线性时间排序:用键的结构换掉比较成本
假设要给 20 万条订单按状态码排序。状态码只有 0 到 15,若直接调用通用排序,程序会反复比较两个状态码;可我们明明知道答案只会落在 16 个位置里。更合适的办法是先数清每个状态码出现多少次,再一次性写出结果。
这正是线性时间排序的出发点:不把输入只看成“可比较的对象”,而是继续利用键的范围、位数或分布。计数排序、基数排序和桶排序都能在合适条件下做到线性时间。条件一旦不成立,它们可能更慢,甚至占用无法接受的内存。
“线性时间”不是对任意输入的无条件承诺。计数排序依赖小整数范围,基数排序依赖可控的位数与基数,桶排序的期望线性依赖桶负载足够均衡。
比较排序为什么停在 n log n
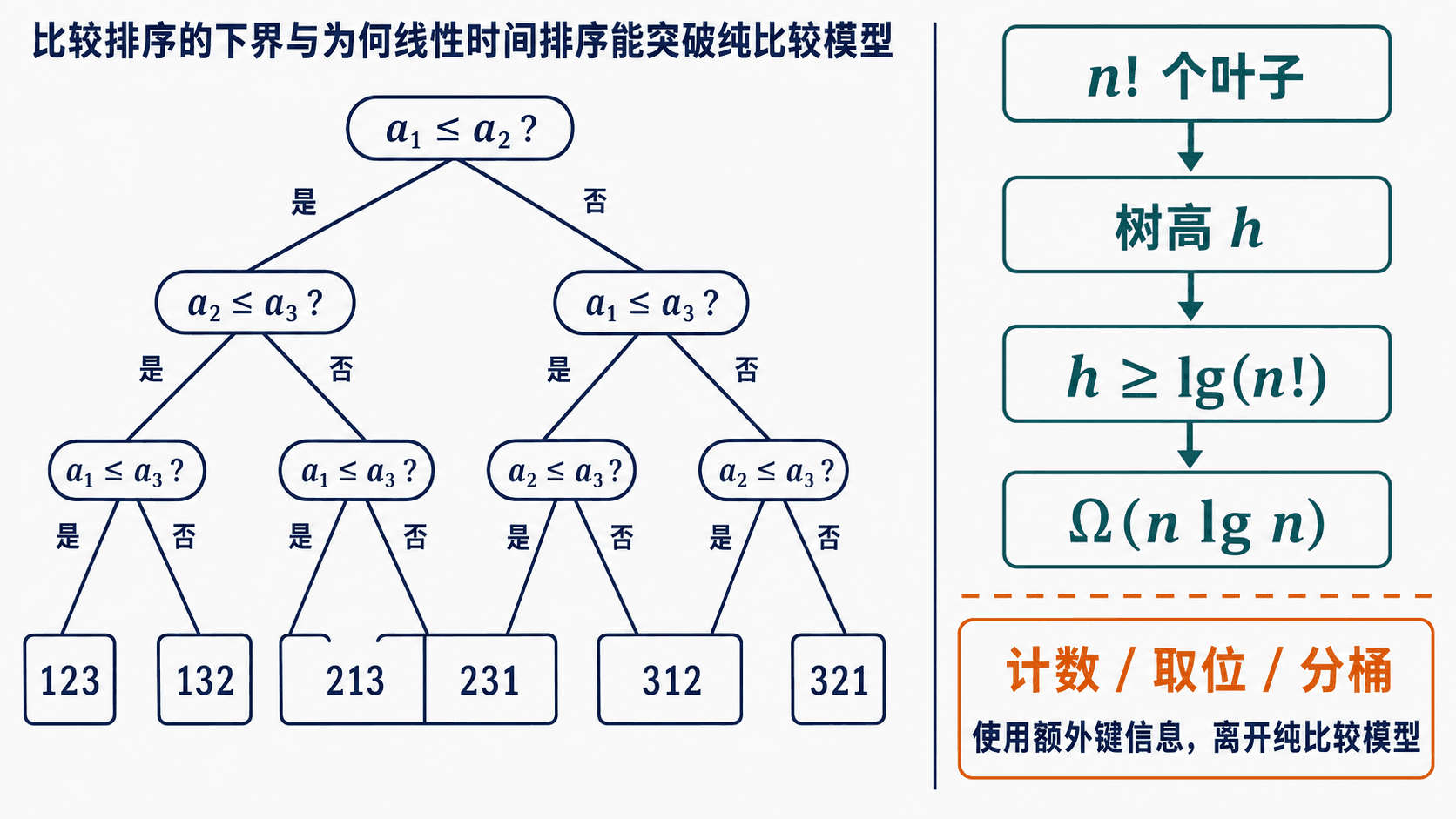
先限定模型:算法只能询问 a[i] <= a[j],不能读取整数值、按位取数,也不能把键直接用作数组下标。每次比较只有“是”和“否”两种结果,因此固定输入规模上的执行过程可以画成一棵二叉决策树。
树的内部节点是比较,根到叶的一条路径是某次执行,叶子是算法最终确认的排列。对 个互不相同的元素,共有 种排列。正确算法必须区分它们,所以至少需要 个可达叶子。
若树高为 ,二叉树最多有 个叶子,于是:
取以 2 为底的对数:
不用复杂近似也能看出它的量级。把阶乘的对数写成求和:
上界显然不超过 。下界只取后半段,至少有 项,每项不小于 :
因此,任何比较排序最坏都要做 次比较。归并排序和堆排序的最坏时间是 ,已经匹配这条下界。
下界没有禁止什么
这条证明没有说“所有排序都必须这么慢”。计数排序会读取键值并把它当下标,基数排序会提取某一位,桶排序会计算映射位置。它们离开了纯比较模型,决策树下界自然不再适用。
1
为什么计数排序不受比较排序 Ω(n log n) 下界约束?
计数排序:从频数走到最终位置
计数排序要求每个键都是 0..k 中的整数。它需要一个长度为 k + 1 的计数数组 C 和一个长度为 n 的输出数组 B。
三次扫描分别在回答什么
统计频数。扫描输入并执行 C[key]++;结束后,C[x] 回答“键 x 出现了多少次”。
累加前缀。让 C[x] += C[x - 1];结束后,C[x] 回答“有多少元素的键不大于 x”,也就是键 x 当前可用位置的右边界。
反向回填。由输入末尾向前扫描,把记录放到 B[--C[key]]。先递减可把一基位置换成 JavaScript 的零基下标,同时为下一个相同键腾出左侧位置。
js
function stableCountingSort(records, maxKey) {
const count = Array(maxKey + 1).fill(0);
for (const item of records) count[item.key]++;
const frequency = [...count];
for (let key = 1; key <= maxKey; key++) {
count[key] += count[key - 1];
}
const prefix = [...count];
const output = Array(records.length);
for (let i = records.length - 1; i >= 0; i--) {
const item = records[i];
output[--count[item.key]] = item;
}
return { frequency, prefix, output };
}把标签视为记录携带的其他数据,真实运行结果如下:
console
count frequency: 2,0,2,3,0,1
count prefix: 2,2,4,7,7,8
count output: 0D 0G 2A 2E 3C 3F 3H 5B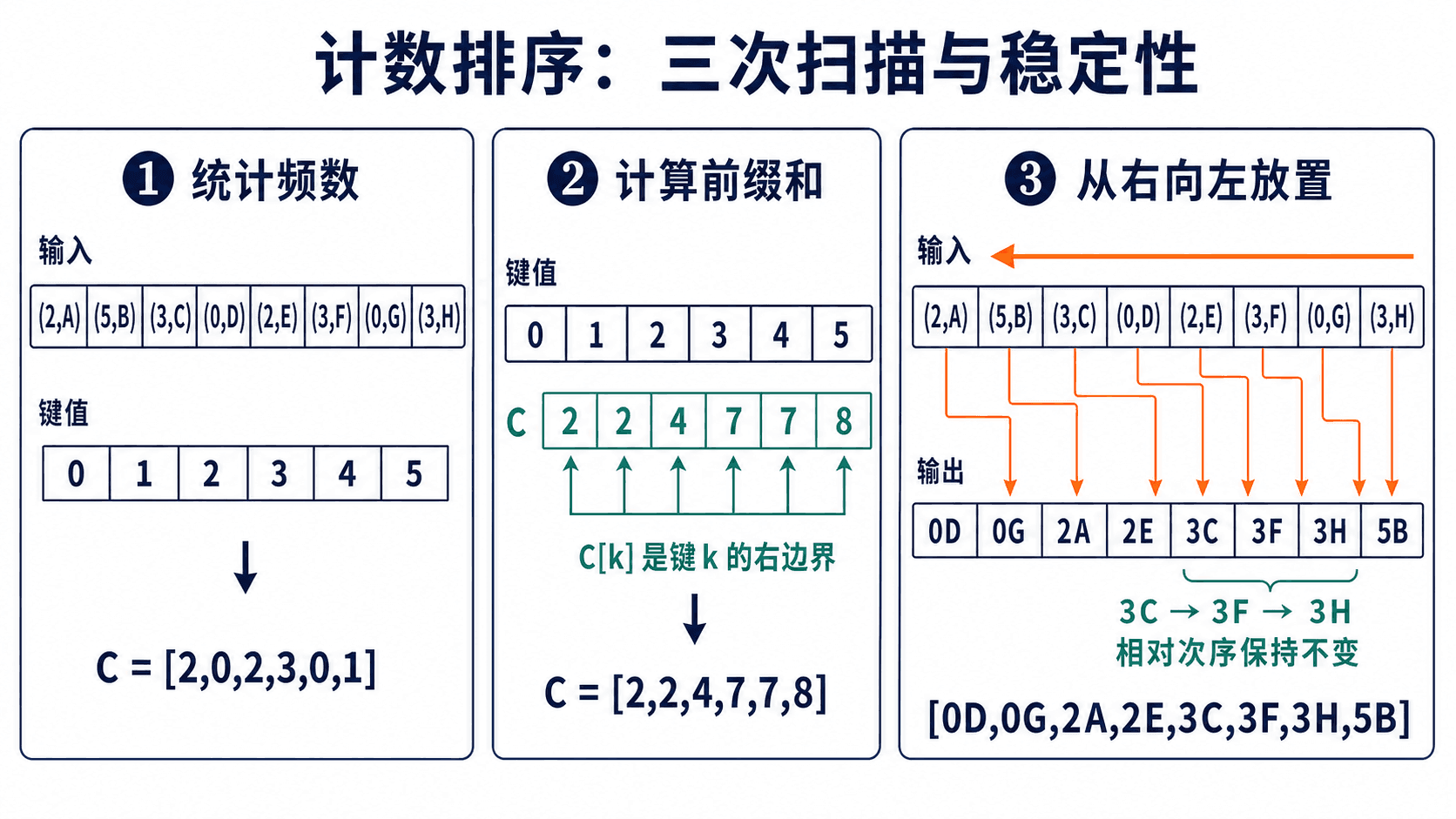
正确性从前缀位置得到
前缀和完成后,C[x] 等于键不大于 x 的元素数。因此键 x 最右边的元素应放在零基下标 C[x] - 1。每放置一个键 x,边界左移一格,所有重复键会占据一段连续位置。不同键的区间按键值递增,所以整个输出有序。
为什么反向扫描保证稳定
若两个记录 p、q 的键相同,并且 p 在输入中先出现,那么反向扫描会先遇到 q,把它放在该键区间的最右空位;稍后遇到 p,放在 q 左边。两者顺序保持不变。
若改成从左向右扫描,却仍使用“最右空位”,排序值依然正确,但相同键记录会倒序。稳定性不是附赠效果,而是扫描方向与位置语义共同产生的结果。
复杂度与边界
初始化和前缀和各扫描 k + 1 个位置,统计和回填各扫描 n 条记录,所以:
空间为 。只有当 时,时间才可简写为 。若只排 100 个编号,而最大编号接近 10 亿,创建计数数组远比排序本身昂贵。
2
稳定计数排序的反向回填开始前,哪些说法正确?
稳定性:多字段排序的连接器
稳定排序要求相同键的记录保持输入时的相对顺序。设订单已经按“创建时间”排好,现在再按“状态码”稳定排序;结果会先按状态码分组,同一状态内仍按创建时间排列。
这可以推广到多个字段。要按 (年, 月, 日) 排日期,可先稳定地按日排,再按月排,最后按年排。每一轮处理更高优先级字段时,相同字段值之间的旧顺序不会被破坏。
计数排序单独使用时可以只输出每个整数若干次,不一定保留记录顺序;但它一旦承担基数排序的逐位子程序,稳定性就是正确性条件。
3
先按低优先级字段稳定排序,再按高优先级字段稳定排序,可以得到按字段元组排序的结果。
基数排序:一位一位保留旧秩序
基数排序把键拆成若干位。LSD 版本从最低有效位开始,每一轮只按一位做稳定排序。以三位十进制整数为例,依次按个位、十位、百位处理。
js
function radixSort(values, digits = 3) {
let records = values.map((value, index) => ({ value, index }));
const passes = [];
for (let place = 1, pass = 0; pass < digits; pass++, place *= 10) {
const decorated = records.map(item => ({
...item,
key: Math.floor(item.value / place) % 10,
}));
records = stableCountingSort(decorated, 9).output;
passes.push(records.map(item => item.value));
}
return passes;
}对 [329, 457, 657, 839, 436, 720, 355] 运行得到:
console
radix pass 1: 720 355 436 457 657 329 839
radix pass 2: 720 329 436 839 355 457 657
radix pass 3: 329 355 436 457 657 720 839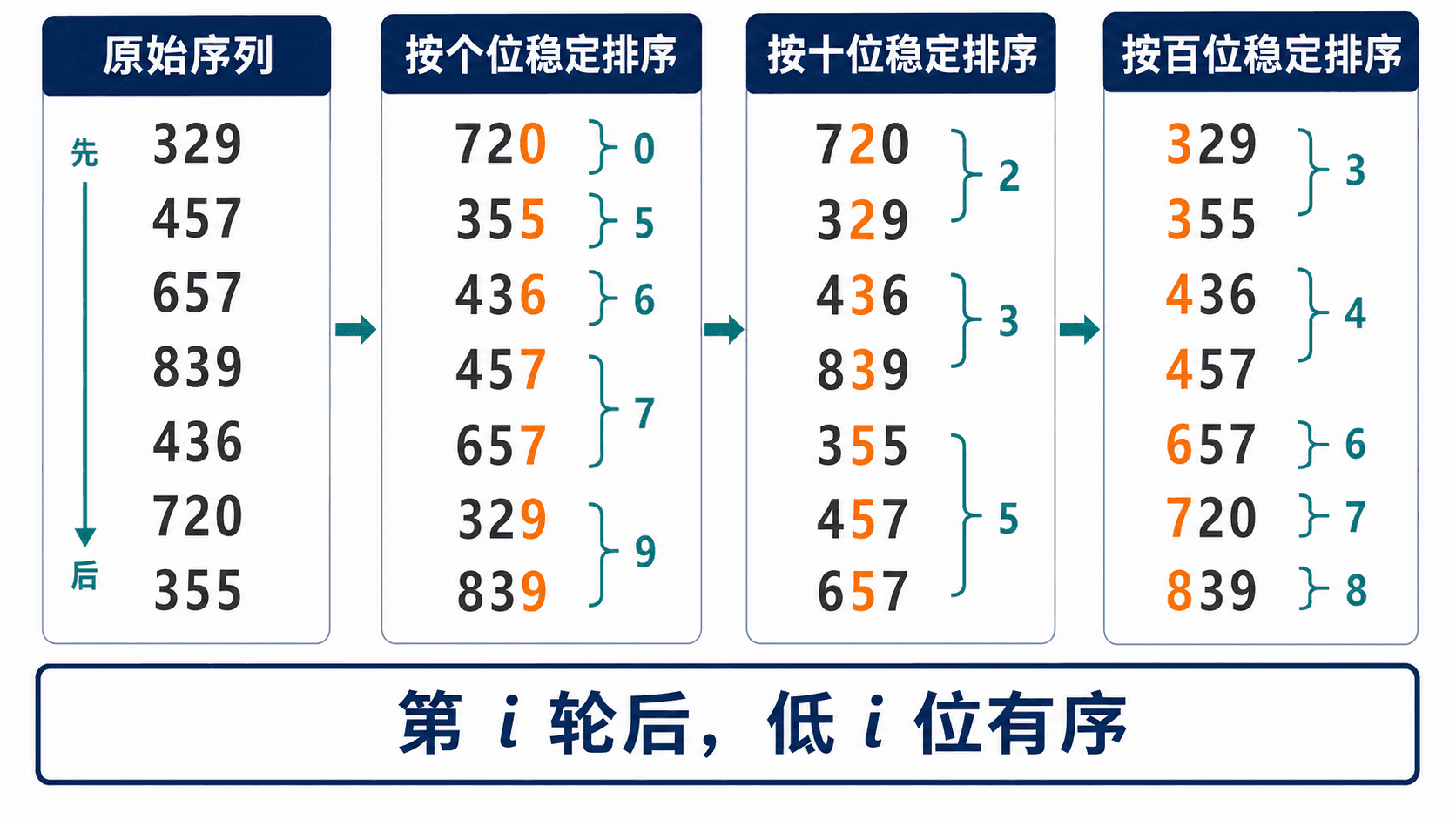
正确性:循环不变式
第 1 轮后,序列按最低 1 位有序。假设第 轮后已按低 位有序;第 轮按新的一位排序。新位不同的记录由本轮决定先后,新位相同的记录因为本轮稳定,继续保持低 位的顺序。因此第 轮后按低 位有序。处理完全部位,整个键就有序。
如果逐位排序不稳定,两个当前位相同的记录可能交换位置,前几轮建立的低位顺序随即丢失,归纳链条在这里断开。
位宽决定复杂度
若每个键有 位,每位有 种取值,逐位计数排序的总时间为:
对 位整数,每轮取 位,则需要 轮,每位有 种值:
把 选得太小,轮数增加;选得太大,计数数组的 项迅速膨胀。当 且取 时,理论上可得线性时间。真实程序还要考虑缓存、数据搬移和额外数组,渐进式更好不等于每个规模都更快。
4
LSD 基数排序的逐位子排序为什么必须稳定?
桶排序:把线性时间写在分布条件里
现在输入换成 [0,1) 内的小数。创建 个等宽桶,并让元素 进入:
逐桶排序后,按桶编号连接即可。若 ,那么 :两者若同桶,由桶内排序决定顺序;若不同桶,x 所在桶一定先输出。这给出了正确性。
期望线性从哪里来
设第 个桶有 个元素,桶内用插入排序。除桶内排序外,初始化、分配和连接都是 ,总成本可写成:
当输入独立且均匀分布时,每个桶的期望负载是常数。更精确地,使用“第 个元素是否落入第 个桶”的指示变量展开平方,可以得到:
对全部 个桶求和仍是 ,所以期望运行时间为 。更一般地,只要实际分桶满足 ,即使原分布并非严格均匀,算法仍可保持线性。
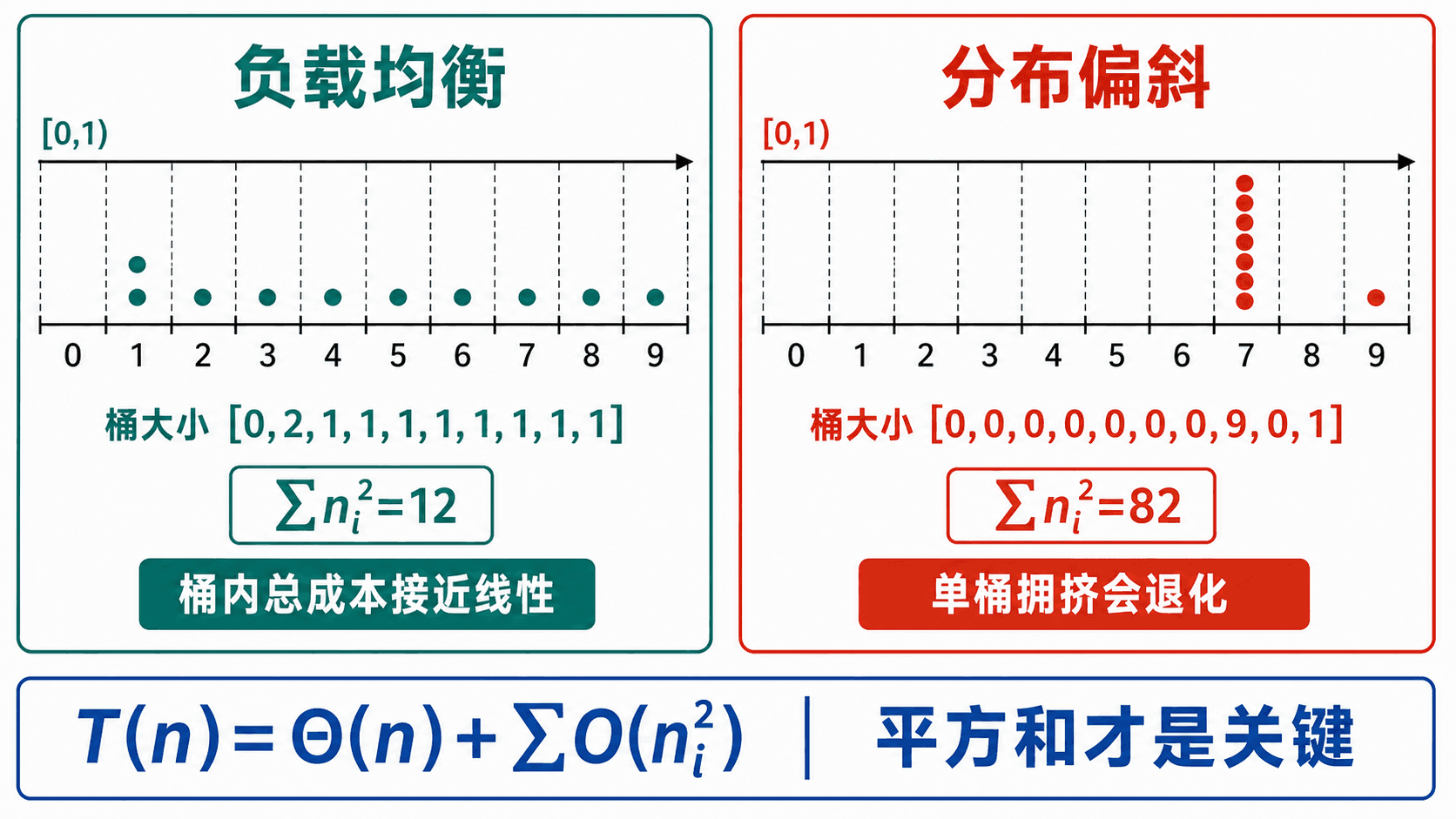
真实运行中,两组同样长度的数据给出完全不同的平方和:
console
uniform sizes: 0,2,1,1,1,1,1,1,1,1 sumSquares= 12
skewed sizes: 0,0,0,0,0,0,0,9,0,1 sumSquares= 82退化与修正
若所有元素落入同一个桶,插入排序会使最坏时间退化到 。把桶内算法换成最坏 的比较排序,可以把整体最坏上界改为 ,同时保留均衡小桶下的线性期望。
若已知连续分布的累积分布函数 且能在常数时间计算,可先把 映射为 。这些值在 [0,1) 上均匀,再使用等宽桶。这里调整的是桶边界,而不是强迫数据服从错误假设。
5
桶内使用插入排序时,哪个量最直接决定桶排序是否接近线性?
选择算法:先审输入契约
同一个复杂度标签可能掩盖完全不同的前提。选择前先回答四个问题:键是不是整数?范围多大?能否拆成少量位?分布是否已知且稳定?
四个常见误判
- “非比较排序击败了排序下界。” 它只绕开了比较模型;键值寻址、取位和分桶都是额外能力。
- “计数排序总比快速排序快。” 当 时,初始化计数数组的时间和内存都会失控。
- “基数排序一定是 O(n)。” 完整式是 ,位数和每位范围必须受控。
- “桶越多越快。” 桶数量增加会带来初始化和管理成本,错误边界仍可能让大部分数据挤在一个桶里。
6
哪些场景应优先放弃直接计数排序?
综合练习与解析
练习一:手算稳定计数排序
对 [(2,A),(1,B),(2,C),(0,D),(1,E)] 写出频数、前缀和与最终输出。
练习二:证明基数排序的一轮
已知某轮开始前,序列已经按低 位有序。本轮对第 位做稳定排序。说明为什么本轮结束后按低 位有序。
练习三:给桶排序加最坏上界
桶内使用插入排序时最坏为 。怎样修改,既保留均匀输入下的线性期望,又把最坏上界降到 ?
练习四:设计排序策略
系统收到 n、整数最大键 k、位宽 b 和一份分布监控报告。写出一条可执行的选择规则。
线性时间排序的真正判断题始终是同一个:程序利用了键的哪一种额外结构,这个结构能否在当前数据上持续成立。