Project Reactor 和 Spring WebFlux
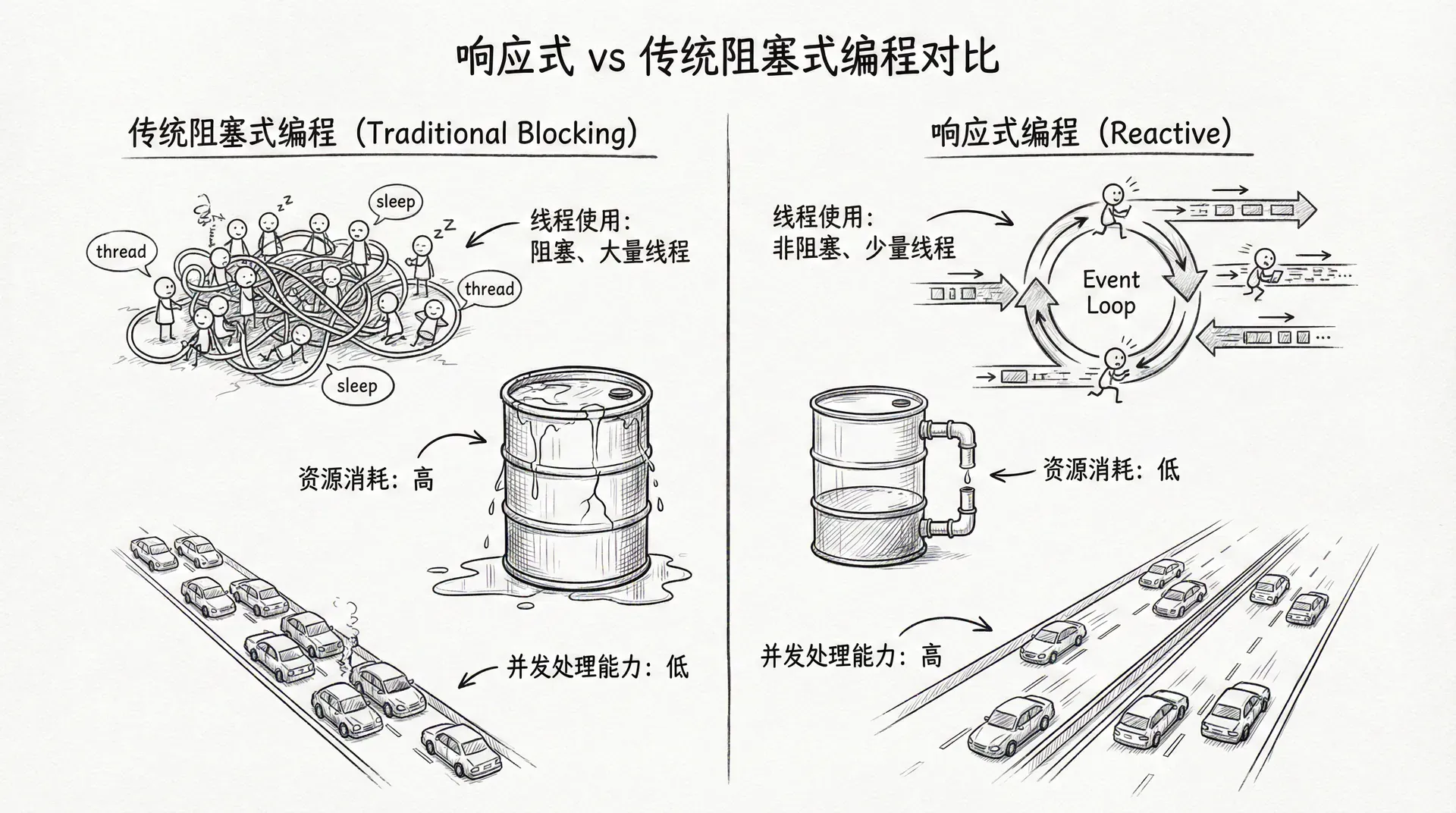
在传统的Spring MVC应用中,每个HTTP请求都会占用一个线程来处理,当请求数量超过线程池大小时,新的请求就需要等待。这种阻塞式的模型在处理大量并发请求时可能会遇到性能瓶颈,因为线程是有限的资源,创建和切换线程都需要消耗系统资源。响应式编程提供了一种非阻塞的替代方案,它使用事件驱动和异步处理的方式,能够在少量线程上处理大量并发请求,从而显著提高应用的吞吐量和资源利用率。
响应式编程不仅仅是一种编程范式,它代表了一种全新的思维方式。在响应式模型中,数据被视为流(Stream),操作被视为对流的转换,而不是对单个数据项的处理。这种模型特别适合处理高并发、高吞吐量的场景,比如实时数据流处理、微服务间的异步通信、以及需要处理大量并发连接的Web应用。
Project Reactor是Spring生态系统中的响应式编程库,它实现了Reactive Streams规范,提供了Mono和Flux两个核心类型来表示异步数据流。Spring WebFlux是基于Project Reactor构建的响应式Web框架,它提供了与Spring MVC类似的编程模型,但底层使用非阻塞的I/O和事件循环机制。这节课我们将深入学习如何使用Project Reactor和Spring WebFlux构建响应式应用,包括Mono和Flux的使用、响应式控制器、响应式数据访问、背压处理、错误处理等内容。
理解响应式编程的核心概念
在深入编写响应式代码之前,我们需要理解响应式编程的几个核心概念。响应式编程基于观察者模式和数据流的思想,它将数据视为可以流动的流,操作被视为对流的转换。与传统的命令式编程不同,响应式编程是声明式的,你只需要声明数据流的转换逻辑,而不需要关心底层的执行细节。
响应式编程的核心是异步和非阻塞。异步意味着操作不会阻塞当前线程,而是通过回调或事件通知来处理结果。非阻塞意味着线程不会因为等待I/O操作而挂起,而是可以继续处理其他任务。这种模型让应用能够在少量线程上处理大量并发操作,从而显著提高资源利用率。
背压(Backpressure)是响应式编程中的另一个重要概念。当数据生产者的速度超过消费者的处理速度时,就会产生背压。响应式流通过背压机制让消费者能够控制数据流的速度,避免内存溢出。这种机制是响应式编程与传统异步编程的重要区别,它让系统能够在高负载下保持稳定。
添加Spring WebFlux依赖
在开始编写响应式代码之前,我们需要添加Spring WebFlux的依赖。Spring WebFlux可以与Spring MVC共存,你可以在同一个应用中使用两种编程模型。在pom.xml文件中添加WebFlux依赖:
xml
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-webflux</artifactId>
</dependency>注意,如果你同时使用spring-boot-starter-web和spring-boot-starter-webflux,Spring Boot会默认使用Spring MVC。如果你想要完全使用WebFlux,需要移除spring-boot-starter-web依赖。但在大多数情况下,你可以在同一个应用中同时使用两者,通过不同的路径来区分。
添加依赖后,刷新Maven项目。Spring Boot会自动配置WebFlux,包括Netty服务器(WebFlux默认使用Netty而不是Tomcat)、响应式路由配置等。你不需要编写额外的配置代码,就能开始使用WebFlux。
理解Mono和Flux
Project Reactor提供了两个核心类型来表示响应式流:Mono表示最多包含一个元素的异步序列,Flux表示包含零个或多个元素的异步序列。这两个类型都实现了Publisher接口,遵循Reactive Streams规范。
Mono通常用于表示单个值的异步操作,比如根据ID查询一个课程、执行一个操作并返回结果等。Flux用于表示多个值的异步序列,比如查询所有课程、处理数据流、接收服务器发送事件等。理解这两个类型的区别和使用场景对于编写正确的响应式代码非常重要。
让我们通过一些简单的例子来理解Mono和Flux的用法。创建一个新的响应式服务类来演示这些概念。在src/main/java/com/example/myapp/my_spring_boot_app/service包下创建ReactiveCourseService.java文件:
java
package com.example.myapp.my_spring_boot_app.service;
import com.example.myapp.my_spring_boot_app.model.Course;
import org.springframework.stereotype.Service;
import reactor.core.publisher.Flux;
import reactor.core.publisher.Mono;
import java.time.Duration;
import java.util.Arrays;
@Service
public class ReactiveCourseService {
public Mono<Course> findCourseById(Long id) {
return Mono.just(new Course(id, "Spring Boot响应式编程"
Mono.just()创建一个包含单个值的Mono,Mono.delayElement()延迟元素的发出,模拟异步操作。Flux.fromIterable()从集合创建Flux,Flux.delayElements()延迟每个元素的发出。Flux.filter()用于过滤元素,只保留满足条件的元素。Flux.count()返回元素的数量,结果是Mono类型。
这些操作都是非阻塞的,它们返回的是Publisher,而不是实际的数据。只有当有订阅者订阅这些Publisher时,操作才会真正执行。这种延迟执行(Lazy Evaluation)是响应式编程的重要特性,它让操作链可以组合和重用。
创建响应式REST控制器
Spring WebFlux提供了两种编程模型:基于注解的控制器(类似于Spring MVC)和函数式路由。我们先学习基于注解的方式,因为它与Spring MVC非常相似,更容易上手。
在src/main/java/com/example/myapp/my_spring_boot_app/controller包下创建ReactiveCourseController.java文件:
java
package com.example.myapp.my_spring_boot_app.controller;
import com.example.myapp.my_spring_boot_app.model.Course;
import com.example.myapp.my_spring_boot_app.service.ReactiveCourseService;
import org.springframework.http.MediaType;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.PathVariable;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import reactor.core.publisher.Flux;
import reactor.core.publisher.Mono;
@RestController
@RequestMapping("/reactive/courses")
public class ReactiveCourseController {
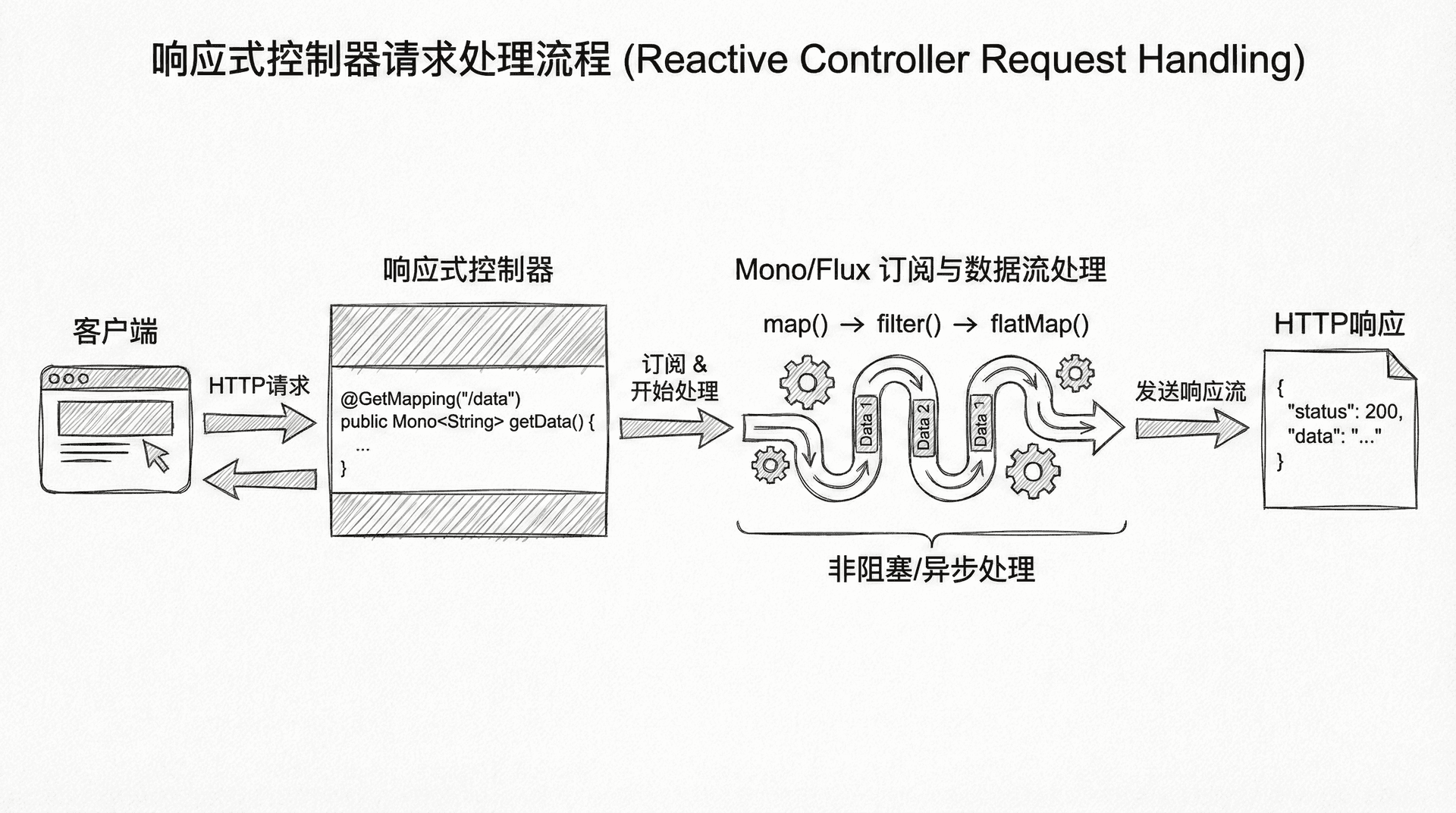
这个控制器与传统的Spring MVC控制器非常相似,主要区别在于返回类型。方法返回Mono<Course>或Flux<Course>而不是Course或List<Course>。Spring WebFlux会自动处理这些响应式类型,将它们转换为HTTP响应。
/stream端点使用了MediaType.TEXT_EVENT_STREAM_VALUE,这表示服务器发送事件(Server-Sent Events,SSE)。客户端可以通过EventSource API订阅这个端点,实时接收数据流。delayElements(Duration.ofSeconds(1))让每个元素延迟1秒发出,模拟实时数据流。
启动应用后,访问http://localhost:8080/reactive/courses,你会看到所有课程的JSON数组。访问http://localhost:8080/reactive/courses/stream,你会看到数据以流的形式逐步返回。
使用响应式操作符转换数据流
Project Reactor提供了丰富的操作符来转换和操作数据流,这些操作符类似于Java Stream API的操作符,但它们是响应式的,支持异步和非阻塞处理。理解这些操作符的使用对于编写高效的响应式代码非常重要。
让我们扩展ReactiveCourseService,添加更多使用操作符的方法:
java
public Flux<String> getCourseTitles() {
return findAllCourses()
.map(Course::getTitle)
.filter(title -> title.contains("Spring"));
}
public Flux<Course> getCoursesSortedByLevel() {
return findAllCourses()
.sort((c1, c2) -> Integer.compare
map操作符用于转换元素,将Course对象转换为标题字符串。filter操作符用于过滤元素,只保留标题包含"Spring"的课程。sort操作符用于排序,根据难度级别对课程进行排序。next操作符获取第一个元素并返回Mono。
flatMap操作符用于将每个元素转换为另一个Publisher并扁平化结果,它常用于异步操作。在这个例子中,每个课程都被包装在一个延迟的Mono中,模拟异步处理。doOnNext操作符用于执行副作用操作,比如打印日志,它不会改变数据流。
buffer操作符将元素收集到批次中,然后flatMap将每个批次转换为Flux。这种方式可以用于批量处理,减少操作次数,提高效率。
处理错误和异常
在响应式编程中,错误处理与传统的异常处理有所不同。由于操作是异步的,异常不能通过try-catch来捕获,而是通过错误信号在数据流中传播。Project Reactor提供了丰富的错误处理操作符来处理这种情况。
让我们看看如何在响应式流中处理错误:
java
public Mono<Course> findCourseByIdWithErrorHandling(Long id) {
return Mono.just(id)
.flatMap(courseId -> {
if (courseId < 0) {
return Mono.error(new IllegalArgumentException("课程ID不能为负数"));
}
return findCourseById(courseId);
})
.onErrorResume(IllegalArgumentException.class, e ->
Mono.error()创建一个包含错误的Mono,错误会在数据流中传播。onErrorResume操作符用于捕获特定类型的错误并提供一个替代的Publisher。onErrorReturn操作符用于在发生任何错误时返回一个默认值。
Flux.defer()延迟Publisher的创建,每次订阅时都会重新创建,这对于需要重试的操作非常有用。retry操作符会在发生错误时重新订阅Publisher,可以指定重试次数。在这个例子中,如果随机数大于0.5就会抛出错误,retry(3)会重试3次,如果仍然失败,onErrorReturn会返回一个默认的课程。
在控制器中使用错误处理:
java
@GetMapping("/{id}")
public Mono<ResponseEntity<Course>> getCourseById(@PathVariable Long id) {
return courseService.findCourseByIdWithErrorHandling(id)
.map(ResponseEntity::ok)
.onErrorReturn(ResponseEntity.status(HttpStatus.NOT_FOUND).build());
}这种方式让错误处理更加优雅,错误信息会通过HTTP状态码返回给客户端,而不是抛出异常。
实现响应式数据访问
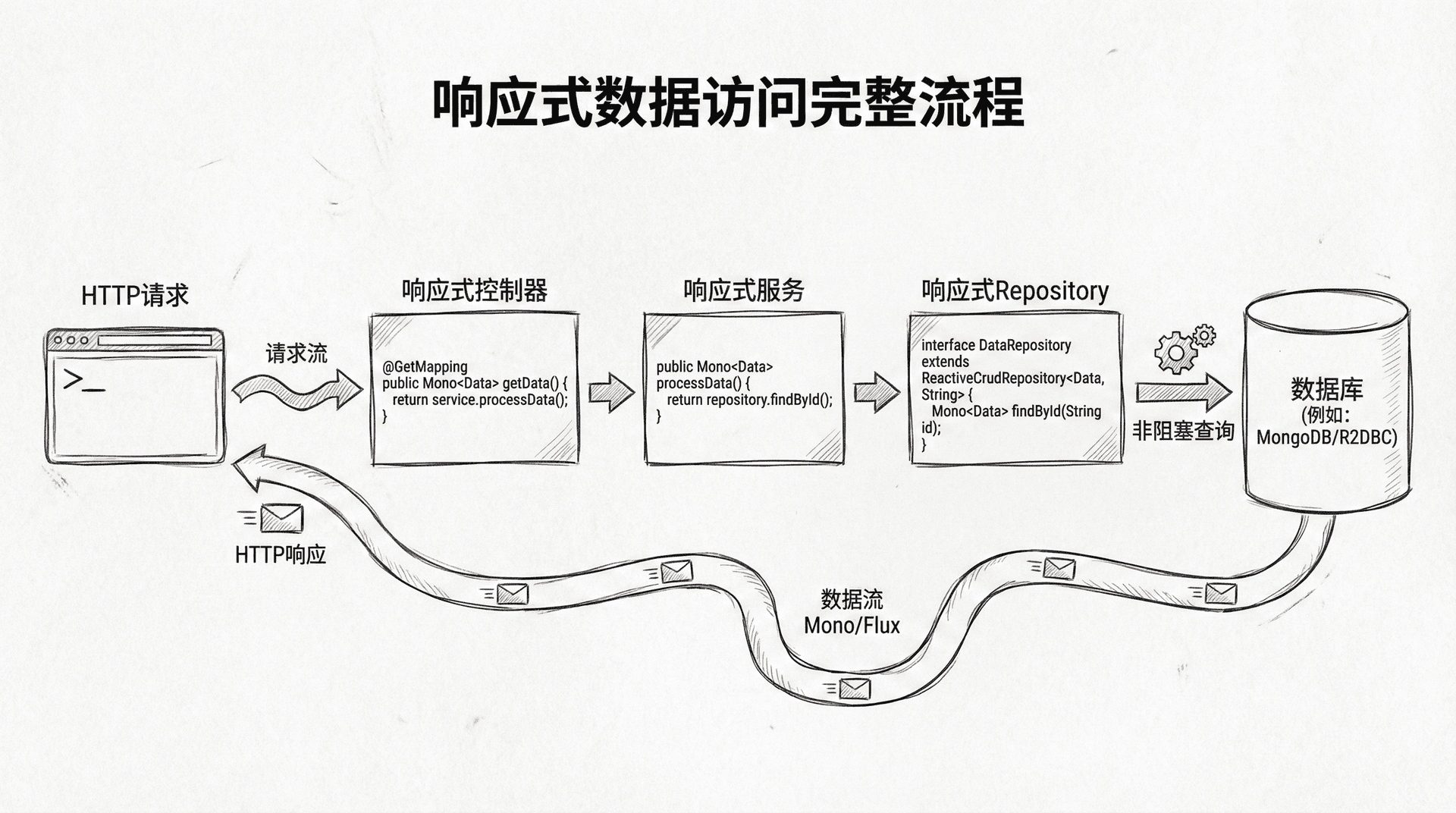
虽然Spring Data JPA是阻塞式的,但Spring Data提供了响应式版本,支持MongoDB、Cassandra、Couchbase等NoSQL数据库。对于关系型数据库,你可以使用R2DBC(Reactive Relational Database Connectivity)来实现响应式数据访问。
让我们看看如何使用R2DBC实现响应式数据访问。在pom.xml中添加R2DBC依赖:
xml
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-r2dbc</artifactId>
</dependency>
<dependency>
<groupId>io.r2dbc</groupId>
<artifactId>r2dbc-h2</artifactId>
<scope>runtime</scope>
</dependency>创建响应式Repository接口。在src/main/java/com/example/myapp/my_spring_boot_app/repository包下创建ReactiveCourseRepository.java文件:
java
package com.example.myapp.my_spring_boot_app.repository;
import com.example.myapp.my_spring_boot_app.model.Course;
import org.springframework.data.r2dbc.repository.R2dbcRepository;
import org.springframework.stereotype.Repository;
import reactor.core.publisher.Flux;
import reactor.core.publisher.Mono;
@Repository
public interface ReactiveCourseRepository extends R2dbcRepository<Course, Long> {
Flux<Course> findByCategory(String category);
Mono<Course> findByTitle
R2dbcRepository是响应式版本的Repository接口,它提供了与JpaRepository类似的方法,但返回的是Mono或Flux类型。方法名的约定与Spring Data JPA相同,Spring会自动生成对应的查询。
更新Course实体以支持R2DBC:
java
@Entity
@Table(name = "courses")
public class Course {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@Column
private String title;
@Column
private String description;
@Column
private String category;
@Column
R2DBC使用@Column注解来映射列,而不是JPA的注解。在application.properties中配置R2DBC连接:
properties
spring.r2dbc.url=r2dbc:h2:mem:///testdb?options=DB_CLOSE_DELAY=-1;DB_CLOSE_ON_EXIT=FALSE
spring.r2dbc.username=sa
spring.r2dbc.password=现在你可以在服务层使用响应式Repository:
java
@Service
public class ReactiveCourseService {
private final ReactiveCourseRepository repository;
public ReactiveCourseService(ReactiveCourseRepository repository) {
this.repository = repository;
}
public Flux<Course> findAllCourses() {
return repository.findAll();
}
public Mono<Course> findCourseById(Long id
所有操作都是非阻塞的,返回的是响应式类型。这种方式让整个数据访问链路都是响应式的,从HTTP请求到数据库查询,没有任何阻塞操作。
理解背压机制
背压是响应式编程中的核心概念,它解决了数据生产者和消费者速度不匹配的问题。当生产者产生数据的速度超过消费者处理的速度时,如果没有背压机制,数据会在内存中堆积,最终导致内存溢出。响应式流通过背压机制让消费者能够控制数据流的速度,当消费者处理不过来时,会向上游发送背压信号,减慢数据产生的速度。
让我们通过一个例子来理解背压:
java
public Flux<Integer> generateNumbers() {
return Flux.range(1, 1000000)
.delayElements(Duration.ofMillis(1))
.onBackpressureBuffer(1000)
.doOnNext(i -> {
if (i % 10000 == 0) {
System.out.println(
Flux.range(1, 1000000)生成从1到1000000的整数序列。delayElements(Duration.ofMillis(1))让每个元素延迟1毫秒发出,模拟慢速的生产者。onBackpressureBuffer(1000)设置缓冲区大小为1000,当缓冲区满时,会向上游发送背压信号。
如果消费者处理速度慢于生产者,缓冲区会逐渐填满。当缓冲区满时,onBackpressureBuffer会向上游发送背压信号,减慢数据产生的速度。如果缓冲区溢出,可以选择丢弃数据、抛出错误或使用其他策略。
在控制器中使用背压处理:
java
@GetMapping(value = "/numbers", produces = MediaType.TEXT_EVENT_STREAM_VALUE)
public Flux<Integer> streamNumbers() {
return courseService.generateNumbers()
.limitRate(100)
.doOnRequest(n -> System.out.println("请求 " + n + " 个元素"))
.doOnNext(n
limitRate(100)限制请求速率,每次最多请求100个元素。doOnRequest在每次请求时执行,可以用于监控请求行为。doOnNext中的延迟模拟慢速的消费者。当消费者处理速度慢时,背压机制会自动调整数据流的速度。
使用调度器控制执行线程
在响应式编程中,操作的执行线程由调度器(Scheduler)控制。Project Reactor提供了多种调度器,用于不同的场景。理解调度器的使用对于编写正确的响应式代码非常重要。
让我们看看如何使用不同的调度器:
java
public Flux<Course> findAllCoursesOnDifferentThread() {
return Flux.defer(() -> {
System.out.println("当前线程: " + Thread.currentThread().getName());
return findAllCourses();
})
.subscribeOn(Schedulers.boundedElastic())
.publishOn(Schedulers.parallel())
.doOnNext(course
subscribeOn指定订阅操作(数据产生)执行的线程池,Schedulers.boundedElastic()适合阻塞操作,它会创建有界的弹性线程池。publishOn指定后续操作(数据消费)执行的线程池,Schedulers.parallel()适合CPU密集型操作,它会创建与CPU核心数相等的线程池。
subscribeOn影响整个链路的执行线程,而publishOn只影响它之后的操作。这种设计让你能够精确控制不同操作的执行线程,优化性能。
在控制器中,WebFlux会自动处理线程调度,你通常不需要手动指定调度器。但在服务层执行阻塞操作时,应该使用Schedulers.boundedElastic()来避免阻塞事件循环线程。
组合多个响应式流
在实际应用中,你往往需要组合多个响应式流,比如并行查询多个数据源、等待多个操作完成、或者根据一个流的结果查询另一个流。Project Reactor提供了丰富的操作符来组合流。
让我们看看如何组合多个流:
java
public Mono<CourseDetails> getCourseDetails(Long id) {
Mono<Course> courseMono = findCourseById(id);
Mono<List<Chapter>> chaptersMono = findChaptersByCourseId(id);
return Mono.zip(courseMono, chaptersMono)
.map(tuple -> {
Course course = tuple.getT1();
List<Chapter> chapters = tuple.getT2
Mono.zip用于组合多个Mono,等待所有Mono完成并返回一个包含所有结果的元组。这种方式适合并行执行多个独立的操作,提高响应速度。
flatMap用于将每个元素转换为另一个Publisher,适合需要根据一个流的结果查询另一个流的场景。collectList将Flux转换为包含所有元素的Mono。
switchIfEmpty在当前流为空时切换到另一个流,适合提供默认值或备用数据源。
实现服务器发送事件
服务器发送事件(Server-Sent Events,SSE)是一种让服务器主动向客户端推送数据的技术。它基于HTTP长连接,服务器可以持续向客户端发送数据,非常适合实时数据推送的场景。
让我们创建一个SSE端点来实时推送课程更新:
java
@GetMapping(value = "/events", produces = MediaType.TEXT_EVENT_STREAM_VALUE)
public Flux<ServerSentEvent<Course>> streamCourseEvents() {
return Flux.interval(Duration.ofSeconds(1))
.flatMap(sequence -> findAllCourses()
.take(1)
.map(course ->
Flux.interval(Duration.ofSeconds(1))每秒发出一个递增的数字,用于模拟定时事件。ServerSentEvent用于构建SSE消息,包含ID、事件类型和数据。doOnCancel在客户端取消订阅时执行,可以用于清理资源。
客户端可以使用EventSource API来订阅这个端点:
javascript
const eventSource = new EventSource('http://localhost:8080/reactive/courses/events');
eventSource.addEventListener('course-update', function(event) {
const course = JSON.parse(event.data);
console.log('收到课程更新:', course);
});这种方式让客户端能够实时接收服务器推送的数据,非常适合实时监控、通知、数据同步等场景。
响应式编程特别适合高并发、高吞吐量的场景,但它也有学习曲线。在决定是否使用响应式编程时,需要权衡性能提升和代码复杂度。对于大多数应用,传统的阻塞式模型已经足够,但对于需要处理大量并发连接或实时数据流的应用,响应式编程能够带来显著的性能提升。
小结
现在你应该已经了解了响应式编程的核心理念,并且掌握了Mono和Flux在实际开发中的用法,知道了如何灵活应用各种数据流操作符,优雅地处理错误、异常和数据背压,并且能够组合多个流、实现高效的响应式数据访问。这些能力将极大提升你开发高性能、高并发应用的信心和水平。
在下一个部分中我们会继续深入,带你一起学习如何为Spring Boot应用编写稳定的测试,包括单元测试、集成测试和端到端测试,让你的代码不仅强大,同时也更加可靠。