性核成本过高的任务。若线性模型已经达到合理效果,它也应当成为核实验的基线。
多项式核
次数 控制交互阶数, 调整内积尺度,(软件中常叫 coef0)影响高阶项与低阶项的相对作用。多项式核适合你确实预期有限阶特征交互的情形,但参数彼此耦合,次数升高后数值范围和过拟合风险都可能快速增加。
RBF 核
RBF 核按欧氏距离衰减。每个支持向量都像在周围放置一个局部影响区域,模型把这些局部响应加权组合成弯曲边界。它能表达很灵活的非线性关系,通常是中小规模表格数据的合理候选,却不是无条件的最佳选择。
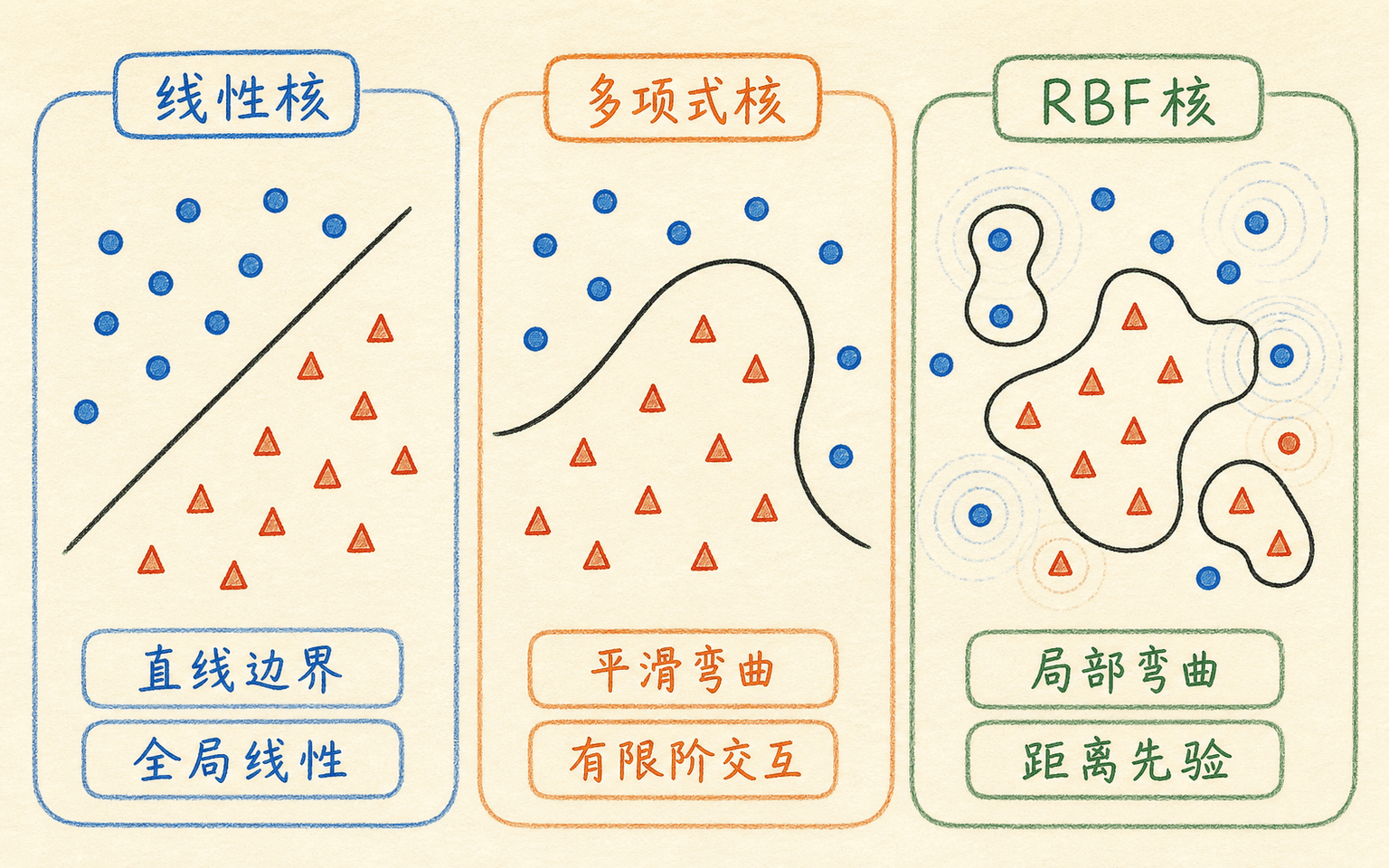
不同核函数表达的是不同相似性假设,并不存在脱离数据的万能选择。
若使用 sigmoid 核,还要更谨慎:
它并非在所有参数取值下都满足有效核条件。多数入门项目没有必要先从它开始。自定义字符串核、图核等也应先确认数学性质、计算成本和数据泄漏边界。
选择核时,我建议先问三个问题:
- 线性基线是否已经足够?
- 当前样本数是否允许核方法进行交叉验证?
- 距离或交互的含义是否与预处理后的特征空间一致?
如果第三个问题说不清,直接上 RBF 往往只是在用超参数搜索替代问题定义。
7
一个具有十万维稀疏词袋特征、样本量很大的文本分类任务,最合适的首个 SVM 基线通常是什么?
gamma 的意义离不开特征尺度
在 RBF 核里, 决定相似度随距离衰减多快。令两点距离满足:
此时:
因此, 可以看成一个直观的影响半径尺度。
- 很小:影响范围很宽,许多样本彼此看起来相似,边界更平缓,过小时可能欠拟合;
- 很大:影响范围很窄,模型可以围着局部样本急转弯,过大时可能记住噪声;
- 与 会相互作用,不能只调一个就解释全部复杂度。
在 scikit-learn 的 SVC 中,gamma="scale" 会从当前拟合数据计算 ,gamma="auto" 则使用 。前者是考虑数据总体方差的起点,不是自动选出的最优值;若缩放器位于 Pipeline 中,这个默认值也会在每个训练折的缩放结果上计算。
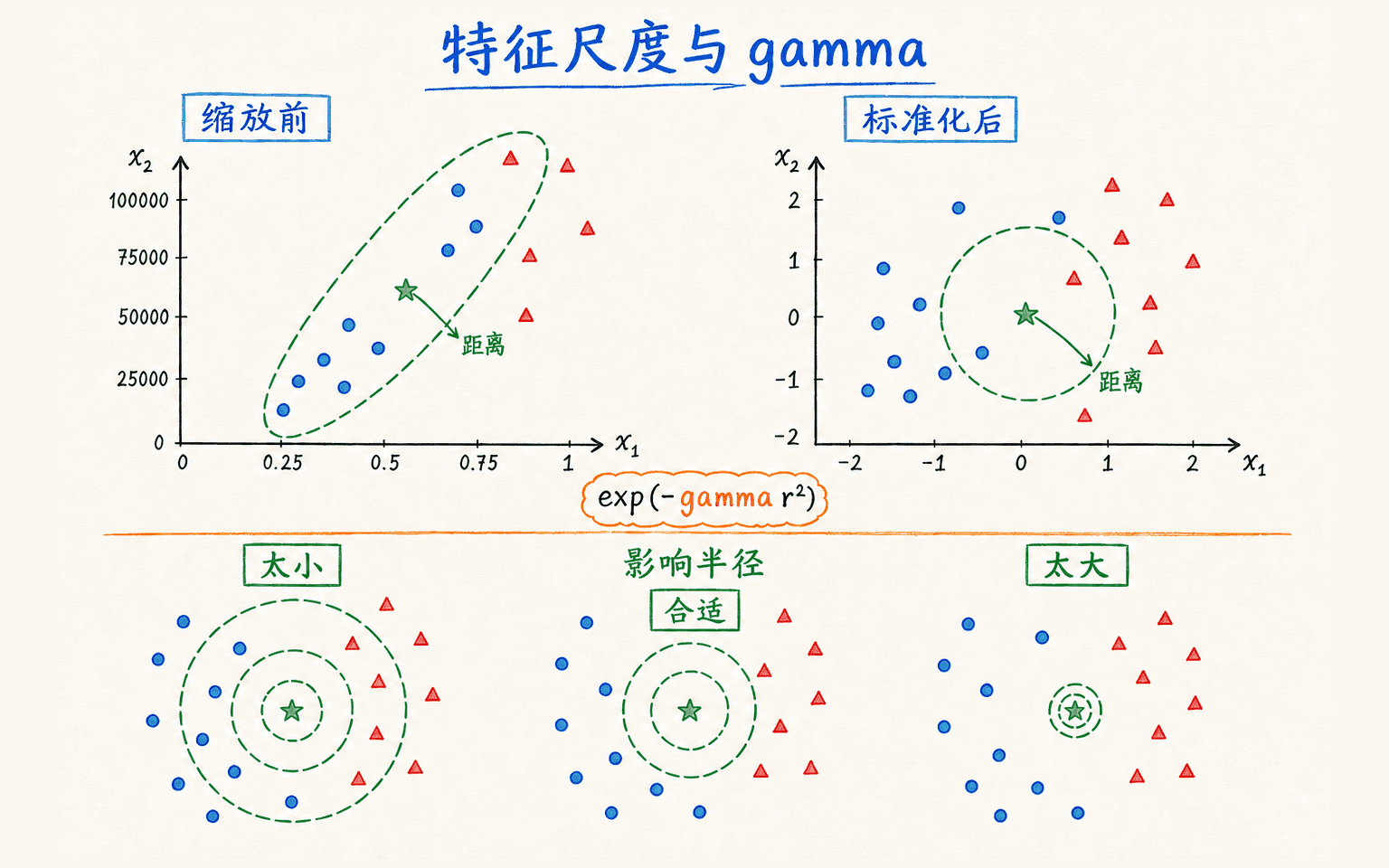
gamma 只有在特征尺度明确时才有稳定含义;它控制单个样本影响衰减的快慢。
假设一个特征是 0 到 1 的比例,另一个特征是 0 到 100000 的金额。未经缩放时,两点欧氏距离几乎完全由金额决定,RBF 核便会把“金额接近”误当成整体相似。线性 SVM 也不是尺度不变的:L2 正则化对每个系数使用同一惩罚,特征单位改变后,实现同一预测所需的系数大小也会改变。
常见做法是让连续特征在训练折内标准化:
但不要先对完整数据求 、 再交叉验证。那会把验证折的分布信息带进训练折。缩放器应放进 Pipeline,让每个折只用自己的训练部分拟合统计量。
稀疏矩阵还有一个工程细节:直接减去均值会把大量零变成非零,导致矩阵稠密化。高维稀疏特征可以使用 StandardScaler(with_mean=False)、MaxAbsScaler,或者根据特征含义保持原稀疏编码。数值列、类别列和文本列混合时,应通过 ColumnTransformer 分别预处理。
8
关于 RBF SVM 的 gamma 与特征缩放,哪些做法合理?
参数搜索必须连同预处理放进交叉验证
SVM 调参最常见的失误,不是网格不够大,而是验证协议不完整。一个可靠流程应先保留最终测试集,再在训练部分内部完成缩放、核选择和超参数搜索。
下面的参数空间把线性核与 RBF 核分开。这样不会为线性核浪费无意义的 组合:
python
from sklearn.model_selection import GridSearchCV, StratifiedKFold
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
from sklearn.svm import SVC
pipe = Pipeline([
("scale", StandardScaler()),
("svc", SVC()),
])
param_grid = [
{
"svc__kernel": ["linear"],
"svc__C": [0.01,
参数通常按指数尺度探索,因为 和 的有效范围可能跨越多个数量级。第一轮用较粗网格找出高分区域,再围绕稳定区域缩小搜索范围,比一开始在小数点后做密集扫描更有效。
交叉验证规则要匹配数据生成过程
StratifiedKFold 只保持类别比例,不会自动阻止同一用户、患者或设备跨折,也不会尊重时间顺序。若同一实体有多条记录,应使用分组切分;预测未来时,应使用时间切分或滚动验证。切分器必须反映部署时“哪些信息在预测当刻可见”。
评分函数也应对应任务。类别稀有时,只用准确率可能选择出几乎不识别正类的模型。可根据目标比较 PR-AUC、ROC-AUC、F1、带召回约束的精确率,或自定义成本;同时保留关键切片和训练时间作为护栏。
如果你在同一份交叉验证结果上试了大量特征、核和参数,再把最佳平均分当成最终泛化成绩,仍会乐观。可使用独立测试集做一次冻结验收;样本较少又需要更稳健估计时,可以使用嵌套交叉验证:内层选参数,外层估计整个选择流程。
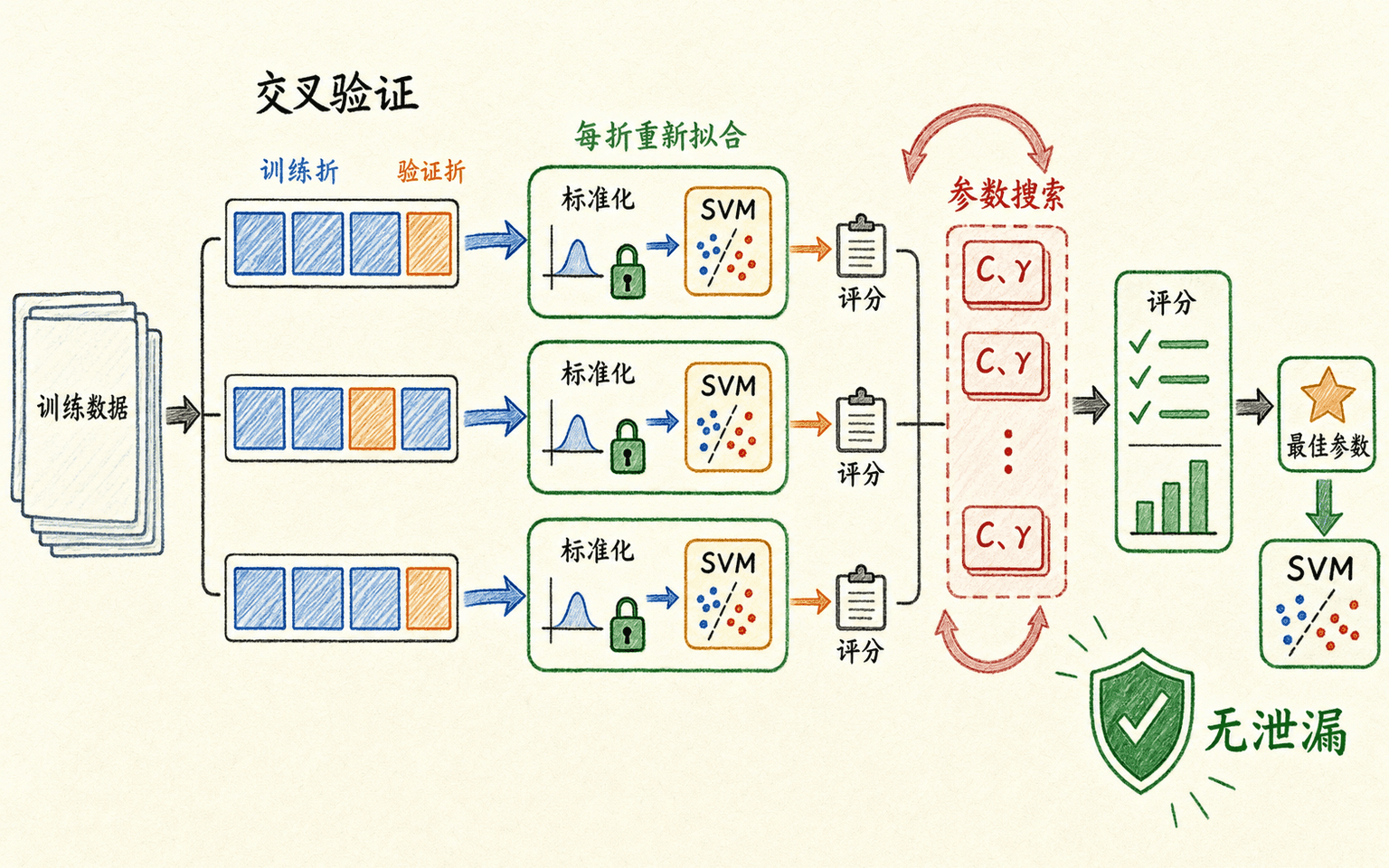
预处理必须在每个训练折内部拟合,参数搜索才不会偷看验证数据。
9
为什么应把 StandardScaler 和 SVC 一起放进 Pipeline 后再做 GridSearchCV?
多分类、决策分数与概率要分开理解
标准 SVM 的推导是二分类。面对 个类别,软件通常组合多个二分类器:
- 一对多(OvR):训练 个分类器,每次把一个类别当正类、其余类别合并为负类;
- 一对一(OvO):训练 个分类器,每个只比较两个类别,再通过投票或分数汇总。
scikit-learn 的核 SVC 内部使用 OvO 训练。decision_function_shape="ovr" 只把返回接口转换成每类一个分数,并不把内部训练改成 OvR。LinearSVC 默认使用 OvR。类别很多时,这个区别会直接影响模型数量、训练成本和分数解释。
决策分数不是后验概率
二分类 decision_function 返回带符号的决策分数。符号决定边界哪一侧,绝对值反映当前模型尺度下离边界的程度。它不满足“0.8 就表示 80% 发生概率”,不同模型或不同折的数值也不一定可直接比较。
若业务确实需要概率,可在独立校准数据或 out-of-fold 分数上拟合校准器。常见方法包括:
- sigmoid 校准,用单调的逻辑函数映射 SVM 分数;
- isotonic 校准,形状更灵活,但小样本时更容易过拟合。
校准数据不能与底层 SVM 的拟合数据重合,否则训练分数过于乐观,校准器会学出过度自信的映射。CalibratedClassifierCV 可以用交叉验证产生较少偏差的校准分数。某些库也提供内置概率开关,但会增加训练成本,而且分类结果与概率最大类别在边界附近可能不完全一致;需要读清实现说明。
概率校准也有边界:它主要修正分数到概率的映射,不能凭空改善类别排序。数据正类率、时间分布或人群构成变化后,旧校准可能失效。需要概率做风险沟通或成本决策时,应在目标分布和关键切片上检查可靠性图、Brier loss 或 log loss,而不是只看准确率。
10
核 SVC 把 decision_function_shape 设置为 ovr 后,内部训练策略就从一对一变成了一对多。
类别不平衡需要同时处理损失、指标与阈值
假设欺诈样本只占 1%。不加任何权重时,大量负类会主导总损失;但简单把正类权重调得很高,也可能产生不可承受的假告警。SVM 中的类别权重,本质上是为不同类别使用不同的违规代价:
若正类权重更高,正类样本违反间隔时付出的代价更大,边界通常会向减少正类漏判的方向移动。class_weight="balanced" 可按训练数据中的类别频率反向设置权重,是合理候选,不是自动最优答案。
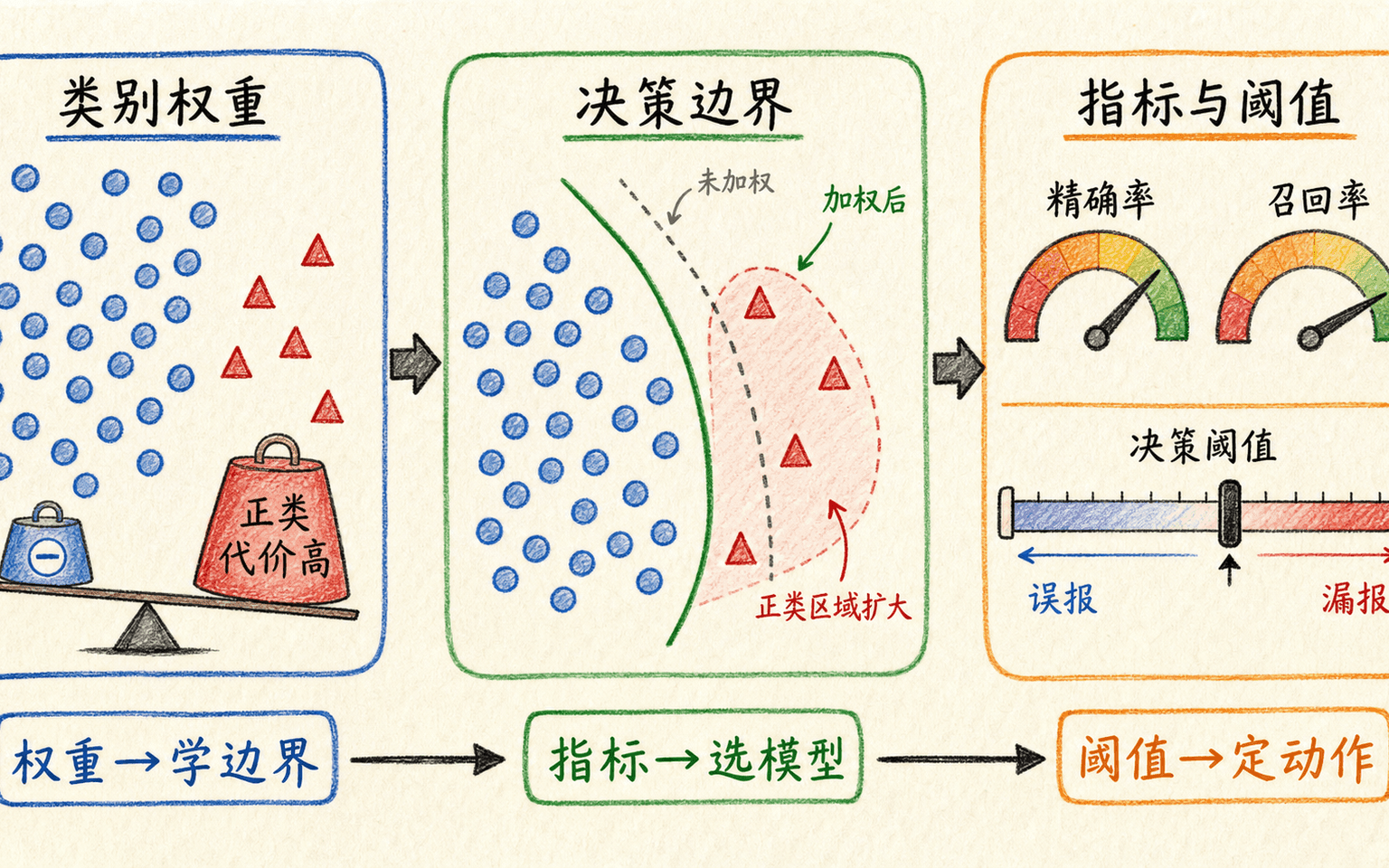
类别权重改变训练代价,部署阈值决定最终行动,两者需要分开验证。
处理不平衡时,至少要分清三件事:
- 训练损失权重改变模型学到的边界;
- 评估指标决定搜索时奖励哪种结果;
- 决策阈值决定连续分数怎样变成最终动作。
三者不能互相替代。提高正类权重可能增加召回,也可能显著降低精确率;改变阈值可以在同一模型上移动误报与漏报,却不会重新学习表示;概率校准让分数更接近频率含义,也不自动选出业务最优阈值。
一个稳妥流程是:在训练折内比较类别权重;在 out-of-fold 或验证分数上按成本、容量或召回约束选择阈值;冻结模型、校准器和阈值后,再用测试集验收。若还要过采样或欠采样,采样步骤同样只能发生在交叉验证的训练折内。
11
在正类稀有的 SVM 项目中,下面哪些判断正确?
线性 SVM 与核 SVM 的规模账要算清楚
“SVM 适合中小数据”说得太粗。线性 SVM 与核 SVM 的计算结构不同,能处理的规模也不同。
核 SVC 的成本跟样本数快速增长
核 SVM 的对偶问题围绕样本对展开。基于 LIBSVM 的 SVC,拟合时间通常至少随样本数平方级增长,具体还受数据分布、缓存命中和收敛情况影响。样本达到数万后,多轮交叉验证就可能变得昂贵。
预测一个新样本时,需要计算它与支持向量的核值:
因此,预测成本与支持向量数量相关。数据重叠或噪声较多时,支持向量可能占训练集很大比例。“只保存支持向量”并不保证模型一定稀疏。
线性求解器按特征结构扩展
LinearSVC、线性 SGDClassifier 等不需要保存核展开,预测时只计算 。它们通常更适合:
- 样本达到十万、百万量级;
- 文本等高维稀疏特征;
- 低延迟在线预测;
- 需要直接检查线性系数的场景。
LinearSVC 与 SVC(kernel="linear") 虽然都产生线性边界,但求解器、默认损失、截距正则化和多分类策略可能不同,所以相同 不保证结果一致。
如果线性边界不够,而完整核 SVC 又太慢,可以考虑 Nyström、随机傅里叶特征等核近似,把非线性映射近似成有限维显式特征,再交给线性学习器。近似误差、映射维度和内存要一起验证。
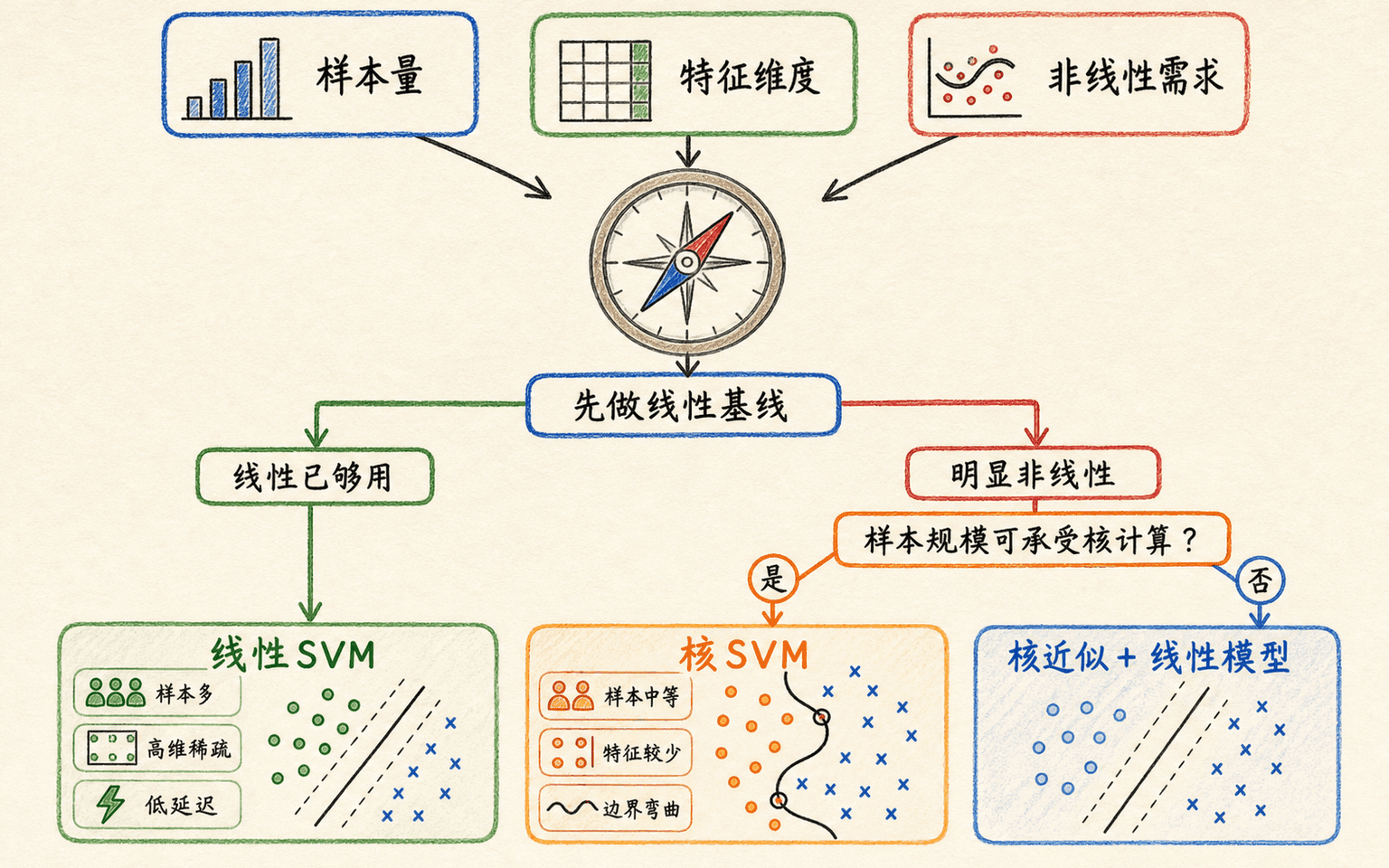
先算训练与推理规模账,再决定是否值得使用非线性核。
下面这张工程账单比“样本多就别用 SVM”更有用:
12
一个 RBF SVC 训练后有 80% 的样本成为支持向量,线上预测又很慢。最直接的原因是什么?
用乳腺肿瘤数据走一遍可复查案例
下面用 scikit-learn 自带的乳腺肿瘤二分类数据演示完整骨架。目标不是追求一个固定分数,而是展示正确的数据边界:测试集先封存,缩放和搜索只在训练集交叉验证中发生,最后一次性评估。
划分数据并建立搜索对象
python
from sklearn.datasets import load_breast_cancer
from sklearn.metrics import (
classification_report,
confusion_matrix,
roc_auc_score,
)
from sklearn.model_selection import (
GridSearchCV,
StratifiedKFold,
train_test_split,
)
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
from sklearn.svm import SVC
data = load_breast_cancer()
这里把 class_weight 也当作候选,是因为类别比例与错误代价需要一并检查。若业务明确规定漏诊和误报成本,搜索指标应改成相应成本或约束,而不是机械照抄 ROC-AUC。
只在方案冻结后查看测试集
python
best_model = search.best_estimator_
y_pred = best_model.predict(X_test)
y_score = best_model.decision_function(X_test)
print("测试 ROC-AUC:", roc_auc_score(y_test, y_score))
print("混淆矩阵:\n", confusion_matrix(y_test, y_pred))
print(
classification_report(
y_test,
y_pred,
target_names=["良性", "恶性"],
)
)
svc = best_model.named_steps["svc"
测试报告至少要连同以下信息保存:
- 数据与标签版本、划分随机种子和实体隔离规则;
- 最终预处理、核、、 与类别权重;
- 搜索空间、切分器、主指标和并列处理方式;
- 混淆矩阵原始计数与关键类别指标;
- 支持向量数、训练时间、预测延迟和模型大小;
- 若使用阈值或校准器,它们的数据来源和版本。
如果报告促使你重新扩大参数网格、换指标或改阈值,这没有问题,但它意味着新一轮开发。刚刚查看过的测试集已经进入决策回路,不能继续把同一份分数称为完全独立的最终证据。
概率需求应单独设计校准切分
这个案例只使用 decision_function 计算 ROC-AUC,没有把分数叫作概率。若下游需要“恶性概率”,应在训练范围内额外设计独立校准集或交叉验证校准,并在测试集上检查概率损失和可靠性图。不要直接对测试分数拟合 sigmoid,再在同一测试集宣称概率准确。
13
关于案例中的数据使用,哪些做法符合独立验收原则?
用症状清单排查 SVM,而不是盲目扩大网格
SVM 出问题时,参数搜索只是诊断工具之一。先把症状和可能原因对上,往往比把网格扩大十倍更快。
还有几项经常被忽略:
- 常量或近常量特征会浪费计算,也可能让默认 的数据方差缩放变得难解释;
- 缺失值处理必须在 Pipeline 中完成,不能先用全数据统计量填补;
- 训练—服务变换不一致会让同一个 面对完全不同的距离尺度;
- 自定义核矩阵的行列顺序必须与样本严格对齐,并检查对称性和数值特征值;
- 收敛警告不能只靠增大迭代上限掩盖,应先检查缩放、重复样本和参数极端值;
- 调参耗时应记录单次拟合、组合数量和折数,先在子集上估算总预算。
最后,把 SVM 放回完整机器学习流程里。它是一种带明确几何与优化结构的分类器,不是解决数据定义、标签质量和分布错配的替代品。前一章的评估协议和误差账本,在这里仍然适用;下一章进入聚类后,标签会消失,但“距离由什么特征和尺度定义”这个问题反而会更突出。
14
RBF SVM 训练准确率接近 100%,交叉验证明显较差,而且多数样本成为支持向量。最合理的第一轮排查是什么?