元数据
当我们在数据库中创建表、索引、视图等对象时,数据库系统需要记录这些对象的相关信息。 比如一个表有哪些列、每列的数据类型是什么、有哪些约束条件等等。这些「关于数据的数据」就是我们今天要学习的元数据。
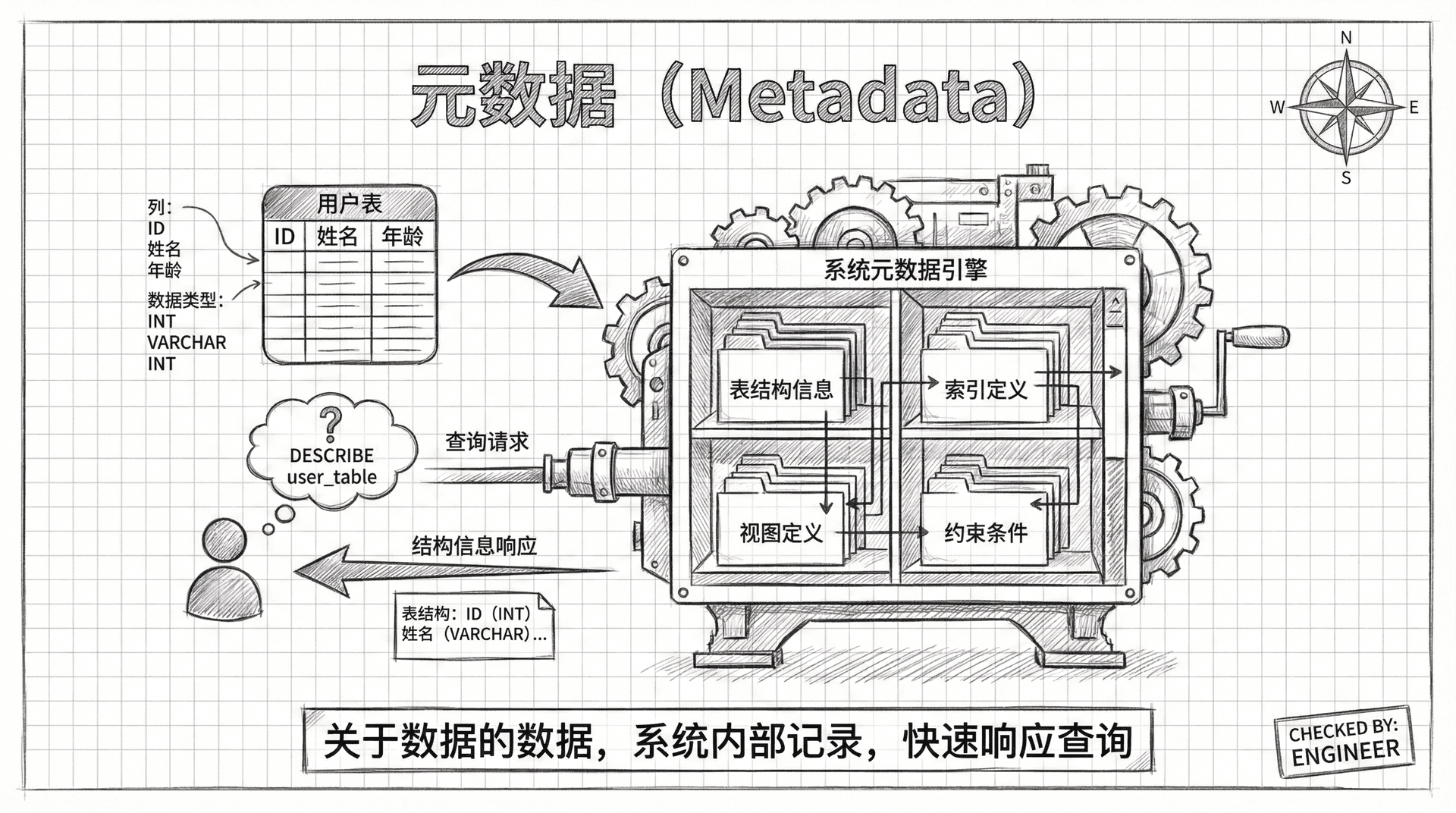
想象当你在MySQL中执行DESCRIBE user_table命令时,数据库是如何知道这个表有哪些列的?答案就是通过查询元数据。
数据库将所有的结构信息都存储在特殊的系统表中,这样就能快速响应我们的查询需求。
什么是元数据
元数据,顾名思义,是关于数据的数据。在数据库系统中,每当创建新的对象(如表、索引、视图等),系统会自动、系统性地记录该对象的结构、属性及约束等详细信息。 这些元数据为数据库的管理、查询优化和安全性校验等提供了基础支撑。
假设我们创建了一个员工表:
sql
CREATE TABLE employees (
id INT PRIMARY KEY AUTO_INCREMENT,
name VARCHAR(50) NOT NULL,
email VARCHAR(100) UNIQUE,
department_id INT,
hire_date DATE DEFAULT CURRENT_DATE
);数据库需要记录的元数据信息包括:表名是employees、有5个列、每列的名称和类型、哪个列是主键、哪些列有约束条件等等。
这些信息被统称为数据字典或系统目录。
数据库必须将元数据持久化存储,并且能够快速检索,因为每次执行SQL语句时都需要验证表结构、列名和数据类型是否正确。
不同的数据库系统使用不同的方式来暴露元数据信息。有些使用系统视图,有些提供存储过程,还有些创建专门的系统数据库。
MySQL和SQL Server都遵循ANSI SQL标准,提供了information_schema这个特殊的数据库来统一访问元数据。
information_schema数据库
information_schema 是 MySQL 提供的一个只读系统数据库,专门用于存储当前实例下所有数据库对象(如表、列、索引、约束等)的元数据信息。
通过该数据库,用户可以使用标准 SQL 语句高效、统一地查询和分析数据库结构。
我们来看一个实际的例子。假设我们有一个名为online_store的数据库,我们想查看其中所有的表:
sql
SELECT table_name, table_type
FROM information_schema.tables
WHERE table_schema = 'online_store'
ORDER BY table_name;这个查询会返回类似这样的结果:
table_type列告诉我们对象的类型:BASE TABLE表示普通的数据表,VIEW表示视图。
如果我们只想看数据表而不包括视图,可以添加过滤条件:
sql
SELECT table_name
FROM information_schema.tables
WHERE table_schema = 'online_store'
AND table_type = 'BASE TABLE'
ORDER BY table_name;查看列信息
若需获取某个表的详细结构信息,可查询information_schema.columns系统视图:
sql
SELECT
column_name,
data_type,
is_nullable,
column_default,
character_maximum_length
FROM information_schema.columns
WHERE table_schema = 'online_store'
AND table_name = 'products'
ORDER BY ordinal_position;这会显示products表的所有列信息:
ordinal_position字段确保我们按照列在表中的实际顺序来显示结果。
查看索引信息
在MySQL中,关于表索引的详细元数据信息存储在information_schema.statistics系统视图中。
该视图记录了每个索引的名称、包含的列、索引的唯一性、列在索引中的顺序等关键属性。
sql
SELECT
index_name,
column_name,
non_unique,
seq_in_index
FROM information_schema.statistics
WHERE table_schema = 'online_store'
AND table_name = 'products'
ORDER BY index_name, seq_in_index;结果可能是这样的:
这告诉我们products表有一个主键索引、一个单列价格索引,还有一个由产品名和价格组成的复合索引。
查询information_schema视图时要注意性能。如果数据库中有大量的表和列,某些查询可能会比较慢,所以建议在查询时尽量使用WHERE子句来限制范围。
查看约束信息
如果你想详细了解数据库中各种约束(如主键、外键、唯一约束等)的具体信息,可以通过查询information_schema.table_constraints视图来实现。
这个视图会为每个表列出所有定义的约束类型及其名称。例如,你可以查到某个表有哪些主键、哪些列上有唯一约束,或者存在哪些外键关联。
通过结合table_constraints和key_column_usage等视图,还能进一步获取约束涉及的具体列和引用关系。
sql
SELECT
constraint_name,
table_name,
constraint_type
FROM information_schema.table_constraints
WHERE table_schema = 'online_store'
ORDER BY constraint_type, table_name;结果示例:
information_schema常用视图总览
MySQL的information_schema数据库包含很多有用的视图,每个视图都有特定的用途:
通过这些视图,我们可以编写各种有用的查询来分析和管理数据库结构。
元数据的应用
在深入掌握元数据查询方法之后,我们能够将这些元数据信息广泛应用于实际的数据库管理与开发场景中。
数据库结构分析
在维护一个复杂的数据库系统时,我们经常需要对数据库的整体结构进行全面分析。 这不仅包括了解有哪些表,还要掌握每个表包含多少列、定义了多少索引、主键和外键等约束,以及这些表之间的关联关系。 例如,数据库管理员可能希望统计每个表的列数、索引数、主键信息等,以便评估表的复杂度、优化查询性能或进行结构调整。
此外,定期分析这些结构信息还有助于发现潜在的设计问题,比如某些表是否过于宽大(列数过多)、是否缺少必要的索引,或者是否存在未被约束的数据关系。 下面我们以“统计每个表的规模”为例,展示如何利用元数据进行结构分析:
sql
SELECT
table_name AS '表名',
(SELECT COUNT(*) FROM information_schema.columns
WHERE table_schema = 'online_store'
AND table_name = t.table_name) AS '列数',
(SELECT COUNT(*) FROM information_schema.statistics
这个查询能帮我们快速了解数据库中每个表的基本统计信息,对于数据库健康检查非常有用。
自动生成DDL语句
利用元数据,我们不仅可以查询表结构,还能自动生成完整的建表(DDL)语句。具体来说,可以通过查询information_schema.columns、information_schema.table_constraints等系统视图,获取表的所有列、数据类型、主键、默认值、
是否允许为空等详细信息,然后拼接成标准的CREATE TABLE语句。这种方法在以下场景非常有用:
- 数据库迁移:将表结构从一个数据库迁移到另一个数据库时,自动生成目标环境所需的建表语句,避免手工编写出错。
- 备份与恢复:在备份数据库结构时,自动导出所有表的DDL,便于后续恢复或重建环境。
- 环境搭建与自动化部署:在新环境初始化时,批量生成并执行建表语句,实现数据库结构的自动化部署。
- 结构文档生成:自动提取表结构信息,生成数据库文档,方便团队协作和维护。
通过这种自动化方式,可以大大提高数据库管理的效率和准确性,尤其适合表结构频繁变动或需要跨环境同步的场景。
假设我们要为customers表生成CREATE TABLE语句:
sql
SELECT CONCAT(
'CREATE TABLE ', table_name, ' (\n',
GROUP_CONCAT(
CONCAT(' ', column_name, ' ',
UPPER(data_type),
CASE
WHEN character_maximum_length IS NOT NULL
THEN CONCAT('(', character_maximum_length, ')')
WHEN numeric_precision IS NOT NULL
THEN CONCAT('(', numeric_precision,
这会生成类似这样的结果:
sql
CREATE TABLE customers (
customer_id INT NOT NULL,
first_name VARCHAR(50) NOT NULL,
last_name VARCHAR(50) NOT NULL,
email VARCHAR(100) NOT NULL,
phone VARCHAR(20),
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);虽然这个例子展示了基本思路,但在实际项目中,还是建议使用专门的数据库迁移工具如mysqldump、Flyway等,它们能处理更复杂的情况并且更加可靠。
数据库文档生成
通过查询和分析数据库的元数据信息,我们可以自动化生成详尽、结构化的数据库文档。
例如,可以基于information_schema视图自动提取每个表的结构、字段类型、约束条件、注释等内容,生成标准化的表结构说明文档。
sql
SELECT
CONCAT('## ', table_name, '表\n\n') AS documentation
FROM information_schema.tables
WHERE table_schema = 'online_store'
AND table_type = 'BASE TABLE'
UNION ALL
SELECT
CONCAT('| ', column_name, ' | ', data_type,
CASE WHEN character_maximum_length IS NOT NULL
THEN CONCAT
这样我们就能快速生成Markdown格式的数据库文档,让团队成员更容易理解数据库结构。
监控数据库变更
在团队开发环境中,我们可以定期查询元数据来监控数据库结构的变化。例如,我们可以检查最近创建的表:
sql
-- 检查最近创建的表
SELECT
table_name,
create_time
FROM information_schema.tables
WHERE table_schema = 'online_store'
AND create_time > DATE_SUB(NOW(), INTERVAL 7 DAY)
ORDER BY create_time DESC;或者查找没有主键的表:
sql
-- 查找没有主键的表
SELECT table_name
FROM information_schema.tables t
WHERE table_schema = 'online_store'
AND table_type = 'BASE TABLE'
AND NOT EXISTS (
SELECT 1
FROM information_schema.table_constraints tc
WHERE tc.table_schema = t.table_schema
AND tc.table_name
这些查询不仅可以帮助我们及时发现数据库设计中的潜在问题,例如缺失主键、表结构异常变更等,还能让我们在团队协作中更好地追踪数据库的演进过程。 通过定期执行这些元数据查询,我们可以快速定位新建表、结构变更或不规范设计,从而及时优化数据库结构,提升数据一致性和系统稳定性。
动态SQL与元数据结合
元数据的一个强大应用场景是与动态SQL结合使用。所谓动态SQL,就是在程序运行时根据实际需求动态拼接和执行SQL语句,而不是在代码中写死具体的SQL。 这样可以让我们的程序更加灵活,能够适应不同的业务场景和数据结构的变化。
在实际开发中,元数据(如information_schema中的表和字段信息)为动态SQL的生成提供了基础。
例如,我们可以通过查询元数据,自动获取某个表的所有字段,然后拼接成SELECT、INSERT或UPDATE等SQL语句。
这样一来,即使表结构发生变化(比如新增或删除字段),我们的SQL生成逻辑也能自动适配,无需手动修改代码。
动态SQL常用于批量数据处理、自动化脚本、通用报表、数据同步等场景。 结合元数据,我们可以实现如“自动生成全表SELECT语句”、“根据主键自动生成UPDATE语句”等高级功能,大大提升开发效率和系统的可维护性。
MySQL提供了PREPARE、EXECUTE和DEALLOCATE PREPARE语句来支持动态SQL执行:
sql
-- 设置查询变量
SET @sql = 'SELECT customer_id, first_name, last_name FROM customers WHERE customer_id = ?';
-- 预处理语句
PREPARE stmt FROM @sql;
-- 设置参数并执行
SET @customer_id = 1001;
EXECUTE stmt USING @customer_id;
-- 清理资源
DEALLOCATE PREPARE stmt;更有趣的是,我们可以利用元数据来动态构建查询语句。比如,根据表结构自动生成SELECT语句:
sql
-- 动态生成包含所有列的SELECT语句
SELECT CONCAT(
'SELECT ',
GROUP_CONCAT(column_name ORDER BY ordinal_position),
' FROM ', table_name,
' WHERE customer_id = ?'
) INTO @dynamic_sql
FROM information_schema.columns
WHERE table_schema = 'online_store'
AND table_name = 'customers'
GROUP BY table_name;
-- 查看生成的SQL
SELECT @dynamic_sql;
-- 执行动态SQL
PREPARE dynamic_stmt FROM
这种方法的优势是,即使表结构发生变化(增加或删除列),我们的查询代码也不需要修改,因为它会自动适应新的表结构。
使用动态SQL时要特别注意SQL注入攻击的风险。始终使用参数化查询(如上面的?占位符),永远不要直接将用户输入拼接到SQL字符串中!
性能监控与优化
元数据不仅可以帮助我们了解数据库结构,还能在性能监控与优化方面发挥重要作用。
通过查询information_schema等元数据表,我们可以发现数据库设计和运行中的潜在问题。
例如,某些大表如果没有合适的索引,查询效率会很低,容易成为性能瓶颈。
我们可以通过元数据查询,自动找出这些缺少索引(除主键外)的表,从而有针对性地进行优化。
sql
-- 查找没有索引的表(除了主键外)
SELECT t.table_name
FROM information_schema.tables t
WHERE t.table_schema = 'online_store'
AND t.table_type = 'BASE TABLE'
AND (SELECT COUNT(*)
FROM information_schema.statistics s
WHERE s.table_schema = t.table_schema
或者找出有很多列但很少被查询的「宽表」:
sql
-- 查找列数超过10列的表
SELECT
table_name,
COUNT(*) AS column_count
FROM information_schema.columns
WHERE table_schema = 'online_store'
GROUP BY table_name
HAVING COUNT(*) > 10
ORDER BY column_count DESC;实战练习
习题1:查询员工表的列信息
假设有一个 company 数据库,其中包含一个 employees 表,表结构如下:
请编写 SQL 查询来获取 employees 表的详细信息,包括列名、数据类型、是否可空和默认值。
习题2:查询表的索引信息
在同一个 company 数据库中,employees 表有以下索引结构:
- 主键索引:employee_id
- 唯一索引:email
- 复合索引:department_id, hire_date(按部门和入职日期)
请编写 SQL 查询来查看 employees 表的所有索引信息。
习题3:查询约束信息
company 数据库中的表有以下约束:
- employees 表:主键约束 PRIMARY,唯一约束 uk_email
- departments 表:主键约束 PRIMARY,外键约束 fk_emp_dept(引用 employees.department_id)
请查询 company 数据库中所有表的约束信息。
习题4:生成建表语句
基于以下表结构,编写 SQL 查询来自动生成 products 表的建表语句:
products 表结构:
习题5:统计数据库结构
company 数据库包含以下表:
- employees(员工表)
- departments(部门表)
- products(产品表)
- orders(订单表)
- order_items(订单明细表)
请编写查询来统计每个表的基本信息:表名、列数、索引数(不含主键)、约束数。
习题6:查找缺少主键的表
在数据库设计中,每个表都应该有主键。请编写查询来找出 company 数据库中没有主键的表。
习题7:动态生成查询语句
基于 employees 表的结构(employee_id, first_name, last_name, email, hire_date, salary, department_id),编写查询来动态生成一个包含所有列的 SELECT 语句。
习题8:查找宽表
“宽表”通常指列数较多的表。请找出 company 数据库中列数超过 8 列的表,并显示它们的列数。
习题9:生成数据库文档
基于以下 customers 表的结构,编写查询来生成 Markdown 格式的表结构文档:
customers 表结构:
习题10:检查外键关系
company 数据库中的表存在以下外键关系:
- employees.department_id -> departments.department_id
- orders.customer_id -> customers.customer_id
- order_items.order_id -> orders.order_id
- order_items.product_id -> products.product_id
请编写查询来查看所有外键约束及其引用的表和列。