用索引和 explain 量化查询成本
纸舟书店已经有了清楚的文档边界,但“能查到”与“数据增长后仍能稳定查到”是两件事。没有合适索引时,MongoDB 可能检查集合中的每一篇文档;有索引后,它可以沿着有序键值缩小范围。索引是否有效,不能凭命令执行得“感觉很快”判断,要看查询计划和实际扫描数。
课程继续以 MongoDB 8.0 为基线。这一节会把书籍集合临时扩充到 8,004 篇文档,对同一条查询分别记录 COLLSCAN 与 IXSCAN。目标查询始终返回 23 篇文档:没有复合索引时检查 8,004 篇,建立 { category: 1, price: 1 } 后只检查 23 个索引键和 23 篇文档。实验结束会删除 _id 以 sample- 开头的 8,000 篇性能样本,只保留纸舟书店的 4 本正式书籍和后续真正有用的索引。
本节关注的是访问路径,不是一次运行用了几毫秒。8,004 篇文档仍然很小,时间可能都显示为 0;扫描数与返回数的比例才是可以随数据增长推理的证据。
索引到底保存了什么
知识点
MongoDB 会为集合自动建立 _id_ 索引。它让按 _id 定位文档很高效,也保证 _id 唯一,但不会自动帮助按分类、价格或订单时间查询。
二级索引保存有序的字段键值以及回到文档的引用。以 { category: 1, price: 1 } 为例,索引先按 category 排序,在同一分类内再按 price 排序。查询先锁定“数据库”这一段,再沿价格范围读取,而不必从集合开头逐篇判断。
这份额外结构有明确成本:
- 建索引要读取已有数据并生成索引键。
- 插入、删除以及修改被索引字段时,MongoDB 还要维护索引。
- 索引占用磁盘,也会争用缓存。
- 数组字段会形成多键索引,一篇文档可能对应多个索引键。
所以索引不是“越多越快”。每条索引都应对应一条重要访问模式,并用 explain 验证。
准备一组可重复的性能数据
知识点
4 本书太少,即使全集合扫描也很难看出访问路径的差异。我们临时加入 8,000 篇带 sample- 前缀的书籍样本。每隔 100 篇设置一个“限量数据库”分类,价格用 30 + (index % 127) 生成。目标过滤器查找这个分类中价格大于等于 120 的样本,固定返回 23 篇。
样本 _id 使用固定前缀,既方便重复执行前清理,也避免误删核心书籍。开始前还会删除书籍集合中除 _id_ 外的旧索引,确保第一份计划确实没有候选二级索引。
实操
如果已经退出 mongosh,重新进入并切换数据库:
shell
docker exec -it paperboat-mongo mongosh --quietjavascript
use bookstore
db.books.deleteMany({ _id: /^sample-/ });
for (const index of db.books.getIndexes()) {
if (index.name !== "_id_") {
db.books.dropIndex(index.name);
}
}
const bulk = db.books.initializeUnorderedBulkOp();
for (let index = 0; index <
结果展示
json
{"insertedCount":8000,"totalBooks":8004,"targetMatches":23}8,000 篇样本已经写入,总数是 8,004。目标分类与核心图书的“数据库”分类不同,因此 23 篇结果全部来自可清理的性能样本。
记录没有二级索引时的计划
知识点
explain("executionStats") 会让 MongoDB 规划并执行查询,然后同时返回计划与执行统计。初学阶段先抓住五个字段:
COLLSCAN 表示集合扫描,IXSCAN 表示索引扫描。计划树外层可能还有 SORT、FETCH 等阶段,所以不能只读取最外层 stage。下面的辅助函数会递归检查整棵计划树。
实操
javascript
function collectStages(node, stages = []) {
if (!node || typeof node !== "object") return stages;
if (node.stage) stages.push(node.stage);
for (const value of Object.values(node)) {
collectStages(value, stages);
}
return stages;
}
const withoutIndex =
结果展示
json
{"stages":["COLLSCAN"],"nReturned":23,"totalKeysExamined":0,"totalDocsExamined":8004}MongoDB 返回 23 篇,却检查了全部 8,004 篇;平均每返回一篇,要判断 348 篇。totalKeysExamined 为 0,因为执行过程根本没有使用二级索引。
查询可能仍在极短时间内结束,这只说明当前数据量和硬件足以掩盖扫描成本。把集合扩大几百倍,扫描工作也会随之扩大。
为查询建立复合索引
知识点
目标查询先对 category 做等值匹配,再对 price 做范围限制。复合索引使用 { category: 1, price: 1 }:
- 等值字段
category放在前面,先把搜索范围缩到一个分类。 price放在后面,在该分类内部形成连续的价格区间。- 当
category固定时,同一索引顺序也为以后的price: 1排序保留了连续的价格键。
等值、排序与范围的顺序是设计复合索引的起点,不是替代 explain 的公式;排序字段与范围字段不同、查询选择性变化或数据分布偏斜时,仍要用真实查询验证。
实操
创建复合索引,再对完全相同的过滤执行 explain:
javascript
const compoundIndexName = db.books.createIndex(
{ category: 1, price: 1 },
{ name: "category_1_price_1" }
);
const withIndex = db.books
.find(targetFilter)
.explain("executionStats");
print(EJSON.stringify({
indexName: compoundIndexName,
stages: [
...new Set(
结果展示
json
{"indexName":"category_1_price_1","stages":["FETCH","IXSCAN"],"nReturned":23,"totalKeysExamined":23,"totalDocsExamined":23}查询仍然返回同样的 23 篇,但访问路径已经变成 IXSCAN。它检查 23 个索引键,再读取对应的 23 篇文档,扫描比从 348:1 降到 1:1。
这里仍有 totalDocsExamined: 23,因为查询最终要返回书籍文档中的字段。若过滤、排序和投影所需字段全部在索引中,并且投影排除不在索引中的 _id,某些查询可以成为覆盖查询,把文档读取降为 0;是否覆盖同样要以计划为准。
索引优化必须保持查询语义不变。前后两次 nReturned 都是 23,说明我们只改变了访问路径,没有为了得到更漂亮的扫描数而缩小结果。
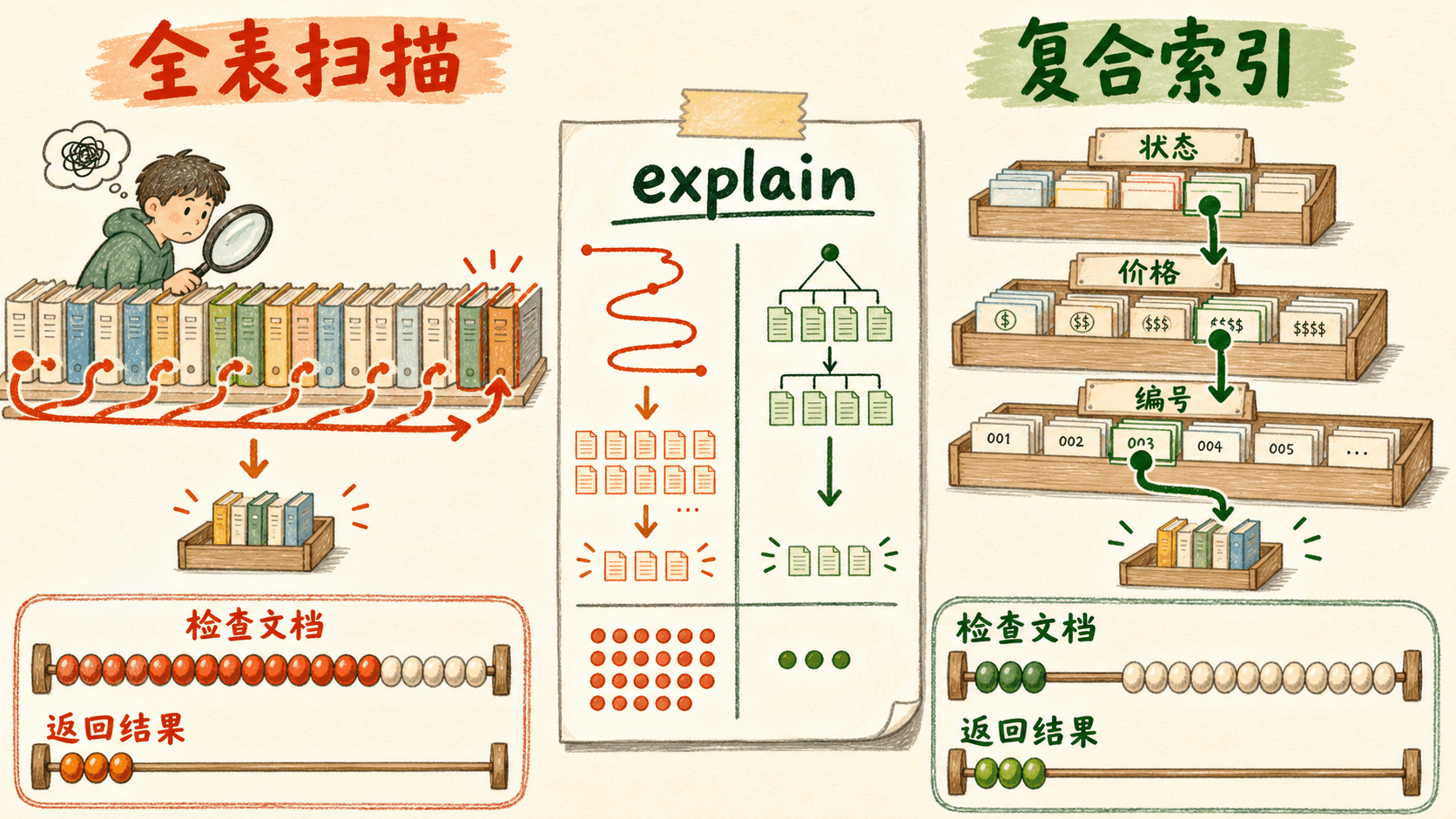
理解复合索引的字段顺序
知识点
复合索引有前缀规则。{ category: 1, price: 1 } 的可用前缀是 category,以及 category + price;它并不能像一条独立的 { price: 1 } 索引那样,直接从所有分类中定位价格区间。
字段顺序也不能简单理解成“选择性最高的字段永远放最前”。要同时考虑等值过滤、排序、范围、查询频率和返回规模。若纸舟书店另有一个不分分类的全站价格查询,它可能需要单独的 { price: 1 } 索引;先确认这条访问模式真的重要,再支付额外写入成本。
实操
读取实际索引定义,确认数据库中的字段顺序与设计一致:
javascript
const compoundDefinition = db.books.getIndexes().find(
(index) => index.name === "category_1_price_1"
);
print(EJSON.stringify({
name: compoundDefinition.name,
key: compoundDefinition.key
}));结果展示
json
{"name":"category_1_price_1","key":{"category":1,"price":1}}索引名称只是管理标签,真正决定顺序的是 key 文档。把键改写成 { price: 1, category: 1 } 会得到另一棵索引,不能因为包含相同字段就认为效果相同。
用唯一索引保护顾客邮箱
知识点
查询性能不是索引的唯一用途。顾客邮箱需要在所有文档之间保持唯一,只在应用中“先查再插”会留下并发窗口:两个请求可能同时查到不存在,然后都尝试写入。唯一索引让服务端在真正写入时保护约束。
创建唯一索引前必须先检查并清理已有重复值,否则索引构建会失败。纸舟书店当前 4 位顾客的邮箱互不重复,可以直接创建。
实操
javascript
const emailIndexName = db.customers.createIndex(
{ email: 1 },
{ name: "email_unique", unique: true }
);
db.customers.deleteOne({ _id: "customer-email-duplicate" });
try {
db.customers.insertOne({
_id: "customer-email-duplicate",
name: "重复邮箱演示",
email: "lin@example.com",
addresses: []
});
}
结果展示
text
DUPLICATE_EMAIL_REJECTED code=11000
{"indexName":"email_unique","duplicateCount":0,"customerCount":4}错误码 11000 表示重复键。演示文档没有进入集合,原来的 4 位顾客都还在。
单字段唯一索引还会处理字段缺失与 null。如果邮箱是可选字段,通常应把唯一约束和部分过滤结合,只索引确实拥有字符串邮箱的文档,而不是假设所有“缺少邮箱”的文档都互不冲突。
用部分索引只覆盖目标子集
知识点
纸舟书店的公开目录只查询 published: true 的书。草稿和性能样本不需要进入这条目录索引。部分索引通过 partialFilterExpression 只为满足条件的文档生成索引键,可以减少索引大小与无关写入维护。
查询只有在逻辑上包含部分过滤条件时,优化器才能安全使用这条索引。若查询没有 published: true,使用部分索引会漏掉未发布文档,MongoDB 不会把它当作完整答案。
实操
为已发布书籍建立价格索引,并读取它的定义:
javascript
const partialIndexName = db.books.createIndex(
{ price: 1 },
{
name: "published_price_partial",
partialFilterExpression: { published: true }
}
);
const partialDefinition = db.books.getIndexes().find(
(index) => index.name === partialIndexName
);
print(EJSON.stringify
结果展示
json
{"name":"published_price_partial","key":{"price":1},"partialFilterExpression":{"published":true}}这条索引只包含 4 本正式书籍,不包含 8,000 篇 published: false 的性能样本。它服务的是公开目录查询,不替代前面的分类与价格复合索引。
稀疏索引也会跳过部分缺失字段的文档,但表达力不如部分索引。需要“只索引已发布且价格存在”之类业务条件时,优先把条件明确写进 partialFilterExpression。
TTL 索引只管理可过期数据
知识点
TTL 索引用于自动清理到期数据,例如登录令牌、短期验证码或临时任务。它是单字段索引,目标字段应保存 BSON Date;expireAfterSeconds: 0 表示每篇文档的日期就是绝对过期时间。
TTL 删除由后台任务完成,不保证到期瞬间立即消失。因此权限判断仍要在读取令牌时检查 expiresAt,不能只依赖后台删除。订单、付款记录和审计事件也不应因为“时间很久了”就交给 TTL;这类数据的保留与删除需要明确业务和合规流程。
实操
我们只验证 TTL 定义,不等待后台删除。示例集合在读取索引后立即清理,不会进入后续章节:
javascript
db.ttl_index_demo.drop();
db.createCollection("ttl_index_demo");
const ttlIndexName = db.ttl_index_demo.createIndex(
{ expiresAt: 1 },
{
name: "expires_at_ttl",
expireAfterSeconds: 0
}
);
const ttlDefinition = db.ttl_index_demo.getIndexes().find(
(index) => index.name ===
结果展示
json
{"name":"expires_at_ttl","key":{"expiresAt":1},"expireAfterSeconds":0,"cleanup":true}索引配置正确,演示集合也已删除。真实令牌文档可以保存 expiresAt: ISODate("..."),应用在查询时仍应同时要求 expiresAt > new Date()。
文本索引只解决朴素全文匹配
知识点
MongoDB 文本索引能对字符串字段做词项搜索,适合需求明确、规模可控的简单全文匹配。它不是通用的中文搜索方案:分词、拼写纠错、同义词、相关性调优和高亮等需求一旦出现,就应评估 Atlas Search 或独立搜索系统。
一个集合只能有一条文本索引,但这条索引可以包含多个文本字段。文本索引也不是普通前缀索引,不能用来高效回答任意子串正则,更不能顺便替代价格排序索引。
实操
纸舟书店只在标题上建立一条演示文本索引,并把语言设为 none,避免套用英语词干规则。然后搜索明确存在的词项 MongoDB:
javascript
const textIndexName = db.books.createIndex(
{ title: "text" },
{
name: "title_text",
default_language: "none"
}
);
const textMatches = db.books
.find(
{ $text: { $search: "MongoDB" } },
{ _id: 0, title: 1 }
)
.toArray();
print(
结果展示
json
{"indexName":"title_text","titles":["MongoDB 从入门到实践"]}结果命中 MongoDB 书,说明这条朴素词项搜索可用。不要从一个英文技术词命中,就推断任意中文句子都能获得理想相关性;搜索质量必须用真实标题和真实查询词单独验收。
把写入成本算进索引设计
知识点
此刻 books 同时维护 _id_、分类价格复合索引、已发布价格部分索引和标题文本索引。插入或删除一篇性能样本时,MongoDB 至少要维护 _id_ 与分类价格索引;更新标题还会改文本索引,更新已发布书的价格会改复合索引和部分索引。
数组索引更容易放大成本。若给 tags 建索引,每个标签都会产生索引键;复合索引中再加入另一个数组字段,还会遇到并行数组限制。建立多键索引前,要观察单篇文档的数组长度上限,而不是只看集合文档数。
可以用下面四个问题审查候选索引:
- 它对应哪条高频或高风险查询?
- 过滤、排序和投影能利用哪些字段前缀?
- 扫描数、返回数和内存排序在
explain中如何变化? - 这条索引增加了多少写入、存储与缓存成本?
本节的部分索引和文本索引用于理解专用能力,后续项目主线暂时不需要它们。我们会删除这两条索引和所有性能样本,保留已经量化有效的分类价格索引,以及保护邮箱约束的唯一索引。
实操
javascript
const deletedPerformanceBooks = db.books.deleteMany({
_id: /^sample-/
});
for (const name of ["published_price_partial", "title_text"]) {
if (db.books.getIndexes().some((index) => index.name === name)) {
db.books.dropIndex(name);
}
}
print
结果展示
json
{"deletedPerformanceBooks":8000,"remainingBooks":4,"bookIndexes":["_id_","category_1_price_1"],"customerIndexes":["_id_","email_unique"]}8,000 篇性能样本已经删除,书籍集合恢复为 4 篇核心文档。书籍保留分类价格复合索引,顾客保留邮箱唯一索引,TTL 演示集合、部分索引和文本索引都没有残留。
建立一条可重复的索引工作流
知识点
面对一条新查询,可以按下面的顺序工作:
写出完整查询形状,包括等值过滤、范围过滤、排序、投影和分页方式。只记录字段名,不记录操作符与顺序,无法设计可靠的复合索引。
在接近真实分布的数据上运行 explain("executionStats"),记录 nReturned、totalDocsExamined、totalKeysExamined、计划阶段和是否出现内存排序。
根据等值、排序和范围设计最小候选索引,检查前缀能服务哪些其他重要查询,也检查它不能服务什么。
hint() 可以用于诊断候选索引,但不应成为掩盖错误索引设计的永久补丁。数据分布和版本升级后,强制计划可能阻止优化器选择更好的路径;只有经过持续验证的特殊场景才适合长期提示。
检查你的理解
1
查询返回 23 篇文档,却检查了 8,004 篇文档。最直接的诊断证据是什么?
2
下列哪些索引选择符合纸舟书店当前需求?
纸舟书店已经把一条真实查询从 COLLSCAN 的 8,004 篇检查,收窄到 IXSCAN 的 23 个键和 23 篇文档,并留下了可复用的复合索引。索引解决“怎样更少地找到目标文档”;下一节会进入聚合管道,继续解决“找到之后,怎样把订单明细展开、分组并计算销量与收入”。