解密语音感知的心理学
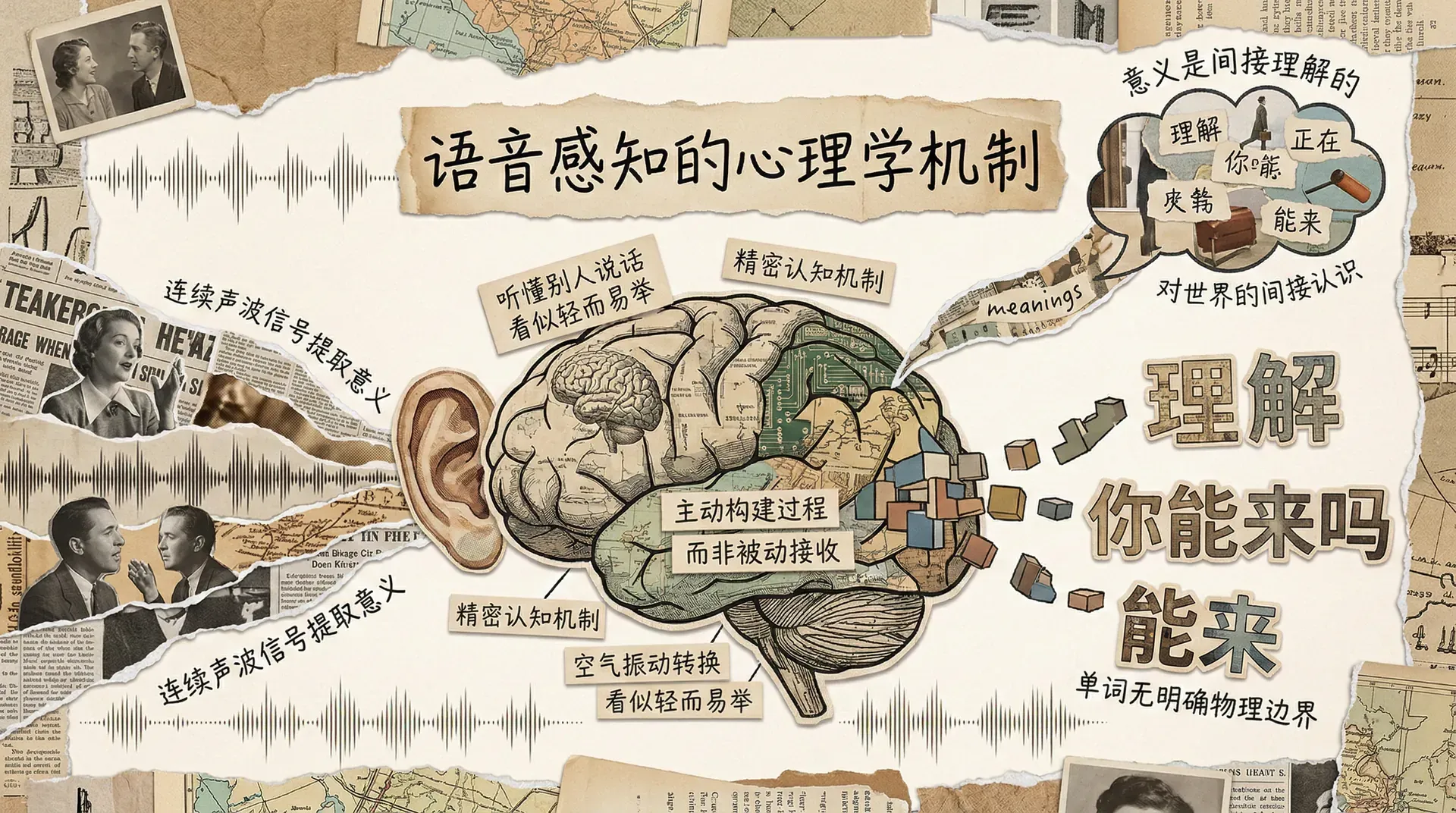
在日常生活中,听懂别人说话似乎轻而易举。当朋友对你说“你能来吗”这句话时,空气分子的振动传到耳朵,经过一系列转换,最终在大脑中变成有意义的信息。然而,这个看似平凡的过程,背后却蕴含着极为精密的认知机制。
语音感知研究的是人类如何从连续变化的声波信号中提取语言意义。与视觉认知一样,听觉认知也是一个主动构建的过程,而非被动接收。所有对世界的认识都是间接的,听觉也不例外。那些我们以为听到的“单词”,在声波信号中并没有明确的物理边界;一句话的意思,也不能直接从说话者的大脑跳跃到听者的大脑中。理解这一点,是进入语音感知心理学的第一步。
声音的物理基础
研究语音感知,必须从声音本身的物理性质出发。声音不是抽象的符号,而是有着精确物理描述的机械波动。只有理解声音“是什么”,才能进一步追问人类是“如何”识别它的。声学基础虽然看似枯燥,但它为整个语音感知研究提供了不可或缺的分析框架。
声波与频谱分析
空气中的声波是压缩与扩张交替出现的连续过程。这种压力变化以纵波形式传播,遇到鼓膜时推动其前后振动,再经由听小骨传导至内耳。描述声音最直接的方式,是绘制压力随时间变化的图形。最简单的声波是正弦波,音叉振动时产生的纯音接近于此。而日常语音远比纯音复杂,其波形是多个正弦波叠加的结果。
复杂声波可以被分解为一组正弦分量,每个分量有各自的频率、振幅和相位,这种分解方式称为“频谱分析”。通过频谱分析,可以知道一个声音由哪些频率成分构成以及各成分的相对强度。这不只是数学推演,物理上的滤波器可以实现同样的功能,它选择性地让特定频率的信号通过,阻断其余频率,就像用不同规格的筛子分离颗粒大小一样。
语音在频谱上的特征,主要取决于发音时声道的形状。声带振动产生的原始声音称为“基频”,经过声道的共鸣和过滤后,特定频率段的能量得到加强,形成“共振峰”。不同的元音对应不同形状的声道,产生不同位置的共振峰,这正是我们区分“a”“i”“u”等元音的声学基础。辅音则主要通过气流在不同部位受阻的方式产生,其声学特征表现为短暂的噪声、爆破音或摩擦音。
语音的产生是一个多层次协调的过程。呼吸系统提供气流,喉部声带控制是否振动以及振动的频率,舌、唇、腭等构音器官共同塑造的声道形状则决定了最终的频谱特征。这三个环节中任何一个发生变化,都会改变听者所接收到的声音。正是这种多器官协同运作的发音机制,使得语音在不同说话者之间表现出极大的差异,而人类的听觉系统却能从这些变异中提取出稳定的语言信息。
语音频谱图
对于随时间持续变化的语音,仅有频谱还不够,还需要引入时间维度。“语音频谱图”就是这样的三维工具:横轴为时间,纵轴为频率,颜色深浅表示各频率成分的强度。在频谱图中,元音表现为几条能量集中的横向条带,辅音则往往呈现短促而分散的过渡特征。从一个音过渡到另一个音时,共振峰的位置会发生移动,形成频谱图上可见的弯曲轨迹,这种过渡段称为“协同发音”的声学痕迹。
频谱图不仅是研究工具,也揭示了说话者的个体特征。同一个词语,不同说话者的频谱图形态各异,反映了各人声道形状和发音习惯的差异。即使同一人在不同时刻、不同语速下的发音,频谱图也会有所不同。汉语中还存在声调这一维度,四个声调通过基频的高低变化来区分,在频谱图上表现为音高轮廓的不同走向。这种高度的变异性,是语音感知研究最核心的难题,也是自动语音识别至今仍面临挑战的根本原因之一。
听觉输入的本质是时间上的事件序列,所有语言信息都通过压力变化的强度和时间关系来携带。频谱图把这些隐藏在声波中的信息以可视化形式呈现出来,是研究语音感知最重要的分析工具之一。
听觉系统的工作机制
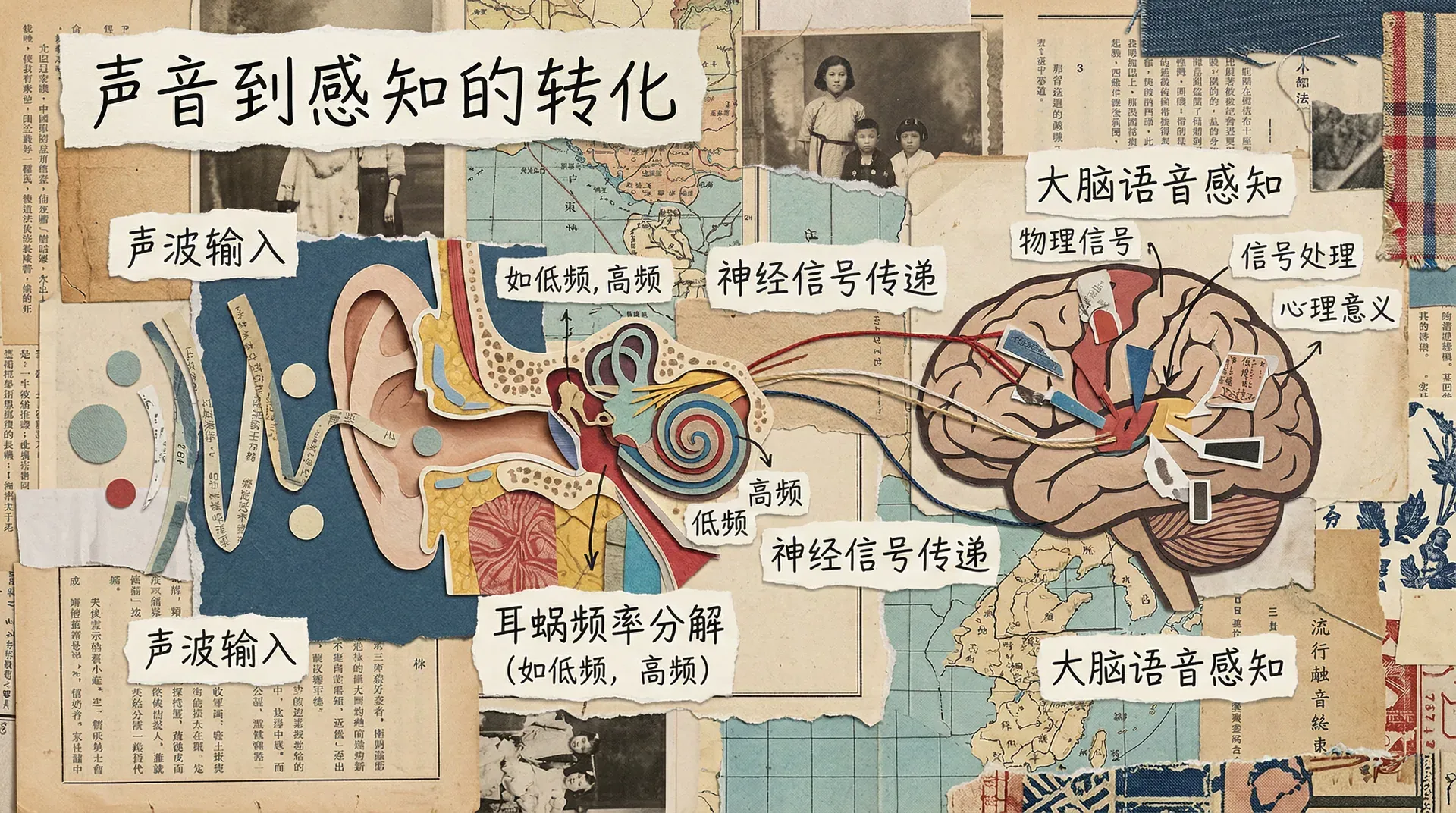
从声波到语言理解,听觉系统需要完成一系列精密的信号处理。这一过程始于耳蜗对声音频率的机械分解,经由神经信号的逐级传递和加工,最终在大脑皮层形成语音感知。理解听觉系统的工作原理,有助于我们看清语音感知在何处、以何种方式将物理信号转化为心理意义。
耳蜗的频率分析
耳蜗是内耳中形状如蜗牛壳的螺旋形管道,是整个听觉系统中第一个重要的分析节点。声波通过卵圆窗进入耳蜗内的液体,引起沿基底膜传播的行进波。基底膜沿其长度方向具有渐变的物理特性:底端较窄而紧绷,顶端较宽而松弛。这种结构使不同频率的声波在基底膜上产生最大位移的位置不同,高频声音集中在底端,低频声音集中在顶端。
基底膜上分布着约一万五千个毛细胞,各自负责检测特定位置的振动,并将机械运动转化为神经冲动。当复杂语音传入时,多个频率同时激活不同位置的毛细胞,产生一组分布式的神经活动模式,其结构类似于该声音的频谱图。这一机制赋予了耳蜗天然的频率分析能力,为后续的语音识别提供了结构化的信息基础。
耳蜗虽然是外周感觉器官,但它完成的工作本质上是一种认知分析,以连续的压力序列为输入,产生具有频率分布特征的神经表征作为输出,为大脑的语音识别提供结构化的信息基础。
来自耳蜗的神经信号经听觉神经传入脑干,再经过若干中继站逐级传递,最终到达大脑颞叶的听觉皮层。在这条通路上,信号并非简单地被转发,而是在每个环节都经历特定的处理。脑干中的神经元对声音的时间结构高度敏感,这对于处理声调语言尤为重要;而听觉皮层中的不同区域则分别负责处理音高、音色、节奏等不同维度的信息。
听觉皮层在处理语音时表现出高度的专门化。研究发现,左侧颞叶在语音的精细时间结构处理上更占优势,而右侧颞叶则对音高和旋律变化更敏感。对于汉语这类声调语言的母语者而言,大脑对声调的处理在语言相关脑区中有更强的激活,而对于非声调语言的母语者来说,相同的声调变化仅触发音乐处理区域的反应。这种神经加工模式的差异,说明语音感知的神经基础本身就受到语言经验的塑造,并非固定不变的生理结构。这也意味着,婴幼儿期的语言输入会对听觉系统的发展方向产生持续而深远的影响。
声音掩蔽与鸡尾酒会效应
在安静环境中清晰可辨的语音,在嘈杂场合往往变得模糊,这种现象称为“掩蔽”。掩蔽的程度取决于噪声与目标语音在频谱上的重叠程度,以及两者的强度关系。白噪声对语音的掩蔽已被广泛研究;另一路无关语音同样可以有效掩蔽目标语音,在两路信号通过同一设备混合播放时尤为明显。
然而在现实生活中,人们在嘈杂的聚会上仍能追随某一人的说话,这就是心理学上著名的“鸡尾酒会效应”。这种选择性聆听能力的主要基础,并非对话语内容的理解,也不主要依赖说话者的声音特质,而在于不同声音来自空间的不同位置。即使闭上眼睛,人们依然能够追随选定的对话;但如果将同一场聚会的录音通过单个麦克风播放,原本清晰的对话就会变得难以辨别。
听觉定位依赖两耳之间的时间差与强度差。来自特定方向的声音到达两耳的时刻略有不同,强度也略有差异;当头部转动时,这些差异的变化规律提供了进一步的位置线索。神经系统对这些微小差异极为敏感,能够据此将来自不同位置的声音流分离开来,实现选择性聆听。
鸡尾酒会效应揭示了一个重要事实:听觉选择并非依赖对内容的理解,而是一种更原始的空间定位能力。这种能力至少部分是先天的,新生儿在听到突然声响时就会将头转向声源方向。
语音的基本单元

语音感知研究的核心难题之一,在于语音信号在物理上是连续的,但人类感知到的却是离散的“音”和“词”。连续性与离散性之间的矛盾,推动研究者从语言学的角度寻找语音分析的基本单元,并在心理学实验中检验这些单元是否具有心理上的现实性。
音素与区别特征
语言学将区分词义的最小语音单位称为“音素”。汉语普通话中“b”和“p”是两个不同的音素,改变其中之一会产生不同的词,如“爸”和“怕”。但音素并非声学上固定不变的实体,同一音素在不同说话者、不同语音环境中的频谱形态可能差异相当大。音素符号代表的是一个类别,而非一个精确的声学模板。
音素还可以进一步分解为“区别特征”,即区分音素的最小属性,通常以二元形式存在:一个语音要么具有某种特征,要么不具备,没有中间状态。
区别特征理论的核心主张是,音素可以用有限数量的二元特征描述和区分,这些特征既有发音上的定义,也有对应的声学表现。音素类别在不同语言中标准不同,普通话区分送气与不送气,许多欧洲语言则主要区分浊音与清音。不同语言的母语者因此对这些特征的感知敏感度存在显著差异,这也正是外语学习者在掌握新语言的发音区分时常常感到困难的原因。
然而区别特征理论也面临内在的循环性困难:每个特征只有在具体语音上下文中才能被准确识别,而上下文本身又依赖对特征的正确判断。识别区别特征需要先识别单词,识别单词又依赖区别特征的正确判断,两者互为前提,构成了一个难以回避的认知循环。
语音的机械识别之所以困难重重,根源正在于此。区别特征并非声学上的固定不变量,它们只有在与整个语音流的关系中才能被定义,这使得任何试图逐一匹配声学特征的识别系统都举步维艰。
认知单元的层次性
语音感知的认知单元并非固定在某一级别,而是随任务要求和聆听条件而变化。音素、音节、词语、短语在不同情境下都可以充当感知的基本单位,聆听者会根据当前的注意焦点和语言知识,灵活调整处理的粒度。
汉语的情况尤为特殊。普通话是典型的声调语言,声调作为区分词义的手段,其在语音感知中的地位与辅音、元音同等重要。“妈、麻、马、骂”四个字声学上仅声调不同,但在感知上却是截然不同的词。声调信息主要通过基频的时间变化轮廓来携带,这要求聆听者不仅要分析瞬间的频谱,还要追踪音高在时间上的变化趋势。
“点击定位”实验为语法短语作为感知单元提供了直接证据。研究者在录音句子的不同位置叠加一个短暂的点击声,要求聆听者判断点击在句子中出现的确切位置。结果发现,判断位置会系统性地向最近的语法断点偏移,偏差可达数百毫秒和几个音素。更有说服力的是,即使两个句子的后半段声学信号完全相同,只要语法结构不同,点击被感知的位置就会有所不同,这说明句子的处理是以语法短语为单元进行的,而非逐个音素或逐个词语。
从反应时间的角度推算,每秒约能完成一个感知决策,对应约三个词语,相当于一个短语的长度。这一推算与日常对话中短语之间自然停顿的现象相互印证,说明短语可能是语音感知中最自然的处理单元。
在真实口语中,词语边界在声学上并没有系统性的标记。“他的判断让我怀疑”这句话,说话者在某个词语内部的停顿,可能比两个相邻词语之间的停顿更长。聆听者感知到的词语边界,是由语言知识和语法期望主动构建出来的,而非声学信号直接给出的。正因如此,不熟悉某种语言的人会觉得母语者说话极快,因为他们缺乏构建词语边界所需的内部知识。语言能力较弱的初学者在词语分割上有特殊困难,这也是为什么我们向他们讲解时,会刻意放慢语速、在词语之间引入明显停顿。
这种词语边界的建构性,在汉语中还与另一个特殊现象密切相关,即同音词与歧义词的感知。汉语中存在大量声学形式相同但意义不同的词,“生意”和“声音”在某些方言中发音相近;“以后”和“意后”读音相同。在连续语流中,聆听者并不会频繁感到困惑,因为词语边界的建构过程本身就同时在整合来自句法和语义层面的约束信息,从而在多数情况下自动选出正确的解读。
语音感知的理论解释

面对语音感知的复杂性,研究者提出了多种理论模型,试图解释聆听者如何将连续变化的声波转化为有意义的语言。不同理论在假设的处理机制和分析层次上各有侧重,相互之间的争论也推动了这一领域的不断深化。
模板模型与滤波器模型
模板模型是最直觉性的理论。它假设大脑储存了所有可能语音片段的详细声学模板,识别时将输入信号与全部模板比较,选出相关性最高的结果。这一思路在逻辑上简洁,但在实践中面临根本性困难:语音变异性极大,要为每种口音、语速、噪声背景下的每个词语储存独立模板,所需存储量是不现实的。更深层的问题在于,模板匹配要求输入信号与模板在时间轴上精确对齐,而真实语音的时长和节奏变化幅度很大,精确对齐几乎无法实现。
滤波器模型设想耳蜗输出的神经信号经过一组滤波器处理,每个滤波器对特定的频谱图案敏感,其输出再经多级组合,识别出音节和词语。这比模板模型灵活得多,也能处理一定程度的声学变异。但面对真实语音的复杂性,单纯的并行滤波仍然不够,还需要引入主动推理机制来处理高层次的语义和语法约束。
另一个值得关注的理论方向是“运动理论”。这一理论认为,语音感知并非仅仅依赖声学分析,而是与发音运动紧密相连。聆听者感知语音时,会在内部隐性地模拟发出这些声音所需的发音动作,这种模拟为声学信号的解读提供了额外的参照框架。运动理论能够解释为什么某些语音对比在感知上呈现出连续性,尽管其声学特征并无连续变化。然而,反驳的证据也不少:即使是从未开口说话的人,同样能理解语音;人们有时能够区分某种外语音素,却无法正确发出这个音素。这说明发音运动并非语音感知的必要前提,运动表征更可能是一种辅助性参照,而非核心机制。
分析-合成模型
目前最有解释力的语音感知理论是“分析-合成”模型。这一模型认为,聆听者在感知语音时并非被动地匹配输入,而是主动地生成关于将听到什么的假设,然后将假设所预期的声学形态与实际输入进行比较。
聆听者基于语言知识和当前上下文,对即将听到的内容生成初步假设。
根据假设,运用语音规则推导出如果假设成立时输入信号应当呈现的声学形态。
将推导出的预期信号与实际听到的声学输入进行比对。
根据比对结果修正或确认假设,完成最终的语音识别。
分析-合成模型有几个重要的优势。它不需要储存所有可能输入的完整目录,只需储存生成这些输入的规则,大幅节省了存储开销。它能在多个层次上灵活运作,从区别特征到音素,从音素到词语,从词语到句子,根据情境选择最合适的分析粒度。它还能自然地解释上下文对语音感知的影响,上下文信息正是用来约束和引导假设生成的机制。
“言语转换效应”为这一模型提供了生动的实验支持。当一个词或短句被反复循环播放时,聆听者会突然感到听到了不同的内容,且这种转变是突然发生的,类似于双稳图形的知觉翻转。不同的解读方案之间存在竞争,当原有方案被另一方案取代时,感知就发生了转变。这一现象有力地说明,听觉是一个持续进行的主动构建过程,大脑不断对相同的输入寻找最合理的解读。
分析-合成模型同样能够解释“语音恢复效应”。当一段录音语音中某个音节被噪声替换时,聆听者通常感知不到缺失,而是将整个词语听成完整的。这种效应说明,在信号不完整的情况下,大脑会依据语言知识自动补全缺失的部分,主动“填写”未能从声学输入中获取的信息。这一补全不是意识层面的推理,而是在感知过程中自动完成的,体现了语音感知与语言知识高度整合的本质。
从认知心理学的视角看,分析-合成模型与“知觉假设检验”框架高度吻合,即感知本质上是一种受约束的猜测过程。不同层次的语言规则——语音规则、音韵规则、词汇知识、句法结构、语义约束——共同构成了这一猜测过程的约束条件,它们协同工作,使得聆听者在大多数情况下都能从不完整、带噪声的声学输入中恢复出说话者的意图。
上下文与语音理解
语音感知并非孤立地处理每一个声学片段,而是深深嵌入在语境之中。聆听者在处理语音时,始终携带着对语言结构的期望,这种期望以“自上而下”的方式影响着“自下而上”的声学分析。上下文的作用不是对基本感知的补充修正,而是感知过程本身不可分割的组成部分。
在一项研究中,聆听者需要在不同程度的噪声背景中识别词语。当词语孤立出现时,错误率随噪声增强而急剧上升;当词语嵌入有意义的句子中时,可理解性显著提升,即使整体信噪比相同。当聆听者提前获知词语来自一个受限的词汇表时,识别准确率也大幅提高。这些结果说明,预期信息通过缩小候选空间来提高识别效率,而不只是在感知完成后进行事后修正。
语法结构同样对语音感知产生实质性影响。由合法词语组成的语法句子,比随机词语串在噪声中更容易被准确识别,即使两者信噪比完全相同。这说明聆听者在处理语音时会自动调用语法知识来约束识别过程,而不只是依赖底层的声学特征。
上下文效应在汉语中的表现尤为突出。汉语是高度依赖语境的语言,大量同音字和多义词的消歧几乎完全依靠上下文完成。“买”和“卖”在声学上极为相近,但在句子“他去市场买菜”和“他去市场卖菜”中,聆听者几乎不会混淆,因为句子的整体语义框架已经强烈地约束了对单个词语的感知。类似地,“经理”和“精力”声音相近,但嵌入不同的句子后,听错的概率极低。
语调和韵律同样承载着超越词汇本身的信息。同一句话用不同的语调说出,传递的意思可能大相径庭。“他走了”以平调陈述是事实;以上扬语调说出,则可能是疑问;配以特定的停顿和重音,还可以表达遗憾、惊讶或责备。聆听者不仅在解码词语,还在同步解读这些韵律信号,将其整合进对整个话语意图的理解之中。
上下文效应的广泛存在,揭示了一个反直觉的事实:我们以为自己“听到”的,其实在很大程度上是大脑在既有知识框架下主动推理的结果。这种主动推理不是随机猜测,而是高度结构化、受语言规则约束的认知过程。正是这种构建能力,使人类能够在复杂嘈杂的真实环境中进行高效的语言交流,也解释了为什么让机器完全模拟人类的语音理解,至今仍是极具挑战性的目标。
个体在语音感知能力上存在显著差异,而这些差异与语言经验密切相关。双语者往往需要同时维护两套语音系统,这对语音感知提出了特殊要求。研究表明,长期使用两种语言的人,其语音感知的灵活性通常优于单语者,更能适应不熟悉口音和不同噪声条件下的语音识别。这也从另一个角度说明,语音感知能力并非固定不变,而是随着语言经验的积累持续发展和调整的。
听觉认知研究最终给我们留下的启示,不只是关于声音和语言,更是关于认知的基本性质:感知不是被动的记录,而是主动的构建;理解不是接收,而是推理。我们所“听到”的世界,始终是大脑与外界信号共同创造的产物。