Transformer、自注意力与生成模型
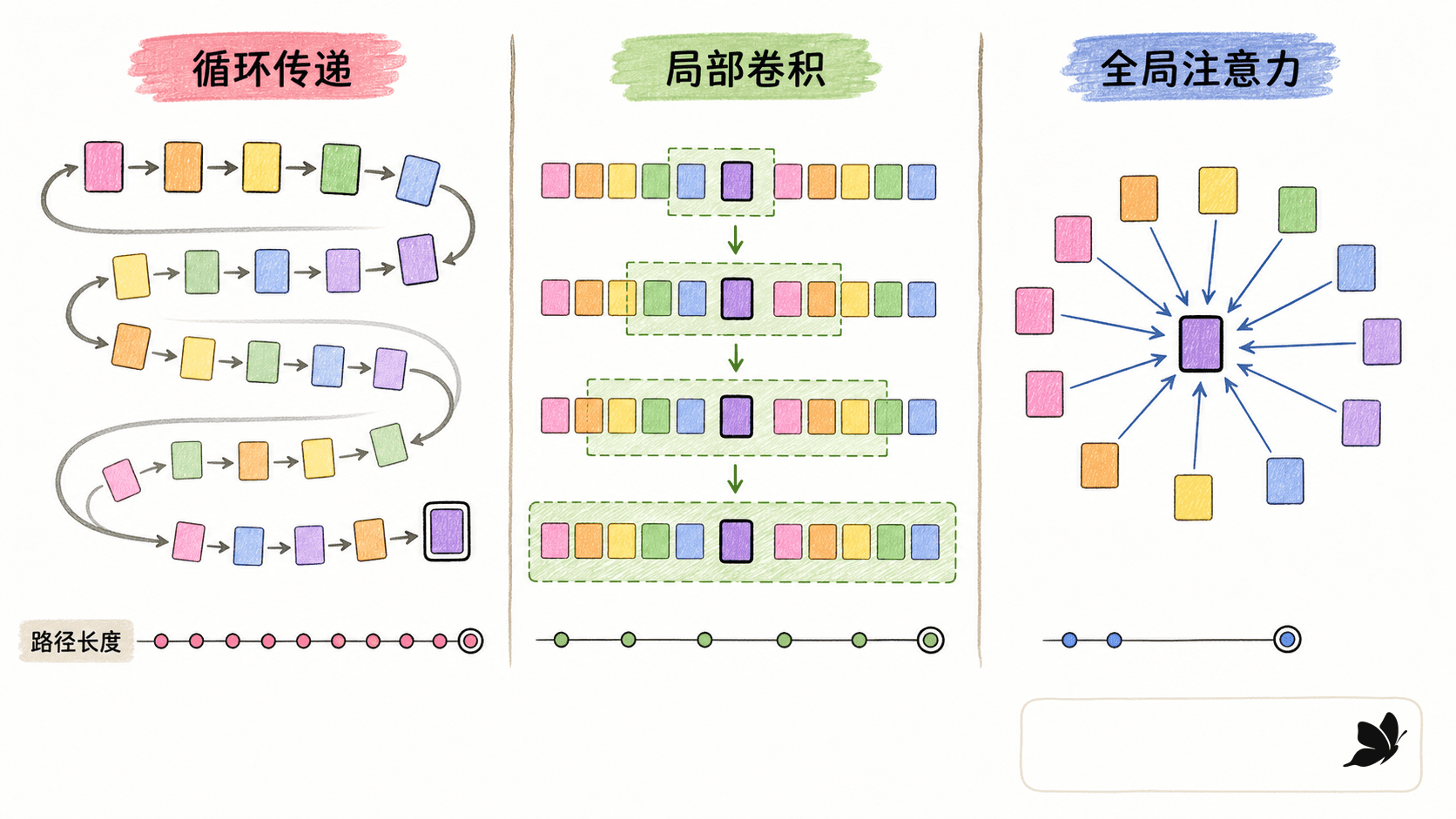
当一句话很长时,真正麻烦的并不是“模型能不能看见前面的词”,而是信息要经过多少步才能抵达当前位置、训练能不能同时处理所有位置、推理时又会不会重复计算。循环网络把序列顺序直接写进计算图,直觉清楚,却让第 个状态依赖第 个状态;卷积可以并行,但较远位置要经过多层才能交换信息。
Transformer 换了一条路线:先让每个位置按内容选择要从哪些位置读取信息,再用位置编码补回顺序,用前馈网络处理每个位置的特征,最后靠残差连接和归一化把许多层稳定地叠起来。它没有消灭序列问题,只是把“逐步传递状态”改成了“显式计算位置之间的路由权重”。
本章会从张量形状出发,把 Q、K、V、缩放点积、多头、两类掩码和完整模块逐项对齐;再比较编码器—解码器、仅编码器和仅解码器三种信息流,解释为什么训练可以并行而自回归生成仍要逐步进行。最后我们会真实核对掩码、归一化、梯度和因果性,并把 KV cache、长上下文与 FlashAttention 放回准确的复杂度边界中。
先看 Transformer 改写了哪条信息通路
从顺序状态到任意位置直接通信
设输入序列有 个 token,每个位置的表示维度是 。循环网络通常按下面的关系更新:
这个式子把顺序先验写得很明确,但也意味着同一个样本内部存在 个依次执行的时间步。位置 1 的信息若要影响位置 ,至少要沿着状态链走过 次更新。门控可以改善信息保留和梯度传播,却不能取消这种计算依赖。
一维卷积把一个局部窗口同时应用到所有位置,所以同一层内更容易并行。代价是感受野从局部开始:若卷积核宽度有限,两个相距很远的位置需要靠加深网络或扩大卷积范围才能相遇。
自注意力让位置 在一层内直接为所有候选位置 计算权重,再读取它们携带的值:
只看图上的信息路径,任意两个位置可以在一个注意力子层内建立连接。这个“路径短”不等于模型一定会学会正确的远距离关系,也不等于长文本成本消失了。稠密注意力要构造 的关系,长度翻倍时,关系数约变成四倍。
训练并行与推理并行不是一回事
已知整条训练序列时,我们可以一次生成每个位置的 Q、K、V,再并行完成矩阵乘法。对于从左到右的语言模型,只需用因果掩码挡住未来位置,就能同时计算所有位置的训练损失。
推理时情况不同。第 个 token 还不存在,必须先根据前缀生成第 个 token,再把它接回输入。矩阵内部仍能并行,批次和多个候选也能并行,但 token 之间的自回归依赖依旧是顺序的。以后看到“Transformer 完全并行”这句话,最好立即追问:说的是训练阶段、单个注意力层,还是逐 token 生成?
生成仍然是概率建模加搜索
仅解码器语言模型把序列概率分解为:
模型给出下一 token 的条件分布,解码策略再决定如何从分布中选 token、何时停止,以及是否保留多个候选。贪心、采样和束搜索改变的是搜索过程,不会修改已经训练好的条件概率。反过来,较低的交叉熵或困惑度也不自动保证一段生成内容在事实、篇章结构和任务目标上更好。
可以把 Transformer 看成一种内容驱动的信息路由器。路由更直接、训练更容易并行,但路由是否正确、上下文是否足够、解码是否合适,仍要用任务数据和针对性测试判断。
1
为什么自注意力缩短了远距离位置之间的信息路径,却没有让长文本成本消失?
2
只要模型使用 Transformer,逐 token 的自回归推理就能像训练一样一次算出全部未知 token。
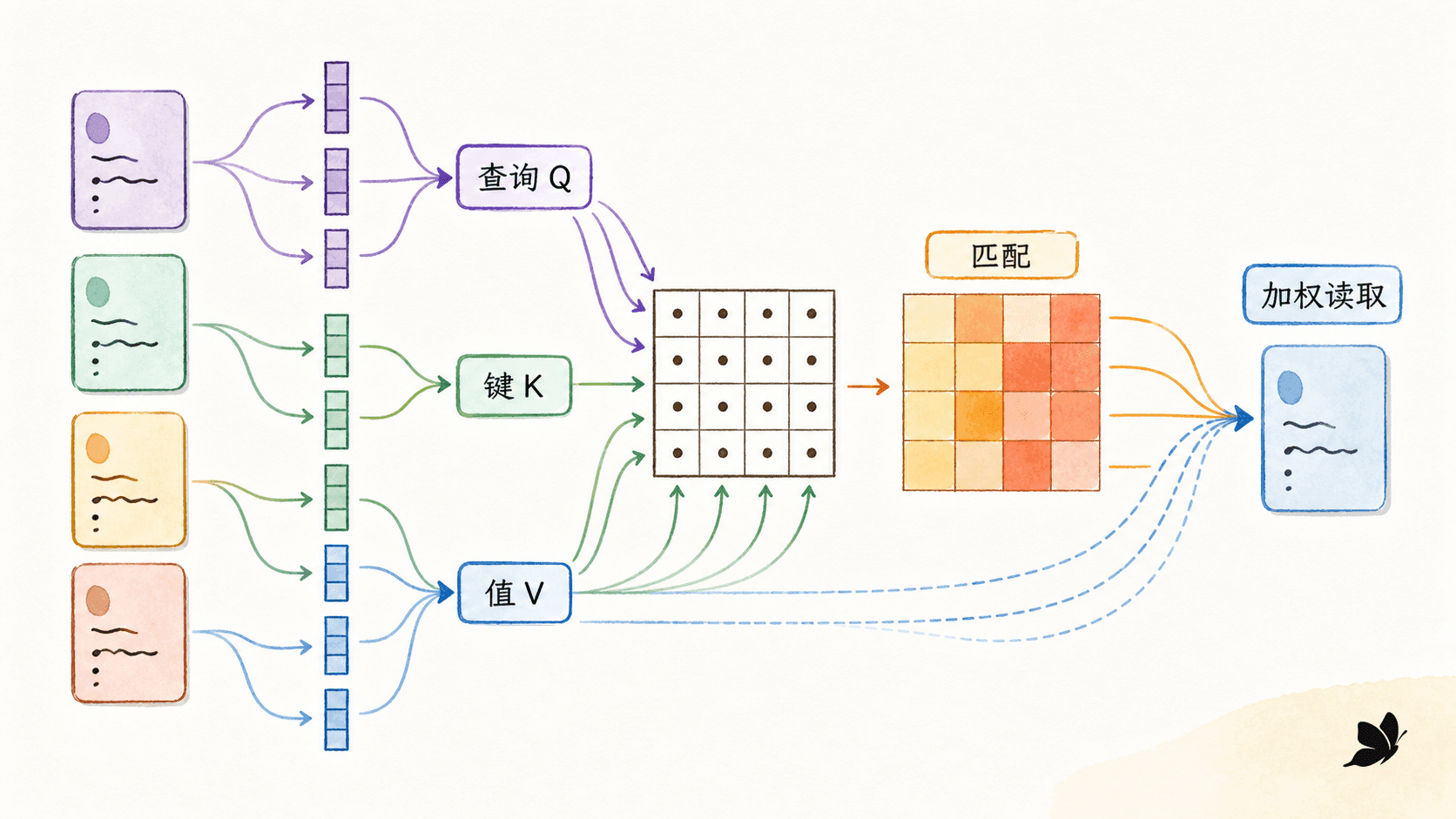
一遍算清 Q、K、V 与缩放点积
三种投影分别承担什么
给定批量输入:
其中 是批量大小, 是序列长度。单头自注意力用三组可学习矩阵得到:
如果头维度为 、值维度为 ,那么:
Q 表示当前位置正在寻找什么,K 表示每个候选位置用什么特征接受匹配,V 表示匹配后真正被聚合的内容。Q 和 K 决定“从哪里读”,V 决定“读到什么”。因此,注意力权重很高只说明当前投影下路由很强,不能直接推出对应 token 是预测的唯一原因。
从相似度到一行和为 1 的读取权重
查询与所有键的点积得到分数矩阵:
自注意力中 ;交叉注意力可以有不同的目标长度和源长度。随后除以 ,按最后一维做 softmax:
是可选的加性掩码。合法位置加 0,被屏蔽位置加一个足够小的数,数学上可写成 。输出为:
每个查询对应 的一行。若至少有一个合法键,这一行所有权重非负且和为 1;输出就是值向量的加权组合。softmax 必须沿键所在的最后一维计算。若错在查询维上归一化,程序可能照样运行,语义却变成“多个查询争夺同一个键”。
这个实验台让你修改查询与键的相似程度,并切换缩放。它最有用的观察不是某个词一定关注另一个词,而是:分数如何变成按行归一化的权重,值向量如何被混合,以及缩放怎样改变分布尖锐程度。
为什么恰好除以平方根
假设查询和键每个分量近似独立,均值为 0、方差为 1。点积是 个乘积之和:
它的方差会随 近似增长到 ,标准差约为 。维度增大后,未缩放分数更容易绝对值很大,使 softmax 过早接近 one-hot,非最大位置的梯度变小。除以 把典型尺度拉回相近范围。
我们用固定随机种子做了 64 维受控计算。未缩放分数的平均 softmax 熵为 0.687854,除以 后为 3.719289。这只是对缩放机制的数值体检,不是“熵越高模型越好”的性能结论;实际训练中分布还会由参数学习、掩码和任务损失共同决定。
3
关于 Q、K、V,下列哪些说法成立?
4
当每个头的键维度是 64 时,缩放点积注意力的分数应除以 ____。
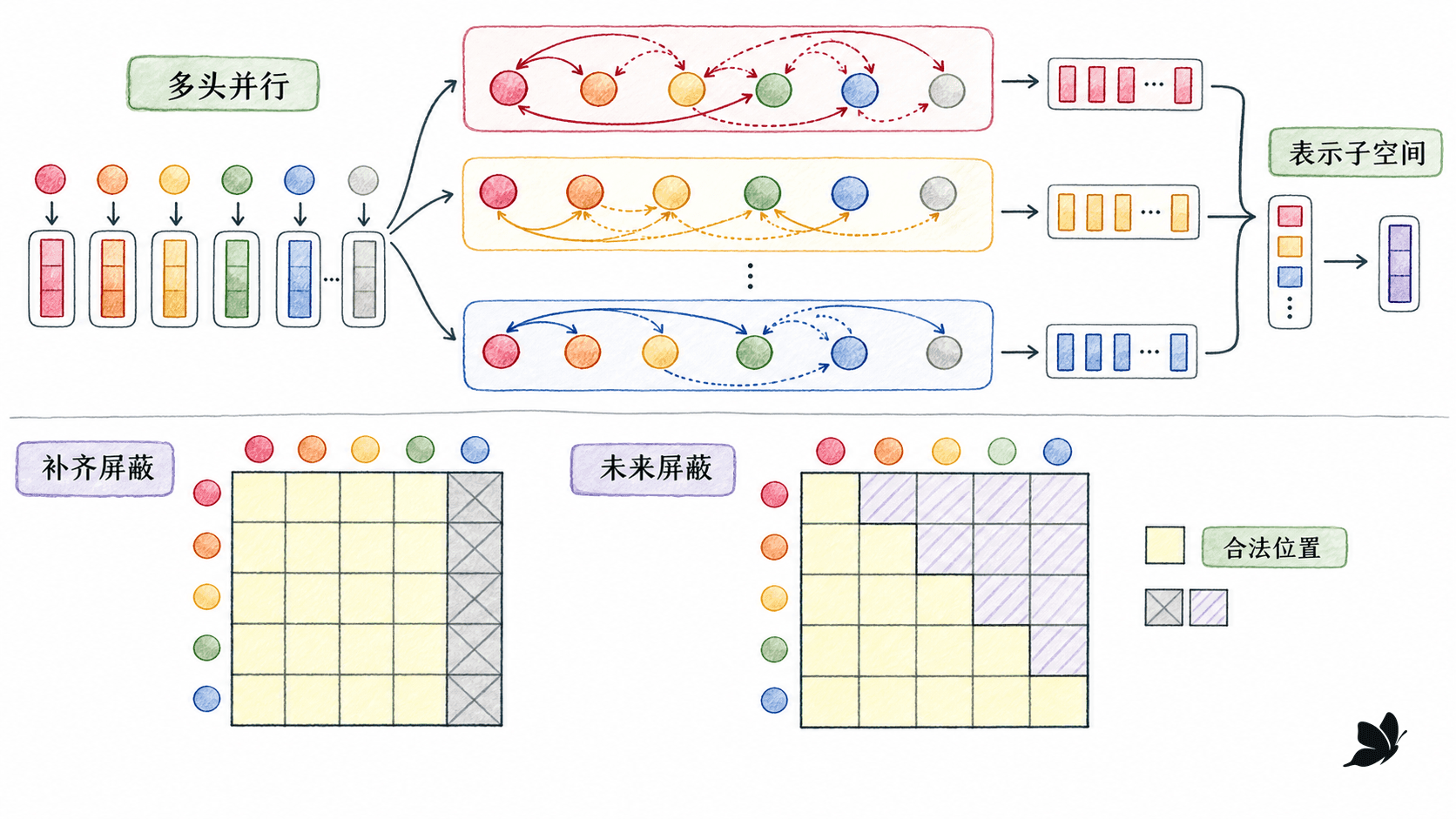
多头注意力与两类掩码
多头是多组学习到的表示子空间
若模型维度为 ,头数为 ,常见设置令每头维度:
实现会把 Q、K、V 整理为:
每个头独立计算注意力,再拼接并投影:
多组投影让模型可以并行尝试不同的匹配方式,缓解单头把所有关系压进一次加权平均的限制。但不要把“可能关注不同子空间”改写成“第 1 头固定负责语法,第 2 头固定负责指代”。头的行为随层、样本、随机初始化和训练目标变化;一些训练好的头甚至可以被剪掉而性能变化不大。可靠表述是:多头增加了并行路由的表达空间,不保证每个头都有稳定、唯一、可命名的语言角色。
padding mask:不要让补齐位置参与读取
批量中的句子长度不同,通常要补齐到同一长度。padding mask 针对键位置,常见形状是:
它会广播到查询和头维度,使任何查询都不能读取 padding 的 K/V。注意,只屏蔽 padding 作为键通常还不够:若损失也覆盖了 padding 查询位置,还应在损失函数中忽略对应标签。
causal mask:不要让当前位置偷看未来
从左到右生成时,第 个位置只能读取 的键。方形因果掩码是下三角:
padding 和 causal 解决不同问题,目标端训练时往往要同时使用。前者随样本有效长度改变,后者表达生成方向。组合后的掩码要能广播到 。
在实验台里切换 padding、causal 和组合模式,再逐行查看合法键。这样做比记一张固定三角图更可靠,因为它会迫使你区分“屏蔽哪一个样本的补齐列”和“屏蔽所有样本的未来列”。
最危险的是 API 语义相反
掩码错误经常不是数学错,而是接口约定错。以 PyTorch 为例:
- nn.MultiheadAttention 的布尔 key_padding_mask 和 attn_mask 中,True 表示该位置被屏蔽;
- torch.nn.functional.scaled_dot_product_attention 的布尔 attn_mask 中,True 表示该位置允许参与。
同一份布尔矩阵直接在两个接口间复用,可能把“允许”与“禁止”完全翻转。最稳妥的做法是先阅读目标 API,再用三个断言验收:被屏蔽权重为 0、合法行和为 1、修改未来 token 不改变此前位置输出。
5
多头注意力训练完成后,每个头都会获得固定且可跨样本命名的语言学职责。
6
验证目标端因果自注意力时,哪些检查真正有用?
位置、残差、归一化和 FFN 补齐一个块
没有位置,注意力不知道先后
若不加入任何位置信号,自注意力只根据内容投影计算关系。同步打乱输入位置会相应打乱输出位置,但计算本身没有“第几个 token”的概念。于是“小王批评小李”和“小李批评小王”会缺少区分主客顺序所需的直接信号。
原始方案把正弦、余弦位置向量加到 token 嵌入:
不同维度使用不同频率,给模型提供绝对位置,同时让固定偏移可通过三角函数关系表示。可学习绝对位置让数据自行决定位置向量;相对位置则把 与 的距离或方向直接纳入注意力。三者没有脱离任务、训练长度和外推需求的统一赢家。
FFN 不负责跨位置通信
注意力完成位置间聚合后,位置前馈网络对每个位置独立使用相同参数:
它通常先扩张特征维度,再压回 。跨位置通信发生在注意力子层;FFN 在每个位置内部做非线性特征变换。若把 FFN 删除,整个块会失去重要的逐位置非线性与通道混合能力。
残差和 LayerNorm 负责让深层网络可训练
原始块使用 post-norm:
许多现代实现也使用 pre-norm:
残差给梯度和表征提供一条直接路径;LayerNorm 针对每个 token 的特征维做归一化,减少层间尺度漂移。pre-norm 与 post-norm 的优化性质不同,不能只把归一化位置当排版细节。使用框架时要核对 norm_first 一类配置,也要确认残差两端维度一致。
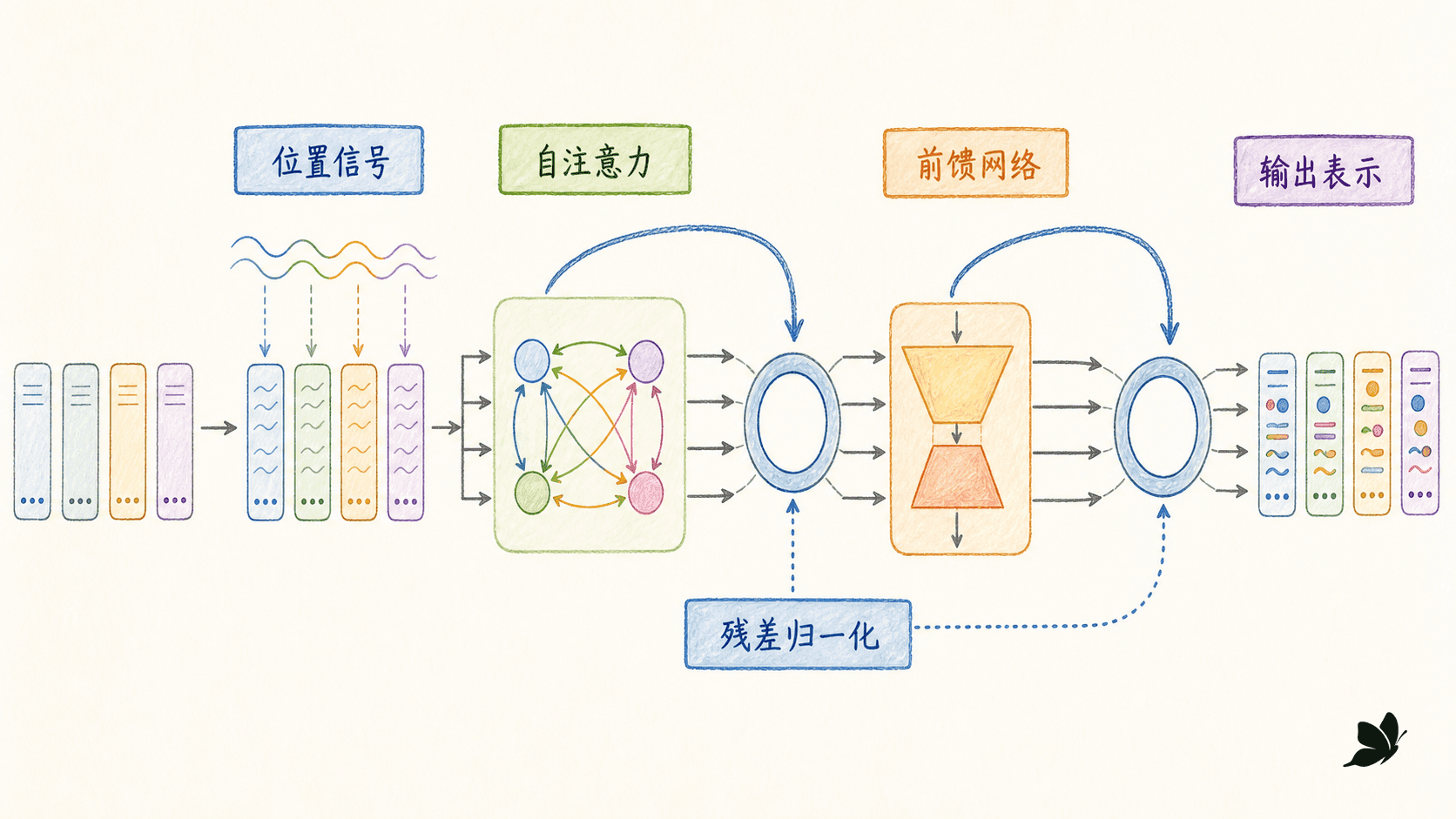
“Attention Is All You Need”不表示一个可用块里只有注意力。位置、残差、归一化和 FFN 都参与表示与优化;纯注意力堆叠和完整 Transformer 不是同一个模型。
7
位置前馈网络的主要计算范围是什么?
8
关于位置与归一化,下列哪些说法正确?
三种架构对应三种信息可见性
编码器—解码器:先理解源序列,再条件生成
编码器每层通常包含双向自注意力和 FFN。只要不是 padding,任一源位置都能读取其他源位置。解码器每层包含三部分:
- 带 causal mask 的目标端自注意力;
- 以目标端状态为 Q、编码器输出为 K/V 的交叉注意力;
- 逐位置 FFN。
交叉注意力是一个软路由接口:生成目标 token 时,解码器可以从全部源位置读取信息。它与传统对齐问题有直觉联系,但注意力权重不是硬词对齐,也不必一一对应。机器翻译、摘要和其他条件生成任务经常使用这种信息流。
仅编码器:左右文都可见,适合表示与判别
仅编码器模型保留双向自注意力,删除自回归解码器和交叉注意力。BERT 的深层表示在各层同时条件于左右上下文,适合分类、抽取和句对建模。由于当前位置能看见右侧 token,它不能在不改变目标和掩码的情况下直接充当标准左到右生成器。
仅解码器:统一成前缀条件下的下一 token 预测
仅解码器模型删除编码器和交叉注意力,只堆叠 causal self-attention 与 FFN。原始 GPT 使用多层 Transformer decoder 做语言模型预训练:
条件任务也可以序列化为同一个前缀,例如把指令、输入、分隔符和目标输出拼成一条序列,再只对需要预测的部分计算损失。这样架构统一,代价是源信息和已生成目标共享同一上下文窗口,且每个位置仍受因果可见性约束。
9
在标准编码器—解码器的交叉注意力中,Q、K、V 通常来自哪里?
10
仅编码器模型的双向自注意力可以原样用于左到右下一 token 生成,因为它已经看到了更完整的上下文。
训练能并行,生成仍逐步,KV cache 只省重复项
训练时为什么可以一次算完
对目标序列右移一位后,输入是已知前缀,标签是下一 token:
实际张量会一次包含所有位置。因果掩码确保第 2 个位置不能读取第 3 个输入,却不妨碍 GPU 同时计算各行。损失仍是所有非 padding 标签的交叉熵之和或均值。教师强制提供真实前缀,有利于并行训练;推理时模型接收自己的历史输出,二者输入分布并不完全相同。
不缓存会重复算什么
生成到第 步时,如果每次把长度 的整个前缀重新送进每一层,那么过去 token 的 K/V 投影会一遍遍重复。KV cache 在每一层保存历史:
新一步只计算当前 token 的 ,再把新 K/V 追加到对应层缓存:
查询只剩一个位置,但仍要和 个历史键比较,并对 个值加权。因此缓存把“每步重算全部过去 Q/K/V 和中间状态”改成“只投影新 token、读取全部历史缓存”,没有把单步对历史的注意力求和变成 。缓存内存还会随层数、批量、头数和上下文长度线性增长。
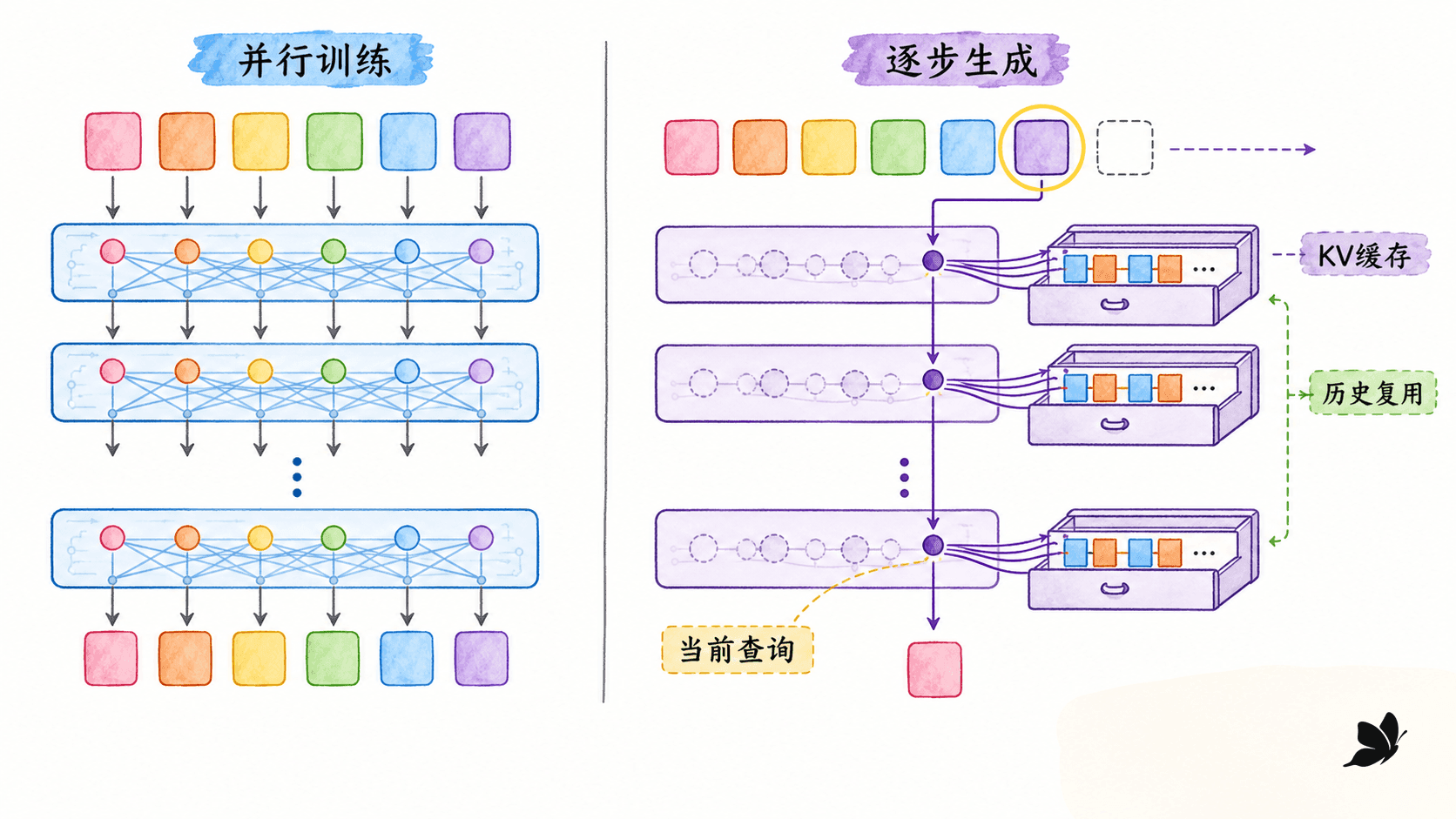
这个实验台逐步增加上下文,分别累计“整段重算”和“缓存 K/V”需要处理的历史投影数量,同时显示缓存占用。它帮助我们同时看见两件事:缓存显著减少重复计算,却把过去状态保存在内存里,并且当前查询仍需读取历史。
缓存最容易出错的三个地方
- 位置索引:新 token 的位置必须从缓存长度继续,不能每步都从 0 开始。
- mask 长度:注意力 mask 要覆盖“过去缓存 + 本次新增”的总键长。
- 训练模式:常规训练需要完整计算图和全序列并行,推理缓存不应被误当成默认训练优化。
若输出与无缓存版本不一致,先在关闭 dropout 的评估模式下,用同一前缀逐 token 对比 logits。只比较最终文本会混入采样随机性,难以定位是缓存、位置还是解码策略出了问题。
11
KV cache 在自回归推理中直接避免了哪一项重复工作?
12
启用 KV cache 后,生成每个新 token 的注意力计算与上下文长度完全无关。
复杂度与长上下文:不要把工程优化说过头
注意力和 FFN 的瓶颈随形状变化
对单层、单个批次,稠密自注意力主要包括 Q/K/V 与输出投影,以及注意力矩阵计算。粗略写成:
FFN 若中间维度为 ,成本约为:
当 较短而模型维度很大时,线性投影和 FFN 可能占主要时间;当 很长时, 项和注意力中间量会迅速主导。只用一句“Transformer 是二次复杂度”不足以预测真实延迟,还要看模型宽度、批量、精度、kernel、内存带宽和是否需要保存注意力权重。
FlashAttention 优化的是 IO,不是把稠密关系改成线性
朴素实现会把完整分数矩阵和 softmax 中间量写到高带宽显存,再反复读取。FlashAttention 用分块和在线 softmax 在片上存储中处理小块,并在反向传播中选择性重计算,减少 HBM 与片上 SRAM 之间的数据搬运。标准形式返回与稠密注意力一致的精确结果。
它能显著改善墙钟时间和额外内存,但没有把所有 个 QK 关系的算术工作自动变成 。因此要区分:
- 数学稀疏或近似:减少真正计算的关系数,可能改变结果或归纳偏置;
- IO-aware 精确实现:保留稠密注意力数学结果,改变中间量的分块、读写与重计算方式。
长上下文没有一个通用开关
可选路线包括:
- 滑动窗口或块稀疏注意力:限制每个位置读取范围,降低关系数,但跨块信息要靠层叠或全局位置传递;
- 分段记忆:复用前一段隐藏状态,缓解固定窗口碎片;Transformer-XL 还用相对位置保持时序一致性;
- 检索与压缩:只把当前任务需要的片段放入窗口,代价是检索召回和压缩失真;
- 精确 kernel 优化:在不改数学结果的前提下降低 IO 和中间存储;
- 缓存量化、滑窗缓存或卸载:控制生成阶段 KV cache 内存,可能引入精度或传输成本。
选择时先写清任务:是训练长文档、生成很长输出、读取超长历史,还是只想降低首 token 延迟?这些目标的瓶颈不同,不能用同一个“支持更长上下文”指标代替。
13
标准 FlashAttention 的核心边界应怎样描述?
14
为长上下文方案做选型时,哪些问题必须单独评估?
用可核对的小实验验证注意力
先验证不变量,再谈训练效果
下面的最小实现只依赖 Python 标准库。它故意不用框架封装,目的是看清四个不变量:形状正确、屏蔽位置为 0、每行权重和为 1、梯度能与有限差分对上。
python
import math
def softmax(scores, allowed):
legal = [s for s, ok in zip(scores, allowed) if ok]
pivot = max(legal)
exps = [math.exp(s - pivot) if ok else 0.0
for s, ok in zip(scores, allowed)]
total = sum(exps)
return [x / total
完整测试使用固定随机种子 20260715,长度 、头维 ,把最后一个键设为 padding,并叠加 causal mask。真实输出如下:
text
output_shape=(1,1,4,8) weights_shape=(1,1,4,4)
masked_weight_max=0.0
row_sum_max_error=0.000e+00
grad_analytic=0.005002817517
grad_numeric=0.005002817494
grad_relative_error=2.352e-09
causal_prefix_delta=0.0解析梯度和中心差分的相对误差为 ,说明该分量的反向推导与前向实现一致。我们又把第 4 个 token 的每一维都增加 100,前三个位置输出最大变化仍为 0,说明未来值确实被 causal mask 隔离。
为什么这些检查比“loss 下降了”更先做
一个方向写反的因果 mask 也可能在训练集上下降 loss,因为模型直接偷看了答案;一个 softmax 维度写错的实现也能产生有限数值;一个 padding 没屏蔽的模型甚至会学会利用补齐模式。先验证数学不变量,可以在训练之前排除这类“能跑但语义错”的故障。
若使用 PyTorch,可再增加三组对账:
- 手写结果与 scaled_dot_product_attention 在 dropout 为 0 时逐元素比较;
- nn.MultiheadAttention 设置 average_attn_weights=False,检查权重形状为 ;
- 同一前缀分别用全量重算和 KV cache 推理,逐步比较最后位置 logits。
15
为什么只观察训练 loss 下降不能证明 causal mask 正确?
16
一个注意力实现的最小验收应包含哪些项目?
把常见实现错误变成检查表
形状错误通常藏在转置和广播里
多头实现的常见流程是:
注意力结束后再反向转置、连续化并拼回 。若把 和 交换错,矩阵乘法可能仍可广播,却让“头”和“位置”互相污染。建议在每次 reshape 后写出形状断言,而不是靠注释猜。
数值错误常来自全屏蔽行和低精度
若某个查询的所有键都被设为 ,softmax 会遇到无合法分母并产生 NaN。padding 较多或切片后的非方形 mask 尤其容易触发。处理方式不是把 NaN 静默改成 0,而是明确保证每个有效查询至少有一个合法键,并在损失端排除无效查询。
混合精度下还要使用框架提供的稳定 softmax 或融合 kernel,不要先在低精度中计算巨大指数。缩放、减行最大值和合适的累积精度都是数值稳定性的一部分。
可视化只能帮助诊断,不能单独证明解释
注意力热力图很适合检查模型是否总盯着 padding、因果方向是否反了、某些头是否完全塌缩。但“某个输入权重大”并不自动说明删掉它会造成同等幅度的输出变化。要讨论解释,应结合梯度、遮蔽、反事实干预或任务级消融。
一份可直接执行的验收顺序
先固定批量、长度、头数和头维,逐项打印 Q、K、V、分数、权重和输出形状;同时断言模型维度能被头数整除。
再构造一个肉眼可核对的小掩码,分别测试 padding、causal 和组合情况;确认屏蔽权重为 0、合法行和为 1。
关闭 dropout,用手写公式与框架算子对账;再做一次解析梯度或有限差分检查,排除转置正确但反向错误的情况。
最后测试训练与推理两条路径:训练端确认未来不泄漏、padding 不计入 loss;推理端确认有缓存和无缓存的逐步 logits 一致。
如果这套检查都通过,我们才进入模型效果调试。此时出现的问题更可能来自数据、目标、优化或解码,而不是一个悄悄翻转的布尔 mask。
17
当某个查询行的所有键都被加性掩码设为负无穷时,最可能出现什么?
18
注意力热力图显示某个 token 权重最大,就足以证明该 token 是输出的因果解释。