浅层神经网络
如果你已经会写逻辑回归,浅层神经网络并不是突然换了一套数学。它仍然做“线性组合、计算损失、沿梯度更新”这几件事,只是在输入和输出之间多放了一层可学习的非线性变换。
这层变换解决了一个很具体的问题:一条直线不够用时,模型怎样自己组合出弯曲或分段的决策边界?我们从 XOR 的矛盾出发,把两层网络的 shape、前向传播、反向传播和初始化逐项对齐,再用 NumPy 从零训练一个月牙数据分类器。读完后,你应该能解释每个公式为什么长这样,也能根据损失曲线和决策边界判断模型卡在了哪里。
一条直线为什么分不开 XOR
先看四个点。XOR 在两个输入不同时取 1,相同时取 0:
线性分类器先计算分数 ,再用一条阈值线 分开两类。问题是,XOR 的两个正类点位于正方形的一组对角,两个负类点位于另一组对角。无论怎样转动一条直线,总会把至少一个点留在错误的一侧。
这不只是“看图好像不行”,还可以写成一个很短的反证。假设分数大于 0 判为 1,那么四个点要求:
由中间两式可得 且 ,于是 ,这与最后一式直接冲突。因此,原始二维空间里不存在能正确分类 XOR 的线性边界。
隐藏层的作用可以理解成“先换一种坐标”。不同隐藏单元各自画出一条线并产生一个非线性响应,输出层再组合这些响应。单个单元仍然简单,但多个单元可以拼出多个区域。对于 XOR,一个隐藏单元可以响应“至少有一个输入为 1”,另一个响应“两个输入都为 1”,输出层再把后者从前者中扣掉。
逻辑回归不是因为优化得不够久才解不出 XOR,而是模型族本身没有合适的边界。继续增加迭代次数只会在同一组直线中寻找,不会凭空得到弯曲边界。先判断是“容量不够”还是“还没优化好”,这是后面诊断神经网络的第一条线索。
1
逻辑回归无法完美分类标准 XOR 四点,最根本的原因是什么?
2
只要给一个纯线性网络增加足够多的线性层,它就能表示 XOR。
两层网络的骨架与统一符号
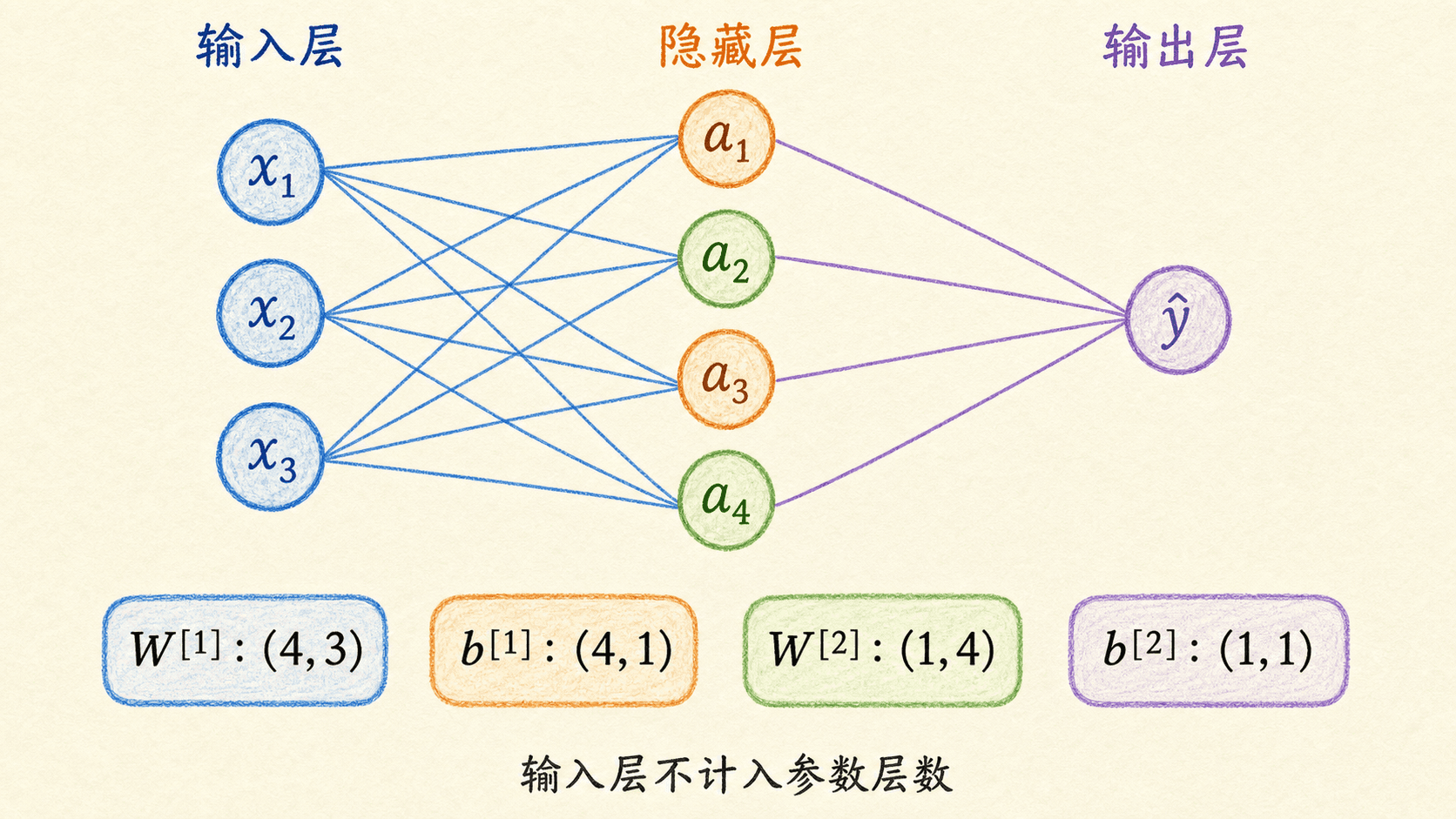
我们把含一个隐藏层和一个输出层的模型称为两层神经网络。这里的“两层”只数带参数的计算层;输入层只是放数据,不计入层数。设输入特征数为 ,隐藏单元数为 ,二分类输出维度为 。
统一符号能省掉大量排错时间。上标 表示第 个计算层,下标可以表示某个单元或样本:
为什么 是 ?因为它有 行,每一行属于一个隐藏单元;每个隐藏单元都要读取 个输入。矩阵乘法随后给出:
同理,输出层只需要一个概率,所以 有一行。参数量也能从 shape 直接读出:
其中前两项来自隐藏层权重和偏置,后两项来自输出层权重和偏置。这个数会随隐藏层宽度 线性增加。
不要把“输入层、隐藏层、输出层共三层”和“两层神经网络”当成数学矛盾。前一种说法在描述结构,后一种说法在数带参数的变换。阅读代码或论文时,先看作者如何定义层数,再对照参数下标。
3
输入有 5 个特征、隐藏层有 8 个单元时,W[1] 的 shape 是 ____。
4
对于隐藏层宽度为 n_h 的二分类两层网络,下列 shape 哪些正确?
前向传播先把 shape 对齐
单个样本从左向右经过两次“线性变换加激活”:
隐藏层激活 暂时可以取 tanh,二分类输出层取 Sigmoid。线性值 是激活函数的输入,激活值 是这一层传给下一层的表示。把两者都缓存下来,是因为反向传播还会用到它们。
训练时不必逐样本写 Python 循环。把 个样本按列堆成 ,标签写成 ,所有公式可以一次完成:
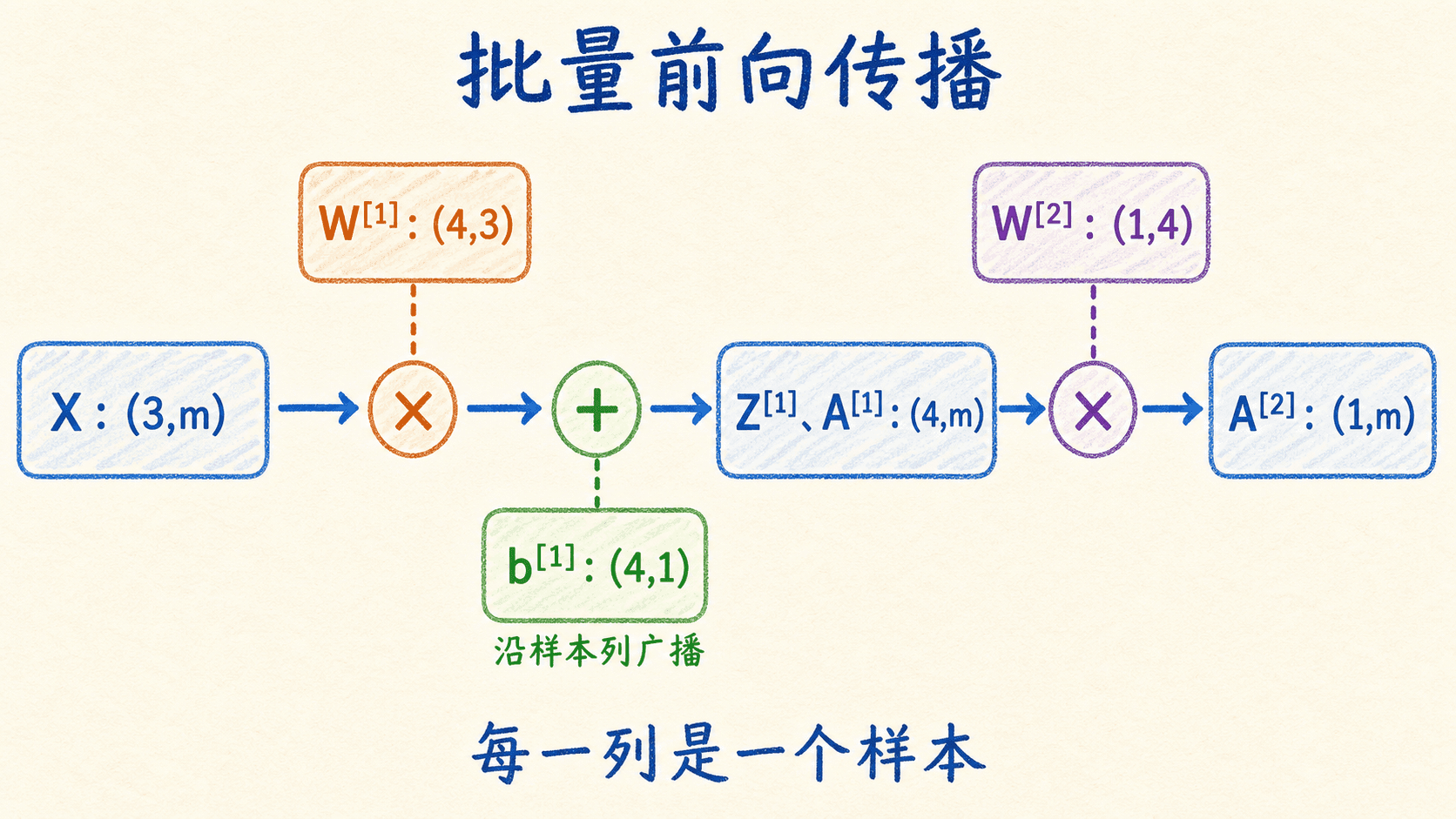
此时 的 shape 仍是 。NumPy 会沿样本列广播它,使每个样本都加上同一组偏置。这里保留第二维很重要:如果把偏置误写成一维数组 (n_h,),它与 (n_h,m) 的尾部维度通常无法按预期对齐,或者在某些特殊数字下悄悄得到错误结果。
python
import numpy as np
def sigmoid(Z):
Z = np.clip(Z, -500, 500)
return 1.0 / (1.0 + np.exp(-Z))
def forward(X, params):
W1, b1 = params["W1"], params["b1"]
W2, b2 = params["W2"], params["b2"]
5
X 的 shape 为 (3, 200),W[1] 的 shape 为 (6, 3) 时,Z[1] 的 shape 是什么?
6
批量前向传播中,每一列放一个样本。若共有 m 个样本,二分类输出 A[2] 的 shape 是 ____。
激活函数决定边界能否弯起来
如果拿掉隐藏层激活,整个网络会重新塌成一个线性模型:
把第一式代入第二式:
括号里的两部分完全可以改名为一个新权重和一个新偏置。也就是说,无论堆多少个纯线性层,最终仍是一层仿射变换。真正让隐藏单元能够拼接不同区域的是非线性激活。
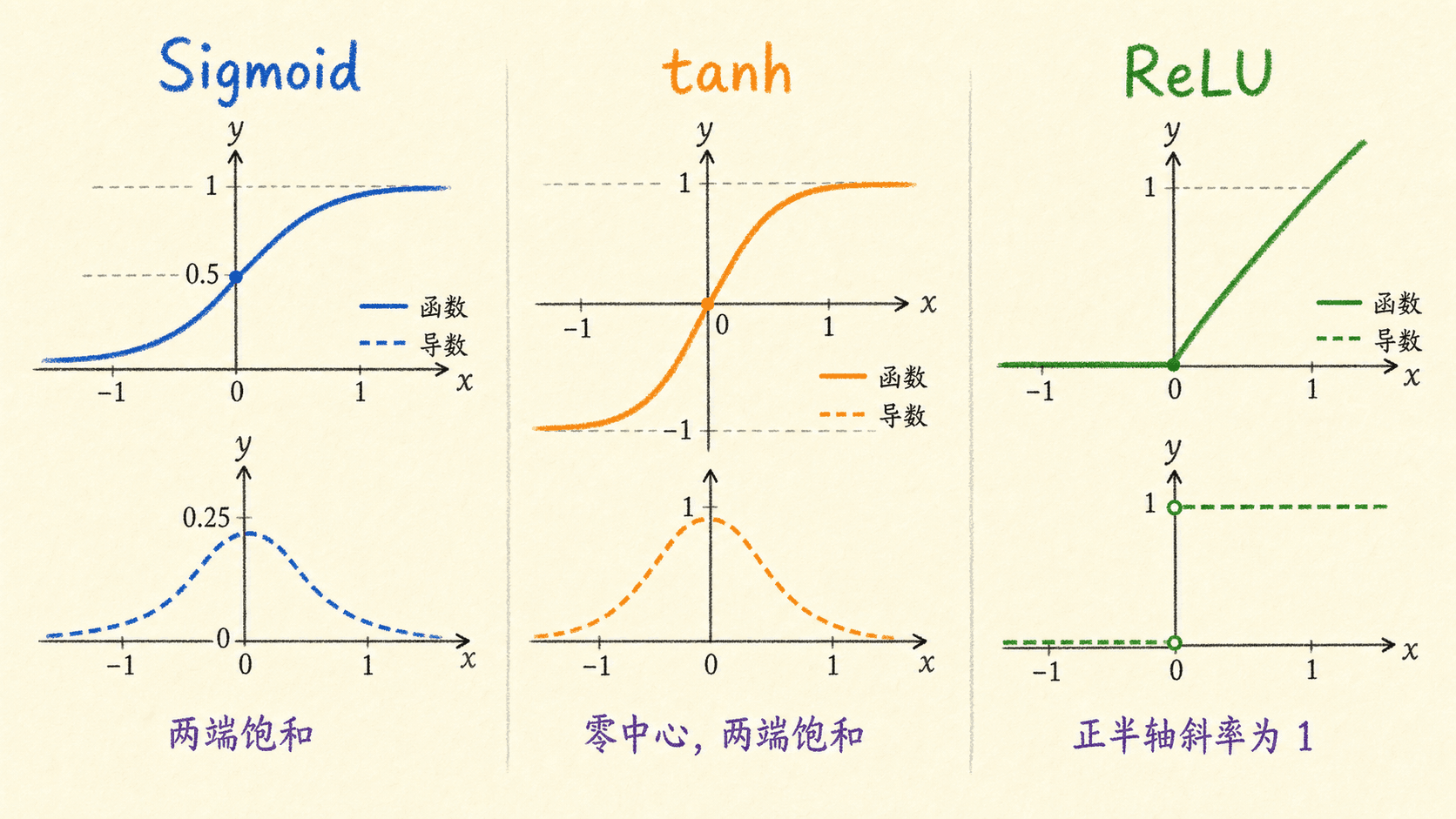
Sigmoid:适合二分类输出
Sigmoid 把实数压到 ,很适合把二分类输出解释为概率。但当 很大时,曲线接近平坦,导数接近 0。它的输出也总是正数,因此如今通常不把它作为隐藏层的默认选择。
tanh:适合小型、居中的隐藏表示
tanh 把输出压到 ,零附近近似线性,正负两侧对称。在本章的小型月牙任务里,我们用它让推导和实现保持紧凑。它同样会在两端饱和,所以输入标准化和合适的初始化仍然重要。
ReLU:多数隐藏层的常用起点
ReLU 在正半轴不会像 Sigmoid 那样饱和,计算也很直接。 处数学上不可导,软件实现会约定一个次梯度,常见取值是 0。它的风险是某个单元若长期落在负半轴,输出和局部梯度都会保持 0,这就是“死亡 ReLU”。降低过大的学习率、换用 Leaky ReLU,或检查输入与初始化,通常比盲目增加训练轮数更有针对性。
一个实用起点是:二分类输出层用 Sigmoid;普通隐藏层优先试 ReLU;小型、输入已居中的浅层网络也可以试 tanh。选择激活时要一起考虑初始化,因为它们共同决定前向信号和反向梯度的尺度。
7
下列关于激活函数的说法,哪些正确?
8
ReLU 在正半轴的斜率为 1,所以使用 ReLU 的网络绝不可能遇到梯度问题。
反向传播是一场逐层对账
前向传播得到预测后,我们用二元交叉熵衡量它与标签的差异。对 个样本,平均损失是:
反向传播没有另造一套规则。它只是从损失出发,按链式法则沿计算图反向传递偏导数。Sigmoid 配合二元交叉熵后,输出层关于线性值的梯度会简化为:
下面按依赖顺序走一遍,并在每一步核对 shape。
先算输出误差 。两者都是 ,所以 也是 。
把这些式子写成 NumPy,几乎就是逐行翻译:
python
def backward(X, Y, params, cache):
m = X.shape[1]
W2 = params["W2"]
A1, A2 = cache["A1"], cache["A2"]
dZ2 = A2 - Y # (1, m)
dW2 = (dZ2 @ A1.T) / m # (1, n_h)
db2 = np.sum(dZ2, axis=1, keepdims
每个参数梯度必须与对应参数 shape 完全相同。若 与 对不上,不要先尝试 reshape;应回到产生它的矩阵乘法,检查样本放在列还是行、哪个矩阵需要转置。随手 reshape 可能让程序继续运行,却改变了梯度的含义。
9
在本章的按列放样本约定下,为什么 dW[2] 要写成 dZ[2] @ A[1].T?
10
若 W[2] 的 shape 为 (1, 6),dZ[2] 的 shape 为 (1, 100),则 dA[1] 的 shape 是 ____。
初始化先打破对称性再控制尺度
如果把同一隐藏层的所有权重都初始化为 0,所有隐藏单元会看到相同输入,产生相同输出,并收到相同梯度。第一次更新后它们仍然相同,后续也不会主动分工。名义上有 个单元,实际上只是在重复同一个单元。

偏置可以初始化为 0,因为随机权重已经让隐藏单元有了不同方向。权重则既要随机,又不能随便放大。过大的权重会把 Sigmoid 或 tanh 推入饱和区;过小的权重在层数增加后又可能让信号和梯度不断缩小。
对 tanh 或近似对称激活,常用 Glorot/Xavier 正态初始化:
这里公式的第二个参数表示方差。对 ReLU,He 初始化根据正半轴保留信号的特点采用:
本章的 tanh 网络使用 Xavier 正态初始化:
python
def xavier_normal(rng, fan_in, fan_out):
std = np.sqrt(2.0 / (fan_in + fan_out))
return rng.normal(0.0, std, size=(fan_out, fan_in))
def initialize(n_x, n_h, seed=42):
rng = np.random.default_rng(seed)
return {
"W1": xavier_normal(rng, n_x, n_h),
"b1": np.zeros((n_h, 1)),
"W2": xavier_normal(rng, n_h, 1),
固定随机种子是为了复现实验,不代表所有实验都应永远用同一个种子。比较两个方案时,最好尝试多个种子;否则某次幸运或不幸运的初值可能被误当成结构差异。
11
隐藏层权重全为 0 时,各隐藏单元会因训练数据不同而自动学出不同特征。
12
下列关于初始化的说法,哪些正确?
用 NumPy 从零跑通训练循环
接下来把数据、前向、损失、反向和更新连起来。我们用三角函数生成两条互相咬合的月牙。它比 XOR 多了噪声与连续分布,更适合观察决策边界是否过于简单或过于曲折;数据生成和神经网络都只用 NumPy 实现。
python
import numpy as np
# 用两段半圆生成月牙数据
def make_moons_numpy(n_samples=400, noise=0.20, seed=7):
rng = np.random.default_rng(seed)
n_outer = n_samples // 2
n_inner = n_samples - n_outer
outer_angle = rng.uniform(0.0, np.pi, n_outer)
inner_angle = rng.uniform(0.0, np.pi, n_inner)
交叉熵中的对数不能接收 0。数值计算时把概率裁到一个很小的开区间,不改变模型结构,只避免浮点下溢产生无穷大:
python
def binary_cross_entropy(A2, Y):
eps = 1e-12
A2 = np.clip(A2, eps, 1.0 - eps)
return -np.mean(Y * np.log(A2) + (1.0 - Y) * np.log(1.0 - A2))
def update(params, grads, learning_rate):
for name in ("W1", "b1", "W2", "b2"):
训练循环每轮只做四件事:前向、算损失、反向、更新。验证集只用于观察,不参与反向传播。
python
def train_two_layer_network(
X_train,
Y_train,
X_val,
Y_val,
n_h=8,
learning_rate=0.2,
steps=5000,
seed=42,
log_every=100,
):
params = initialize(X_train.shape[0], n_h, seed=seed)
history = {"step"
这里没有承诺某个固定准确率。数据噪声、划分、隐藏宽度、学习率、训练步数和随机种子都会影响结果。真正要观察的是:损失有没有下降、训练与验证走势是否分叉、边界有没有学到月牙的大体形状。
不要根据验证集表现反复调参之后,又把同一验证集称为“最终测试集”。一旦它参与了模型选择,它就已经影响了决策。需要客观报告最终泛化表现时,应另留测试集,在所有结构与超参数确定后只评估一次。
13
在上面的训练循环中,验证集最合适的用途是什么?
14
二分类时把概率 A2 转成类别,常用规则是 A2 大于等于 ____ 判为 1。
从决策边界诊断模型并走向更深网络
只看最终准确率,会把很多不同问题压成一个数字。浅层二维任务有一个额外优势:我们可以直接画出预测概率和决策边界,看看网络究竟学了什么。
python
import matplotlib.pyplot as plt
def plot_decision_boundary(params, X, Y, step=0.03):
x_min, x_max = X[0].min() - 0.6, X[0].max() + 0.6
y_min, y_max = X[1].min() - 0.6, X[1].max() + 0.6
xx, yy = np.meshgrid(
np.arange(x_min, x_max, step),
np.arange(y_min, y_max, step),
)
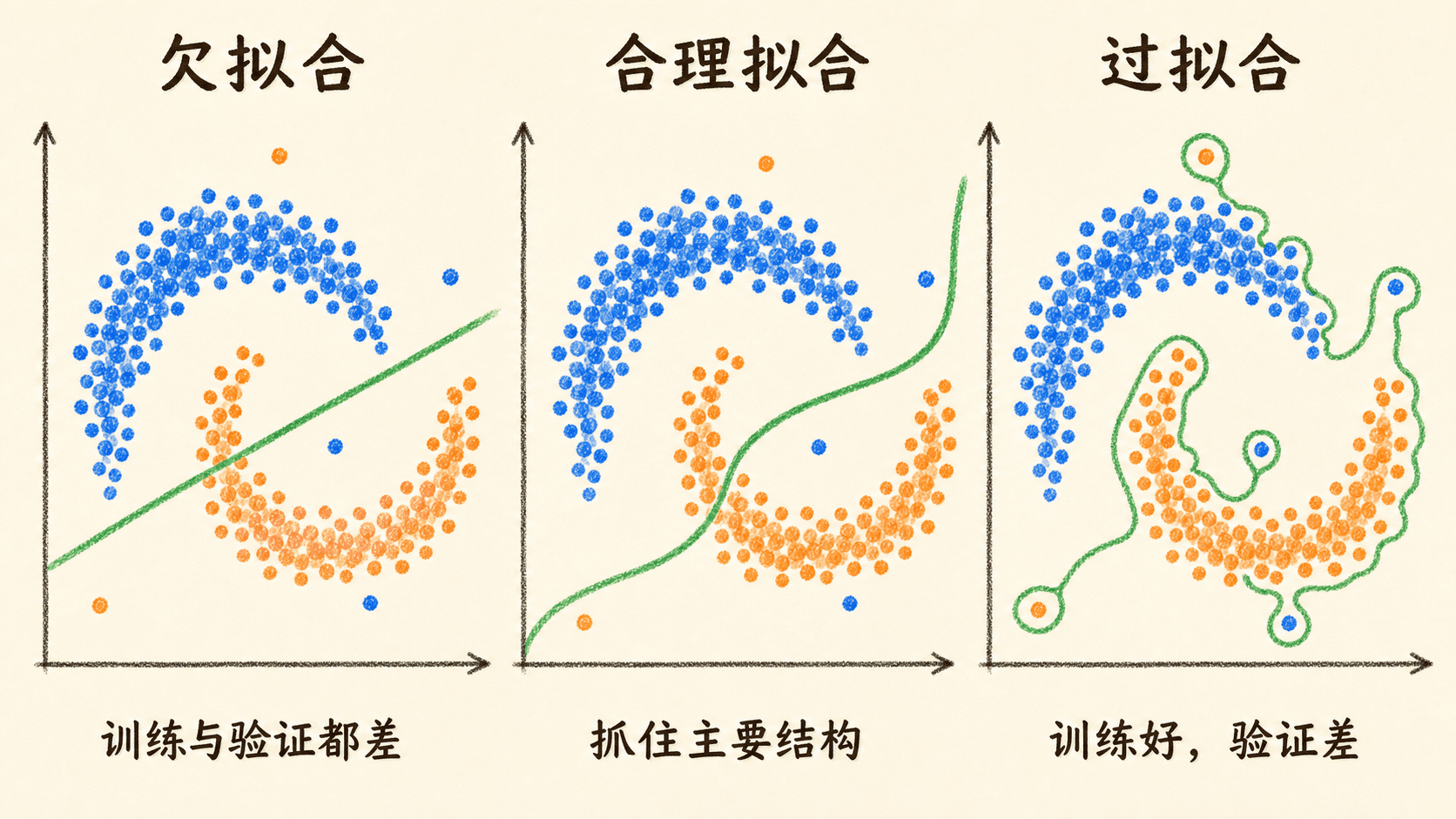
可以把常见现象整理成一张诊断表:
一个隐藏层已经能组合出非线性边界,但“足够宽就能逼近很多连续函数”不等于“训练一定容易”,也不等于“浅层永远最省参数”。更深的网络把表示拆成多级复合:前一层形成较简单的特征,后一层继续组合。到了深层网络,前向与反向的基本公式并没有变,真正新增的是层循环、缓存管理,以及更严肃的梯度尺度问题。
换句话说,本章最值得带走的不是某个固定宽度或学习率,而是一套对账方法:先看模型族能不能表示目标边界,再核对每层 shape,然后检查激活与初始化是否让信号处于可学习区间,最后用训练/验证曲线和边界图判断容量与泛化。下一步把层数从 2 推广到 时,这套方法仍然有效。
15
哪些现象支持“模型可能过拟合”这一判断?
16
从两层网络推广到深层网络后,前向的线性变换加激活、反向的链式法则这两套基本逻辑仍然成立。