用访问模式设计纸舟书店的数据
前六节已经让纸舟书店拥有可查询、可更新的数据。第 6 节结束时,书店有 4 本正式书籍、4 位顾客和 5 张订单;MongoDB 书的库存是 22,还带有一条评价。现在先不急着继续增加功能,我们要回答一个更基础的问题:这些字段为什么放在这里,数据增长后这个形状还能不能工作?
课程继续以 MongoDB 8.0 为基线。MongoDB 的灵活模式不会替我们完成数据建模。它只是允许我们把经常一起读取、一起修改的数据放进同一文档,也允许模式分阶段演进。真正的设计依据仍然是访问模式、数据之间的所有权、增长上限和一致性要求。
本节不追求把所有实体都塞进一张“万能文档”。我们会用纸舟书店现有数据判断嵌入与引用,验证订单快照,拆解无界数组风险,选择金额类型,并给订单校验器增加一个可演进的版本字段。
确认建模起点
知识点
数据模型不是画在白板上的静态结构,它已经承载了业务状态。开始调整前,先确认核心文档数以及上一节产生的评价和库存,避免把错误起点误认为模型差异。
实操
进入 mongosh,切换到 bookstore:
shell
docker exec -it paperboat-mongo mongosh --quietjavascript
use bookstore
const mongoBook = db.books.findOne({ _id: "book-mongodb" });
print(EJSON.stringify({
counts: {
books: db.books.countDocuments({}),
customers: db.customers.countDocuments({}),
orders: db.orders.countDocuments({})
},
mongoBook: {
stock: mongoBook.stock,
reviewCount: mongoBook.reviews?.length ?? 0
}
}));结果展示
json
{"counts":{"books":4,"customers":4,"orders":5},"mongoBook":{"stock":22,"reviewCount":1}}这组结果说明课程状态连续:草稿已经删除,新顾客陈墨仍在,订单没有被前两节改动,MongoDB 书的评价数组有一个元素。下面的建模判断都从这个状态出发。
先写访问模式,再决定文档形状
知识点
从关系型数据库转到 MongoDB 时,一个常见动作是把每张表机械地改成一个集合。这样虽然也能存数据,却没有利用文档模型。更可靠的顺序是先写出业务真正执行的读写,再决定文档边界。
纸舟书店目前有几条高频访问模式:
这张表里没有“嵌入永远更快”或“引用永远更规范”的结论。嵌入减少读取时的组装,也让同一文档内的写入保持原子;引用减少重复和文档增长,但读取时可能需要第二次查询或 $lookup。设计要看哪一种代价更符合真实操作。
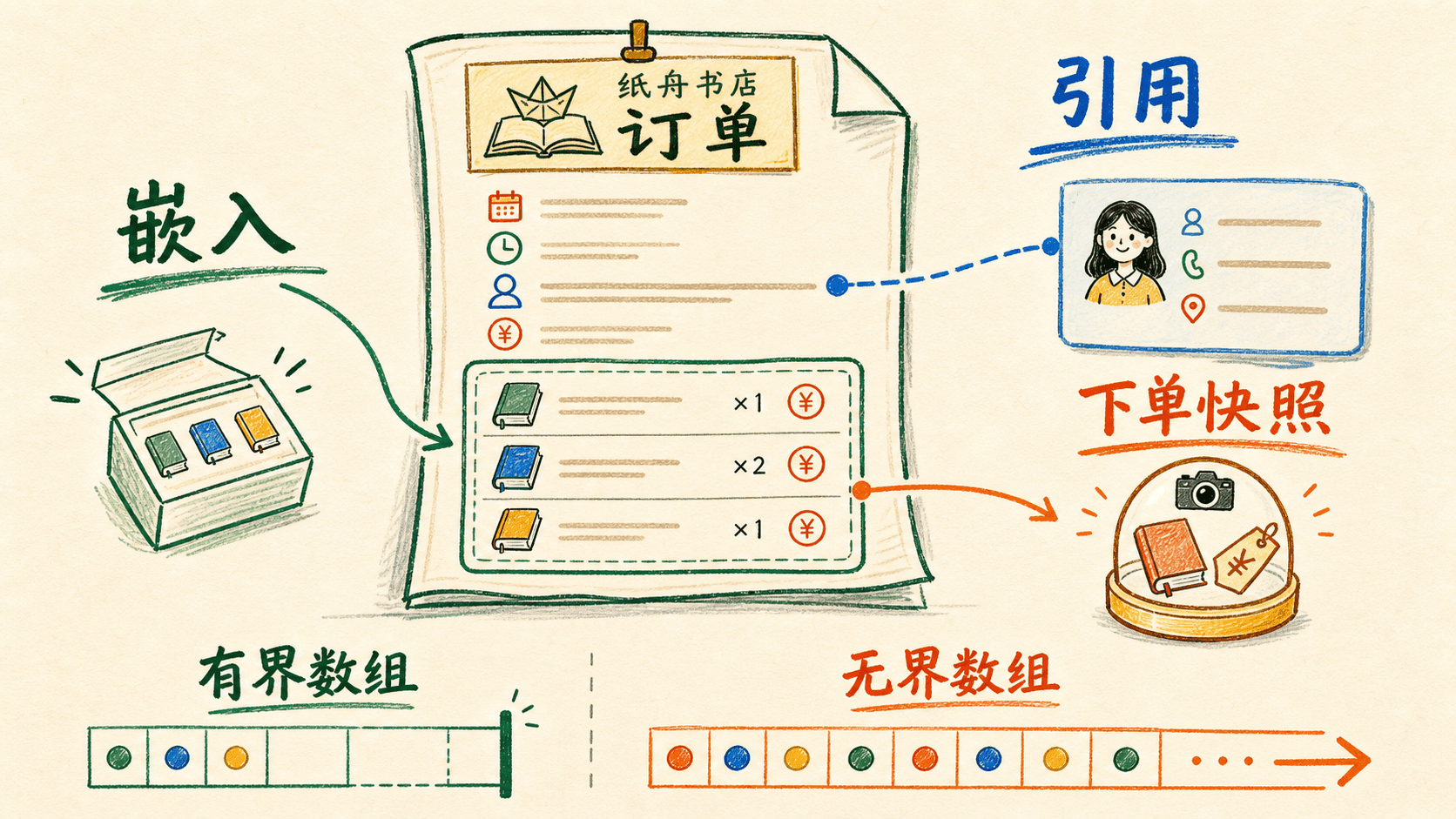
嵌入判断的四个问题
可以依次问四个问题:
- 子数据是否只属于一个父对象?
- 父子是否经常一起读取?
- 父子是否通常一起创建、归档或删除?
- 子数据的数量是否有清楚上限?
四个答案大多为“是”时,嵌入通常是好候选。地址属于一位顾客,订单明细属于一张订单,都符合这个方向。
引用判断的四个问题
如果子数据会被多个对象共享、需要独立查询和更新、数量持续增长,或者生命周期与父对象不同,就更适合独立成集合,再保存引用。书籍是独立实体,一本书会出现在多张订单里,因此订单保存 bookId,不会把整本书籍文档复制进每张订单。
“一起显示”不等于“一定嵌入”。商品页会显示评价,但评价会持续增加,也需要独立分页和审核。读取上的便利不能掩盖无界增长。
在现有文档中识别嵌入与引用
知识点
纸舟书店已经同时用了两种关系。customers.addresses 是嵌入数组;orders.customerId 和 orders.items.bookId 是引用。我们先把它们并排读出来,不靠抽象定义猜结构。
实操
javascript
const customerShape = db.customers.findOne(
{ _id: "customer-lin" },
{ _id: 1, name: 1, addresses: 1 }
);
const orderShape = db.orders.findOne(
{ _id: "order-1001" },
{
_id: 1,
customerId: 1,
"items.bookId": 1,
"items.title": 1
结果展示
json
{"customer":{"_id":"customer-lin","name":"林晓舟","addresses":[{"label":"默认","city":"上海","detail":"静安区纸舟路 8 号"}]},"order":{"_id":"order-1001","customerId":"customer-lin","items":[{"bookId":"book-mongodb","title":"MongoDB 从入门到实践",读取顾客时,地址已经随文档返回,不需要用地址 ID 再查一次。订单则只用 customerId 指向当前顾客;顾客改名或增加地址时,不必更新所有历史订单。
订单明细看起来有些特别:它既有 bookId,又复制了 title 和 unitPrice。这不是无意重复,而是下一部分要验证的历史快照。
用引用找到现在,用快照保存当时
知识点
订单创建后,要回答的是“顾客下单时买了什么、单价是多少”,而不是“这些书今天叫什么、今天卖多少钱”。如果订单只保存 bookId,每次展示历史订单都去读取当前书价,那么书籍调价会让旧订单看起来也变了。
纸舟书店把两类事实放在一起:
bookId是引用,用来找到当前书籍、处理售后或做跨集合分析。title和unitPrice是快照,记录成交时看到的商品信息。quantity与订单total也是订单事实,不能随着商品文档变化而重算后覆盖。
快照不是缓存。缓存失效后可以重新生成,历史成交事实不能根据今天的数据重建。
实操
用 order-1001 的明细快照重新核对一次总额:
javascript
const snapshotOrder = db.orders.findOne({ _id: "order-1001" });
const calculatedTotal = snapshotOrder.items.reduce(
(sum, item) => sum + item.unitPrice * item.quantity,
0
);
print(EJSON.stringify({
orderId: snapshotOrder._id,
storedTotal: snapshotOrder.total,
calculatedTotal,
lines: snapshotOrder.items.map((
结果展示
json
{"orderId":"order-1001","storedTotal":158,"calculatedTotal":158,"lines":[{"bookId":"book-mongodb","title":"MongoDB 从入门到实践","unitPrice":89,"quantity":1},{"bookId":"book-node","title":"Node.js 项目开发","unitPrice":69,"quantity":两条明细的快照金额相加是 158,与订单保存的 total 一致。以后任一本书调价,这三个历史值都不应被批量“同步”为新价格。
订单快照应只复制结算与展示所需的稳定字段,不要把库存、实时销量等不断变化的字段一起复制。复制得越多,字段含义越容易混乱。
识别无界数组
知识点
第 6 节为了讲解 $push,把一条评价放进了 book-mongodb.reviews。一条评价没有问题,真正的问题是这个数组有没有上限。
一本畅销书可能积累几十万条评价。继续把它们追加到同一书籍文档,会同时带来几类成本:
- BSON 文档最终会碰到 16 MiB 大小上限。
- 每次写评价都竞争同一本书籍文档,热门书会变成写入热点。
- 读取商品基础信息时,若投影不严谨,会把越来越大的数组一起传回。
- 给评价字段建立多键索引后,一本文档可能产生大量索引键,写入与存储成本继续增加。
因此“数量会持续增长”本身就是拆分信号。评价适合独立为 reviews 集合,每条评价保存 bookId,再为 { bookId: 1, createdAt: -1 } 建立分页所需索引。书籍文档可以保留有界摘要,例如评价数和平均分。
实操
先观察当前数组的实际形状与增长入口:
javascript
const reviewedBook = db.books.findOne(
{ _id: "book-mongodb" },
{ _id: 1, title: 1, reviews: 1 }
);
const firstReview = reviewedBook.reviews[0];
print(JSON.stringify({
bookId: reviewedBook._id,
reviewCount: reviewedBook.reviews.length,
firstReview: {
customerId: firstReview.customerId,
rating: firstReview.rating,
comment: firstReview.comment,
结果展示
json
{"bookId":"book-mongodb","reviewCount":1,"firstReview":{"customerId":"customer-zhou","rating":5,"comment":"结构清楚,示例可以直接跟做","createdAt":"2026-07-06T09:00:00.000Z"}}现在只有一条评价,正适合在数据变大之前确定边界。拆分后的目标形状可以写成下面这样。这是设计草图,不需要执行:
javascript
// books 中只留有界摘要
{
_id: "book-mongodb",
title: "MongoDB 从入门到实践",
reviewSummary: {
count: 1,
averageRating: 5
}
}
// reviews 中每条评价独立增长
{
_id: ObjectId("..."),
bookId: "book-mongodb",
customerId: "customer-zhou",
rating
摘要与评价分开后,新增评价会同时涉及评价文档和书籍摘要。若业务要求两者必须一起成功,后面可以用事务;若允许短暂延迟,也可以异步重算摘要。模型选择会直接影响一致性方案。
为金额选择明确类型
知识点
种子数据为了便于阅读,使用了 59、69、79、89 这样的整数价格。真实商品一旦出现 89.90 元,就不能随意用二进制浮点数保存并反复计算。JavaScript 中 0.1 + 0.2 的结果并不是精确的 0.3,税费、优惠和退款累计后会把细小误差带进对账。
常见的可靠方案有两种:
一旦选定方案,同一个金额字段就应保持同一种 BSON 类型和同一单位。不要让部分订单保存“元”,另一部分保存“分”,也不要让应用根据数值大小猜单位。
实操
下面不修改书店数据,只比较 JavaScript 浮点、Decimal128 与整数分的加法结果:
javascript
const moneyResult = db.books.aggregate([
{ $match: { _id: "book-mongodb" } },
{
$project: {
_id: 0,
decimalSum: {
$add: [
{ $literal: NumberDecimal("0.10") },
{ $literal: NumberDecimal("0.20") }
]
},
centsSum: {
$add: [
{ $literal: NumberLong("10") },
{ $literal: NumberLong
结果展示
json
{"jsFloat":0.30000000000000004,"decimalSum":"0.30","centsSum":"30"}Decimal128 保留了十进制结果 0.30,整数方案得到 30 分。纸舟书店若改用整数分,可以把字段明确命名为 unitPriceCents 和 totalCents;若使用 Decimal128,API 层也应约定字符串序列化方式,避免在返回 JSON 前丢失精度。
先读取现有校验器
知识点
MongoDB 常被称为“灵活模式”数据库,但灵活不等于没有模式。字段含义已经存在于应用、数据和查询中;集合校验器负责把关键规则放到服务端,让不同写入入口共享最低约束。
第 3 节为 orders 配置了第一版 JSON Schema。修改前先读取现状,确认我们是在已有规则上演进,而不是无意覆盖它。
实操
javascript
const orderInfo = db.getCollectionInfos({ name: "orders" })[0];
const currentSchema = orderInfo.options.validator.$jsonSchema;
print(EJSON.stringify({
required: currentSchema.required,
statusValues: currentSchema.properties.status.enum
}));结果展示
json
{"required":["customerId","status","items","total","createdAt"],"statusValues":["pending","paid","shipped","cancelled"]}现有校验器保护五类订单事实,并限制状态枚举。它没有验证 customerId 指向的顾客是否存在,也没有验证 total 是否等于每条明细之和。JSON Schema 擅长字段存在性、BSON 类型、枚举和数组形状;跨文档存在性与金额计算仍要由写入流程负责。
用扩展、迁移、收紧演进模式
知识点
直接把新字段加入 required,会让还没升级的写入程序立刻失败。一个更稳妥的模式演进通常分三步:
- 扩展。 校验器允许旧形状和新形状共存,新程序开始写新字段。
- 迁移。 分批回填旧文档,记录匹配数、修改数和失败样本。
- 收紧。 所有写入方都升级、旧数据也完成回填后,再把字段加入
required。
纸舟书店先给订单增加整数 schemaVersion。本节完成扩展与一次小规模回填,但暂时不把它设为必填,这样后续尚未升级的写入示例仍可工作。真实发布中,应在确认所有写入方都带版本后完成第三步。
实操
先回填 5 张现有订单,再用 collMod 更新集合校验器。新校验器保留原有规则,并规定:只要出现 schemaVersion,它就必须是大于等于 1 的整数。
javascript
const versionMigration = db.orders.updateMany(
{ schemaVersion: { $exists: false } },
{ $set: { schemaVersion: NumberInt(1) } }
);
const collModResult = db.runCommand({
collMod: "orders",
validator: {
$jsonSchema: {
bsonType: "object",
required: ["customerId", "status", "items", "total", "createdAt"
结果展示
第一次执行会得到:
json
{"matchedCount":5,"modifiedCount":5,"collModOk":1,"version1Count":5}5 张旧订单都完成了版本回填,collModOk: 1 表示校验器更新成功。若重复执行,迁移过滤器不再命中,两个更新计数会变成 0;这正是用“字段不存在”作为迁移条件的作用。
知识点
校验器是否真的生效,不能只看 collMod 返回成功。我们要写入一张其他字段都合规、但把 schemaVersion 错写成字符串的订单。服务端应拒绝它,并且集合中不能留下这张文档。
实操
javascript
db.orders.deleteOne({ _id: "order-schema-invalid" });
try {
db.orders.insertOne({
_id: "order-schema-invalid",
schemaVersion: "v1",
customerId: "customer-wang",
status: "paid",
items: [
{
bookId: "book-web",
title: "现代 Web 基础",
unitPrice: 59,
quantity: 1
}
],
结果展示
text
INVALID_SCHEMA_VERSION code=121
invalidCount=0错误码 121 表示文档校验失败。计数为 0,说明错误订单没有进入集合。这个验证比只展示一段校验器配置更有价值:它证明服务端正在执行我们刚写入的规则。
不要用 validationAction: "warn" 长期掩盖迁移失败。警告模式适合受控观察期,但如果没有告警采集、修复期限和收紧计划,错误形状仍会继续积累。
把模型决定写成可检查的步骤
知识点
每增加一种文档,可以按同一顺序做设计检查:
先列出高频读取、写入、排序和分页方式,并标明哪些操作必须原子完成。不要从字段清单直接跳到集合清单。
再判断所有权与生命周期。只属于一个父对象、经常一起读取且数量有界的数据优先考虑嵌入;共享、独立变化或持续增长的数据优先考虑引用。
区分当前实体与历史事实。引用用于找到当前对象,快照用于保存成交时的信息,两者可以在同一订单明细中共存。
为数量、日期和金额选择明确 BSON 类型,写进字段约定与校验器。类型选择必须能被所有应用驱动正确读写。
模型不是一次画完的。访问模式会变化,数据量也会暴露早期假设。真正稳定的是这套检查方法,而不是某个永远不改的嵌入层级。
检查你的理解
1
下列哪些数据适合从书籍文档中拆成独立集合?
2
为订单增加必填字段时,哪种发布顺序更稳妥?
纸舟书店的数据边界现在有了清楚理由:顾客地址和订单明细有界嵌入,书籍与顾客通过 ID 引用,订单用快照保存历史事实,无界评价应独立增长,金额需要明确类型,校验器则按阶段演进。下一节会把这些访问模式交给索引,并用 explain 直接测量数据库检查了多少文档和索引键。