分治法:把一次难题拆成一棵可计价的树
一段连续 17 天的价格记录摆在面前,只允许买入一次、之后卖出一次。最直接的做法是枚举所有买卖日,比较每一对日期的收益。日期数翻倍,候选对数大约会变成四倍。
另一条路是先把相邻两天的价格差写成数组,再寻找和最大的连续片段。问题的表面变了,真正的难点也显出来了:把数组从中间切开以后,最优片段可能完全在左边、完全在右边,也可能横跨切口。前两种可以递归处理,第三种必须专门设计合并步骤。
这正是分治法的工作方式:拆开问题只是起点,合并答案才决定算法是否成立;递推式则记录整棵递归树到底花了多少工作。
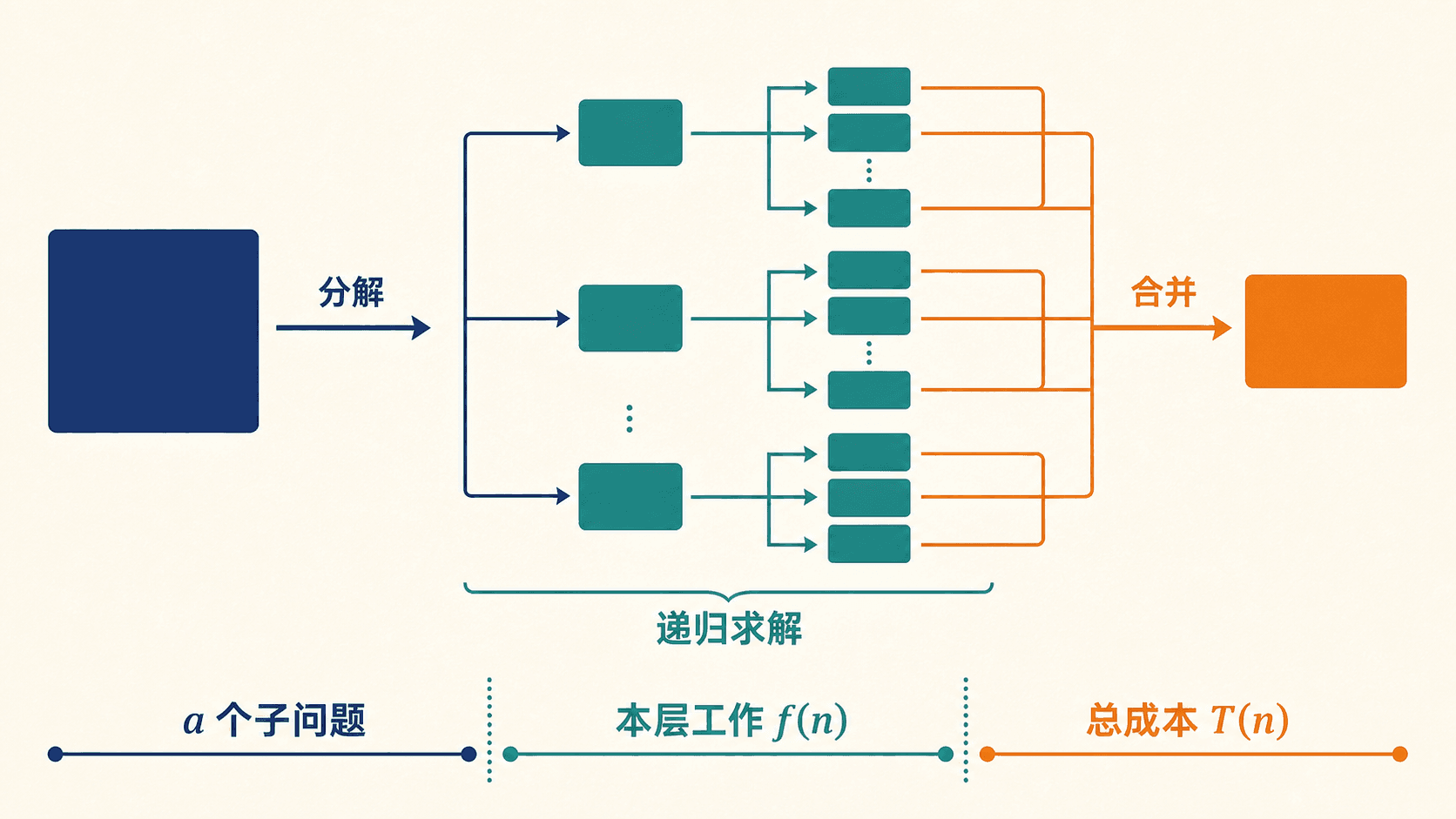
图中的分支数对应递推式里的 ,每个节点内部的非递归工作对应 ;所有节点成本累加后才是 。
从“拆成两半”到完整算法
一个分治算法通常包含三个动作。
分解:把规模为 的问题切成若干个更小的同类问题。切分要让子问题保留原问题的结构,否则递归过程无法复用同一套解法。
求解:对子问题继续执行同样的算法。当规模小到可以直接回答时停止递归,这个停止点是基本情形。
合并:利用子问题的答案构造原问题的答案。合并可能只需一次比较,也可能需要扫描整个区间;这部分成本经常决定最终复杂度。
如果一次调用产生 个规模约为 的子问题,并且本层分解、合并及其他非递归工作一共需要 ,运行时间常写成:
这里的 不能被“常数可以忽略”这句话删掉。它决定每个节点有多少个孩子,继而决定第 层有多少个节点。比如 和 的递归树宽度完全不同。
递推式还需要一个基本情形。若常数规模输入可以在常数时间内解决,可以写成:
分析渐近增长时,通常把 与 简写为 。这种简写不等于程序可以忽略边界。实现仍要保证两个子区间都缩小,并且最终会到达基本情形。
并非所有递归都符合上面的等分形式。下面三类递推各自描述了不同的拆分方式:
看到递归代码时先问“子问题是否真正变小、答案是否覆盖全部情况、合并成本是多少”。只写出递归调用,并不能自动得到一个正确或高效的分治算法。
1
递推式 T(n)=4T(n/2)+n 中的系数 4 表示什么?
最大子数组:合并步骤决定答案
设价格为:
text
[100, 113, 110, 85, 105, 102, 86, 63, 81, 101, 94, 106, 101, 79, 94, 90, 97]把第 天相对第 天的变化记为 ,得到:
text
[13, -3, -25, 20, -3, -16, -23, 18, 20, -7, 12, -5, -22, 15, -4, 7]若从第 7 天收盘后买入,在第 11 天收盘后卖出,收益就是变化数组下标 7 到 10 的总和。于是买卖问题变成:寻找一个非空、连续且元素和最大的子数组。
三类候选没有遗漏
考虑区间 ,中点为 。任意连续片段相对中点只可能处在三个位置之一:
- 终点不超过 ,整个片段位于左半区间。
- 起点大于 ,整个片段位于右半区间。
- 起点不超过 且终点大于 ,片段横跨中点。
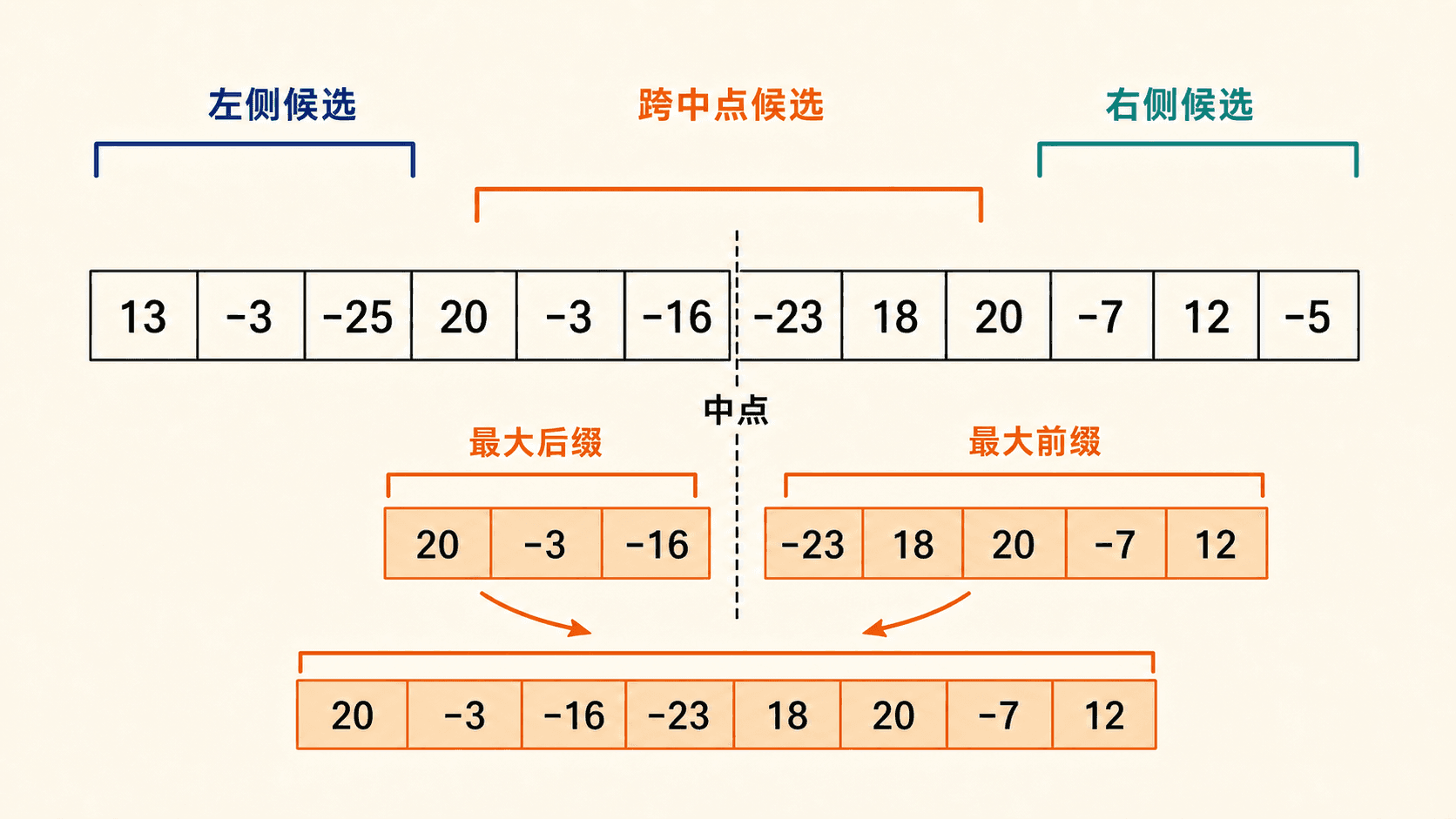
图中这次切分的跨中点候选是左侧最大后缀 [20, -3, -16] 与右侧最大前缀 [-23, 18, 20, -7, 12] 的拼接。递归调用还会分别给出左侧候选和右侧候选,三者取和最大者。
左、右候选是规模更小的最大子数组问题,可以递归求解。跨中点候选附带“必须经过切口”的限制,不是原问题的普通缩小版,应放进合并步骤处理。
跨中点候选为什么能线性求出
任何跨中点片段都可以唯一分成两段:以 结尾的左侧后缀,以及从 开始的右侧前缀。最佳跨中点片段必然使用“和最大的左侧后缀”与“和最大的右侧前缀”。如果其中一边不是最大,把它替换成更大的同类片段就会得到更好的跨中点答案,产生矛盾。
从中点向左累加一次,再从中点右侧向右累加一次,就能找出这两段:
python
def crossing(a, low, mid, high):
best_left_sum = float("-inf")
total = 0
best_left = mid
for i in range(mid, low - 1, -1):
total += a[i]
if total > best_left_sum:
best_left_sum = total
best_left = i
best_right_sum
两个循环合计访问 high - low + 1 个元素,因此合并成本是 。
递归实现与复杂度
python
def max_subarray(a, low=0, high=None):
high = len(a) - 1 if high is None else high
if low == high:
return low, high, a[low]
mid = (low + high) // 2
candidates = (
max_subarray(a, low, mid),
max_subarray(a, mid + 1
两个递归调用各处理一半数组,跨中点扫描是线性的,所以:
每层的区间总长度都是 ,树高约为 ,因此:
下面的结果来自 Python 3.14.6 的实际运行:
console
最大连续片段: [18, 20, -7, 12]
下标与总和: (7, 10, 43)
买卖日: (7, 11)
全负数: (3, 3, -2)best_left_sum 和 best_right_sum 必须初始化为负无穷,而不是 0。题目要求非空子数组时,全负数输入的答案应是最大的单个元素;把初值写成 0 会悄悄允许空片段。
2
跨中点最大子数组由哪两部分组成?
分块矩阵乘法:递归不一定更快
两个 矩阵相乘时,结果元素为:
结果共有 个位置,每个位置要累加 个乘积,直接算法需要 时间。
把每个矩阵分成四个半规模方块:
普通分块乘法得到:
四个结果块各需要两次半规模矩阵乘法,总共是 8 次递归乘法。矩阵加法需要遍历 个元素,于是递推式为:
它的解仍是 。这说明“写成递归”不会自动改善复杂度。真正影响指数的是递归树的分支数与缩小比例。
实现分块时还要决定是否复制数据。用行列范围表示子矩阵,切分本身可以做到常数时间;即使复制导致本层多出 工作,递推式的渐近解仍不会改变,不过实际常数和内存占用会增加。
3
把普通矩阵乘法改写成四分块递归后,时间复杂度会自动降到 Θ(n² log n)。
Strassen:用加减法换掉一次递归乘法
普通分块方案的瓶颈是 8 个递归乘法。Strassen 的做法是先组合输入块,只计算 7 个乘积,再用这些乘积还原四个输出块。
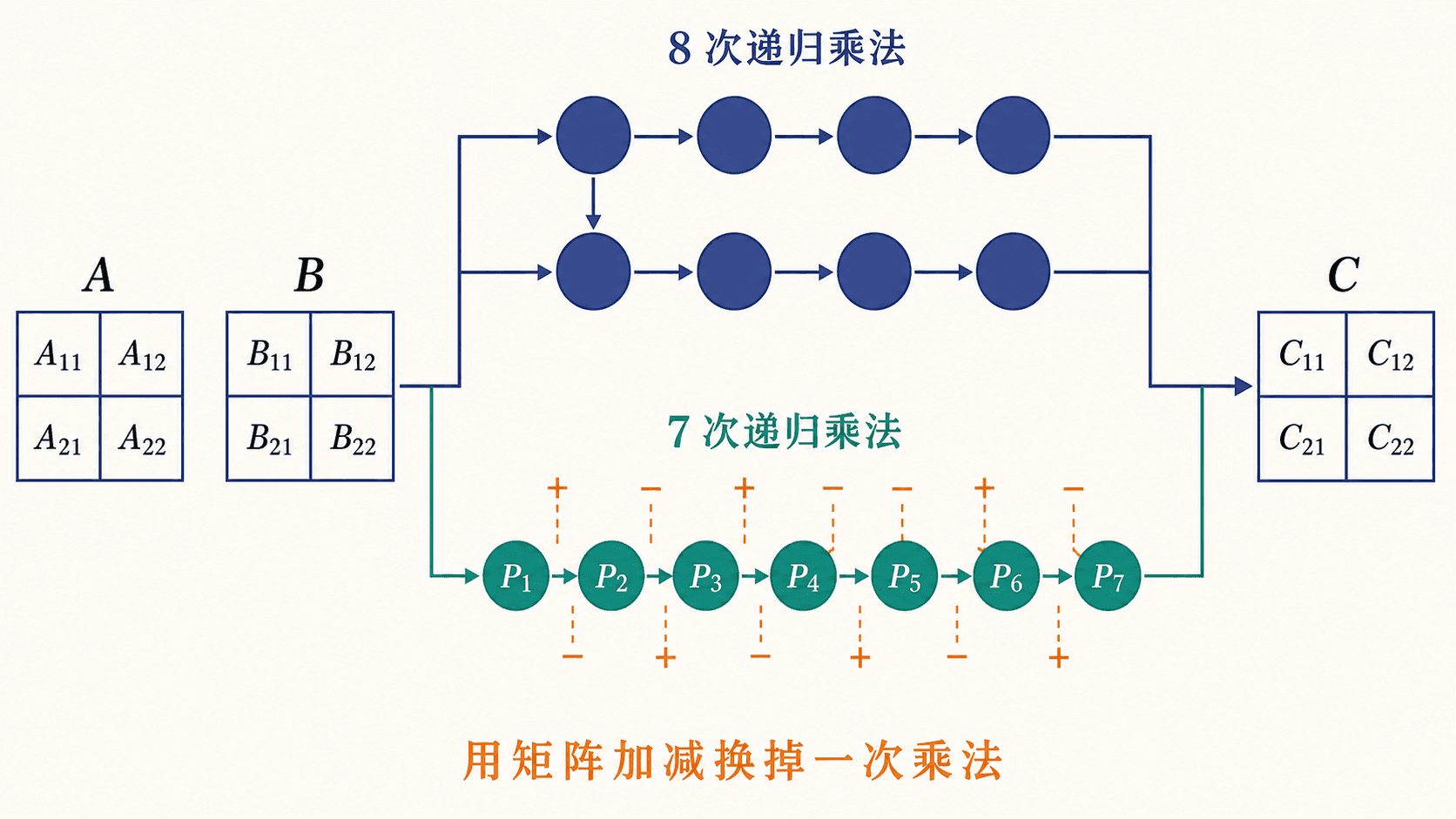
普通分块路径的 8 个乘法节点使递归树每层按 8 倍扩张;下方路径增加矩阵加减组合,把分支数降为 7。
一种常用的七乘积写法是:
随后重组结果:
这些加减法处理的仍是半规模矩阵,本层总成本为 ;递归乘法从 8 次降到 7 次:
因此:
用下面两个矩阵核对公式:
Python 3.14.6 的实际输出为:
console
普通乘法: [[18, 14], [62, 66]]
七个乘积: [6, 8, 72, -10, 48, -12, -84]
Strassen: [[18, 14], [62, 66]]
指数: 2.807355两条路径给出同一个结果。小矩阵上,额外加减、临时矩阵与内存访问可能让 Strassen 更慢;工程实现通常设置阈值,小规模时切回普通乘法。若矩阵边长不是 2 的幂,可以补零到不小于 的最近 2 的幂,计算后再裁掉补出的行列。补零后的边长小于 ,不会改变渐近阶。
4
Strassen 改善渐近复杂度的直接原因是什么?
递归树:逐层把成本加起来
递归树把一个递推式画成调用结构。每个节点标记“该子问题本层的非递归成本”,边表示递归产生的子问题。分析时按三步计价:
- 求第 层的节点数。
- 求该层每个节点的规模与单节点成本。
- 先算层成本,再把所有层与叶子成本相加。
以最大子数组的递推为例,先把常数省略成:
第 层有 个节点,每个节点规模为 。每个节点的扫描成本与自身规模成正比,因此第 层总成本是:
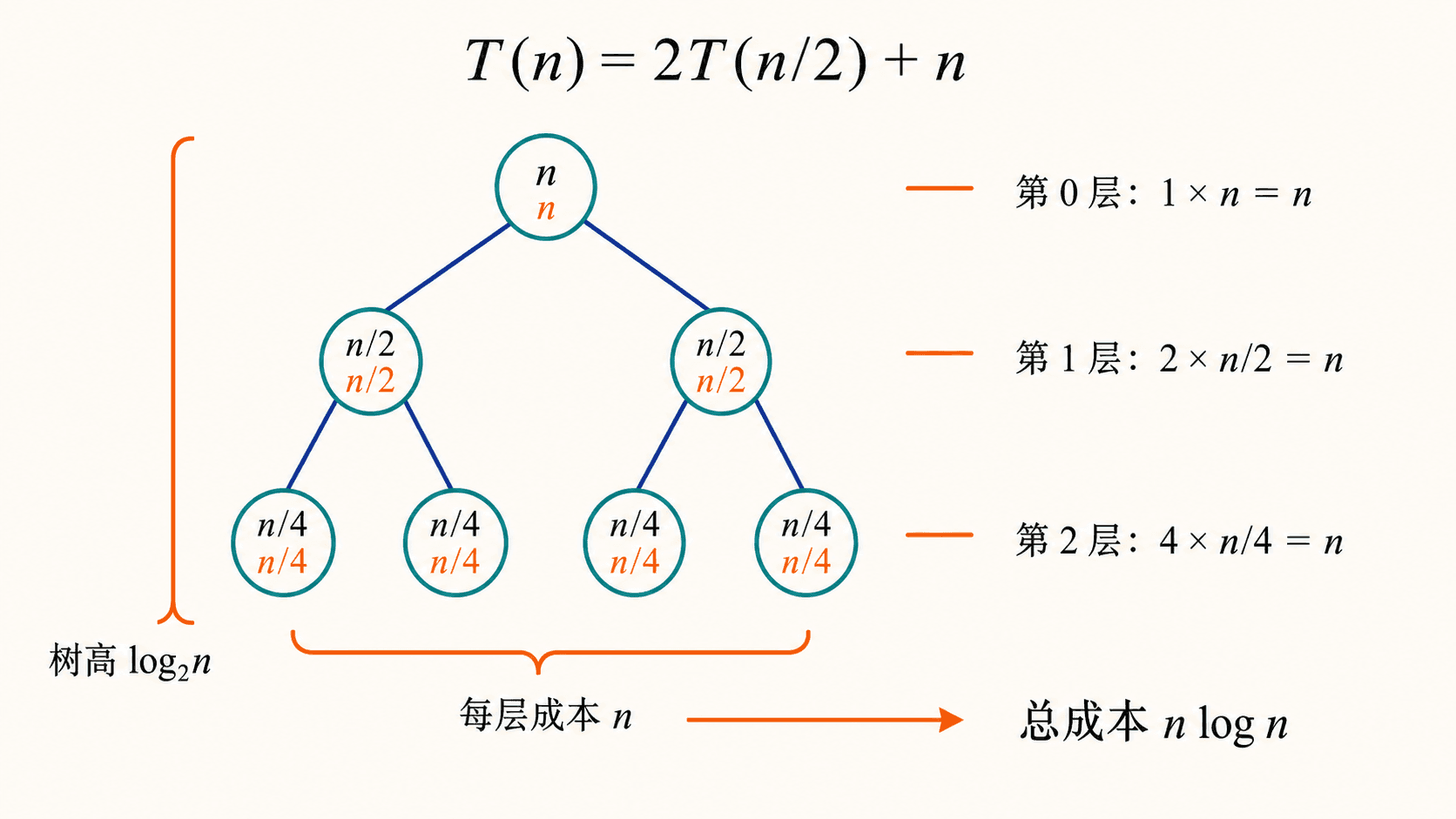
节点内黑色数字表示子问题规模,橙色数字表示该节点本层扫描成本。节点数增加与单节点成本下降正好抵消,所以每层总成本保持为 。
当子问题规模降到 1 时:
所以树高 。每层成本都是 ,共有约 层,叶子总成本也是 ,最终得到 。
对 n=64 的实际计算显示前六层成本完全相同:
console
递归树层成本: [(0, 1, 64, 64), (1, 2, 32, 64), (2, 4, 16, 64), (3, 8, 8, 64), (4, 16, 4, 64), (5, 32, 2, 64)]另一个形状是:
第 层有 个节点,每个节点的本层成本是 ,因此层成本为:
层成本按比例 衰减,所有内部层形成收敛的几何级数,总量与根节点的 同阶。因此根部附近主导,总成本为 。
对 这类不等规模递推,树的叶子深度并不一致。不能把最长路径当成所有分支的高度,再假设每一层始终有完整的 成本。递归树可以帮助形成上界猜想,但严谨结论还应通过代入法或更合适的工具核验。
5
在 T(n)=3T(n/4)+cn² 的递归树中,第 i 层内部节点的总成本是什么?
主方法:比较递归增长与本层工作
主方法处理固定数量、固定比例子问题的递推:
其中 、。先计算基准量:
它可以看作“只计算叶子数量时得到的规模”。再把 与这个基准作多项式级比较。
第三种情况还要求存在常数 ,使足够大的 满足:
这个条件保证本层工作沿递归向下按固定比例衰减,不会出现看似根部很大、下层却反常增大的情况。
三个算法怎样落入三种形状
最大子数组的分治算法有 、、。基准也是 ,属于同阶情况:
普通分块矩阵乘法有 、、。基准为 ,递归部分多项式级更大:
Strassen 有 、、。基准为 ,仍由递归部分主导:
不能直接套用的情形
下面两种递推都不适合直接套这版主方法:
它的两个子问题大小不同,无法写成 个统一的 。
这里的基准是 ,而 虽然更大,却没有大出一个 因子,落在同阶情况与多项式级更大情况之间的空档。不能只凭“看起来更大”就选第三种情况。
6
对 T(n)=9T(n/3)+n,主方法给出的紧确界是什么?
常见误区与设计检查
误区:只验证了两个递归分支
最大子数组若只比较左、右结果,就会漏掉跨中点片段。设计分治算法时,应先证明所有答案能被一组互斥且完备的情况覆盖,再为每种情况安排求解路径。
误区:基本情形改变了题意
非空最大子数组在全负数输入上必须返回某个负数。把累计和初值设为 0,等价于把空数组偷偷加入候选。基本情形与初始值都要服从问题定义。
误区:把递推式里的分支数吞掉
中的 8 决定树宽,不能因为它是常数就写成 。渐近记号可以忽略的是整项外的常数倍,例如 ,不是递归调用的数量。
误区:主方法只比较“谁更大”
第一、第三种情况要求多项式级差距;第三种还要检查正则条件。若落入两种情况之间的空档,应改用递归树、代入法或更一般的递推分析工具。
一张可复用的检查表
- 子问题与原问题是否同类,规模是否严格减小?
- 基本情形是否覆盖最小合法输入?
- 候选分类是否互斥且没有遗漏?
- 合并结果是否足以恢复原问题答案?
- 本层非递归成本 是否计算完整?
- 递推式是否准确保留子问题个数与规模?
- 所选递推分析方法是否满足适用条件?
- 代码中的取整、空输入、全负数与非 2 次幂边长是否处理清楚?
7
下列哪些检查能直接发现一个分治算法的结构性错误?
综合练习与解析
练习一:判断递归树由哪一层主导
分析:
写出第 层的节点数、单节点非递归成本、层成本和最终紧确界。
练习二:处理非 2 次幂矩阵
要用 Strassen 计算两个 矩阵,可以补零到多大?为什么这不会改变 的渐近界?
练习三:识别主方法的空档
判断主方法能否直接处理:
练习四:从定义检查全负数数组
对数组 [-8, -3, -6, -2, -5, -4],非空最大子数组是什么?若允许空子数组,答案怎样改变?
8
哪一个递推式准确描述了分治最大子数组算法?