聚类:从 K-means 原理到可解释、可复现的分群流程
聚类常被描述成“让算法自己发现数据里的群体”。这句话只说对了一半。算法确实不需要我们提前给每个样本贴上类别标签,但它不会凭空读懂“什么叫相似”。我们选了哪些特征、怎样缩放、使用哪种距离、允许什么形状的簇,这些决定已经把人的判断写进了问题。
所以,聚类结果不是藏在数据里、等着被挖出来的唯一答案。对同一批用户,有人按消费能力分群,有人按活跃习惯分群,两种结果都可能合理;换一个观察窗口或距离定义,分组又可能改变。我们真正要做的是:先说明当前任务里的相似性,再找出一种稳定、可解释、能支持后续行动的划分。
这一章会以 K-means 为主线。我们会从目标函数推到分配与更新步骤,解释 k-means++ 为什么不是“每次选最远点”,再处理特征缩放、空簇、离群点、局部最优和不同形状等工程问题。最后,我们用图像颜色量化和用户分群把完整流程串起来,并比较层次聚类、DBSCAN、HDBSCAN、高斯混合模型等替代方案。
本章默认有 个样本、 个数值特征,希望得到 个簇。样本写作 ,第 个中心写作 ,第 个样本的簇分配写作 。簇编号只是数组索引,不表示大小、等级或先后顺序。
聚类先回答“按什么相似”,再谈算法
监督学习有目标值 。模型预测错了多少,可以直接和标签比较。聚类只有样本 ,没有一列现成答案告诉我们“这个用户属于哪一群”。这使它适合探索结构,也使结果更依赖问题定义。
举个具体例子。我们有一批音乐用户,原始字段包括年龄、城市、近 30 天播放次数、跳过率、夜间收听占比和常听曲风。如果目标是设计会员权益,消费与活跃特征可能更有用;如果目标是编排首页内容,曲风和收听时段可能更重要。把所有字段不加选择地扔给算法,看似客观,实际上只是让数据量纲和冗余字段替我们做决定。
一次聚类至少包含四层选择
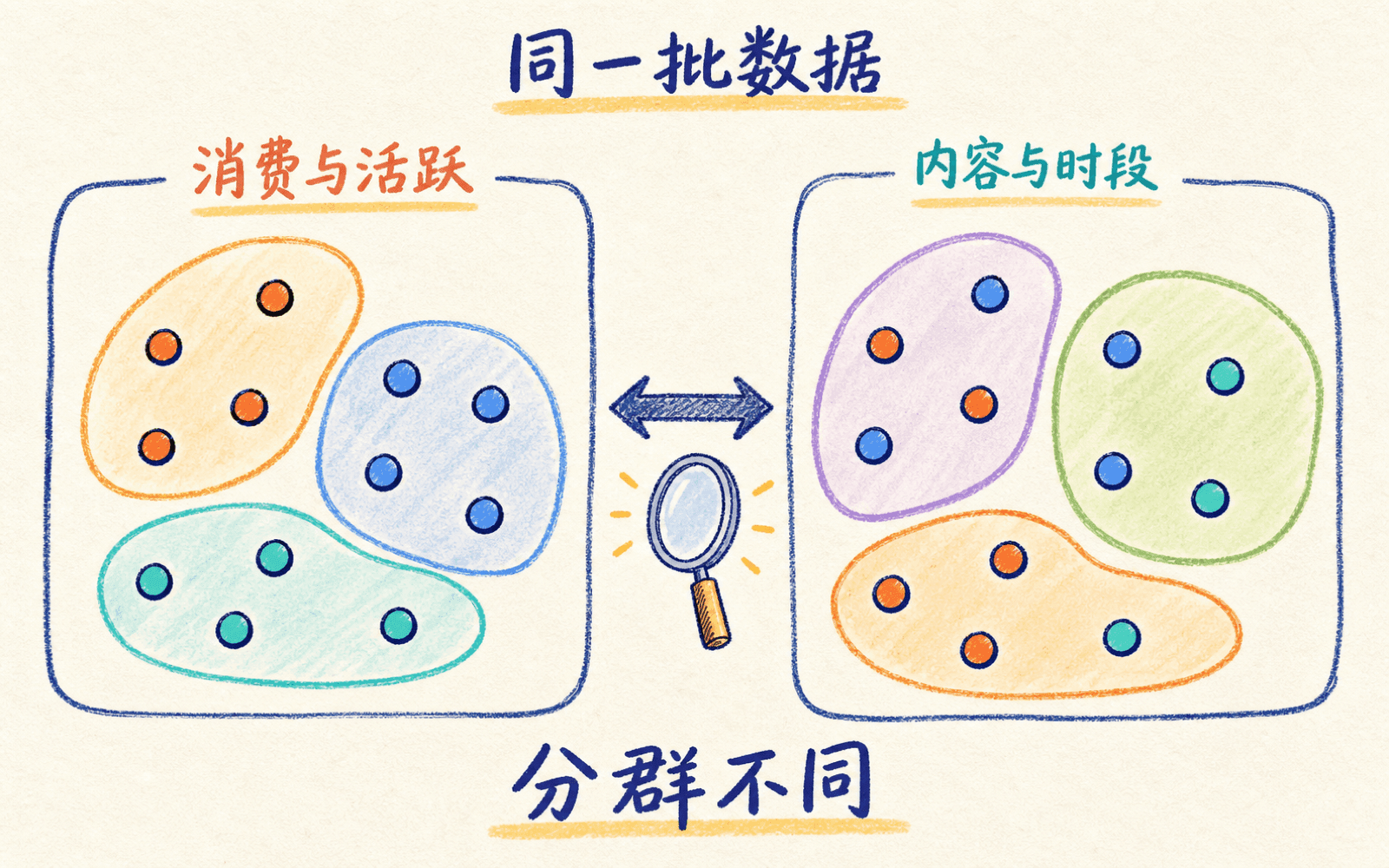
聚类没有脱离任务的唯一答案,先定义“什么叫相似”。
这也解释了为什么“簇是不是天然真相”通常没有简单答案。物种、疾病亚型等任务有时存在外部知识可检验;用户偏好、新闻主题和商品风格往往更像连续谱。即便数据完全没有明显团块,聚类算法仍然能切出若干组。算法返回了标签,不等于数据证明了这些群体真实存在。
聚类项目开始前,我建议先写下一句可检验的任务说明:
在给定的时间窗口和特征表示下,把样本划成若干组,使组内对象在指定距离上更接近,并检查这些分组是否稳定、可解释且能支持后续决策。
这句话没有承诺“发现真实类别”,却把样本、相似性和验收条件都摆到了桌面上。
1
同一批用户分别按消费行为和内容偏好得到两套分群,最合理的判断是什么?
K-means 优化的是簇内平方距离
K-means 的名字来自两件事:我们预先指定 个簇,每个簇用成员的均值表示。它的目标是让每个样本靠近自己所属的中心。常见目标函数叫簇内平方和(within-cluster sum of squares,WCSS),在 scikit-learn 中对应 inertia_:
有些教材在前面乘 ,把总和写成平均值。这个常数不会改变最优的分配和中心。关键部分是欧氏距离的平方:远离中心的点会受到更大的惩罚,中心则由算术平均数给出。
也可以把目标写成“每个点挑最近中心”的形式:
当中心固定时,空间会被最近中心切成若干 Voronoi 区域。落在同一区域的样本归为一簇,区域之间的边界是到两个中心等距的超平面。因此,标准 K-means 偏好紧凑、凸、尺度相近的团块。
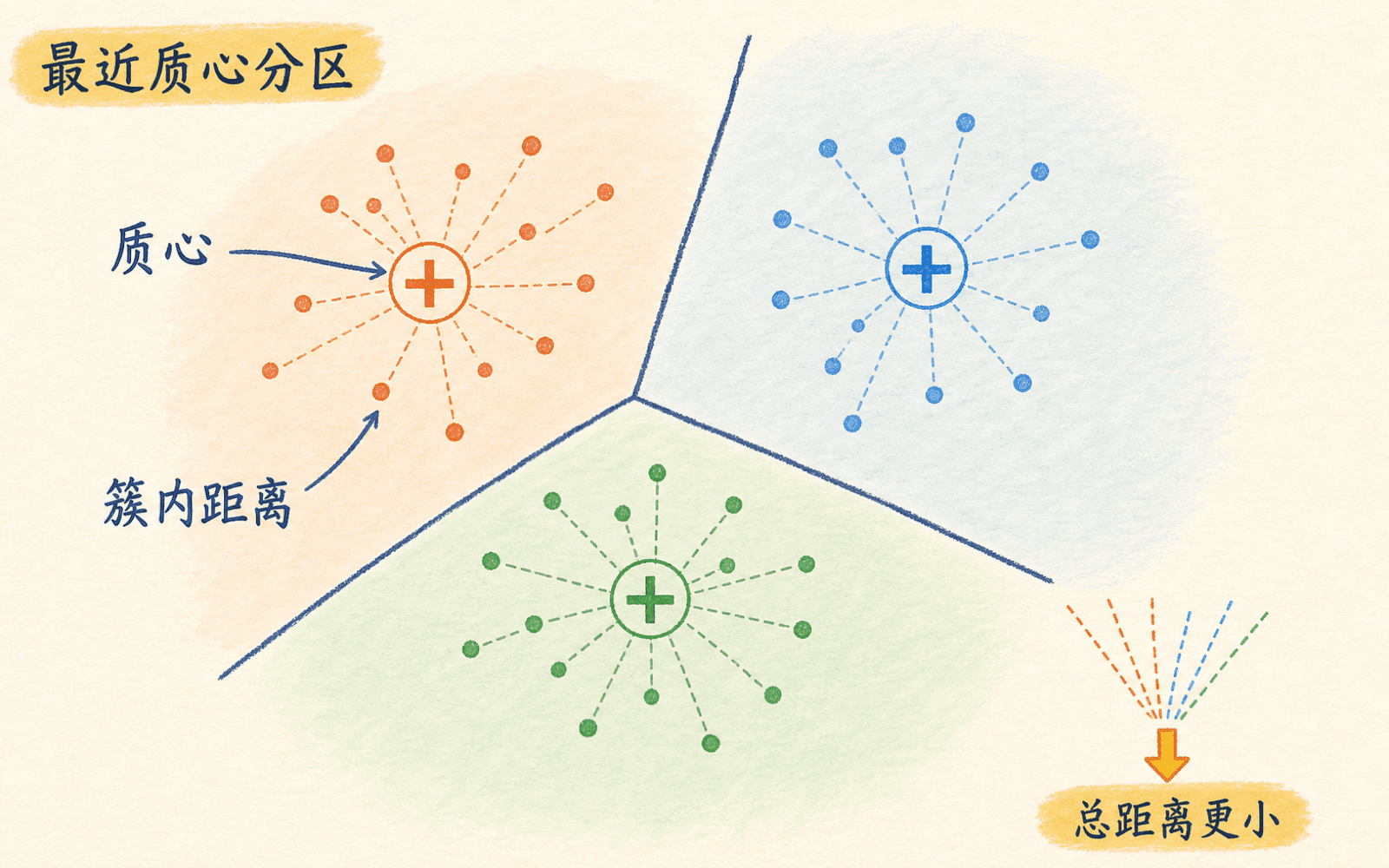
每个点归给最近质心,算法优化的是到所属质心的平方距离总和。
中心不一定是某个真实样本
若一个簇里有三个二维样本 、 和 ,中心是:
这个点可以不在原始数据中。若业务要求“代表对象必须是真实商品或真实用户”,更贴近需求的是 k-medoids:它从样本里选中心,并且通常比均值对极端值更稳健。
簇标签可以任意重命名
一次运行输出 [0, 0, 1, 1],另一次输出 [1, 1, 0, 0],两者表达的是同一划分。数字 0 和 1 没有语义,也没有顺序。展示用户分群时,应根据画像另建稳定名称,例如“高频低客单”与“低频高客单”,不要把 cluster_id=3 解释成“等级 3”。
2
K-means 输出的簇编号 2 比簇编号 1 更大,因此可以直接解释为更高价值人群。
分配与更新是对同一目标的交替优化
同时搜索所有样本的簇分配和所有中心很难。Lloyd 算法采用一个直接办法:固定一半变量,优化另一半,再交换。这样每一步都不会让目标函数上升。
固定中心:每个样本选最近的一簇
给定中心 ,不同样本的选择互不影响。第 个样本只需比较到所有中心的平方距离:
若两个中心距离完全相同,实现通常按固定规则打破平局。这不会破坏目标函数,但可能使边界上的个别样本在不同实现间得到不同编号。
固定分配:每个中心移动到成员均值
令第 个簇的样本索引集合为:
只看这个簇对目标的贡献:
对 求梯度并令它为零:
得到更新公式:
所以“更新到均值”不是随手选的启发式规则,而是固定分配后让簇内平方和最小的精确解。
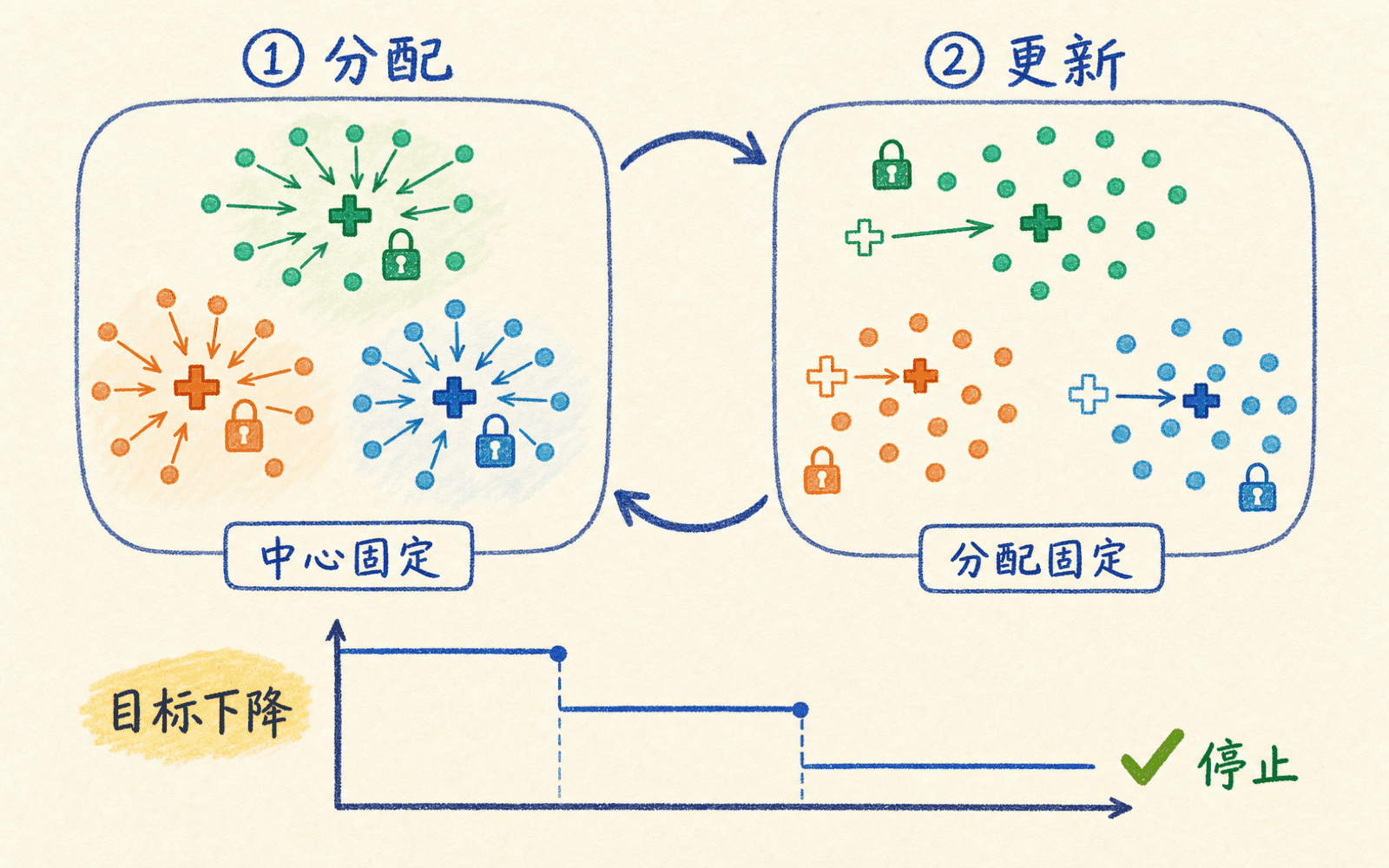
分配和更新分别固定一半变量,使同一个目标逐步不增。
为什么会收敛,又为什么不保证全局最优
分配步骤选择当前最近中心,目标不会增大;更新步骤把中心放到当前成员的均值,目标也不会增大。有限个样本只有有限种分配,算法最终会停在某个不再改进的解上。常用停止条件包括中心移动量低于阈值、目标下降太小或达到最大迭代次数。
但“每一步都下降”只说明收敛到一个局部解。初始中心不同,算法可能走向不同终点。目标曲线单调下降是运行正常的信号,不是已经找到全局最小值的证明。
空簇没有均值
若某轮分配后 为空,更新公式的分母是 0。不同实现会保留旧中心、重新选择远点或拆分高误差簇。自己实现时必须明确策略;否则一个 mean([]) 就会产生 NaN,下一轮所有距离都可能失效。
3
固定当前簇分配后,为什么把中心更新为簇内样本均值?
k-means++ 与多次运行是在管理局部最优
最朴素的初始化是从训练样本中随机选 个不同点。若多个初始中心挤在同一团数据里,另一个真正分离的区域就可能没有中心,后续迭代容易落入较差的局部解。
k-means++ 用“相距远,但仍保留随机性”的方式选种子。先均匀随机选第一个中心;已有中心集合为 时,对每个样本计算它到最近已有中心的平方距离:
下一个中心按下面的概率从样本中抽取:
距离已有中心越远,被抽中的概率越高;但它不是每轮确定性地选择最远点。这种 加权保留了随机性,也避免一个孤立极端值必然被当成中心。
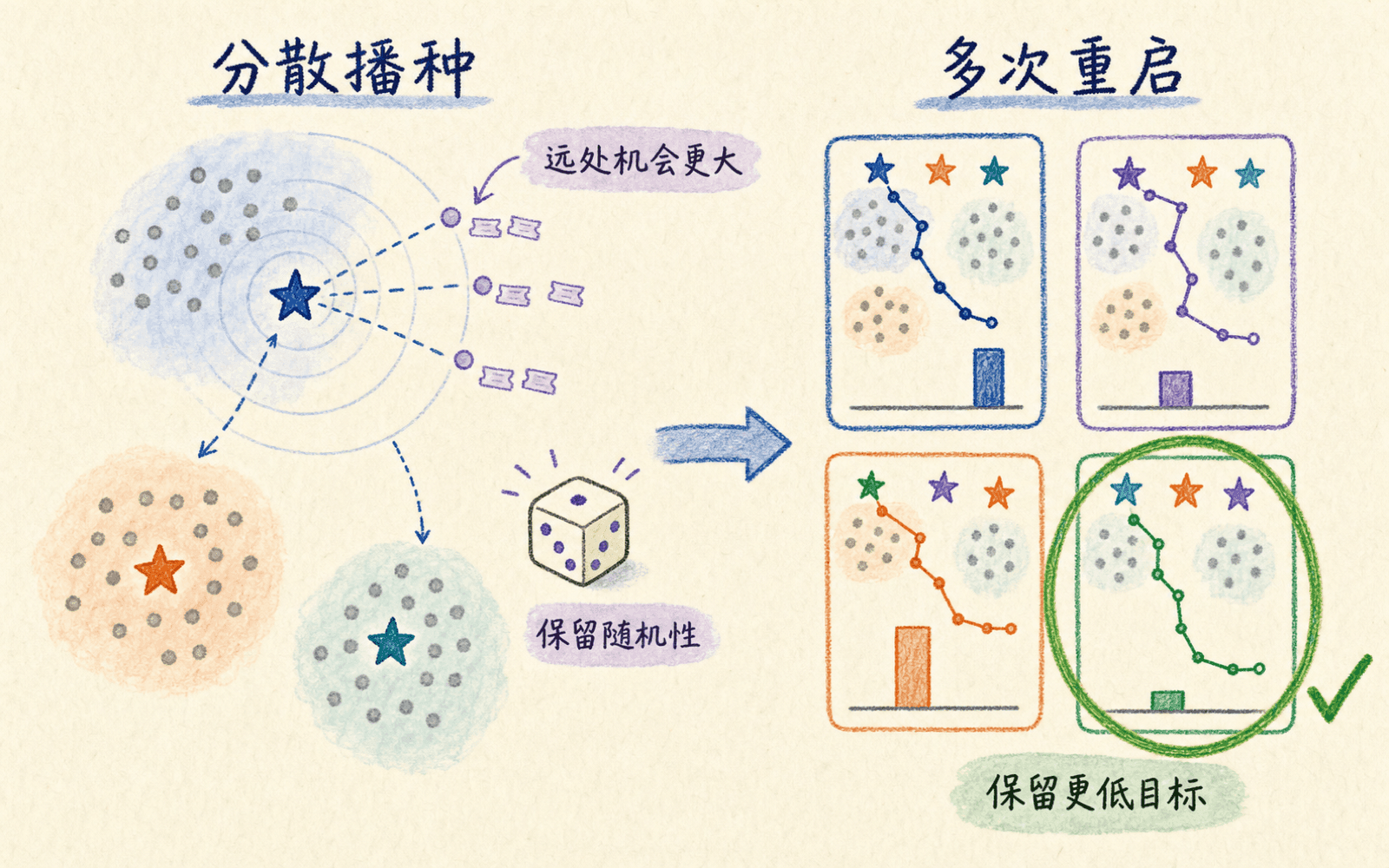
更好的播种和多次独立运行是在管理局部最优,不是消除它。
好初始化仍然需要重启
k-means++ 改善起点,不会把非凸问题变成凸问题。稳妥做法是使用多个随机种子独立拟合,保留 inertia_ 最小的一次。重启次数没有适合所有数据的固定数字:簇越重叠、维度越高、结果越重要,越应该查看多次运行的目标分布和分群稳定性。
在 scikit-learn 中,n_init 控制独立初始化次数,random_state 让同一配置可复现。显式写出 n_init 比依赖不同版本的默认值更清楚:
python
from sklearn.cluster import KMeans
model = KMeans(
n_clusters=4,
init="k-means++",
n_init=20,
max_iter=300,
random_state=42,
)
labels = model.fit_predict(X_scaled)
print(model.inertia_, model.n_iter_)复现同一个随机种子是为了定位问题和交付结果,不是为了证明结果稳定。稳定性要通过更换种子、重采样或时间窗口后仍得到相近划分来检查。
4
关于 k-means++ 和多次运行,下列哪些说法正确?
特征缩放和距离定义决定谁算“邻居”
K-means 每一次分配都在比较欧氏距离。若一个用户用两个特征表示:年消费金额范围是 到 元,月访问次数范围是 到 次,那么未缩放时,金额方向的一点变化就可能压过访问次数的全部差异。算法并不知道“元”和“次”不能直接比较。
标准化常把每个特征变成均值约为 0、标准差约为 1:
这样做不是永远正确,只是让各列的典型波动处在相近尺度。若业务明确认为订单金额比访问次数重要,可以在标准化后再施加权重;比起让原始单位暗中决定权重,这种做法更容易解释。
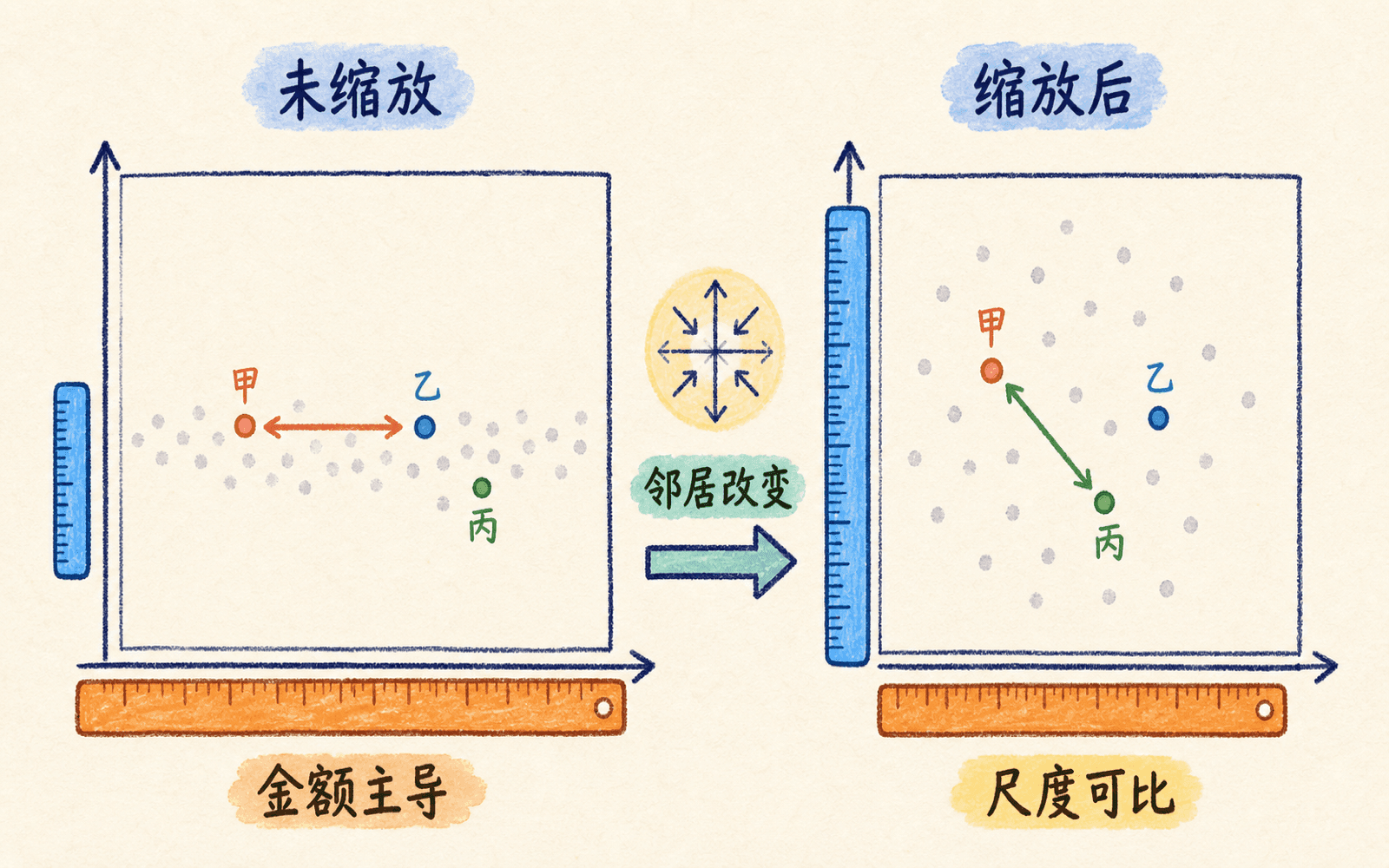
距离会把量纲写进模型;缩放方式本身就是相似性假设。
缩放参数也会泄漏信息
若要把聚类模型应用到未来用户,均值和标准差只能在拟合样本上计算,再原样用于后续数据。先用全量数据计算缩放参数,再回头做时间验证,会让未来分布参与训练。这个泄漏不像标签泄漏那样显眼,却会让离线结果偏乐观。
欧氏距离不是所有数据的默认答案
- 连续数值且关注绝对差异时,标准化后的欧氏距离通常是可解释起点。
- 文本词频等高维稀疏向量常更关心方向,可先做 L2 归一化,再谨慎使用 K-means;这时欧氏距离与余弦相似性存在紧密关系。
- 类别字段不能用城市编号
1、2、3直接制造距离。需要合适编码,或改用能处理混合数据的距离与算法。 - 周期变量如小时
23与0实际很近,直接使用整数却很远,可编码成正弦和余弦。 - 经纬度覆盖较大区域时,平面欧氏距离未必合适,应考虑球面距离或先投影到合适坐标系。
“先标准化再 K-means”不是无需思考的固定配方。标准化仍然隐含“每个特征一个标准差同等重要”。相关特征重复出现还会被重复计权,因此要同时检查特征选择、相关性和业务权重。
5
用户特征包含年消费金额和月访问次数,直接做 K-means 后几乎只按金额分组。最先应检查什么?
先看失败模式,再决定是否继续用 K-means
K-means 的速度和可扩展性很好,但它的目标函数带着清楚的几何偏好。知道这些偏好,比把任何结果都解释成“发现规律”更重要。
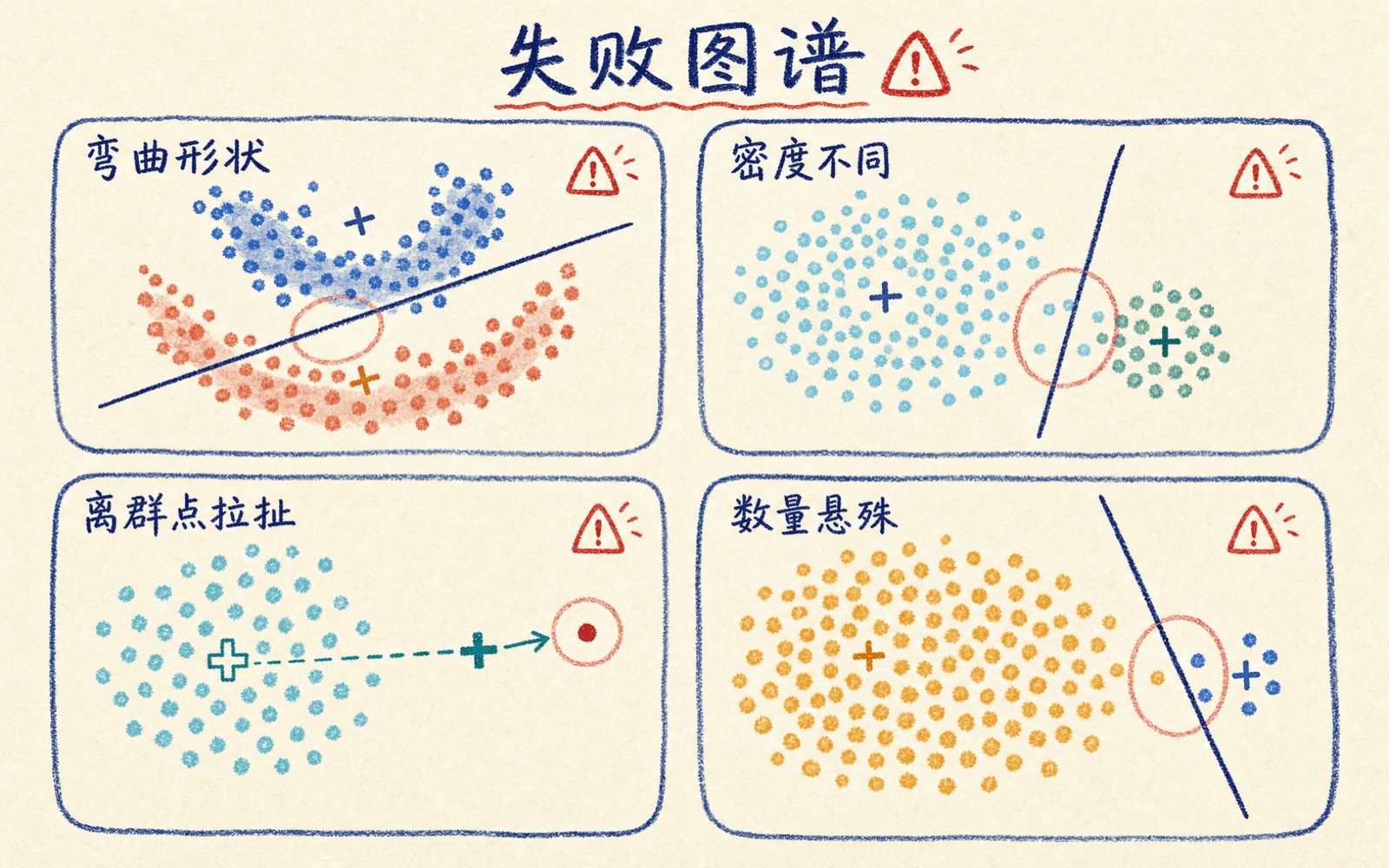
先识别数据形状是否符合假设,再决定是否继续使用 K-means。
非球形结构:两轮月牙会被直线切开
最近中心产生的边界是线性片段。环形、月牙形或沿曲线延伸的簇,可能在视觉上连成一体,却被 K-means 横切。若结构由局部连通性定义,DBSCAN、HDBSCAN 或谱聚类通常更贴近问题。
密度和方差差异:大团块会吞掉小团块
K-means 偏好方差相近的紧凑簇。一个宽而稀疏的群体旁边有一个小而密的群体时,中心会为了降低总平方误差而移动,边界未必落在视觉上的低密度谷底。不同样本数也会产生类似问题:大簇对总目标贡献更大。
离群点:平方损失会放大远距离
一个极远样本可能显著拉动均值,甚至独占一个中心。先核对异常值是数据错误、真正的少数模式,还是任务外样本。若希望把孤立点显式标为噪声,可以考虑密度方法;若仍要中心代表,可比较 k-medoids 或做有依据的稳健预处理。
高维空间:所有点都可能显得差不多远
特征很多且含噪时,欧氏距离的区分度会下降。此时应先做领域驱动的特征筛选,或在保留足够信息的前提下尝试 PCA,再重新评估稳定性。不能因为二维投影看出几个团,就断言高维空间里存在同样边界;投影本身也会改变几何关系。
空簇与小簇:它们可能是诊断信号
频繁出现空簇,常见原因包括 过大、重复样本很多、初始化不佳或数据有效结构不足。只有一两个样本的小簇也值得复核:它可能是珍贵的稀有群体,也可能只是极端值吸走了中心。不要只写一段“重新随机初始化”就把信号抹掉。
6
下列哪些数据形态容易让标准 K-means 给出违背直觉的结果?
选择 K 要联合看肘部、轮廓、稳定性和用途
固定同一批数据时, 增大,簇内平方和不会上升。极端情况下令 ,每个样本独占一簇,目标可以降到 0,但这个结果通常毫无概括价值。因此,“选让 inertia 最小的 ”没有意义。
肘部法看边际收益是否明显变小
对一组候选 分别拟合,画出 与 inertia 的关系。若从 到 下降很多,之后改善变缓, 像手臂弯折处的肘部。问题是,很多真实曲线平滑下降,没有清楚拐点;不同观察者也可能选出不同位置。
轮廓系数同时比较组内紧密和组间分离
对样本 ,令 为它到同簇其他样本的平均距离, 为它到最近其他簇中样本的平均距离。轮廓系数是:
接近 1 表示样本比起其他簇更贴近本簇;接近 0 表示处于边界;小于 0 表示它平均更靠近另一个簇。整体分数通常取样本平均值。
轮廓系数也有边界。它要求至少两个有效簇,不能评价 ;它偏爱紧凑、凸且分离的结构,因此可能不公平地低估密度型的弯曲簇。只报一个平均值还会掩盖小簇很差的情况,最好同时看每簇分布。
稳定性问“数据稍微变化,结果还在吗”
可以反复抽取子样本、改变随机种子或移动时间窗口,再比较共同样本的分群一致性。若某个 的平均指标不错,但轻微扰动就让大量样本换组,这个解不适合作为稳定运营规则。比较时要用对标签置换不敏感的指标,例如 ARI,而不是直接计算簇编号相等率。
业务边界决定结果能否落地
运营团队只能维护 4 套方案, 即使轮廓略高也未必可用;图像颜色量化则可以把 直接理解为调色板颜色数,在画质和存储之间权衡。还要检查最小簇是否足够大、画像差异是否能解释、每组是否有不同动作,以及新样本如何归组。
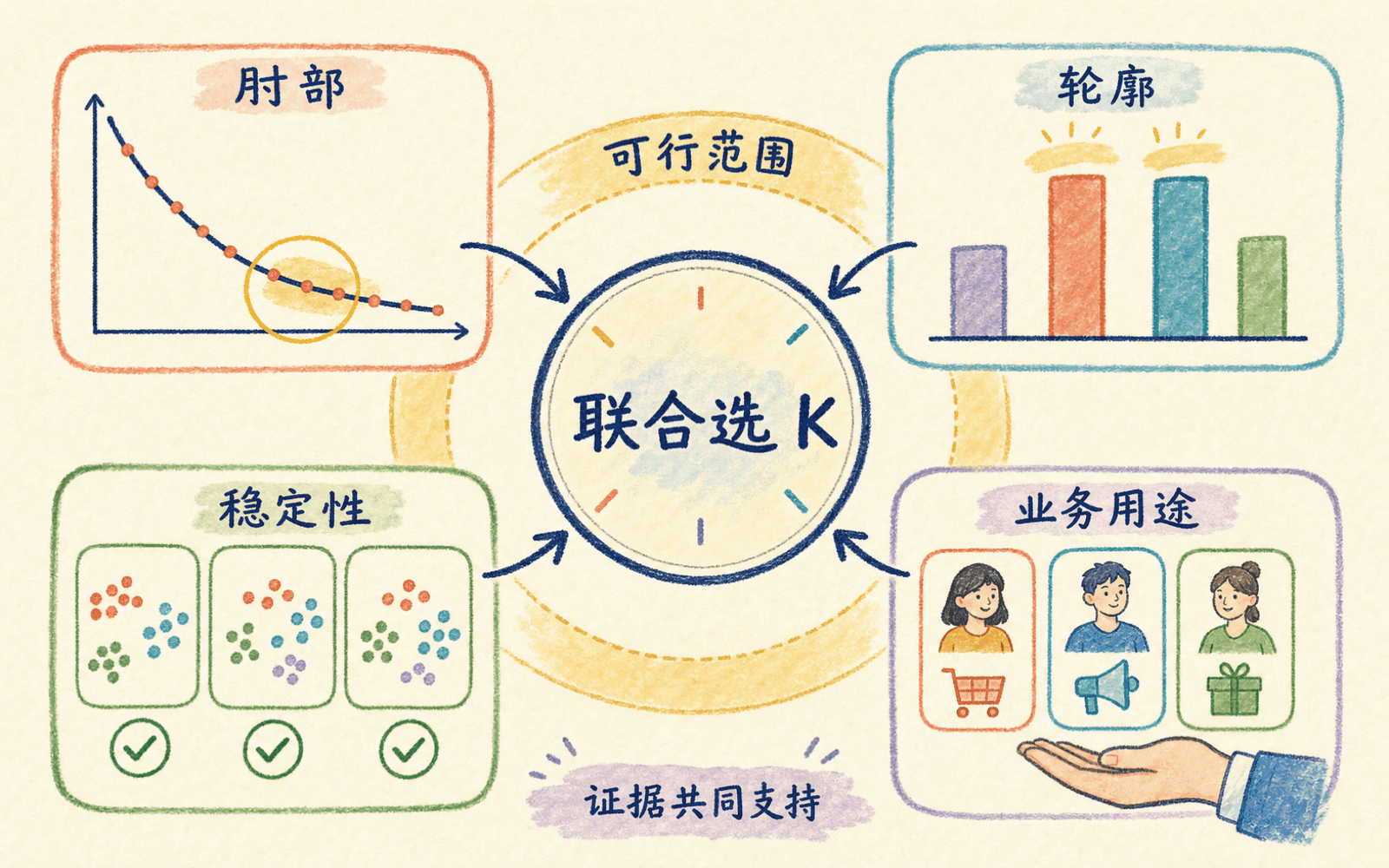
K 是证据与用途的共同选择,单个内部指标不能替代业务判断。
一个稳妥的选择过程不是让四个标准投票,而是先设业务可行范围,再在范围内联合比较:
- 肘部是否有明显的边际收益变化;
- 轮廓的整体均值和逐簇分布;
- 重采样、随机种子和时间窗口下的稳定性;
- 簇规模、画像与后续动作是否合理。
若这些证据都不支持清楚结构,“不发布分群”也是有效结论。
7
某数据的 inertia 随 K 平滑下降、没有明显肘部。下一步最合理的做法是什么?
聚类评估要分清有无外部真值
聚类没有通用的“准确率”。评估前先问:是否存在独立于聚类过程的参考标签?这个标签代表的是不是我们当前想找的结构?鸢尾花物种可以用于教学比较,但若我们按花朵尺寸做市场包装,物种标签未必就是目标。
有参考标签:比较划分,而不是比较编号
调整兰德指数(Adjusted Rand Index,ARI)从样本对出发:两种划分是否都把一对样本放在一起,或都把它们分开。它对簇编号置换不敏感,并对随机一致进行校正。ARI 接近 1 表示高度一致,接近 0 表示与随机划分相当,某些冲突划分可以得到负值。
调整互信息(AMI)从信息共享角度比较两套划分,也会校正随机一致。两者都不要求预测簇编号和参考类别编号一一相同。
参考类别与聚类之间也可能不是一对一关系。一个物种内部可能按生长阶段分成两个簇,两个类别也可能因当前特征不可分而落入同一簇。指标低时,要先理解差异结构,不要立即把算法判成“错误”。
没有参考标签:内部指标只能检验自己的假设
inertia 衡量对平方欧氏目标的拟合程度;轮廓系数衡量指定距离下的紧密与分离;Calinski–Harabasz、Davies–Bouldin 等指标也各有几何偏好。它们能比较候选解,却不能证明这些簇有业务含义。
稳定性与下游效用补上另外两块证据
稳定性检查结果能否在采样噪声、时间变化和随机初始化下复现。下游效用则检查分群是否改善真实任务,例如人工审核效率、推荐覆盖率或营销实验增量。若聚类用于探索而非决策,也可以请领域人员盲评画像是否一致、边界样本是否合理。
评估最好形成一张证据表:
8
若预测簇标签是 [0,0,1,1],参考标签是 [1,1,0,0],仅因数字不相同就应判为完全错误。
MiniBatch K-means 用少量精度换取规模
标准 Lloyd 迭代每轮都要让 个样本与 个中心比较。在 维空间迭代 轮,朴素计算量大致是:
数据有数千万行时,即使单次距离很便宜,反复全量扫描也会成为瓶颈。MiniBatch K-means 每轮随机抽取一小批样本,只用这批样本更新相关中心。中心采用流式均值,随着已见样本数增加,单个新样本带来的移动会逐渐变小。
若中心 已累计接收 个样本,新样本 分到该中心,一种直观更新写法是:
它仍在尝试优化同一个簇内平方距离目标,但没有在每轮精确完成全数据分配与均值更新。结果通常更快,解可能比完整 K-means 略差。
什么时候值得使用
- 全量 K-means 的运行时间或内存已经影响实验速度;
- 数据持续到达,需要分批更新;
- 可接受小幅目标损失,换取显著吞吐提升;
- 已用代表性样本确认特征、距离和 大致合理。
不要只比较训练时间。至少同时记录完整数据上的 inertia 近似、轮廓抽样、重启稳定性、簇规模和下游表现。批大小太小会增加更新噪声,太大则逐渐失去加速收益。
python
from sklearn.cluster import MiniBatchKMeans
mini = MiniBatchKMeans(
n_clusters=8,
batch_size=2048,
n_init=10,
random_state=42,
)
mini.fit(X_scaled)
print("迭代批次数:", mini.n_steps_)
print("近似簇内平方和:", mini.inertia_)对高维稀疏文本,距离集中和初始化不稳定往往比计算量更早暴露。可以在验证表示方式后使用 MiniBatchKMeans,但应增加重启并检查空簇、小簇和主题可解释性。
9
使用 MiniBatch K-means 的主要权衡是什么?
层次、密度与概率模型各自回答不同问题
看到 K-means 失败,不应直接在它的参数上无限调试。先判断失败来自哪条假设,再选择更贴近任务的算法。
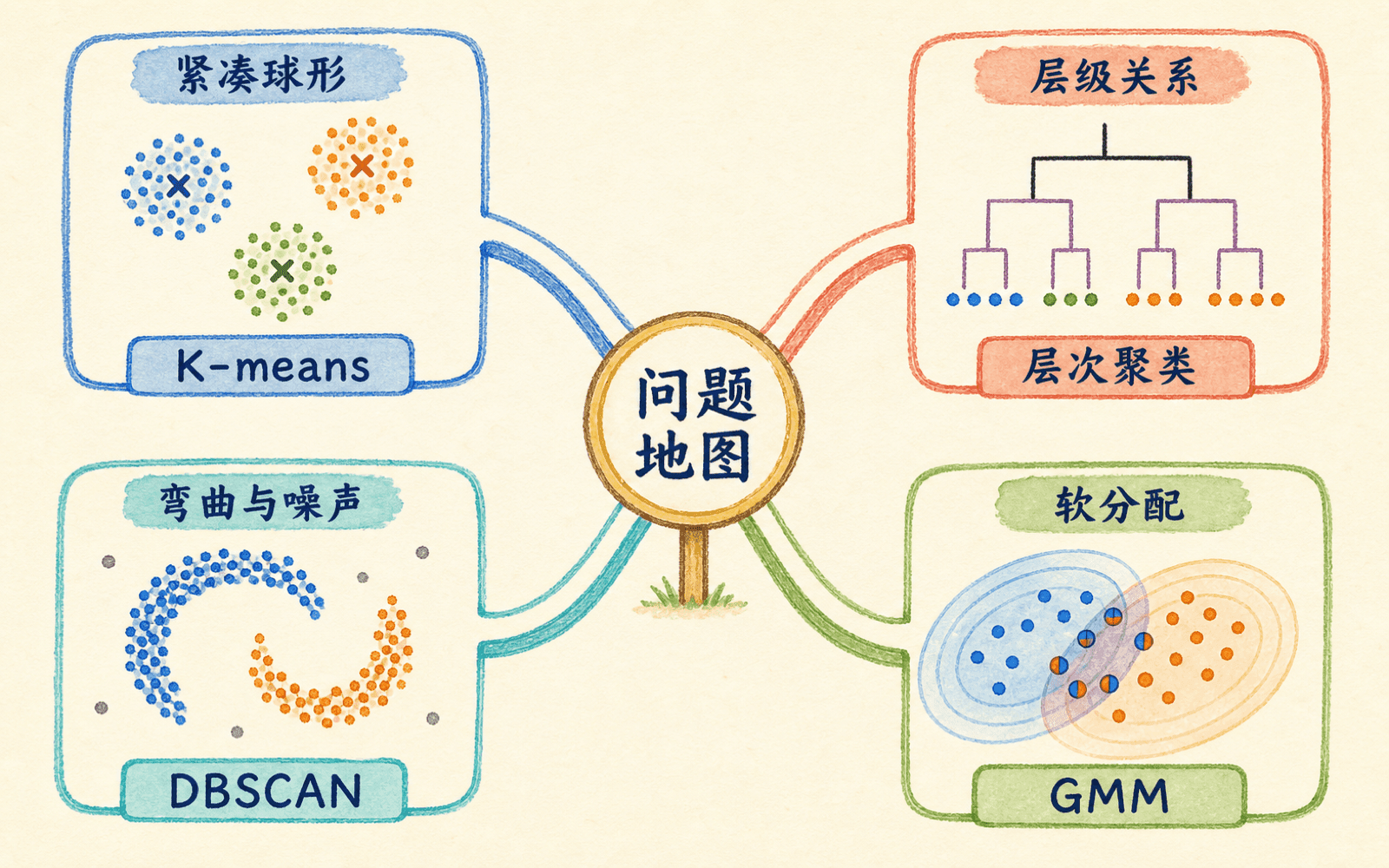
不同算法回答不同结构问题,选择应从簇形状、噪声和输出需求出发。
层次聚类:需要一棵从细到粗的关系树
凝聚式层次聚类从每个样本各自成簇开始,逐步合并最接近的两组。树状图能展示不同切割高度下的分组,适合探索基因、商品品类等层级关系。结果强烈依赖 linkage:single 容易沿链条连接,complete 强调最远成员,average 看平均距离,Ward 倾向降低簇内方差。
它不意味着“完全不用决定簇数”。你仍需选择切割高度或目标簇数,而且大数据上的距离和树结构会带来计算与内存压力。
DBSCAN / HDBSCAN:簇由高密度连通区域定义
DBSCAN 用邻域半径 eps 和最小样本数 min_samples 寻找核心点,并从核心点扩展密度连通区域。它不需要预先给 ,能发现弯曲形状,还会把无法归入密集区域的点标为噪声。
但单一 eps 难以同时照顾密度差异很大的簇。eps 太小会把稀疏簇切碎,太大又会把相邻密集簇连起来。HDBSCAN 通过多尺度密度层次处理变化密度,代价是参数和结果解释更复杂。
高斯混合模型:需要软分配和椭圆形概率结构
高斯混合模型(GMM)假设数据由多个高斯成分生成,估计每个成分的均值、协方差和混合权重。它能输出每个样本属于各成分的概率,而不是只有一个硬标签;完整协方差还可以表达倾斜的椭圆形簇。
GMM 仍需选择成分数和协方差结构,也会受初始化影响。样本太少而协方差过于自由时,容易过拟合或出现数值问题。BIC 可以作为模型选择证据之一,但同样不能替代领域检验。
其他常见选择
算法选择最终回到一句话:你希望“同一簇”由中心距离、层级合并、局部密度,还是生成概率来定义?
10
下列任务与候选方法的搭配中,哪些较合理?
图像颜色量化把像素压成一张调色板
一张 RGB 图像的每个像素可以写成三维向量 。把所有像素当样本,令 表示允许保留的代表色数量,K-means 中心就变成一张 色调色板。每个像素用最近中心颜色替换,即完成向量量化。
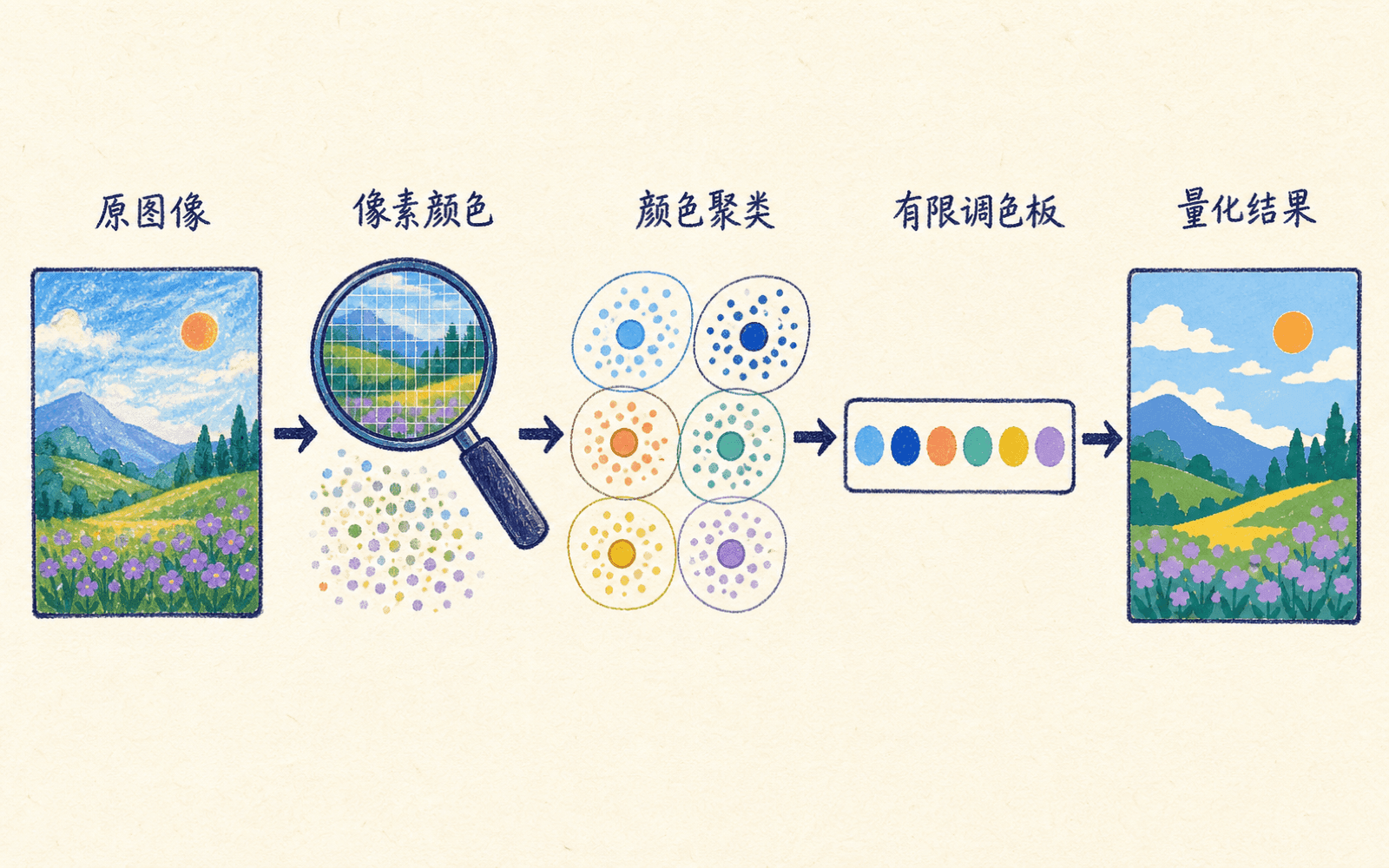
颜色量化把每个像素映射到最近质心颜色,以更小调色板近似原图。
流程可以拆成四步:
读取形状为 的图像,把它重排为 的像素矩阵。若使用浮点数显示,通常把通道值缩放到 。
python
import numpy as np
from PIL import Image
from sklearn.cluster import MiniBatchKMeans
image = np.asarray(Image.open("photo.png").convert("RGB"), dtype=np.float32)
h, w, channels = image.shape
pixels = image.reshape(-1, channels) / 255.0
quantizer = MiniBatchKMeans(
n_clusters=16,
这个案例也暴露了 K-means 的假设。普通 RGB 欧氏距离不完全等同于人眼感知色差;像素被独立聚类,空间相邻关系没有进入目标;均值颜色可能不是原图中出现过的颜色。若对感知质量要求高,可以改用更合适的颜色空间或色差度量,并把结果交给真实编码器验证。
还有一个常见误区:把颜色从 1600 万种降到 16 种,不等于磁盘文件必然按比例缩小。实际体积取决于是否使用索引色、调色板开销、PNG/JPEG 等编码方式和图像内容。K-means 提供的是有限码本,压缩率必须对最终文件测量。
11
用 K-means 做 RGB 颜色量化时,K 个聚类中心共同形成一张 ____。
用户分群要从行动目标走回原始量纲
用户分群不是执行一次 fit_predict 就结束。一个可以交付的项目,至少要把数据窗口、特征口径、拟合流程、画像命名和线上使用连起来。
假设订阅产品想制定召回策略。我们先把任务写清楚:以过去 90 天仍有使用记录的用户为样本,按近 30 天活跃、内容消费和付费行为分群,目标是设计不同的消息频率与权益,而不是预测谁一定会续费。
特征要有时间边界和可行动含义
可以选择:
- 近 30 天活跃天数;
- 每次会话平均时长;
- 完播率;
- 距上次访问天数;
- 近 90 天付费金额;
- 内容类别分布的集中程度。
计数和金额常有长尾,可比较 log1p 变换;比例要检查分母过小;强相关的重复指标要删减。城市、设备等字段是否加入,取决于它们是不是我们希望定义相似性的依据,也要考虑公平性和隐私边界。
训练空间与解释空间要分开
模型在经过变换和标准化的特征上寻找中心,但画像应回到原始单位。我们关心的是“该簇近 30 天活跃中位数为 18 天”,而不是“标准分为 1.27”。均值容易受长尾影响,画像表可以同时给出样本数、中位数、四分位数和相对全体的差异。
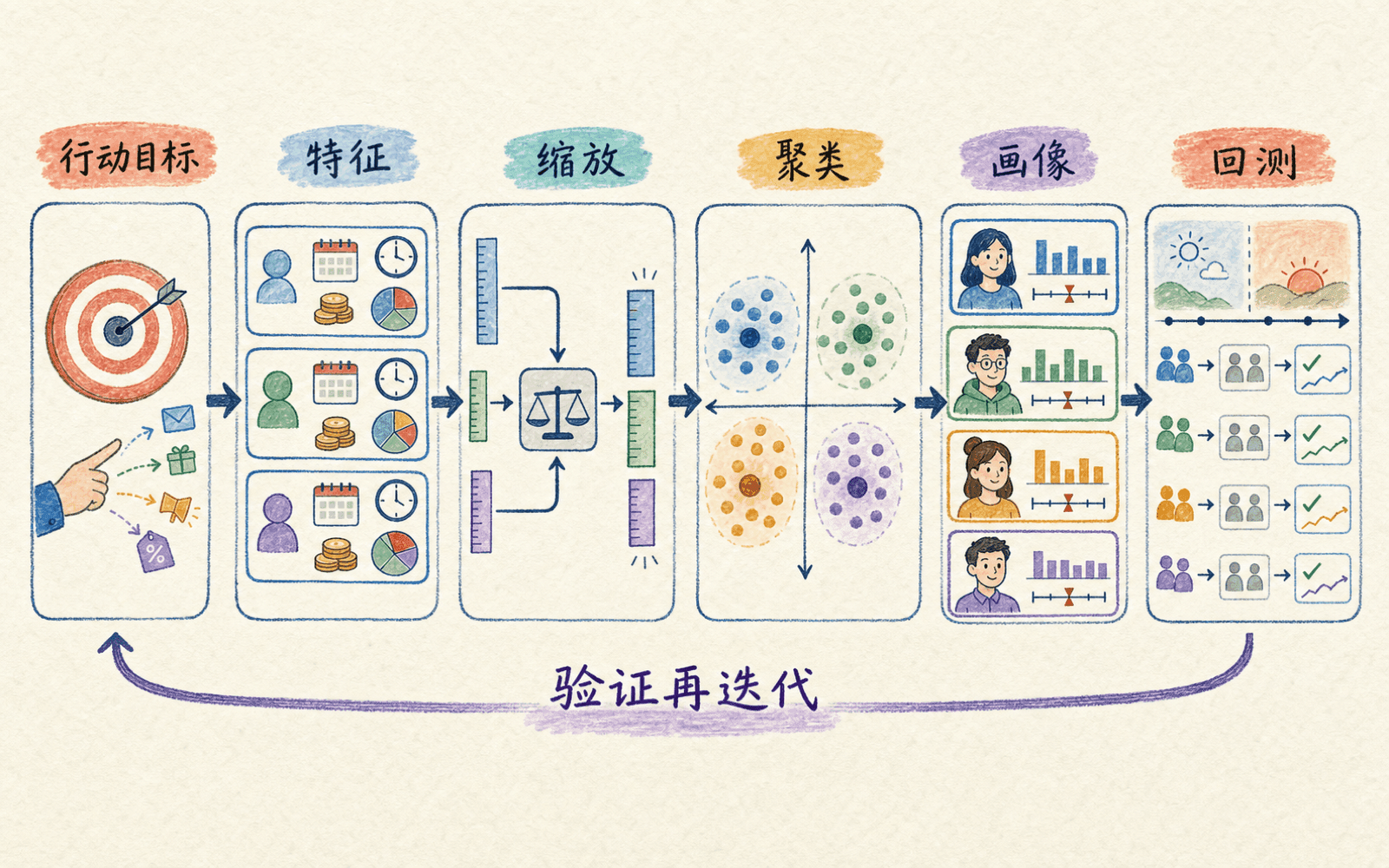
可行动的用户分群必须回到原始量纲、真实人群和后续策略中验证。
一个简化流程如下:
python
import pandas as pd
from sklearn.cluster import KMeans
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
feature_cols = [
"active_days_30d",
"avg_session_minutes",
"completion_rate",
"days_since_last_visit",
"spend_90d_log1p",
]
X = users[feature_cols].copy()
segmenter = Pipeline([
发布前要解决簇身份漂移
下个月重训后,“簇 0”可能对应上个月的“簇 3”。若下游系统直接把数字当固定人群,策略会串组。可以根据中心距离和画像相似度做新旧簇匹配,再发布稳定业务键;若匹配质量很差,应触发人工复核,而不是强行沿用名称。
最后用实验验证价值。例如在每个分群内随机分配两种召回策略,观察增量,而不是只比较不同群体天然存在的续费率。聚类描述的是行为结构,因果效果仍要靠对照实验。
12
用户分群模型重训后,cluster_id=0 的画像完全改变。最稳妥的处理是什么?
可复现实现要记录数据、参数和诊断证据
最后把实现压缩成一个可以复查的最小流程。重点不是追求最多指标,而是让另一个人能回答:用了哪批数据、怎样变换、为什么选这个 、随机性如何控制、结果是否稳定。
python
from dataclasses import dataclass
import numpy as np
from sklearn.cluster import KMeans
from sklearn.metrics import silhouette_score
from sklearn.preprocessing import StandardScaler
@dataclass
class ClusterResult:
labels: np.ndarray
centers_scaled: np.ndarray
inertia: float
silhouette: float
iterations: int
def fit_kmeans_checked(X, k, seed=
排错时按现象找原因
一份可交付记录至少包括
- 数据快照或查询版本、样本范围、时间窗口和排除规则;
- 特征定义、缺失值处理、变换、缩放器参数和距离选择;
- 算法版本、、初始化、
n_init、停止条件和随机种子; - 各候选 的内部指标、逐簇规模与重启结果;
- 重采样或跨时间窗口的稳定性;
- 原始量纲画像、簇命名规则和新旧簇匹配方法;
- 失败样本、边界样本和下游验证结果。
走完这些步骤,我们得到的不是一句“数据天然分成四类”,而是一份条件明确的结论:在当前样本、表示和距离下,某个划分比候选方案更稳定,也更能支持指定任务。条件变化时,结论应当重新验证。这正是聚类从演示代码走向可靠分析的分界线。
13
为了让一次 K-means 分群可复现、可审查,至少应记录哪些内容?