数据结构:先定操作,再定存法
想象一个急诊接诊系统。普通病人按到达时间候诊,高危病人需要优先处理,已接诊记录又要能按编号迅速找到。如果只准备一个容器,这三类操作很难同时做得便宜。
这正是数据结构要解决的问题:不是单纯把数据“装起来”,而是为将要发生的操作安排存储方式。我们会从接口与表示的区别出发,然后依次比较数组、链表、栈、队列、哈希表和二叉搜索树。读完后,你应该能根据操作分布选结构,而不是靠背一张复杂度表。
先写接口,再讨论表示
假设要保存一组任务。业务层可能只关心以下操作:
- 插入一个新任务;
- 删除一个已完成任务;
- 按任务编号查找;
- 取出下一个应处理的任务。
这些是“能做什么”,也就是接口。至于任务放在连续数组、链式节点、哈希桶还是树节点里,那是“数据怎样存”,也就是表示。
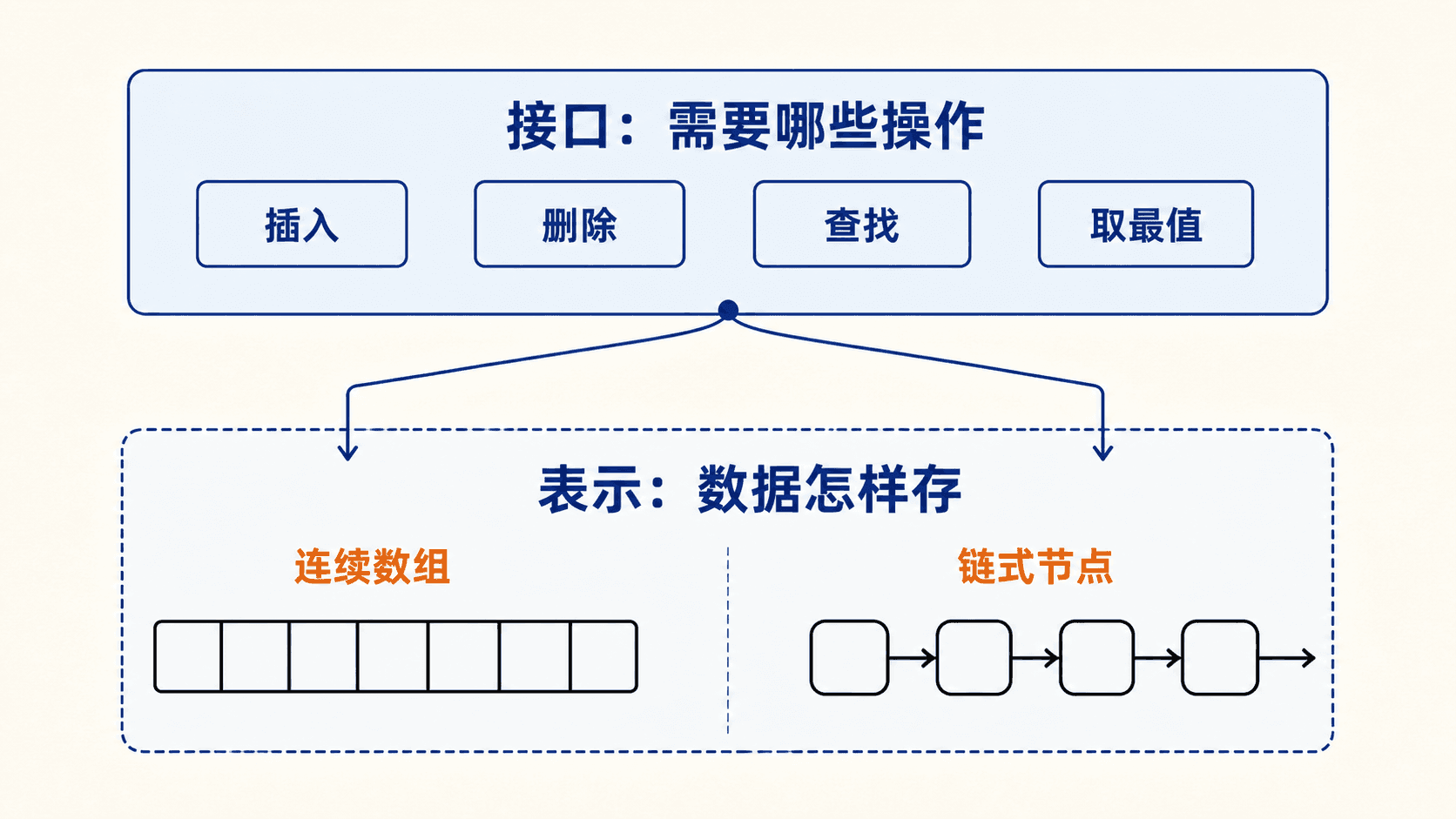
分开这两层有一个实用好处:同一个接口可以换表示。栈可以由数组实现,也可以由链表实现;字典可以用哈希表,也可以用搜索树。调用方看到的操作可以不变,但运行时间、内存使用和能否按序遍历会变。
分析一个新问题时,先写出必须支持的操作和它们的频率。若还没有这张“操作清单”,就急着选哈希表或树,通常是把实现方便误当成问题需求。
1
某模块只规定 push、pop 和 isEmpty,却没有说数据必须放在数组中。这三项描述的是什么?
数组与链表:位置和连接是两种路线
数组用连续位置存元素。如果每个元素占用同样大小的空间,下标就能直接换算为地址,因此访问 A[i] 是 。代价是中间插入或删除时,为了保持顺序,可能要移动后面的 个元素。
链表不要求节点连续。每个节点保存键,并用 next 指向下一个节点;双链表再增加 prev。要找第 个节点,必须从表头沿链走过去,所以按位置访问是 。但如果已经拿到要操作的节点,插入或删除只需改固定数量的连接。
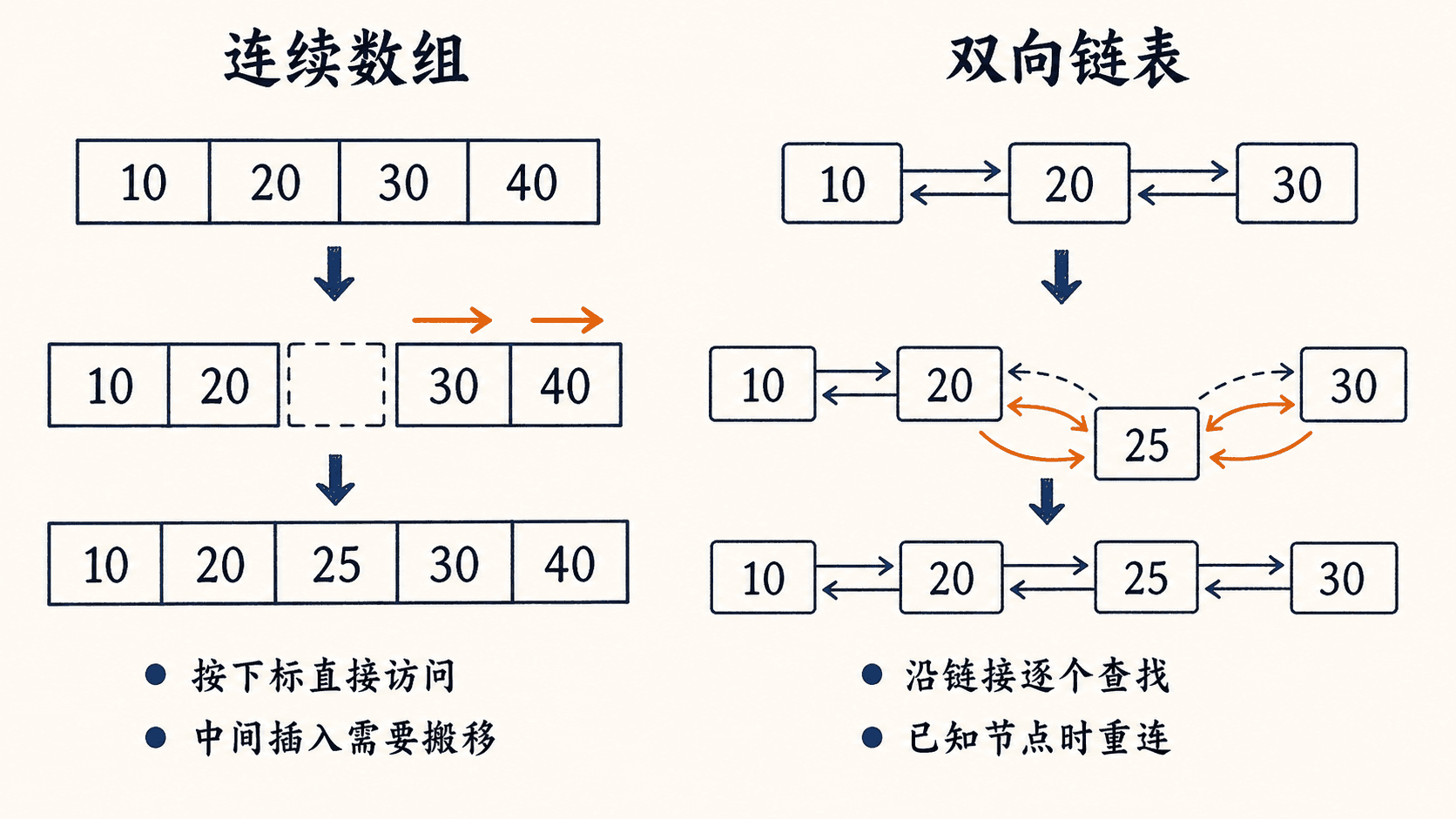
下面是一次真实的双链表指针更新。先把 25 插在 20 与 30 之间,再删除 25:
python
x.prev, x.next = node20, node30
node20.next, node30.prev = x, x
x.prev.next, x.next.prev = x.next, x.prevPython 3.13.11 的实际输出是:
console
linked list after insert = [10, 20, 25, 30]
neighbors after delete = 20 <-> 30这里的删除是 ,因为已经拿到 x。如果题目只给一个键 25,我们还要先顺着链找它,整个过程仍可能是 。
数组和链表也不是绝对对立的。可以用并行数组 key[i]、next[i]、prev[i] 表示链式对象:同一下标的三个字段构成一个逻辑节点,next[i] 存的是另一个节点的下标。连续数组解决物理存储,索引解决逻辑连接。
2
双链表中删除一个节点永远是 O(1)。
栈与队列:用删除顺序表达策略
栈和队列不是某一块固定的内存。它们是对“下一个删除谁”的约束。
- 栈删除最近插入的元素,即后进先出(LIFO)。函数调用、撤销、括号匹配和深度优先搜索使用这个顺序。
- 队列删除停留时间最长的元素,即先进先出(FIFO)。任务排队、数据缓冲和广度优先搜索使用这个顺序。
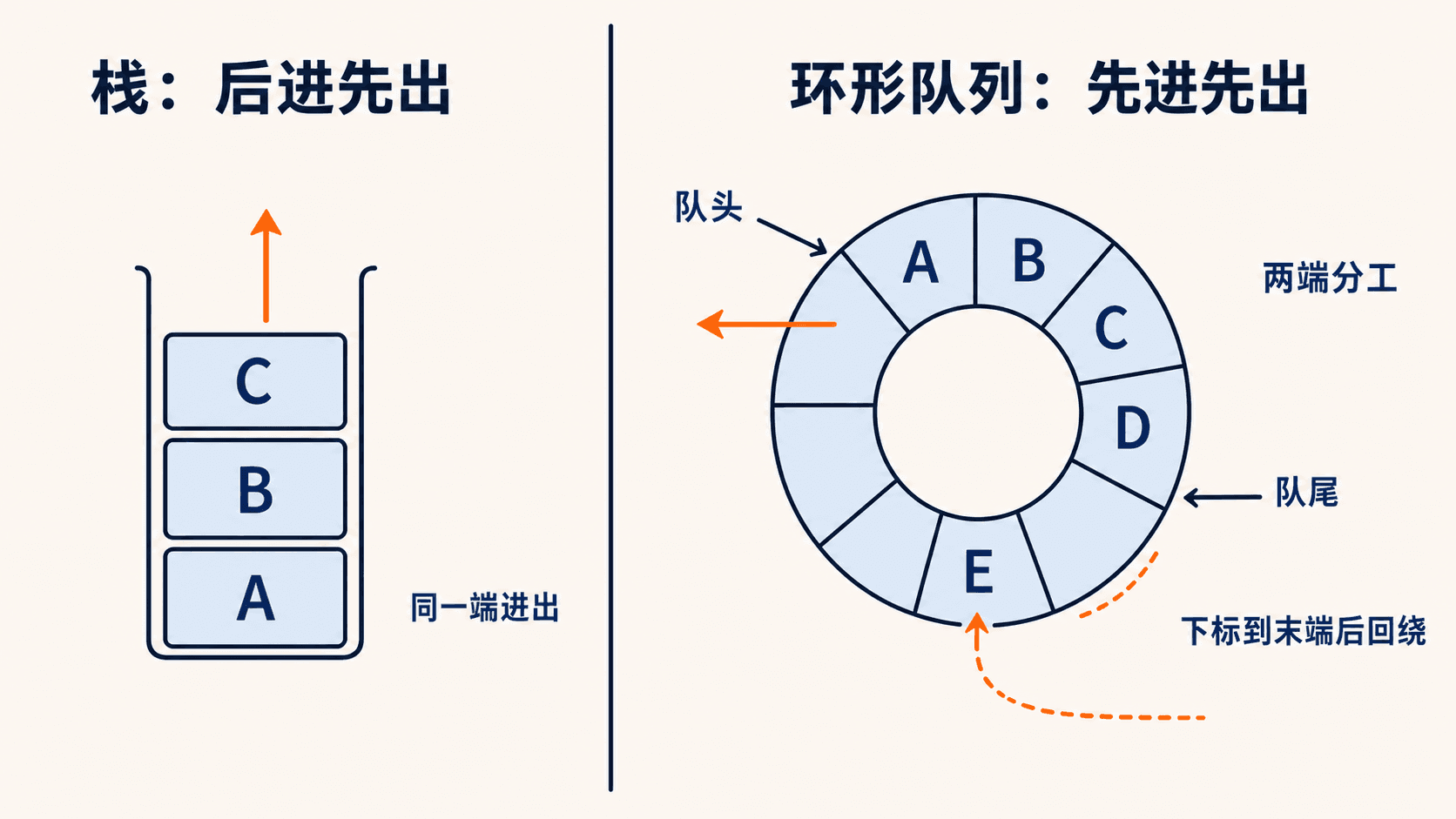
数组栈用一个 top 标记栈顶,压栈和弹栈只改一个元素与 top,都是 。数组队列则用 head 和 tail。若下标到达数组末端就回到起点,数组便成了一个环:
长度为 5 的环形队列先入队 A,B,C,D,再出队两次,最后入队 E,F。真实执行后的底层状态是:
console
circular queue removed = ['A', 'B']
circular queue array = ['F', None, 'C', 'D', 'E'], head=2, tail=1, size=4F 绕回了数组开头,但逻辑出队顺序仍是 C,D,E,F。环形表示避免了从头部删除后搬移全部元素。
3
依次把 A、B、C 放入待处理容器,若取出顺序是 C、B、A,该容器遵守哪种规则?
哈希表:把大键域压到有限的槽
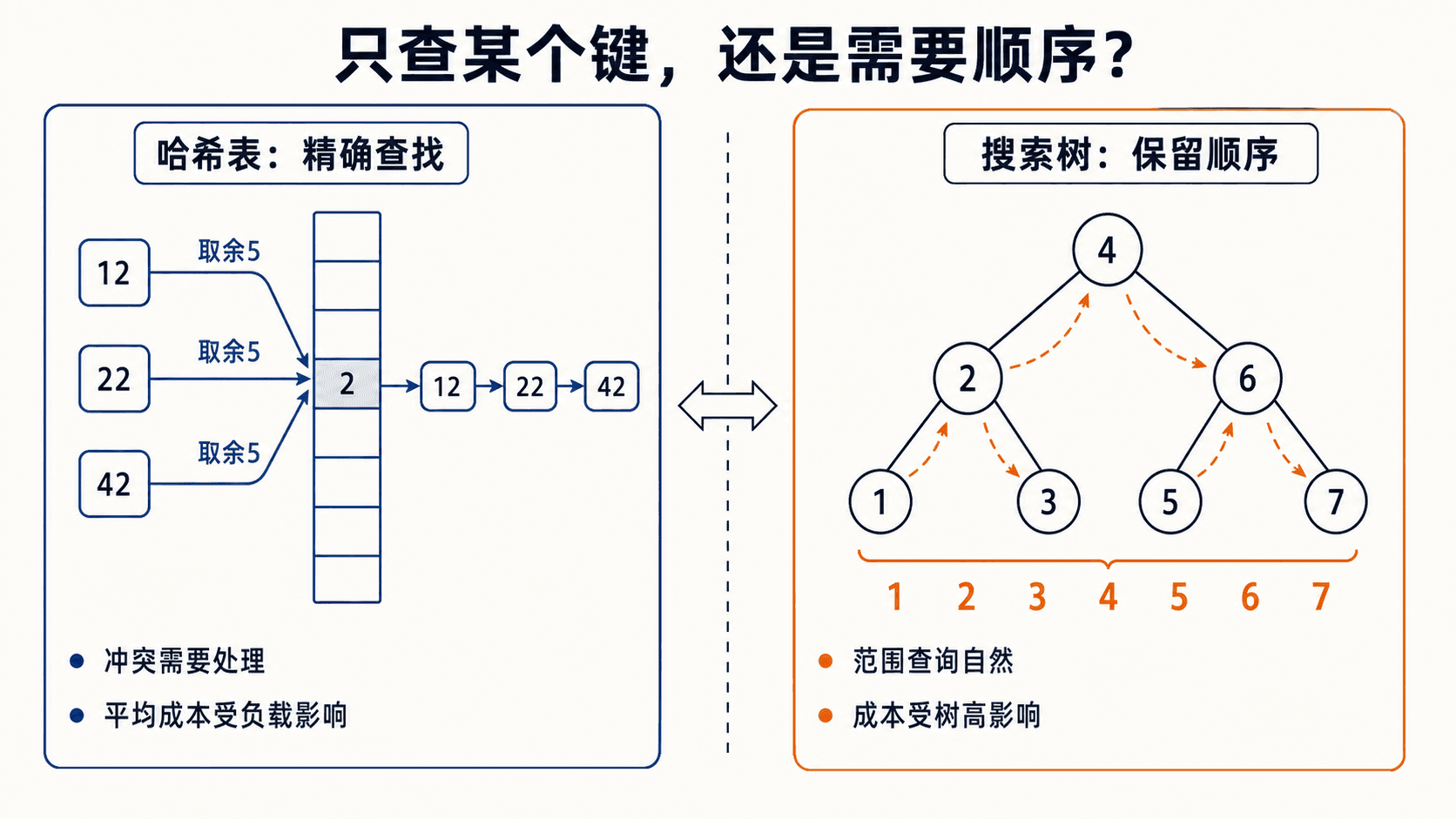
如果会员编号是从 0 到 9999 的整数,可以直接准备长度 10000 的数组,把编号当下标。这叫直接定址,查找、插入和删除都可 。但若编号可能是 12 位整数,实际只有 5000 位会员,为全部可能编号准备数组就不现实。
哈希函数 把键 映射到 个槽之一。因为可能的键多于槽,两个键进入同一槽无法完全避免。这不是程序故障,而是实现必须处理的冲突。
链地址法在每个槽里保存一条链。设已存元素数为 ,槽数为 ,负载因子是:
下面的测试用 把 7 个键放入 5 个槽:
console
hash load factor = 1.40
hash buckets = [[5, 15], [], [12, 22, 42, 7, 17], [], []]负载因子是 ,但第 2 个槽一次聚集了 5 个键。这说明仅看 还不够,哈希函数还要让键尽量均匀分散。在均匀分散且 的前提下,链地址法的期望查找时间是 ,也就是常数级。
开放定址法不建槽内链表,而是冲突时按探测序列继续找空槽。查找时必须重放同一序列。删除不能简单改成“从未使用”,否则会让后续键的查找提前停止;通常需要一个“已删除”墓碑状态。
哈希表的“查找 ”通常是有假设的平均或期望结论,不是无条件的最坏保证。键分布很差、负载过高或冲突处理不当,都会让查找变长。
4
一张哈希表有 20 个槽,已存 15 个元素,其负载因子是 ____。
二叉搜索树:用树高换取顺序
哈希表擅长回答“键 42 在不在”,却没有天然的键顺序。如果问题还需要找最小键、下一个更大的键或某个区间内的所有键,就需要保留顺序的表示。
二叉搜索树的每个节点保存键、左孩子、右孩子与父节点。对任意节点 ,它满足:
因此,按“左子树→根→右子树”做中序遍历,得到的键是非降序。查找时每到一层比较一次,小于当前键就向左,大于当前键就向右。查找、插入、取最小值的成本都受树高 限制:
树高取决于形状,不只取决于键的个数。把 1,2,3,4,5,6,7 依次插入会得到一条向右的链;按 4,2,6,1,3,5,7 插入则更接近平衡。实际运行结果是:
console
ordered BST height = 6
balanced BST height = 2
balanced BST inorder = [1, 2, 3, 4, 5, 6, 7]接近平衡时,;退化成链时,。所以“二叉搜索树查找是 ”同样需要平衡性条件。
5
下列哪些需求会让保持顺序的搜索树比普通哈希表更自然?
把选择写成一张操作账单
比较结构时,不要只挑一个最好看的数字。先列出操作,再标上频率和条件。
再看开头的急诊系统。普通候诊队列适合 FIFO 队列,高危优先处理需要优先队列,按编号找记录可以另建哈希索引。真实系统完全可以同时使用多种结构,让每一种结构负责它擅长的操作。代价是每次更新都要保持多份表示一致。
6
系统需要经常按用户 ID 精确查找,偶尔按注册时间输出全部用户。下列哪个判断最合理?
综合练习与解析
练习 A:环形队列的下标
长度为 8 的环形数组中,tail=6。连续三次入队后,tail 是多少?假设队列容量足够且 tail 始终指向下一个可写位置。
练习 B:链表的隐藏前提
一个未排序双链表有 个节点。给定键 ,删除第一个键等于 的节点。请写出整个操作的最坏复杂度。
练习 C:哈希负载与冲突
链地址哈希表有 50 个槽、100 个元素。计算负载因子,并判断“每个槽一定恰好有两个元素”是否成立。
练习 D:树高与操作成本
两棵二叉搜索树都有 31 个不同键。树 P 高度为 4,树 Q 高度为 30。在两棵树中查找一个不存在的键,最多会走多少层?
练习 E:给记事应用选结构
一个记事应用需要支持:按 ID 精确打开笔记,按修改时间显示最近 20 条,以及撤销最近的编辑动作。请给出一个组合方案,并说明为什么不必强迫一种结构完成全部任务。