认证机制攻击
认证是Web应用的第一道防线,也是最容易被攻击的地方,认证相关的漏洞占了所有漏洞的很大比例。这一节课,我们从实战的角度,理解认证机制的常见缺陷,以及如何发现和利用这些缺陷。
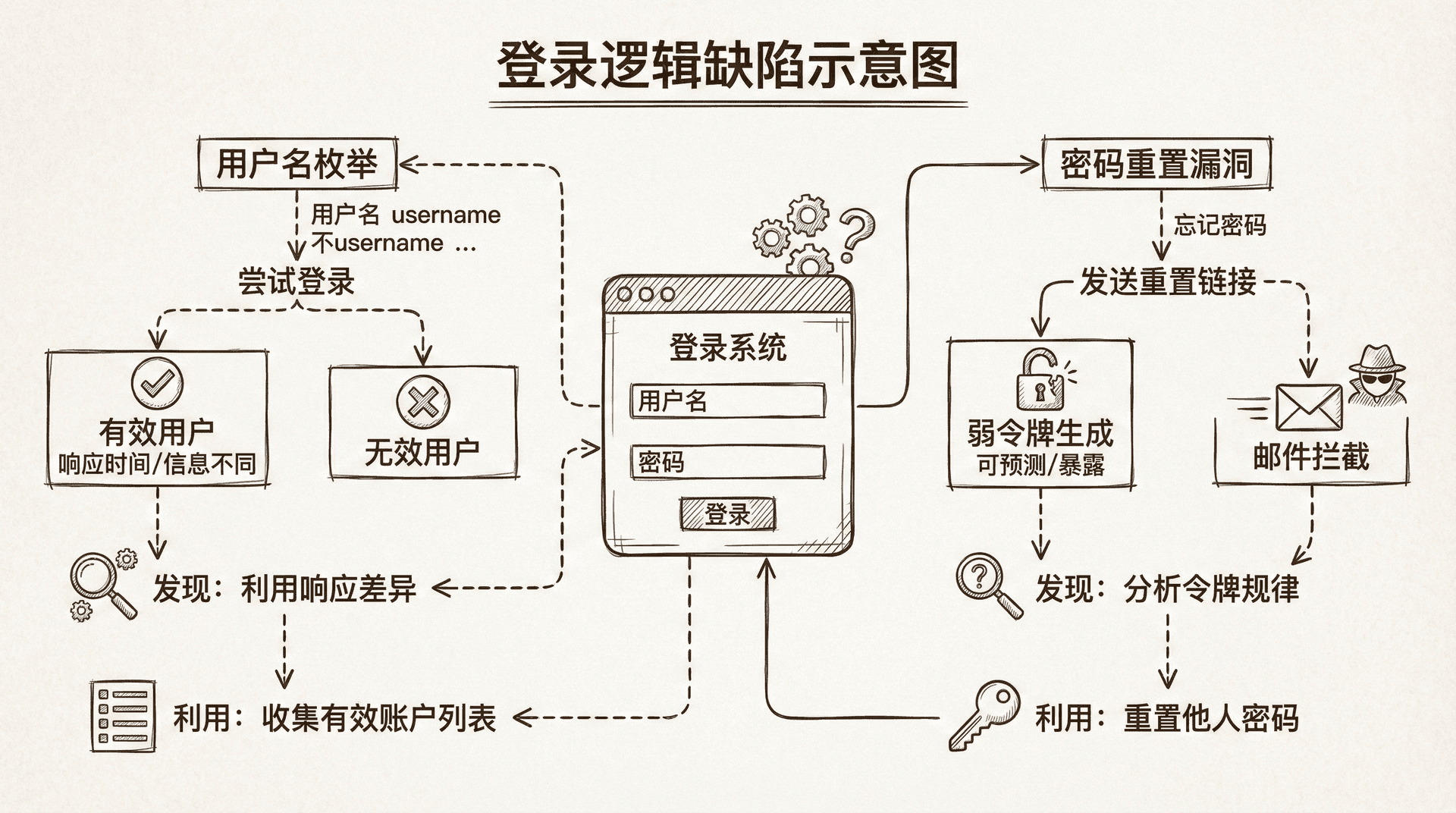
登录逻辑缺陷实战
用户名枚举
用户名枚举是最常见的认证问题之一。通过登录接口的响应差异,攻击者可以判断用户名是否存在。
攻击原理:
正常的登录接口,如果用户名不存在和密码错误,返回的错误信息可能不同。用户名不存在时返回用户不存在,密码错误时返回密码错误。通过这个差异,攻击者可以枚举出系统中存在的用户名,因为如果返回密码错误,说明用户名存在,只是密码不对。
案例:
假设一个系统的登录接口,响应如下:
http
POST /login HTTP/1.1
Content-Type: application/json
{"username":"admin","password":"wrong"}响应(用户名存在,密码错误):
json
{"status":"error","message":"密码错误"}响应(用户名不存在):
json
{"status":"error","message":"用户不存在"}通过这个差异,就可以轻松枚举出所有存在的用户名。
绕过方法:
统一错误信息,无论用户名是否存在,都返回“用户名或密码错误”,这是最根本的修复方法。这样攻击者就无法通过错误信息判断用户名是否存在。
响应时间差异也要注意,即使错误信息统一,响应时间可能不同。用户名存在时,需要查数据库验证密码,响应时间可能更长。如果用户名不存在,可能直接返回,响应时间较短。攻击者可以通过响应时间判断用户名是否存在,所以修复时还要注意响应时间的一致性。
测试方法:
python
import requests
import time
def test_username(username):
url = "https://example.com/login"
data = {"username": username, "password": "wrong_password_12345"}
start = time.time()
response = requests.post(url, json=data)
end = time.time()
response_time = end - start
response_text
密码重置漏洞
密码重置功能是认证系统的重要组成部分,也是漏洞的高发区。
常见漏洞类型:
验证码可绕过,验证码不验证,系统可能没有真正验证验证码。验证码可重复使用,同一个验证码可以用多次。验证码可预测,如果验证码生成算法有问题,可能可以预测。
Token问题,Token可预测,如果Token生成算法有问题,可能可以预测其他用户的Token。Token不验证,系统可能没有验证Token的有效性。Token不过期,Token可能永久有效,即使重置了密码,旧Token还能用。
邮箱/手机号验证绕过,不验证邮箱/手机号是否属于当前用户,攻击者可能可以用别人的邮箱/手机号重置密码,可以重置任意用户的密码。
案例1:验证码可重复使用
假设一个系统的密码重置流程是这样的:输入用户名/邮箱,发送验证码到邮箱,输入验证码和新密码。
如果系统在验证码发送后,可以多次使用,即使已经重置过密码,验证码仍然有效,就存在问题。
这意味着如果攻击者获取了验证码(比如通过邮箱泄露、中间人攻击等),可以多次重置密码。
案例2:Token可预测
假设另一个系统,密码重置使用Token:用户请求重置密码,系统生成Token,发送重置链接:/reset?token=abc123,用户点击链接,输入新密码。
如果Token是基于时间戳生成的:md5(username + timestamp),时间戳可以预测(比如当前时间),攻击者就可以预测其他用户的Token,重置他们的密码。
测试方法:
python
import requests
import hashlib
import time
def generate_token(username, timestamp):
"""模拟Token生成逻辑"""
return hashlib.md5(f"{username}{timestamp}".encode()).hexdigest()
def test_reset_token(username):
"""测试Token可预测性"""
# 获取当前时间戳(假设是重置请求的时间)
current_timestamp = int(time.time())
# 尝试预测Token
for offset in range(
验证码绕过
验证码是用来防止自动化攻击的,但如果实现不当,可以被绕过。
常见绕过方法:
验证码不验证,前端验证,后端不验证,直接删除验证码参数就能绕过。
验证码可重复使用,验证后不删除,可以多次使用同一个验证码。
验证码可预测,基于时间生成,或者基于简单算法生成,如果算法有问题,可能可以预测。
验证码识别,可以用OCR识别、机器学习识别,或者人工打码平台。
案例:
假设一个登录功能,前端有验证码,但后端不验证。如果直接删除验证码参数,仍然可以正常登录,说明验证码防护无效。
测试请求:
http
POST /login HTTP/1.1
Content-Type: application/json
{"username":"admin","password":"123456","captcha":"1234"}删除captcha参数:
http
POST /login HTTP/1.1
Content-Type: application/json
{"username":"admin","password":"123456"}仍然可以登录成功。
登录次数限制绕过
很多系统会限制登录尝试次数,防止暴力破解。但如果实现不当,可以被绕过。
常见绕过方法:
IP限制可绕过,使用代理IP、使用Tor网络、使用云服务(每个IP尝试几次),都能绕过IP限制。
账户限制可重置,成功登录后重置计数,或者通过其他方式(如注册)重置计数。
限制不严格,只限制密码错误次数,不限制用户名枚举,限制时间窗口太大。
案例:
比如在测试一个系统时,发现登录失败5次后,账户被锁定30分钟。但可以通过注册新账户来“重置”限制(系统不检查IP),或者使用代理IP,每个IP尝试5次。
密码爆破技巧与绕过
字典选择
密码爆破的关键是字典。好的字典能大大提高成功率。
字典来源:
常见密码字典,包括rockyou.txt最常用的密码字典,top10000.txt最常见的10000个密码,common-passwords.txt常见密码。
针对性字典,基于目标信息生成(公司名、员工名等),基于泄露的密码库(如Have I Been Pwned)。
规则生成,基于常见规则生成(如:公司名+年份),使用工具如hashcat的规则模式。
测试方法:
假设在测试时,先收集目标信息(公司名、员工名、业务相关词汇),基于这些信息生成针对性字典,结合常见密码字典,使用规则生成更多变体。这种针对性字典比通用字典成功率更高。
速率限制绕过
很多系统会限制请求速率,防止暴力破解。需要想办法绕过。
常见绕过方法:
分布式爆破,使用多个IP同时爆破,或者使用云服务(每个实例一个IP)。
降低请求频率,延长请求间隔,模拟人类行为(随机延迟)。
利用时间窗口,如果限制是“每分钟X次”,可以每分钟尝试X次,跨多个时间窗口。
绕过限制逻辑,如果限制基于IP,使用代理,如果限制基于账户,枚举多个账户。
案例:
假设一个系统限制每个IP每分钟最多10次登录尝试。如果使用10个代理IP,每个IP每分钟尝试10次,总共每分钟可以尝试100次,成功绕过了速率限制。
验证码识别
如果系统有验证码,需要识别或绕过。
常见识别方法:
OCR工具,包括Tesseract OCR、商业OCR API。
机器学习,训练模型识别验证码,使用现成的验证码识别服务。
人工打码,使用打码平台(如超级鹰、图鉴)。
绕过验证码,如果验证码实现有问题,直接绕过。
案例:
假设遇到一个简单的数字验证码,使用Tesseract OCR识别,准确率约80%。结合重试机制(识别失败重试),成功率提高到95%以上。对于简单的验证码,OCR识别是有效的绕过方法。
分布式爆破
对于有严格限制的系统,可以使用分布式爆破。
常见实现方法:
多机器协作,在多台机器上运行爆破工具,共享字典和进度。
云服务,使用云服务器,每个实例一个IP,可以自动扩展。
工具支持,Hydra支持分布式,Burp Suite的Collaborator可以协作。
案例:
假设在测试一个高价值目标时,准备100个代理IP,使用Hydra分布式模式,每个IP负责字典的一部分,可以在几小时内完成爆破(如果单IP需要几天)。分布式爆破可以大大提高效率。
多因素认证绕过
什么是多因素认证?
多因素认证(MFA/2FA)是在密码之外,增加额外的验证因素,比如短信验证码、邮箱验证码、硬件Token、生物识别等。
常见绕过方法
1. 验证码可绕过
和密码重置类似,如果验证码实现不当,可以绕过。验证码不验证、验证码可重复使用、验证码可预测,这些都是常见问题。
实战案例:
假设一个系统,登录需要密码+短信验证码,但验证码验证逻辑有bug:只要验证码格式正确(6位数字),就通过验证。攻击者可以暴力破解验证码(只有100万种可能,可以快速尝试),成功绕过MFA。
2. 时间窗口攻击
很多MFA系统使用时间窗口(如Google Authenticator的30秒窗口),如果时间同步有问题,可能可以重用验证码,或者验证码有效期太长。
案例:
假设一个系统使用TOTP(基于时间的OTP),但服务器时间不同步,导致时间窗口重叠,可以重用之前的验证码。这种时间同步问题可能导致MFA被绕过。
3. 逻辑缺陷
MFA的逻辑实现可能有缺陷,可以先登录,再验证MFA(如果MFA验证失败,会话不失效),或者MFA验证失败后,可以重试(没有限制)。
案例:
假设一个系统,输入用户名密码,先登录成功(创建会话),然后要求输入MFA验证码。如果MFA验证失败,会话仍然有效,攻击者可以通过其他方式(如会话固定)绕过MFA。
4. 社会工程学
如果MFA依赖用户操作(如点击确认),可能被社会工程学攻击,诱导用户点击确认,或者通过其他渠道获取验证码。
认证流程漏洞案例
案例1:会话在认证前创建
漏洞描述:
系统在用户输入用户名密码之前,就创建了会话。这意味着攻击者可以先获取会话ID,然后诱导用户登录,登录后会话ID不变(会话固定攻击)。
测试步骤:
访问登录页面,获取Session ID:sessionid=abc123,保存这个Session ID,正常登录(或诱导用户登录),登录后Session ID仍然是abc123,使用这个Session ID可以访问用户账号。
修复建议:
登录成功后,重新生成Session ID,或者登录前不创建会话。
案例2:认证状态可绕过
漏洞描述:
系统通过前端JavaScript检查认证状态,但后端不验证,前端检查localStorage中的token,有就显示已登录,后端不验证token,直接返回数据。
测试步骤:
未登录状态下,打开浏览器控制台,设置localStorage:localStorage.setItem('token', 'fake_token'),刷新页面,前端认为已登录。访问需要认证的接口,后端不验证token,返回数据。
修复建议:
后端必须验证每个请求的认证状态,不能依赖前端验证。
案例3:记住我功能漏洞
漏洞描述:
比如“记住我”功能生成的Token不安全,Token可预测、Token不过期、Token强度弱(容易被破解)。
测试步骤:
比如登录时勾选“记住我”,获取生成的Token(可能在Cookie中),分析Token的生成规律。如果可以预测,可以伪造其他用户的Token。
修复建议:
比如使用强随机数生成Token,设置合理的过期时间,使用加密签名(如JWT)。
总结
本节我们一起揭开了认证机制中的各种常见漏洞:比如用户名枚举、密码重置和验证码的绕过,登录次数限制的突破等登录逻辑缺陷;还有密码爆破相关的手段,包括字典攻击、速率限制、验证码识别和分布式爆破。对于多因素认证,也介绍了验证码绕过、窗口攻击、逻辑漏洞和社会工程学等方式。此外,认证流程的设计也容易出问题,比如会话管理不当、认证状态后端未校验、“记住我”功能不安全等。
最重要的是,请你一定要牢牢记住:认证就是Web应用安全的第一道门槛,也是攻击者最常试图突破的目标。 在实际测试时,认证相关的每一个细节都值得你多花些心思仔细检查。
接下来,我们会继续学习会话管理方面的安全问题。其实认证和会话管理是紧密联系、相辅相成的。只有先理解了认证的原理和陷阱,才能更深入把握会话管理背后的安全要点。
重要提醒:密码爆破等攻击技术仅用于授权的安全测试。未经授权的攻击是违法行为。在实际测试中,要遵守测试授权书的规定,不能对未授权的系统进行测试。