文本生成:从概率分布到可上线的解码系统
让模型写一句话,看起来只是不断“猜下一个词”。真正把它做成稳定的产品,却要同时回答四个问题:模型认为哪些词可能出现,解码器怎样在候选中取舍,系统何时停止,以及结果到底算不算好。
这四个问题不能混在一起。模型概率高,不代表事实正确;束搜索找到更高分的序列,不代表故事更好看;调高温度得到更多版本,也不代表多样性一定有价值。我们会从一个可计算的小例子开始,逐步搭起搜索、采样、约束、评估和线上诊断的完整链路。
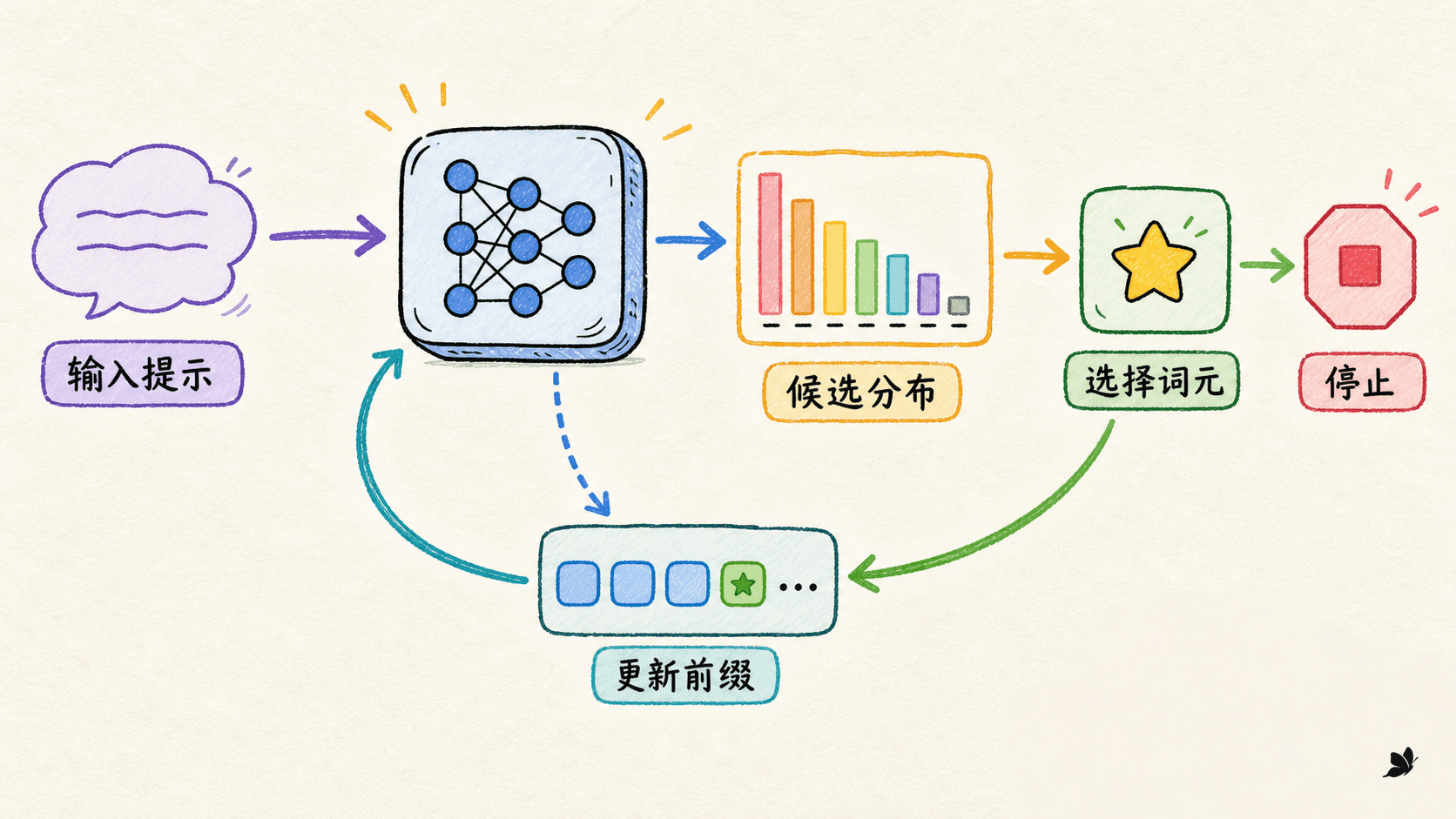
生成是一个带停止条件的序列决策
从链式概率开始
给定输入 ,一个从左到右生成的模型把输出 的条件概率拆成每一步的条件概率:
为了避免很多小概率相乘造成数值下溢,实现时通常累加对数概率:
这里有一个容易忽略的区别:模型只负责给“下一 token”打分,解码器才负责选择。相同的 logits 交给贪婪、束搜索或采样,会得到完全不同的文本。换句话说,生成结果是“模型 + 解码算法 + 约束 + 随机种子”的共同产物。
模型通常先输出词表上的 logits ,再经 softmax 得到概率:
logits 的差值决定概率比。例如两个候选的 logits 相差 2,它们未归一化权重的比值就是 。因此,后面讲的温度、重复惩罚和禁用词,实质上都是在“选择发生前”改写这组分数。
EOS 不是唯一的结束方式
一次生成至少应定义以下停止条件:
- 生成结束 token(EOS);
- 命中一个或一组停止字符串;
- 达到最大新增 token 数;
- 达到时间预算或计算预算;
- 结构化输出完成,例如 JSON 括号闭合且通过校验。
最大长度是保险丝,不是理想的结束语义。如果大量请求都靠最大长度强行截断,常见原因包括 EOS 概率过低、提示没有说明输出边界、停止字符串与分词结果不一致,或模型进入重复循环。线上应分别记录 finish_reason=eos、stop_sequence、length 和 timeout,否则你只会看到“平均输出长度变长”,却不知道生成为什么没停。
最小长度也要谨慎。摘要系统可以在前几步屏蔽 EOS,避免只生成标题式短句;问答系统如果把最小长度设得太大,模型会在答案已经结束后继续补话。停止条件应该表达任务需要,而不是用一个统一数字覆盖所有场景。
自回归模型每一步都以已经生成的前缀为条件。早期选择不仅占据一个位置,还会改变后续每一步的概率分布,因此“第一个词只差一点”可能在十步后变成完全不同的文本。
1
同一组模型 logits 为什么可能生成不同文本?
2
哪些现象说明停止条件值得单独排查?
贪婪与束搜索:是在找高分,不是在判断好坏
贪婪解码的速度与短视
贪婪解码每一步选概率最大的 token:
它只保留一个前缀,速度快、结果确定,适合低延迟且答案空间较窄的任务。问题是当前最优不保证整段最优。假设第一步“模型”的概率是 0.52,“系统”的概率是 0.48;“模型”后面最好的完整路径概率可能只有 ,而“系统”后面出现一个概率 0.90 的自然续写。贪婪在第一步已经删掉了后者,后面没有补救机会。
另一个风险是吸引子:某个高频短语一旦出现,又让自身在下一步变得更可能,于是“需要改进,需要改进……”不断循环。贪婪没有探索分支,最容易被这种局部模式锁住。
束搜索保留多个活跃前缀
束宽为 时,每一步先扩展当前 个前缀,再从所有扩展结果中保留累计分数最高的 个。束宽 1 就退化为贪婪。束搜索不是穷举,它会永久剪掉落在束外的前缀,所以仍然是近似搜索。
若词表大小为 、最多生成 步,朴素候选层面要比较约 个扩展分数;实际延迟还受模型前向、KV 缓存重排、并行批处理和 top-k 内核影响。因此“束宽翻倍,延迟一定恰好翻倍”也不成立,但显存中的活跃状态和候选处理量通常都会增加。
直接累加对数概率会偏爱短序列,因为每增加一个 token 通常都会加上一个负数。常见做法是用长度函数归一化:
其中可以取 ,也可以使用带平移项的版本。 不是“越大越好”的质量旋钮:它只改变长短候选的相对排序,合适值取决于参考长度、任务与模型。还要决定已经产生 EOS 的候选是立即进入完成集,还是继续和未完成候选竞争。
机器翻译、受源文约束的摘要和语音识别通常有较明确的目标,束搜索有机会用后续证据修正早期选择。开放式故事、对话或头脑风暴存在许多同样合理的续写,最高概率路径常常过于通用,扩大束宽甚至可能让输出更平淡、更重复。
看候选轨迹,而不只看最终文本
调试束搜索时,建议每一步保留以下记录:前缀、原始累计对数概率、长度归一化分数、是否完成、父节点和被剪枝原因。只看最终答案,你无法判断是模型从未给好词足够概率,还是好路径曾经出现但被束宽、长度惩罚或提前停止剪掉。
3
把束宽从 4 增加到 16,哪项结论最可靠?
4
长度惩罚的作用是直接提高文本事实正确率。
采样:先塑造分布,再掷骰子
温度改变相对差距
温度采样把 logits 除以正数 后再做 softmax:
会放大 logits 差距,让分布更尖; 会缩小差距,让分布更平。温度不改变候选的排序,只改变概率差距。 接近 0 时,采样逐渐接近贪婪;温度过高时,原本不可靠的长尾 token 也会获得可见概率。
熵可以帮助观察分布有多分散:
但“熵更高”不等于“内容更好”。它只说明下一步的不确定性更大。创意任务可能需要一定探索,事实抽取和格式转换通常更希望分布集中。
Top-k 与 top-p 解决不同问题
Top-k 每一步只保留概率最高的 个 token,再归一化采样。它的候选数固定,容易理解,也容易出现两种不适配:模型很确定时仍保留 个长尾词;模型很犹豫时又只允许 个选择。
Top-p(nucleus sampling)先把 token 按概率排成 ,再找到累计概率达到阈值 的最短前缀:
实现时必须保留“第一个让累计概率越过 的 token”,否则保留集合的概率质量会小于阈值。模型确定时集合自然变小,模型不确定时集合会扩大,这是 top-p 相对固定 top-k 的核心差异。
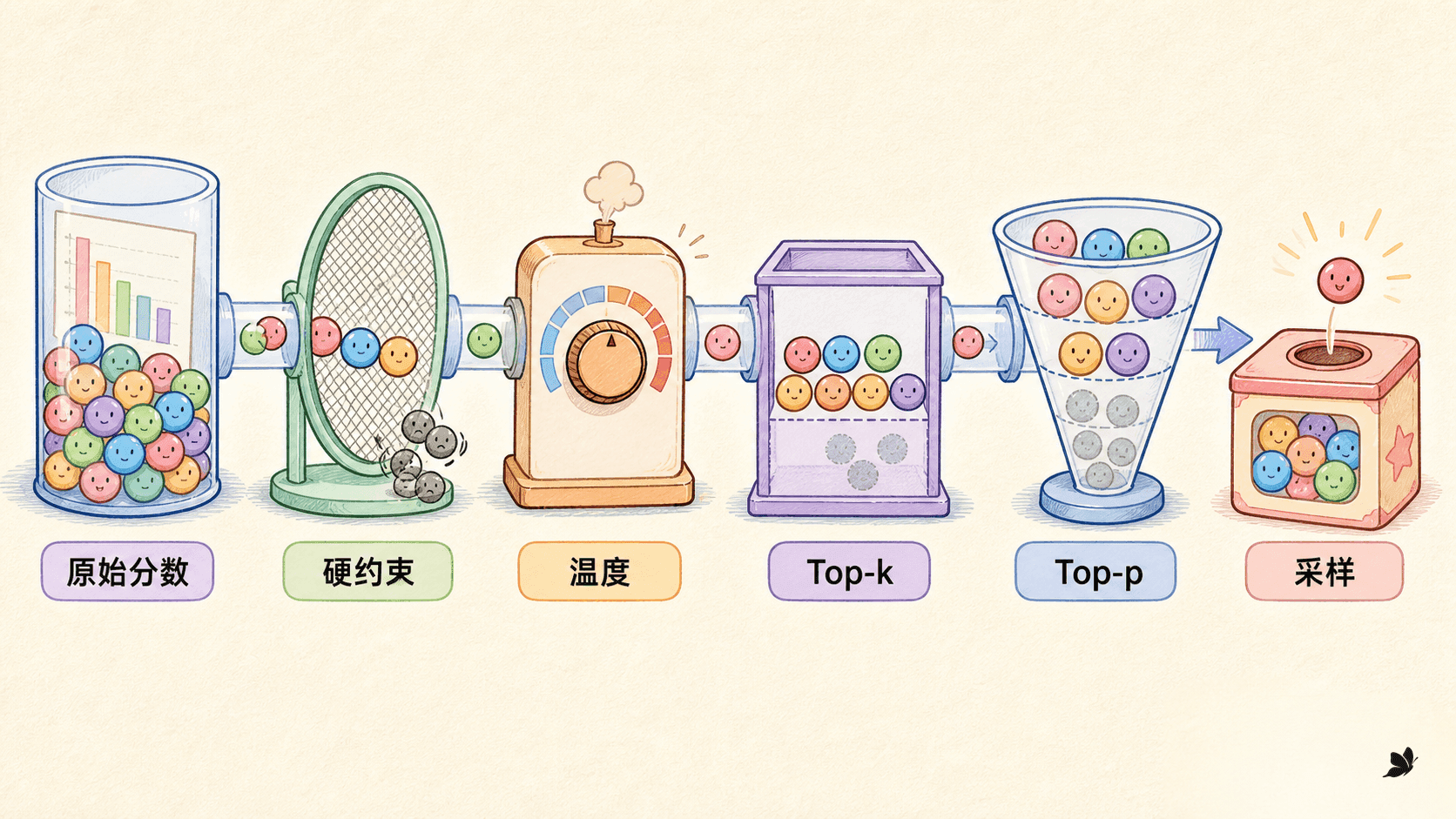
组合顺序必须明确
一个可审计的推理管线可以这样定义:
先根据格式、禁词、最小长度和重复规则处理硬约束,并对需要惩罚的 token 调整 logits。
再应用 temperature,改变剩余候选的相对概率差距。
随后执行 top-k,把候选数限制在上界内。
在 top-k 的剩余候选上执行 top-p,保留达到概率质量阈值的最小集合。
这里的顺序是一种明确约定,不是数学上唯一合法的顺序。若先 top-p 再 top-k,最终集合可能不同;先截断再调温度,也会让累计概率阈值表达另一件事。不同库版本还可能把 processor 和 warper 分开组织。线上不要只保存 top_p=0.9,还要保存处理器顺序与运行版本。
5
关于 temperature 与 top-p,哪些说法正确?
6
Top-p 应保留第一个使累计概率 ____ 阈值 p 的 token。
长度、重复和禁用 token:约束要能解释副作用
硬约束与软惩罚
常见约束可以分成两类:
- 硬约束:把不允许的 token 或序列分数设为负无穷,例如禁用词、最小长度前屏蔽 EOS、JSON 语法状态机、禁止重复 n-gram。
- 软惩罚:降低某些 token 的相对分数,但仍允许它们出现,例如重复惩罚、长度惩罚、主题偏置。
硬约束容易验证,却可能把合法答案彻底删除。软惩罚保留退路,却需要阈值校准。敏感场景不能只靠禁词表:分词可能把一个词拆成多段,拼写变体和上下文含义也会绕过简单匹配。更可靠的做法是输入审核、生成约束、输出分类与人工升级共同工作。
重复惩罚不是“去重按钮”
no_repeat_ngram_size=n 会禁止已经出现过的 n-gram 再出现。它对“重复 重复 重复”很有效,但也会误伤合理复现:人名、法律术语、代码变量、诗歌叠词以及摘要中必须再次提及的实体都可能被阻断。
工程中常见的 repetition penalty 会对已经出现的 token 改写 logits。某些实现对正 logits 做除法、对负 logits 做乘法,使其概率下降。它以 token 为单位,不理解“这个重复是强调还是退化”,而中文子词、标点和提示中的 token 也可能被一起处罚。惩罚过强时,模型会为了避开已有 token 而改写专有名词,甚至破坏语法。
可以同时监控不同粒度的重复率:
词级、短语级和句子级重复的原因可能不同。若所有请求都重复同一句开场白,问题可能在模板或训练分布;若单条长文本后半段循环,才更像解码吸引子或停止失败。
长度与禁词也会相互作用
最小长度屏蔽 EOS 后,如果 top-k 很小,原本排第二的低质量 token 可能被迫成为唯一选择。禁词处理放在 top-p 之后,又可能让剩余概率和变成 0。稳妥实现应在每一步检查:是否至少有一个有限分数,约束冲突时采用什么回退,完成原因是什么。
任何约束都要配一个反例集。测试中应包含必须重复的品牌名、含否定词的安全说明、短答案、长结构化输出和多 token 禁词,确认规则没有为了消灭一种退化而制造另一种错误。

7
把 no-repeat 设得足够严格,就能在所有任务中提高质量。
8
禁用 token 后所有候选都变成负无穷,系统最该做什么?
训练与推理的错位:不要把所有问题都推给解码器
Teacher forcing 与暴露偏差
最大似然训练通常在预测 时喂入真实前缀 ,这叫 teacher forcing。推理时没有真实答案,模型只能读取自己生成的 。一次早期错误会把模型带到训练数据里较少见的前缀,后续错误便可能累积,这种分布错位常被称为暴露偏差。
对应的 token 级负对数似然是:
但要把因果说清楚:teacher forcing 让序列似然能够高效、稳定地训练,并不天然“错误”。生成退化还可能来自模型容量、数据偏差、目标函数与人类偏好不一致、解码近似或提示缺少约束。看到重复就直接改训练方式,往往太早。
Scheduled sampling 有直觉,也有争议
Scheduled sampling 在训练时按一定概率把真实前一 token 换成模型预测,并随训练推进增加替换比例。直觉是让模型提前接触自己的错误前缀。然而,模型预测是由当前参数产生的,混合分布和目标会不断变化;理论分析指出,这种训练目标可能不是一个一致的概率估计目标。
所以更准确的结论是:它在部分序列任务上可能是有用的课程学习技巧,但不是“暴露偏差已解决”的通用方案。采用时应和纯最大似然、噪声前缀训练、序列级目标等基线比较,并同时看校准、长序列稳定性和任务指标。
Unlikelihood 从训练层面降低坏候选概率
如果已经能定义负候选集合 ,例如会构成不合理重复的 token,可以在似然损失外加入 unlikelihood 项:
它不是在推理时临时挡住某个 token,而是训练模型给负候选更低概率。优势是贪婪或束搜索也可能得到更少退化的分布;风险是 的定义带着人的假设。若“出现过的词”全部算负候选,模型同样会忘记合理重复。对矛盾、有害内容等语义错误,负样本质量比公式本身更重要。
实践中可以把问题分层处理:格式和法规禁项用硬约束;局部重复先尝试可逆的解码策略;稳定且可定义的退化模式再考虑 unlikelihood 或专门数据;事实错误则要加入来源约束和核验,不能期待重复损失顺便解决。
9
Scheduled sampling 最准确的定位是什么?
10
设计 unlikelihood 负候选集合时应检查哪些风险?
评估生成文本:每个指标只照亮一个侧面
BLEU:修正精确率与短句惩罚
BLEU 计算候选与一个或多个参考之间的 n-gram 重合。它对候选 n-gram 做裁剪计数,避免模型靠重复同一个命中词刷分。设 为修正后的 n-gram 精确率,语料级 BLEU 为:
短句惩罚为:
其中 是候选总长度, 是对应参考长度。BLEU 最初服务于语料级机器翻译系统比较;在单句上,高阶 n-gram 很容易为零,分词、大小写、平滑和参考数量都会强烈影响结果。报告分数时应同时报告实现和配置。
ROUGE、BERTScore 与 MAUVE 看的是不同对象
ROUGE-N 更偏向参考侧召回:参考摘要中的信息单元有多少被候选覆盖。ROUGE-L 使用最长公共子序列,能够容纳一部分非连续匹配。它们适合观察摘要覆盖,却仍然依赖表面重合;候选把“增长”改成“下降”,可能保留大量相同词而改变事实。
BERTScore 用上下文嵌入计算候选 token 与参考 token 的软匹配,能给同义改写更合理的相似度。它仍不是事实核验器:两个句子语义表面接近,但数字、实体关系或否定方向不同,得分可能仍然较高;结果也依赖底层编码器和基线校正。
MAUVE 比较一批机器文本与一批人类文本在表征空间中的分布差异,尝试同时观察质量与覆盖。它适合开放式生成的集合级分析,不适合给一条回答判对错;样本数量、文本长度、嵌入模型和量化设置都会影响结果。
一次可复核的手算
参考是“模型 可以 生成 流畅 文本”,候选是“模型 生成 流畅 文本”。按空格切分后:
- 候选 4 个 unigram 都在参考中,;
- 候选 3 个 bigram 中,“生成 流畅”“流畅 文本”命中,;
- 候选长度 4,参考长度 5,;
这个例子说明 BLEU 的 brevity penalty 会惩罚删词,而 ROUGE 召回直接反映“可以”没有被覆盖。但这两个数都不能判断删掉“可以”是否改变了真实含义,还要回到任务和来源。
人工评估也要像实验
人工评价不应只问“你觉得好吗”。先定义维度:有来源的任务看事实一致性和信息覆盖;对话看相关性、具体性与连贯性;创作看可读性、风格符合度与新颖性;所有线上任务都要看安全和任务完成率。
更稳妥的流程是随机化样本顺序、隐藏系统身份、给评审正反例、使用清楚的量表、记录评审背景,并报告一致性与分歧处理。成对比较常比孤立的 1–5 分更容易校准。领域事实应由领域评审或可核验来源判断,不能因为普通评审觉得“读起来像真的”就算正确。

11
哪些指标或流程能直接单独证明一段摘要事实无误?
12
为什么不应拿单句 BLEU 当最终质量裁判?
事实、安全、多样性与可控生成要分开治理
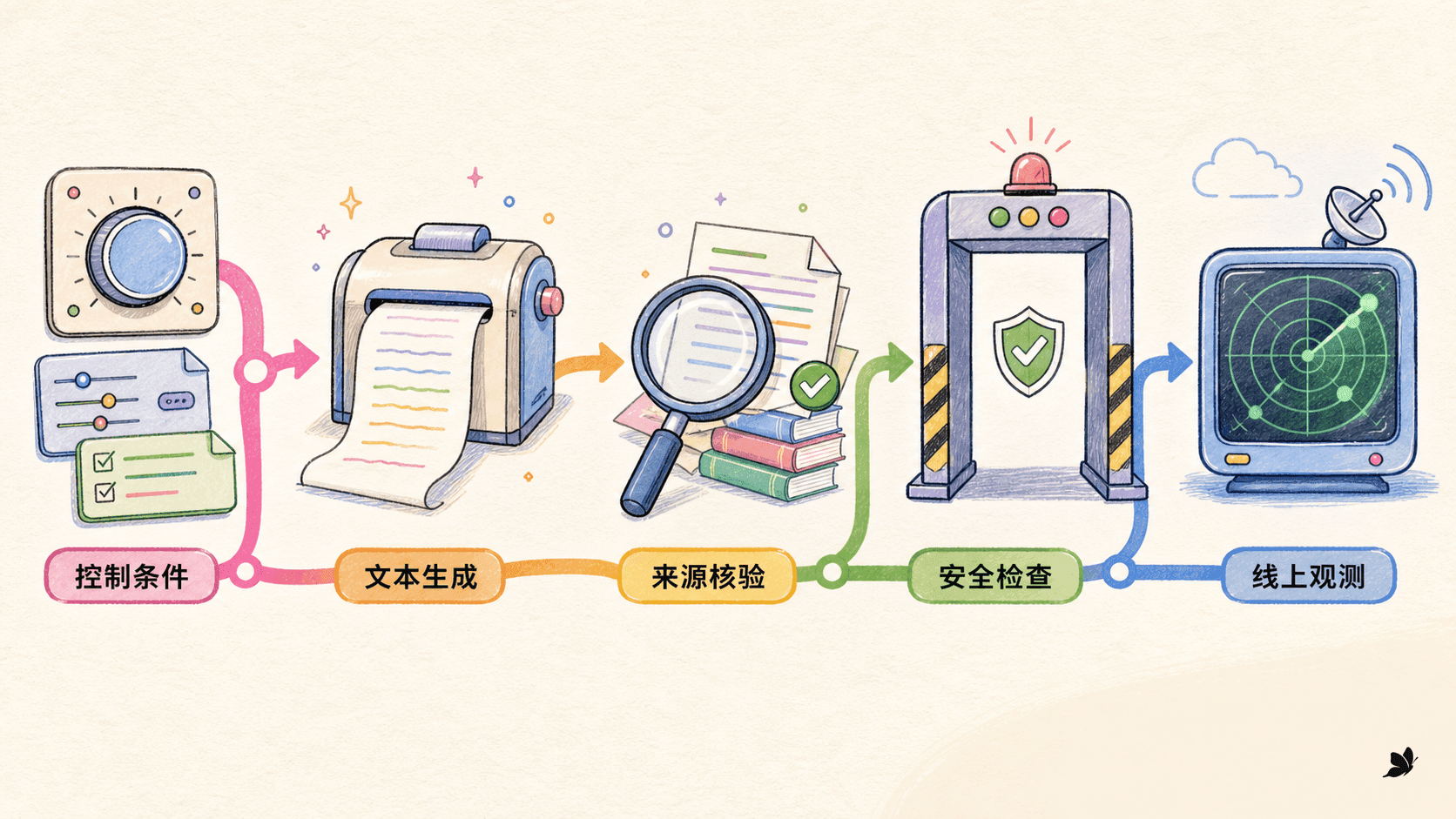
事实性不能从流畅度推出
自回归模型优化的是条件 token 概率,不是外部世界中的真值。一个句子可以语法自然、概率很高,却把年份、主体或因果关系写错。对检索问答、数据报告和摘要,可以建立一条更明确的事实链:先确定允许使用的来源,再生成带来源映射的原子陈述,随后检查实体、数值、时间、否定和关系,无法支持的内容删除、重试或转人工。
困惑度、BLEU、ROUGE 和 BERTScore 都可以作为观测,但事实一致率、无依据陈述率和引用可追溯率必须单独统计。安全也一样:有害、隐私、偏见和越权操作需要独立规则、分类器、红队样本与处置流程。
多样性是覆盖合理答案,不是制造噪声
可以用 distinct-n、self-BLEU、唯一序列数或分布指标观察多样性,但要同时看质量。如果把温度调得很高,唯一序列数会上升,胡言乱语也会增加。更有意义的目标是在事实与任务约束内覆盖不同表达、观点或方案,并报告“合格样本中的多样性”。
我们在固定 logits 的小模型上做了 50 个随机种子的可复现实验。温度从 0.7 提到 1.3 时,唯一序列从 20 增至 35,平均一步熵从 0.7124 增至 1.2348;这只证明分布更分散。Top-p=0.75 时平均候选约 2.03 个,组合 temperature=0.9 → top-k=4 → top-p=0.85 时约 2.20 个。参数含义只有连同候选集与实际文本一起看才完整。
三类控制路径
可控生成大致有三种入口:
- 输入与训练时条件:用明确指令、结构字段或控制码表达风格、领域、受众。CTRL 展示了训练时控制码的路线。它高效直接,但只能学到训练分布中可识别的属性。
- 推理时引导:PPLM 一类方法借助属性模型的梯度扰动生成状态,不必重训主模型。控制更灵活,代价是推理更慢,控制过强还可能破坏流畅性。
- 约束解码与后处理:关键词、语法状态机、禁用序列、候选重排或事实验证器。它容易接入现有系统,但后处理只能在候选里选择,无法凭空补回模型没提出的好答案。
现代系统还常用条件微调、偏好优化和检索增强。无论用哪种方式,都应分别测控制成功率、内容质量、事实性和副作用。一个“语气很专业”的回答可能更容易让错误显得可信,所以风格控制成功并不代表风险下降。
13
只要 BERTScore 很高,就可以省略事实来源核验。
14
评价可控生成时应同时观察哪些方面?
从一次实操到线上错误诊断
固定 logits,才能看清解码器做了什么
为了把模型差异排除,我们用一个固定状态表模拟小语言模型:每个前缀对应一组确定 logits;词表包含“模型、会、重复、创新、表达、结束、EOS”。实现了贪婪、beam=3、temperature、top-k、top-p、组合过滤和 2-gram 阻塞,并固定 0–49 共 50 个采样种子。
贪婪输出为:
text
模型 会 重复 重复 重复 重复 重复 重复它在长度上限仍未产生 EOS,bigram 重复率为 0.5714。加入 2-gram 阻塞后得到“模型 会 重复 重复 结束”,重复率降到 0,随后产生 EOS。这说明硬约束确实能切断循环;它没有证明同一规则适合人名、术语或诗歌。
beam=3 在不做长度归一化和 时都选中“创新 表达 结束”,但候选归一化分数发生了变化。这个结果也很重要:一个超参数改变评分公式,不代表每个测试输入都会改变最终文本。测试应记录候选轨迹,而不是为了展示效果专挑会翻转答案的例子。
核心过滤逻辑可以写成下面这样:
python
def decode_step(logits, temperature, top_k, top_p):
scores = logits / temperature
# 先限制候选上界
keep = scores.argsort(descending=True)[:top_k]
masked = scores.new_full(scores.shape, float("-inf"))
masked[keep] = scores[keep]
# 再在剩余候选上保留达到 top-p 的最小集合
probs = masked.softmax(dim=-1)
sorted_p, sorted_i = probs.sort(descending=
真实服务还要加边界检查:temperature 必须大于 0,top-k 不得超过词表,top-p 在 内,约束后概率和不能为 0,并把种子、处理顺序和完成原因写入追踪记录。
一张故障到证据的对照表
线上最小观测面
每次请求至少记录模型与解码配置版本、输入长度、输出长度、完成原因、延迟、随机种子、每步或抽样步骤的熵、截断后候选数、被触发的约束、重复率、事实/安全检测结果。为了控制成本,可以只对异常请求保存完整 top-N 轨迹,但聚合指标要能按任务、语言、长度和用户场景分层。
上线流程可以按“离线反例集 → 小流量影子测试 → A/B 或交错比较 → 持续漂移监控”推进。自动指标用于高频报警,人工与任务结果用于定期校准。最重要的一条是保留可回放性:同一模型版本、输入、种子和处理器顺序应能重现候选变化,否则一次线上坏例只能变成猜测。
15
线上大量输出都因长度上限结束,第一步最合理的排查是什么?
16
为了让一次坏例可以回放,至少应保存哪些信息?