快速排序:把一次划分变成完整排序
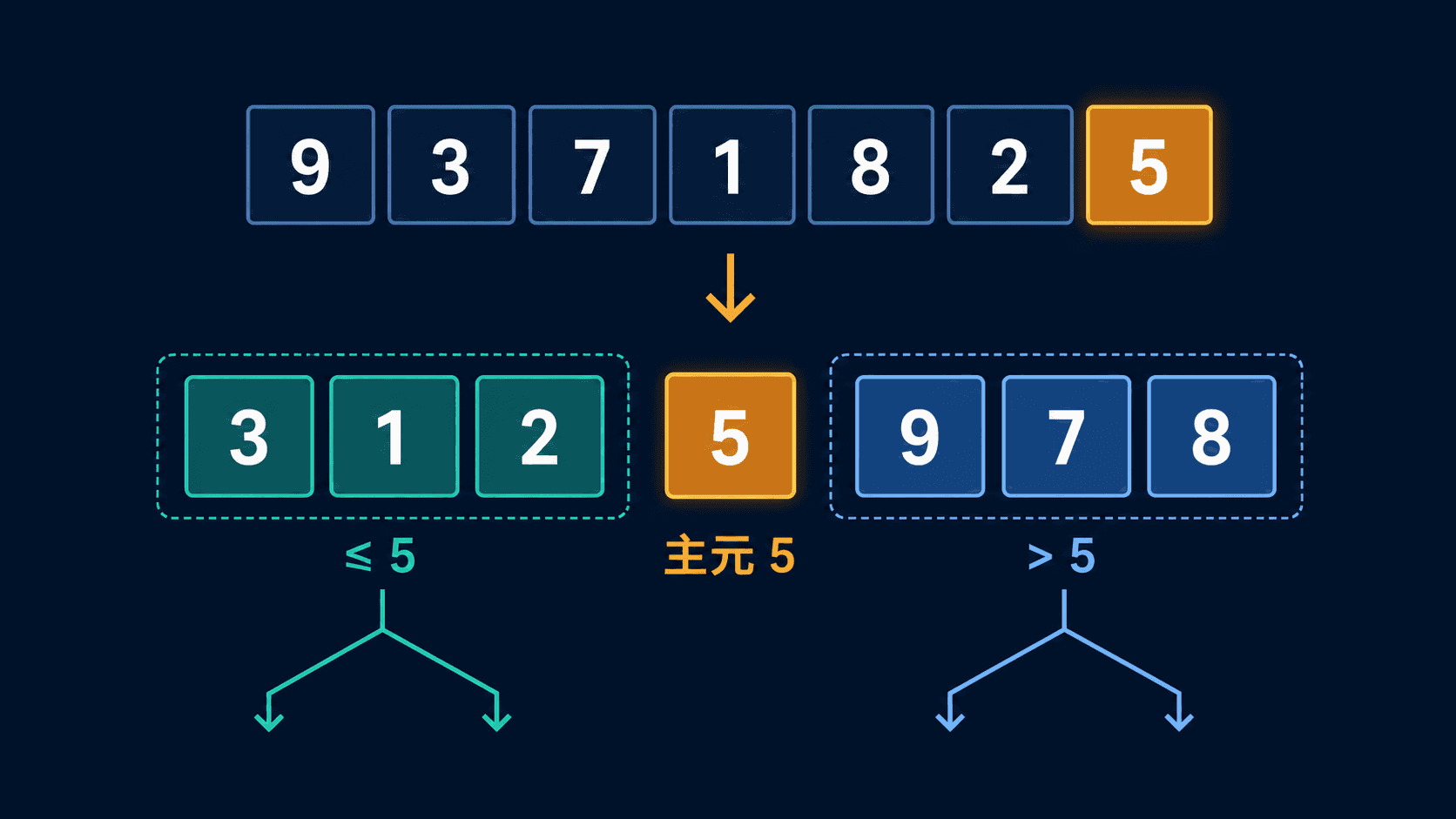
有一批待处理任务,优先级是 [9, 3, 7, 1, 8, 2, 5]。如果只想先找到优先级 5 的位置,不必立刻排好全部元素:把小于等于 5 的任务移到左边,把更大的移到右边,5 就落在最终位置。左右两段再做同样的事,整个序列便会有序。
这就是快速排序的核心。它的代码不长,行为却取决于三个细节:分区是否正确、主元是否经常把问题切得太偏、重复值是否被反复处理。本章从一个可验证的分区开始,再推到正确性、复杂度、随机化与三路分区。
快速排序通常是原地排序,但交换会改变相同键元素的先后次序,因此通常不稳定。若业务要求相同键保持原顺序,需要选择稳定排序,或把原始下标加入比较键。
从一次分区到递归排序
设当前处理闭区间 a[lo..hi]。选择一个主元后,分区需要建立如下关系:
这里的 q 是主元的最终位置。左段和右段分别排好后,不需要额外合并,因为任意左段元素都不大于主元,任意右段元素都大于主元。
python
def quicksort(a, lo, hi):
if lo >= hi:
return
q = lomuto_partition(a, lo, hi)
quicksort(a, lo, q - 1)
quicksort(a, q + 1, hi)递归终止条件 lo >= hi 覆盖空区间和单元素区间。分区返回后不再递归 q,因此两个子问题都严格缩小。
在
[9, 3, 7, 1, 8, 2, 5] 中选择末元素 5 为主元。扫描其余元素,把
3、1、2 收进左区;其余元素留在右区。将主元放到两区之间,得到
[3, 1, 2, 5, 8, 7, 9],此时 5 的下标 3 已经确定。递归处理
[3, 1, 2] 和 [8, 7, 9],最终得到完整有序序列。1
一次 Lomuto 分区返回 q 后,哪两个区间仍需递归?
Lomuto 分区与循环不变式
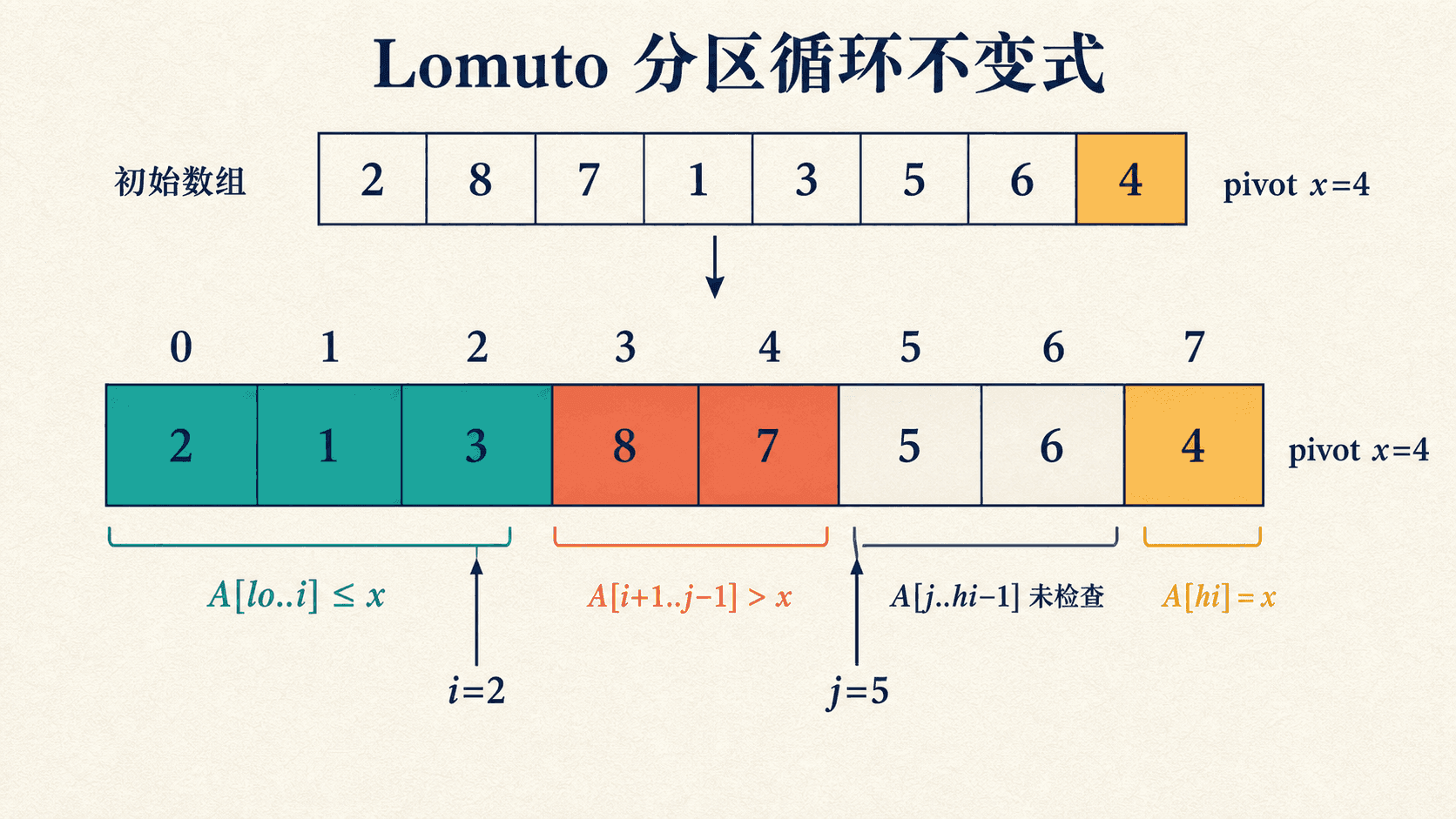
Lomuto 分区选末元素为主元 x,用 i 标记小值区的末端,用 j 扫描尚未归类的元素。
python
def lomuto_partition(a, lo, hi):
x = a[hi]
i = lo - 1
for j in range(lo, hi):
if a[j] <= x:
i += 1
a[i], a[j] = a[j], a[i]
a[i + 1], a[hi] = a[hi], a[i + 1]
return i + 1每轮扫描开始时,数组分为四段:
为什么它正确
初始化。 第一次循环前 i=lo-1、j=lo,前两个已分类区间都是空集;主元仍在 hi,不变式成立。
保持。 若 a[j] > x,只让 j 右移,大值区扩张一格。若 a[j] <= x,先右移 i,再交换 a[i] 与 a[j],小值进入小值区,被换出的元素进入大值区。不论哪种情况,下一轮开始时不变式仍成立。
终止。 当 j=hi,除主元外的元素都已分类。交换 a[i+1] 与主元后,主元左侧全部不大于它,右侧全部大于它,返回位置满足分区后置条件。
实际执行一次分区:
console
input = [9, 3, 7, 1, 8, 2, 5]
q = 3
output = [3, 1, 2, 5, 8, 7, 9]2
当扫描到 a[j] > pivot 时,应当同时右移 i 和 j。
Hoare 分区为何有另一套边界
Lomuto 每次扫描一个元素,写法直观,但可能进行较多交换。Hoare 分区让指针从两端相向移动:左指针停在大于等于主元的位置,右指针停在小于等于主元的位置;若两者尚未交错,就交换这对“站错边”的元素。
python
def hoare_partition(a, lo, hi):
x = a[lo]
i, j = lo - 1, hi + 1
while True:
j -= 1
while a[j] > x:
j -= 1
i += 1
while a[i] < x:
i += 1
if i >= j:
return j
a[i], a[j] = a[j], a[i]它返回的是切分点 j,并不承诺主元已经位于 j。正确递归边界因此是:
python
def quicksort_hoare(a, lo, hi):
if lo >= hi:
return
split = hoare_partition(a, lo, hi)
quicksort_hoare(a, lo, split)
quicksort_hoare(a, split + 1, hi)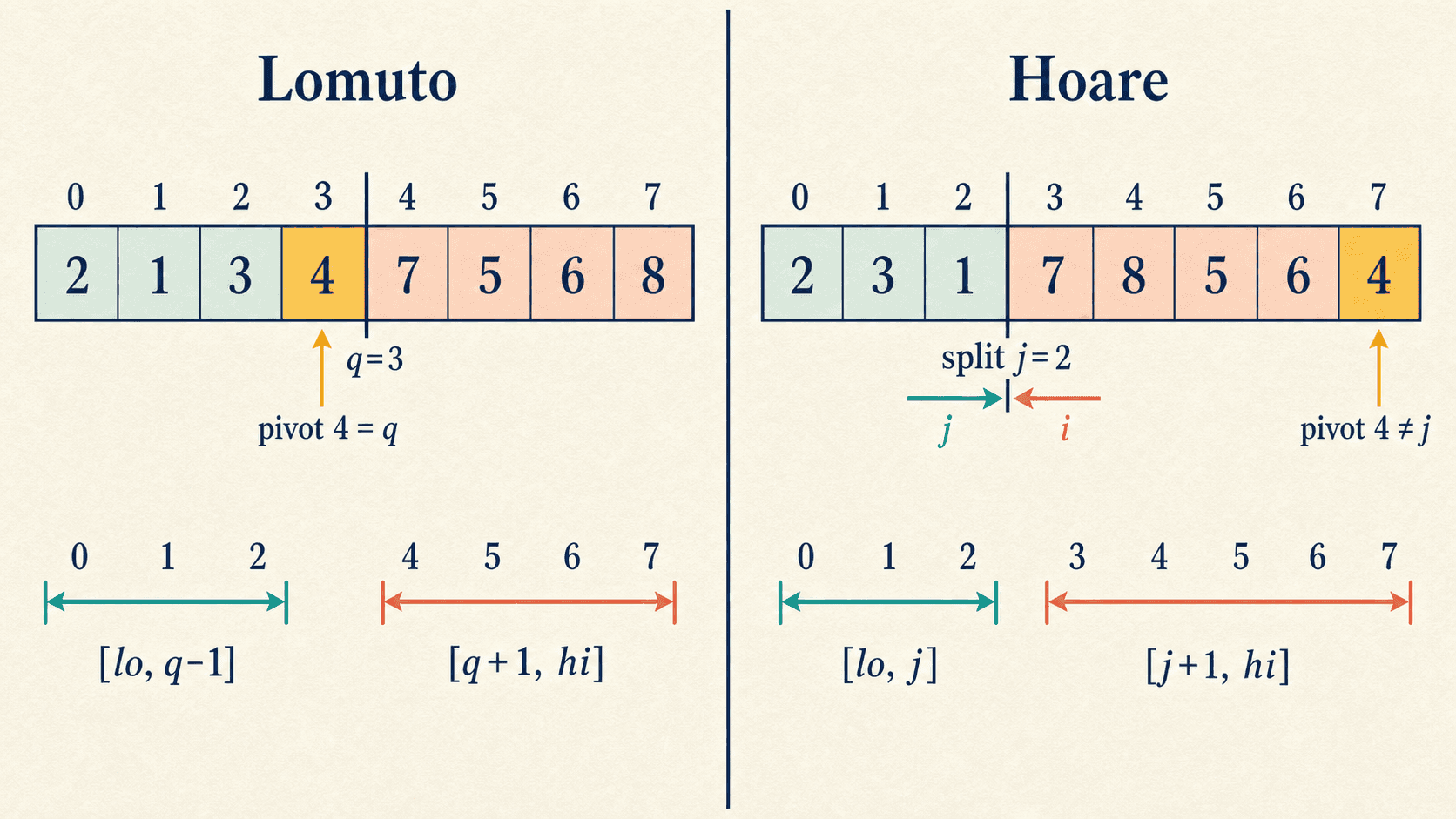
不要把 Hoare 返回的 split 套进 Lomuto 的 q-1、q+1 模板。前者只是左右区间的边界,主元可能仍在某个子区间中;混用边界会漏排元素,也可能让递归区间无法缩小。
两种分区的后置条件可这样区分:
3
Hoare 分区返回 split=4 时,正确的递归区间是哪一组?
递归树决定时间复杂度
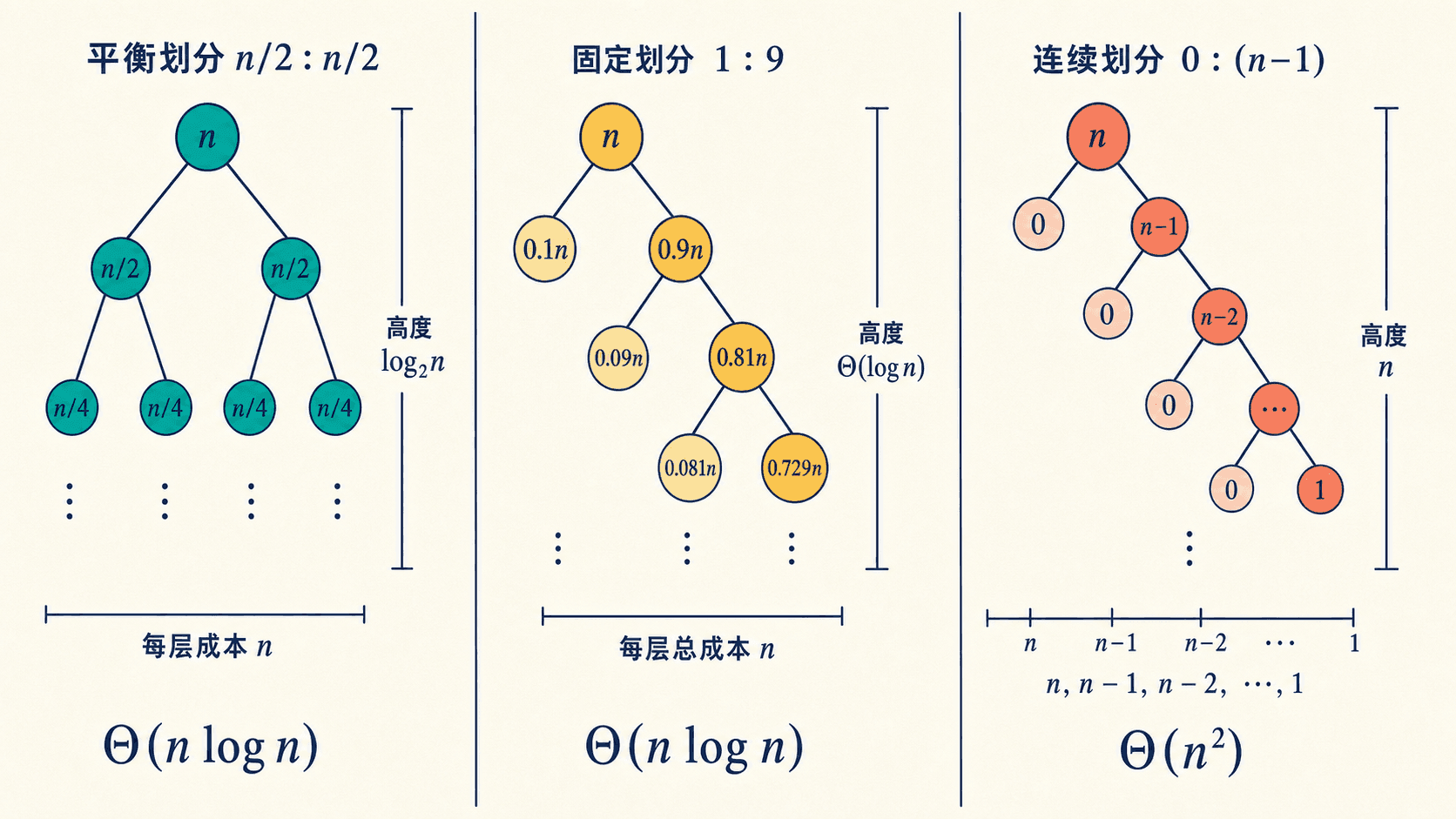
长度为 n 的一次分区会线性扫描当前区间,成本为 。总时间取决于每次分区产生的两段有多大。
平衡划分
若两段规模都接近一半:
递归树约有 层,每层全部子问题的长度之和不超过 。
连续偏斜划分
若每次都切出空段和长度 n-1 的段:
展开得到:
固定选择末元素为主元时,已经升序、降序或全部相等的输入都可能触发这种形状。
不必追求每次正好对半
如果每次都按固定常数比例切分,例如 1:9,较长路径的深度仍是 ,每层总工作仍是 ,所以总时间仍是 。真正危险的是较小一侧长期只有常数个元素。
真实执行固定末元素主元的实现:
console
n=20, sorted input
comparisons = 190
max_depth = 19
n=20, balanced-pivot sample
comparisons = 63
max_depth = 54
若每次分区都稳定产生 1:9 的规模比例,渐进时间复杂度是什么?
随机主元把输入顺序移出方程
固定选首元素或末元素时,输入顺序可以直接决定递归树。更稳妥的做法是在当前区间等概率选一个主元,再把它交换到末端并复用 Lomuto 分区。
python
from random import randrange
def randomized_partition(a, lo, hi):
k = randrange(lo, hi + 1)
a[k], a[hi] = a[hi], a[k]
return lomuto_partition(a, lo, hi)随机化并没有删除 的最坏递归树。它改变的是触发方式:同一个固定输入不再稳定对应同一棵坏树,性能分析转向随机选择的期望。
为什么期望是 Θ(n log n)
假设元素互不相同,排序后记为 。任意一对 最多比较一次,因为元素只会在其中一个被选为主元时比较;主元分区完成后不会再进入后续子问题。
两者会比较,当且仅当集合
中最先被选为主元的是端点 或 。每个元素等概率最先被选中,因此
令 为总比较次数,利用期望的线性性:
精确到常用形式,互异元素的期望比较次数为:
当 n=20 时,该式给出 71.105... 次比较。
5
随机化快速排序保证每次运行都在 O(n log n) 时间内结束。
重复值需要三路分区
若数组只有少量不同键,普通 Lomuto 的 <= pivot 会把等值元素全部推到一侧。所有元素相等时,每次只能确定一个主元位置,仍会产生长度 n-1 的子问题。
三路分区同时维护四个区域:
python
def quicksort_three_way(a, lo, hi):
if lo >= hi:
return
x = a[lo]
lt, i, gt = lo, lo + 1, hi
while i <= gt:
if a[i] < x:
a[lt], a[i] = a[i], a[lt]
lt += 1
i += 1
elif a[i] > x:
a[i], a[gt] = a[gt], a[i]
gt -= 1
else:
i += 1
quicksort_three_way(a, lo, lt - 1)
quicksort_three_way(a, gt + 1, hi)当 a[i] > x 时,右端换来的元素尚未检查,所以只左移 gt,不能立即右移 i。循环结束后,中间整个等值段都已就位,递归只处理严格小于和严格大于的两段。
对固定样例 [0,1,2,0,1,2,0,1,2,0,1,2,0,1,2,0,1,2,0,1],真实执行结果为:
console
two-way comparisons = 76
three-way comparisons = 37
two-way max depth = 7
three-way max depth = 36
三路分区在 a[i] > pivot 时,哪些动作是正确的?
把递归栈控制在对数级
随机化改善期望时间,却不能阻止一次具体运行产生很深的递归栈。解决办法是每次只递归较短的一侧,用循环继续处理较长的一侧。
python
def quicksort_stack_safe(a, lo, hi):
while lo < hi:
q = lomuto_partition(a, lo, hi)
if q - lo < hi - q:
quicksort_stack_safe(a, lo, q - 1)
lo = q + 1
else:
quicksort_stack_safe(a, q + 1, hi)
hi = q - 1被递归处理的短边长度至多是当前区间的一半。因此每多压入一层栈,问题规模至少减半,最坏同时驻留的栈帧数为 。循环处理长边不会增加调用栈。
工程实现还常加入两项策略:小区间改用插入排序,降低递归和分区的固定开销;递归深度超过阈值时切换到有最坏界保证的排序,防止极端输入拖到平方级。三数取中等取样策略能改善常见输入上的主元质量,但不能单独证明最坏时间为 。
7
若每次递归都只进入较短子数组,最坏调用栈深度是 ____。
一套可执行的选择准则
选择分区方案时,先看数据而不是只看代码长度:
快速排序是否“不稳定”,与采用哪种主元策略无关。只要分区通过跨距离交换移动相同键元素,就可能改变它们的相对次序。例如记录 [(2,A),(1,B),(2,C),(1,D)] 按第一项排序后,两个键为 2 的记录可能从 A,C 变成 C,A。
8
数组包含一百万条状态记录,但状态值只有 5 种。优先考虑哪种方案?
综合练习与解析
练习一:手算分区
对 [6, 2, 9, 4, 7, 3, 5] 执行一次 Lomuto 分区,主元是末元素 5。写出返回下标和分区后的数组。
练习二:找出边界错误
某实现调用 split = hoare_partition(a, lo, hi) 后递归 [lo, split-1] 与 [split+1, hi]。说明问题并修正。
练习三:证明对数栈深度
说明“递归短边、循环长边”为什么不依赖分区是否平衡,也能保证最坏 栈深度。
练习四:从概率到期望
对于秩分别为 i<j 的两个互异元素,解释它们的比较概率为什么是 ,再说明为什么把所有元素对的概率相加合法。
掌握快速排序的检查顺序是:先写清分区后置条件,再核对递归边界;随后用递归树判断时间,用重复值分布判断是否需要三路分区,最后再加随机主元与栈深度保护。