深入数据处理
在前面的课程中,我们已经掌握了Spring Data JPA的基础用法,能够通过继承JpaRepository接口获得基本的CRUD操作能力。然而,在实际的业务场景中,你往往需要执行更复杂的查询操作,比如根据多个条件组合查询、分页查询、排序查询、统计查询等。这些需求超出了基础CRUD的范围,需要你深入了解Spring Data JPA的高级特性。
数据处理不仅仅是简单的增删改查,它还涉及到数据的一致性、事务的边界、查询的性能、以及复杂业务规则的实现。Spring Boot和Spring Data JPA提供了丰富的工具和机制来应对这些挑战,让你能够以声明式的方式表达复杂的查询逻辑,而不需要编写大量的样板代码。
这节课我们将深入学习Spring Data JPA的高级特性,包括自定义查询方法、JPQL和原生SQL查询、分页和排序、事务管理、数据验证、实体关系映射等内容。
扩展Course实体添加更多字段
在深入学习复杂查询之前,让我们先扩展一下Course实体,添加更多字段以便演示各种查询场景。打开src/main/java/com/example/myapp/my_spring_boot_app/model/Course.java文件,将内容更新为:
java
package com.example.myapp.my_spring_boot_app.model;
import jakarta.persistence.Entity;
import jakarta.persistence.GeneratedValue;
import jakarta.persistence.GenerationType;
import jakarta.persistence.Id;
import jakarta.persistence.Table;
import jakarta.validation.constraints.NotBlank;
import jakarta.validation.constraints.Size;
import java.time.LocalDateTime;
@Entity
@Table(name = "courses")
public class Course {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@NotBlank
@Size(min = 1, max = 200)
private String title;
@Size(max = 1000)
private String description;
private String category;
private Integer difficultyLevel;
private LocalDateTime createdAt;
private LocalDateTime updatedAt;
public Course() {
}
public Course(String title, String description, String category, Integer difficultyLevel) {
this.title = title;
this.description = description;
this.category = category;
this.difficultyLevel = difficultyLevel;
this.createdAt = LocalDateTime.now();
this.updatedAt = LocalDateTime.now();
}
// getter和setter方法
public Long getId() {
return id;
}
public void setId(Long id) {
this.id = id;
}
public String getTitle() {
return title;
}
public void setTitle(String title) {
this.title = title;
}
public String getDescription() {
return description;
}
public void setDescription(String description) {
this.description = description;
}
public String getCategory() {
return category;
}
public void setCategory(String category) {
this.category = category;
}
public Integer getDifficultyLevel() {
return difficultyLevel {
return difficultyLevel;
}
public void setDifficultyLevel(Integer difficultyLevel) {
this.difficultyLevel = difficultyLevel;
}
public LocalDateTime getCreatedAt() {
return createdAt;
}
public void setCreatedAt(LocalDateTime createdAt) {
this.createdAt = createdAt;
}
public LocalDateTime getUpdatedAt() {
return updatedAt;
}
public void setUpdatedAt(LocalDateTime updatedAt) {
this.updatedAt = updatedAt;
}
}我们添加了category字段用于课程分类,difficultyLevel字段用于表示难度级别,createdAt和updatedAt字段用于记录创建和更新时间。@NotBlank和@Size注解用于数据验证,确保标题不为空且长度在合理范围内。这些额外的字段将帮助我们演示更复杂的查询场景。
使用约定式方法名创建查询
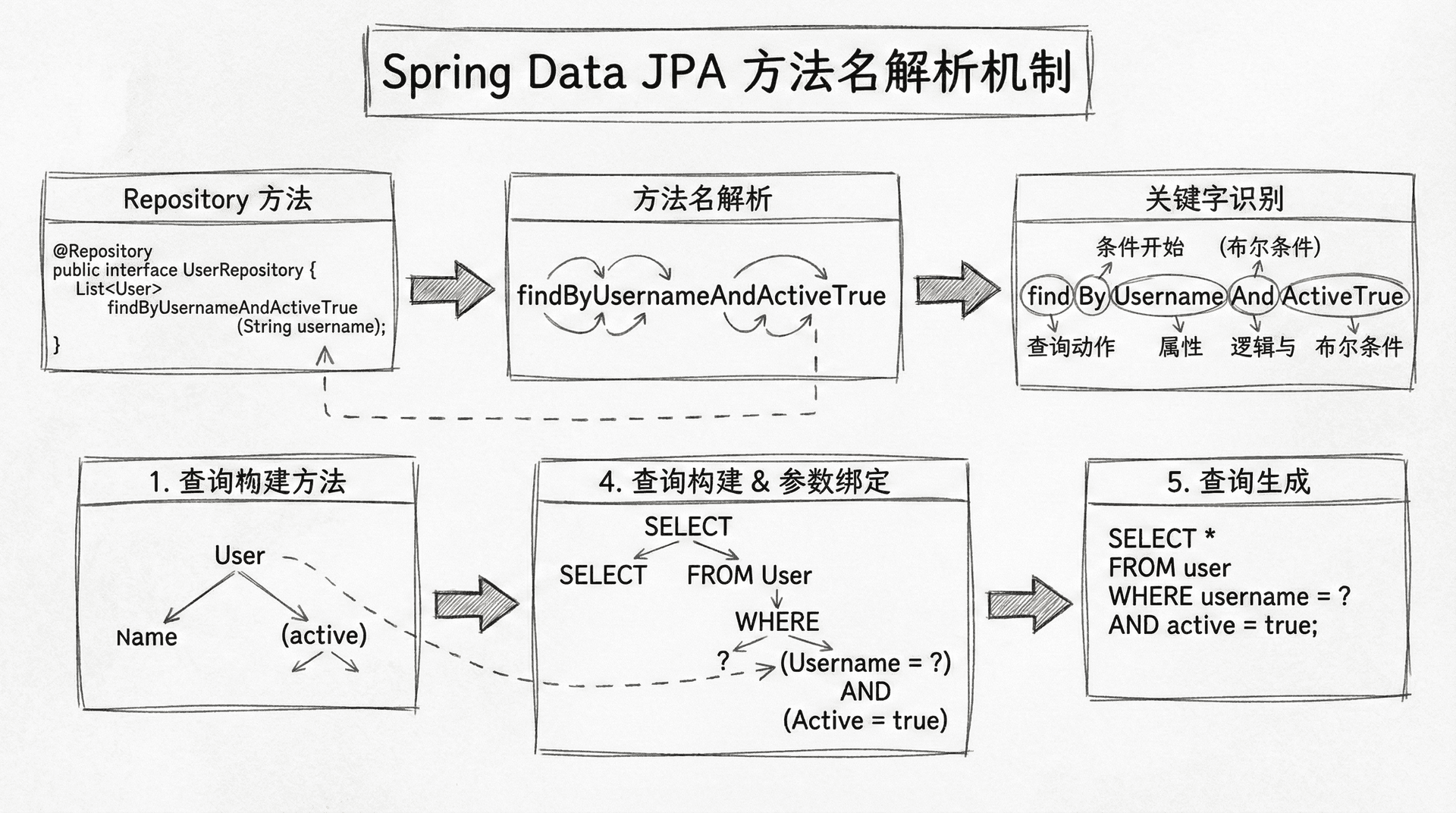
Spring Data JPA最强大的特性之一就是能够根据方法名自动生成查询。只要你的方法名遵循特定的命名约定,Spring Data JPA就能自动解析方法名并生成对应的SQL查询,无需编写任何实现代码。
打开src/main/java/com/example/myapp/my_spring_boot_app/repository/CourseRepository.java文件,添加一些自定义查询方法:
java
package com.example.myapp.my_spring_boot_app.repository;
import com.example.myapp.my_spring_boot_app.model.Course;
import org.springframework.data.jpa.repository.JpaRepository;
import org.springframework.data.jpa.repository.Query;
import org.springframework.data.repository.query.Param;
import org.springframework.stereotype.Repository;
import java.util.List;
import java.util.Optional;
@Repository
public interface CourseRepository extends JpaRepository<Course, Long> {
Optional<Course> findByTitle(String title
findByTitle方法会根据标题精确查找课程,相当于SELECT * FROM courses WHERE title = ?。findByCategory方法查找指定分类的所有课程。findByCategoryAndDifficultyLevel方法演示了多条件查询,使用And关键字连接多个条件。findByTitleContaining方法使用Containing关键字实现模糊查询,相当于SQL的LIKE '%keyword%'。
findByTitleStartingWith和findByTitleEndingWith分别实现前缀和后缀匹配。findByDifficultyLevelGreaterThan使用GreaterThan关键字实现大于比较。findByDifficultyLevelBetween使用Between关键字实现范围查询。findByCategoryOrderByCreatedAtDesc演示了排序功能,OrderBy后面跟字段名,Desc表示降序,Asc表示升序。
countByCategory方法返回指定分类的课程数量,existsByTitle方法检查是否存在指定标题的课程。这些方法名都遵循Spring Data JPA的命名约定,框架会自动生成对应的查询实现。
使用@Query注解编写自定义查询
虽然约定式方法名能够处理大多数查询场景,但有时候你需要执行更复杂的查询,比如多表关联、聚合函数、子查询等。在这种情况下,你可以使用@Query注解来编写自定义的JPQL(Java Persistence Query Language)查询或原生SQL查询。
在CourseRepository接口中添加使用@Query注解的方法:
java
@Query("SELECT c FROM Course c WHERE c.category = :category AND c.difficultyLevel >= :minLevel")
List<Course> findCoursesByCategoryAndMinLevel(@Param("category") String category, @Param("minLevel") Integer minLevel);
@Query("SELECT c FROM Course c WHERE c.title LIKE %:keyword% OR c.description LIKE %:keyword%")
List<Course> searchCourses(@Param("keyword") String keyword);
@Query("SELECT c FROM Course c ORDER BY c.createdAt DESC")
JPQL是JPA提供的面向对象的查询语言,它使用实体类和属性名而不是数据库表和列名。SELECT c FROM Course c中的c是实体别名,Course是实体类名。JPQL查询会被Hibernate转换为对应的SQL查询,这样你就不需要关心底层数据库的SQL方言差异。
@Param注解用于绑定方法参数到查询中的命名参数,:category和:minLevel是查询中的命名参数,通过@Param注解与方法参数绑定。这种方式比使用位置参数(?1, ?2)更加清晰和安全。
最后一个查询countCoursesByCategoryGroup演示了分组查询,返回一个Object[]数组的列表,每个数组包含分类名称和对应的课程数量。对于这种返回非实体类型的查询,你需要使用Object[]或创建专门的DTO类来接收结果。
使用原生SQL查询
虽然JPQL能够处理大多数查询场景,但有时候你需要使用数据库特定的SQL特性,比如窗口函数、递归查询、特定的函数等。Spring Data JPA允许你使用原生SQL查询,只需要在@Query注解中设置nativeQuery = true。
添加原生SQL查询方法:
java
@Query(value = "SELECT * FROM courses WHERE category = :category AND difficulty_level >= :minLevel ORDER BY created_at DESC LIMIT :limit", nativeQuery = true)
List<Course> findTopCoursesByCategoryAndLevel(@Param("category") String category, @Param("minLevel") Integer minLevel, @Param("limit") Integer limit);
@Query(value = "SELECT category, COUNT(*) as count FROM courses GROUP BY category ORDER BY count DESC", nativeQuery = true)
原生SQL查询直接使用数据库表的列名,而不是实体类的属性名。注意在原生SQL中,我们使用下划线命名(difficulty_level、created_at),这与数据库表的实际列名一致。使用原生SQL时需要注意数据库兼容性,不同的数据库可能有不同的SQL语法。
实现分页和排序查询
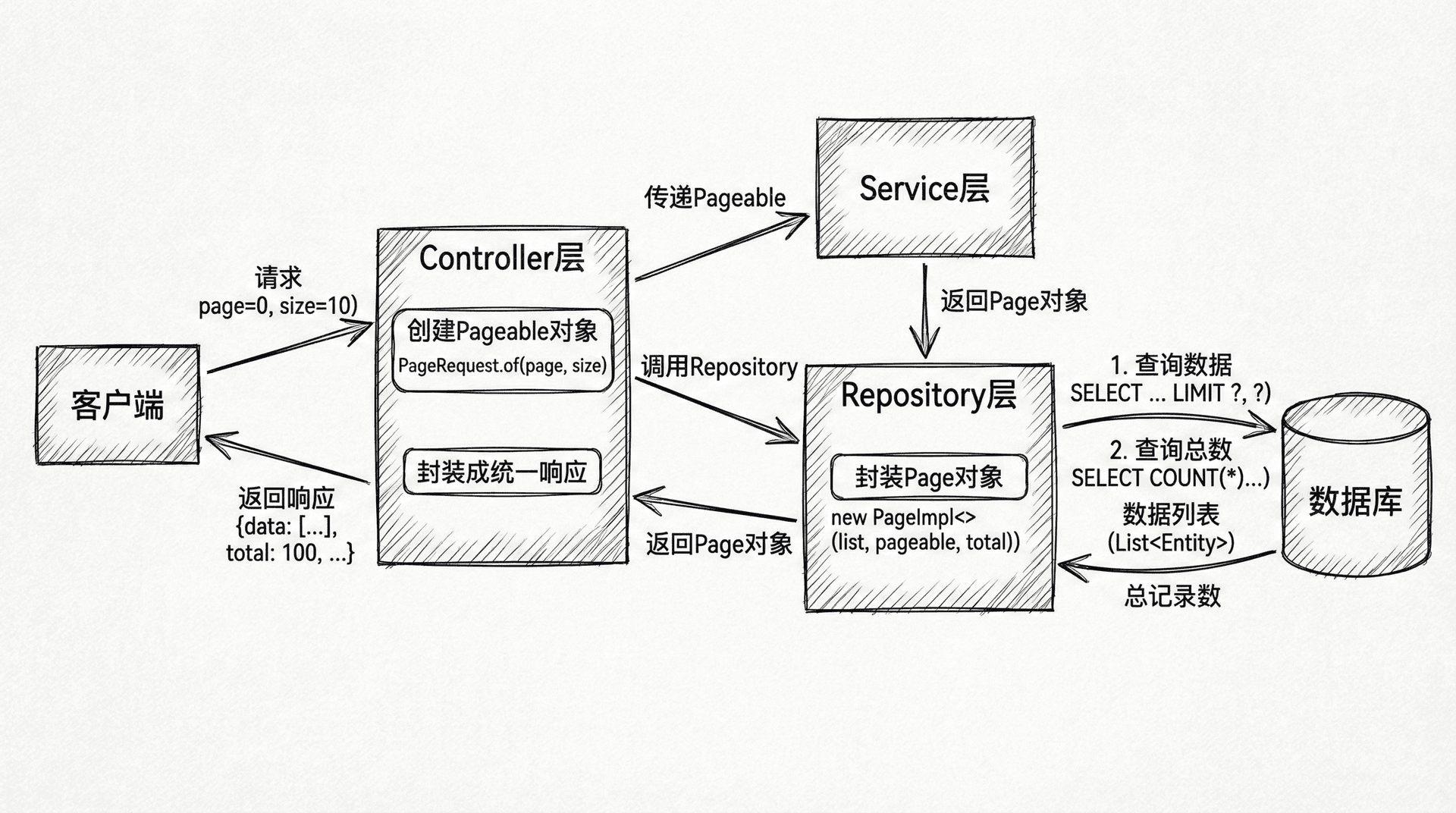
当数据量较大时,一次性加载所有数据不仅会消耗大量内存,还会影响查询性能。分页查询是处理大量数据的标准做法,Spring Data JPA提供了强大的分页支持,让你能够轻松实现分页查询。
在CourseRepository接口中添加分页查询方法:
java
import org.springframework.data.domain.Page;
import org.springframework.data.domain.Pageable;
import org.springframework.data.domain.Sort;
Page<Course> findByCategory(String category, Pageable pageable);
List<Course> findByDifficultyLevel(Integer level, Sort sort);Pageable接口封装了分页信息,包括页码、每页大小、排序信息等。Page接口不仅包含当前页的数据,还包含总记录数、总页数、是否有上一页和下一页等分页元信息。使用分页查询时,Spring Data JPA会自动执行两条SQL:一条查询数据,一条统计总数。
在服务层中使用分页查询:
java
@Service
@Transactional
public class CourseService {
private final CourseRepository repository;
public CourseService(CourseRepository repository) {
this.repository = repository;
}
public Page<Course> getCoursesByCategory(String category, int page, int size) {
Pageable pageable = PageRequest.of
PageRequest.of(page, size, sort)创建了一个Pageable对象,指定了页码(从0开始)、每页大小和排序规则。Sort.by("createdAt").descending()创建了按创建时间降序排序的Sort对象。and方法可以组合多个排序字段,实现多字段排序。
在控制器中返回分页结果:
java
@GetMapping("/category/{category}")
public ResponseEntity<Map<String, Object>> getCoursesByCategory(
@PathVariable String category,
@RequestParam(defaultValue = "0") int page,
@RequestParam(defaultValue = "10") int size) {
Page<Course> coursePage = courseService.getCoursesByCategory
分页响应包含了当前页的数据、当前页码、总记录数、总页数等信息,客户端可以根据这些信息实现分页导航。
事务管理
事务是数据库操作的基本单位,它确保一组操作要么全部成功,要么全部失败,不会出现部分成功的情况。Spring的事务管理通过@Transactional注解提供了声明式事务支持,让你能够以声明式的方式管理事务边界,而不需要编写大量的事务管理代码。
事务的传播行为定义了当方法被另一个事务方法调用时,事务应该如何传播。默认的REQUIRED行为表示如果当前存在事务就加入该事务,如果不存在就创建一个新事务。其他常见的传播行为包括REQUIRES_NEW(总是创建新事务)、SUPPORTS(如果存在事务就加入,否则以非事务方式执行)、NOT_SUPPORTED(以非事务方式执行)、MANDATORY(必须在事务中执行,否则抛出异常)等。
事务的隔离级别定义了事务之间的可见性规则。READ_UNCOMMITTED允许读取未提交的数据,可能导致脏读。READ_COMMITTED只允许读取已提交的数据,避免了脏读但可能出现不可重复读。REPEATABLE_READ确保在同一事务中多次读取同一数据时结果一致,避免了不可重复读但可能出现幻读。SERIALIZABLE是最严格的隔离级别,完全避免了并发问题但性能最差。
在服务方法中使用不同的事务配置:
java
@Service
@Transactional
public class CourseService {
private final CourseRepository repository;
public CourseService(CourseRepository repository) {
this.repository = repository;
}
@Transactional(readOnly = true)
public List<Course> findAllCourses() {
return repository.findAll();
@Transactional(readOnly = true)标记方法为只读事务,这可以优化查询性能,因为只读事务不需要获取写锁。@Transactional(propagation = Propagation.REQUIRES_NEW)确保方法总是在新事务中执行,即使调用它的方法已经在事务中。这对于需要独立提交的操作(如日志记录)非常有用。
使用Bean Validation进行数据验证
数据验证是确保数据质量的重要环节,它能够在数据进入业务逻辑之前就发现并拒绝不合法的数据。Spring Boot集成了Bean Validation(JSR-303),提供了丰富的验证注解,让你能够以声明式的方式定义验证规则。
在实体类上添加验证注解:
java
@Entity
@Table(name = "courses")
public class Course {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@NotBlank(message = "课程标题不能为空")
@Size(min = 1, max = 200, message
@NotBlank确保字符串不为空且去除空白后不为空。@Size限制字符串或集合的大小范围。@Pattern使用正则表达式验证字符串格式。@Min和@Max限制数值的范围。message属性定义了验证失败时的错误消息。
在控制器方法中启用验证:
java
@PostMapping
public ResponseEntity<Course> createCourse(@Valid @RequestBody Course course) {
Course created = courseService.createCourse(course);
return ResponseEntity.status(HttpStatus.CREATED).body(created);
}
@PutMapping("/{id}")
public ResponseEntity<Course> updateCourse(
@PathVariable Long id,
@Valid注解启用Bean Validation验证,如果验证失败,Spring会抛出MethodArgumentNotValidException异常。你可以在全局异常处理器中捕获这个异常并返回友好的错误响应:
java
@RestControllerAdvice
public class GlobalExceptionHandler {
@ExceptionHandler(MethodArgumentNotValidException.class)
public ResponseEntity<Map<String, Object>> handleValidationException(
MethodArgumentNotValidException ex) {
Map<String, Object> body = new HashMap<>();
body.put("error", "VALIDATION_ERROR");
Map<String,
这个异常处理器会收集所有验证错误,并以结构化的方式返回给客户端,让客户端能够清楚地知道哪些字段验证失败以及失败的原因。

实现实体关系映射
在实际应用中,实体之间往往存在各种关系,比如一个课程可能有多个章节,一个用户可能注册了多门课程。JPA提供了丰富的注解来映射这些关系,包括@OneToOne、@OneToMany、@ManyToOne、@ManyToMany等。
让我们创建一个Chapter实体来演示一对多关系。在src/main/java/com/example/myapp/my_spring_boot_app/model包下创建Chapter.java文件:
java
package com.example.myapp.my_spring_boot_app.model;
import jakarta.persistence.Entity;
import jakarta.persistence.GeneratedValue;
import jakarta.persistence.GenerationType;
import jakarta.persistence.Id;
import jakarta.persistence.ManyToOne;
import jakarta.persistence.JoinColumn;
import jakarta.persistence.Table;
@Entity
@Table(name = "chapters")
public class Chapter {
@Id
@GeneratedValue(strategy
@ManyToOne注解表示多对一关系,多个章节属于一个课程。@JoinColumn(name = "course_id")指定了外键列名。在Course实体中添加反向关系:
java
@OneToMany(mappedBy = "course", cascade = CascadeType.ALL, orphanRemoval = true)
private List<Chapter> chapters = new ArrayList<>();@OneToMany注解表示一对多关系,一个课程有多个章节。mappedBy = "course"指定了关系的拥有方是Chapter实体中的course字段。cascade = CascadeType.ALL表示级联操作,当保存、更新或删除课程时,相关的章节也会被保存、更新或删除。orphanRemoval = true表示当章节从列表中移除时,会自动从数据库中删除。
使用自定义Repository实现
有时候你需要实现一些复杂的业务逻辑,这些逻辑无法通过简单的查询方法或JPQL查询来表达。在这种情况下,你可以创建自定义的Repository实现,在其中编写复杂的业务逻辑。
创建一个自定义Repository接口:
java
public interface CourseRepositoryCustom {
List<Course> findComplexCourses(String category, Integer minLevel, LocalDateTime startDate);
}实现这个接口:
java
@Repository
public class CourseRepositoryCustomImpl implements CourseRepositoryCustom {
@PersistenceContext
private EntityManager entityManager;
@Override
public List<Course> findComplexCourses(String category, Integer minLevel, LocalDateTime startDate) {
CriteriaBuilder cb = entityManager.getCriteriaBuilder();
CriteriaQuery<Course> query = cb.createQuery(Course.class);
让CourseRepository继承自定义接口:
java
public interface CourseRepository extends JpaRepository<Course, Long>, CourseRepositoryCustom {
// 其他方法
}Criteria API提供了类型安全的查询构建方式,特别适合动态查询场景,你可以在运行时根据条件动态构建查询。
自定义Repository实现是处理复杂业务逻辑的有效方式,它让你能够在保持Repository接口简洁的同时,实现复杂的查询和业务逻辑。Criteria API提供了类型安全的查询构建方式,避免了字符串拼接SQL可能带来的错误。
优化查询性能
随着数据量的增长,查询性能变得越来越重要。Spring Data JPA提供了多种方式来优化查询性能,包括使用@EntityGraph解决N+1查询问题、使用@QueryHints添加查询提示、使用投影查询减少数据传输等。
N+1查询问题是JPA中常见的性能问题,当你查询一个实体并访问其关联实体时,JPA会为每个关联实体执行一次额外的查询。使用@EntityGraph可以一次性加载关联实体:
java
@EntityGraph(attributePaths = {"chapters"})
@Query("SELECT c FROM Course c WHERE c.category = :category")
List<Course> findByCategoryWithChapters(@Param("category") String category);@EntityGraph(attributePaths = {"chapters"})告诉JPA在查询课程时同时加载章节信息,使用LEFT OUTER JOIN一次性获取所有数据,而不是为每个课程执行一次额外的查询。
使用投影查询只查询需要的字段:
java
public interface CourseSummary {
String getTitle();
String getCategory();
Integer getDifficultyLevel();
}
@Query("SELECT c.title as title, c.category as category, c.difficultyLevel as difficultyLevel FROM Course c")
List<CourseSummary> findCourseSummaries();投影查询只查询需要的字段,减少了数据传输量,提高了查询性能。接口投影使用接口定义返回结构,Spring Data JPA会自动创建实现类。
小结
现在,相信你已经对Spring Data JPA的高级用法有了更深入的了解。无论是通过约定式方法名简洁地构建查询,还是利用JPQL和原生SQL编写复杂逻辑,亦或是掌握分页、排序、事务管理、数据验证、实体关系映射和性能优化,相信这些工具都能帮助你游刃有余地应对各种实际开发场景。
下一节课,我们将一起走进Spring MVC的世界,看看如何搭建一个完整的Web应用,学习更多关于视图、表单、文件上传等实用技术!