Map-Reduce
假如你在管理一家遍布全国的连锁超市,每天都有大量订单和销售数据涌入。要是靠单台服务器或人工统计全国所有门店的数据,无论多高效,肯定也是吃力不讨好。
数据量一旦大起来,光靠单点就撑不住了。我们得把这些数据分散到多台服务器,像组建一支团队那样协作处理。但团队成员多了,怎么分工、怎么高效合作,又成了新的问题。
以前用传统数据库时,要么直接在数据库服务器里做查询和计算,要么把数据拉到客户端自己算。留在服务器里计算省去了数据传输,但机器的压力骤增;拉到客户端则数据量巨大,网络也跟着吃不消。
Map-Reduce就是这样诞生的。它借用了函数式编程里常见的map和reduce操作,但更重要的是引入了一种全新的分布式处理方式和思想。
Map-Reduce的精髓其实就一句话:“就近处理”——让计算发生在数据存储的地方,而不是大规模把数据拖来拖去。
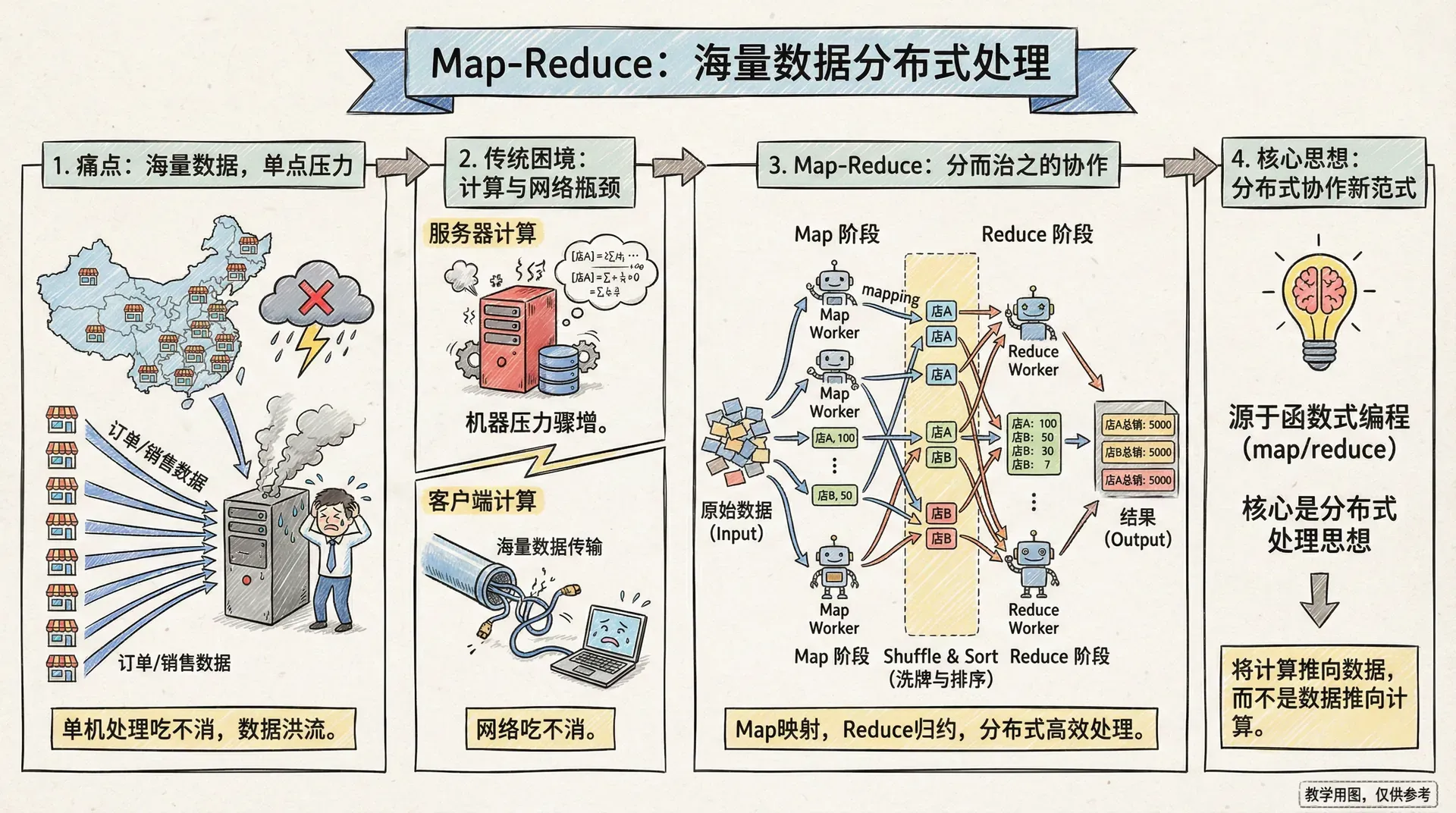
Map-Reduce 是怎么工作的?
让我们举个更直观的例子:比如连锁超市想统计过去一周各种商品的销售情况,而数据分布在全国的服务器上。
数据的组织很常见:每张订单下面有很多商品明细,每个明细都有商品ID、数量和价格。现在,销售部门希望能得到每种商品最近一周的总销售额。 这时候,Map-Reduce正好派上用场。整个过程分为两个主要阶段:
Map阶段:数据提取与转换
Map函数就像是我们派遣到各个门店的数据收集员。每个收集员的工作很简单:拿到一个订单,把其中的商品信息提取出来,按照商品编号分类整理。
比如一个包含iPhone、小米手机和华为耳机的订单,经过Map函数处理后,会输出三个键值对。iPhone对应数量2台和金额12000元,小米手机对应数量1台和金额3000元,华为耳机对应数量1副和金额500元。 Map阶段的好处在于每个Map任务都是完全独立的。就像每个数据收集员只需要专注于自己手头的订单,不需要与其他同事协调,这使得Map操作能够在集群中的各个节点上并行执行。
Reduce阶段:数据聚合与汇总
Reduce函数则像是我们的数据分析师,负责把所有收集员提交的同类商品数据进行汇总。所有标记为“iPhone”的销售记录会被送到同一个分析师那里,然后计算出iPhone的总销售额和总数量。
Reduce函数会把所有相同键的数据收集到一起,然后合并成一个最终结果。Map函数每次只负责处理单条数据的转换,Reduce函数则能够“看到”同一个键下的全部数据,因此可以进行更复杂的聚合分析。
用Map-Reduce框架时,很多琐碎而复杂的事情,比如任务怎么分配、数据如何在节点之间移动、结果怎么收集,框架都会自动帮我们搞定。我们只需要专注于写出两个核心函数:Map负责从原始数据提取有用信息,Reduce则负责汇总这些信息。
分区与合并
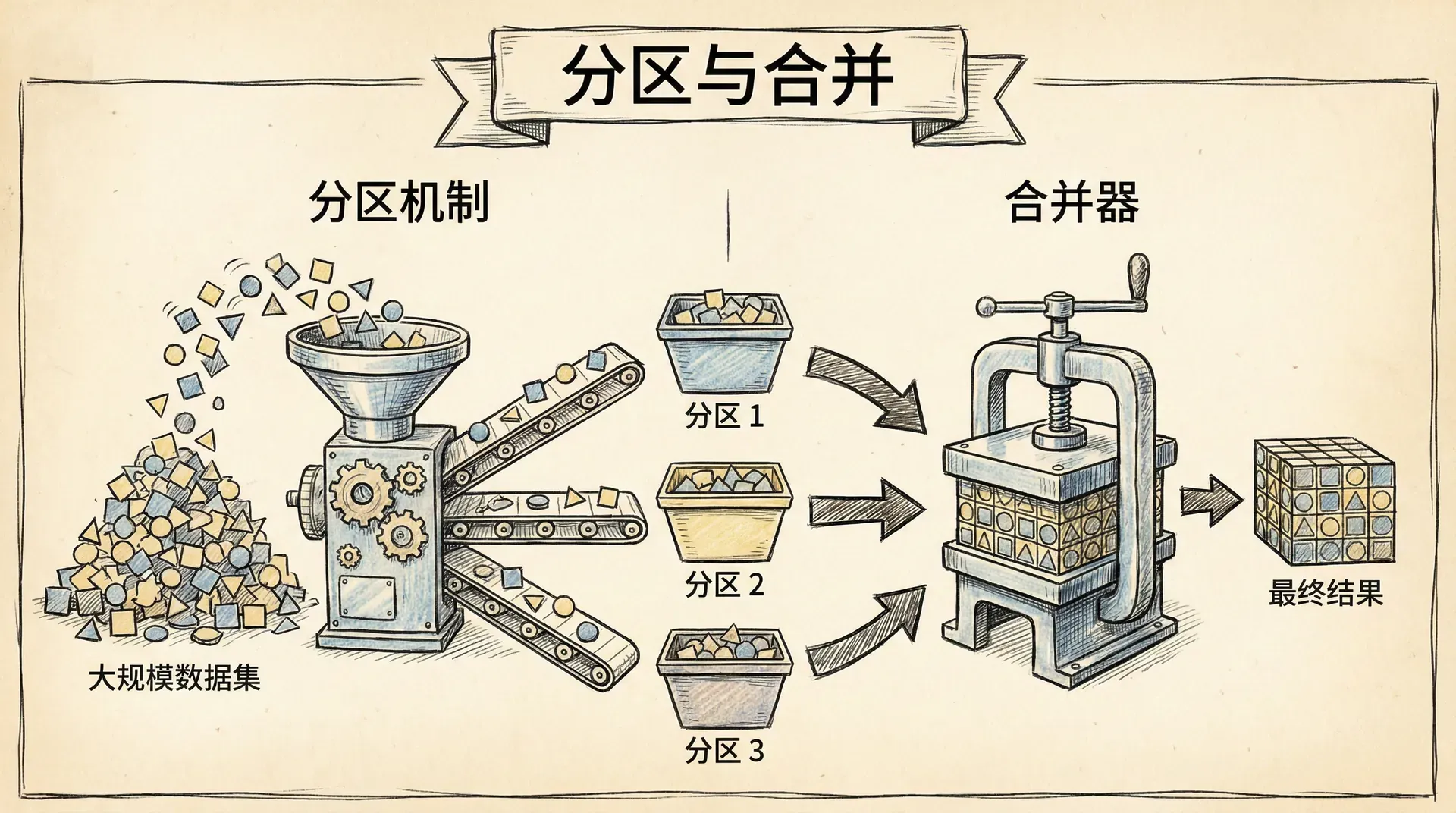
最简单的Map-Reduce实现可能会把所有Map结果都丢给一个Reduce函数处理。这其实就像全国所有快递都要送去一个分拣中心,很快就装不下、也成了瓶颈。想要充分利用集群的算力,就得用点巧劲。
分区机制
分区的核心就是把Map输出根据键分组分区,不同的Reduce任务并行处理各自的数据分块。比如回到超市的例子,我们可以按照商品类别分组:电子产品归A组分析师,服装归B组,食品归C组。
分区机制让我们可以同时跑多个Reduce任务,每个任务只聚焦自己分到的那部分数据,各自为战、高效推进。当然,这种设计同样有局限:一个Reduce任务没办法同时拿到所有不同的键,所以像“分析不同商品类别之间的关系”这种需求,就实现不了。
实际用的时候,系统通常会把一批键打包到同一个分区,然后从各个节点收集这个分区的数据,把它们归并后交给相应的Reducer来处理。这个归并、移动数据的环节,大家常叫它“洗牌”。有些地方也管分区叫“桶”或者“区域”。
合并器
Map到Reduce之间,传输的数据经常会有很多重复。举个例子,全国各地统计出来的“iPhone”销售记录,可能成千上万条,但其实我们只想要一个最终合计。合并器就是为了解决这个问题而生的。
合并器其实就是个小型的Reduce函数,提前在本地节点先做一次“缩减”。比如说,一个节点上有100条“iPhone”销售的数据,用合并器直接汇成一条,统计好总数量和总金额,这样到最后要传到网络上的数据就大大变少了。
需要注意,并不是所有Reduce函数都能直接用作合并器。只有那种输入和输出格式完全一样的Reduce才行,我们管这类函数叫“可组合的Reducer”。
举个“不能直接用作合并器”的例子:比如你想统计每个商品有多少个独立客户购买。Map函数输出的是商品名加客户ID,Reduce要算的是去重后的客户数量——这时候输入是一堆客户ID,输出却只是一个数字,两者格式不一致,就不能直接当合并器用。
当然,即使遇到这个问题,我们还是可以加个定制的本地合并器——比如先在本地把客户ID去一下重。这样即使它不是最终Reducer,依旧能有效减少需要传输的数据量。
如果你用的是可组合的Reducer,那Map-Reduce框架的弹性就特别大。不光能让不同分区里的Reduce一起跑,还能让同一分区的Reduce分好几次串行做。甚至有些情况下,Map任务还没全部干完,Reduce就可以提前合并上了——整体效率高出不少。
组合计算
Map-Reduce 虽然给我们带来了很强大的分布式处理能力,但和直接写代码不同,它也有一些「规矩」和限制。比如,有些原本很简单的计算,换成 Map-Reduce 以后,做法就得变一变。
简单说,Map 阶段只能对每条数据做处理,Reduce 阶段只能聚合同一个键下的所有值。这就限制了我们不能在 Reduce 时看到「所有」的数据,所以要做跨多组、多个键的数据统计,就得拆解成多个步骤,不能一步到位。
平均数计算
举个例子,我们来算商品的平均订购数量。直觉上平均值就是「总数 / 总个数」,但在 Map-Reduce 里,这事不能一步做完。
比如,假设两批 iPhone 订单:第一批平均 3 台,第二批平均 5 台。你能直接得出总平均是 4 台吗?其实不行,因为你不知道每批各有多少个订单。只有把总数量和订单总数都统计出来,最后才能算出准确平均值。 所以更好的做法,是 Map 阶段把总数量和笔数都带上,Reduce 阶段累计这两个数,最后一起除一下计算出平均数:
这样,我们就把一个不可组合的操作(计算平均数)转换为可组合的操作(累加总数和个数)。
计数统计
在Map-Reduce里做计数,其实非常直接。当Map函数遇到一条需要统计的记录时,输出一个“1”就行了。Reduce阶段把这些“1”都加起来,就是总数。
比如,我们要统计每种商品有多少个订单。Map这边每碰到一个订单,就给该商品输出一个“1”;Reduce这边,把所有“1”加总,就是每种商品的订单总数。这种做法很自然,也特别适合Map-Reduce那种大家并行各扫自家门前雪的风格。
两阶段计算
有些更复杂的分析不能一步到位,这时候我们就得把计算拆成几步、做成多阶段的Map-Reduce流水。像搭积木一样,每步都做点事。 假设业务部门想对比一下2023年每个月商品的销售,跟2022年同期比变化大不大。这个需求要跨年份、跨月份,就特别适合分两阶段用Map-Reduce来处理。
第一阶段:月度销售汇总
第一阶段的任务是从原始订单数据中提取每个商品每个月的销售汇总:
第一阶段的Map函数读取订单记录,提取商品名称和月份信息,输出形如“iPhone-2023-03”这样的复合键和对应的销售金额。Reduce函数则汇总同一商品同一月份的所有销售记录。
第二阶段:同比分析计算
第二阶段使用第一阶段的输出,进行年度对比分析:
第二阶段的Map函数会根据年份的不同,将2023年的数据标记为“当年数据”,2022年的数据标记为“去年数据”,其他年份的数据则忽略。输出的键是“商品名-月份”的组合,比如“iPhone-03月”。
Reduce函数接收到同一商品同一月份的两年数据后,就可以计算同比增长率了。比如,iPhone在3月份2022年销售100万,2023年销售120万,同比增长20%。
将复杂计算分解为多个简单的Map-Reduce步骤,不仅让代码更容易编写和维护,中间结果还可以被其他分析任务重复使用,大大提高了效率。
这种分阶段的方法带来了意想不到的好处。第一阶段产生的月度汇总数据可以作为物化视图保存起来,为其他各种分析提供基础数据。当我们需要进行季度分析、年度分析或者其他维度的分析时,都可以直接使用这些预处理好的中间结果,避免重复处理海量的原始订单数据。
增量更新
现实里,数据一直在变、一直在涨。比如咱们的超市,每天都会冒出新订单,每小时都有新的销售流水。如果每次想更新报表都把所有历史数据重算一遍,那不光浪费时间,还特别消耗算力——一点都不划算。增量 Map-Reduce 其实就是为了解决这种麻烦。 简单来说,假设昨天咱们已经统计过商品的销量,今天只需要把新增的订单算出来,再和昨天的汇总结果合并,就能得到最新的数据了。核心思想很简单:只处理新变化的那一部分,不用每次都全部重头来过。
Map阶段
在 Map 阶段,事情其实挺简单。每个 Map 任务本来就是互不影响的。只要有新订单进来,只对这些数据跑一下 Map 就行,已经处理过的老数据可以直接跳过,省了不少功夫。
比如,昨天我们已经处理了1000万个订单,今天又新增了10万个订单。我们只需要对这新增的10万个订单执行Map操作,大大减少了计算量。
Reduce阶段的增量怎么做
Reduce这一步在做增量的时候麻烦一些。因为新来的Map结果很可能影响不少聚合键。有了分区机制其实还好——只有那些有新数据的分区才需要重新跑Reduce,没变化的数据分区就直接沿用之前的结果,省不少事。
可组合的Reducer在增量场景下很实用。只要是新数据,没有什么删除或修改,那我们只需要把新增计算出来的结果和原来的汇总直接合并一下就行。
比如昨天统计的iPhone一共卖了500台,总金额300万元,今天新卖了50台,卖了30万元。累加一下,iPhone的新统计就是550台,330万元。因为加法这种操作天生容易组合,新旧合一起就是最新结果。
但如果还遇到退货、改价这些修改类操作,事情就没那么顺了。你可能就得用更细致的方法——比如维护依赖关系网络,确保只重新计算那些真正受影响的部分,不要什么都推倒重来。
实时与效率,取个巧
增量Map-Reduce其实就是帮我们在“要数据实时”跟“不能浪费算力”之间找到了一个折中。我们不用每来个变动都把全量数据再计算一遍,只针对增量快速算、快速更新结果。
实际项目里,各种Map-Reduce框架对增量支持也五花八门。有的针对增量专门做了优化,能自动感知数据哪变了,智能分配任务。
小结
Map-Reduce不仅仅是一种编程模式,更代表了一种全新的思维方式。它引导我们在分布式环境中重构对计算问题的理解,将庞杂的分布式计算任务拆分为两个基本操作:Map进行数据的转换与提取,Reduce完成数据的聚合和汇总。 这种极简的结构带来了卓越的并行处理能力和系统容错性,同时也催生了像分区机制和合并器这样的配套优化方法,极大提升了集群资源的利用效率和任务执行的灵活性。
面对日益复杂和动态变化的数据处理需求,我们学会把大问题进一步拆解成多个Map-Reduce阶段,通过管道式的组合构建强大的数据处理流程。每个阶段可以产出物化视图,为后续分析留存有用基础数据。 结合增量更新机制,系统不仅能在数据持续增长的情况下高效运行,避免不必要的重复计算,还能实现资源利用的最优化和更接近实时的结果更新。