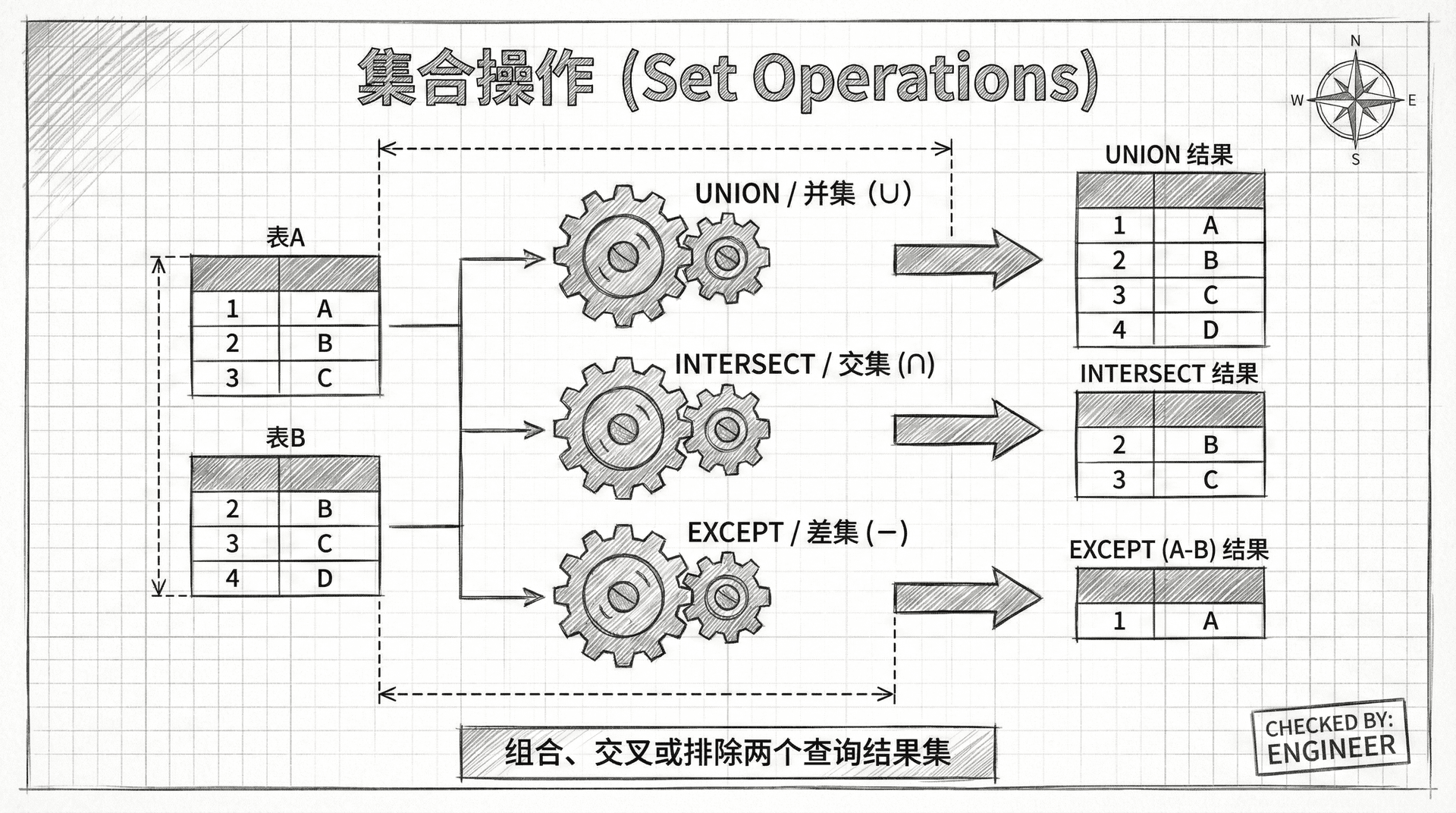
集合操作
在关系型数据库中,我们不仅可以逐行处理数据,更重要的是要掌握如何处理「数据集合」。当我们需要将多个查询结果组合在一起时,SQL 的集合操作符就派上了用场。
假设现在你有两个学生名单:一个是数学课的学生名单,另一个是英语课的学生名单。你可能想要知道:哪些学生同时选了两门课?哪些学生只选了数学课?或者想要一个包含所有学生的完整名单。这些问题都可以通过数据库的集合操作来解决。
集合基础
在深入学习 SQL 集合操作之前,我们需要先理解基本的集合概念。集合论是数学的一个分支,它研究的是对象的「集合」以及这些集合之间的关系。
并集操作
并集是最基本的集合操作之一。当我们说「集合 A 和集合 B 的并集」时,我们指的是包含 A 和 B 中所有元素的新集合,重复的元素只出现一次。
比如说,如果集合 A 包含「张三、李四、王五」,集合 B 包含「李四、赵六、钱七」,那么 A 和 B 的并集就是「张三、李四、王五、赵六、钱七」。注意李四虽然在两个集合中都出现,但在并集中只出现一次。
交集操作
交集操作关注的是两个集合的「共同部分」。交集包含同时存在于集合 A 和集合 B 中的所有元素。
继续用刚才的例子,集合 A「张三、李四、王五」和集合 B「李四、赵六、钱七」的交集就是「李四」,因为只有李四同时出现在两个集合中。
如果两个集合没有任何共同元素,那么它们的交集就是空集。就像两个完全不相关的班级,可能没有任何学生同时在两个班级中。
差集操作
差集操作告诉我们「集合 A 中有,但集合 B 中没有」的元素。用数学符号表示就是 A - B 或 A except B。
还是刚才的例子,集合 A「张三、李四、王五」减去集合 B「李四、赵六、钱七」的结果是「张三、王五」,因为这两个学生只在集合 A 中出现,在集合 B 中不存在。
组合操作的优势
这三种基本操作可以组合使用来解决更复杂的问题。比如,如果你想找到「只选了一门课的学生」(排除同时选两门课的学生),你可以这样思考: 先找到所有学生的并集,然后减去同时选两门课的学生(交集)。用集合操作表示就是:
(数学课学生 ∪ 英语课学生) - (数学课学生 ∩ 英语课学生)
或者你也可以分别找到「只选数学课的学生」和「只选英语课的学生」,然后将这两个结果合并:
(数学课学生 - 英语课学生) ∪ (英语课学生 - 数学课学生)
这就是集合操作的方便之处,同一个问题往往可以用多种方式来解决。
SQL 中的集合操作
理解了集合基础的概念后,我们需要学习如何在 SQL 中实际应用这些概念。在数据库中处理集合操作时,有一些重要的规则需要遵守。
数据兼容性要求
当我们想要将两个查询结果合并时,不能随意将任意两个表进行集合操作。假设现在你试图将「学生信息表」和「商品信息表」进行合并,会发生什么?
比如学生表的结构是这样的:
而商品表的结构是这样的:
如果我们强行将这两个表进行并集操作,数据库需要将第一列(student_id 和 product_id)放在一起,第二列(学生姓名和商品名称)放在一起,以此类推。虽然前面几列看起来还说得过去,但是第五列会出现问题:学生表只有 4 列,而商品表有 5 列。更重要的是,将年龄和价格混在一起,将专业和分类混在一起,这样的数据毫无意义。
SQL 集合操作有两个铁律:参与操作的所有查询必须返回相同数量的列,并且对应位置的列必须具有兼容的数据类型。违反这些规则,数据库会直接拒绝执行你的查询。
兼容数据类型的示例
让我们看一个正确的例子。假设我们有两个相关的表:
在校学生表 (current_students)
sql
SELECT student_id, name, 'current' as status
FROM current_students
WHERE graduation_year = 2024;毕业学生表 (graduated_students)
sql
SELECT student_id, name, 'graduated' as status
FROM graduated_students
WHERE graduation_year = 2023;这两个查询都返回三列:学生编号(整数)、姓名(字符串)、状态(字符串)。数据类型完全匹配,我们可以安全地对它们进行集合操作。
复合查询的基本语法
在 SQL 中,我们通过在两个 SELECT 语句之间放置集合操作符来创建复合查询:
sql
SELECT 列1, 列2, 列3
FROM 表1
WHERE 条件1
[集合操作符]
SELECT 列1, 列2, 列3
FROM 表2
WHERE 条件2;让我们用一个简单的例子来演示:
sql
SELECT 1 as number, 'hello' as greeting
UNION
SELECT 2 as number, 'world' as greeting;这个查询会返回:
虽然这两个子查询分别只返回一行,但通过 UNION 操作符,我们得到了一个包含两行数据的结果集。
SQL 集合操作符
现在我们来深入学习一些 SQL 中的各种集合操作符。每种操作符都有其特定的用途和行为特点。
UNION 操作符
UNION 操作符是最常用的集合操作符,它实现了我们之前讲到的「并集」概念。不过 SQL 提供了两种版本的并集操作:UNION 和 UNION ALL。
UNION vs UNION ALL
两者的主要区别在于对重复数据的处理方式:
- UNION:会自动去除重复行,并对结果进行排序
- UNION ALL:保留所有行,包括重复的行,不进行排序
让我们通过一个实际的例子来理解这个差异。假设现在我们正在管理一个在线学习平台,有两个表分别记录不同课程的学生:
数学课学生表 (math_students)
sql
-- 假设表中有这些数据
-- student_id | name | course
-- 1001 | 张三 | 高等数学
-- 1002 | 李四 | 高等数学
-- 1003 | 王五 | 高等数学
-- 1001 | 张三 | 线性代数英语课学生表 (english_students)
sql
-- 假设表中有这些数据
-- student_id | name | course
-- 1002 | 李四 | 英语听力
-- 1004 | 赵六 | 英语口语
-- 1005 | 钱七 | 英语写作
-- 1002 | 李四 | 英语阅读现在我们想要获取所有学生的名单。
使用 UNION ALL
sql
SELECT student_id, name
FROM math_students
UNION ALL
SELECT student_id, name
FROM english_students;结果会是:
注意,张三出现了 2 次,李四出现了 3 次,因为 UNION ALL 保留了所有的行。
使用 UNION
sql
SELECT student_id, name
FROM math_students
UNION
SELECT student_id, name
FROM english_students;结果会是:
这次每个学生都只出现一次,重复的行被自动去除了。
从性能角度来说,UNION ALL 通常比 UNION 更快,因为数据库不需要检查和去除重复项。如果你确定数据中没有重复,或者你需要保留重复数据,就放心使用 UNION ALL。
实际应用场景
让我们看一个更贴近现实的例子。假设你在一家电商公司工作,需要生成一份客户报告,包含个人客户和企业客户的信息:
sql
-- 个人客户信息
SELECT
'individual' as customer_type,
customer_id,
CONCAT(first_name, ' ', last_name) as full_name,
city
FROM individual_customers
WHERE status = 'active'
UNION ALL
-- 企业客户信息
SELECT
'business' as customer_type,
customer_id,
company_name as full_name,
city
FROM business_customers
WHERE这个查询巧妙地解决了一个常见问题:个人客户有 first_name 和 last_name 两个字段,而企业客户只有一个 company_name 字段。我们通过 CONCAT 函数将个人客户的姓名合并,并添加了一个额外的列来标识客户类型。
常见的陷阱
新手在使用 UNION 时经常遇到以下问题:
1. 列数不匹配
sql
-- 错误示例
SELECT customer_id, first_name, last_name
FROM individual_customers
UNION
SELECT customer_id, company_name -- 只有两列
FROM business_customers;2. 数据类型不兼容
sql
-- 错误示例
SELECT customer_id, registration_date
FROM individual_customers
UNION
SELECT customer_id, annual_revenue -- 日期类型 vs 数值类型
FROM business_customers;3. 期望不正确的排序
sql
-- 错误的期望:认为结果会按某种特定顺序返回
SELECT name FROM table1
UNION ALL
SELECT name FROM table2;
-- UNION ALL 不保证任何特定的顺序INTERSECT 操作符
INTERSECT 操作符实现了我们之前讲到的「交集」概念,它返回同时存在于两个查询结果中的行。遗憾的是,MySQL 目前还不支持 INTERSECT 操作符,但我们可以通过其他方式来实现相同的功能。
需要注意的是,MySQL 8.0 及之前的版本都不支持 INTERSECT 和 EXCEPT 操作符。如果你使用的是 Oracle、SQL Server 或 PostgreSQL,这些操作符是可以直接使用的。
概念理解
假设我们想要找到「既选了数学课又选了英语课的学生」,这就是一个典型的交集问题。 在支持 INTERSECT 的数据库系统中,我们可以这样写:
sql
-- 这段代码在 MySQL 中无法运行
SELECT student_id, name
FROM math_students
INTERSECT
SELECT student_id, name
FROM english_students;这个查询会返回同时出现在两个表中的学生记录。
在 MySQL 中实现交集
虽然 MySQL 不支持 INTERSECT,但我们可以用 INNER JOIN(我们在上节课中学到的) 或 EXISTS 来实现相同的功能:
方法一:使用 INNER JOIN
sql
SELECT DISTINCT m.student_id, m.name
FROM math_students m
INNER JOIN english_students e
ON m.student_id = e.student_id AND m.name = e.name;方法二:使用 EXISTS
sql
SELECT DISTINCT student_id, name
FROM math_students m
WHERE EXISTS (
SELECT 1
FROM english_students e
WHERE e.student_id = m.student_id
AND e.name = m.name
);方法三:使用 IN 子查询
sql
SELECT DISTINCT student_id, name
FROM math_students
WHERE (student_id, name) IN (
SELECT student_id, name
FROM english_students
);这三种方法都能够找到同时选了数学课和英语课的学生,效果都等同于 INTERSECT 操作。
EXCEPT 操作符
EXCEPT 操作符实现了「差集」概念,它返回存在于第一个查询中但不存在于第二个查询中的行。同样,MySQL 也不支持这个操作符。
假设我们想要找到「只选了数学课但没有选英语课的学生」,这就是一个差集问题。 在支持 EXCEPT 的数据库系统中,我们可以这样写:
sql
-- 这段代码在 MySQL 中无法运行
SELECT student_id, name
FROM math_students
EXCEPT
SELECT student_id, name
FROM english_students;在 MySQL 中实现差集
我们可以使用 LEFT JOIN 或 NOT EXISTS 来实现差集操作:
方法一:使用 LEFT JOIN
sql
SELECT DISTINCT m.student_id, m.name
FROM math_students m
LEFT JOIN english_students e
ON m.student_id = e.student_id AND m.name = e.name
WHERE e.student_id IS NULL;方法二:使用 NOT EXISTS
sql
SELECT DISTINCT student_id, name
FROM math_students m
WHERE NOT EXISTS (
SELECT 1
FROM english_students e
WHERE e.student_id = m.student_id
AND e.name = m.name
);方法三:使用 NOT IN 子查询
sql
SELECT DISTINCT student_id, name
FROM math_students
WHERE (student_id, name) NOT IN (
SELECT student_id, name
FROM english_students
WHERE student_id IS NOT NULL
AND name IS NOT NULL
);使用 NOT IN 时要特别小心 NULL 值。如果子查询中包含 NULL 值,NOT IN 可能会返回意外的结果。因此建议加上 NULL 值的过滤条件。
理解 EXCEPT ALL
在支持的数据库系统中,还有一个 EXCEPT ALL 操作符,它在处理重复值时有特殊的行为。 假设我们有这样的数据:
集合 A
集合 B
使用 EXCEPT,结果是:
使用 EXCEPT ALL,结果是:
EXCEPT 会完全移除在集合 B 中出现的所有值,而 EXCEPT ALL 只会为集合 B 中的每个值移除集合 A 中的一个对应值。让我们看一个实际的业务场景。假设你在一家在线商城工作,需要找到「浏览了商品但没有购买的用户」:
sql
-- 浏览过商品的用户
SELECT user_id, product_id
FROM product_views
WHERE view_date >= '2024-01-01'
-- 减去购买了商品的用户(使用 LEFT JOIN 实现)
SELECT DISTINCT v.user_id, v.product_id
FROM product_views v
LEFT JOIN orders o ON v.user_id = o.user_id AND v.product_id = o.product_id
WHERE v.
这个查询帮助我们识别出有购买意向但最终没有下单的用户,这些用户可能是推广活动的好目标。
集合操作的高级规则
掌握了基本的集合操作符后,我们还需要了解一些重要的规则和技巧,这些知识会让你在实际工作中更加得心应手。
结果排序规则
当你执行复合查询时,可能需要对最终结果进行排序。这时需要遵循一个重要原则:ORDER BY 子句只能放在整个复合查询的最后,并且只能引用第一个查询中的列名。 让我们看一个例子:
sql
-- 正确的排序方式
SELECT student_id, name, '数学' as subject
FROM math_students
WHERE grade >= 80
UNION ALL
SELECT student_id, name, '英语' as subject
FROM english_students
WHERE grade >= 80
ORDER BY student_id, name;这个查询会将所有成绩优秀的学生合并在一起,然后按学生编号和姓名排序。
注意,ORDER BY 子句中的列名必须与第一个 SELECT 语句中的列名完全一致。如果你在第二个查询中使用了不同的列名,ORDER BY 中则不能引用第二个查询的列名。
看看这个错误的例子:
sql
-- 错误示例
SELECT student_id, name
FROM math_students
UNION
SELECT stu_id, stu_name -- 不同的列名
FROM english_students
ORDER BY stu_id; -- 错误:无法识别 stu_id为了避免这种问题,建议为复合查询中的所有列使用相同的别名:
sql
-- 推荐的做法
SELECT student_id as id, name
FROM math_students
UNION
SELECT stu_id as id, stu_name as name
FROM english_students
ORDER BY id;操作符优先级
当复合查询包含三个或更多的子查询时,不同集合操作符的执行顺序就变得重要了。虽然 MySQL 不支持 INTERSECT,但了解优先级规则对使用其他数据库系统很有帮助。
根据 SQL 标准,操作符的优先级如下:
- INTERSECT(最高优先级)
- UNION 和 EXCEPT(相同优先级,从左到右执行)
让我们通过一个例子来理解这个概念。假设我们有三个学生组:
sql
-- 如果MySQL支持所有操作符,这个查询的执行顺序是怎样的?
SELECT student_id FROM group_a
UNION
SELECT student_id FROM group_b
INTERSECT
SELECT student_id FROM group_c;由于 INTERSECT 有更高的优先级,这个查询实际上等同于:
sql
SELECT student_id FROM group_a
UNION
(SELECT student_id FROM group_b
INTERSECT
SELECT student_id FROM group_c);也就是说,会先计算 group_b 和 group_c 的交集,然后再与 group_a 进行并集操作。
使用括号控制执行顺序
在支持括号的数据库系统中,你可以使用括号来明确指定操作的执行顺序:
sql
-- 在支持括号的数据库中
(SELECT student_id FROM group_a
UNION
SELECT student_id FROM group_b)
INTERSECT
SELECT student_id FROM group_c;这样就会先执行 group_a 和 group_b 的并集,然后再与 group_c 进行交集操作。
虽然 MySQL 目前不支持在复合查询中使用括号,但在设计查询时考虑执行顺序仍然很重要。如果你需要特定的执行顺序,可以考虑使用子查询或临时表。
性能优化提示
在实际项目中,集合操作可能涉及大量数据,以下是一些性能优化的建议:
1. 选择合适的操作符
sql
-- 如果确定没有重复数据,使用 UNION ALL
SELECT customer_id FROM region_north
UNION ALL -- 比 UNION 更快
SELECT customer_id FROM region_south;
-- 如果需要去重,才使用 UNION
SELECT customer_id FROM all_orders_2023
UNION -- 需要去重时使用
SELECT customer_id FROM all_orders_2024;2. 在子查询中添加适当的过滤条件
sql
-- 好的做法:在合并前就过滤数据
SELECT customer_id, order_amount
FROM orders_2023
WHERE order_amount > 1000 -- 提前过滤
UNION ALL
SELECT customer_id, order_amount
FROM orders_2024
WHERE order_amount > 1000 -- 提前过滤
ORDER BY order_amount DESC;3. 确保相关列上有索引
sql
-- 确保参与集合操作的列上有适当的索引
-- 特别是用于连接和过滤的列
CREATE INDEX idx_customer_id ON orders_2023(customer_id);
CREATE INDEX idx_customer_id ON orders_2024(customer_id);处理 NULL 值
在集合操作中,NULL 值的处理需要特别注意:
sql
-- NULL 值在集合操作中被视为相等
SELECT 'A' as col1, NULL as col2
UNION
SELECT 'A' as col1, NULL as col2;
-- 结果只会返回一行,因为两行完全相同(包括 NULL)
-- 但在比较操作中要小心
SELECT customer_id
FROM customers
WHERE city NOT IN (
SELECT city FROM stores
WHERE city IS NOT NULL -- 重要:过滤 NULL 值
);实战练习
通过以下练习,你可以巩固对集合操作的理解。这些练习都基于一个虚构的在线教育平台的数据。 假设你在一家名为「智学在线」的教育平台工作,平台有以下几个表:
学生表 (students)
课程注册表 (course_enrollments)
讨论区活跃用户表 (forum_active_users)
练习 1:基础并集操作
编写一个查询,找出所有「注册了Python编程课程」或「在讨论区发过帖」的学生ID。要求保留重复值。
练习 2:去重并集操作
修改练习1的查询,这次要去除重复的学生ID,并按学生ID升序排列。
练习 3:模拟交集操作
找出既「注册了课程」又「在讨论区活跃」的学生ID。(提示:使用INNER JOIN实现)
练习 4:模拟差集操作
找出「注册了课程但从未在讨论区发过帖」的学生ID。
练习 5:复杂业务场景
生成一份「学生活跃度报告」,包含以下信息:
- 学生ID
- 学生姓名
- 活跃类型(「课程学习」或「社区互动」)
- 活跃度得分(课程学习用平均成绩,社区互动用发帖数量)
思考题
-
集合概念理解:如果集合A = {1001, 1002, 1003, 1001},集合B = {1002, 1004, 1005},那么:
- A ∪ B(并集)的结果是什么?
- A ∩ B(交集)的结果是什么?
- A - B(差集)的结果是什么?
-
SQL操作选择:在什么情况下你会选择使用 UNION ALL 而不是 UNION?请列举至少三个场景。
-
性能思考:如果你需要合并两个各有100万行数据的表,并且你知道这两个表的数据完全不重复,你会选择哪个操作符?为什么?
通过这些练习,你应该已经掌握了 SQL 集合操作的核心概念和实际应用。集合操作是处理复杂数据查询的强大工具,在数据分析、报表生成和业务逻辑实现中都有着广泛的应用。