深层神经网络
从两层网络走到深层网络,最容易产生的错觉是:层数变多以后,我们需要重新学一套数学。其实核心动作没有变。每一层仍然先做线性变换,再做非线性激活;训练时仍然从损失出发,沿计算图反向使用链式法则。
真正变难的是管理。你需要让所有层共用一套符号,随时说清矩阵 shape;前向传播要保存反向传播稍后会用到的量;初始化还得让信号和梯度穿过多层后不至于迅速变小或变大。只要这几本账能对上, 层网络就是可检查、可实现的工程对象,而不是一团嵌套公式。
这一章沿用前面二分类任务的设定:样本按列排列,隐藏层使用 ReLU,输出层使用 Sigmoid,损失使用二元交叉熵。我们会先把两层网络推广为任意深度,再写出模块化 NumPy 实现,最后用训练曲线和验证曲线判断模型到底卡在哪里。
用一套符号描述任意深度
设网络有 个带参数的计算层。输入只负责承载数据,所以记为第 层,不计入 。如果网络有三个隐藏层和一个输出层,那么 ,而不是 5。
令第 层的单元数为 ,一个批次有 个样本。统一记号如下:
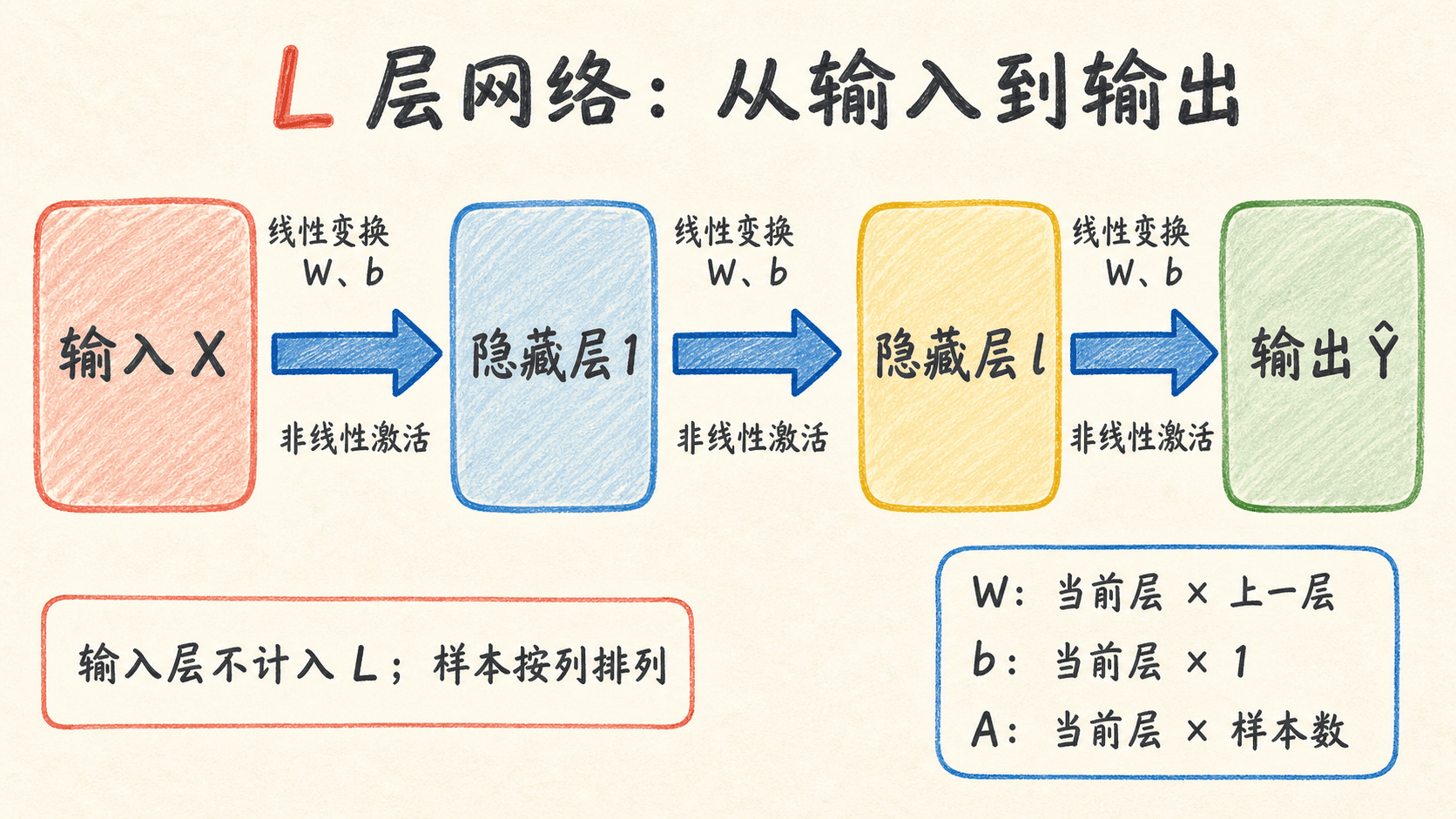
对任意一层,计算都能写成同一个模板:
上标方括号表示“层”,不是幂。比如 是第 3 层的权重,并不是 的三次方。这个区别看起来小,手写推导时却很容易混。
把各层宽度收进列表会更方便。layer_dims = [5, 8, 4, 1] 表示输入有 5 个特征,两个隐藏层分别有 8 个和 4 个单元,输出维度是 1。列表长度是 4,但带参数的层数是 3:
不同教材对“几层网络”的口径可能不同。这里始终只数带参数的层,输入层不计数。阅读别人的代码时不要先争层数名称,先看 从哪里连到哪里,再看作者怎样定义 。
1
layer_dims = [6, 10, 4, 1] 时,按本章约定 L 等于多少?
2
W[2] 的行数等于第 2 层单元数,列数等于第 1 层单元数。
一个批次怎样逐层向前
单样本推导通常把激活写成列向量。真正训练时,我们把 个样本并排放进矩阵,每次矩阵乘法同时处理整个批次:
偏置 只有一列。NumPy 在相加时把这列偏置广播到 个样本,因此结果仍是 。概念上可以把它看成每个样本都加同一份偏置;实现时不需要手工复制 份。
假设某层输入 的 shape 是 ,该层有 8 个单元,那么 是 , 是 ,最后的 和 都是 。
先看目标层有多少个单元。这里是 8,所以输出必须有 8 行,权重也必须有 8 行。
再看上一层输出有多少行。这里是 5,所以权重需要 5 列,才能与输入的 5 行完成矩阵乘法。
最后保留批次轴。32 个样本一直放在列上,线性变换不会改变样本数,所以输出有 32 列。
在二分类网络中,常见安排是前 层用 ReLU,最后一层用 Sigmoid:
最后一行的每个值都落在 0 到 1 之间,可以解释为对应样本属于正类的预测概率。若任务改为多分类,输出层和损失会换成 Softmax 与多类交叉熵,但隐藏层循环的结构不变。
shape 检查要盯住两条轴:行表示当前表示的维度,列表示批次里的样本。层与层之间通常改变行数,不改变列数。只要某一层突然把 放到第一维,后续公式即使侥幸能广播,也很可能已经算错。
3
A[l-1] 的 shape 为 (7, 64),W[l] 的 shape 为 (12, 7),则 Z[l] 的 shape 是 ____。
4
在样本按列排列的前提下,下列说法哪些正确?
缓存让反向传播有据可查
前向传播不只要产出预测,还要给反向传播留下“计算凭证”。以一层为例,反向公式会用到 、 和 :
- 用来计算 ;
- 用来把梯度传回 ;
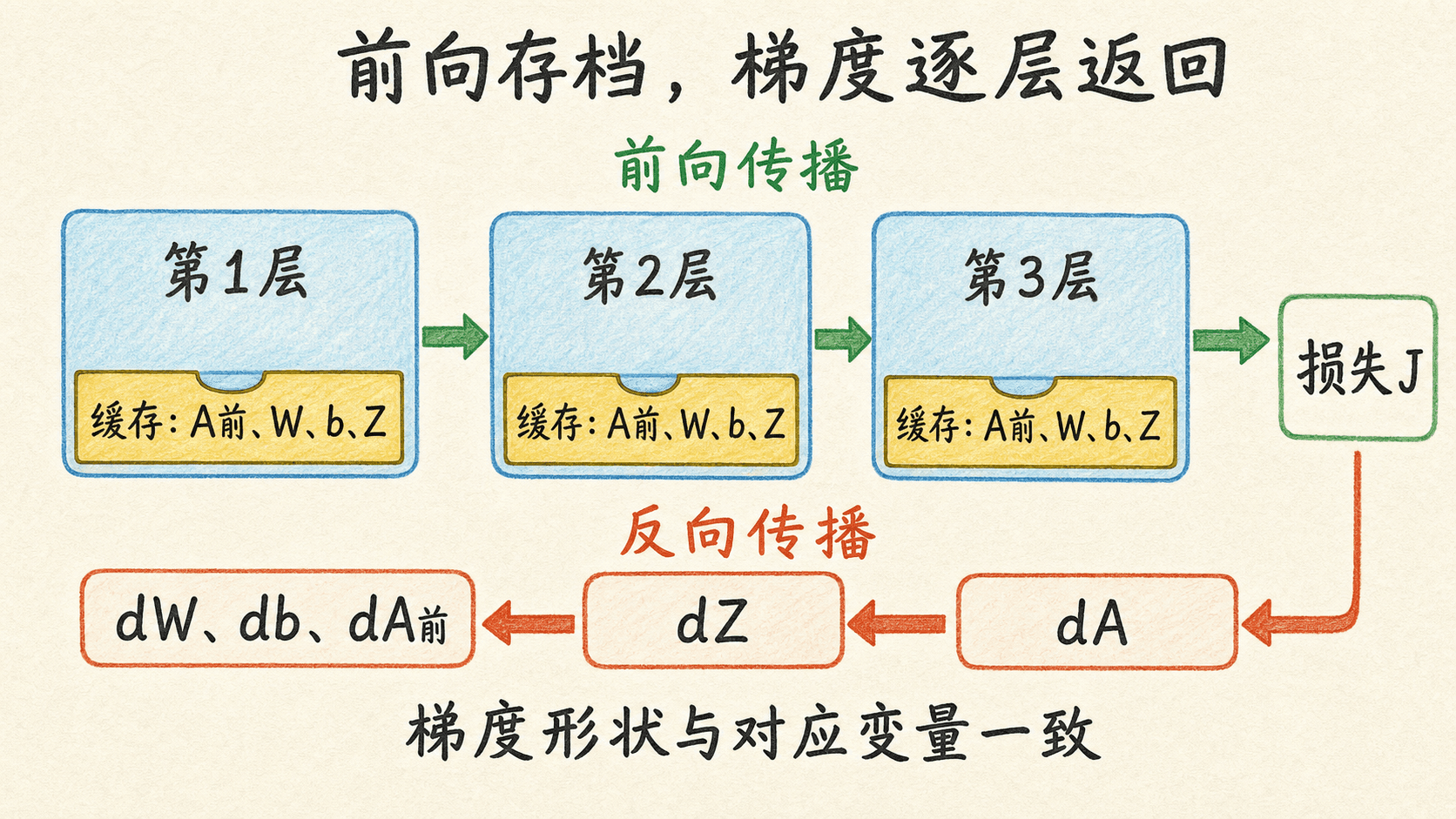
因此可以让每一层的前向函数同时返回激活值和缓存:
python
def linear_activation_forward(A_prev, W, b, activation):
Z = W @ A_prev + b
A = relu(Z) if activation == "relu" else sigmoid(Z)
cache = (A_prev, W, b, Z, activation)
return A, cache所有层的缓存按前向顺序放进列表。反向传播再从列表末尾往前读取。这样做有两个直接好处:每个函数只处理一层;一旦某层 shape 错了,可以在层边界立刻发现,而不是等到整个训练循环报出一个难以定位的矩阵乘法错误。
缓存不是越多越好。教学实现直接保存 A_prev、W、b、Z,逻辑最清楚。成熟框架会考虑内存复用、重计算或自动微分图的生命周期。我们的目标是先把依赖关系写对,再讨论怎样省内存。
不要在前向传播后原地改写缓存引用的数组。反向传播假设缓存与产生当前预测时的参数和激活一致。如果两者来自不同版本,得到的梯度就不再对应当前损失。
5
为什么 ReLU 层的缓存通常要保留 Z[l]?
6
每层的 dW 和 db 必须在前向传播时提前算好并放进缓存。
梯度怎样沿链式法则返回
反向传播可以理解成对前向计算逐层“倒放”。假设第 层已经收到上游梯度 ,先穿过激活函数:
符号 表示逐元素相乘。然后穿过线性变换:
这三条式子的 shape 会自动和对应变量对齐:
对 ReLU,局部导数是一个掩码: 的位置导数为 1,其余位置为 0。对二元交叉熵与 Sigmoid 的组合,输出层有一个很干净的合并结果:
这条式子已经把损失对输出的导数和 Sigmoid 的导数合在一起。实现时直接使用它,比先算含除法的 再乘 Sigmoid 导数更简洁,也更不容易在概率接近 0 或 1 时制造数值问题。
每算出一个梯度就和原变量对 shape:dW.shape == W.shape、db.shape == b.shape、dA_prev.shape == A_prev.shape。这不是多余的防御代码,而是手写反向传播时成本最低的单元测试。
还要分清“梯度平均”放在哪里。上面的损失定义为批次平均,所以 和 带 。我们没有在 上再次除以 ,否则同一份平均因子会被重复计算。
7
若 dZ[l] 为 (9, 32),A[l-1] 为 (5, 32),则 dW[l] 的 shape 是 ____。
8
关于二分类网络的反向传播,下列说法哪些正确?
先估参数量,再谈网络大小
深层网络有多大,可以先从每层的权重和偏置数起算。第 层参数量为:
全网参数量为:
例如 layer_dims = [4, 6, 3, 1]:第一层有 个参数,第二层有 个,输出层有 个,总计 55 个。
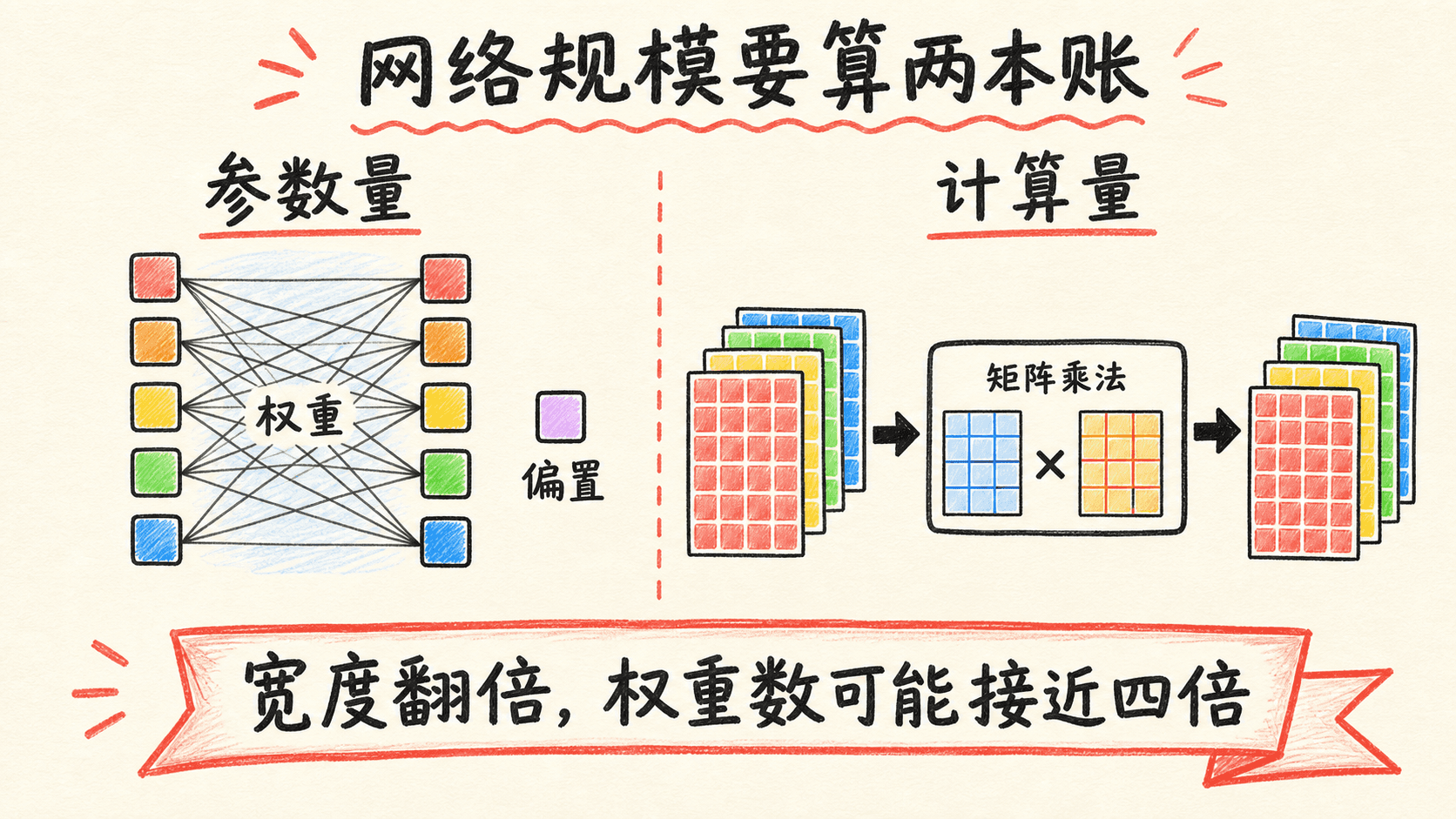
全连接层的主要计算来自矩阵乘法。只看前向传播,一个批次的主项与下式同阶:
若把一次乘法和一次加法分别计作一次浮点运算,常会在前面写近似系数 2;不同工具的 FLOPs 口径并不完全相同,所以比较模型时先确认计数规则。反向传播还要计算参数梯度和输入梯度,通常也是同一数量级,而不是“免费附送”。
内存则至少包括参数,以及为反向传播保留的激活和缓存。批次增大时,参数量不变,但激活内存大致随 增长。于是“大批次放不下”不一定是参数太多,也可能是中间激活占了主要空间。
网络宽度翻倍时,连接两个同宽隐藏层的权重数会接近变成四倍,因为权重矩阵的行和列都翻倍。只盯着“单元数翻倍”容易低估参数和计算的增长。
9
layer_dims = [4, 6, 3, 1] 的全网参数总数(含偏置)是 ____。
10
固定网络结构后,把批次大小 m 翻倍会把模型参数量也翻倍。
深度的价值在于多级组合
单隐藏层网络在合适条件下可以逼近很广的一类函数,但“能够逼近”没有告诉我们需要多少单元,也没有保证优化容易。深层网络提供的是另一种函数组织方式:让后一层复用前一层已经算出的中间表示,再继续组合。
如果目标本身有组合结构,这种多级复用可能很省。比如先计算若干局部模式,再把局部模式组合为更大的模式;前面的结果被多个后续单元共享,不必在一层里为每种大组合从头重复全部计算。Deep Learning Book 也用函数复合来定义前馈网络的深度。
这件事有严格但有限定范围的理论结果。Telgarsky 的深度分离结果构造了某些函数族:较深网络能用较少节点表示,而深度受限的网络若想近似它们,宽度可能需要指数增长。这里的关键词是“存在某些函数”,不能把它改写成“任何任务上越深都越省参数”。
深度也有成本。层越多,优化路径越长,梯度尺度更难控制,缓存和计算也会增加。如果数据很少、目标关系简单,较浅模型可能更容易训练,也足够完成任务。网络深度应由任务结构、验证表现和资源限制共同决定。
万能逼近定理不是“一个隐藏层永远优于深层网络”,深度分离结果也不是“加层一定提高准确率”。前者主要讨论表示存在性,后者讨论特定函数族的表示效率;训练算法、数据量和泛化仍然需要单独检查。
11
关于深层网络的表示效率,哪项说法最准确?
12
单隐藏层网络具有广泛的逼近能力,等价于它总能用很少单元高效表示目标函数。
初始化、激活与梯度流是一件事
反向传播反复乘上权重转置和激活导数。把多层连起来看,早期层梯度包含一串 Jacobian 的乘积。若这些变换整体把向量持续缩小,梯度会逐层变弱;若持续放大,梯度会爆炸。前向信号也有相似问题:激活方差若越传越小,各层输出会挤在很窄的范围;若越传越大,Sigmoid 或 tanh 容易进入饱和区。
因此初始化不能只说“随机就行”。它要同时参考输入连接数和激活函数。对 ReLU 隐藏层,常用 He 初始化的正态版本:
写成代码,就是标准正态随机数乘以 。对 tanh 或 Sigmoid,常见 Xavier/Glorot 思路会同时考虑 fan_in 和 fan_out;PyTorch 的 Xavier 正态版本对应标准差:
这些缩放是在随机初始化时尽量控制层间方差,不是对梯度稳定性的绝对保证。网络结构、数据分布、训练过程和归一化方法都会影响真实梯度流。
权重不能全部初始化为零。若同一层所有单元从完全相同的权重出发,它们会收到相同梯度,之后仍保持相同,多个单元等于只学一个重复特征。偏置可以初始化为零,因为随机权重已经打破了单元之间的对称性。
激活函数也会改变梯度。Sigmoid 在 很大时导数接近 0,不适合反复堆在许多隐藏层里。ReLU 在正半轴导数为 1,通常更利于深层隐藏表示,但负半轴导数为 0;如果某个单元长期落在负区,它可能很难恢复。初始化尺度与学习率都可能影响这种现象。
np.random.randn(...) * 0.01 不是适用于所有深度和激活函数的通用配方。固定的 0.01 没有参考每层 fan-in,网络变深或宽度变化后,信号尺度可能迅速偏离可训练区间。
13
下列哪些做法符合本节的初始化原则?
14
深层隐藏层反复使用 Sigmoid 时,较大的 |Z| 为什么可能妨碍训练?
用 NumPy 把每层拼成完整模型
下面的实现刻意保持模块边界清楚:初始化、前向、损失、单层反向、全网反向和参数更新各做一件事。它不是为了替代 PyTorch,而是让你能看见自动微分框架替我们管理了哪些依赖。
python
import numpy as np
def sigmoid(Z):
"""数值较稳定的 Sigmoid。"""
A = np.empty_like(Z, dtype=float)
positive = Z >= 0
A[positive] = 1.0 / (1.0 + np.exp(-Z[positive]))
exp_z = np.exp(Z[~positive])
A[~positive] = exp_z /
调用前先固定数据约定:X_train.shape == (n_x, m_train),Y_train.shape == (1, m_train);验证集也采用同样的行含义。验证集只用于评估,不参与 model_backward 和参数更新。
python
layer_dims = [X_train.shape[0], 16, 8, 1]
parameters, history = train(
X_train,
Y_train,
X_val,
Y_val,
layer_dims,
learning_rate=0.01,
num_steps=3000,
record_every=100,
)这份代码还有两项适合你自己补上。第一项是数值梯度检查:随机挑少量参数,用有限差分近似梯度,与反向传播结果比较。第二项是把全批次训练改成小批次迭代。这两项会增加代码长度,但不会改变每一层的前向和反向接口。
损失中的 clip 用于让对数计算保持有限;输出层梯度仍直接使用 Sigmoid 与二元交叉熵合并后的 AL - Y。不要把裁剪后的概率再塞回前向缓存,否则你等于悄悄改了用于求导的计算图。
15
手写 L 层网络时,哪条断言最能直接发现参数梯度 shape 错误?
16
若 layer_dims 的长度为 6,则带参数的层数 L 是 ____。
从两条曲线判断下一步
模型能运行不代表训练合理。最基本的诊断材料是同一组横坐标下的训练损失和验证损失。它们回答的是两个不同问题:训练损失看当前模型是否在拟合训练数据,验证损失看这种拟合能否迁移到未参与更新的数据。
常见现象可以这样读:
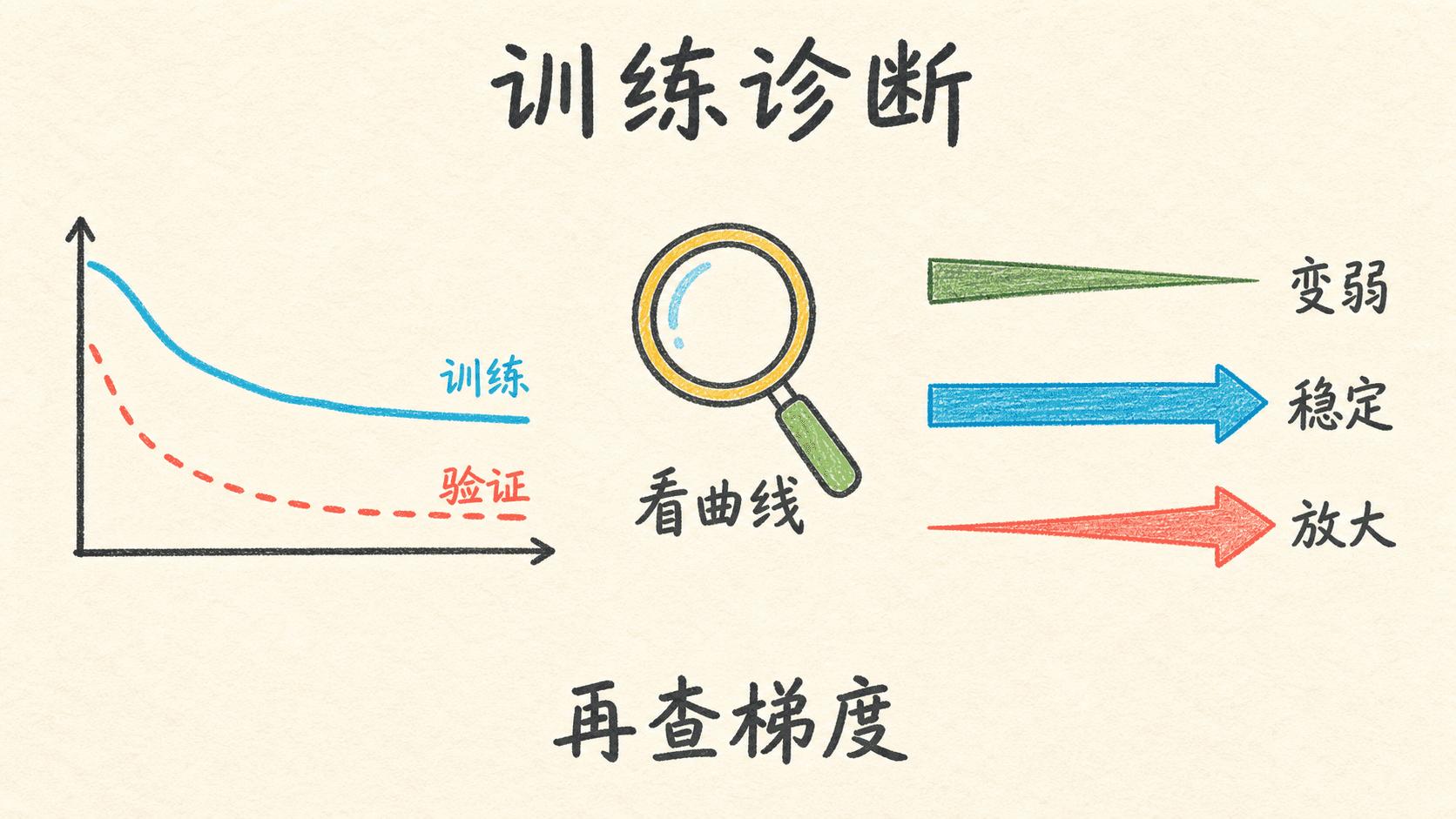
诊断顺序很重要。若训练损失根本降不下来,先别急着把问题归为过拟合,也不要立刻加正则化。先确认实现与优化正常:输出概率是否有限,梯度 shape 是否匹配,参数确实发生更新,各层激活和梯度有没有快速塌缩。
当训练损失已经很低、验证损失却明显变差时,才更像泛化问题。下一章的正则化会处理权重衰减、Dropout 和早停等方法;优化章节会讨论小批次、动量和 Adam 怎样改变更新过程。这些方法不会替代本章的 shape 与梯度检查,它们建立在前后向传播已经正确的前提上。
一份可重复的排查清单
- 固定随机种子和数据划分,保留训练、验证两条曲线。
- 用一个很小的数据子集尝试过拟合;若连小样本都拟合不了,优先查实现或优化。
- 记录每层激活的均值、标准差、零值比例,以及梯度范数。
- 一次只改一个变量,比如学习率、初始化或宽度,避免无法判断是哪项改动生效。
- 用多个随机种子重复实验,报告整体趋势,不只保留最理想的一次。
17
训练损失继续下降、验证损失却连续回升时,哪些措施值得优先考虑?
18
若训练一开始两条损失都不下降,最合理的第一步是什么?