多表查询
在之前的课程中,我们学习了如何将数据通过规范化过程分解到不同的表中。比如我们可能有一个「学生」表和一个「专业」表。但是,当我们需要生成一份包含学生姓名、专业名称的综合报告时,就需要一种机制将这些分散在不同表中的数据重新组合起来。 这种机制就叫做「连接」,现在我们将重点介绍最简单也是最常用的连接类型——内连接。
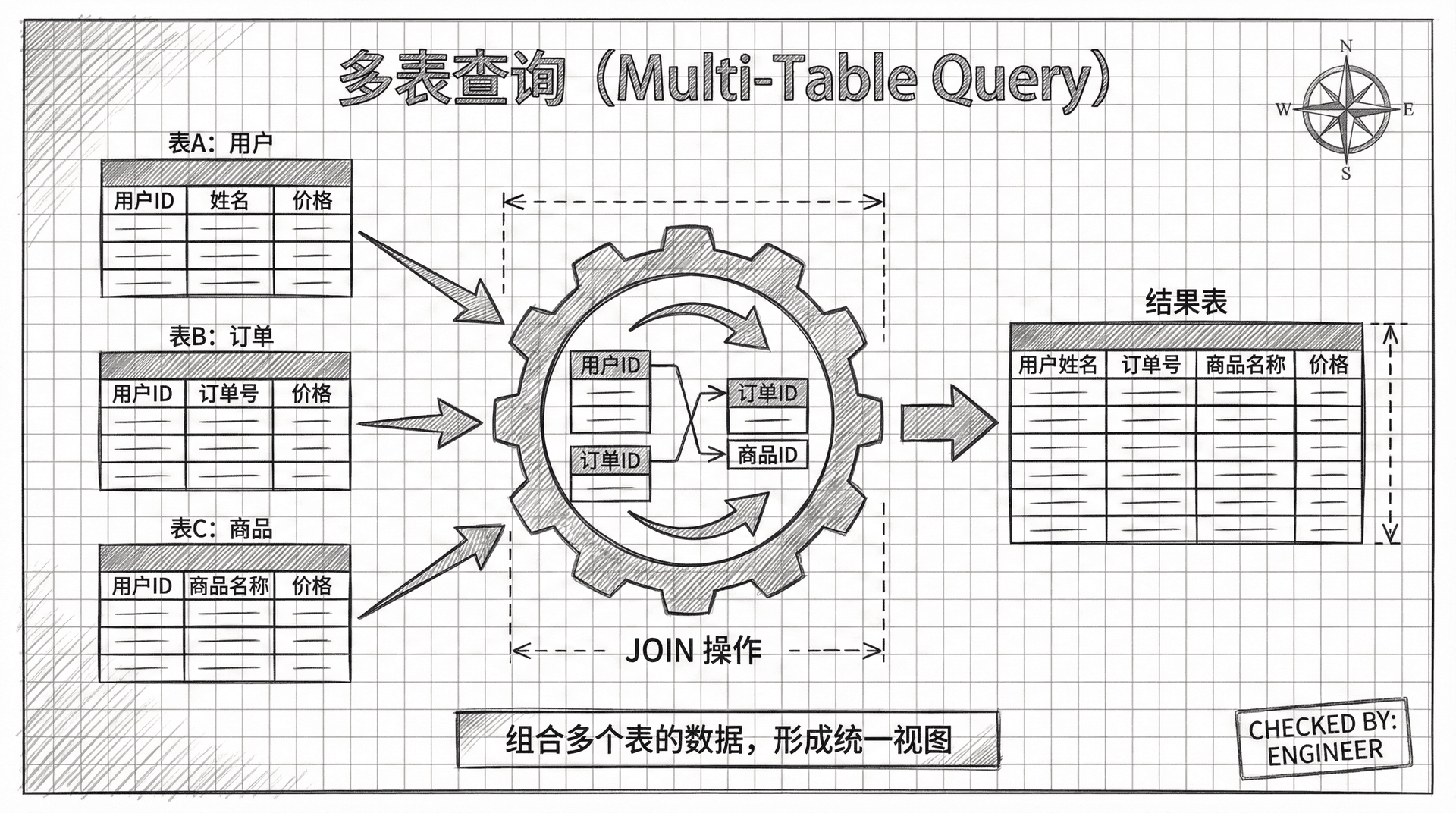
什么是连接
虽然单表查询在实际工作中也很常见,但你会发现大多数查询都需要涉及两个、三个甚至更多的表。为了说明这一点,让我们来看看「员工」表和「部门」表的结构,然后设计一个能够从这两个表中检索数据的查询。 假设我们有以下两个表:
员工表结构:
sql
DESC 员工表;部门表结构:
sql
DESC 部门表;现在假设我们想要获取每个员工的姓名以及他们所属部门的名称。我们的查询需要检索「员工表.姓名」和「部门表.部门名称」这两个字段。但是,如何在一个查询中从两个表获取数据呢?
答案就在于「员工表.部门编号」字段,它保存了每个员工所属部门的ID。更正式地说,「员工表.部门编号」是指向「部门表」的外键。查询会指示数据库服务器使用「员工表.部门编号」作为连接「员工表」和「部门表」的桥梁,从而允许两个表的字段都包含在查询结果中。
外键是连接不同表的关键。它建立了表之间的关联关系,使我们能够将存储在不同表中的相关数据组合在一起。
让我们通过一个具体的例子来理解这个概念。假设员工「张三」在员工表中的部门编号字段值为101,数据库服务器会使用这个值去部门表中查找部门编号为101的记录,然后获取该记录的部门名称字段,比如「技术部」。
这种将多个表中的数据组合起来的操作就称为「连接」。通过连接,我们可以创建包含来自多个表的信息的结果集,这正是关系数据库强大功能的体现。
笛卡尔积
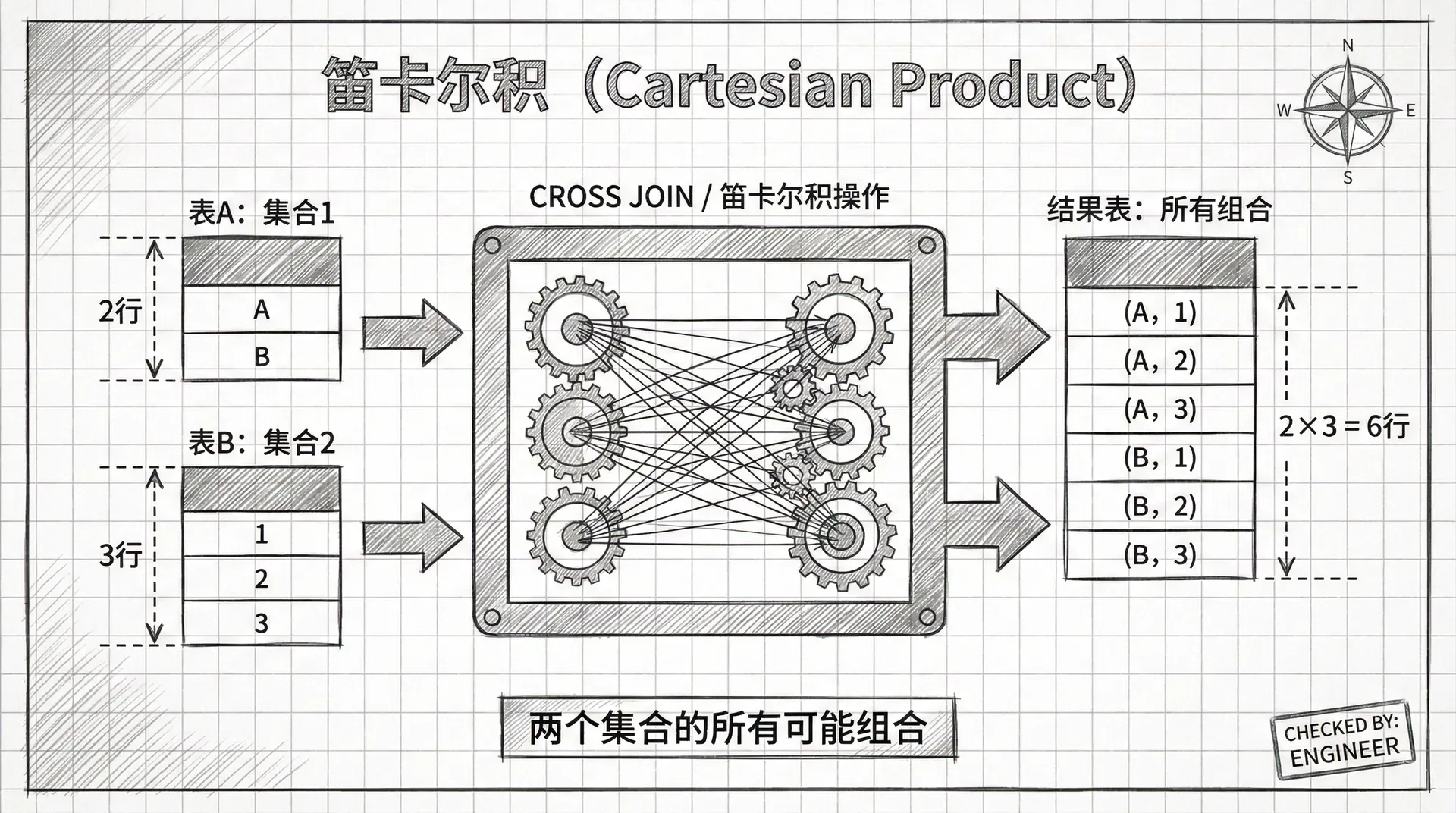
最直接的方式是将「员工表」和「部门表」都放入查询的FROM子句中,看看会发生什么。下面是一个查询员工姓名和部门名称的例子,在FROM子句中使用JOIN关键字连接两个表:
sql
SELECT e.姓名, d.部门名称
FROM 员工表 e JOIN 部门表 d;假设我们的数据是这样的:
员工表数据:
部门表数据:
执行上面的查询后,你可能会惊讶地发现结果是这样的:
我们有3个员工和3个部门,但结果却显示了9行!仔细观察可以发现,每个员工的姓名都和所有部门名称进行了组合。这是因为查询没有指定两个表应该如何连接,所以数据库服务器生成了笛卡尔积,也就是两个表的所有可能的排列组合(3个员工 × 3个部门 = 9种组合)。
笛卡尔积通常不是我们想要的结果。它会产生大量无意义的数据组合,在实际应用中很少故意使用。
这种类型的连接被称为「交叉连接」,除非有特殊需求,否则在实际工作中应该避免使用。想象一下,如果员工表有1000条记录,部门表有10条记录,笛卡尔积会产生10000行结果,这显然不是我们想要的。
内连接
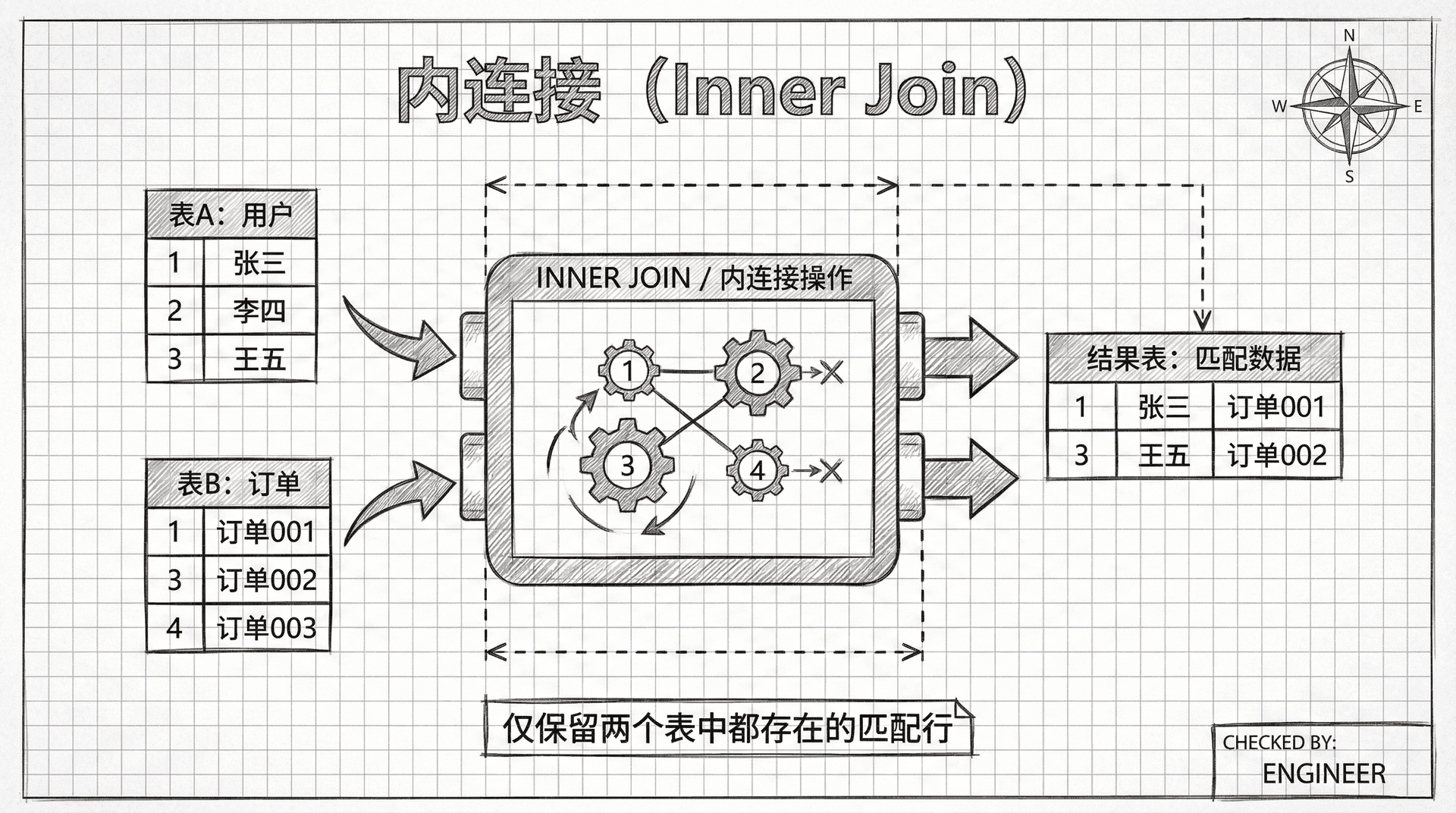
要让前面的查询只返回3行结果(每个员工一行),我们需要描述两个表是如何关联的。之前我们提到,「员工表.部门编号」字段是连接两个表的桥梁,所以我们需要将这个信息添加到FROM子句的ON子句中:
sql
SELECT e.姓名, d.部门名称
FROM 员工表 e JOIN 部门表 d
ON e.部门编号 = d.部门编号;现在查询结果变成了我们期望的样子:
我们从9行结果减少到了预期的3行,这要归功于ON子句的添加。ON子句指示服务器通过部门编号字段来连接员工表和部门表。例如,张三在员工表中的部门编号字段值为101,服务器使用这个值在部门表中查找部门编号为101的行,然后获取该行的部门名称「技术部」。
如果某个表中存在部门编号值,但在另一个表中找不到对应的记录,那么连接会失败,这些行会被排除在结果集之外。这种类型的连接称为「内连接」,它是最常用的连接类型。
内连接只会返回在两个表中都能找到匹配记录的行。如果某行在任一表中没有匹配的记录,它就不会出现在结果中。
在前面的例子中,我们没有在FROM子句中明确指定连接类型。但是,当你希望使用内连接来连接两个表时,应该在FROM子句中明确指定。下面是相同的例子,但添加了连接类型的关键字:
sql
SELECT e.姓名, d.部门名称
FROM 员工表 e INNER JOIN 部门表 d
ON e.部门编号 = d.部门编号;如果你不指定连接类型,服务器默认会执行内连接。但是由于存在多种连接类型,你应该养成明确指定所需连接类型的习惯。
当用于连接两个表的字段名相同时(就像前面查询中的情况),你可以使用USING子句来代替ON子句:
sql
SELECT e.姓名, d.部门名称
FROM 员工表 e INNER JOIN 部门表 d
USING (部门编号);虽然USING是一种简化写法,但它只能在特定情况下使用。为了避免混淆,建议始终使用ON子句。
ANSI连接语法
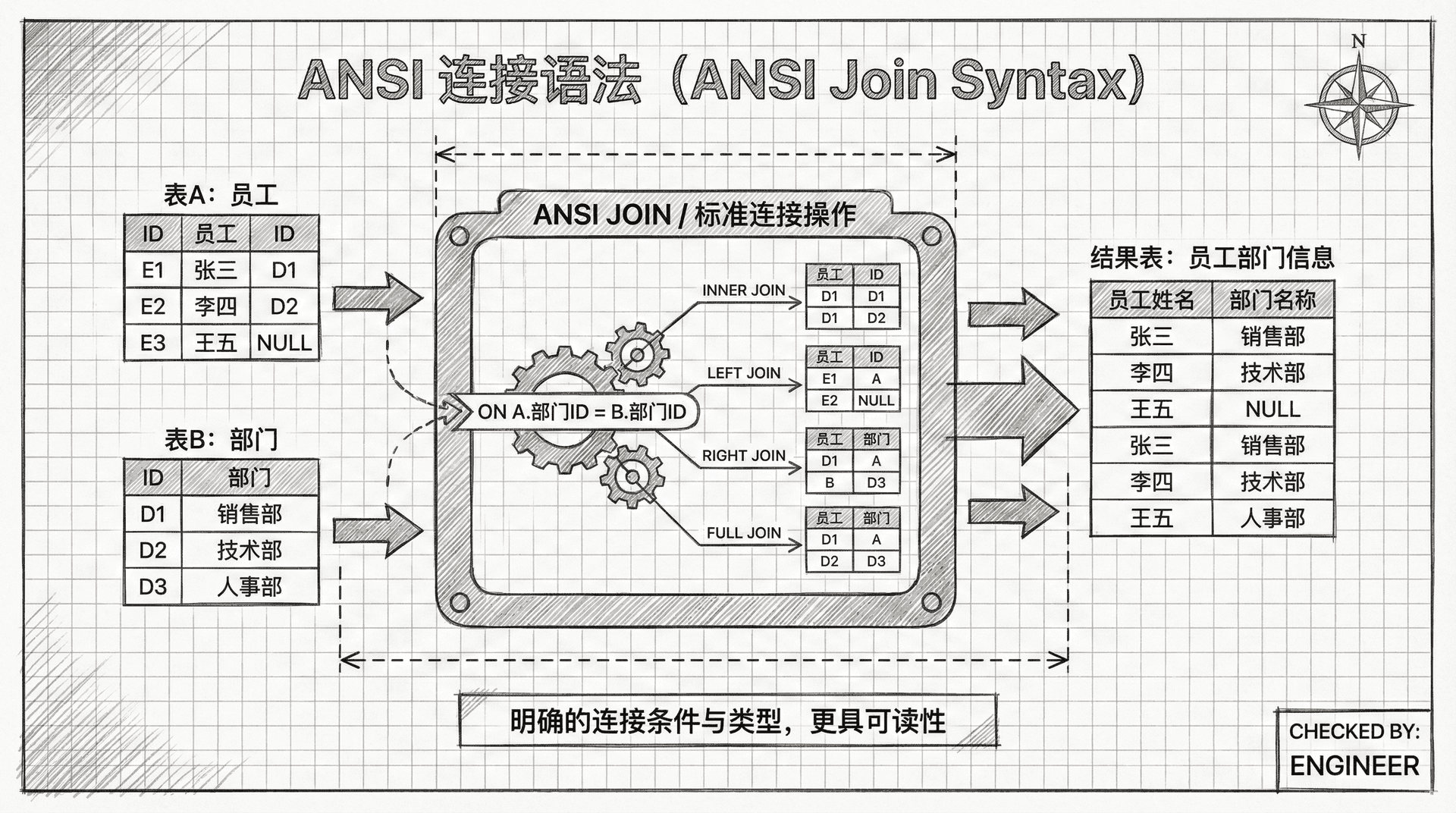
我们的课程中使用的连接表的语法是在SQL92版本的ANSI SQL标准中引入的。所有主要的数据库系统(Oracle、Microsoft SQL Server、MySQL、IBM DB2、PostgreSQL等)都采用了SQL92连接语法。
因为大多数数据库服务器在SQL92规范发布之前就已经存在,它们也支持较旧的连接语法。例如,所有这些服务器都能理解以下查询的变体:
sql
SELECT e.姓名, d.部门名称
FROM 员工表 e, 部门表 d
WHERE e.部门编号 = d.部门编号;这种较旧的方法不包含ON子句,而是在FROM子句中用逗号分隔表名,将连接条件包含在WHERE子句中。
ANSI连接语法具有以下优势:
- 分离关注点: 连接条件和过滤条件分别放在不同的子句中(ON子句和WHERE子句),使查询更容易理解。
- 避免遗漏: 每对表的连接条件都包含在各自的ON子句中,不太可能意外遗漏部分连接条件。
- 可移植性: 使用SQL92连接语法的查询在不同数据库服务器之间具有更好的可移植性。
让我们通过一个复杂查询来展示ANSI连接语法的优势。假设我们要查找所有由经验丰富的员工(2020年之前入职)开设的账户:
使用旧语法:
sql
SELECT a.账户编号, a.客户编号, a.开户日期
FROM 账户表 a, 分支机构表 b, 员工表 e
WHERE a.开户员工编号 = e.员工编号
AND e.入职日期 < '2020-01-01'
AND e.分支机构编号 = b.分支机构编号
AND e.职位 = '客户经理'
AND b使用ANSI语法:
sql
SELECT a.账户编号, a.客户编号, a.开户日期
FROM 账户表 a INNER JOIN 员工表 e
ON a.开户员工编号 = e.员工编号
INNER JOIN 分支机构表 b
ON e.分支机构编号 = b.分支机构编号
WHERE e.入职日期 < '2020-01-01'
AND e.职位
使用SQL92连接语法的版本很明显更容易理解也更加的清晰明了,连接条件和过滤条件被清晰地分开了。
连接三个或更多表
连接三个表与连接两个表类似,只是有一个小区别。在两表连接中,FROM子句包含两个表和一个连接类型,以及一个ON子句来定义表的连接方式。在三表连接中,FROM子句包含三个表和两个连接类型,以及两个ON子句。
让我们先看一个两表连接的例子:
sql
SELECT a.账户编号, c.客户名称
FROM 账户表 a INNER JOIN 客户表 c
ON a.客户编号 = c.客户编号
WHERE c.客户类型 = '企业客户';这个查询返回所有企业客户的账户编号和客户名称。如果我们想要在查询中添加员工表来获取开户员工的姓名,查询会变成这样:
sql
SELECT a.账户编号, c.客户名称, e.姓名
FROM 账户表 a INNER JOIN 客户表 c
ON a.客户编号 = c.客户编号
INNER JOIN 员工表 e
ON a.开户员工编号 = e.员工编号
WHERE c.客户类型 = '企业客户';现在FROM子句中列出了三个表、两个连接类型和两个ON子句,查询变得复杂了一些。
连接顺序重要吗?
如果你对为什么所有三个版本的账户/员工/客户查询都产生相同的结果感到困惑,请记住SQL是一种非过程化语言。这意味着你只需描述你想要检索什么以及需要涉及哪些数据库对象,但由数据库服务器决定如何最好地执行你的查询。
使用从数据库对象收集的统计信息,服务器必须从三个表中选择一个作为起点(被选择的表称为「驱动表」),然后决定以什么顺序连接其余的表。因此,表在FROM子句中出现的顺序并不重要。
例如,下面三个查询会产生相同的结果,尽管表的顺序不同:
版本1:
sql
SELECT a.账户编号, c.客户名称, e.姓名
FROM 账户表 a INNER JOIN 客户表 c
ON a.客户编号 = c.客户编号
INNER JOIN 员工表 e
ON a.开户员工编号 = e.员工编号
WHERE c.客户类型 = '企业客户';版本2:
sql
SELECT a.账户编号, c.客户名称, e.姓名
FROM 客户表 c INNER JOIN 账户表 a
ON a.客户编号 = c.客户编号
INNER JOIN 员工表 e
ON a.开户员工编号 = e.员工编号
WHERE c.客户类型 = '企业客户';版本3:
sql
SELECT a.账户编号, c.客户名称, e.姓名
FROM 员工表 e INNER JOIN 账户表 a
ON e.员工编号 = a.开户员工编号
INNER JOIN 客户表 c
ON a.客户编号 = c.客户编号
WHERE c.客户类型 = '企业客户';在大多数情况下,你应该让数据库优化器决定最佳的连接顺序。现代数据库系统的查询优化器非常智能,能够分析表的大小、索引情况等因素来选择最优的执行计划。
如果你确实认为查询中的表应该始终按特定顺序连接,你可以使用数据库特定的提示。例如,在MySQL中可以使用STRAIGHT_JOIN关键字,在SQL Server中可以使用FORCE ORDER选项,在Oracle中可以使用ORDERED或LEADING优化器提示。
思考包含三个或更多表的查询的一种方式是将其想象成一个滚雪球的过程。前两个表开始了这个过程,每个后续表都被添加到雪球中。你可以将雪球想象为中间结果集,它随着后续表的连接而获得越来越多的列。
因此,员工表实际上不是直接连接到账户表,而是连接到客户表和账户表连接后创建的中间结果集。这种理解方式有助于处理复杂的多表查询。
使用子查询作为表
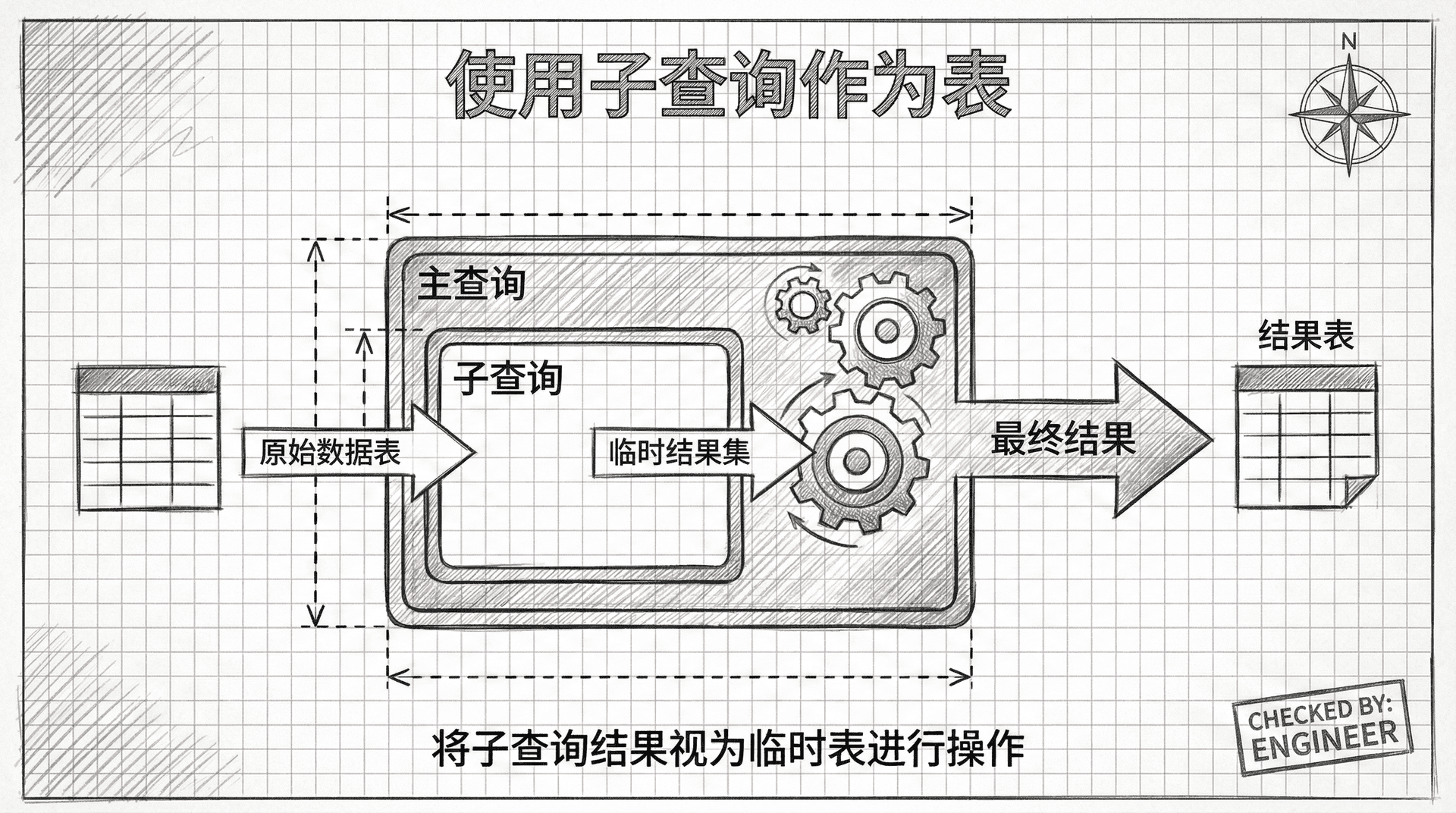
我们已经看过几个使用三个表的查询示例,但还有一个值得提及的变化:当某些数据集是由子查询生成的时候该怎么办。下面是一个使用子查询的例子,它查找所有由经验丰富的员工(2020年之前入职)在「北京分行」开设的账户:
sql
SELECT a.账户编号, a.客户编号, a.开户日期, a.产品类型
FROM 账户表 a INNER JOIN
(SELECT 员工编号, 分支机构编号
FROM 员工表
WHERE 入职日期 < '2020-01-01'
AND (职位 = '客户经理' OR 职位 = '高级客户经理')) e
ON a.开户员工编号 = e
第一个子查询(别名为e)查找所有经验丰富的客户经理。第二个子查询(别名为b)查找北京分行的ID。首先,账户表与经验丰富的客户经理子查询通过员工编号连接,然后结果表与北京分行子查询通过分支机构编号连接。
子查询可以作为表来使用,这为复杂查询提供了更大的灵活性。通过在子查询中预先过滤数据,可以提高查询的性能和可读性。
在这个查询中你可能注意到主查询没有WHERE子句,这是因为所有的过滤条件都在子查询内部,所以主查询不需要额外的过滤条件。
使用同一个表两次
如果你要连接多个表,可能会发现需要多次连接同一个表。在我们的数据库中,例如分支机构表既被账户表引用(账户开设的分支机构),也被员工表引用(员工工作的分支机构)。如果你想在结果集中包含这两个分支机构信息,可以在FROM子句中两次包含分支机构表,分别与员工表和账户表连接一次。
为了实现这一点,你需要为分支机构表的每个实例提供不同的别名,以便服务器知道你在各种子句中引用的是哪一个。例如:
sql
SELECT a.账户编号, e.员工编号,
b_开户.名称 AS 开户分行, b_员工.名称 AS 员工分行
FROM 账户表 a INNER JOIN 分支机构表 b_开户
ON a.开户分支机构编号 = b_开户.分支机构编号
INNER JOIN 员工表 e
ON a.开户员工编号 = e.员工编号
INNER JOIN 分支机构表 b_员工
这个查询显示了每个储蓄账户是在哪个分行开设的,以及开户员工当前在哪个分行工作。分支机构表被包含了两次,别名分别为b_开户和b_员工。通过为分支机构表的每个实例分配不同的别名,服务器能够理解你引用的是哪个实例:是连接到账户表的,还是连接到员工表的。
自连接
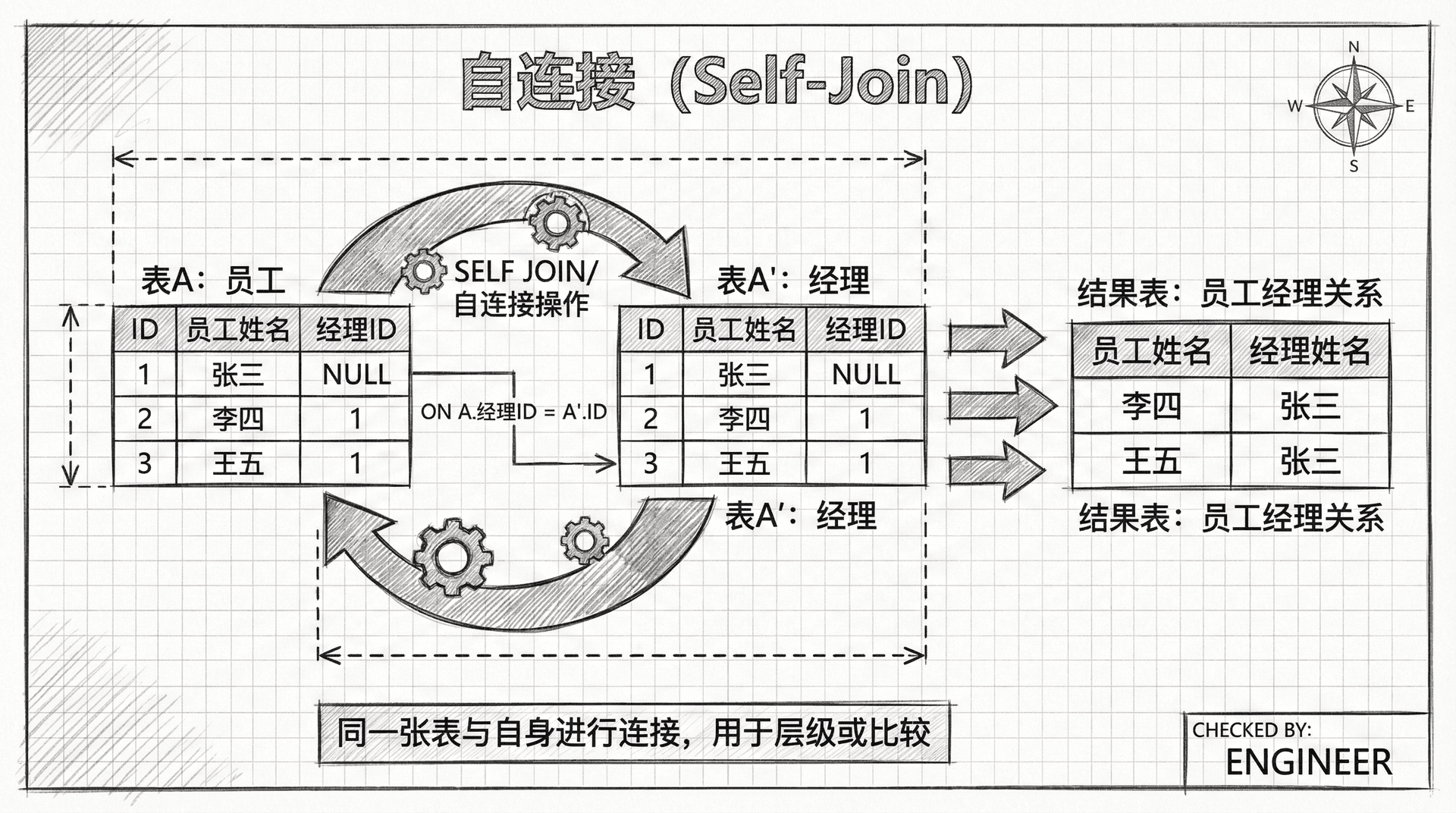
你不仅可以在同一个查询中多次包含同一个表,还可以将表与自身连接。这开始听起来可能很奇怪,但确实有合理的理由这样做。例如,员工表包含一个自引用外键,这意味着它包含一个指向同一表内主键的列(上级员工编号)。这个列指向员工的经理(除非员工是最高领导,在这种情况下该列为null)。
使用自连接,你可以编写一个查询,列出每个员工的姓名以及他或她的经理的姓名:
sql
SELECT e.姓名 AS 员工姓名,
e_经理.姓名 AS 经理姓名
FROM 员工表 e INNER JOIN 员工表 e_经理
ON e.上级员工编号 = e_经理.员工编号;假设我们的员工表数据如下:
查询结果会是:
这个查询包含员工表的两个实例:一个用于提供员工姓名(别名为e),另一个用于提供经理姓名(别名为e_经理)。ON子句使用这些别名通过上级员工编号外键将员工表与自身连接。
注意查询只返回了3行,而不是员工表中的4行。这是因为王总没有上级(他的上级员工编号为null),所以他的连接失败了。如果你想在结果集中包含王总,需要使用外连接。
这是另一个需要使用表别名的查询示例,否则服务器无法知道你引用的是员工还是员工的经理。
等值连接与非等值连接
到目前为止显示的所有多表查询都使用了等值连接,这意味着两个表中的值必须匹配才能成功连接。等值连接总是使用等号,例如:
sql
ON e.分支机构编号 = b.分支机构编号虽然大多数查询都会使用等值连接,但你也可以通过值的范围来连接表,这被称为非等值连接。下面是一个按值范围连接的查询示例:
sql
SELECT e.员工编号, e.姓名, e.入职日期
FROM 员工表 e INNER JOIN 产品表 p
ON e.入职日期 >= p.发布日期
AND e.入职日期 <= p.停售日期
WHERE p.产品名称 = '免费支票账户';这个查询连接两个没有外键关系的表。目的是找到所有在「免费支票账户」产品提供期间开始为银行工作的员工。因此,员工的入职日期必须在产品发布日期和停售日期之间。
你还可能需要自非等值连接,这意味着表使用非等值连接连接到自身。例如,假设运营经理决定为所有银行出纳员举办国际象棋锦标赛。 你被要求创建所有配对的列表。你可以尝试将员工表与自身连接,对于所有出纳员(职位 = '出纳员'),并返回员工编号不匹配的所有行(因为一个人不能和自己下棋):
sql
SELECT e1.姓名 AS 选手1, e2.姓名 AS 选手2
FROM 员工表 e1 INNER JOIN 员工表 e2
ON e1.员工编号 != e2.员工编号
WHERE e1.职位 = '出纳员' AND e2.职位 = '出纳员';假设我们有5个出纳员,这个查询会返回20行结果。但是这里有个问题:对于每个配对(比如张三对李四),还会有一个反向配对(李四对张三)。
一种解决方法是使用连接条件 e1.员工编号 < e2.员工编号,这样每个出纳员只会与员工编号更高的出纳员配对:
sql
SELECT e1.姓名 AS 选手1, e2.姓名 AS 选手2
FROM 员工表 e1 INNER JOIN 员工表 e2
ON e1.员工编号 < e2.员工编号
WHERE e1.职位 = '出纳员' AND e2.职位 = '出纳员';现在我们得到了10个不重复的配对,这正是5个出纳员所需要的配对数量。
连接条件与过滤条件
你现在已经熟悉了连接条件属于ON子句,而过滤条件属于WHERE子句的概念。但是,SQL在条件放置位置方面很灵活,所以在构建查询时需要小心。
例如,以下查询使用单个连接条件连接两个表,并在WHERE子句中包含单个过滤条件:
sql
SELECT a.账户编号, a.产品类型, c.客户名称
FROM 账户表 a INNER JOIN 客户表 c
ON a.客户编号 = c.客户编号
WHERE c.客户类型 = '企业客户';这个查询很直观,但如果你错误地将过滤条件放在ON子句中而不是WHERE子句中会发生什么?
sql
SELECT a.账户编号, a.产品类型, c.客户名称
FROM 账户表 a INNER JOIN 客户表 c
ON a.客户编号 = c.客户编号
AND c.客户类型 = '企业客户';在这种情况下,查询仍然会生成相同的结果。如果将两个条件都放在WHERE子句中,但FROM子句仍使用ANSI连接语法,会怎样?
sql
SELECT a.账户编号, a.产品类型, c.客户名称
FROM 账户表 a INNER JOIN 客户表 c
WHERE a.客户编号 = c.客户编号
AND c.客户类型 = '企业客户';同样,MySQL服务器依然会返回一样的结果。不过,建议你把连接条件和筛选条件分别放在合适的位置,这样写出来的SQL语句更清晰、更容易看懂和维护。
前辈们的最佳实践:将连接条件放在ON子句中,将过滤条件放在WHERE子句中。这样可以使查询的意图更加清晰,也更容易维护和调试。
通过遵循这些约定,你的SQL查询将更具可读性,其他开发者更容易理解你的代码意图。在处理复杂的多表连接时,清晰的结构变得尤为重要。
到这里,我们已经覆盖了多表查询的核心概念。掌握这些技能后,你就能处理大多数实际工作中遇到的复杂查询需求了。记住,实践是掌握这些概念的关键,不要害怕尝试不同的连接组合和查询结构。
小练习
1. 关于数据库连接的概念,以下哪个说法是正确的?
2. 关于笛卡尔积的描述,以下哪个是正确的?
3. 关于内连接的特点,以下哪个说法是正确的?
4. 关于自连接的特点,以下哪个说法是正确的?
5. 关于等值连接与非等值连接的区别,以下哪个说法是正确的?
6. 多表连接查询
假设你有以下三个表:
员工表:
部门表:
项目表:
请编写一个SQL查询,查询所有项目的项目名称、负责人姓名以及负责人所属的部门名称。
7. 自连接应用
假设员工表包含以下字段:员工编号、姓名、上级员工编号。数据如下:
请编写一个SQL查询,列出每个员工的姓名以及他们的直接上级的姓名。对于没有上级的员工(如王总),应该在结果中显示为"无上级"。
8. 复杂查询设计
假设你有一个订单系统,包含以下表:
订单表:
客户表:
员工表:
部门表:
请编写一个SQL查询,查找所有在2024年2月之后下单的企业客户,要求显示:订单编号、客户名称、处理订单的员工姓名、员工所属部门名称。结果按订单日期降序排列。