核心 RESTful API 模式
设计模式是软件工程领域中解决常见问题的可复用方案。在 RESTful API 的设计中,同样存在一系列经过实践验证的模式,它们为开发者提供了应对各种典型场景的标准化解决方案。
掌握这些核心模式不仅能够帮助你更快地做出设计决策,还能确保你的 API 符合行业惯例,降低使用者的学习成本。 这节课我们将学习在 RESTful API 设计中最常用的核心模式,从基础的 CRUD 操作到复杂的资源关系处理,逐一剖析每种模式的适用场景、实现要点和注意事项。
CRUD 操作模式
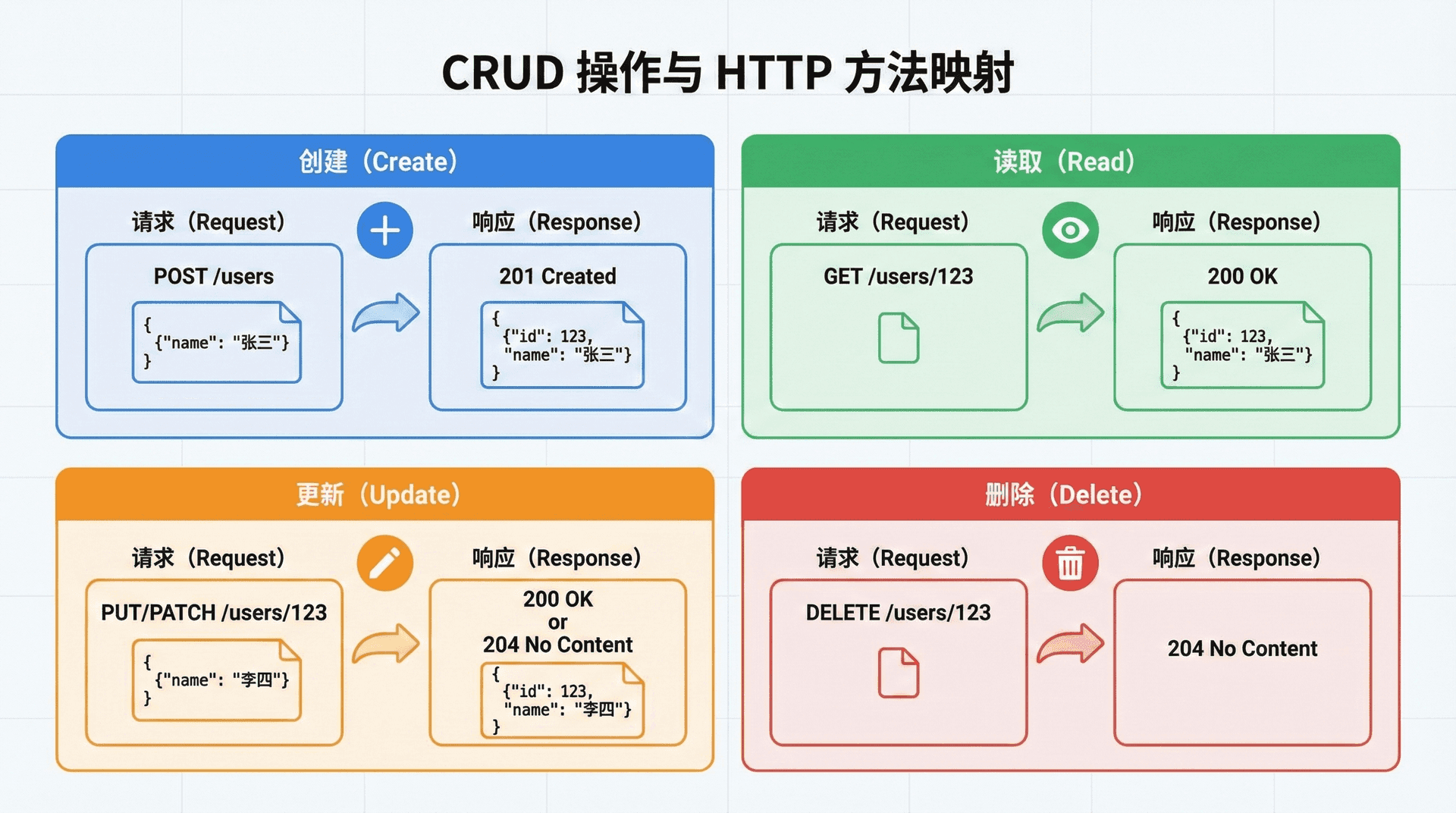
CRUD 是 Create(创建)、Read(读取)、Update(更新)、Delete(删除)四个单词的首字母缩写,代表了对数据进行操作的四种基本类型。 在 RESTful API 的世界中,CRUD 操作与 HTTP 方法形成了自然的映射关系,这种映射是如此直观和优雅,以至于许多开发者将 RESTful API 简单地理解为"CRUD over HTTP"。
虽然这种理解过于简化,但 CRUD 操作确实构成了大多数 API 的基础功能。理解如何正确实现 CRUD 操作是掌握 RESTful API 设计的第一步。
创建资源
创建新资源通常使用 POST 方法向资源集合端点发送请求。请求体中包含新资源的属性数据,服务器在成功创建资源后返回 201 Created 状态码,响应体中包含新创建资源的完整表述,响应头中的 Location 字段指向新资源的 URI。
这种设计背后有着深思熟虑的考量。返回新创建资源的完整表述使得客户端可以立即获得服务器可能添加或修改的字段,如自动生成的 ID、创建时间戳、默认值等,而不需要再发起一次 GET 请求。Location 头部提供了新资源的规范位置,这对于需要对新资源进行后续操作的客户端非常有用。
在某些场景下,资源的创建可能涉及复杂的业务逻辑和验证规则。当验证失败时,API 应该返回 400 Bad Request 或 422 Unprocessable Entity 状态码,并在响应体中提供详细的错误信息,说明哪些字段不满足要求以及具体原因。这种详尽的错误反馈能够帮助客户端快速定位和修正问题。
关于 POST 请求的幂等性,默认情况下 POST 不是幂等的,每次请求都可能创建一个新资源。然而在某些业务场景中,如支付订单的创建,我们需要防止因网络问题导致的重复创建。解决这个问题的常见方法是引入幂等键机制:客户端在请求头中携带一个唯一的幂等键,服务器记录这个键与操作结果的关联,当收到相同幂等键的重复请求时,直接返回之前的结果而不重新执行创建操作。
读取资源
读取操作使用 GET 方法,这是 HTTP 中最简单也是使用最频繁的方法。GET 请求应该是安全和幂等的,意味着它不会对服务器状态产生任何副作用,多次执行相同请求应该返回相同的结果。
读取单个资源时,客户端向资源的唯一 URI 发送 GET 请求,服务器返回该资源的表述。如果资源存在,返回 200 OK 和资源数据;如果资源不存在,返回 404 Not Found。响应中应该包含适当的缓存控制头部,使得客户端和中间代理可以缓存响应以提高性能。
读取资源集合时,客户端向集合端点发送 GET 请求。由于集合可能包含大量资源,分页几乎是必须的功能。响应中除了包含当前页的资源列表外,还应该包含分页元数据,如总数量、当前页码、每页大小,以及导航到其他页面的链接。
条件请求是优化读取操作的重要机制。客户端可以在请求中包含 If-None-Match(携带之前响应的 ETag 值)或 If-Modified-Since(携带之前响应的最后修改时间)头部,服务器在资源未发生变化时返回 304 Not Modified 而不传输响应体,从而节省带宽和处理时间。
更新资源
更新资源可以使用 PUT 或 PATCH 方法,两者的语义有着重要的区别。PUT 用于完整替换资源的表述,请求体应该包含资源的所有属性,未包含的属性将被设置为空值或默认值。PATCH 用于部分更新,请求体只需要包含要修改的属性。
PUT 的完整替换语义意味着客户端需要先获取资源的当前状态,修改需要变更的字段,然后将完整的资源表述发送回服务器。这种方式简单明确,但在只需要修改个别字段时会传输大量不必要的数据。PUT 请求是幂等的,因为多次执行相同的 PUT 请求,资源的最终状态是确定的。
PATCH 的部分更新语义更加灵活和高效,特别适合只需要修改资源少数属性的场景。然而,PATCH 请求体的格式需要能够明确表达修改意图。JSON Merge Patch 是一种简单直观的格式,客户端只需发送包含要修改字段的 JSON 对象,服务器将其与现有资源合并。JSON Patch 则是一种更强大的格式,它定义了一系列操作指令,支持添加、删除、替换、移动、复制、测试等操作,能够表达更复杂的修改逻辑。
更新操作应该返回更新后资源的完整表述,使客户端能够看到服务器端可能进行的任何额外修改。如果更新涉及乐观锁并发控制,客户端应该在请求中携带资源的版本号(通过 If-Match 头部传递 ETag),服务器在版本不匹配时返回 409 Conflict 状态码。
删除资源
删除资源使用 DELETE 方法。成功删除后,服务器可以返回 204 No Content(无响应体)或 200 OK(响应体包含被删除资源的最后状态)。DELETE 请求是幂等的,对同一资源多次执行 DELETE,资源的最终状态都是"不存在"。
在实现删除操作时,需要考虑几个重要问题。首先是软删除与硬删除的选择。软删除只是将资源标记为已删除,数据仍然保留在数据库中,可以支持数据恢复和审计追踪。硬删除则是真正从数据库中移除数据。这个选择取决于业务需求,但从 API 的角度来看,两种实现对客户端应该是透明的。
其次是级联删除的处理。当一个资源被删除时,与之关联的子资源应该如何处理?是一同删除、断开关联、还是阻止删除?这需要根据具体的业务规则来决定,并在 API 文档中清晰说明。
最后是关于删除不存在资源的响应。从幂等性的角度看,删除一个不存在的资源应该返回成功(204 或 200),因为期望的最终状态(资源不存在)已经达成。但也有观点认为应该返回 404 Not Found,因为请求的资源确实不存在。两种做法都有支持者,关键是在 API 中保持一致。
资源集合模式
资源很少孤立存在,它们通常以集合的形式组织在一起。资源集合模式定义了如何设计和操作一组同类型资源的 API 端点。
集合与单个资源的 URI 设计
集合资源和单个资源应该有清晰区分的 URI 结构。集合端点使用复数名词表示,如 /users、/products、/orders。单个资源的 URI 是在集合 URI 后附加资源标识符,如 /users/123、/products/abc-def。
这种设计创建了一个自然的层次结构。集合端点支持 GET(列出所有资源)和 POST(创建新资源)操作。单个资源端点支持 GET(获取资源详情)、PUT/PATCH(更新资源)和 DELETE(删除资源)操作。这种分工明确的设计使得 API 的行为可预测,开发者可以根据 URI 的形式推断出支持的操作。
资源标识符的选择对 API 的可用性和安全性都有影响。自增整数 ID 简单直观,但可能暴露业务信息(如用户总数、订单量)并且容易被遍历攻击。UUID 提供了更好的安全性,但较长且不便于人类阅读。短哈希或编码后的 ID(如 YouTube 的视频 ID)在安全性和可读性之间取得了平衡。某些资源可以使用有业务含义的自然键作为标识符,如用户名、产品 SKU 等。
集合的过滤与查询
当集合包含大量资源时,客户端通常需要根据特定条件筛选出感兴趣的子集。过滤功能通过查询参数实现,使得同一个集合端点可以返回不同的结果子集。
基本的等值过滤是最常见的需求。客户端通过查询参数指定字段名和期望值,如 /orders?status=pending 获取所有待处理订单,/products?category=electronics 获取电子产品分类下的商品。多个过滤条件可以组合使用,通常以 AND 逻辑连接。
范围过滤用于数值和日期类型的字段。常见的设计是使用后缀来表示比较操作,如 price_min=100&price_max=500 表示价格在 100 到 500 之间,created_after=2024-01-01 表示创建日期在指定日期之后。另一种设计是使用方括号语法,如 price[gte]=100&price[lte]=500,这种方式更加结构化但也更复杂。
模糊匹配和全文搜索通常通过专门的查询参数实现。简单的模糊匹配可以使用 name_like=apple 这样的参数,表示名称包含指定文本。更复杂的全文搜索可能需要专门的搜索端点或使用通用的 q 参数,如 /products?q=wireless bluetooth headphones,背后由专门的搜索引擎提供支持。
集合的排序
客户端可能需要按照不同的字段和顺序来获取资源列表。排序功能同样通过查询参数实现,常见的设计是使用 sort 或 order_by 参数。
单字段排序的一种简洁设计是使用前缀符号表示方向:sort=price 表示按价格升序,sort=-price 表示按价格降序(减号表示降序)。多字段排序可以用逗号分隔多个字段,如 sort=-created_at,name 表示先按创建时间降序,再按名称升序。
另一种更显式的设计是分别指定排序字段和方向,如 sort_by=price&sort_order=desc。这种设计更加清晰但也更冗长,对于多字段排序的支持也不够自然。
服务端需要注意排序的性能影响。对于大数据集,没有索引支持的排序可能导致严重的性能问题。API 文档应该明确说明哪些字段支持排序,对于不支持排序的字段应该返回适当的错误响应。
集合的分页
分页是处理大集合的必要机制,它将结果分割成可管理的小块,逐页返回给客户端。
基于偏移量的分页使用 offset 和 limit(或 page 和 page_size)参数。/users?page=3&page_size=20 表示获取第三页,每页 20 条记录。这种方式实现简单,支持随机访问任意页面,但在大偏移量时性能较差,且在数据变化时可能出现记录遗漏或重复。
基于游标的分页使用一个不透明的游标令牌来标记当前位置。响应中包含下一页的游标,客户端请求下一页时携带这个游标。这种方式性能更好,对数据变化更稳定,但不支持随机访问页面,只能顺序翻页。
无论采用哪种分页方式,响应中都应该包含分页元数据。常见的元数据包括:当前页码或游标、每页大小、总记录数(如果计算成本可接受)、总页数、是否有更多数据,以及导航到上一页、下一页、首页、末页的链接。
在设计分页 API 时,应该考虑设置合理的默认值和上限。如果客户端不指定分页参数,使用合理的默认值(如每页 20 条)而不是返回所有记录。同时设置每页大小的上限(如最多 100 条),防止客户端请求过大的页面导致服务器资源耗尽。
子资源与嵌套资源模式
当资源之间存在从属或包含关系时,子资源模式提供了一种自然的表达方式。子资源的 URI 嵌套在父资源的 URI 之下,清晰地表达了它们之间的关系。
何时使用子资源
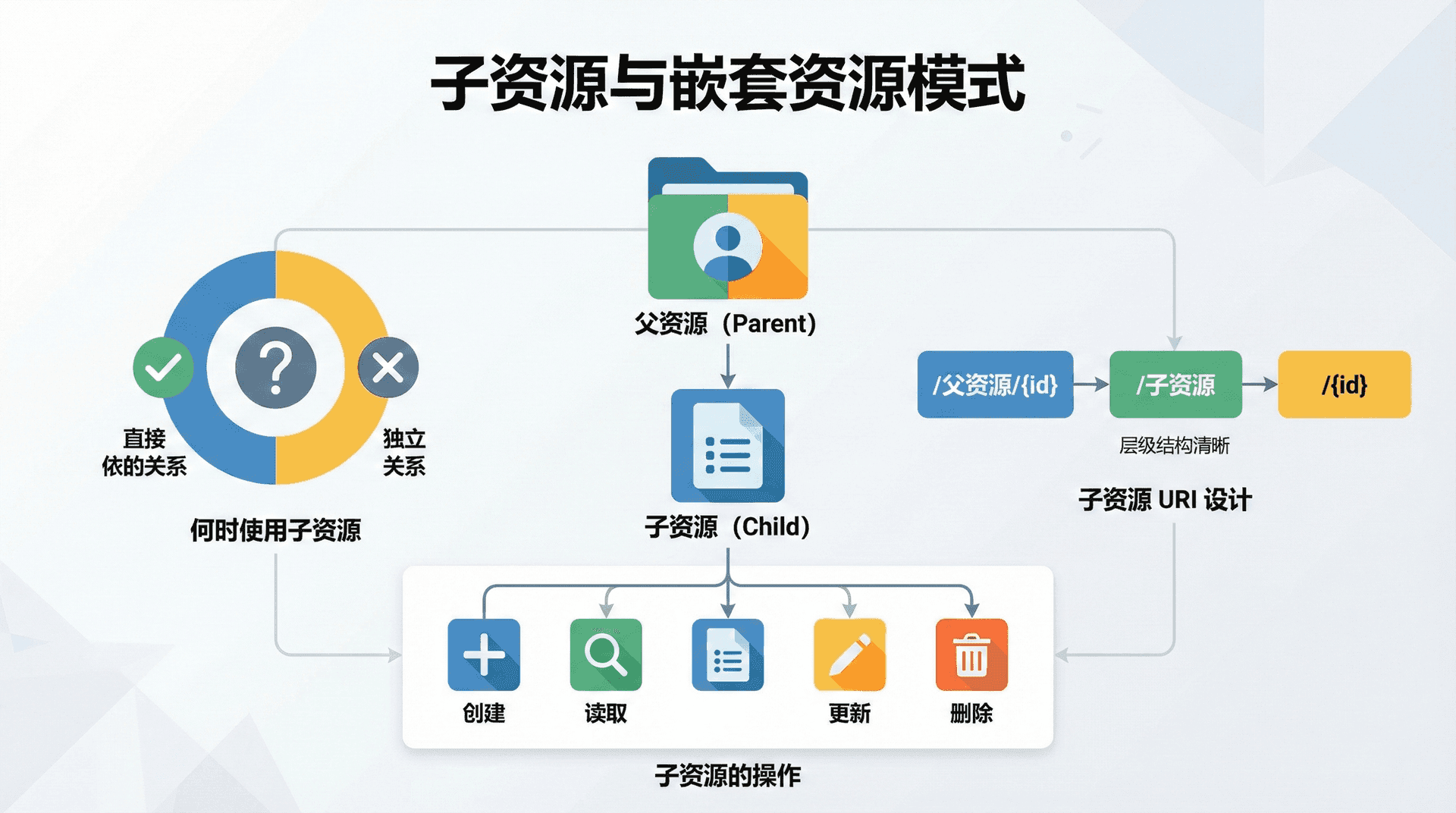
子资源模式适用于那些在逻辑上强烈依附于父资源的场景。判断是否应该使用子资源可以考虑以下几个因素。
首先是生命周期依赖:如果子资源的存在完全依赖于父资源,父资源删除时子资源也应该被删除,那么使用子资源模式是合适的。例如,订单项依附于订单,评论依附于文章,收货地址依附于用户账户。
其次是访问模式:如果子资源通常是在父资源的上下文中被访问和操作的,子资源模式能够提供更清晰的语义。例如,获取"用户 123 的所有订单"比获取"所有订单并过滤出用户 123 的"在语义上更加直观。
第三是唯一性范围:如果子资源的标识符只在父资源的范围内唯一(而不是全局唯一),子资源模式是自然的选择。例如,订单中的第 1 项在不同订单中可能都叫"第 1 项",但它们是不同的资源。
子资源的 URI 设计
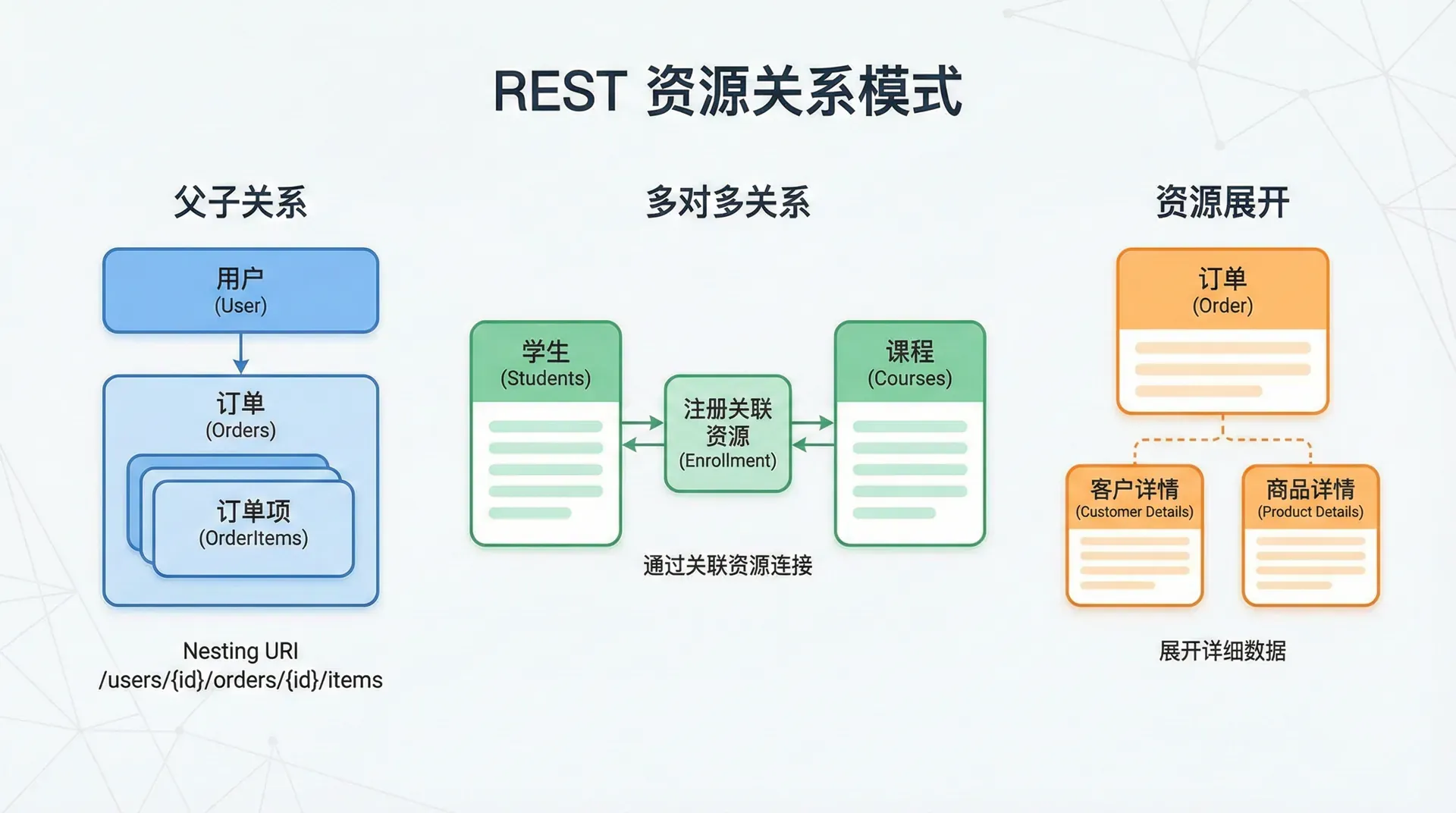
子资源的 URI 遵循嵌套结构:/parents/{parent_id}/children/{child_id}。例如,/users/123/orders 表示用户 123 的订单集合,/users/123/orders/456 表示用户 123 的订单 456。
嵌套层次不宜过深。虽然技术上可以创建任意深度的嵌套,如 /a/1/b/2/c/3/d/4,但这会使 URI 变得冗长且难以使用。经验法则是将嵌套控制在两到三层以内。如果需要更深的层次,可以考虑将某些子资源提升为顶级资源,通过查询参数或链接来表达关系。
在某些情况下,子资源可能同时需要嵌套访问和直接访问两种方式。例如,评论可以通过 /posts/123/comments/456 访问(在文章上下文中),也可以通过 /comments/456 直接访问(当已知评论 ID 时)。是否支持这种双重访问取决于业务需求,但需要确保两个 URI 指向的是同一个资源,行为应该一致。
子资源的操作
子资源支持与普通资源相同的 CRUD 操作,只是操作发生在父资源的上下文中。
创建子资源时,向父资源下的子资源集合发送 POST 请求。例如,POST /users/123/orders 创建用户 123 的新订单。请求中不需要再指定用户 ID,因为这个信息已经包含在 URI 中了。服务器创建订单时会自动关联到正确的用户。
读取子资源集合时,只返回属于特定父资源的子资源。GET /users/123/orders 只返回用户 123 的订单,而不是所有订单。这是子资源模式的核心价值之一:通过 URI 结构自然地实现了过滤。
更新和删除子资源的操作与普通资源类似,只是需要确保子资源确实属于 URI 中指定的父资源。如果客户端尝试通过错误的父资源路径访问子资源(如 /users/123/orders/456,但订单 456 实际属于用户 789),服务器应该返回 404 Not Found 而不是 403 Forbidden,以避免泄露订单归属信息。
资源关系模式
除了从属关系外,资源之间还可能存在关联关系、多对多关系等其他类型的关系。这些关系需要不同的 API 设计策略来表达和操作。
关联关系的表示
当两个资源之间存在关联但不是严格的从属关系时,可以通过在资源表述中包含相关资源的引用来表示。这种引用可以是关联资源的 ID,也可以是指向关联资源的完整 URI。
使用完整 URI 作为引用更符合 REST 的超媒体原则,使得客户端可以直接使用这个 URI 获取关联资源,而不需要知道如何构造 URI。然而在实践中,许多 API 出于简洁考虑只包含 ID,依赖客户端了解 URI 的构造规则。
某些场景下,客户端可能希望在一次请求中同时获取主资源和关联资源的数据,以减少请求次数。这可以通过资源扩展(resource expansion)或嵌入(embedding)来实现。客户端在请求中指定希望嵌入的关联资源,如 GET /orders/123?expand=customer,products,服务器在响应中不仅返回订单信息,还直接嵌入客户和产品的详细数据。
多对多关系的处理
多对多关系是资源建模中较为复杂的场景。例如,学生和课程之间的选课关系,用户和角色之间的分配关系。有几种常见的方式来处理这类关系。
第一种方式是将关系本身建模为独立的资源。创建一个新的资源类型来代表两个资源之间的关联,如"选课记录"(Enrollment)资源,包含学生 ID、课程 ID,可能还有关系的附加属性如选课日期、成绩等。这种方式最为灵活,特别是当关系本身具有属性时。客户端可以通过 CRUD 操作来管理这些关系资源。
第二种方式是通过子资源端点来管理关系。例如,使用 /students/123/courses 获取学生 123 选修的所有课程,使用 PUT /students/123/courses/456 或 DELETE /students/123/courses/456 来添加或移除选课关系。这种方式较为直观,但对于关系有额外属性的场景支持不够好。
第三种方式是在资源表述中直接包含关联资源的 ID 列表,通过更新资源来修改关系。例如,用户资源中包含一个 role_ids 数组,通过 PATCH 请求修改这个数组来变更用户的角色分配。这种方式简单直接,但在关系数量很大时可能不太实用。
选择哪种方式取决于具体场景:关系是否有自己的属性?关系的数量规模如何?主要的访问和修改模式是什么?没有放之四海而皆准的最佳方案,需要根据实际需求做出权衡。
资源嵌入与展开
在处理资源关系时,一个常见的挑战是如何平衡请求次数和响应大小。如果响应只包含关联资源的引用(ID 或链接),客户端可能需要发起多次请求来获取所需的完整数据,这被称为"N+1 查询问题"。如果响应总是嵌入所有关联资源的完整数据,则可能传输大量客户端并不需要的信息。
资源展开机制为客户端提供了控制嵌入深度的能力。通过查询参数,客户端可以指定希望展开哪些关联资源。例如,GET /orders/123?expand=customer 请求订单时同时嵌入客户信息,GET /orders/123?expand=customer.addresses,items.product 则请求更复杂的嵌套展开。
实现资源展开时需要注意几个问题。首先是性能考量:嵌入关联资源意味着服务器需要额外的数据库查询,过多的展开可能影响响应时间。可以设置展开的最大深度限制,并监控性能指标。其次是循环引用的处理:如果 A 引用 B,B 又引用 A,需要有机制防止无限递归。通常的做法是限制展开深度,或者在已经展开过的资源再次出现时只返回引用而不是完整数据。
批量操作模式
在实际应用中,经常需要对多个资源同时进行操作,如批量创建、批量更新或批量删除。RESTful API 的资源模型天然是面向单个资源的,处理批量操作需要一些特殊的设计策略。
批量创建
批量创建最直接的方式是向集合端点 POST 一个包含多个对象的数组。服务器处理这个数组中的每个对象,尝试创建相应的资源。
响应设计需要考虑部分成功的情况:如果数组中的某些对象创建成功而另一些失败,应该如何响应?一种方式是采用全有或全无的事务语义,任何一个失败则整体回滚,返回错误信息。另一种方式是返回混合结果,响应中包含每个对象的处理结果(成功或失败及原因),使用 207 Multi-Status 状态码。后者更加灵活,但客户端需要处理更复杂的响应结构。
批量创建的大小应该有合理的限制。过大的批量请求可能导致超时、内存溢出等问题。API 应该明确说明支持的最大批量大小,并在超出限制时返回明确的错误信息。
批量更新
批量更新的设计比批量创建更加复杂,因为需要同时指定要更新的资源和更新的内容。
一种方式是使用集合端点的 PATCH 方法,请求体包含一个数组,每个元素包含资源标识符和要更新的字段。这种设计直观但需要精心设计请求格式以确保无歧义。
另一种方式是将批量更新建模为一个独立的"批量更新任务"资源。客户端 POST 一个任务请求,服务器创建任务并异步执行,客户端可以通过任务资源来查询执行进度和结果。这种方式特别适合涉及大量资源或耗时较长的更新操作。
条件批量更新是另一个值得考虑的功能:更新所有满足特定条件的资源,而不是显式列出每个资源的标识符。例如,PATCH /orders?status=pending 可能表示更新所有待处理订单。这种模式功能强大但也比较危险,需要谨慎设计并加以适当的限制。
批量删除
批量删除面临与批量更新类似的设计挑战。DELETE 方法传统上不支持请求体(虽然 HTTP 规范并未禁止),因此需要其他方式来指定要删除的资源。
一种方式是在查询参数中传递资源标识符列表,如 DELETE /users?ids=1,2,3,4,5。这种方式简单直接,但当标识符列表很长时,可能超出 URL 长度限制。
另一种方式是创建一个专门的批量删除端点,使用 POST 方法并在请求体中携带标识符列表,如 POST /users/batch-delete。虽然从 REST 纯粹性的角度看使用 POST 来表示删除操作不太理想,但这是一种务实的解决方案。
条件批量删除,即删除所有满足特定条件的资源,与条件批量更新一样是高风险操作,应该有额外的安全保障,如确认机制、软删除、操作日志等。
批量操作应该谨慎使用,特别是批量更新和批量删除。在生产环境中,一个错误的批量操作可能导致大量数据被错误修改或删除。建议为批量操作实现额外的安全措施,如操作确认、操作日志、软删除、限制单次操作的资源数量等。同时,批量操作的 API 权限应该与普通操作分开管理,只授予确实需要的用户或系统。
搜索模式
搜索是许多应用的核心功能,它与简单的过滤不同,通常涉及更复杂的查询逻辑、相关性排序和全文匹配。
简单搜索
简单搜索可以通过资源集合端点的查询参数来实现。最基本的形式是使用一个通用的搜索参数,如 q 或 search,接受用户输入的搜索关键词。服务器在多个相关字段中搜索包含这些关键词的资源。
例如,GET /products?q=wireless headphones 可能在产品名称、描述、标签等多个字段中搜索匹配的产品。搜索结果通常按相关性排序,而不是按默认的创建时间或 ID 排序。
简单搜索的实现可以依赖数据库的全文搜索功能(如 PostgreSQL 的 Full Text Search、MySQL 的 FULLTEXT 索引),也可以使用专门的搜索引擎(如 Elasticsearch、Algolia)。后者通常能提供更好的搜索体验,包括分词、同义词、拼写纠正、高亮显示等高级功能。
高级搜索
当搜索需求变得复杂时,简单的查询参数可能不够用。高级搜索场景可能涉及多字段组合查询、复杂的布尔逻辑、范围条件、嵌套条件等。
一种方式是设计一个结构化的查询语言,通过请求体传递复杂的查询条件。Elasticsearch 的 Query DSL 就是这种方式的典型代表。这种方式功能强大,但学习曲线较陡。
另一种方式是使用 POST 请求到专门的搜索端点,如 POST /products/search,请求体包含结构化的搜索条件。虽然使用 POST 进行查询不太符合 HTTP 方法的标准语义(搜索本质上是读取操作),但这是一个被广泛接受的实践折中。
GraphQL 在复杂查询场景中展现出优势,它允许客户端精确指定需要的字段和关联,以及复杂的过滤条件。对于搜索密集型的应用,考虑在 RESTful API 的基础上补充 GraphQL 端点可能是值得的选择。
搜索结果的呈现
搜索结果的呈现需要考虑几个特殊因素。
相关性评分让客户端了解每个结果与查询的匹配程度。搜索结果可以包含一个 score 或 relevance 字段,客户端可以据此向用户展示结果的相关性,或进行二次排序。
高亮显示帮助用户快速理解为什么某个结果被返回。响应中可以包含一个 highlights 字段,标记出匹配关键词在各字段中的位置,客户端使用这些信息进行视觉高亮。
分面搜索(Faceted Search)允许用户通过多个维度筛选结果。响应中除了返回搜索结果,还返回各个分面的统计信息,如"品牌:苹果(42)、三星(38)、华为(25)"。用户可以点击分面值来进一步筛选结果。
搜索建议和自动完成是提升搜索体验的重要功能,通常通过专门的端点实现,如 GET /search/suggestions?q=wire,返回以输入前缀开头的热门搜索词或产品名称。
部分响应与字段选择模式
当资源具有大量属性时,客户端可能只需要其中的一部分。部分响应模式允许客户端指定希望在响应中包含的字段,从而减少不必要的数据传输和处理。
字段选择的实现
字段选择通常通过查询参数实现。最常见的设计是使用 fields 参数,其值为逗号分隔的字段名列表。例如,GET /users/123?fields=id,name,email 只返回用户的 ID、姓名和邮箱字段。
对于嵌套对象,可以使用点号表示法来选择嵌套字段。例如,fields=id,name,address.city 表示选择 ID、姓名,以及地址对象中的城市字段。
某些 API 采用相反的策略,使用 exclude 参数指定要排除的字段,如 GET /users/123?exclude=password_hash,internal_notes。这在需要大多数字段但排除敏感字段的场景中更加方便。
实现字段选择时需要考虑性能影响。如果选择的字段对应数据库的不同表或需要额外的计算,简单地在应用层过滤响应字段并不能带来真正的性能提升。理想情况下,字段选择应该能够影响底层的数据获取逻辑,只查询必要的数据。
稀疏字段集
JSON:API 规范定义了稀疏字段集(Sparse Fieldsets)的标准格式,使用 fields[resource_type]=field1,field2 的语法。这种格式的优势在于可以同时为多种资源类型指定字段选择,特别适合包含多种资源类型的复合响应。
例如,GET /orders/123?fields[orders]=id,total&fields[customers]=name&fields[products]=name,price 可以在获取订单时,同时指定订单本身、关联客户和关联产品各自需要返回的字段。
预设视图
为常见的字段组合提供预设视图可以简化客户端的使用。例如,GET /users/123?view=summary 返回用户的摘要信息(ID、姓名、头像),GET /users/123?view=full 返回完整的用户资料。
预设视图是对字段选择的补充而非替代。它们为常见场景提供便利,而字段选择则提供精细控制的灵活性。两种机制可以共存,客户端根据需求选择使用。
小结
这节课我们用贴近实践的方式梳理了 RESTful API 设计的核心模式:从最常用的 CRUD 操作,到资源集合的 URI 设计、过滤/排序/分页、子资源和复杂关系的处理,再到批量操作、搜索和部分响应等进阶用法,都帮助你了解了 RESTful API 如何应对各种真实的业务场景。这些方法不仅提升了开发效率,也让接口更易用、更易维护。
实际开发中,没有万能的模式,关键是灵活组合这些工具,找到最适合业务需求的设计。掌握了这些基础之后,你将具备搭建高质量 API 的核心能力。接下来,我们还会带你走进 HATEOAS、异步处理、事件驱动等更高级的模式,让 API 设计变得更加丰富和强大。