二叉搜索树:让动态数据始终保持次序
假设一个竞赛系统持续收到新分数。我们既要插入新分数,又要回答“有没有 73 分”“当前最低分是多少”“比 73 分高的下一档是多少”。把数据放进数组,查询可以很快,但在中间插入会移动元素;放进普通链表,插入方便,按大小查询又要从头扫描。
二叉搜索树(Binary Search Tree,BST)把比较结果直接写进连接关系:较小的键进入左子树,较大的键进入右子树。于是,查找、插入和删除都只需沿树的一条路径前进。它们真正依赖的不是节点总数本身,而是树高 :
这条式子是全篇主线。树低矮时,路径接近 ;树退化成链时,路径可能长到 。
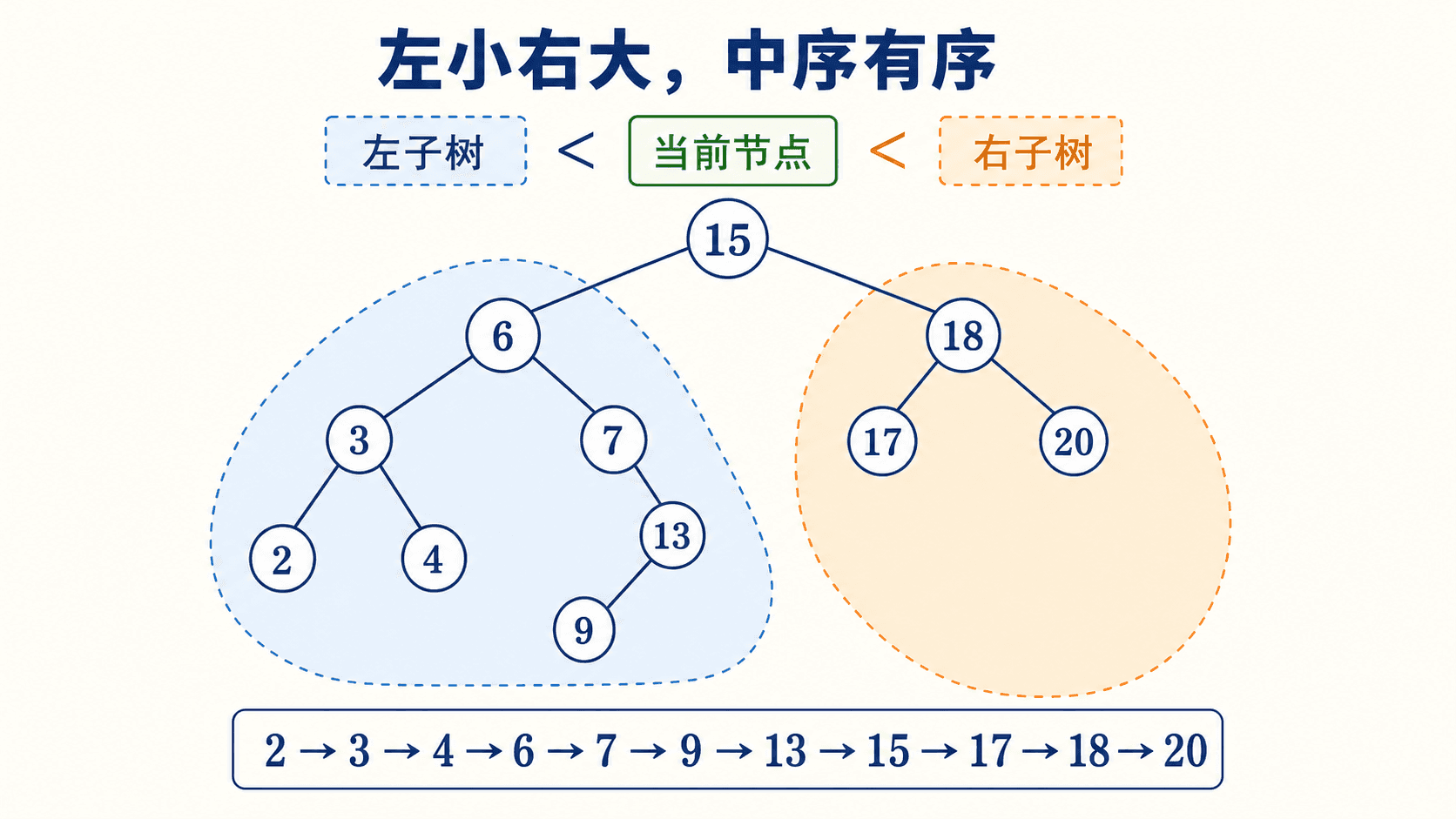
从“左小右大”推出有序遍历
全局约束,不只是比较两个孩子
本章先约定所有键互不相同。对任意节点 x,二叉搜索树必须满足:
这里 与 分别表示 x 的整棵左子树和整棵右子树。关键词是“整棵”:只检查 x.left.key < x.key < x.right.key 不够。例如根为 10,右孩子为 15,而 15 的左孩子为 6,父子关系看似正确,6 却落在根的右子树里,破坏了全局约束。
常见的链式节点会记录 key、left、right 和 parent。空孩子用 NIL 表示,根节点的父指针也是 NIL。如果业务允许重复键,必须另定政策:统一放一侧,或在节点内保存计数。没有明确政策,搜索、遍历和删除对“相等”就会产生歧义。
中序遍历为什么必然有序
中序遍历的顺序是“左子树、当前节点、右子树”:
txt
INORDER-WALK(x)
if x != NIL
INORDER-WALK(x.left)
visit x
INORDER-WALK(x.right)可以按子树规模验证它。叶子只有一个键,显然有序。若左右子树的中序结果各自有序,那么左子树所有键都小于根,右子树所有键都大于根;把“左序列、根、右序列”拼起来仍然严格递增。
遍历必须访问全部 个节点,所以时间为 ,不随树是否平衡而降到 。低树高只能缩短单条查询路径,不能跳过需要输出的节点。
用序列 [15, 6, 18, 3, 7, 17, 20, 2, 4, 13, 9] 建树,真实运行结果是:
console
base.inorder = [2,3,4,6,7,9,13,15,17,18,20]
base.preorder = [15,6,3,2,4,7,13,9,18,17,20]
base.height = 4中序结果揭示键的次序,前序结果则先记录每棵子树的根,更能反映树形。
1
根为 10,右孩子为 15,15 的左孩子为 6。为什么它不是二叉搜索树?
2
一棵含 n 个节点且高度为 O(log n) 的 BST,其中序遍历时间也是 O(log n)。
查询:每次比较都排除一棵子树
在示例树中搜索 13,路径是 15 → 6 → 7 → 13。每到一个节点,只保留仍可能包含目标的一侧:目标更小就向左,目标更大就向右。
txt
ITERATIVE-SEARCH(x, k)
while x != NIL and x.key != k
if k < x.key
x = x.left
else
x = x.right
return x循环开始时可以保持一个不变量:如果键 k 存在,它一定在以当前节点 x 为根的子树中。一次比较排除错误的一侧,不变量继续成立;遇到相等时返回目标,遇到 NIL 时说明候选范围已经为空。

真实执行得到两条路径:
console
search(13) = [15,6,7,13] found
search(16) = [15,18,17] not found
minimum = 2
maximum = 20搜索 16 到达 17 后还应向左,但左孩子为空,因此失败。失败搜索并没有白走:最后一个非空节点正是将来插入 16 时需要修改孩子指针的位置。
最小值与最大值
某棵非空子树只要还有左孩子,当前根就不可能是最小值;所以最小值沿左指针走到底。最大值完全对称,沿右指针走到底。两者访问的节点也组成一条简单路径,时间都是 。
“只沿一条路径”不等于每次都对半缩小元素数量。只有树形足够低矮时,路径长度才接近对数;普通 BST 的查询上界应先写成 。
3
关于一次失败的 BST 搜索,哪些说法正确?
4
在示例树中搜索 16,依次访问 15、18、____,随后到达空指针。
前驱与后继:把局部路径接回全局次序
节点 x 的后继,是中序序列中紧跟在 x 后面的节点;互异键下,也就是大于 x.key 的最小键。前驱是小于它的最大键。
后继分两种情况:
x有右子树。比x大的最近候选就在右边,取右子树最小值。x没有右子树。沿父指针上升,跳过所有从右孩子回到父节点的边;第一次从左孩子回到父节点时,这个父节点就是后继。
第二种情况容易写反。向上时遇到“我是父节点的右孩子”,说明父节点和它的左侧都已在中序遍历中访问过,还要继续上升。只有当“我是父节点的左孩子”时,父节点尚未访问,才是下一个键。
txt
SUCCESSOR(x)
if x.right != NIL
return MINIMUM(x.right)
y = x.parent
while y != NIL and x == y.right
x = y
y = y.parent
return y前驱把左右完全交换即可。若最大节点一路向上仍找不到后继,返回 NIL;最小节点没有前驱也同理。
console
neighbors(2) = {"predecessor":null,"successor":3}
neighbors(13) = {"predecessor":9,"successor":15}
neighbors(15) = {"predecessor":13,"successor":17}
neighbors(20) = {"predecessor":18,"successor":null}单次前驱或后继最多上升或下降一条路径,因此为 。如果从最小值开始连续调用后继遍历整棵树,总时间却是 :整段过程中,每条边只会被向下和向上经过常数次,不能把单次上界机械乘成 。
5
节点 x 没有右子树。向上寻找后继时,应在什么时刻停止?
6
若一个节点有两个孩子,那么它的后继一定没有左孩子。
插入:失败搜索停下的位置就是新叶子
插入新键时不需要发明另一套导航规则。先按搜索路径走到 NIL,同时用 parent 记录最后一个非空节点;再把新节点接到 parent.left 或 parent.right。空树是唯一的边界情况,此时新节点直接成为根。
txt
INSERT(T, z)
parent = NIL
x = T.root
while x != NIL
parent = x
if z.key < x.key
x = x.left
else
x = x.right
z.parent = parent
if parent == NIL
T.root = z
else if z.key < parent.key
parent.left = z
else
parent.right = z新节点最初没有孩子,所以它总是作为叶子加入。路径上的所有旧关系都不变,只新增一条父子边。搜索路径已经证明:沿途被排除的子树不可能容纳该键,最终空位就是保持全局次序的合法位置。
对于初始键 [15, 6, 20, 3, 7, 18, 25],插入 13 的比较路径为 15 → 6 → 7 → 13。插入成本由路径长度决定,仍为 。
7
向示例树插入 16 时,新节点会成为哪个节点的哪个孩子?
8
只要输入键互不相同,新插入的 BST 节点最初一定是叶子。
删除:先分类,再让子树接位
删除难在“拿走节点后,谁接上断开的结构”。把“以新子树替换旧子树在父节点处的位置”封装为 TRANSPLANT,可以把指针修改和情况分析分开:
txt
TRANSPLANT(T, u, v)
if u.parent == NIL
T.root = v
else if u == u.parent.left
u.parent.left = v
else
u.parent.right = v
if v != NIL
v.parent = u.parent这个过程只负责父节点一侧的接位以及新根的父指针,不会自动安排 v.left 和 v.right。
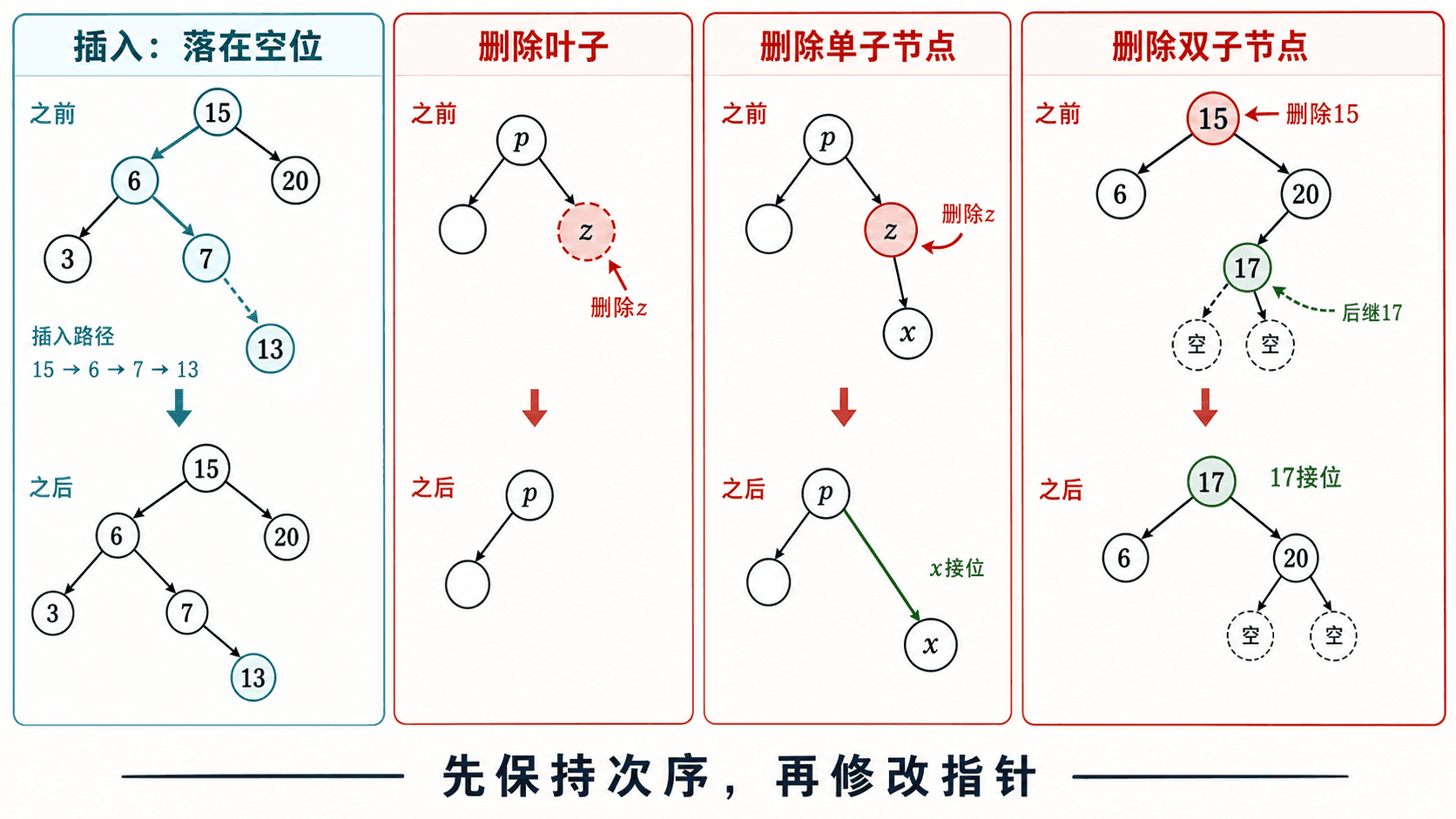
没有孩子或只有一个孩子
- 叶子:用
NIL替换它。 - 只有右孩子:用右子树替换它。
- 只有左孩子:用左子树替换它。
这三种情况都只需把至多一棵现成子树接回原位置。子树内部次序没有变化,而它原本就在被删节点允许的取值范围内,所以 BST 性质继续成立。
两个孩子:用后继填补次序缺口
设被删节点为 z,取 z 右子树中的最小节点 y。y 是 z 的后继,而且没有左孩子。
- 若
y就是z.right,让y直接接替z,再把z.left接到y.left。 - 若
y位于右子树更深处,先用y.right填补y的原位置,再把z.right接到y.right;最后让y接替z,并把z.left接到y.left。
选择后继不是随意替换。y 大于 z 的整棵左子树,又不大于原右子树中的其他节点,正好能占据 z 留下的次序位置。它没有左孩子,所以从原位置摘走时至多需要接回一棵右子树。
三种删除在 Node.js v25.2.1 中的实际输出如下。每次都从同一棵原树重新开始:
console
delete(4) = leaf [2,3,6,7,9,13,15,17,18,20]
delete(7) = one child [2,3,4,6,9,13,15,17,18,20]
delete(6) = two children [2,3,4,7,9,13,15,17,18,20]中序结果仍严格递增,说明删除没有破坏顺序不变量。除寻找后继需要沿左链下降外,其余都是常数次指针修改,因此总成本为 。
常见错误
- 只把后继的键复制给
z,却忘记处理后继原位置;这会留下重复节点。 - 深层后继接位时漏改
y.right.parent或y.left.parent;向上的后继查询会走错。 - 误以为删除顺序可以交换。即使最后剩余键集合相同,不同删除顺序选择的接位节点可能不同,树形也会不同。
9
删除一个有两个孩子的节点 z,并选右子树最小节点 y 接位。哪些结论正确?
10
为什么双子删除常用后继接位?
高度:同一组键也会有完全不同的速度
BST 的形状由插入顺序决定。把 1..15 依次升序插入,每个新键都成为上一个节点的右孩子,最终得到高度为 14 的链。若先插中间值,再递归插入左右区间的中间值,可以得到高度为 3 的低矮树。
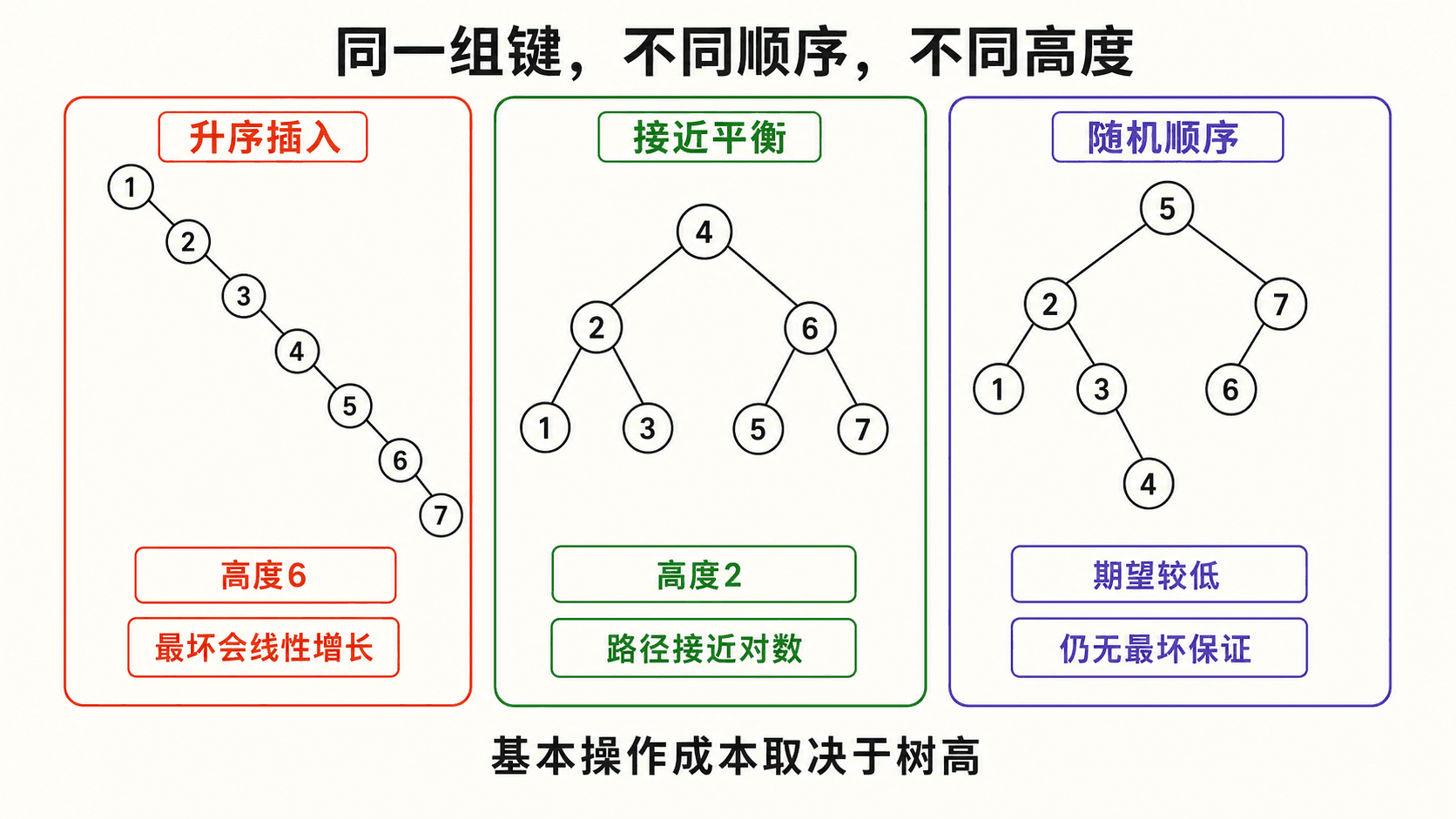
真实执行三组固定输入:
console
sorted.height = 14
balanced.height = 3
fixed-shuffle.height = 7于是复杂度应分开写:
“随机建立”到底随机在哪里
随机建立的 BST 指:给定 个互异键,让所有 种插入排列等概率,再把选中的排列依次插入空树。它不等于“所有合法 BST 形状等概率”。不同数量的插入排列可能生成同一种树形,因此树形出现概率并不均匀。
第一个插入的键成为根。若它在有序键中排名为 ,左子树含 个键,右子树含 个键;两侧又分别按剩余键的相对顺序递归建立。设随机树高度为 ,则结构上有:
分析最大值时,可以考察指数高度 。根排名在 到 之间等概率,结合左右子问题的随机性,可以把 控制在关于 的多项式范围内。指数函数是凸函数,因此:
右侧若至多按 的常数次幂增长,取对数就得到:
这个结论说的是期望高度,不是每次随机排列都低矮,也不是最坏情况保证。若输入恰好有序,普通 BST 仍会退化。随机建立的递归形状也与随机化快速排序相似:第一个插入键像第一次主元,把较小键和较大键拆成两个递归子问题。
判断 BST 性能时先看高度来源:普通树只有 保证;随机插入可讨论期望 ;需要最坏情况也保持对数高度时,必须使用带平衡约束的搜索树。
11
“随机建立的 BST 期望高度为 O(log n)”能推出什么?
12
把 1 到 15 严格升序插入空 BST,若叶子高度为 0,则整棵树高度为 ____。
把所有操作串成一条判断链
面对一道 BST 题,可以依次问四个问题:
- 不变量是什么? 对每个节点,左子树全部更小,右子树全部更大;重复键政策要先说明。
- 本次操作走哪些边? 搜索、极值、插入、前驱后继都沿一条简单路径;遍历则访问全部节点。
- 修改后为什么仍有序? 插入落在失败搜索的空位;删除用唯一孩子接位,或用后继填补双子节点的次序缺口。
- 树高从哪里来? 普通 BST 不自动平衡,必须把复杂度写成 ,再根据具体树形判断 。
这套判断链比记住孤立伪代码更可靠。指针步骤忘记时,可以回到“保持全局次序”重新推导;复杂度犹豫时,可以数操作实际经过的树边。
13
普通二叉搜索树的搜索、插入和删除都应无条件标为 O(log n)。
综合练习与解析
以下题目都使用互异键,并约定叶子高度为 0。
练习一:建树与遍历
依次插入 [15, 6, 18, 3, 7, 17, 20, 2, 4, 13, 9]。写出中序遍历与前序遍历,并给出树高。
练习二:查询与邻居
在上题的树中写出搜索 16 的路径,并求 13 的前驱、后继以及 20 的后继。
练习三:三类删除
每次从原树重新开始,分别删除 4、7、6。判断删除类型,并写出删除后的中序序列。
练习四:寻找指针错误
删除双子节点 z 时,后继 y 位于 z.right 的更深处。某实现先用 y.right 替换 y,再让 y 接替 z,但没有执行 y.right = z.right。会出现什么问题?
练习五:复杂度辨析
判断下列说法:随机建立的 BST 单次搜索最坏为 ;从最小节点连续调用后继访问全部节点需要 。