键值数据库
键值数据库是最简单、也最容易理解的一种 NoSQL 数据库。你可以把它想象成一个超级大的字典,每一项就是“键”对应一个“值”。和传统关系数据库需要各种表格、SQL 查询语法不同,键值数据库就是把存储回归得很直接,用起来没有那么多复杂的规则。
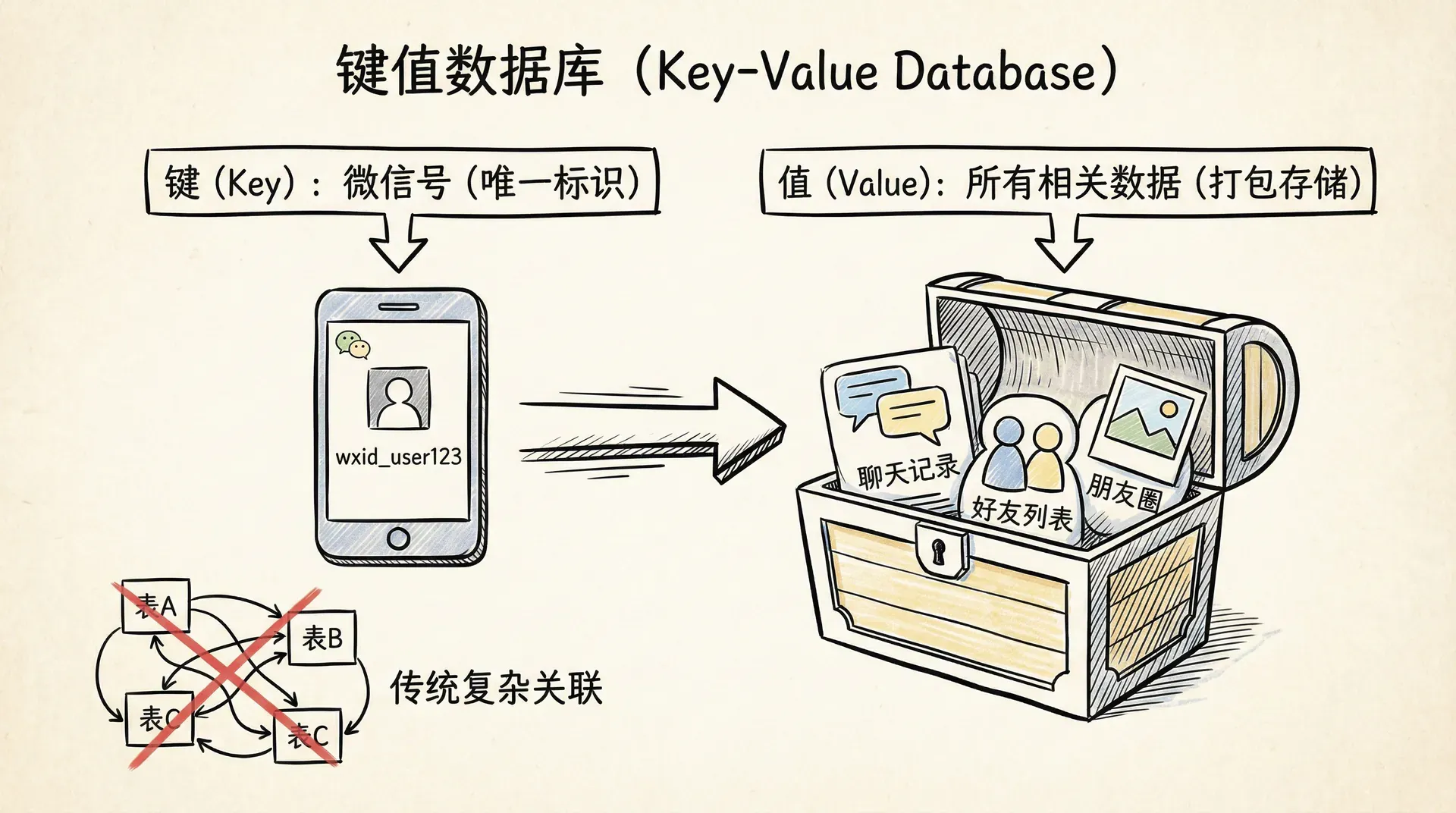
比如,在微信的聊天记录存储里,每个人都有自己的微信号,这个微信号就作为唯一的键。跟这个键绑定的,就是用户的所有聊天记录、好友列表、朋友圈这些信息。只要有了微信号,系统就能一下子把相关数据都拿出来,不用绕来绕去查好几张表。
键值存储的工作原理
键值数据库的核心理念非常朴素:通过一个唯一的键来快速定位和访问对应的数据。这就像我们生活中的储物柜系统,每个柜子都有一个编号(键),我们用这个编号就能打开对应的柜子获取里面的物品(值)。
在技术实现上,键值数据库本质上就是一个高度优化的哈希表。当我们想要存储一条用户信息时,比如用户“张三”的个人资料,数据库会将“张三”这个键通过哈希算法映射到具体的存储位置,然后将包含个人资料的数据块存储在那里。
键值数据库的最大优势在于极简的操作接口:获取(GET)、存储(PUT)、删除(DELETE)。这种简单性带来了出色的性能表现,特别适合高并发的互联网应用场景。
让我们看一个淘宝购物车的实际例子:
javascript
// 存储用户购物车数据
await kvStore.put('cart_user_12345', {
items: [
{ productId: 'iphone15', quantity: 1, price: 5999 },
{ productId: 'airpods', quantity: 2, price: 1299 }
],
totalAmount: 8597,
lastUpdated: '2024-10-16T10:30:00Z'
})
// 快速获取购物车内容
const cartData = await kvStore.get('cart_user_12345')现在常用的键值数据库各有各的特点。比如 Redis,就不仅仅是简单地存储字符串了,它其实是个“数据结构服务器”,直接就能用列表、集合、哈希表这些复杂的数据结构,还能做点比如“获取用户最近10次浏览记录”、“统计两个用户有没有共同好友”这样的操作。
再比如 Riak,更强调分布式和高可用。它用“桶”(bucket)来分门别类地装数据,比如有的桶专门放用户资料,有的桶专门放订单信息。
键值存储特性
如果数据库只是跑在一台机器上,一致性其实没啥难度,因为所有东西都在同一个地方操作。但一旦像微博这样要服务海量用户,数据被拆分到很多台服务器上,这时候怎么保证大家看到的数据一致,就变得没那么简单了。
分布式键值数据库一般会采用「最终一致性」的做法。比如说,某个用户刚发了一条微博,这条消息在北京的服务器会立刻写入,但可能要等几毫秒或者几秒钟后才同步到上海、广州的其他服务器。在这个短暂的同步延迟里,不同地方的用户有可能看到的内容并不完全一样,不过过一会儿,所有节点上的数据最终都会达成一致。
Riak 其实给了我们很灵活的一致性调节方式。通过调 N(副本数)、R(读取时需要几个节点返回)、W(写入时要有几个节点写成功)这些参数,你可以在一致性和性能之间自由权衡。举个例子,一个 5 节点的集群,N=3、W=2、R=2,就意味着每份数据会保存 3 份,写的时候要有 2 个节点写成功才算数,读的时候也要有 2 份数据返回。 这样既不容易丢数据,宕掉一两台机器也没事,同时性能又不会太差。
传统关系型数据库实现 ACID 事务比较容易,毕竟大部分时候都是“一桌一锅”。但键值数据库里,每个 key 就是一条线,跨 key 的操作天生就是“各管各的”,想要做真正的多键事务很难。
比如说电商转账:A 给 B 转 100 元。关系型数据库可以加个 transaction,A 扣钱、B 加钱,要么一起成功、要么一起失败。但在键值库里,A 和 B 两条记录本身没啥联系,除非你在业务层协调,否则有可能只完成了一边操作。
正因如此,很多时候得在应用层“绕一下”,比如加事务日志或者搞个补偿机制,来保证数据的完整性。
当然,也不是说完全没办法。像 Redis 有 MULTI/EXEC 这种批量操作能力,Riak 也有“法定人数”(quorum)机制,能在一定程度上支持有限的事务需求。
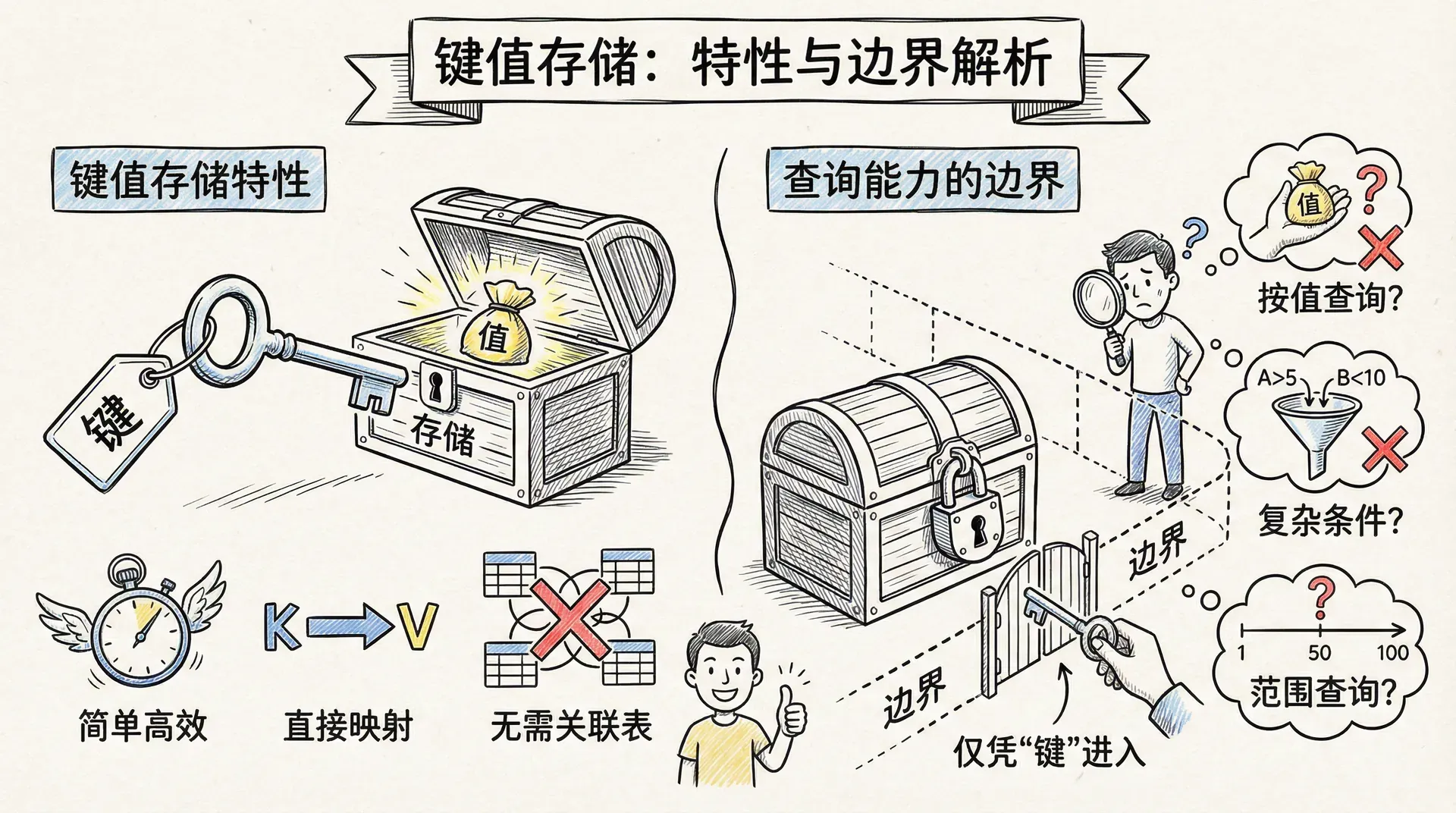
查询能力的边界
键值库的查询功能其实很有限,主要就是“有钥匙才能开门”。你可以想到它像宾馆前台,只有拿着房卡(key)才能进房间拿到数据。如果你想要按照房间价格、楼层、朝向搜索房间,那键值库本身帮不了你,这就是设计上为速度作出的妥协。
javascript
// 这样的查询很简单,性能极佳
const user = await kvStore.get('user_12345')
// 但这样的查询就不可能了
// "找出所有年龄在25-30岁之间的北京用户"
// 传统键值数据库无法直接支持这种查询不过,这种查询能力受限的情况也让大家想出了不少办法。比如 Riak Search 就集成了 Apache Lucene,可以支持对值的全文搜索。有时候,应用还会自己维护一些额外的索引,比如按城市给用户建个分类索引,从而实现更灵活的查询。
所以键的设计就变得格外关键了。一个合理的 key,能帮你把业务逻辑直接编码进去,比如用 "user:profile:12345" 存用户资料,用 "user:orders:12345" 存用户订单。这样有规律的 key 前缀,也方便后续数据的整理和查找。
键值数据库的应用场景
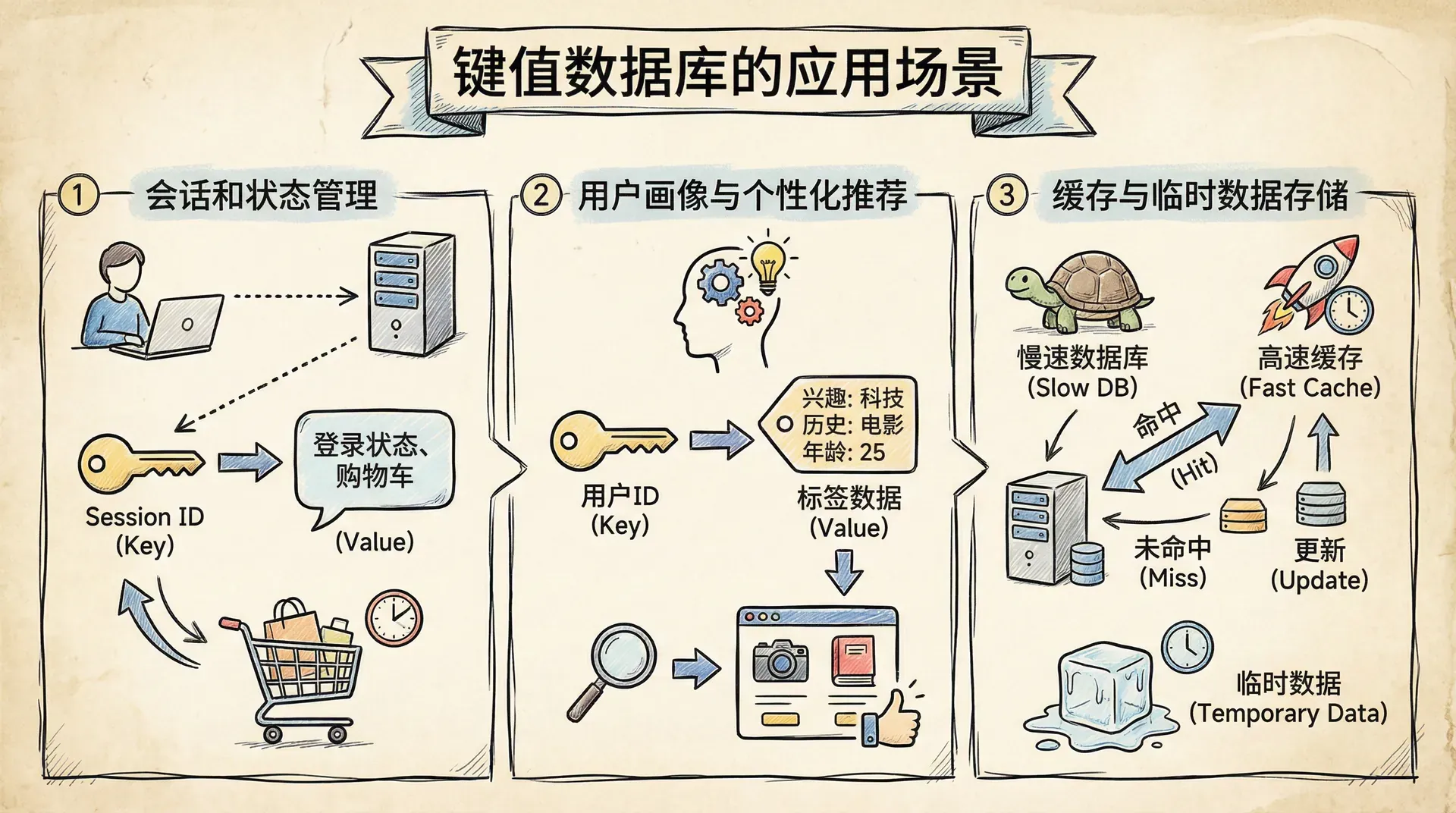
会话和状态管理
Web 应用中的会话(Session)管理是键值数据库的典型应用场景。每当用户登录如京东、天猫等电商平台,系统会为其分配一个全局唯一的会话 ID(session ID),该 ID 作为键值数据库中的 key,映射到存储用户登录状态、购物车条目、浏览历史等内容的 value。
这种设计模式的核心优势在于高效的数据读取性能。服务器可通过单次键值检索即可获取完整的会话数据,极大减少了传统关系型数据库中多表关联(JOIN)操作的复杂性和性能消耗,提升了大规模并发环境下的响应速度与扩展性。
javascript
// 典型的会话数据结构
const sessionData = {
userId: 'user_12345',
loginTime: '2024-10-16T09:00:00Z',
shoppingCart: [...],
recentViews: [...],
preferences: {
language: 'zh-CN',
currency: 'CNY'
}
}
await kvStore.put(`session_${sessionId}`, sessionData, {
expireIn: 3600 // 1小时后自动过期
})用户画像与个性化推荐
在现代互联网应用中,用户画像与个性化推荐已成为提升用户体验和增强业务价值的核心能力。例如,内容平台如抖音需为每位用户持续维护多维度的数据,包括兴趣标签、行为特征、社交关系网等,且这些数据需要支撑高并发、高频次的低延迟读取。
键值数据库在此类场景下具备显著优势。可通过用户唯一标识(如 userId)作为 key,将用户画像各类维度数据以聚合对象的方式存储于 value,实现对单用户数据的高效读写访问。此种数据模型不仅便于横向扩展和高速检索,也能够支持大规模、个性化的数据处理需求。
javascript
// 用户画像数据示例
const userProfile = {
demographics: {
age: 28,
city: '北京',
occupation: '软件工程师'
},
interests: ['科技', '电影', '美食'],
behaviorTags: ['夜猫子', '价格敏感', '品质追求者'],
socialGraph: {
friends: ['user_456', 'user_789'],
followings: ['tech_blogger_001']
},
缓存与临时数据存储
键值数据库因其极高的读写性能与低延迟特性,被广泛应用于缓存和高速临时数据存储场景。例如,企业通常采用 Redis 作为关系型数据库(如 MySQL)的一级缓存,将高频访问的数据(如商品信息、用户基础资料、会话令牌等)保存在内存,显著降低后端数据库压力,提升整体系统吞吐量。
以微博热搜榜为例,系统会定期根据实时数据计算最新热搜结果,并将其存储于键值数据库中。前端请求用户只需从缓存中读取热搜数据,无需每次均重新聚合/计算,大幅降低主数据库负载并优化用户访问体验。这一模式不仅提升了数据访问速度,也确保了高并发条件下的系统可扩展性与稳定性。
什么时候不应该选择键值数据库
如果你的应用需要频繁进行多表关联查询,键值数据库就不是最佳选择。考虑一个企业 CRM 系统,需要查询“过去三个月内,购买金额超过1万元的北京客户的联系方式,按购买时间排序”。这种涉及多个数据维度的复杂查询在关系数据库中可以用一条 SQL 语句完成,但在键值数据库中却需要复杂的应用层逻辑来实现。
强行在键值数据库上构建复杂的关联查询逻辑不仅开发复杂,性能往往也不如专门设计的关系数据库。
金融系统的转账操作要求严格的 ACID 特性,任何数据不一致都可能导致资金损失。虽然一些键值数据库提供了有限的事务支持,但在需要跨多个数据实体进行强一致性操作的场景下,传统关系数据库仍然是更安全的选择。
如果你需要对数据进行复杂的统计分析,比如“计算各个城市用户的平均消费水平”或“分析产品销量的季节性趋势”,键值数据库的能力同样也就显得不足了。这类需求更适合使用专门的分析型数据库或数据仓库解决方案。
小结
键值数据库就像一个超级庞大的字典,用简单的“钥匙-箱子”的思维方式来存储数据。它的核心魅力在于极致的简洁和速度:通过唯一的键就能瞬间定位到对应的数据,不需要复杂的表格关联或者SQL查询语法。这种设计让它在处理海量并发请求时表现出色,比如微信这样的应用需要快速响应数亿用户的即时操作。
不过,这种简单性也带来了些许局限性。在数据一致性和复杂查询方面,键值数据库不像传统关系数据库那样面面俱到。它更适合那些对读取速度要求极高、数据结构相对简单的场景,比如电商网站的购物车管理、内容平台的个性化推荐,以及各种缓存需求。 当我们面对复杂的业务关联或者需要严格事务保证的场合时,或许还是应该选择更传统的数据库方案。