文件与异常处理 | 自在学
文件与异常处理
在现实世界中,程序不仅需要处理我们预先设定的完美数据,更要面对各种意外情况:文件可能不存在、用户可能输入错误的数据、网络连接可能中断。
同时,为了让程序真正有用,我们需要能够保存和读取数据,让用户的工作成果不会因为程序关闭而丢失。在这一部分,我们将学习如何优雅地处理这些现实情况,
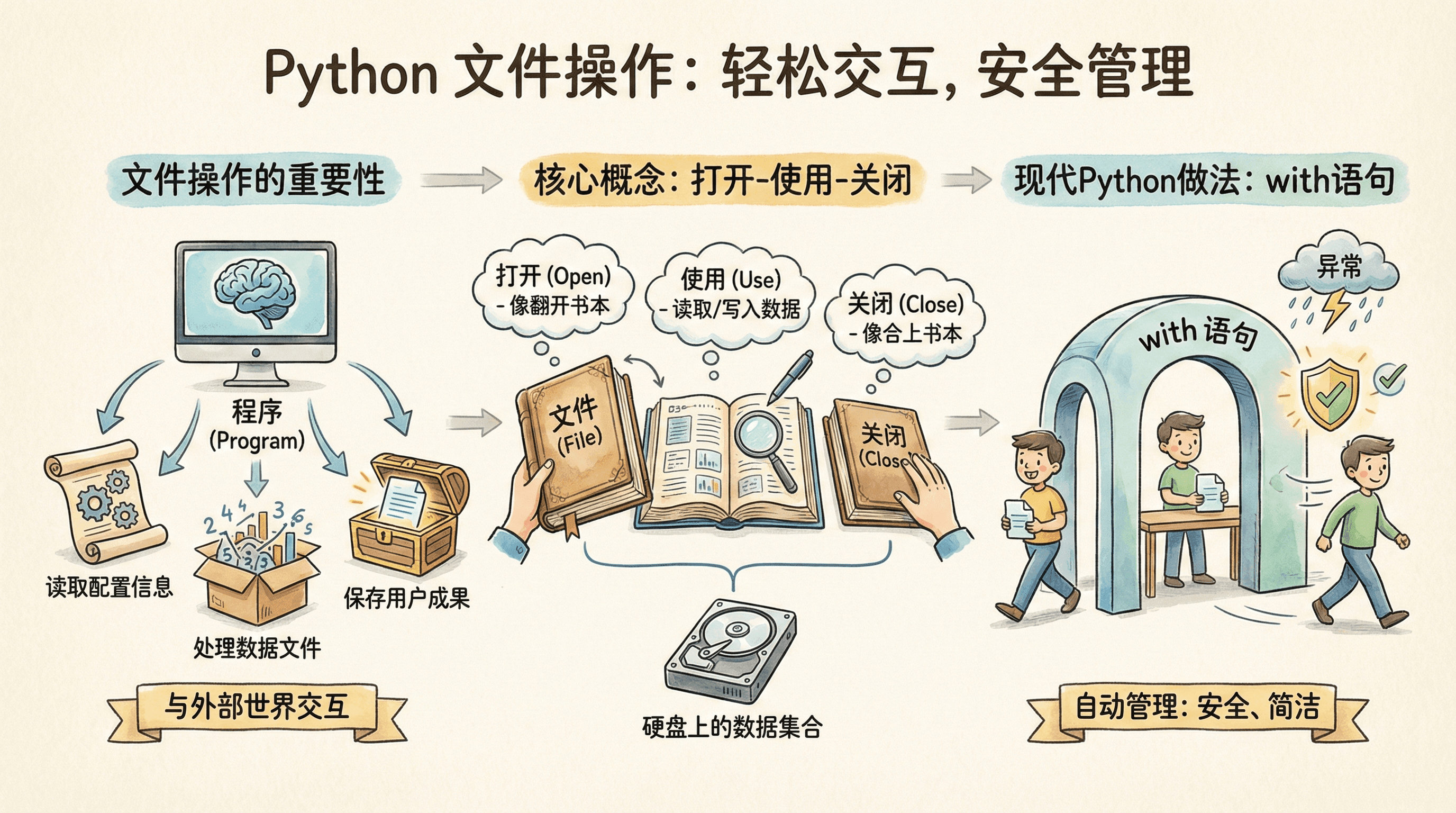
文件操作是程序与外部世界交互的重要方式。无论是读取配置信息、处理数据文件,还是保存用户的工作成果,文件操作都是不可或缺的技能。
Python提供了简洁而强大的文件操作接口,让我们能够轻松地处理各种文件相关的任务。
理解文件操作的关键在于认识到文件是存储在计算机硬盘上的数据集合。当我们的程序需要使用文件中的数据时,必须先将文件打开,
这个过程类似于打开一本书准备阅读。使用完毕后,我们需要关闭文件,就像看完书后把书合上一样。
Python的文件操作遵循打开-使用-关闭的基本模式。现代Python推荐使用with语句来处理文件,这种方式能够自动处理文件的打开和关闭,
即使在程序出现异常时也能确保文件被正确关闭,避免数据丢失或文件损坏的问题。
文件的读取操作
文件读取是数据处理的起点。通过读取文件,我们可以处理大量的文本数据、配置信息或者其他程序生成的数据。
Python提供了多种读取文件的方式,每种方式都有其适用的场景。
读取完整文件内容
最直接的文件读取方式是一次性读取文件的全部内容。这种方法适合处理相对较小的文件,能够让我们快速获得文件的完整信息。
# 创建一个示例文件用于演示 sample_content = """春天的花朵绽放了 夏天的阳光明媚 秋天的果实累累 冬天的雪花飞舞"""
# 先创建一个示例文件 with open ( 'seasons.txt' , 'w' , encoding = 'utf-8' ) as file : file .write(sample_content)
# 现在读取文件内容 with open ( 'seasons.txt' , encoding = 'utf-8' ) as file : content = file .read() print ( "文件内容:" ) print (content) 在这个例子中,with语句创建了一个文件上下文,确保文件在使用完毕后会被自动关闭。open()函数的第一个参数是文件名,
encoding='utf-8'参数指定了文件的编码格式,这对于正确处理中文字符很重要。
read()方法会读取文件的全部内容并将其作为一个字符串返回。需要注意的是,如果文件末尾有额外的空白字符,
我们可以使用rstrip()方法来清除它们:
with open ( 'seasons.txt' , encoding = 'utf-8' ) as file : content = file .read().rstrip() print (content) 文件路径的处理
在实际项目开发中,我们经常需要读取或写入存放在不同文件夹、不同层级甚至不同磁盘分区的文件。此时,理解文件路径的概念就显得尤为重要。文件路径分为绝对路径 和相对路径 两种:
绝对路径 :从磁盘根目录开始,完整地描述了文件在系统中的位置。例如:C:\Users\Alice\Documents\data.txt(Windows)或/home/alice/data.txt(Linux)。相对路径 :相对于当前程序的工作目录(即os.getcwd()返回的目录)来描述文件位置。例如:data/student_records.txt表示在当前目录下的data文件夹中的student_records.txt文件。
在编写代码时,合理选择和拼接路径非常重要。Python的os.path.join()函数可以帮助我们自动适配不同操作系统的路径分隔符,避免手动拼接路径时出错。此外,操作文件前还应确保目标目录存在,可以用os.makedirs()创建多级目录。
import os
# 相对路径示例 current_dir = os.getcwd() print ( f "当前工作目录: { current_dir } " )
# 处理不同目录中的文件 data_dir = "data" filename = "student_records.txt"
# 确保目录存在 if not os.path.exists(data_dir): os.makedirs(data_dir)
# 构建完整的文件路径 file_path = os.path.join(data_dir, filename) print ( f "文件路径: { file_path 逐行读取文件
在处理大型文件时,如果一次性将整个文件内容读入内存,可能会导致内存占用过高,甚至引发程序崩溃。此时,采用逐行读取的方式更加高效。
通过遍历文件对象,每次只读取一行内容,可以边读边处理每一行数据,无需将整个文件加载到内存中。这种方式不仅节省内存,还能方便地对每一行进行独立的处理,非常适合处理日志、配置文件等需要流式处理的场景。
# 创建一个包含多行数据的文件 diary_entries = [ "今天天气很好,适合出门散步" , "学习了Python的文件操作,收获很大" , "和朋友一起吃了午餐,聊得很开心" , "晚上看了一部有趣的电影" , "准备明天的学习计划" ]
with open ( 'diary.txt' , 'w' , encoding = 'utf-8' ) as file : for entry in diary_entries: file .write(entry + ' \n ' )
逐行读取时,每一行的末尾都包含换行符\n,通常我们需要使用rstrip()方法来去除这些不可见的字符。
这种读取方式特别适合处理日志文件、配置文件或其他结构化的文本数据。
将文件行存储为列表
在处理文件时,有些情况下我们希望在文件关闭之后依然能够访问和操作文件中的所有内容。
为此,可以在读取文件时,将文件的每一行都一次性读取出来并存储下来。
这样,文件关闭后,我们依然可以对这些内容进行各种处理,比如统计、排序或筛选等操作,而不必反复打开文件。
# 创建一个购物清单文件 shopping_items = [ "苹果 - 2公斤" , "牛奶 - 1升装" , "面包 - 全麦" , "鸡蛋 - 一打" , "香蕉 - 6根" ]
with open ( 'shopping_list.txt' , 'w' , encoding = 'utf-8' ) as file : for item in shopping_items: file .write(item + ' \n ' )
readlines()方法返回一个列表,其中每个元素都是文件中的一行。这种方法的优点是可以在文件关闭后继续操作这些数据,
适合需要多次访问或复杂处理的场景。
处理文件内容
读取文件只是第一步,真正的价值在于对文件内容进行有意义的处理。让我们看一个更实际的例子:
# 创建一个包含古诗的文件 poem_content = """静夜思 床前明月光,疑是地上霜。 举头望明月,低头思故乡。
春晓 春眠不觉晓,处处闻啼鸟。 夜来风雨声,花落知多少。"""
with open ( 'classical_poems.txt' , 'w' , encoding = 'utf-8' ) as file : file .write(poem_content)
# 分析诗歌内容 with open ( 'classical_poems.txt' , encoding = 'utf-8' ) as file : 这个例子展示了如何读取文件后进行实际的数据分析。我们不仅读取了内容,还对其进行了统计和搜索,
这种模式在处理日志分析、数据挖掘等任务中非常常见。
文件的写入操作
在编程中,文件写入是将程序中的数据保存到磁盘上的过程。比如,你可以把用户的输入、程序的运行结果,或者需要长期保存的信息写入到一个文本文件中。
这样,即使程序关闭或计算机重启,这些数据依然可以被保留和再次读取。掌握文件写入的方法,是开发实用型程序时不可或缺的能力。
写入新文件
当你需要将内容保存到一个新文件时,可以使用写入模式打开文件。此时,如果指定的文件不存在,Python 会自动创建它;
如果文件已经存在,写入操作会清空原有内容,然后写入新数据。写入操作通常通过 open 函数配合 'w' 模式实现,写入的数据必须是字符串类型。
如果你要保存数字或其他类型的数据,需要先将其转换为字符串。
# 创建一个学习日志 study_log = """Python学习日志
今天学习内容: 1. 文件读取操作 2. 异常处理基础 3. with语句的使用
心得体会: Python的文件操作比想象中简单,with语句让代码更安全。 异常处理能让程序更加健壮,用户体验更好。
明天计划: 继续学习文件写入和JSON数据处理。"""
filename = 'study_log.txt' with open (filename, 'w' , encoding = 'utf-8' ) as file : file .write(study_log)
print ( f "学习日志已保存到 { 写入模式'w'会创建新文件或覆盖已存在的文件。Python只能将字符串写入文本文件,如果需要写入数字或其他类型的数据,
必须先使用str()方法将其转换为字符串。
写入多行内容
当需要写入多行内容时,我们需要手动添加换行符来确保内容的正确格式。
# 创建一个课程安排表 course_schedule = [ "星期一:Python基础语法" , "星期二:数据结构与算法" , "星期三:文件操作与异常处理" , "星期四:面向对象编程" , "星期五:项目实践" ]
filename = 'course_schedule.txt' with open (filename, 'w' , encoding = 'utf-8' ) as file : file .write( "本周课程安排 \n " ) file .write( "=" * 在写入多行时,\n字符表示换行。我们可以使用字符串格式化、循环等技术来动态生成文件内容,
这样可以创建结构化和格式良好的文件。
追加到现有文件
有时候,我们希望在已有文件的基础上继续添加内容,而不是将原有内容清空覆盖。
这种情况下,可以通过使用追加模式来实现,即每次写入的新内容都会被加在文件的末尾,而不会影响文件中已经存在的数据。
# 先创建初始的读书记录 initial_books = """我的读书记录
已读完的书籍: 1. 《Python编程:从入门到实践》 2. 《算法图解》"""
filename = 'reading_record.txt' with open (filename, 'w' , encoding = 'utf-8' ) as file : file .write(initial_books)
print ( "初始读书记录已创建" )
# 随时间推移,追加新的读书记录 new_books = [ "3. 《代码整洁之道》" , "4. 《设计模式》" , "5. 《重构》" 追加模式'a'不会删除文件的现有内容,而是将新内容添加到文件末尾。这种模式特别适合日志记录、
数据收集等需要持续添加信息的场景。
格式化文件输出
在编写文件时,通过合理地排版、对齐文本、添加分隔线以及使用字符串格式化方法,可以让输出的内容更加清晰和美观。
例如,可以将标题居中显示,表格内容对齐,数值保留合适的小数位数,并用横线分隔不同部分,这样读者在查看文件时能够一目了然地获取关键信息。
# 创建一个格式化的学生成绩报告 students_data = [ { "name" : "张小明" , "chinese" : 85 , "math" : 92 , "english" : 78 }, { "name" : "李小红" , "chinese" : 91 , "math" : 88 , "english" : 94 }, { "name" : "王小刚" , "chinese" 这个例子展示了如何使用字符串格式化技术创建结构化的报告。通过合理使用空格、对齐、分隔线等元素,
我们可以创建既美观又易读的文件输出。
异常处理
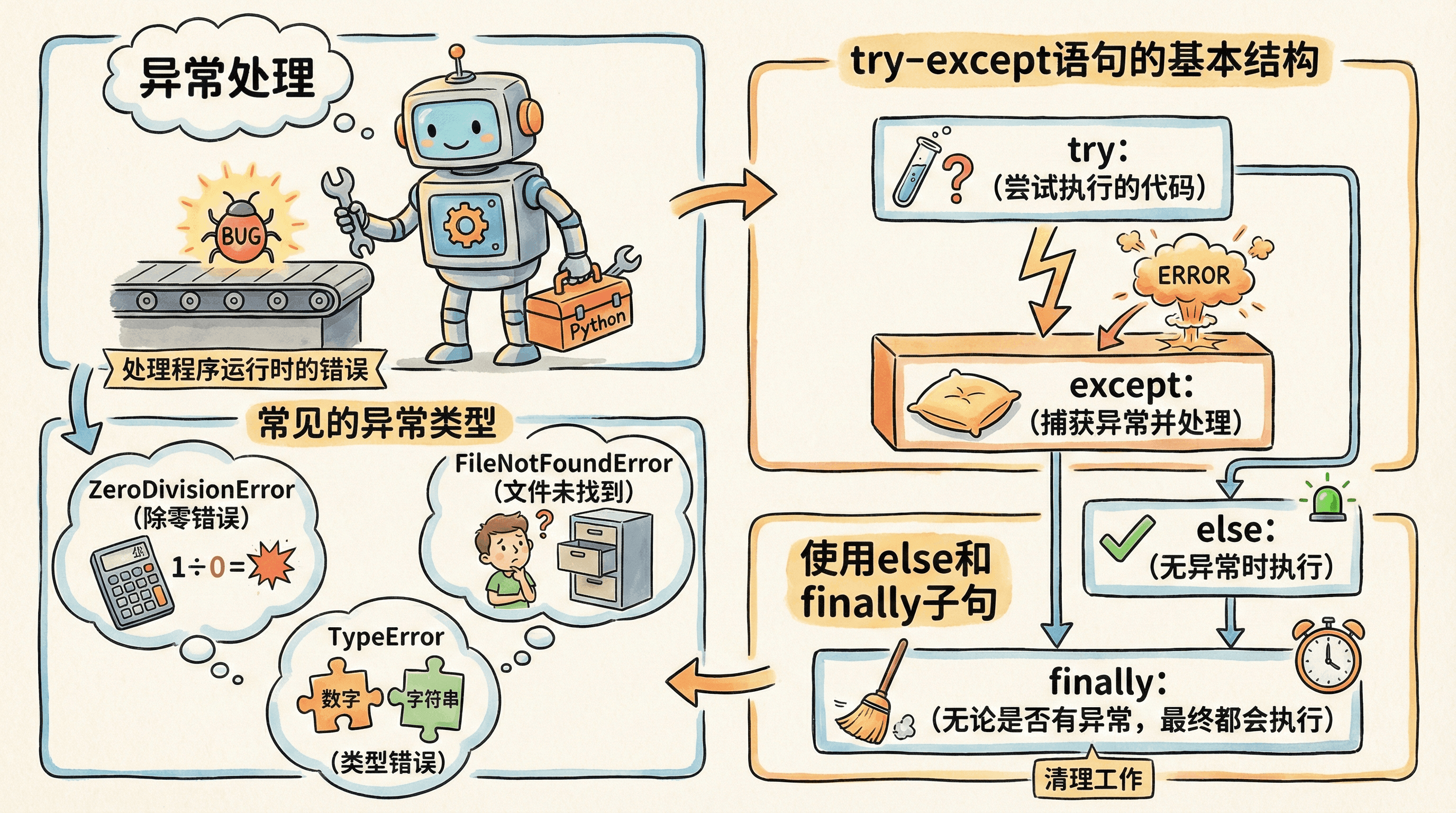
我们在语句的部分已经学习了异常处理的基本概念,在程序运行过程中,各种意外情况都可能发生:文件不存在、用户输入无效数据、网络连接中断等。如果不加处理,
这些情况会导致程序崩溃并显示令人困惑的错误信息。异常处理机制让我们能够预见这些问题并优雅地处理它们,为用户提供友好的体验。
异常是Python创建的特殊对象,用来表示程序执行过程中遇到的错误状况。当Python遇到无法处理的情况时,
它会创建一个异常对象,如果我们没有处理这个异常,程序就会停止运行并显示错误追踪信息。
异常处理的核心思想是“预防胜于治疗”。我们不能等到程序崩溃后再想办法,而应该在编写代码时就考虑可能出现的问题,
并为这些问题准备相应的处理方案。这样的程序不仅更加稳定,也能为用户提供更好的使用体验。
常见的异常类型
Python中有许多内置的异常类型,每种类型对应不同的错误情况。理解这些异常类型有助于我们更好地处理程序中的错误。
# 演示几种常见的异常情况
print ( "演示常见异常类型:" )
# 1. ZeroDivisionError - 除零错误 print ( " \n 1. 除零错误示例:" ) try : result = 10 / 0 except ZeroDivisionError : print ( "捕获到除零错误:不能用零作除数" )
# 2. ValueError - 值错误 print ( " \n 2. 值错误示例:" ) try : number = int ( try-except语句的基本结构
try-except语句是Python中处理异常的核心机制。当你希望某段代码在执行过程中即使遇到错误也不会导致程序崩溃时,可以使用try块将这段代码包裹起来。
如果try块中的代码在运行时发生了异常,程序会立即跳转到对应的except块执行,从而让你有机会对错误进行处理,比如输出提示信息、记录日志或者采取其他补救措施。
这样,程序不仅能够优雅地应对各种意外情况,还能继续后续的运行,而不是因为一个小小的错误就中断整个流程。
# 创建一个安全的计算器程序 def safe_calculator (): """一个安全的计算器,能够处理各种输入错误""" print ( "欢迎使用安全计算器!" ) print ( "支持的操作:加(+)、减(-)、乘(*)、除(/)" ) print ( "输入'quit'退出程序 \n " ) while True : try : # 获取用户输入 expression = input ( "请输入计算表达式(如:10 + 5):" ) if expression.lower() == 'quit' 使用else和finally子句
try-except语句还可以包含else和finally子句,提供更精细的控制。
else子句在没有异常发生时执行finally子句无论是否发生异常都会执行,常用于清理资源
# 演示完整的异常处理结构 def process_student_file (filename): """处理学生信息文件的完整示例""" print ( f "开始处理文件: { filename } " ) file_handle = None try : # 尝试打开文件 file_handle = open (filename, 'r' , encoding = 'utf-8' ) # 读取并处理数据 lines = file_handle.readlines() student_count 文件操作中的异常处理
在进行文件操作时,经常会遇到各种异常情况。例如,尝试打开一个文件时,如果该文件并不存在,程序就会报错;
有时候文件可能正被其他程序占用,导致无法访问;或者当前用户没有足够的权限去读取或写入某个文件。这些问题如果没有妥善处理,程序就会中断,影响用户体验。
因此,学会在文件操作中进行异常处理,是编写健壮、可靠程序的重要一环。通过合理地捕获和处理这些异常,程
序不仅能够给出友好的错误提示,还能根据实际情况采取补救措施,比如提示用户检查文件路径、自动创建缺失的文件,或者建议用户更改权限设置,从而保证程序能够平稳运行下去。
处理文件不存在的情况
在文件操作中,最常见的异常之一就是FileNotFoundError。当你尝试打开一个并不存在的文件时,Python 就会抛出这个异常。
比如,用户输入了一个错误的文件名,或者文件还没有被创建,这时如果没有进行异常处理,程序就会直接报错退出。
通过捕获FileNotFoundError,你可以给用户一个明确的提示,说明文件不存在,并引导用户检查文件名是否拼写正确、文件是否在指定目录下,或者是否需要新建该文件。
这样,程序就能更加智能和人性化地应对文件缺失的情况。
# 创建一个智能的文件阅读器 def smart_file_reader (filename): """智能文件阅读器,能够处理文件不存在的情况""" try : with open (filename, 'r' , encoding = 'utf-8' ) as file : content = file .read() return content except FileNotFoundError : print ( f "抱歉,找不到文件 ' { filename } '" ) 批量文件处理中的异常处理
当我们需要处理一批文件时,常常会遇到某些文件不存在、权限不足、编码不一致等各种问题。
如果在处理某个文件时发生了异常,而没有妥善处理,整个批量操作就会被中断,后续文件也无法继续处理。
为了保证即使某个文件出错也不会影响其他文件的分析,我们应该把异常处理语句放在循环内部。
这样,每当处理一个文件时,如果出现异常,程序会捕获并报告该文件的错误,然后自动跳过,继续处理下一个文件。
import os
def analyze_text_files (directory): """分析指定目录中所有文本文件的内容""" print ( f "开始分析目录: { directory } " ) # 检查目录是否存在 if not os.path.exists(directory): print ( f "错误:目录 ' { directory } ' 不存在" ) return # 获取所有.txt文件 txt_files = [] for filename 静默处理异常
在实际编程中,有些情况下我们并不希望因为某个错误就让整个程序中断。
例如在批量处理大量文件时,某些文件可能不存在、被占用或者格式不正确。
此时,我们可以选择在捕获到特定异常后什么都不做,让程序自动跳过出错的部分,继续处理后续任务。
这种做法被称为“静默失败”。它的核心思想是:当遇到错误时,不输出任何提示,也不抛出异常,而是让程序像什么都没发生一样继续执行。
需要注意的是,静默处理异常虽然可以提升程序的健壮性,但如果滥用,可能会掩盖潜在的问题,导致错误难以及时发现。
因此,只有在错误不会影响整体结果,或者错误是可以被安全忽略的场景下,才建议采用这种方式。
def batch_process_config_files (file_list): """批量处理配置文件,忽略无法处理的文件""" successful_configs = {} for filename in file_list: try : with open (filename, 'r' , encoding = 'utf-8' ) as file : # 假设配置文件格式为 key=value config = {} for line in file : line = 数据的持久化存储
在编写程序时,变量和数据结构中的内容通常只会保存在内存中。当程序运行结束后,这些数据就会全部消失。
如果你希望下次启动程序时还能继续使用这些数据,就需要将它们保存到磁盘文件中,实现数据的持久化。
实现持久化存储的方式有很多,其中使用JSON格式是一种非常常见且实用的方法。JSON格式不仅结构清晰、易于阅读和编辑,
而且在不同的编程语言之间也能方便地进行数据交换,非常适合用来保存程序中的配置信息、用户数据、日志等内容。
JSON格式的基本概念
JSON的全称是JavaScript对象表示法(JavaScript Object Notation),虽然最初源自JavaScript,但现在已经成为一种通用的数据描述标准。
JSON格式可以用来表达多种数据类型,包括字符串、数字、布尔值、对象(在Python中对应字典)、数组(在Python中对应列表)以及null(在Python中对应None)。
JSON的语法简洁明了,数据以键值对和有序集合的形式组织,既适合人类阅读,也方便程序自动处理。
在Python中,标准库自带了json模块,可以非常方便地实现Python对象和JSON格式之间的相互转换。
将Python对象转换为JSON字符串或写入文件的过程叫做“序列化”;而从JSON字符串或文件中还原为Python对象的过程叫做“反序列化”。
通过这两个过程,程序的数据就可以在内存和磁盘之间自由流动,实现持久化存储和跨平台的数据交换。
使用json.dump()和json.load()
在实际开发中,最常见的需求就是把Python中的数据结构保存到JSON文件中,或者从JSON文件中读取数据还原为Python对象。
json.dump()函数可以直接将Python对象写入到文件,并自动完成格式转换和编码处理。
json.load()函数则可以从文件中读取JSON内容,并自动解析为对应的Python数据结构。
通过这两个函数,你可以轻松地实现数据的保存和恢复,无需手动处理字符串格式或编码问题。
import json from datetime import datetime
# 演示基本的JSON操作 def demonstrate_json_basics (): """演示JSON的基本保存和读取操作""" # 准备要保存的数据 student_data = { "basic_info" : { "name" : "张小明" , "student_id" : "2024001" , "grade" : 10 , "class" : "A" }, "subjects" : [ 在这个例子中,我们使用了几个重要的参数:
ensure_ascii=False:允许保存中文字符indent=2:格式化输出,增加可读性
用户数据的保存和读取
在实际开发中,我们经常需要将用户的个性化设置、游戏的进度信息或者应用的当前状态保存到本地文件中。
这样做的好处是,当用户下次打开程序时,可以自动恢复到上一次的使用环境,无需重新配置。
例如,用户界面的主题颜色、字体大小、最近打开的文件列表、窗口的位置和大小等信息,都可以通过保存和读取数据文件来实现持久化。
import json import os from datetime import datetime
class UserPreferences : """用户偏好设置管理类""" def __init__ (self, username): self .username = username self .preferences_file = f " { username } _preferences.json" self .preferences = self .load_preferences() def load_preferences (self): 高级JSON应用
在实际开发过程中,随着项目的不断扩展,我们经常会遇到需要保存和读取包含嵌套结构、日期时间对象、以及自定义类型等多种复杂数据的需求。
例如,一个项目管理系统可能不仅要记录项目的基本信息,还要保存每个项目的任务列表、成员分工、进度状态以及每次更新时间等详细内容。
这些数据往往包含字典、列表、字符串、数字,甚至是 Python 的 datetime 类型对象。此时,单纯使用默认的 JSON 编码和解码方式已经无法满足需求,
我们需要通过自定义编码器和解码器,来实现对特殊类型(如日期和时间)的正确序列化和反序列化,从而保证数据的完整性和可用性。
通过这种方式,复杂的数据结构也能被安全地保存到文件中,并在需要时准确地还原回来,极大地提升了程序的数据管理能力和灵活性。
import json import os from datetime import datetime, date
class DateTimeEncoder ( json . JSONEncoder ): """自定义JSON编码器,处理日期时间对象""" def default (self, obj): if isinstance (obj, datetime): return { "_type" : "datetime" , "value" : obj.isoformat() } elif isinstance (obj, date): return { 文件操作和异常处理是编写实用程序的基础技能。掌握这些技术不仅能让你的程序更加稳定,还能为用户提供更好的体验。记住,优秀的程序不只是功能正确,更要能优雅地处理各种意外情况。
习题
A. read()
B. readline()
C. readlines()
D. scan()
A. try
B. except
C. finally
D. else
下面哪个函数用于将Python对象保存为JSON格式?
A. json.save()
B. json.dump()
C. json.write()
D. json.store()
A. FileNotFoundError
B. ValueError
C. TypeError
D. IndexError
A. with语句
B. try语句
C. if语句
D. for语句
A. json.load()
B. json.read()
C. json.get()
D. json.parse()
8. 文件读取和异常处理
编写一个程序,安全地读取文件内容,并处理文件不存在的情况。
显示答案 try : with open ( 'data.txt' , 'r' , encoding = 'utf-8' ) as file : content = file .read() print (content) except FileNotFoundError : print ( "文件不存在" ) except Exception as e: print ( f "读取文件时出错: { e } " ) 9. 异常处理练习
编写一个程序,处理除零错误和无效输入的情况。
显示答案 try : result = 10 / int ( input ( "请输入除数:" )) print ( f "结果: { result } " ) except ZeroDivisionError : print ( "不能除以零" ) except ValueError : print ( "请输入有效数字" ) except Exception as e: print ( f 10. JSON文件操作
编写一个程序,将Python字典保存为JSON文件,然后读取并显示内容。
显示答案 import json
# 写入JSON文件 data = { "name" : "张三" , "age" : 25 , "city" : "北京" } with open ( 'user.json' , 'w' , encoding = 'utf-8' ) as file : json.dump(data, file , ensure_ascii = False , indent = 2 ) }
"
)
# 创建示例数据文件
student_data = """张三,85,90,78
李四,92,88,95
王五,76,82,89"""
with open (file_path, 'w' , encoding = 'utf-8' ) as file :
file .write(student_data)
# 读取文件
with open (file_path, encoding = 'utf-8' ) as file :
records = file .read()
print ( "学生记录:" )
print (records)
# 逐行读取并处理
print ( "日记内容(逐行读取):" )
line_number = 1
with open ( 'diary.txt' , encoding = 'utf-8' ) as file :
for line in file :
cleaned_line = line.rstrip() # 去除行末的换行符
print ( f " { line_number } . { cleaned_line } " )
line_number += 1
# 读取所有行到列表中
with open ( 'shopping_list.txt' , encoding = 'utf-8' ) as file :
lines = file .readlines()
# 现在可以在文件关闭后处理这些行
print ( "购物清单:" )
total_items = len (lines)
for i, line in enumerate (lines, 1 ):
item = line.rstrip()
print ( f "第 { i } 项(共 { total_items } 项): { item } " )
# 对列表进行进一步处理
print ( " \n 按字母顺序排列的清单:" )
sorted_items = sorted ([line.rstrip() for line in lines])
for item in sorted_items:
print ( f "- { item } " )
lines
=
file
.readlines()
# 处理和分析
poem_lines = []
for line in lines:
cleaned_line = line.strip()
if cleaned_line: # 跳过空行
poem_lines.append(cleaned_line)
print ( f "总共读取了 {len (poem_lines) } 行诗句" )
print ( " \n 诗歌分析:" )
# 统计字符
total_chars = 0
for line in poem_lines:
char_count = len (line)
total_chars += char_count
print ( f "' { line } ' - { char_count } 个字符" )
print ( f " \n 平均每行字符数: { total_chars / len (poem_lines) :.1f } " )
# 查找特定字符
target_char = "月"
lines_with_target = []
for line in poem_lines:
if target_char in line:
lines_with_target.append(line)
print ( f " \n 包含' { target_char } '字的诗句:" )
for line in lines_with_target:
print ( f "- { line } " )
filename
}
"
)
# 验证文件是否正确写入
with open (filename, encoding = 'utf-8' ) as file :
content = file .read()
print ( " \n 文件内容预览:" )
print (content[: 100 ] + "..." if len (content) > 100 else content)
20
+
"
\n\n
"
)
for day, course in enumerate (course_schedule, 1 ):
file .write( f " { course }\n " )
file .write( " \n 注意事项: \n " )
file .write( "- 请按时参加课程 \n " )
file .write( "- 课前预习相关材料 \n " )
file .write( "- 完成课后练习 \n " )
print ( "课程安排表已生成" )
# 读取并显示生成的文件
with open (filename, encoding = 'utf-8' ) as file :
content = file .read()
print ( " \n 生成的课程安排表:" )
print (content)
]
with open (filename, 'a' , encoding = 'utf-8' ) as file :
file .write( " \n\n 最近新读的书籍: \n " )
for book in new_books:
file .write(book + " \n " )
file .write( f " \n 更新时间:2024年1月 \n " )
file .write( "总计:5本书" )
print ( "读书记录已更新" )
# 查看完整的读书记录
with open (filename, encoding = 'utf-8' ) as file :
complete_record = file .read()
print ( " \n 完整的读书记录:" )
print (complete_record)
:
76
,
"math"
:
85
,
"english"
:
82
},
{ "name" : "赵小丽" , "chinese" : 88 , "math" : 90 , "english" : 87 }
]
filename = 'student_grades.txt'
with open (filename, 'w' , encoding = 'utf-8' ) as file :
# 写入标题
title = "学生成绩报告"
file .write(title.center( 50 , "=" ) + " \n\n " )
# 写入表头
header = f " { '姓名' :<8 } { '语文' :>6 } { '数学' :>6 } { '英语' :>6 } { '平均分' :>8 } "
file .write(header + " \n " )
file .write( "-" * 50 + " \n " )
# 写入学生数据
total_average = 0
for student in students_data:
chinese = student[ 'chinese' ]
math = student[ 'math' ]
english = student[ 'english' ]
average = (chinese + math + english) / 3
total_average += average
line = f " { student[ 'name' ] :<8 } { chinese :>6 } { math :>6 } { english :>6 } { average :>8.1f } "
file .write(line + " \n " )
# 写入统计信息
file .write( "-" * 50 + " \n " )
class_average = total_average / len (students_data)
file .write( f "班级平均分: { class_average :.1f }\n " )
file .write( f "总人数: {len (students_data) } 人 \n " )
print ( "学生成绩报告已生成" )
# 显示生成的报告
with open (filename, encoding = 'utf-8' ) as file :
report = file .read()
print ( " \n 生成的成绩报告:" )
print (report)
"abc123"
)
except ValueError :
print ( "捕获到值错误:字符串无法转换为整数" )
# 3. IndexError - 索引错误
print ( " \n 3. 索引错误示例:" )
try :
my_list = [ 1 , 2 , 3 ]
element = my_list[ 10 ]
except IndexError :
print ( "捕获到索引错误:列表索引超出范围" )
# 4. KeyError - 键错误
print ( " \n 4. 键错误示例:" )
try :
my_dict = { "name" : "张三" , "age" : 25 }
value = my_dict[ "salary" ]
except KeyError :
print ( "捕获到键错误:字典中不存在指定的键" )
# 5. FileNotFoundError - 文件未找到错误
print ( " \n 5. 文件未找到错误示例:" )
try :
with open ( "nonexistent_file.txt" , 'r' ) as file :
content = file .read()
except FileNotFoundError :
print ( "捕获到文件未找到错误:指定的文件不存在" )
print ( " \n 所有异常都被妥善处理,程序继续正常运行。" )
:
print ( "感谢使用,再见!" )
break
# 解析表达式
parts = expression.split()
if len (parts) != 3 :
raise ValueError ( "表达式格式不正确" )
num1 = float (parts[ 0 ])
operator = parts[ 1 ]
num2 = float (parts[ 2 ])
# 执行计算
if operator == '+' :
result = num1 + num2
elif operator == '-' :
result = num1 - num2
elif operator == '*' :
result = num1 * num2
elif operator == '/' :
if num2 == 0 :
raise ZeroDivisionError ( "除数不能为零" )
result = num1 / num2
else :
raise ValueError ( f "不支持的操作符: { operator } " )
print ( f "计算结果: { num1 } { operator } { num2 } = { result }\n " )
except ValueError as e:
print ( f "输入错误: { e } " )
print ( "请检查输入格式是否正确 \n " )
except ZeroDivisionError as e:
print ( f "计算错误: { e } " )
print ( "请使用非零数作为除数 \n " )
except Exception as e:
print ( f "发生了未预期的错误: { e } " )
print ( "请重新输入 \n " )
# 运行计算器(在实际环境中取消注释)
# safe_calculator()
# 演示计算器的错误处理能力
test_cases = [
"10 + 5" ,
"20 / 0" ,
"abc + 5" ,
"10 * " ,
"15 % 3"
]
print ( "测试安全计算器的错误处理:" )
for test_case in test_cases:
print ( f " \n 测试输入: { test_case } " )
try :
parts = test_case.split()
if len (parts) != 3 :
raise ValueError ( "表达式格式不正确" )
num1 = float (parts[ 0 ])
operator = parts[ 1 ]
num2 = float (parts[ 2 ])
if operator == '+' :
result = num1 + num2
elif operator == '/' :
if num2 == 0 :
raise ZeroDivisionError ( "除数不能为零" )
result = num1 / num2
else :
raise ValueError ( f "不支持的操作符: { operator } " )
print ( f "结果: { result } " )
except ValueError as e:
print ( f "输入错误: { e } " )
except ZeroDivisionError as e:
print ( f "计算错误: { e } " )
=
0
valid_records = []
for line_num, line in enumerate (lines, 1 ):
line = line.strip()
if not line or line.startswith( '#' ): # 跳过空行和注释
continue
try :
# 解析学生信息:姓名,年龄,成绩
parts = line.split( ',' )
if len (parts) != 3 :
raise ValueError ( f "第 { line_num } 行格式错误" )
name = parts[ 0 ].strip()
age = int (parts[ 1 ].strip())
score = float (parts[ 2 ].strip())
if age < 0 or age > 150 :
raise ValueError ( f "第 { line_num } 行年龄无效" )
if score < 0 or score > 100 :
raise ValueError ( f "第 { line_num } 行成绩无效" )
valid_records.append({
'name' : name,
'age' : age,
'score' : score
})
student_count += 1
except ValueError as e:
print ( f "数据错误: { e } " )
continue
except FileNotFoundError :
print ( f "错误:找不到文件 { filename } " )
return None
except PermissionError :
print ( f "错误:没有权限访问文件 { filename } " )
return None
except Exception as e:
print ( f "意外错误: { e } " )
return None
else :
# 只有在没有异常时才执行
print ( f "文件读取成功!共处理 { student_count } 条有效记录" )
# 计算统计信息
if valid_records:
average_age = sum (record[ 'age' ] for record in valid_records) / len (valid_records)
average_score = sum (record[ 'score' ] for record in valid_records) / len (valid_records)
print ( f "平均年龄: { average_age :.1f } 岁" )
print ( f "平均成绩: { average_score :.1f } 分" )
return valid_records
else :
print ( "没有找到有效的学生记录" )
return []
finally :
# 无论是否发生异常都会执行
if file_handle:
file_handle.close()
print ( "文件已关闭" )
print ( "文件处理完成 \n " )
# 创建测试文件
test_data = """# 学生信息文件
# 格式:姓名,年龄,成绩
张三,20,85
李四,19,92
王五,21,78
赵六,abc,88
钱七,20,150
孙八,22,95"""
with open ( 'students.txt' , 'w' , encoding = 'utf-8' ) as f:
f.write(test_data)
# 测试文件处理
result = process_student_file( 'students.txt' )
if result:
print ( "处理结果:" )
for student in result:
print ( f "- { student[ 'name' ] } : { student[ 'age' ] } 岁, { student[ 'score' ] } 分" )
# 测试不存在的文件
process_student_file( 'nonexistent.txt' )
# 提供帮助信息
print ( "可能的原因:" )
print ( "1. 文件名拼写错误" )
print ( "2. 文件位于其他目录" )
print ( "3. 文件还未创建" )
# 尝试创建默认文件
user_choice = input ( "是否创建一个默认文件?(y/n): " )
if user_choice.lower() == 'y' :
default_content = f """这是自动创建的 { filename } 文件
您可以编辑这个文件,添加您需要的内容。
创建时间:2024年1月
"""
try :
with open (filename, 'w' , encoding = 'utf-8' ) as file :
file .write(default_content)
print ( f "默认文件 ' { filename } ' 已创建成功!" )
return default_content
except PermissionError :
print ( "创建文件失败:权限不足" )
return None
else :
return None
except PermissionError :
print ( f "错误:没有权限读取文件 ' { filename } '" )
return None
except UnicodeDecodeError :
print ( f "错误:文件 ' { filename } ' 的编码格式不正确" )
print ( "尝试使用其他编码格式..." )
# 尝试常见的编码格式
encodings = [ 'gbk' , 'gb2312' , 'latin1' ]
for encoding in encodings:
try :
with open (filename, 'r' , encoding = encoding) as file :
content = file .read()
print ( f "成功使用 { encoding } 编码读取文件" )
return content
except UnicodeDecodeError :
continue
print ( "无法确定文件编码格式" )
return None
# 测试智能文件阅读器
test_files = [ 'existing_file.txt' , 'missing_file.txt' , 'diary.txt' ]
for filename in test_files:
print ( f " \n{ '=' * 50} " )
print ( f "尝试读取文件: { filename } " )
print ( '=' * 50 )
# 为了演示,先创建一个测试文件
if filename == 'existing_file.txt' :
with open (filename, 'w' , encoding = 'utf-8' ) as f:
f.write( "这是一个存在的测试文件 \n 包含一些示例内容。" )
content = smart_file_reader(filename)
if content:
print ( "文件内容预览:" )
preview = content[: 100 ] + "..." if len (content) > 100 else content
print (preview)
in
os.listdir(directory):
if filename.endswith( '.txt' ):
txt_files.append(filename)
if not txt_files:
print ( "该目录中没有找到任何.txt文件" )
return
print ( f "找到 {len (txt_files) } 个文本文件" )
successful_count = 0
failed_count = 0
total_words = 0
total_lines = 0
for filename in txt_files:
file_path = os.path.join(directory, filename)
print ( f " \n 正在处理: { filename } " )
try :
with open (file_path, 'r' , encoding = 'utf-8' ) as file :
content = file .read()
lines = content.split( ' \n ' )
words = content.split()
print ( f " 行数: {len (lines) } " )
print ( f " 单词数: {len (words) } " )
print ( f " 字符数: {len (content) } " )
total_words += len (words)
total_lines += len (lines)
successful_count += 1
except FileNotFoundError :
print ( f " 错误:文件不存在" )
failed_count += 1
except PermissionError :
print ( f " 错误:权限不足" )
failed_count += 1
except UnicodeDecodeError :
print ( f " 错误:编码格式不支持" )
failed_count += 1
except Exception as e:
print ( f " 意外错误: { e } " )
failed_count += 1
# 输出总结
print ( f " \n{ '=' * 40} " )
print ( "处理总结:" )
print ( f "成功处理: { successful_count } 个文件" )
print ( f "处理失败: { failed_count } 个文件" )
if successful_count > 0 :
print ( f "总计行数: { total_lines } " )
print ( f "总计单词数: { total_words } " )
print ( f "平均每文件单词数: { total_words / successful_count :.1f } " )
# 创建测试环境
test_dir = "text_files"
if not os.path.exists(test_dir):
os.makedirs(test_dir)
# 创建几个测试文件
test_files_content = {
"story1.txt" : "从前有座山,山上有座庙,庙里有个老和尚。 \n 老和尚在给小和尚讲故事。" ,
"story2.txt" : "小红帽的故事大家都知道。 \n 她要去看望生病的奶奶。" ,
"notes.txt" : "今天学习了Python文件操作。 \n 异常处理很重要。 \n 要多练习。" ,
"poem.txt" : "床前明月光,疑是地上霜。 \n 举头望明月,低头思故乡。"
}
for filename, content in test_files_content.items():
file_path = os.path.join(test_dir, filename)
with open (file_path, 'w' , encoding = 'utf-8' ) as f:
f.write(content)
# 运行分析
analyze_text_files(test_dir)
line.strip()
if line and not line.startswith( '#' ):
if '=' in line:
key, value = line.split( '=' , 1 )
config[key.strip()] = value.strip()
successful_configs[filename] = config
except FileNotFoundError :
# 静默忽略不存在的文件
pass
except PermissionError :
# 静默忽略没有权限的文件
pass
except Exception :
# 静默忽略其他错误
pass
return successful_configs
# 创建测试配置文件
config_files = [ "app.conf" , "database.conf" , "cache.conf" ]
# 创建一些测试配置
configs = {
"app.conf" : """# 应用配置
app_name=我的应用
version=1.0
debug=false""" ,
"database.conf" : """# 数据库配置
host=localhost
port=3306
username=admin"""
}
for filename, content in configs.items():
with open (filename, 'w' , encoding = 'utf-8' ) as f:
f.write(content)
# 测试批量处理(包括不存在的文件)
all_files = [ "app.conf" , "database.conf" , "cache.conf" , "missing.conf" ]
result = batch_process_config_files(all_files)
print ( "成功加载的配置文件:" )
for filename, config in result.items():
print ( f " \n{ filename } :" )
for key, value in config.items():
print ( f " { key } = { value } " )
print ( f " \n 总共处理了 {len (all_files) } 个文件" )
print ( f "成功加载了 {len (result) } 个配置文件" )
{
"name"
:
"语文"
,
"score"
:
85
,
"teacher"
:
"李老师"
},
{ "name" : "数学" , "score" : 92 , "teacher" : "王老师" },
{ "name" : "英语" , "score" : 78 , "teacher" : "Smith" }
],
"activities" : [ "篮球社" , "编程俱乐部" , "学生会" ],
"is_monitor" : True ,
"total_credits" : 30
}
# 保存数据到JSON文件
filename = "student_profile.json"
print ( "正在保存学生数据..." )
try :
with open (filename, 'w' , encoding = 'utf-8' ) as file :
json.dump(student_data, file , ensure_ascii = False , indent = 2 )
print ( f "数据已成功保存到 { filename } " )
except Exception as e:
print ( f "保存失败: { e } " )
return
# 从JSON文件读取数据
print ( " \n 正在读取学生数据..." )
try :
with open (filename, 'r' , encoding = 'utf-8' ) as file :
loaded_data = json.load( file )
print ( "数据读取成功!" )
# 验证数据完整性
if loaded_data == student_data:
print ( "数据完整性验证通过" )
else :
print ( "警告:读取的数据与原始数据不一致" )
# 显示读取的数据
print ( " \n 学生信息:" )
basic_info = loaded_data[ "basic_info" ]
print ( f "姓名: { basic_info[ 'name' ] } " )
print ( f "学号: { basic_info[ 'student_id' ] } " )
print ( f "年级: { basic_info[ 'grade' ] } " )
print ( f "班级: { basic_info[ 'class' ] } " )
print ( " \n 科目成绩:" )
for subject in loaded_data[ "subjects" ]:
print ( f "- { subject[ 'name' ] } : { subject[ 'score' ] } 分( { subject[ 'teacher' ] } )" )
print ( f " \n 课外活动: { ', ' .join(loaded_data[ 'activities' ]) } " )
print ( f "是否班长: { '是' if loaded_data[ 'is_monitor' ] else '否' } " )
print ( f "总学分: { loaded_data[ 'total_credits' ] } " )
except FileNotFoundError :
print ( "错误:找不到数据文件" )
except json.JSONDecodeError as e:
print ( f "JSON格式错误: { e } " )
except Exception as e:
print ( f "读取失败: { e } " )
demonstrate_json_basics()
"""加载用户偏好设置"""
default_preferences = {
"username" : self .username,
"theme" : "light" ,
"language" : "zh-CN" ,
"font_size" : 12 ,
"auto_save" : True ,
"notification_enabled" : True ,
"recent_files" : [],
"window_size" : { "width" : 800 , "height" : 600 },
"last_login" : None ,
"login_count" : 0
}
try :
with open ( self .preferences_file, 'r' , encoding = 'utf-8' ) as file :
saved_preferences = json.load( file )
# 合并默认设置和保存的设置
for key, value in default_preferences.items():
if key not in saved_preferences:
saved_preferences[key] = value
print ( f "成功加载 {self .username } 的偏好设置" )
return saved_preferences
except FileNotFoundError :
print ( f "首次使用,为 {self .username } 创建默认设置" )
self .save_preferences(default_preferences)
return default_preferences
except json.JSONDecodeError:
print ( "偏好设置文件损坏,使用默认设置" )
return default_preferences
def save_preferences (self, preferences = None ):
"""保存用户偏好设置"""
if preferences is None :
preferences = self .preferences
try :
with open ( self .preferences_file, 'w' , encoding = 'utf-8' ) as file :
json.dump(preferences, file , ensure_ascii = False , indent = 2 )
print ( "偏好设置已保存" )
except Exception as e:
print ( f "保存设置失败: { e } " )
def update_preference (self, key, value):
"""更新单个偏好设置"""
self .preferences[key] = value
self .save_preferences()
print ( f "已更新设置: { key } = { value } " )
def add_recent_file (self, filepath):
"""添加最近使用的文件"""
recent_files = self .preferences[ "recent_files" ]
# 如果文件已存在,先移除
if filepath in recent_files:
recent_files.remove(filepath)
# 添加到列表开头
recent_files.insert( 0 , filepath)
# 保持最多10个最近文件
if len (recent_files) > 10 :
recent_files = recent_files[: 10 ]
self .preferences[ "recent_files" ] = recent_files
self .save_preferences()
def record_login (self):
"""记录登录信息"""
self .preferences[ "last_login" ] = datetime.now().isoformat()
self .preferences[ "login_count" ] += 1
self .save_preferences()
def get_preference (self, key, default = None ):
"""获取偏好设置值"""
return self .preferences.get(key, default)
def display_preferences (self):
"""显示当前偏好设置"""
print ( f " \n{self .username } 的偏好设置:" )
print ( "-" * 30 )
for key, value in self .preferences.items():
if key == "recent_files" :
print ( f " { key } : {len (value) } 个最近文件" )
for i, file in enumerate (value[: 3 ], 1 ):
print ( f " { i } . { file } " )
if len (value) > 3 :
print ( f " ... 还有 {len (value) - 3} 个文件" )
else :
print ( f " { key } : { value } " )
# 演示用户偏好设置系统
def demo_user_preferences ():
"""演示用户偏好设置系统"""
print ( "=== 用户偏好设置系统演示 === \n " )
# 创建用户实例
user1 = UserPreferences( "张小明" )
user1.record_login()
# 修改一些设置
user1.update_preference( "theme" , "dark" )
user1.update_preference( "font_size" , 14 )
user1.update_preference( "language" , "en-US" )
# 添加最近使用的文件
recent_files = [
"项目计划.docx" ,
"学习笔记.txt" ,
"代码备份.py" ,
"会议记录.md"
]
for file in recent_files:
user1.add_recent_file( file )
# 显示当前设置
user1.display_preferences()
print ( " \n " + "=" * 50 )
# 模拟另一个用户
user2 = UserPreferences( "李小红" )
user2.record_login()
user2.update_preference( "notification_enabled" , False )
user2.add_recent_file( "数据分析.xlsx" )
user2.display_preferences()
print ( " \n 重新加载用户1的设置(模拟程序重启):" )
user1_reload = UserPreferences( "张小明" )
user1_reload.display_preferences()
demo_user_preferences()
"_type" : "date" ,
"value" : obj.isoformat()
}
return super ().default(obj)
def datetime_decoder (dct):
"""自定义JSON解码器,还原日期时间对象"""
if "_type" in dct:
if dct[ "_type" ] == "datetime" :
return datetime.fromisoformat(dct[ "value" ])
elif dct[ "_type" ] == "date" :
return date.fromisoformat(dct[ "value" ])
return dct
class ProjectManager :
"""项目管理系统示例"""
def __init__ (self, data_file = "projects.json" ):
self .data_file = data_file
self .projects = self .load_projects()
def load_projects (self):
"""加载项目数据"""
try :
with open ( self .data_file, 'r' , encoding = 'utf-8' ) as file :
data = json.load( file , object_hook = datetime_decoder)
print ( f "成功加载 {len (data) } 个项目" )
return data
except FileNotFoundError :
print ( "首次运行,创建新的项目数据库" )
return []
except json.JSONDecodeError as e:
print ( f "数据文件损坏: { e } " )
backup_file = f " {self .data_file } .backup"
if os.path.exists(backup_file):
print ( "尝试从备份文件恢复..." )
try :
with open (backup_file, 'r' , encoding = 'utf-8' ) as file :
return json.load( file , object_hook = datetime_decoder)
except :
pass
print ( "使用空数据库" )
return []
def save_projects (self):
"""保存项目数据"""
try :
# 创建备份
if os.path.exists( self .data_file):
backup_file = f " {self .data_file } .backup"
with open ( self .data_file, 'r' , encoding = 'utf-8' ) as src:
with open (backup_file, 'w' , encoding = 'utf-8' ) as dst:
dst.write(src.read())
# 保存当前数据
with open ( self .data_file, 'w' , encoding = 'utf-8' ) as file :
json.dump( self .projects, file , cls = DateTimeEncoder,
ensure_ascii = False , indent = 2 )
print ( "项目数据已保存" )
except Exception as e:
print ( f "保存失败: { e } " )
def add_project (self, name, description, deadline = None ):
"""添加新项目"""
project = {
"id" : len ( self .projects) + 1 ,
"name" : name,
"description" : description,
"created_date" : datetime.now(),
"deadline" : deadline,
"status" : "planning" ,
"tasks" : [],
"team_members" : []
}
self .projects.append(project)
self .save_projects()
print ( f "已添加项目: { name } " )
return project[ "id" ]
def add_task (self, project_id, task_name, assigned_to = None ):
"""为项目添加任务"""
project = self .get_project(project_id)
if project:
task = {
"id" : len (project[ "tasks" ]) + 1 ,
"name" : task_name,
"assigned_to" : assigned_to,
"created_date" : datetime.now(),
"completed" : False
}
project[ "tasks" ].append(task)
self .save_projects()
print ( f "已为项目 ' { project[ 'name' ] } ' 添加任务: { task_name } " )
def get_project (self, project_id):
"""获取指定项目"""
for project in self .projects:
if project[ "id" ] == project_id:
return project
return None
def list_projects (self):
"""列出所有项目"""
if not self .projects:
print ( "暂无项目" )
return
print ( " \n 项目列表:" )
print ( "-" * 80 )
for project in self .projects:
deadline_str = ""
if project[ "deadline" ]:
deadline_str = f "截止: { project[ 'deadline' ].strftime( '%Y-%m- %d ' ) } "
print ( f "ID: { project[ 'id' ] } " )
print ( f "名称: { project[ 'name' ] } " )
print ( f "状态: { project[ 'status' ] } " )
print ( f "任务数: {len (project[ 'tasks' ]) } " )
print ( f "创建时间: { project[ 'created_date' ].strftime( '%Y-%m- %d %H:%M' ) } " )
if deadline_str:
print (deadline_str)
print ( "-" * 40 )
# 演示项目管理系统
def demo_project_manager ():
"""演示项目管理系统"""
print ( "=== 项目管理系统演示 === \n " )
pm = ProjectManager()
# 添加一些示例项目
project1_id = pm.add_project(
"网站重新设计" ,
"重新设计公司官网,提升用户体验" ,
date( 2024 , 3 , 15 )
)
project2_id = pm.add_project(
"移动应用开发" ,
"开发iOS和Android版本的移动应用"
)
# 为项目添加任务
pm.add_task(project1_id, "用户需求调研" , "张设计师" )
pm.add_task(project1_id, "界面原型设计" , "张设计师" )
pm.add_task(project1_id, "前端开发" , "李程序员" )
pm.add_task(project2_id, "技术方案设计" , "王架构师" )
pm.add_task(project2_id, "UI设计" , "赵设计师" )
# 显示项目列表
pm.list_projects()
print ( " \n 重新加载数据(模拟程序重启)..." )
pm2 = ProjectManager()
pm2.list_projects()
demo_project_manager()
'r'是只读模式,用于读取文件file.read()一次性读取文件的全部内容FileNotFoundError捕获文件不存在的异常with语句确保文件在使用后自动关闭 "发生错误:
{
e
}
"
)
ZeroDivisionError捕获除零错误ValueError捕获类型转换错误(如int('abc'))可以添加多个except子句处理不同类型的异常
print ( "数据已保存到user.json" )
# 读取JSON文件
try :
with open ( 'user.json' , 'r' , encoding = 'utf-8' ) as file :
loaded_data = json.load( file )
print ( "从文件读取的数据:" )
print ( f "姓名: { loaded_data[ 'name' ] } " )
print ( f "年龄: { loaded_data[ 'age' ] } " )
print ( f "城市: { loaded_data[ 'city' ] } " )
except FileNotFoundError :
print ( "文件不存在" )
except json.JSONDecodeError:
print ( "JSON格式错误" )
数据已保存到user.json
从文件读取的数据:
姓名:张三
年龄:25
城市:北京
json.dump()将Python对象写入JSON文件ensure_ascii=False确保中文字符正确保存indent=2使JSON文件格式化,更易读json.load()从JSON文件读取数据并转换为Python对象