视图
在设计应用程序时,我们通常会暴露公共接口而隐藏实现细节,这样可以在不影响最终用户的情况下进行未来的设计更改。 在数据库设计中,我们可以通过保持表的私有性,并只允许用户通过一组视图来访问数据,从而实现类似的效果。
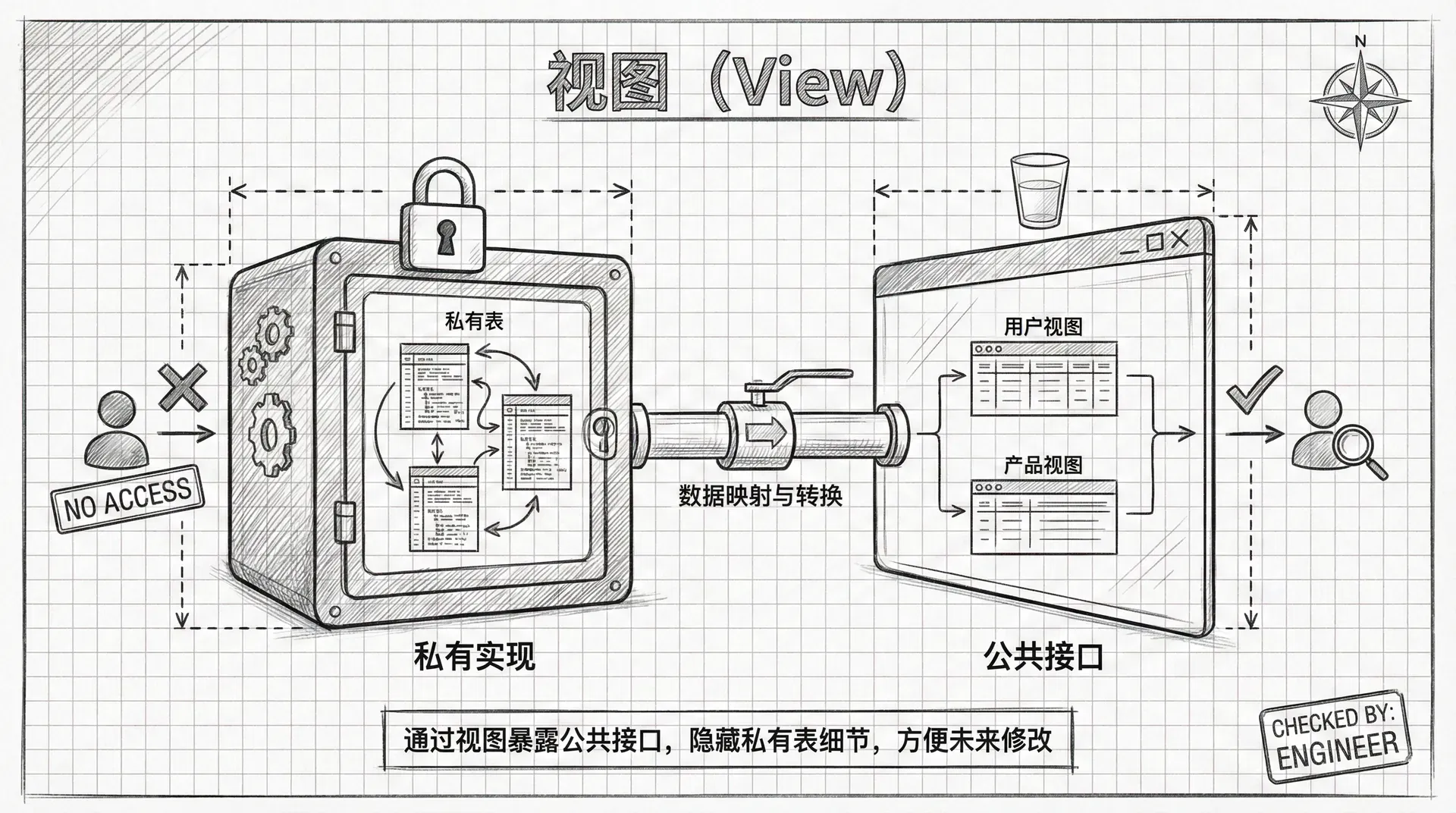
什么是视图
视图本质上是一个查询数据的机制。与表不同,视图不涉及数据存储,你不需要担心视图会占用磁盘空间。 创建视图的过程很简单:为一个select语句分配一个名称,然后将该查询存储起来供其他人使用。 其他用户可以像查询普通表一样使用你的视图来访问数据,他们甚至可能不知道自己正在使用视图。
让我们用一个具体的例子来理解视图的概念。假设我们有一个在线书店的用户表,包含了用户的完整手机号码。
出于隐私保护的考虑,客服部门只需要看到手机号的后四位来验证用户身份,而不应该看到完整的手机号。
因此,我们不允许直接访问用户表,而是定义一个名为user_vw的视图,要求所有员工都使用它来访问用户数据。
sql
CREATE VIEW user_vw
(user_id,
phone_masked,
user_type,
city,
register_date
)
AS
SELECT user_id,
concat('****', substr(phone, 8, 4)) phone_masked,
user_type,
city,
register_date
FROM users;这个语句的第一部分列出了视图的列名,这些列名可以与底层表的列名不同(例如,user_vw视图有一个名为phone_masked的列,它映射到users.phone列)。
语句的第二部分是一个select语句,必须为视图中的每一列提供一个表达式。
当执行create view语句时,数据库服务器只是存储视图定义以备将来使用;查询不会被执行,也不会检索或存储任何数据。
一旦创建了视图,用户就可以像查询表一样查询它:
sql
SELECT user_id, phone_masked, user_type
FROM user_vw;查询结果可能如下所示:
实际上,数据库服务器在执行查询时,并非简单地运行用户提交的SQL语句,也不是直接执行视图的定义语句。 相反,服务器会将用户的查询与视图的定义进行解析和优化,生成一个新的、等价的查询语句。例如,在本例中,最终执行的SQL如下:
sql
SELECT user_id,
concat('****', substr(phone, 8, 4)) phone_masked,
user_type
FROM users;尽管user_vw视图在定义时包含了用户表的五个字段,但在实际查询过程中,数据库服务器仅会检索被请求的三列。这
种行为体现了数据库在处理视图时的优化能力,尤其是在视图列涉及函数计算或子查询时,这一点尤为关键。
从使用者的角度来看,视图与物理表无异。若需了解视图的具体列结构,可通过数据库的DESCRIBE命令进行查看:
sql
DESCRIBE user_vw;你可以在查询视图时自由使用select语句的任何子句,包括group by、having和order by。下面是一个例子:
sql
SELECT user_type, count(*)
FROM user_vw
WHERE city = '北京'
GROUP BY user_type
ORDER BY 1;此外,你可以在查询中将视图与其他表(甚至其他视图)连接,如下所示:
sql
SELECT u.user_id, u.phone_masked, o.order_count
FROM user_vw u INNER JOIN order_summary o
ON u.user_id = o.user_id;这个查询将user_vw视图与订单汇总表连接,以检索用户的脱敏信息和订单统计。
为什么使用视图
我们刚刚通过一个简单的视图示例,展示了如何对用户表中的手机号码进行掩码处理,实现了基础的数据脱敏功能。 实际上,视图(View)作为数据库中的一种虚拟表结构,远不止于此用途。 视图在实际业务系统中具有多方面的重要价值,包括但不限于数据安全隔离、敏感信息保护、数据访问权限控制、复杂查询逻辑封装、数据聚合与统计、跨表数据整合、接口标准化等。
数据安全
如果你创建一个表并允许用户查询它,他们将能够访问表中的每一列和每一行。 但是,你的表可能包含一些敏感数据的列,比如身份证号码或银行卡号; 向所有用户公开这些数据不仅是一个坏主意,而且可能违反公司的隐私政策,甚至违反国家法律。
解决这些情况的最佳方法是保持表的私有性(即不授予任何用户查询权限),然后创建一个或多个视图来省略或模糊敏感列。 你还可以通过在视图定义中添加where子句来约束用户可以访问的行。
例如,下面的视图定义只允许查询VIP用户:
sql
CREATE VIEW vip_user_vw
(user_id,
phone_masked,
city,
membership_level
)
AS
SELECT user_id,
concat('****', substr(phone, 8, 4)) phone_masked,
city,
membership_level
FROM users
WHERE membership_level = 'VIP';如果你将此视图提供给VIP客服部门,他们将只能访问VIP账户,因为视图的where子句中的条件将始终包含在他们的查询中。
视图不是完整的一次性安全解决方案。你仍然需要在应用程序层面实施适当的访问控制和权限管理。
数据聚合
在实际业务场景中,报表类应用通常需要对数据进行聚合统计。通过视图,可以将复杂的聚合逻辑封装起来,使数据以预聚合的形式呈现,提升查询效率并简化应用开发。 例如,某应用每月需生成各城市的用户数量及订单总额统计报表。此时,可为开发人员提供如下视图,无需其直接操作底层表结构:
sql
CREATE VIEW city_stats_vw
(city_name,
user_count,
total_orders,
avg_order_amount
)
AS
SELECT u.city,
count(DISTINCT u.user_id) user_count,
count(o.order_id) total_orders,
avg(o.amount) avg_order_amount
FROM users u LEFT JOIN orders o
ON u.
使用这种方法为数据库设计人员提供了很大的灵活性。如果你在将来的某个时候决定,如果数据在表中预聚合而不是使用视图求和,查询性能会显著提高,
你可以创建一个city_stats表并修改city_stats_vw视图定义从这个表检索数据。在修改视图定义之前,你可以使用它来填充新表:
sql
-- 创建聚合表
CREATE TABLE city_stats
AS
SELECT * FROM city_stats_vw;
-- 修改视图指向新表
CREATE OR REPLACE VIEW city_stats_vw
AS
SELECT city_name, user_count, total_orders, avg_order_amount
FROM city_stats;从现在开始,所有使用city_stats_vw视图的查询都将从新的city_stats表中提取数据,这意味着用户将看到性能改进,而无需修改他们的查询。
隐藏复杂性
使用视图的最常见原因之一是保护最终用户免受复杂性的影响。例如,假设每月创建一份报告,显示每个部门的员工数量、活跃项目数量和总预算。你可以提供一个如下所示的视图,而不是期望报告设计人员浏览四个不同的表来收集必要的数据:
sql
CREATE VIEW department_summary_vw
(dept_name,
location,
employee_count,
active_projects,
total_budget
)
AS
SELECT d.name, d.location,
(SELECT count(*)
FROM employees e
WHERE e.dept_id = d.dept_id) emp_count,
(SELECT count
这个视图定义很有趣,因为五列中的三列是使用标量子查询生成的。如果有人使用这个视图但没有引用employee_count、active_projects或total_budget列,那么这些子查询都不会被执行。
连接分区数据
一些数据库设计将大表分解为多个部分以提高性能。例如,如果订单表变得很大,设计人员可能决定将其分解为两个表:orders_current,包含最近三个月的数据,和orders_archive,包含三个月前的所有数据。
如果客户想要查看某个账户的所有订单,你需要查询两个表。但是,通过创建一个查询两个表并将结果合并在一起的视图,你可以让它看起来像所有订单数据都存储在一个表中:
sql
CREATE VIEW orders_vw
(order_id,
user_id,
order_date,
amount,
status,
created_date
)
AS
SELECT order_id, user_id, order_date, amount, status, created_date
FROM orders_archive
UNION ALL
SELECT order_id, user_id, order_date, amount, status, created_date
FROM orders_current;在这种情况下使用视图是一个好主意,因为它允许设计人员在不需要强制所有数据库用户修改其查询的情况下更改底层数据的结构。
可更新视图
如果你为用户提供一组视图用于数据检索,那么当用户还需要修改相同的数据时该怎么办? 例如,强制用户使用视图检索数据,但然后允许他们使用update或insert语句直接修改底层表,这似乎有点奇怪。 为此,MySQL、Oracle数据库和SQL Server都允许你通过视图修改数据,只要你遵守某些限制。
在MySQL中,如果满足以下条件,视图是可更新的:
- 不使用聚合函数(max()、min()、avg()等)
- 视图不使用group by或having子句
- select或from子句中不存在子查询,where子句中的任何子查询都不引用from子句中的表
- 视图不使用union、union all或distinct
- from子句包含至少一个表或可更新视图
- 如果有多个表或视图,from子句只使用内连接
虽然可更新视图为我们提供了便利,但在实际应用中,我们仍然建议通过应用程序层来控制数据修改,以确保业务逻辑的一致性和数据的完整性。
为了演示可更新视图的实用性,我们从一个简单的视图定义开始,然后转到更复杂的视图。
更新简单视图
让我们从我们刚刚创建的视图开始,这个视图相当简单:
sql
CREATE VIEW user_vw
(user_id,
phone_masked,
user_type,
city,
register_date
)
AS
SELECT user_id,
concat('****', substr(phone, 8, 4)) phone_masked,
user_type,
city,
register_date
FROM users;user_vw视图查询单个表,七列中只有一列是通过表达式派生的。此视图定义不违反前面列出的任何限制,因此你可以使用它来修改用户表中的数据:
sql
UPDATE user_vw
SET city = '深圳'
WHERE city = '广州';查询结果会显示修改了一行:
text
Query OK, 1 row affected (0.34 sec)
Rows matched: 1 Changed: 1 Warnings: 0
让我们检查底层的用户表,确认修改确实生效了:
sql
SELECT DISTINCT city FROM users;结果可能如下所示:
虽然你可以通过这种方式修改视图中的大部分列,但你无法修改phone_masked列,因为它是从表达式派生的:
sql
UPDATE user_vw
SET city = '广州', phone_masked = '****9999'
WHERE city = '深圳';这会产生类似下面的错误:
shell
ERROR 1348 (HY000): Column 'phone_masked' is not updatable在这种情况下,这可能不是坏事,因为视图的整个目的就是模糊手机号码。
如果你想使用user_vw视图插入数据,你会遇到困难;包含派生列的视图不能用于插入数据,即使派生列不包含在语句中。
例如,下一个语句尝试仅使用user_vw视图填充user_id、user_type和city列:
sql
INSERT INTO user_vw(user_id, user_type, city)
VALUES (9999, 'VIP', '成都');这会产生类似下面的错误:
shell
ERROR 1471 (HY000): The target table user_vw of the INSERT is not insertable-into更新复杂视图
尽管单表视图较为常见,但在实际业务场景中,许多视图的底层查询往往涉及多个表的联合。 如下所示的视图,通过连接用户表与订单表,实现了对用户订单信息的统一查询与展示:
sql
CREATE VIEW user_order_vw
(user_id,
username,
city,
user_type,
order_id,
order_date,
amount
)
AS
SELECT u.user_id,
u.username,
u.city,
u.user_type,
o.order_id,
o.order_date,
o.
你可以使用此视图更新用户表或订单表中的数据,如下的例子所示:
sql
-- 更新用户表的城市信息
UPDATE user_order_vw
SET city = '北京'
WHERE user_id = 101;
-- 更新订单表的金额信息
UPDATE user_order_vw
SET amount = 1500.00
WHERE order_id = 50001;上述第一个语句实际更新了users表中的city字段,第二个语句则更新了orders表中的amount字段。
你或许会关心:如果尝试在同一条语句中同时更新两个基表的字段,会发生什么情况?
sql
UPDATE user_order_vw
SET city = '上海', amount = 2000.00
WHERE user_id = 101;这会产生类似下面的错误:
shell
ERROR 1393 (HY000): Can not modify more than one base table through a join view 'user_order_vw'如上所示,通过该视图可以分别对两个底层表的数据进行修改,但在同一条语句中同时更新两个基表的列是不被允许的。 接下来,我们进一步探讨通过该视图插入新用户数据的可行性:
sql
-- 尝试插入用户信息
INSERT INTO user_order_vw
(user_id, username, city, user_type)
VALUES (102, 'newuser', '武汉', 'VIP');该语句通常可以成功执行,因为它仅涉及向用户表插入数据,并未涉及订单表的字段。相反,如果你尝试插入订单相关信息:
sql
-- 尝试插入订单信息
INSERT INTO user_order_vw
(user_id, order_id, order_date, amount)
VALUES (102, 50002, '2024-01-15', 800.00);该操作通常会失败,其原因在于user_id列同时存在于两个基表中,但视图中的user_id仅映射自users.user_id。
因此,通过该视图无法实现对订单表的插入操作。
在复杂的应用程序中,通过视图更新数据有太多限制。对于非简单的应用程序,建议使用存储过程或应用程序层逻辑来处理数据修改操作。
实践练习
习题 1:创建用户隐私视图
假设有一个 employees 员工表,包含以下字段:
emp_id(INT): 员工IDname(VARCHAR): 员工姓名phone(VARCHAR): 手机号码email(VARCHAR): 邮箱地址salary(DECIMAL): 薪资dept_name(VARCHAR): 部门名称hire_date(DATE): 入职日期
请创建一个视图 emp_privacy_vw,要求:
- 隐藏完整的手机号码,只显示后四位(格式:****1234)
- 隐藏薪资信息
- 包含其他所有字段
习题 2:部门统计聚合视图
使用上面的 employees 表和一个 projects 项目表,projects 表包含以下字段:
project_id(INT): 项目IDproject_name(VARCHAR): 项目名称dept_name(VARCHAR): 负责部门budget(DECIMAL): 项目预算status(VARCHAR): 项目状态('进行中'、'已完成'、'暂停')start_date(DATE): 开始日期
请创建一个视图 dept_stats_vw,显示每个部门的项目统计信息,包含:
- 部门名称
- 员工数量
- 进行中的项目数量
- 总项目预算
习题 3:订单分区视图
假设订单数据被分成了两个表:
orders_recent 表(最近6个月的订单):
order_id(INT): 订单IDcustomer_id(INT): 客户IDorder_date(DATE): 下单日期amount(DECIMAL): 订单金额status(VARCHAR): 订单状态
orders_archive 表(6个月前的历史订单):
order_id(INT): 订单IDcustomer_id(INT): 客户IDorder_date(DATE): 下单日期amount(DECIMAL): 订单金额status(VARCHAR): 订单状态
请创建一个统一的视图 orders_all_vw,让用户可以查询所有订单数据,就像查询一个表一样。
习题 4:可更新视图练习
使用 employees 表(字段同习题1),创建一个可更新的视图 emp_contact_vw,包含:
emp_idnameemaildept_name
然后编写SQL语句通过此视图更新员工的邮箱地址。
习题 5:多表连接视图
使用 employees 表和 projects 表(字段同习题2),创建一个视图 emp_project_vw,显示每个员工及其参与的项目信息:
视图字段:
emp_idnamedept_nameproject_nameproject_budgetproject_status
习题 6:带条件过滤的视图
使用 employees 表,创建一个视图 senior_emp_vw,只显示工作年限超过3年的员工信息。
视图包含字段:
emp_idnameemaildept_namehire_dateyears_of_service