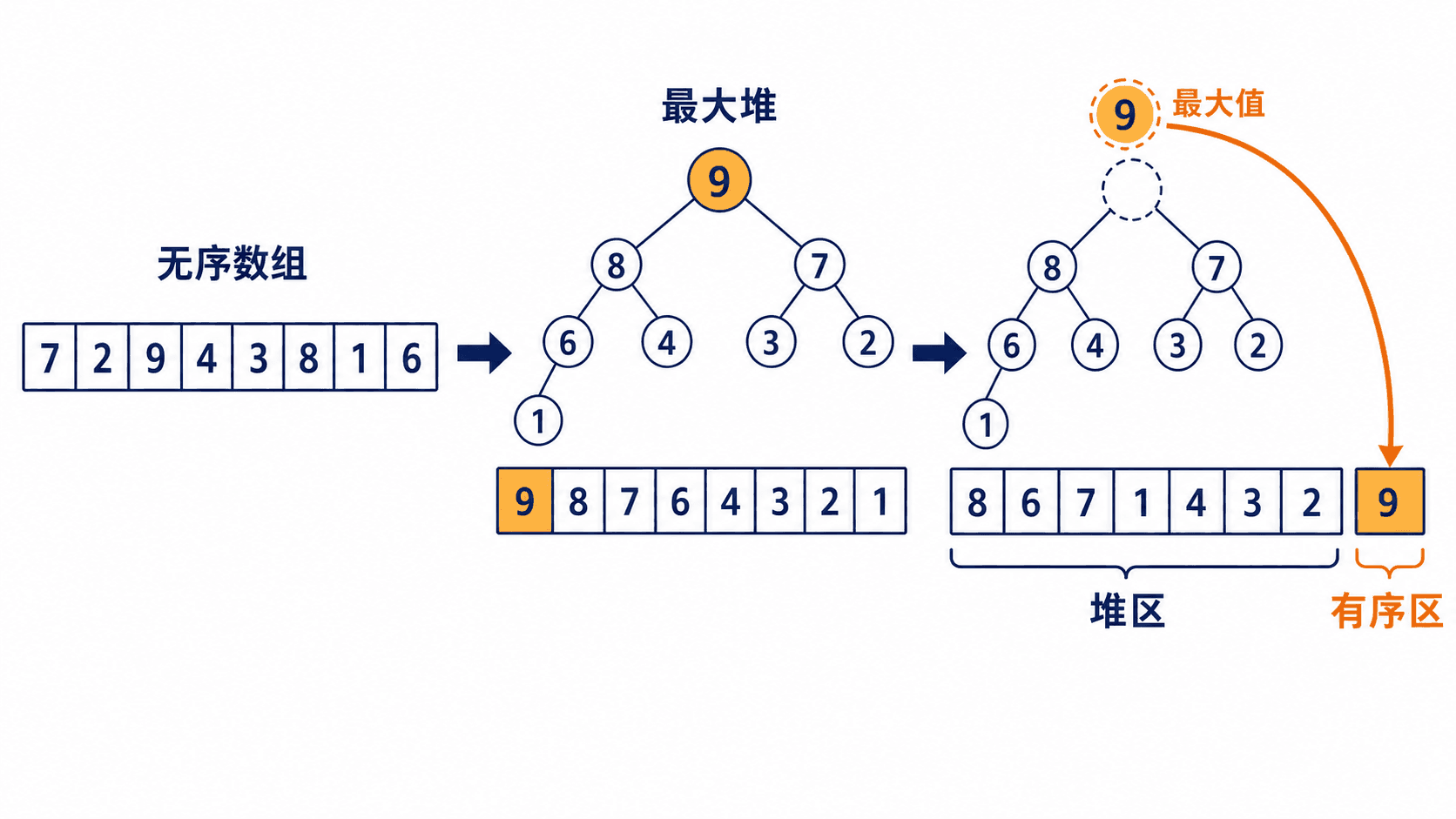
堆排序:把最大值一轮轮送到数组末尾
有一组不断变化的任务,每个任务都有优先级。我们既想随时取出最高优先级任务,又希望最终能把全部任务按优先级排好。每次重新扫描整个数组当然可行,但取一次最大值就要花 。二叉堆把这件事压缩成一条从根到叶的路径:最大值始终放在根,修复一次只走 层。
堆排序利用同一个结构完成原地排序。先把无序数组整理成最大堆,再把堆顶与堆尾交换;堆区逐轮缩小,有序区从右向左增长。整个过程最坏为 ,除调用栈外可以只用常数个临时变量。
本文的可运行代码采用 JavaScript 常见的 0 基索引。讲算法时也会给出 1 基索引公式,切换口径时要同时修改父子索引,不能只把数组下标减一。
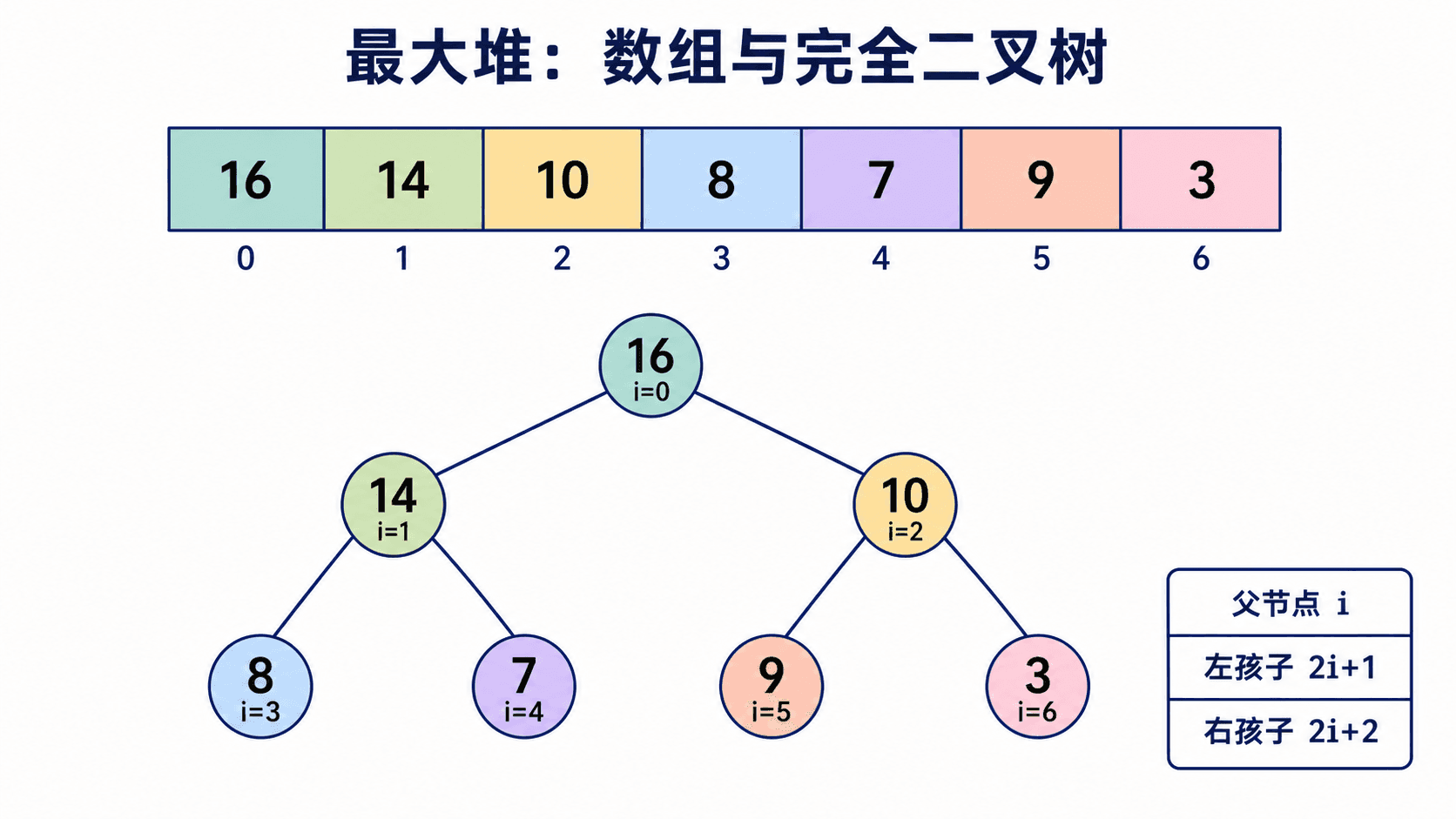
数组为什么能装下一棵树
二叉堆的形状是一棵完全二叉树:除最后一层外,每层都填满;最后一层从左向右连续填入。正是这个形状消除了“空洞”,让层序遍历的节点能够紧密地排进数组,不必保存左右指针。
若使用 1 基索引,节点 的亲属位置为:
若使用 0 基索引,则变为:
形状只解决存储问题,还需要“堆序”约束。最大堆要求每个非根节点的键不大于父节点:
沿着任意节点向根走,键值不会下降,因此全局最大值一定在根。最小堆把不等号反过来,根保存全局最小值。两种堆都只约束父子关系,不约束兄弟之间的顺序,更不保证左子树整体小于右子树。
长度为 的 0 基堆中,最后一个内部节点是 ,索引 到 全是叶子。这条边界随后会决定建堆从哪里开始。
1
在 0 基数组堆中,索引 5 的左孩子索引是多少?
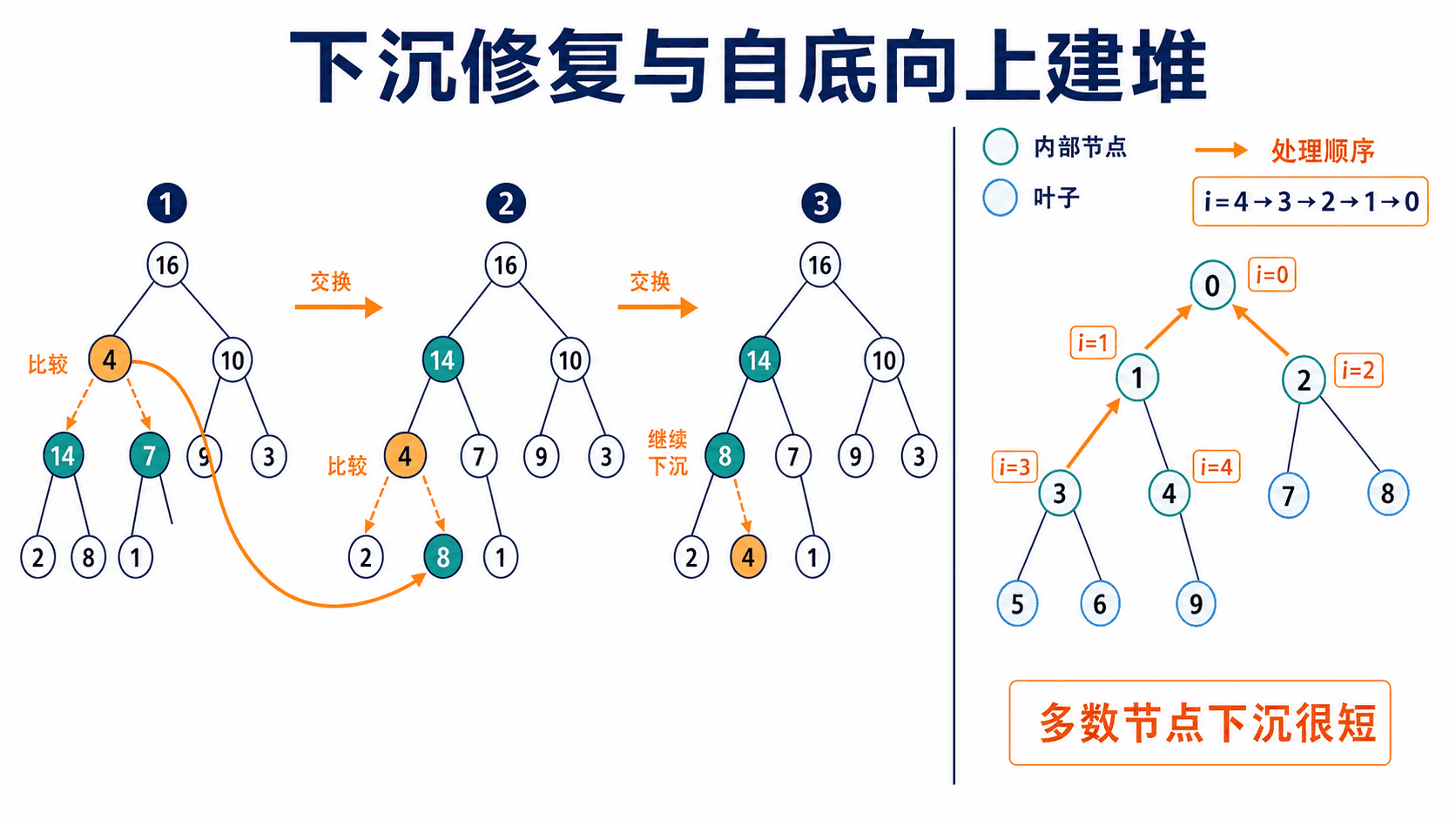
下沉修复:只处理一处局部违规
设节点 i 的左右子树都已经是最大堆,但 a[i] 可能小于某个孩子。修复时比较父节点和两个孩子,把三者中的最大值换到父节点。如果发生交换,原来的父节点落到下一层,新的违规只可能出现在它落下的位置,于是继续向下检查。
js
function siftDown(a, i, heapSize) {
while (true) {
const left = 2 * i + 1;
const right = left + 1;
let largest = i;
if (left < heapSize && a[left] > a[largest]) largest = left;
这里必须与“较大的孩子”交换。若只要发现左孩子更大就立刻交换,右孩子可能比交换后的父节点还大,根部仍然违规。
以 [16,4,10,14,7,9,3,2,8,1] 为例,从索引 1 修复。真实运行记录是:
text
i=1,比较 4、14、7,4 与 14 交换
i=3,比较 4、2、8,4 与 8 交换
i=8,没有孩子,停止
结果:[16,14,10,8,7,9,3,2,4,1]正确性可以按每轮循环来理解:循环开始时,除了当前节点可能小于孩子外,它的两棵孩子子树都是最大堆。把三者最大值放到当前节点后,当前根满足堆序;若原值下沉,只有新位置需要继续修复。算法每轮至少下降一层,最终在堆序已满足或到达叶子时终止。
完全二叉树的高度为 ,下沉每层只做常数次比较和一次交换,因此:
2
siftDown(a, i, heapSize) 正确工作的前提有哪些?
自底向上建堆为什么是线性的
无序数组并不满足下沉修复的前提。解决办法是倒着处理内部节点:叶子天然是堆;处理某个内部节点时,它的孩子位置更靠后,已经被处理过,所以两棵孩子子树都是堆。
js
function buildMaxHeap(a) {
for (let i = Math.floor(a.length / 2) - 1; i >= 0; i--) {
siftDown(a, i, a.length);
}
}对 [4,1,3,2,16,9,10,14,8,7] 运行后,各轮状态为:
text
i=4 [4,1,3,2,16,9,10,14,8,7]
i=3 [4,1,3,14,16,9,10,2,8,7]
i=2 [4,1,10,14,16,9,3,2,8,7]
i=1 [4,16,10,14,7,9,3,2,8,1]
i=0 [16,14,10,8,7,9,3,2,4,1]循环不变式是:准备处理索引 i 时,所有索引大于 i 的节点都是某棵最大堆的根。一次 siftDown 让 i 也成为最大堆的根。循环结束时索引 0 是整棵树的根,于是整个数组成为最大堆。
为什么不是紧确答案
“约有 个内部节点,每次下沉 ”确实给出一个上界,却把所有节点都当成了根。实际情况是,越靠近底层的节点越多,但它们能下沉的距离越短。
高度为 的节点数量至多约为 ,每个这样的节点最多下沉 层,因此总成本满足:
去掉取整带来的低阶项后:
而级数满足:
所以自底向上建堆的紧确数量级是 。这不是说每个节点只花常数时间,而是大量低节点的短路径摊薄了少数高节点的长路径。
3
因为 siftDown 最坏为 O(log n),所以 buildMaxHeap 的紧确时间必然是 Θ(n log n)。
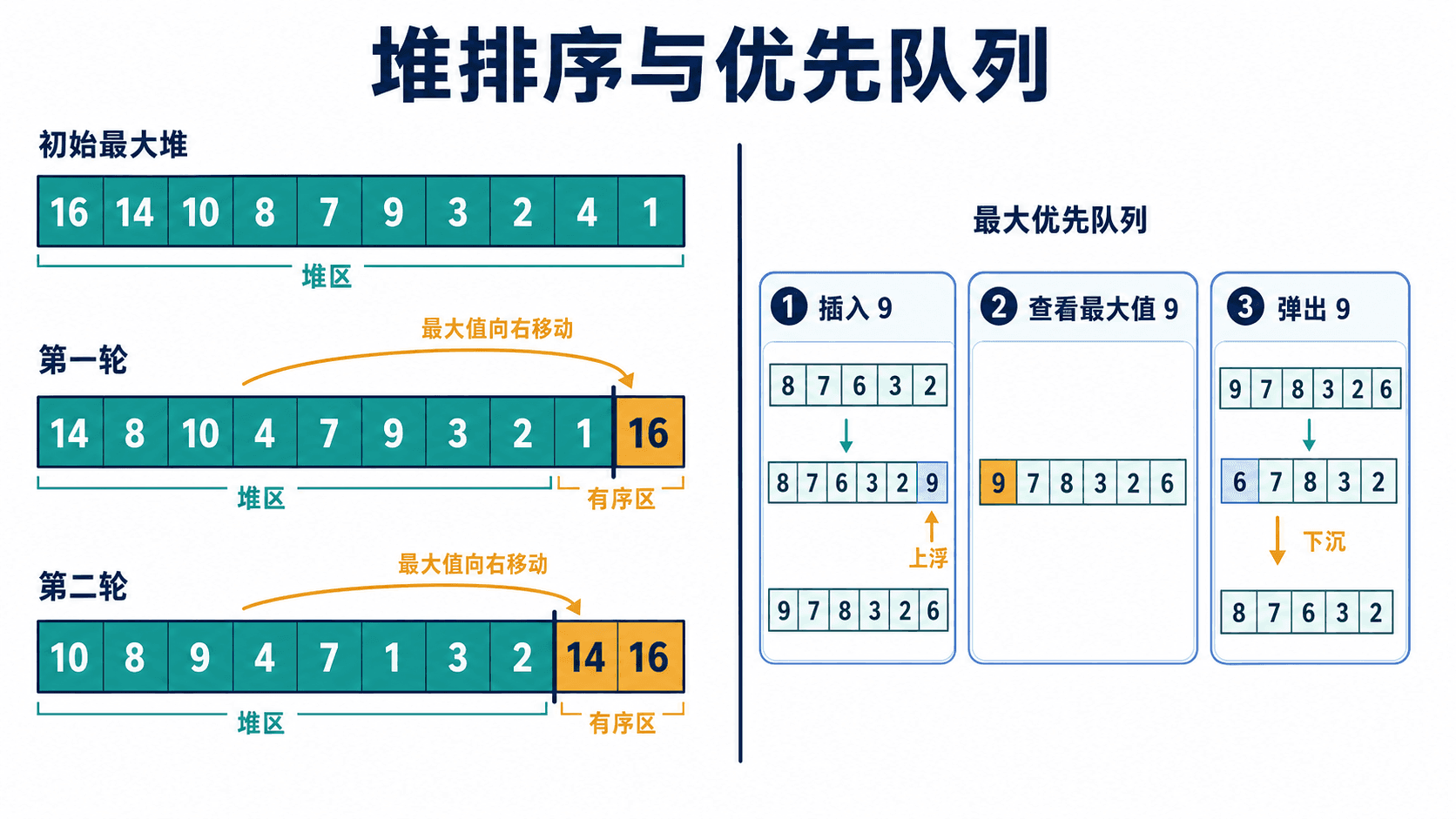
排序阶段:堆区缩小,有序区增长
最大堆只能保证根是最大值,并没有把整个数组排好。要得到升序结果,可以把根与堆区末尾交换。最大值从此固定在末尾;随后把堆区长度减一,再修复新根。
js
function heapSort(a) {
buildMaxHeap(a);
for (let end = a.length - 1; end > 0; end--) {
[a[0], a[end]] = [a[end], a[0]];
siftDown(a, 0, end);
}
return a;
}
对同一示例数组执行排序,真实输出为:
text
第 1 轮:堆区 [14,8,10,4,7,9,3,2,1];有序区 [16]
第 2 轮:堆区 [10,8,9,4,7,1,3,2];有序区 [14,16]
第 3 轮:堆区 [9,8,3,4,7,1,2];有序区 [10,14,16]
最终结果:[1,2,3,4,7,8,9,10,14,16]排序循环的不变式包含两部分:进入每一轮时,a[0..end] 是最大堆;a[end+1..n-1] 已按升序就位,并且其中每个值都不小于堆区中的值。根尾交换把当前最大值放入正确位置,下沉则恢复缩小后堆区的最大堆性质。end 变为 0 时,每个位置都已经确定。
建堆为 。排序阶段执行 轮,每轮修复最多花 ,总时间为:
即便输入已经有序,根尾交换与堆区维护仍需进行;对互异元素可得到 的下界。因此通常把堆排序的时间写成 。
迭代版下沉只在原数组中交换元素,额外空间为 。但它不是稳定排序:远距离的根尾交换可能颠倒相等键的原有次序。
4
最大堆做升序堆排序时,根与堆尾交换后首先应做什么?
从排序原语到优先队列
堆排序一次处理完整数组;优先队列则维护一个持续变化的集合。最大优先队列通常支持四类操作:
extractMax() 与堆排序的一轮很相似:保存根,用末尾元素补到根,缩短数组,再向下修复。插入则走相反方向:先把新元素放到末尾,再与父节点比较,只要它更大就持续上浮。
js
class MaxPriorityQueue {
constructor() {
this.heap = [];
}
maximum() {
if (this.heap.length === 0) throw new Error('priority queue is empty');
return this.heap[0];
}
insert(value) {
this.heap.push(value);
依次插入 4,1,7,3,9,2,真实运行结果如下:
text
插入后堆数组:[9,7,4,1,3,2]
maximum():9
extractMax():9
删除后堆数组:[7,3,4,1,2]任务调度适合最大优先队列:优先级越高越先处理。事件模拟、最短路等场景更常用最小优先队列:时间戳或暂定距离越小越先处理。选择最大堆还是最小堆,取决于“谁应最先出队”,并不取决于数据本身是正数还是负数。
5
哪些场景适合使用优先队列,而不是每次把全部数据重新排序?
常见误区与实现检查
把堆当作二叉搜索树
最大堆只保证祖先不小于后代。一个较小值可能出现在左子树,也可能出现在右子树。除根之外,查找某个任意键在最坏情况下仍可能检查 个元素。
混用 0 基与 1 基公式
0 基索引的左孩子是 2*i+1,1 基索引的左孩子是 2*i。如果数组是 0 基却使用 1 基公式,根的左孩子会错误地指回根本身,循环可能停滞或漏节点。
忘记区分数组长度和堆区长度
堆排序后半段已经就位,不能再参与下沉。siftDown 必须接收 heapSize,边界判断也必须使用它,而不是始终使用 a.length。
错把建堆写成逐个插入
逐个插入也能得到堆,但最坏成本是 。如果数据已经完整地放在数组中,自底向上的 buildMaxHeap 才能利用底层节点多、下沉距离短的结构,做到 。
忽略空队列与非法改键
对空优先队列取最大值应明确抛错或返回约定的空值。increaseKey(i, k) 还必须确认 k 不小于旧键;若键变小,应向下修复而不是向上修复。
6
最大堆中第二大元素一定是根的左孩子。
综合练习与解析
练习一:手动建堆
对数组 [3,9,2,1,4,5] 使用 0 基索引执行自底向上建堆,写出最终数组。
练习二:定位边界错误
下面代码试图进行一轮堆排序。说明错误并修正。
js
[a[0], a[end]] = [a[end], a[0]];
siftDown(a, 0, a.length);练习三:复杂度组合
现有 个任务,先用自底向上方法建最大堆,然后执行 次 extractMax()。给出总时间复杂度。
7
总时间复杂度是 ____。
练习四:选择数据结构
一个模拟器会不断产生带时间戳的事件,并总要先处理时间戳最小的事件。应使用哪种堆?
8
最合适的数据结构是什么?
完成这些练习后,可以用三个问题自检:父子索引是否统一,堆区边界是否正确,下沉或上浮的方向是否与键值变化一致。堆相关实现的大多数错误,都能在这三处找到。