版本戳
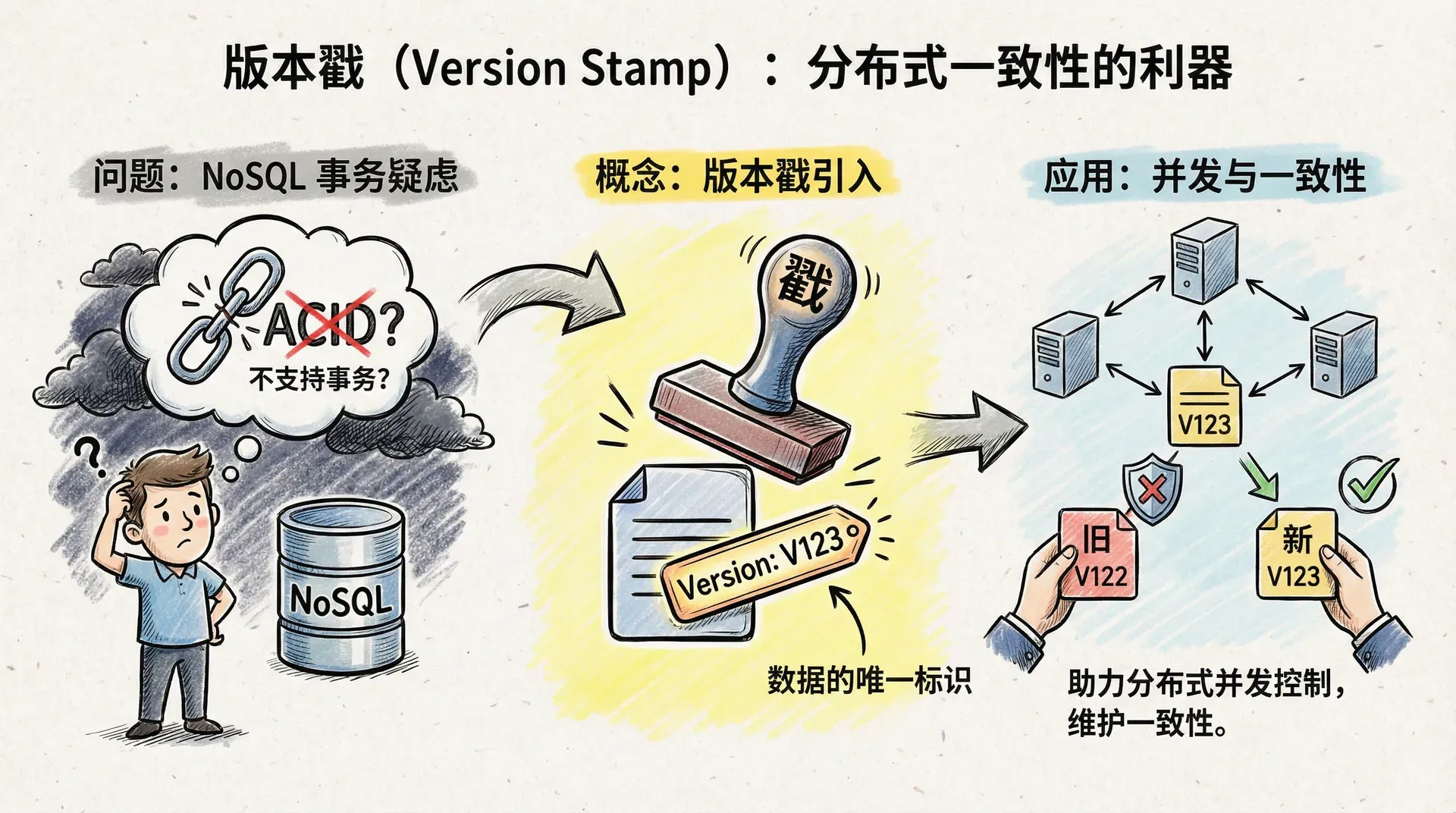
在NoSQL数据库领域,关于“不支持事务”的声音屡见不鲜,许多开发者因此产生疑虑。确实,传统关系型数据库基于ACID原则的事务机制对于保障强一致性举足轻重,但NoSQL数据库则采用了针对分布式场景优化的不同一致性保障策略。 所以这里我们将介绍“版本戳”这一概念——它类似于数据的唯一标识,有效助力分布式系统中的并发控制与一致性维护。
业务事务与系统事务
以电商系统为例:用户从浏览商品到下单付款,表面上这是一个完整的业务流程(即“业务事务”)。例如,用户在浏览页面时看到《深入理解数据库》一书标价58元,经过十分钟决策后提交订单,并完成收货和支付信息的填写。这一系列操作,在业务上可视为一个事务单元。
然而,从底层技术角度来看,将整个用户操作周期封装在单一数据库系统事务中是不合理且不可行的。原因在于,若在用户打开商品详情页时便开启数据库事务,并持续至支付完成,相关数据会长时间被锁定。这种设计不仅拖慢系统响应,还极大降低数据库并发处理能力,甚至影响其他用户的正常业务操作。
实际上,大多数应用程序只会在用户点击“确认购买”按钮后才开启系统事务,这样数据库锁定的时间只有几秒钟。然而,这种做法带来了一个新的问题:在用户浏览商品到最终确认购买的这段时间里,商品的价格可能已经发生了变化,或者库存可能已经不足。
在分布式系统中,业务事务和系统事务之间的时间差是不可避免的。我们需要特殊的机制来处理这种“时间窗口”带来的数据一致性问题。
版本戳的诞生
为了解决前面提到的问题,我们需要想办法判断数据在“业务事务”进行的这段时间里有没有被其他人动过。这时候,版本戳就派上用场了。
你可以把版本戳理解为每条数据的“小标签”——只要这条数据有了变动,这个标签就会跟着变。等你再想修改这条数据时,只需比对一下当前的版本戳和当初读取时的,看有没有变化,就能知道数据期间有没有被别人更新过。 假设小张刚点进《深入理解数据库》商品页时,系统返回给他的不只是书的信息(比如标题、价格、库存),还顺手带了一个版本戳,比如“version: 42”。过了十分钟,小张决定下单,这时候系统会再查一下数据库。如果这本书的版本戳还是42,那就说明这段时间里没人动过,订单可以照常进行。
但如果版本戳已经是43了,就意味着有变化——比如管理员调整了价格,或其他用户买书导致库存变了。系统这时就会拒绝小张的购买请求,并提示他刷新页面,确认最新的信息。
javascript
// 用户浏览商品时获取数据和版本戳
const bookData = {
id: "book-001",
title: "深入理解数据库",
price: 58,
stock: 10,
version: 42 // 版本戳
}
// 10分钟后用户确认购买
async function purchaseBook(bookId, expectedVersion) {
// 重新读取当前数据
const currentBook = await getBook(bookId)
if (currentBook.version !== expectedVersion) {
// 版本戳不匹配,说明数据已被修改
throw new Error("商品信息已更新,请重新确认购买")
}
// 版本戳匹配,可以安全地进行购买操作
// 同时更新版本戳到43
await updateBookAndCreateOrder(bookId, currentBook.version + 1)
}这种机制在HTTP协议中也有类似的实现,叫做ETag(实体标签)。当我们从服务器获取资源时,服务器会在响应头中包含一个ETag值。如果我们后续要更新这个资源,可以在请求头中包含“If-Match”字段,服务器会检查ETag是否匹配。如果不匹配,服务器会返回412状态码(Precondition Failed),表示更新失败。
版本戳的四种实现方式
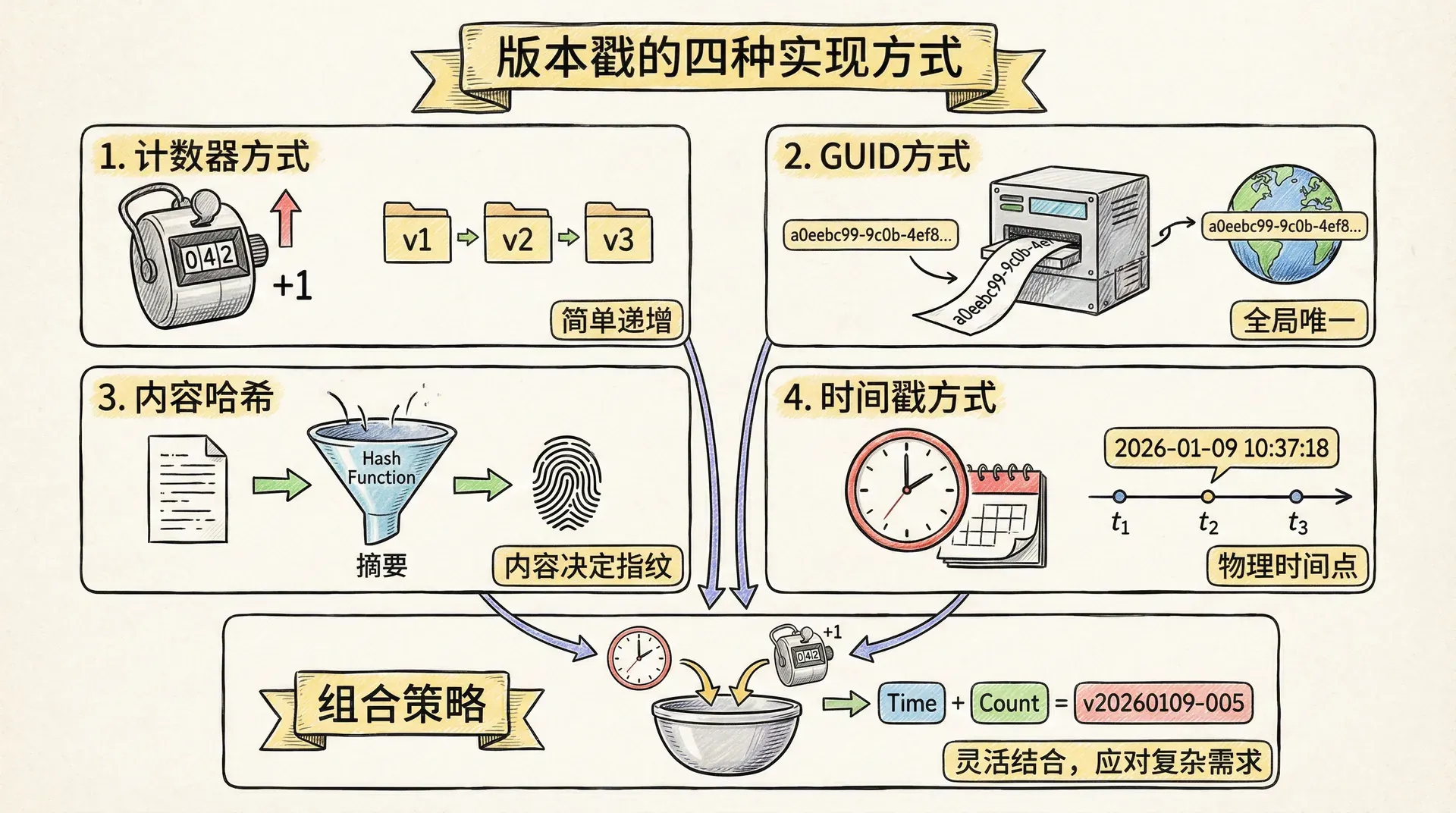
既然版本戳如此重要,那么我们该如何生成这些“时间标签”呢?不同的应用场景需要不同的版本戳策略,让我们来看看四种主要的实现方式。
计数器方式
计数器的方法非常直接易懂:只要数据有变动,版本号就+1。你可以把它想象成数据的小本子,每改一次就往上翻一页,页码自然越来越大。 比如我们做一个用户信息管理系统,每次用户修改个人资料,这个版本号就会自动递增:
javascript
// 用户资料的版本演进
const userProfile = {
userId: "user-12345",
name: "张小明",
email: "xiaoming@example.com",
version: 1 // 初始版本
}
// 用户更新邮箱
updateUserProfile(userId, { email: "newmail@example.com" })
// version 变为 2
// 用户更新姓名
updateUserProfile(userId, { name: "张大明" })
// version 变为 3计数器方式的最大优势是我们可以轻松判断哪个版本更新。版本3肯定比版本2更新,版本2肯定比版本1更新。但这种方式有一个限制:需要有一个中央服务器来生成这些递增的数字,确保不会出现重复的版本号。
GUID方式
GUID(Globally Unique Identifier,全球唯一标识符)是一串128位的随机数,能够做到全球范围内都不会重复。你可以把它理解成“数据的身份证号”,每条数据都能分到一个独一无二的标识。
javascript
// 使用GUID作为版本戳的例子
const documentVersion1 = {
content: "这是文档的第一版内容",
version: "550e8400-e29b-41d4-a716-446655440000"
}
const documentVersion2 = {
content: "这是修改后的文档内容",
version: "6ba7b810-9dad-11d1-80b4-00c04fd430c8"
}GUID的优势在于任何服务器、任何时间都可以生成,而且绝对不会重复。这对分布式系统来说非常有价值。但GUID也有缺点:它们通常很长(占用更多存储空间),而且我们无法直接比较两个GUID来判断哪个更新。
内容哈希
内容哈希就是把数据内容“压缩”成一个固定长度的字符串,你可以把它想象成每条数据独一无二的指纹。内容一样,哈希值一定一样;哪怕只改动了一个字,算出来的哈希值也会完全不同。
javascript
// 使用内容哈希作为版本戳
const article = {
title: "NoSQL数据库入门",
content: "NoSQL数据库是一种非关系型数据库...",
contentHash: "a1b2c3d4e5f6" // 根据title和content计算的哈希值
}
// 当内容发生变化时
const updatedArticle = {
title: "NoSQL数据库入门",
content: "NoSQL数据库是一种非关系型数据库,它具有高扩展性...", // 内容有所修改
contentHash: "x7y8z9w1v2u3" // 新的哈希值
}内容哈希的神奇之处在于它是确定性的——任何服务器对同样的数据都会计算出完全相同的哈希值。这在分布式系统中特别有用,因为不需要协调就能确保一致性。但和GUID一样,我们无法通过比较哈希值来判断时间先后顺序。
时间戳方式
时间戳其实就是我们熟悉的修改时间,数据每次变动,都会留下一个新的“时间脚印”。这种方法很直接,一看时间就知道哪个版本更新。
javascript
// 使用时间戳作为版本戳
const productInfo = {
name: "智能手表",
price: 299,
lastModified: "2024-03-15T10:30:00Z" // ISO格式的时间戳
}
// 价格更新后
const updatedProductInfo = {
name: "智能手表",
price: 259, // 价格降低
lastModified: "2024-03-16T14:20:00Z" // 新的时间戳
}时间戳用起来其实非常直观,容易理解,多个服务器也都能各自生成自己的时间戳。不过,这种方式也有一个很容易被忽略的问题:一旦服务器之间的时钟不一致,就可能带来麻烦。 举个例子,假如服务器A的时间比服务器B快了5分钟,那么A生成的所有时间戳看起来都比B要新,哪怕实际上B的更新更晚一点。
在分布式系统中用时间戳做版本戳时,一定要保证服务器之间时钟同步。别小看几毫秒的误差,在高并发应用场景下,一点点偏差都可能引发数据一致性的小插曲。
组合策略
聪明的数据库设计者意识到,我们可以结合多种方式的优势来创建更强大的版本戳系统。 比如,CouchDB数据库采用了计数器和内容哈希的组合。大多数情况下,我们可以通过计数器来判断版本的新旧关系,这样既高效又直观。 但当两个节点同时更新数据时(计数器相同但内容哈希不同),系统可以立即识别出冲突,并采取适当的处理措施。
javascript
// CouchDB风格的组合版本戳
const document = {
_id: "doc123",
content: "文档内容",
_rev: "3-a1b2c3d4e5f6" // "3"是计数器,"a1b2c3d4e5f6"是内容哈希
}有了这种组合方式,我们既能方便地判断版本的先后,也能利用哈希值准确检测内容冲突,两方面的优势都能兼顾到。
多节点环境
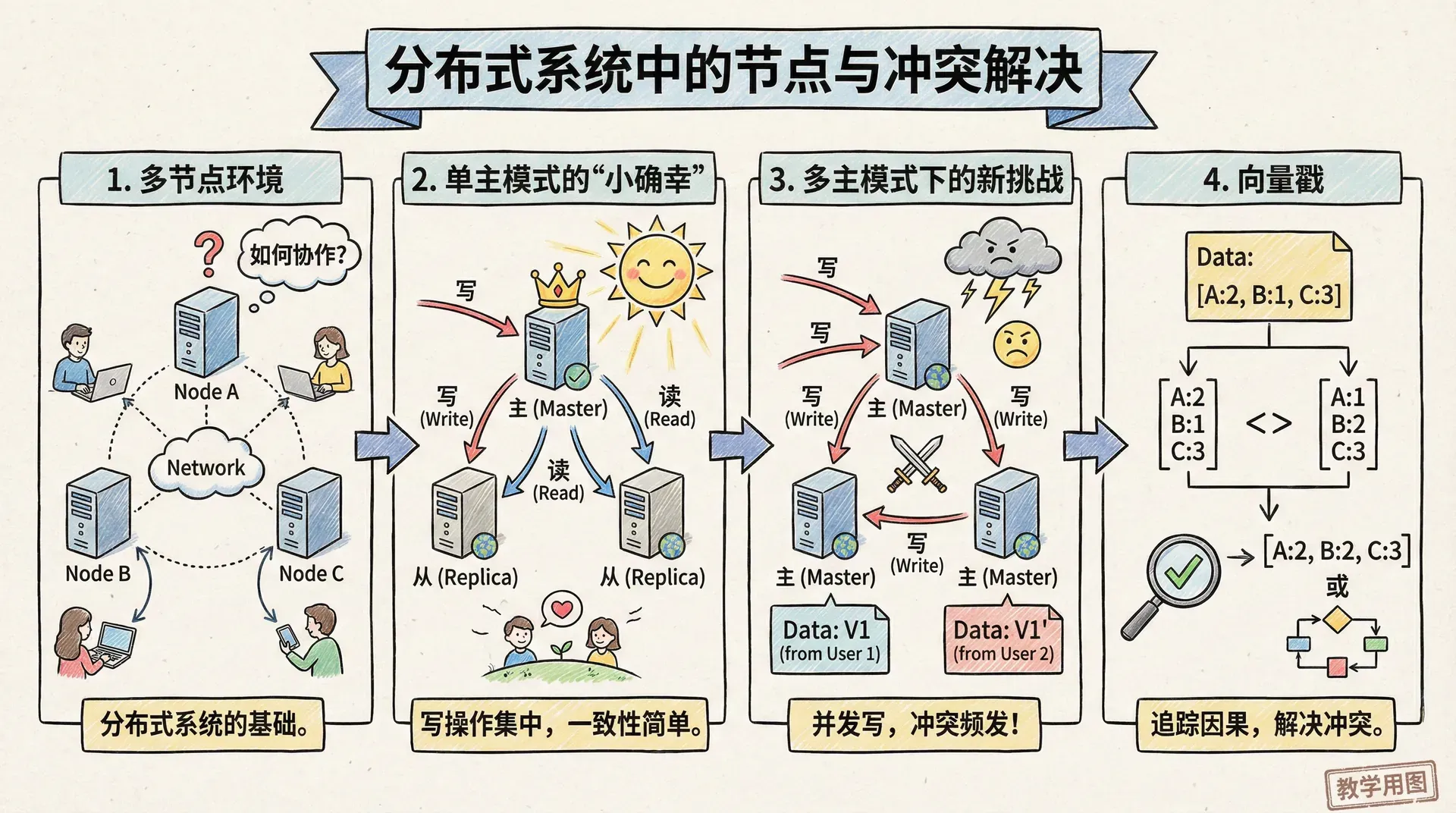
当系统只运行在一台服务器上时,版本戳的使用相对很简单。但一旦扩展到多台服务器,比如北京、上海和广州三地都在独立处理用户数据,这时候问题就开始变得有意思了。
单主模式的“小确幸”
如果我们采用单主模式,事情其实并不复杂。所有写操作都由一台主服务器来处理,其它服务器主要负责同步和备份,跟着主服务器走,主服务器的版本戳说了算。
在这种主从架构下,所有版本戳都以主服务器为准:哪怕北京的从库返回版本戳4,而上海的从库返回版本戳6,我们也能很快判断出——上海那边的数据更新过。根本原因就在于,所有变化都得经过主库确认,主是谁说了算。
多主模式下的新挑战
但如果允许多台服务器都能直接写数据,故事就有点复杂了。比如北京、上海、广州的服务器都能各自接收用户的修改请求,三地的用户互不打扰、各写各的,等要同步时才发现,光用简单的自增计数,已经搞不清谁才是“最新”的。
举个常见例子:小王在北京更新了个人资料,几乎同时,小李在上海也修改了同一份资料。于是,两台服务器分别把版本号从3加到4,但它们内容却不一样。这时,同是“4”的两个版本碰到一块,系统该怎么办?
向量戳
要解决这类问题,工程师们想出了“向量戳”的办法。和单一数字不同,向量戳实际上是每台服务器各自维护一个计数器——所有计数器合起来,就记录了每个节点各自的更新历史。
比如,如果我们有三台服务器:北京(B)、上海(S)、广州(G),那一个典型的向量戳看起来可能就是:[B:5, S:3, G:7],分别表示每台服务器本地更新的次数。
javascript
// 向量戳的数据结构
const vectorStamp = {
beijing: 5, // 北京服务器的计数器
shanghai: 3, // 上海服务器的计数器
guangzhou: 7 // 广州服务器的计数器
}向量戳的用法可以简单归纳为两条:
- 第一,自己本地有更新,就把自己的计数器加一。 比如北京服务器更新了一次,就把它自己的计数从5加到6,于是向量戳成了[B:6, S:3, G:7]。
- 第二,不同服务器互相同步时,要把对方的向量戳和自己的比一比,每项都取最大值。 这样大家的信息就能保持同步。
咱们用个具体例子来体会一下:
那么向量戳如何检测冲突呢?当我们比较两个向量戳时,会出现三种情况:
小结
版本戳作为分布式系统维护数据一致性的关键工具,通过为数据分配“时间标签”,让我们能在数据更新与事务处理中精准发现意外变更。常见的实现方式包括简单计数器、GUID、内容哈希与时间戳等,分别适用于不同的技术场景:如单主节点系统适合用计数器,分布式系统中则多采用GUID或内容哈希,而时间戳在时钟同步性好的环境中也颇为常见。
当系统进入多节点分布式阶段,单一版本戳策略已无法满足需求,此时向量戳成为冲突检测的有力助力。它通过为每个节点分别计数,能够同时识别数据变化的先后关系和并发冲突,为系统带来更强一致性保障。
版本戳让我们在NoSQL数据库的世界中,即使没有传统的ACID事务保证,也能构建出可靠、一致的应用系统。