链表:把逻辑顺序交给指针
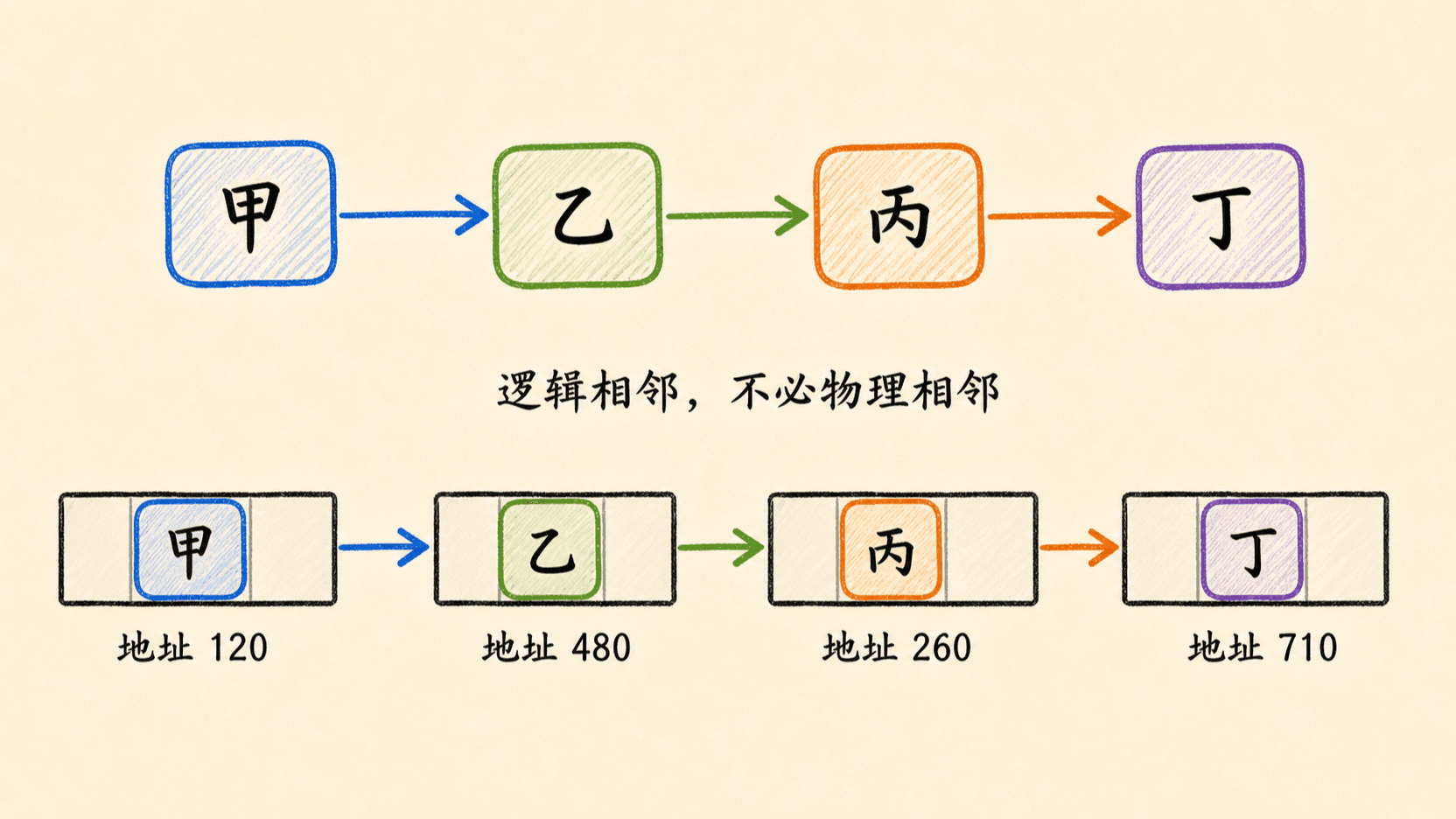
数组用连续下标表达顺序,链表则把“下一个是谁”写进节点。节点可以散落在不同内存位置,只要链接关系正确,从头节点出发仍能得到一条确定的线性序列。
这个差别会改变我们分析操作的方式。数组擅长按下标直接定位;链表擅长在已知连接位置时改动局部链接。链表并不会让“查找某个值”自动变快,也不会让所有插入、删除都变成常数时间。真正决定成本的是:操作开始时,我们手里有什么指针,还需要走多少个节点。
下面默认键值可以重复,查找返回从头开始遇到的第一个匹配节点。伪代码里的 NIL 表示空指针;C++ 示例使用 nullptr。时间复杂度中的 表示当前链表节点数。
链接如何定义一条线性序列
一个链表节点至少保存数据和一个链接。单向链表节点只记录后继:
text
节点 x = (key, next)若 x.next 指向 y,那么 y 是 x 的后继。头指针 head 是进入整条链的入口;head == NIL 表示空表;非循环链表的尾节点满足 tail.next == NIL。
双向链表再给每个节点增加一个前驱链接:
text
节点 x = (prev, key, next)非循环双向链表中,头节点的 prev 为 NIL,尾节点的 next 为 NIL。从任意节点向前或向后走一步都很方便,但每次插入、删除也必须同时维护两个方向。只改其中一个方向,正向遍历或许暂时看不出问题,反向遍历却会进入旧节点或断链。
四个相互独立的分类维度
“单向”和“循环”并不是互斥概念。描述一条链表时,最好把下面几件事分开说:
- 链接方向:单向链表只有
next;双向链表还有prev。 - 边界形态:非循环链表用
NIL结束;循环链表让尾与头相接。 - 键值顺序:有序链表让节点顺序与键值顺序一致;无序链表允许任意排列。
- 边界表示:可以直接保存
head,也可以放置一个不承载业务数据的哨兵节点。
有序链表仍然不支持随机访问。即使目标键比当前键小,可以提前停止搜索,最坏情况下仍要走完整条链。循环链表也没有天然的“末尾空指针”,遍历必须用“再次回到起点”、计数器或哨兵来终止。
链接表达的是逻辑顺序,不保证节点地址递增,也不保证相邻节点落在同一缓存行。遍历链表时只能沿当前节点保存的链接前进,不能用“节点地址加一”猜下一个节点。
交互实验:沿着链接查找
选择目标键并逐步前进。实验会区分“当前检查的节点”“下一跳”和“未找到时到达空指针”。
小测
1
非循环双向链表中,哪个条件能说明节点 x 是尾节点?
2
下列哪些说法准确描述了链表?
单向链表的操作从入口开始
单向链表只有前进方向。查找、按位置访问以及按值删除,都要从 head 出发逐步走到目标附近。
查找与遍历
查找第一个键值为 k 的节点:
text
SEARCH(head, k)
x = head
while x != NIL and x.key != k
x = x.next
return x空表会直接返回 NIL。若目标不存在,算法检查全部 个节点后返回 NIL;若目标位于尾部,也要进行 次比较。因此最坏时间是 。最好情况是头节点命中,耗时 。
头插为什么是常数时间
新节点 x 插到表头只需两个动作:
text
x.next = head
head = x这两个动作的顺序不能颠倒。若先执行 head = x,再写 x.next = head,x 会指向自己,原链表入口随之丢失。空表不需要单独分支,因为原 head 恰好是 NIL。
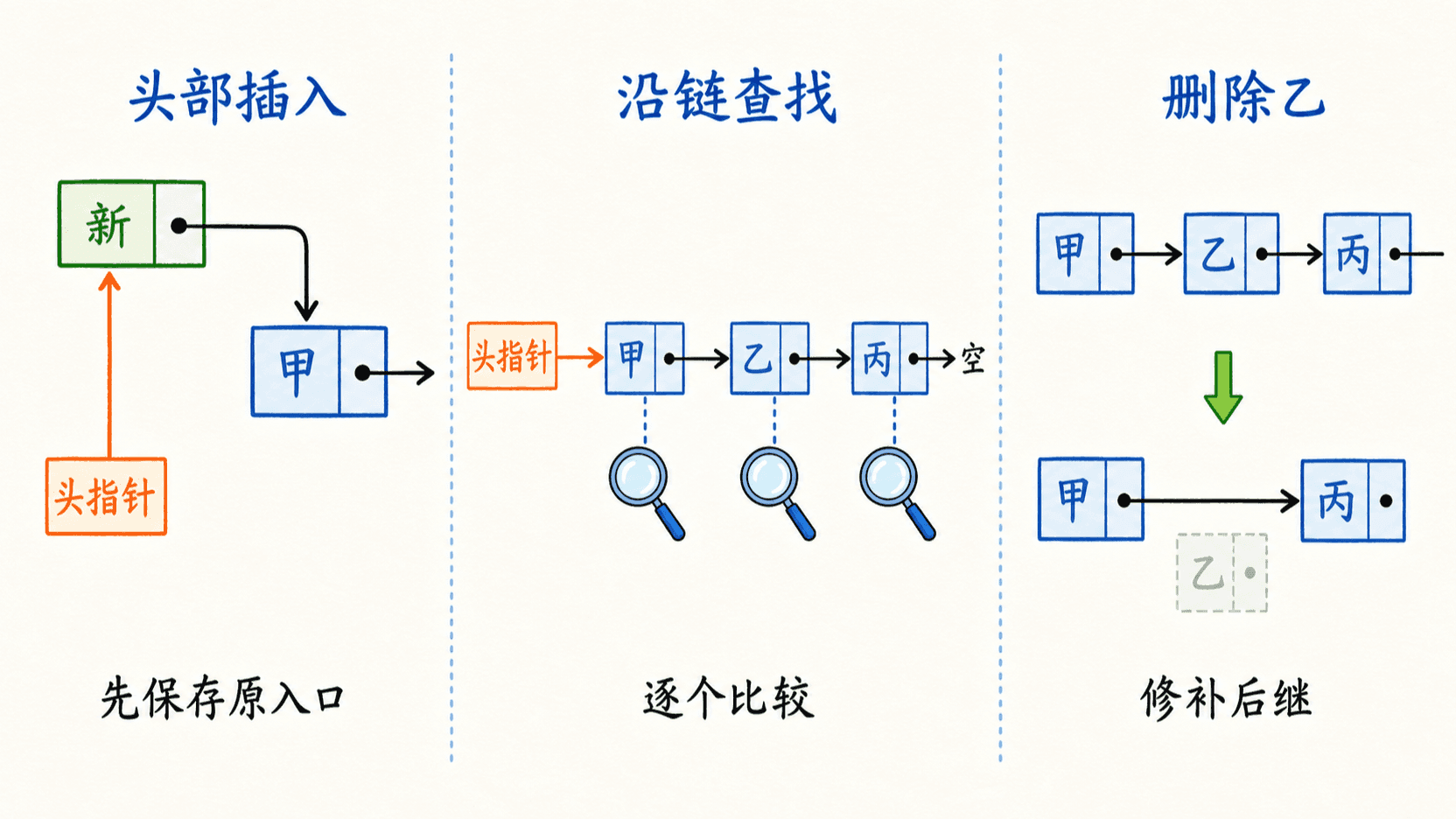
删除要先区分“按节点”与“按值”
已知待删除节点 x,不代表单向链表能立刻删除它。要把 x 从链中摘除,通常还需要它的前驱 prev:
text
若 x == head:
head = head.next
否则:
prev.next = x.next
释放 x所以有两种常见接口:
eraseAfter(prev)已经拿到前驱,只改常数个链接,耗时 ;eraseValue(k)先寻找目标及其前驱,最坏耗时 。
删除头节点时没有前驱,必须更新 head。删除尾节点时,前驱的 next 要改成 NIL;若另外维护 tail,还要把 tail 更新为前驱。只有一个节点时,删除后 head 和 tail 都应为空。
一份可运行的单向链表实现
下面的实现同时维护 head_ 与 tail_。这样头插、尾插都是 ;按值删除仍要搜索。
cpp
#include <cstddef>
#include <iostream>
#include <utility>
template <class T>
class SinglyLinkedList {
private:
struct Node {
T value;
Node* next;
explicit Node(const T& v) : value(v), next(nullptr) {}
};
Node*
反转时要先保存 cur->next,再改写它。否则从当前节点通向剩余链表的唯一入口会被覆盖。整个反转访问每个节点一次,时间为 ,额外空间为 。
用单向链表实现栈时,把表头当作栈顶,压栈和弹栈都是 。实现队列时同时维护头、尾指针:尾部入队、头部出队也都是 。出队删掉最后一个节点后,别忘了同时清空尾指针。
小测
3
一个单向链表只保存 head。若要删除第一个键值为 k 的节点,最坏时间复杂度是多少?
4
单向链表头插时,应先令 head 指向新节点,再令新节点的 next 指向 head。
双向链表把前驱写进节点
双向链表多保存一个 prev,换来从已知节点直接访问前驱的能力。查找依然是线性的,但已经拿到节点指针后,插入和删除不再需要从头寻找前驱。
插入表头要维护四处关系
把新节点 x 插到无哨兵双向链表表头:
text
x.next = head
if head != NIL
head.prev = x
head = x
x.prev = NIL第二行只在旧表非空时执行。若链表同时保存 tail,空表插入后还要令 tail = x。每一行只读写固定数量的指针,所以操作是 。
已知节点时删除只需修补邻居
删除节点 x 时,前驱若存在,就让前驱越过 x 指向后继;否则 x 是头节点,需要移动入口。后继同理:
text
if x.prev != NIL
x.prev.next = x.next
else
head = x.next
if x.next != NIL
x.next.prev = x.prev
else
tail = x.prev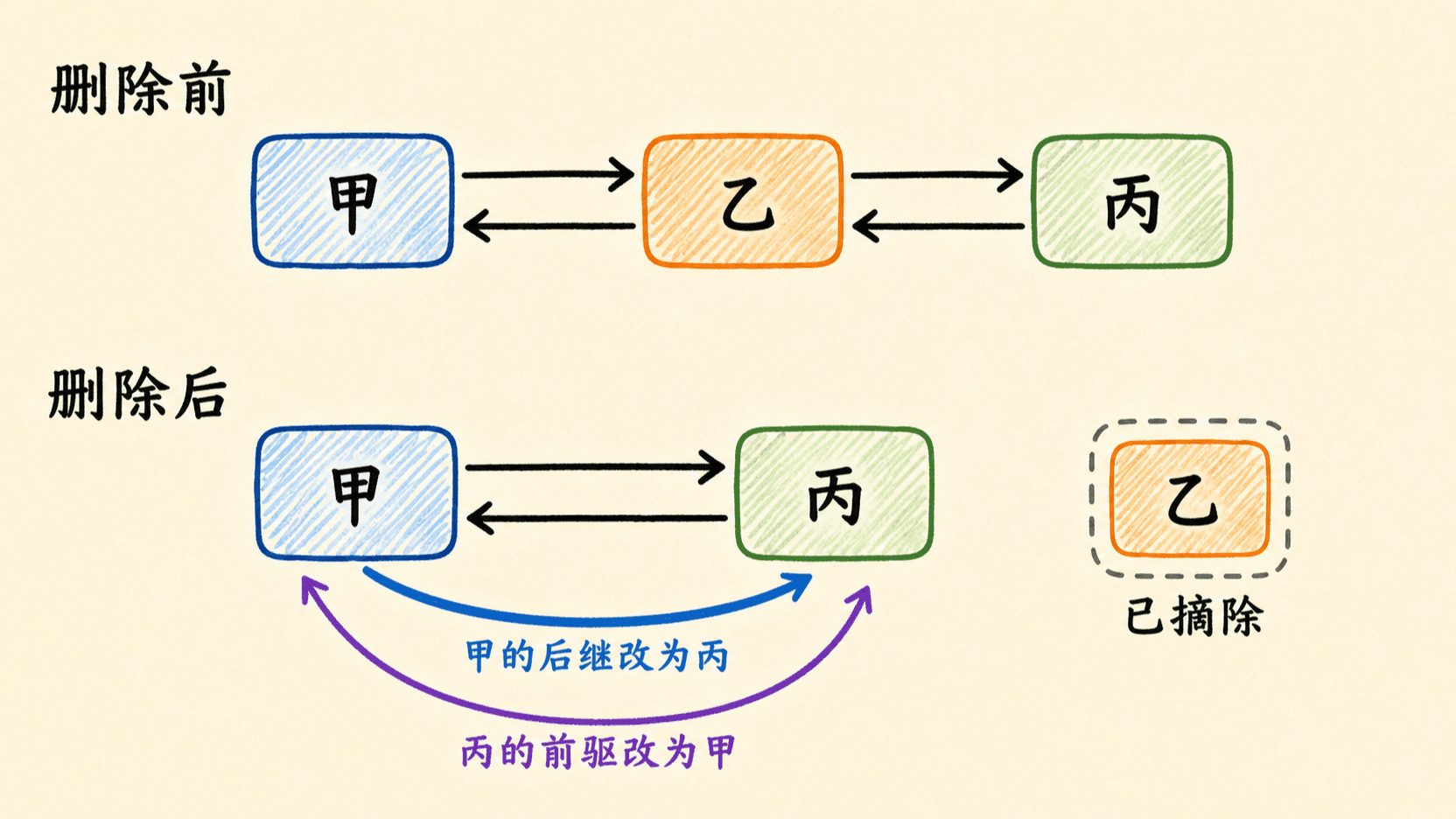
这里的 有明确前提:调用者已经给出属于该链表的有效节点 x。如果接口收到的只是键值,仍要先做最坏 的搜索。若 x 已经释放、属于另一条链或是边界哨兵,直接改指针都会破坏结构;健壮的公开接口应通过迭代器归属、句柄代数或调试断言限制这些非法输入。
哨兵把边界变成普通链接
无哨兵实现之所以有多个分支,是因为头节点没有前驱,尾节点没有后继。可以加入一个不保存业务数据的哨兵 nil,并把双向链表首尾接成环:
nil.next指向头节点;nil.prev指向尾节点;- 头节点的
prev与尾节点的next都指向nil; - 空表满足
nil.next == &nil且nil.prev == &nil。
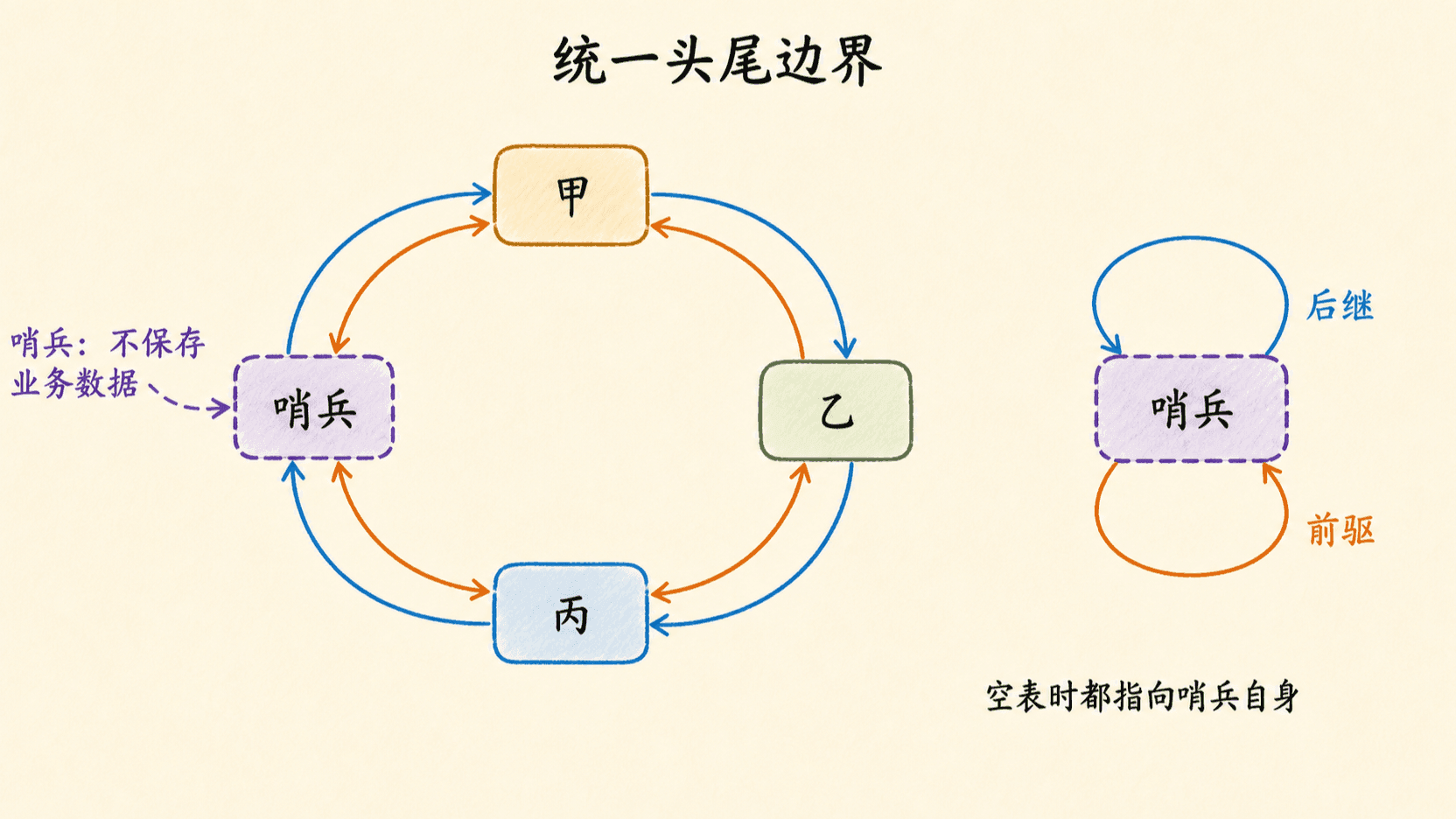
此时删除普通节点只剩两行:
text
x.prev.next = x.next
x.next.prev = x.prev在表头插入也无需为空表单独分支:
text
x.next = nil.next
nil.next.prev = x
nil.next = x
x.prev = nil哨兵没有改变渐近复杂度。它用每条链一个额外节点,换来较少的边界分支和更统一的不变量。若系统中有大量极短链表,这个固定空间开销可能不可忽略。
查找时仍可同时检查“是否回到哨兵”和“键值是否匹配”。若特别在意循环内分支,还可以暂时把目标键写入哨兵,循环只比较键值;最终停在哨兵就表示未找到。这个技巧会临时修改共享状态,并不适合未经同步的并发查找。多数实现保留两个清楚的条件更容易维护。
交互实验:删除时到底改哪两条链接
选择一个业务节点并执行删除。你可以先看无哨兵版本的边界分支,再切换到哨兵版本观察统一的两次修补。
小测
5
无哨兵双向链表删除已知节点 x 时,哪些情况需要额外更新链表对象保存的边界指针?
6
带哨兵的空循环双向链表中,nil.next 与 nil.prev 都指向 ____。
循环链表需要明确停止规则
循环链表把边界空指针替换为回环链接。单向循环链表通常令尾节点的 next 指向头节点;循环双向链表还令头节点的 prev 指向尾节点。
这个结构适合反复轮转的任务,例如轮流处理等待项。处理完当前节点后直接移动到 current.next,不必在尾部跳回头部。它也适合拼接:如果两条单向循环链表都保存尾指针,交换两个尾节点的 next 就能在 时间把两个环接成一个环。
遍历不能再等待空指针
从头遍历一圈可以这样写:
text
if head != NIL
x = head
do
VISIT(x)
x = x.next
while x != head这里必须使用 do...while 或等价逻辑,确保头节点至少访问一次。若写成“只要 x != head 就继续”,第一次检查就会退出。若链接被破坏后再也回不到 head,循环会永久运行,因此生产代码常在调试模式同时检查节点计数上限。
头尾指针决定两端操作的成本
只保存 head 的单向循环链表,要找尾节点仍需走 步。只保存 tail 则更方便,因为头节点始终是 tail->next:
- 表头插入:把新节点插在
tail与tail->next之间,; - 表尾插入:先按表头插入,再把
tail移到新节点,; - 删除表头:改写
tail->next,; - 删除唯一节点:把
tail设为空,不能让它继续指向已释放内存。
“循环”本身不会让搜索变快。按值查找仍可能检查整整一圈,最坏是 。
何时不值得使用循环结构
若业务天然存在明确终点,非循环链表的 NIL 往往更容易调试。循环结构要求每段遍历代码都遵守停止协议;忘记停止条件的后果不是普通的越界,而是死循环。带哨兵的循环双向链表通常比“直接让头尾相接”的版本更统一,因为哨兵同时提供稳定起点和终止标记。
不要用“遇到重复键值”判断是否绕了一圈。链表允许键值重复,业务数据不能充当结构边界。应比较节点身份、哨兵地址或受维护的节点数量。
小测
7
单向循环链表没有 NIL 结尾,因此按值查找的最坏时间会从 Θ(n) 降为 O(1)。
8
单向循环链表只保存 tail 指针时,头节点由哪个表达式得到?
数组下标也能承担指针职责
链式结构需要的是“位置标识”,不一定非要使用语言提供的裸指针。若对象放在固定容量的数组池中,可以用数组下标表示节点位置。
多数组表示把同一下标拼成对象
准备三个等长数组 key、next、prev。下标 i 同时选择三个字段:
text
节点 i = (key[i], next[i], prev[i])若 next[5] = 2,就表示第 5 号节点的后继是第 2 号节点。链表入口 L 保存头节点下标。NIL 可以取一个不可能成为合法槽位的整数,例如数组合法下标是 0..m-1 时使用 -1。
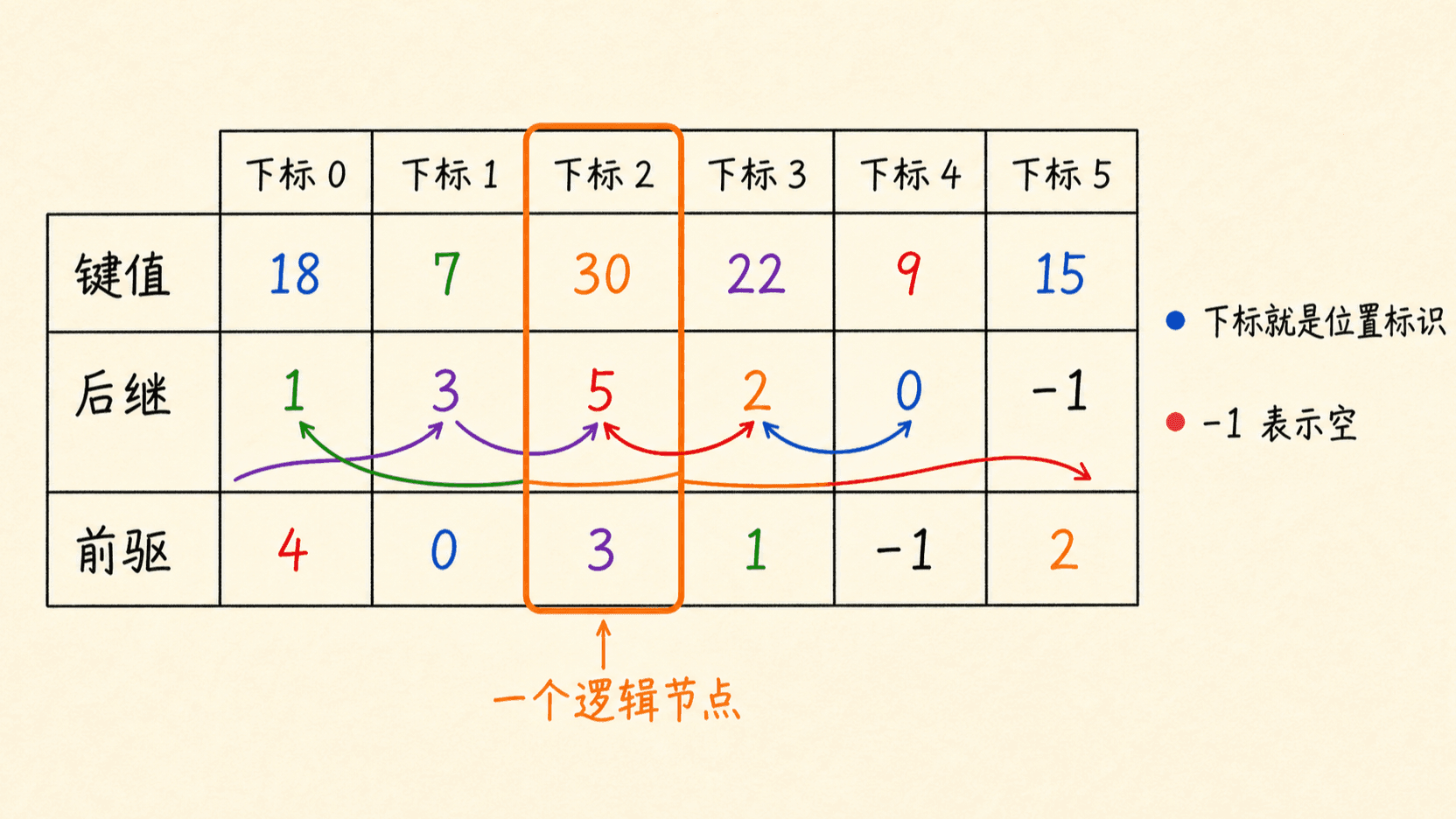
这种布局把同一字段连续放置,适合批量扫描某个字段。代价是读取一个完整节点时要访问多个数组,而且所有字段数组必须保持相同容量与槽位状态。
单数组表示使用起始位置与字段偏移
也可以让一个节点占单数组中的连续三个槽位。若 p 是节点起始下标,偏移 0、1、2 分别保存键值、后继和前驱:
这与“对象地址加字段偏移”是同一个思路。定长、同构对象容易管理;若不同对象占用长度不同,还要处理大小记录、对齐和碎片,分配器会复杂许多。
空闲链表管理未使用槽位
容量为 的池中,活跃链表占用 个槽位,其余 个槽位可以串成一条单向空闲链表。freeHead 保存空闲链表表头,空闲槽位暂时复用 next 字段。
text
ALLOCATE()
if freeHead == NIL
报告“对象池已满”
x = freeHead
freeHead = next[x]
return x
FREE(x)
next[x] = freeHead
freeHead = x分配相当于空闲栈弹出,归还相当于压入,二者都是 。同一个槽位在任一时刻必须恰好属于活跃结构或空闲链表,不能同时属于两者。FREE 前应先从活跃链表摘除节点;ALLOCATE 后应在对外可见前初始化键值和业务链接。
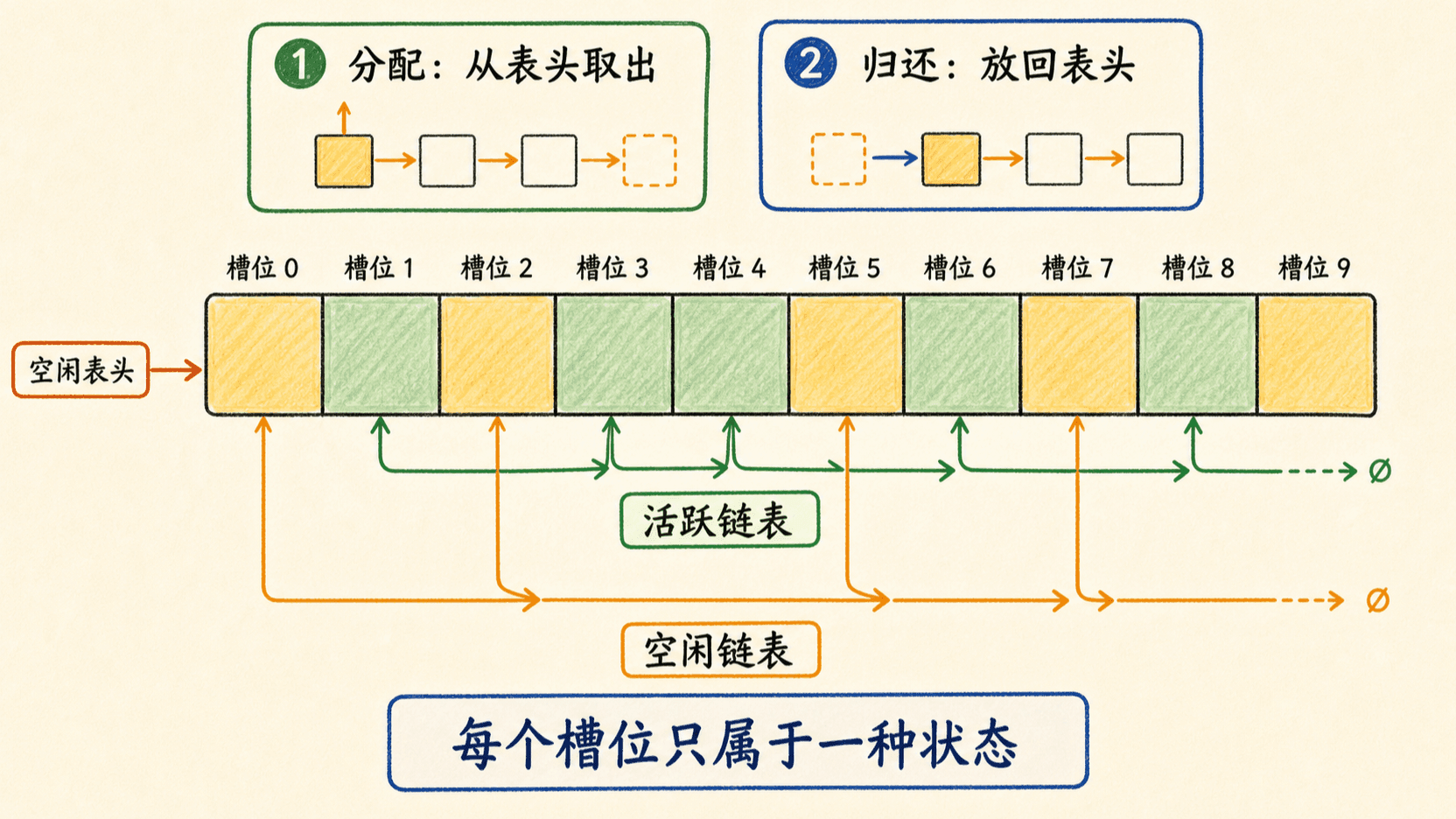
多个活跃链表可以共享同一条空闲链表。key 和 prev 在槽位空闲时无需清零,因为空闲链表只读取 next;但重新分配后必须在使用前覆盖所有会被读取的字段。若系统允许外部长期保存槽位下标,还应加入“代数”或版本号,避免槽位释放后被复用,旧下标悄悄指向新对象。
交互实验:分配与归还对象槽位
点击“分配”会从空闲链表表头取一个槽位,点击活跃槽位可以把它归还。观察 next 字段如何在两种角色之间复用。
小测
9
多数组表示中,指针值 5 通常表示什么?
10
使用空闲链表管理固定容量对象池时,下列哪些说法正确?
链表还能表示不相交集合
链表除了保存普通序列,也能表示一组互不重叠的集合。每个集合有一个集合对象,保存:
head:成员链表的第一个节点;tail:成员链表的最后一个节点;size:成员数量。
每个成员节点保存成员值、next,以及反向指向所属集合对象的 set。链表内的成员顺序可以任意,头节点中的成员就是该集合的代表元。
建立集合与查询代表元
MAKE_SET(x) 创建只含 x 的集合,令集合对象的头尾都指向 x,size = 1,并让 x.set 指回该集合对象。所需字段固定,所以是 。
FIND_SET(x) 沿 x.set 到集合对象,再读取 head 中的成员,也只需 。这项速度依赖反向指针;如果成员只保存 next,就无法从任意成员直接定位集合对象。
简单合并的昂贵部分不是接链
合并集合 与 时,可以用 S_x.tail.next = S_y.head 在 时间接上两条链,并更新尾指针。问题在于, 的每个成员原来都指向集合对象 ,现在必须逐个把 改为 。
因此,若把 接到 后面,一次合并的成本是 。若反复把越来越长的链追加到单节点链后面,更新量可能是:
接链是常数时间,不代表保持全部数据不变量也是常数时间。
加权合并让每个成员少搬几次
保存集合大小后,每次都把较短链表追加到较长链表,并只更新短链成员的 set。平局时任选一边。
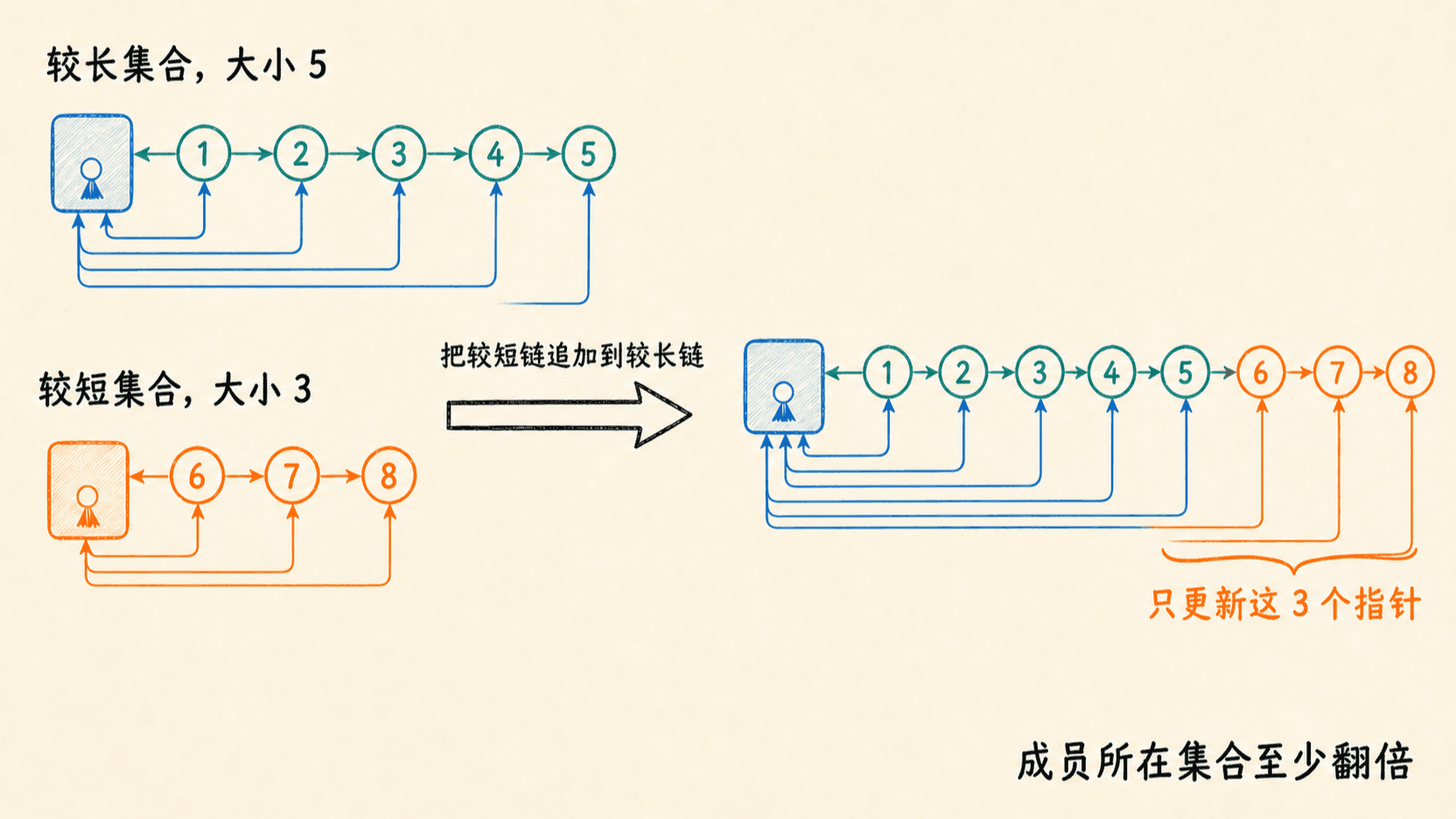
观察某个成员 x。每次 x.set 被更新,x 原先一定在较小集合中。合并后它所在集合的大小至少翻倍:
集合最多有 个成员,所以同一成员的反向指针至多更新 次。全部成员在所有合并中的更新总量是 。
若一段操作序列共有 次 MAKE_SET、FIND_SET 与 UNION,其中有 次建立单元素集合,那么总时间为:
这个结论是序列总成本。单次加权合并仍可能更新接近 个成员,耗时 ;只是同一成员不可能反复落在较短一侧太多次。
加权合并伪代码
text
UNION(x, y)
A = x.set
B = y.set
if A == B
return A
if A.size < B.size
交换 A 与 B
A.tail.next = B.head
p = B.head
while p != NIL
p.set = A
p = p.next
A.tail = B.tail
A.size = A.size + B.size
销毁集合对象 B
return A同集合合并要立即返回,否则可能把一条链接到自身并制造环。若集合为空不被允许,head 和 tail 始终有效;若接口允许空集合,就要额外定义代表元和合并语义。
小测
11
链表表示不相交集合时,简单 UNION 的主要线性成本来自哪里?
12
采用按大小加权合并后,每一次 UNION 的最坏时间都变为 O(log n)。
正确实现依赖清晰的不变量
链表代码短,但错误往往不会在出错位置立刻出现。一次漏改 prev 可能等到反向遍历才暴露;一个悬空 tail 可能在下次尾插时才写入已释放内存。比起记住几段模板,更可靠的做法是先写不变量,再让每个操作恢复这些不变量。
一份实用的不变量清单
对非循环双向链表,可以检查:
- 空表时
head == NIL且tail == NIL; - 非空时
head.prev == NIL且tail.next == NIL; - 对每条
x.next = y,都有y.prev = x; - 从
head沿next恰好访问size个节点并到达NIL; - 从
tail沿prev也恰好访问同一批节点。
对带哨兵的循环双向链表,边界条件改成:
- 空表时
nil.next == nil且nil.prev == nil; - 非空时
nil.next.prev == nil且nil.prev.next == nil; - 沿任一方向走
size + 1步会回到哨兵。
调试构建中可以在每次修改后遍历验证,虽然检查本身是 ,但能把结构损坏定位到最早的操作。正式构建再关闭这类全表断言。
先看定位成本,再看修改成本
下面的复杂度都假设单次字段读写为常数时间:
“中间插入是 ”这句话必须带上定位前提:若已经持有插入位置或相邻节点,它成立;若输入只是下标或键值,找到位置仍是 。
资源所有权要与链接分开考虑
手动管理内存时,摘链和释放是两个动作。应先修补结构,使任何活跃链接都不再指向目标节点,再释放它。遍历释放整表时,要先保存下一个节点,随后才能删除当前节点。
若链表拥有节点,复制链表不能只复制 head 指针,否则两个对象会共享同一批节点并重复释放。可以实现深拷贝与移动语义,也可以像上面的 C++ 示例一样显式禁用复制。实际项目中,优先使用标准容器或智能指针明确所有权;只有在确实需要稳定节点地址、侵入式链接或定制内存池时,再维护自定义链表。
特殊压缩表示要权衡可维护性
理论上,双向链表可以只存一个 next XOR prev 字段。遍历时只要同时知道当前节点和上一个节点,就能异或恢复下一个节点;交换“头”和“尾”甚至能在 时间改变遍历方向。
这种表示节省一个指针,却失去了普通指针的可读性,调试器难以直接展开,语言的内存安全规则也常不允许把指针随意当整数异或。它适合帮助我们理解“表示法可以压缩”,不应在没有明确空间压力和平台保证时贸然使用。
分析链表操作时,可以固定问三句话:入口在哪里?目标是否已经定位?操作结束后哪些正向、反向和边界链接必须成立?这三问能同时回答复杂度与正确性。
小测
13
维护 head、tail、size 的非循环双向链表删除唯一节点后,哪些状态必须成立?
14
没有额外索引时,链表按下标访问第 i 个节点的最坏时间复杂度是 ____。