超参数调优与批归一化
同一份数据、同一类网络,为什么一组配置能稳定收敛,另一组却在损失曲线上来回震荡?很多时候,问题不在“模型会不会反向传播”,而在训练流程之外的那些选择:学习率取多大、批量放多少样本、要训练多久、用什么指标选模型,以及验证分数是否真的可以复现。
这一章把两件经常一起出现的事讲透。前半部分讨论如何把调参变成一项有边界、可比较的实验;后半部分讨论 Batch Normalization(批归一化,简称 BN)到底做了什么,尤其是训练和推理为什么不能混用同一套统计量。最后,我们会把 Softmax 写成数值稳定的形式,并给出选择深度学习框架时更实际的判断标准。
主题脉络参考了 DeepLearning.AI《Improving Deep Neural Networks》课程的超参数调优、Batch Normalization 与编程框架单元,技术细节则以原始论文和当前框架官方文档交叉核对。
本章不会给出一张“所有任务通用的最佳超参数表”。超参数的有效范围依赖数据、模型、优化器、硬件和训练预算。更可靠的目标,是学会设计一场公平实验,并从有限预算里得到下一步可用的信息。
从可训练参数到超参数
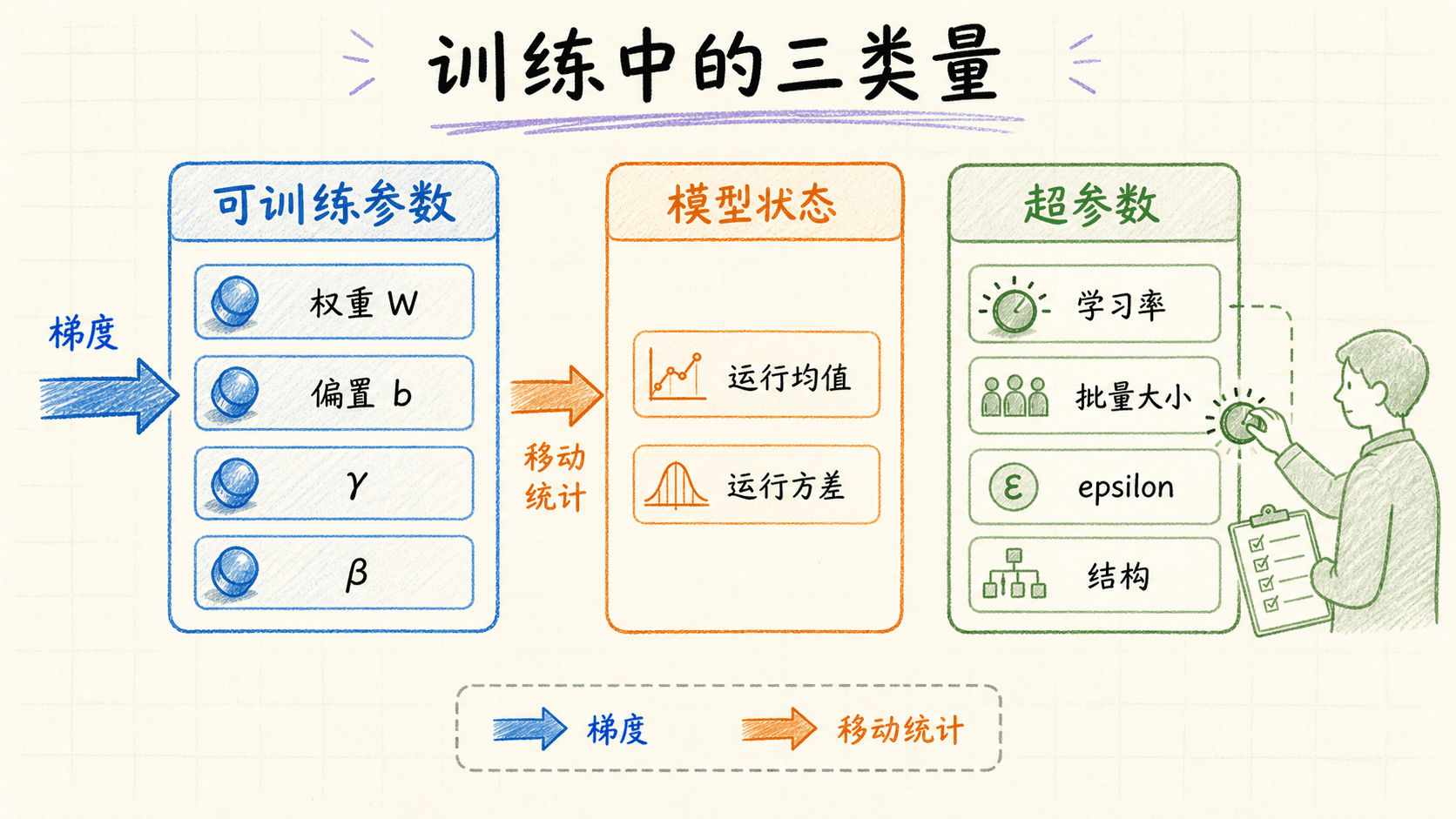
第一次调神经网络时,很容易把所有“数值”都叫作参数。工程上最好先分清两层:模型在一次训练中通过梯度学到的量,叫可训练参数;训练开始前由我们指定、搜索算法选择或外层流程控制的量,叫超参数。
假设一层线性变换写成:
和 会在反向传播后被优化器更新,所以它们是可训练参数。学习率、批量大小、隐藏层宽度、权重衰减、Dropout 概率、训练轮数和数据增强强度,则决定“怎样训练”或“训练什么结构”,通常属于超参数。
这个边界不是由符号决定的,而是由更新方式决定的。BN 中的缩放系数 和平移系数 虽然看起来像配置项,却会接收梯度,因此是可训练参数;运行均值和运行方差会随训练更新并写进模型状态,但不通过梯度优化,通常被框架登记为 buffer 或 non-trainable variable;BN 的 eps 和运行统计更新系数则是超参数。
为什么这个边界会影响实验
一次 trial(单次试验)固定一组超参数,然后在训练集上学习参数。调参算法比较的是多个 trial 的验证结果。若我们一边看测试集,一边改学习率,测试集实际上已经进入外层优化;最后得到的测试分数就会偏乐观。
你可以把整个过程看成两层循环:
python
best = None
for config in search_space: # 外层:选择超参数
model = build_model(config)
model.fit(train_data) # 内层:学习可训练参数
score = evaluate(model, val_data)
best = keep_better(best, config, score)
final_score = evaluate(best.model, test_data)真实项目还会多一层约束:数据预处理、特征选择和阈值确定也只能在训练集与验证集范围内完成。测试集要留到开发决策结束之后再使用。
1
下列哪一项在标准 Batch Normalization 层中会通过梯度下降学习?
2
在一次 trial 内由反向传播更新的是模型的 ____,而学习率和批量大小属于超参数。
先固定指标、预算与基线
调参之前最容易被忽略的问题是:我们到底在优化什么?“准确率更高”还不够完整。类别不均衡时可能要看宏平均 F1,检索任务可能看召回率,概率预测还可能关心对数损失和校准误差。指标必须与上线目标一致,并在搜索开始前写清楚主指标和约束指标。
指标不能脱离选择规则
如果主指标是验证集宏平均 F1,就要说明是在每轮结束后计算、按哪个阈值计算,以及分数相同时怎样选择。若同时要求延迟低于 20 毫秒,也应把它写成硬约束,而不是等找到大模型后再补一句“最好还能快一点”。
同样要固定验证协议:数据划分、交叉验证折、预处理流程、评估频率和最佳检查点规则。否则两个 trial 的分数差异可能来自评估方式,而不是超参数本身。
预算要用可比较的单位
预算可以是 trial 数、GPU 小时、训练步数、处理过的样本数或总费用。只写“每个模型训练 10 个 epoch”有时并不公平:批量大小变化后,每个 epoch 的更新次数会变;数据采样策略变化后,每轮看到的样本也可能不同。
实际记录时,我会同时保留两类预算:一个是业务真正承担的墙钟时间或费用,另一个是方便分析的训练步数、样本数和 epoch。这样既能回答“花了多少资源”,也能解释“模型实际上更新了多少次”。
可复现基线是调参的起点
基线不必很强,但必须能重复运行。至少固定并记录:
- 代码版本、数据版本和划分标识;
- 随机种子,以及 Python、NumPy、框架等随机数来源;
- 硬件、驱动、框架版本和精度模式;
- 模型结构、初始化、优化器与学习率调度;
- 主指标、检查点规则和实际资源消耗。
PyTorch 的可复现性说明明确提醒:即使设置种子,也不能保证跨版本、跨平台或 CPU/GPU 的完全一致;确定性算法还可能牺牲速度。因此“可复现”更实际的含义是:在声明的环境和协议下控制已知随机源,并把无法消除的差异写进实验记录。
不要只跑一次基线就把 0.2 个百分点的提升当成结论。训练本身有随机波动,验证集也有抽样误差。对进入决赛的少量配置,使用多个种子重复运行并报告均值与离散程度,通常比把全部预算花在更多单次 trial 上更可信。
3
为了公平比较两个调参 trial,通常应预先固定哪些内容?
4
只要调用了随机种子设置函数,就能保证同一代码在任意 PyTorch 版本、平台和设备上逐位复现。
网格、随机与搜索空间
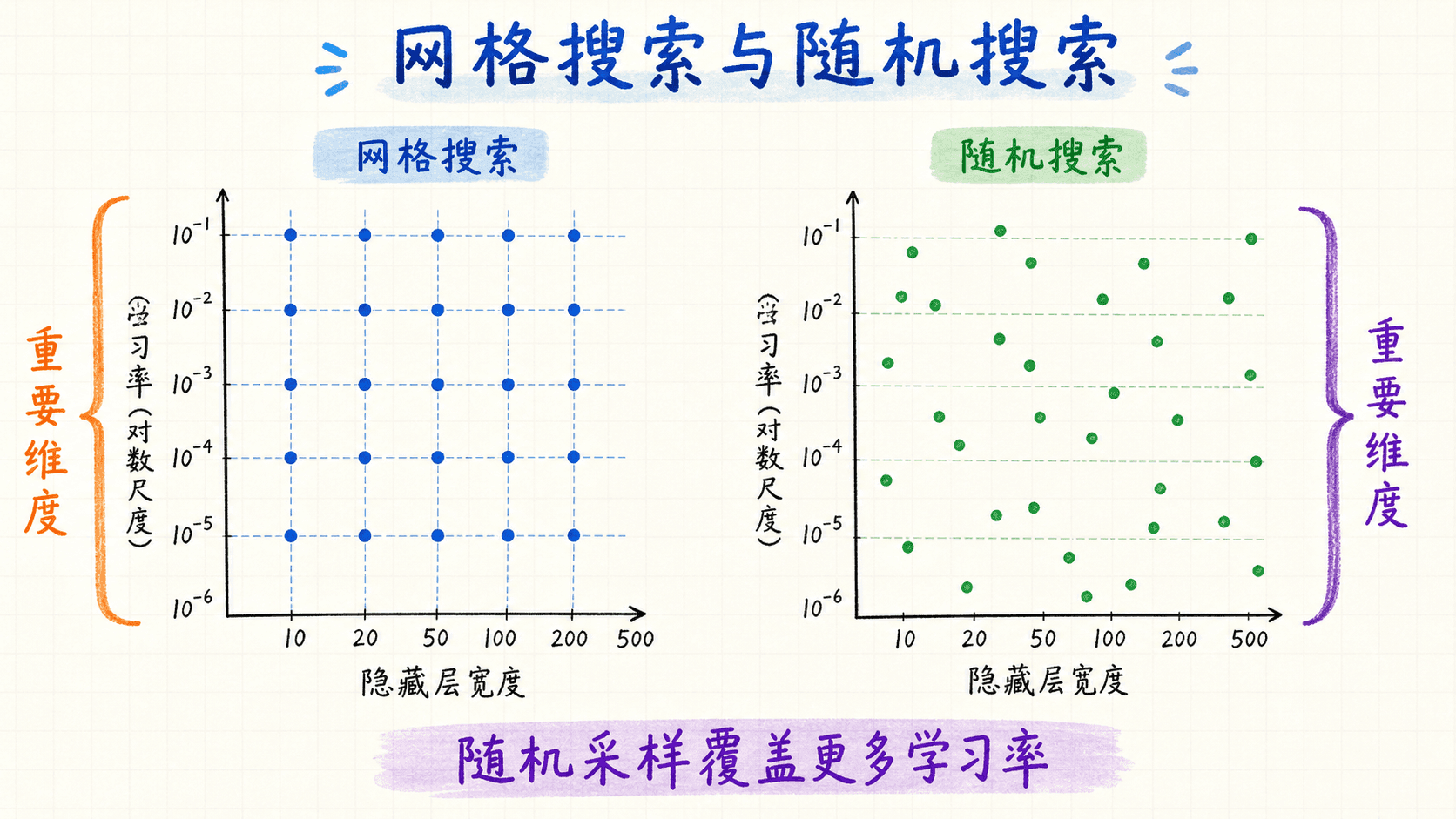
网格搜索会为每个超参数列出有限取值,再计算它们的笛卡尔积。它的优点是直观、容易复现,也适合只有一两个参数且候选值确实有业务含义的场景。问题出现在维度增加之后:每个维度取 5 个值,8 个维度就有 种组合。
随机搜索从预先定义的分布中独立采样。Bergstra 和 Bengio 在 JMLR 论文《Random Search for Hyper-Parameter Optimization》中给出的核心观察是:在很多问题上,真正显著影响结果的往往只有少数超参数,而且“重要的是哪几个”会随数据集改变。在相同 trial 预算下,随机搜索通常能在重要维度上尝试更多不同取值,因此是一个很强的基线。
连续超参数先选分布,再选范围
学习率从 到 是 10 倍变化,从 到 也是 10 倍变化。若在线性区间 上均匀采样,大量样本会挤在较大的数量级。更合理的做法是先均匀采样指数:
这会让 、 等每个数量级获得相同概率。权重衰减、epsilon 等跨多个数量级的正数也常用对数分布。Dropout 概率或数据增强概率只有有限区间,通常可以在线性尺度上采样;层数、宽度和批量大小则要根据离散结构与硬件约束设计候选值。
python
import optuna
def objective(trial):
lr = trial.suggest_float("lr", 1e-5, 1e-1, log=True)
optimizer_name = trial.suggest_categorical("optimizer", ["sgd", "adamw"])
if optimizer_name == "sgd":
momentum = trial.suggest_float("momentum", 0.0, 0.95)
这里的 momentum 只在选择 SGD 时出现,这叫条件搜索空间。Optuna 的官方文档把这种用普通 Python 条件语句动态构造空间的方式称为 define-by-run。条件空间能避免搜索无效组合,比如给 AdamW 试验一个实际上不会使用的 SGD momentum。
随机搜索优于“机械网格”不等于随机搜索永远最好。低维空间、离散且昂贵的业务配置,或为了画出某一个参数的响应曲线时,网格仍然很合适。关键是让搜索方式匹配问题结构与预算。
5
要在 1e-5 到 1e-1 之间搜索学习率,哪种采样更能均匀覆盖不同数量级?
6
哪些情况更适合在搜索空间中使用条件分支?
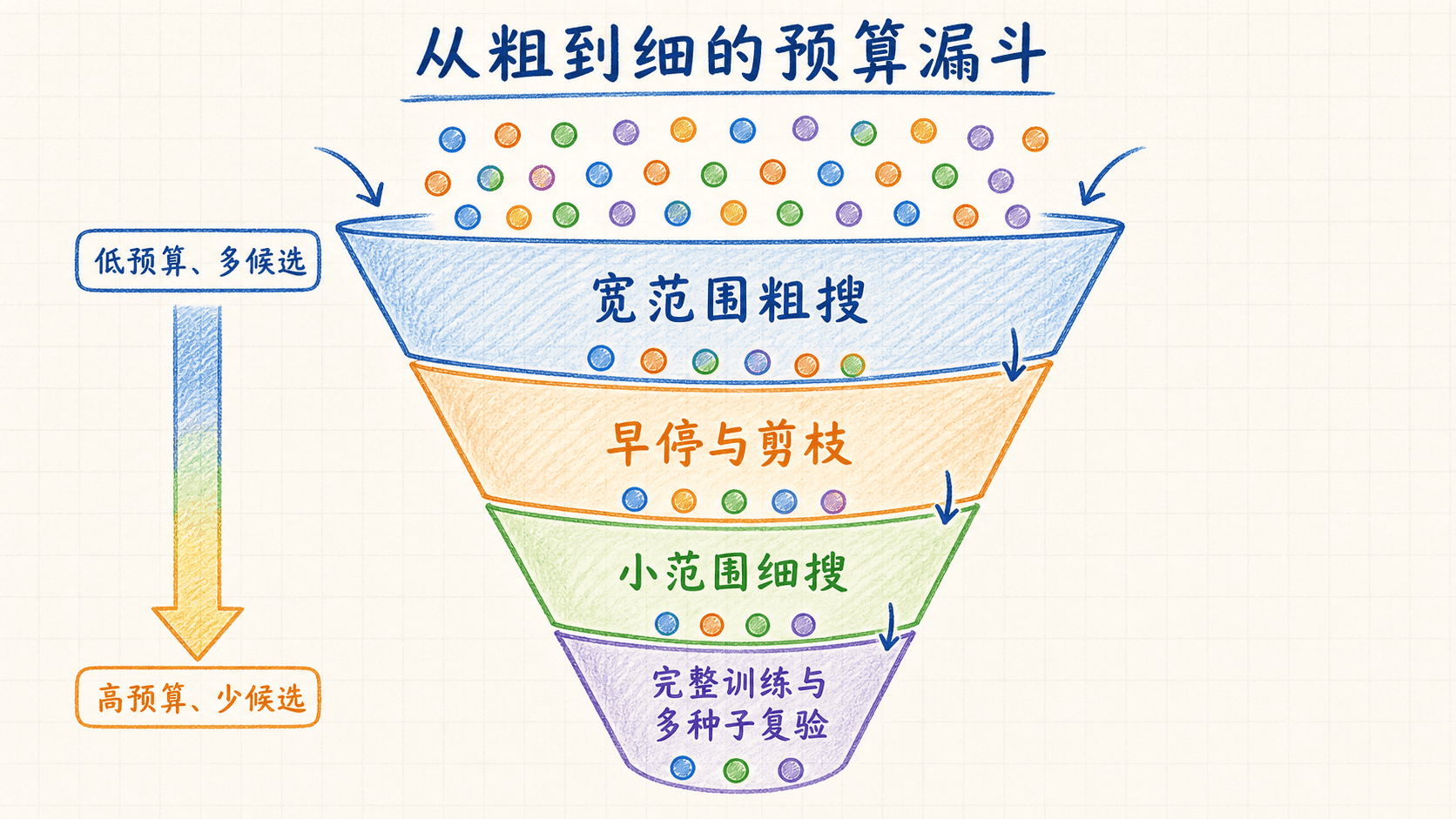
粗到细与多保真分配预算
一次完整训练要十几个小时,就不适合让每个配置都跑到底。更实用的思路是先粗后细:第一阶段用宽范围、较多配置和较低资源找到有希望的区域;第二阶段缩小范围、提高单次训练预算;最后只对少量候选做完整训练和多种子复验。
粗搜不是随便把训练砍短
低保真评估可以减少 epoch、采样部分数据、缩小输入分辨率或使用较小模型。但代理任务必须与最终目标有足够相关性。某些配置前期学得快,后期却更差;某些学习率调度需要较长 warmup;小数据上的模型排序也未必能迁移到完整数据。
因此,粗搜阶段要保留一个最低资源门槛,并定期检查“低预算排名”和“完整训练排名”是否一致。若排序相关性很差,继续早停只是在更快地做错误选择。
早停与剪枝回答的是资源问题
普通早停关注单个模型:验证指标在一段时间内不再改善,就停止训练。超参数优化中的 pruning(剪枝)还会横向比较多个 trial,在中间步骤淘汰明显落后的配置,把资源留给更有希望的试验。
TensorFlow 的 Keras Tuner 教程介绍的 Hyperband 就使用自适应资源分配和早停;Optuna 也提供剪枝机制。这些方法的共同直觉是:先给很多候选少量资源,再逐轮增加幸存者的预算。
剪枝阈值必须与指标噪声和学习曲线形态相匹配。验证集很小、评估方差很大或模型存在明显“后程发力”时,过早剪枝会系统性漏掉好配置。先设置 warmup 步数,再用多个检查点判断趋势,比看到一次落后就停止更稳妥。
一个可执行的三阶段方案
假设总预算是 120 GPU 小时,可以这样拆:
- 粗搜:60 个配置,每个最多 1 GPU 小时,并允许在最低步数后剪枝;
- 细搜:保留 8 个区域内候选,每个训练 5 GPU 小时;
- 复验:选择 2 个最终配置,各用 3 个种子完整训练。
这个例子不是固定比例。真正要固定的是晋级规则:看哪个指标、使用哪个检查点、遇到失败 trial 怎么处理,以及复验时是否锁定全部超参数。
7
在多保真搜索中,越早淘汰当前分数落后的 trial,一定越节省预算且不会错过好配置。
8
先让大量配置使用少量资源,再把更多资源分配给少数候选,这类思路通常称为 ____ 优化。
让每次试验都能回答问题
调参最怕出现这种局面:排行榜上有一个分数很好,却不知道它用了哪份数据、哪个检查点、是否发生过重启,也无法从日志里判断提升来自模型还是运气。一个 trial 的价值不只在最终分数,还在它能不能被重放、比较和解释。
最少要记录哪些字段
我会把记录分成五类:
配置要保存完整快照,而不是只记“这次把学习率改成了 0.001”。若默认值在库升级后变化,差异式记录就无法恢复当时训练。
json
{
"run_id": "bn-search-042",
"code_revision": "a1b2c3d",
"data_version": "images-v5",
"seed": 2026,
"optimizer": {
"name": "adamw",
"lr": 0.0007,
"weight_decay": 0.0001
},
"model": {
"batch_norm": true,
"batch_norm_eps":
失败 trial 也要留下来
出现 nan、显存不足、数据加载错误或主动剪枝时,不应直接从表中消失。失败分布本身能暴露搜索空间问题:如果较大学习率几乎全部数值溢出,就该调整上界;如果某类结构总是显存不足,就应把硬件约束写进条件空间。
比较 trial 时还要检查选择偏差。我们通常用同一个验证集搜索很多次,搜索越久,就越可能把验证噪声当成提升。因此最终候选需要在冻结配置后用多种子复验,并只在最后使用独立测试集。
9
一个可复现的单次试验记录通常应包括哪些信息?
10
为什么被剪枝或发生 OOM 的 trial 仍应保留记录?
Batch Normalization 的计算过程
Batch Normalization 由 Ioffe 和 Szegedy 在 2015 年的原始论文中提出。先看它在一个训练 mini-batch 上做什么。设某层一个特征或卷积通道在批中的取值为 ,先计算批均值与批方差:
然后标准化:
最后再做可学习的缩放和平移:
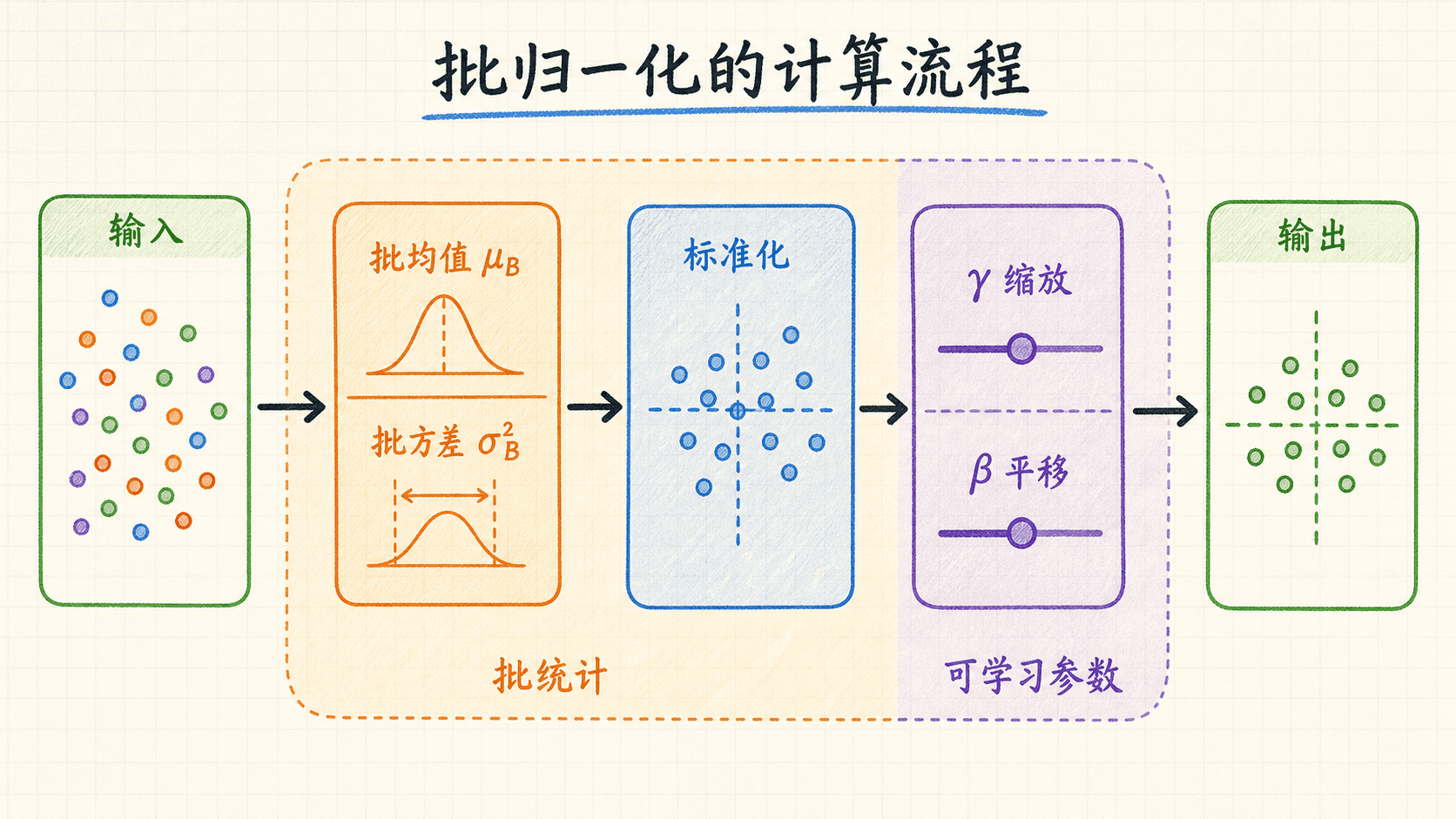
用于避免方差很小时除法不稳定; 与 则把表达能力还给网络。若某个特征更适合非零均值或不同尺度,训练可以通过这两个参数学出来。把 BN 理解成“强迫每层永远输出标准正态分布”并不准确:标准化只是中间步骤,仿射变换后的输出均值和方差由模型学习。
统计沿哪些维度计算
全连接层常按特征维分别统计一个 mini-batch;二维卷积的 BN 通常按通道统计,并把 batch 与空间位置一起纳入统计。以 PyTorch 的 (N, C, H, W) 为例,每个通道 的统计来自 (N, H, W) 切片。具体轴取决于框架的数据布局,因此迁移模型时不能只看层名。
放在激活前还是激活后
常见顺序是 Linear/Conv -> BN -> Activation,与原始论文的构造一致。也有架构把归一化放在其他位置,例如预激活残差网络。这里没有脱离架构的统一答案;复现已有模型时应遵循它的定义,自建网络时则选定一种顺序并保持实验可比。
如果线性层后立刻接启用中心化的 BN,线性层偏置通常是冗余的,因为减批均值会抵消统一偏移,BN 的 还能提供可学习平移。因此很多实现令前一层 bias=False。但在关闭 BN 中心化、改变顺序或做模型转换时,不能机械删除偏置。
检查 BN 实现时,可以依次核对四件事:统计轴是否正确,gamma 与 beta 是否可训练,epsilon 是否与目标框架一致,以及训练模式和推理模式是否被明确切换。这四项比背一个默认数值更有用。
11
Batch Normalization 在标准化之后还会用可学习的 ____ 和 beta 进行缩放与平移。
12
关于标准 Batch Normalization 的计算,下列哪些说法正确?
训练统计与推理统计不能混用
BN 最容易出错的地方不是公式,而是模式切换。训练时,同一样本的输出会受到批内其他样本影响,因为归一化使用当前 mini-batch 的均值和方差。推理时若仍这样做,单样本预测没有可靠方差,不同拼批方式还会让同一个输入得到不同结果。
标准做法是在训练时维护运行均值与运行方差,推理时用这些模型状态代替当前批统计:
TensorFlow 的 BatchNormalization 官方文档明确区分:training=True 使用当前批统计,推理使用训练期间积累的 moving statistics。PyTorch 的 BatchNorm2d 文档默认也会跟踪运行统计,并在 eval() 模式下使用它们。
同名 momentum 有相反的记法
这是跨框架迁移的高频坑。设 是旧运行统计, 是当前批统计。
PyTorch 的 BN momentum=m 使用:
Keras 的 BN momentum=m 使用:
所以 PyTorch 的 momentum=0.1 与 Keras 的 momentum=0.9 在系数含义上对应,都是给新批统计 0.1 的权重;但两边默认值并不完全等价。PyTorch 文档当前默认是 0.1,Keras 文档当前默认是 0.99。迁移配置时要比较更新公式,不能复制同一个数字。
epsilon 也会影响迁移结果
PyTorch BatchNorm2d 文档列出的默认 eps 是 ,Keras BatchNormalization 的默认 epsilon 是 。两者都用于稳定分母,但差两个数量级。当通道方差很小、使用低精度计算或要求严格复现时,这个差异会改变输出。
方差估计的细节也要核对。PyTorch 文档说明,训练前向传播使用有偏估计,也就是与 torch.var(input, correction=0) 等价;写入运行方差时使用无偏估计,与 correction=1 等价。这个差异平时由框架管理,但手写 BN、转换检查点或逐元素对齐输出时不能忽略。
因此,加载跨框架权重时至少要对齐统计轴、、、运行均值、运行方差、epsilon、方差约定和模式。若运行统计没有正确迁移,只复制可训练权重也得不到同一个模型。
验证或部署前忘记调用推理模式,会让 Dropout 继续随机丢弃单元,也会让 BN 继续依赖当前批统计。反过来,如果训练阶段误用推理模式,BN 的运行统计不会按预期更新。模式切换应写进训练与评估流程,而不是靠人工记忆。
13
若想让新批统计占 10% 权重,哪组配置在更新系数含义上对应?
14
只要 gamma 和 beta 相同,PyTorch 与 Keras 的 Batch Normalization 输出就一定相同。
BN 的收益、边界与替代方案
原始 BN 论文报告了更高学习率、更少训练步数以及对初始化敏感度降低等实验结果。后来 Santurkar 等人的优化分析提出,BN 的帮助不必只用“减少内部协变量偏移”解释,它还会让优化问题的损失与梯度更平滑。对实践者来说,比较稳妥的说法是:BN 经常改善深层网络的优化行为,但收益大小依赖架构、批量和任务。
小批量会让统计变得嘈杂
批越小,均值和方差估计通常越不稳定。检测、分割或高分辨率训练常因显存限制只能给每张设备很小的 local batch;多卡训练如果每个设备各自计算 BN,实际统计批量也可能远小于全局 batch。可以考虑同步 BN、冻结或重新校准统计量,或者使用不依赖 batch 的归一化方法。
Batch Renormalization 论文就明确讨论了小批量或非独立同分布 mini-batch 下的退化问题。具体替代方案要通过验证实验决定,不能只按“批量小于某个数字”机械切换。
分布漂移会让运行统计过期
推理依赖训练期间积累的运行统计。如果线上输入分布、图像预处理、传感器范围或数据增强流程与训练阶段不一致,运行均值与方差就可能不再代表当前数据。迁移学习中冻结骨干网络也要明确:是只冻结 、,还是连 BN 运行统计一起冻结?不同框架对 trainable 与训练模式的交互并不完全相同。
一种实用排查方法是对比同一验证集在 train/eval 两种模式下的输出与指标,再检查各层运行统计是否异常。若差异很大,应先确认模式、预处理和统计量,而不是立刻调学习率。
BN 不等于正则化承诺
训练时的批统计会引入噪声,原始论文也观察到一定正则化效果。但这不保证 BN 可以替代 Dropout、权重衰减或数据增强。大批量、同步统计、任务结构和实现细节都会改变这种噪声。是否减少其他正则化,应以验证集和多次运行结果为准。
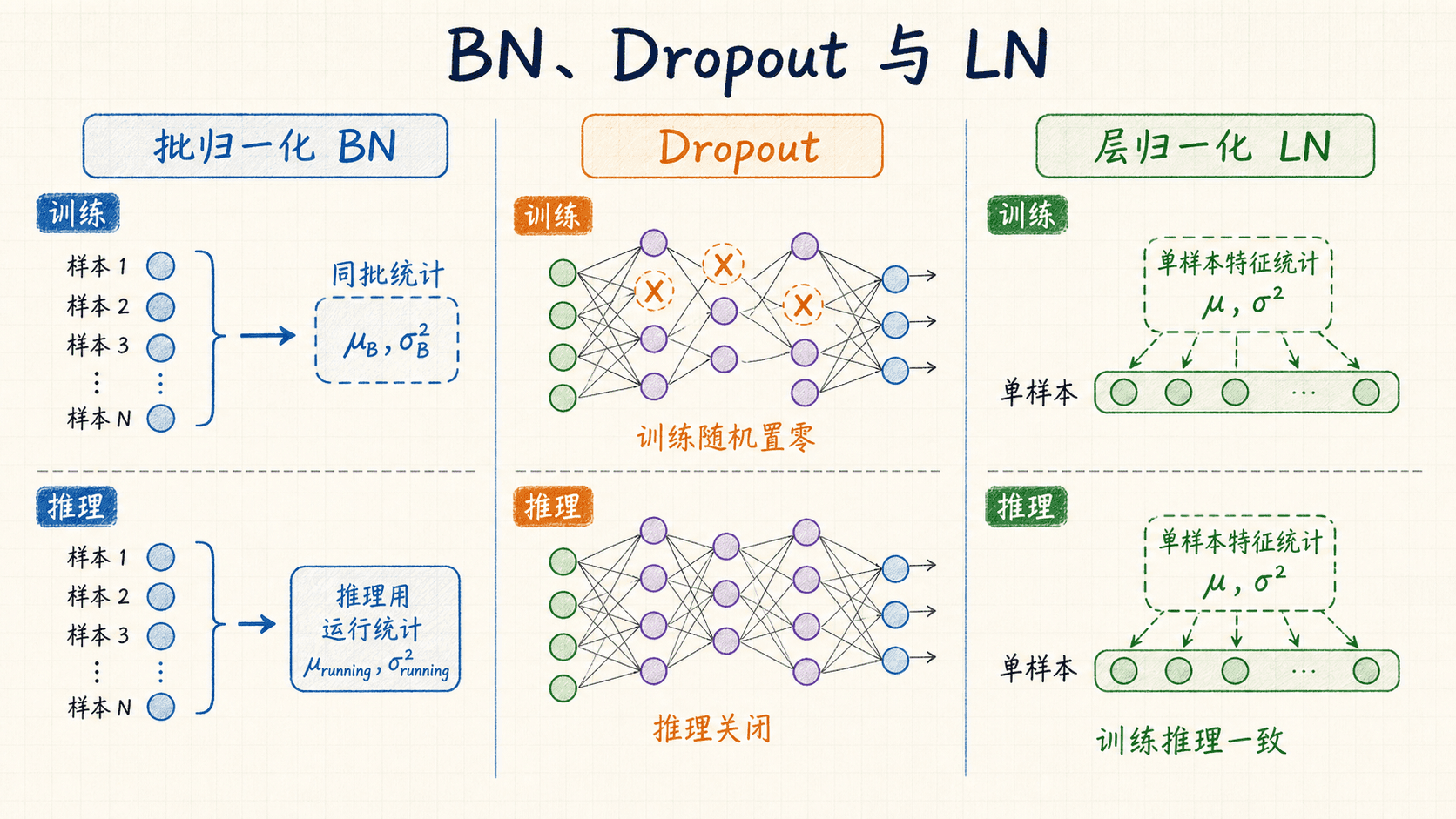
PyTorch 的 LayerNorm 文档说明它在训练和评估阶段都使用当前输入计算的统计量。它不是“更好的 BN”,而是统计维度与适用约束不同。选择哪一种,要看模型结构、批量条件、部署模式和验证结果。
15
哪些情况可能让 Batch Normalization 的效果或推理一致性变差?
16
下面哪项最准确地描述 BN 与 Dropout 的关系?
数值稳定的 Softmax 与交叉熵
多分类网络的最后一层通常输出 个 logits:。它们是未归一化分数,可以是任意实数。Softmax 把它们转换成和为 1 的概率:
若标签是互斥单类别,真实类别为 ,交叉熵可写成:
直接计算 exp(z) 有溢出风险。例如 float32 中很大的正 logit 会让指数变成无穷。Softmax 对所有 logits 同减一个常数不变,因此通常减去最大值 :
此时最大的指数是 ,其余指数不大于 1,溢出风险明显降低。
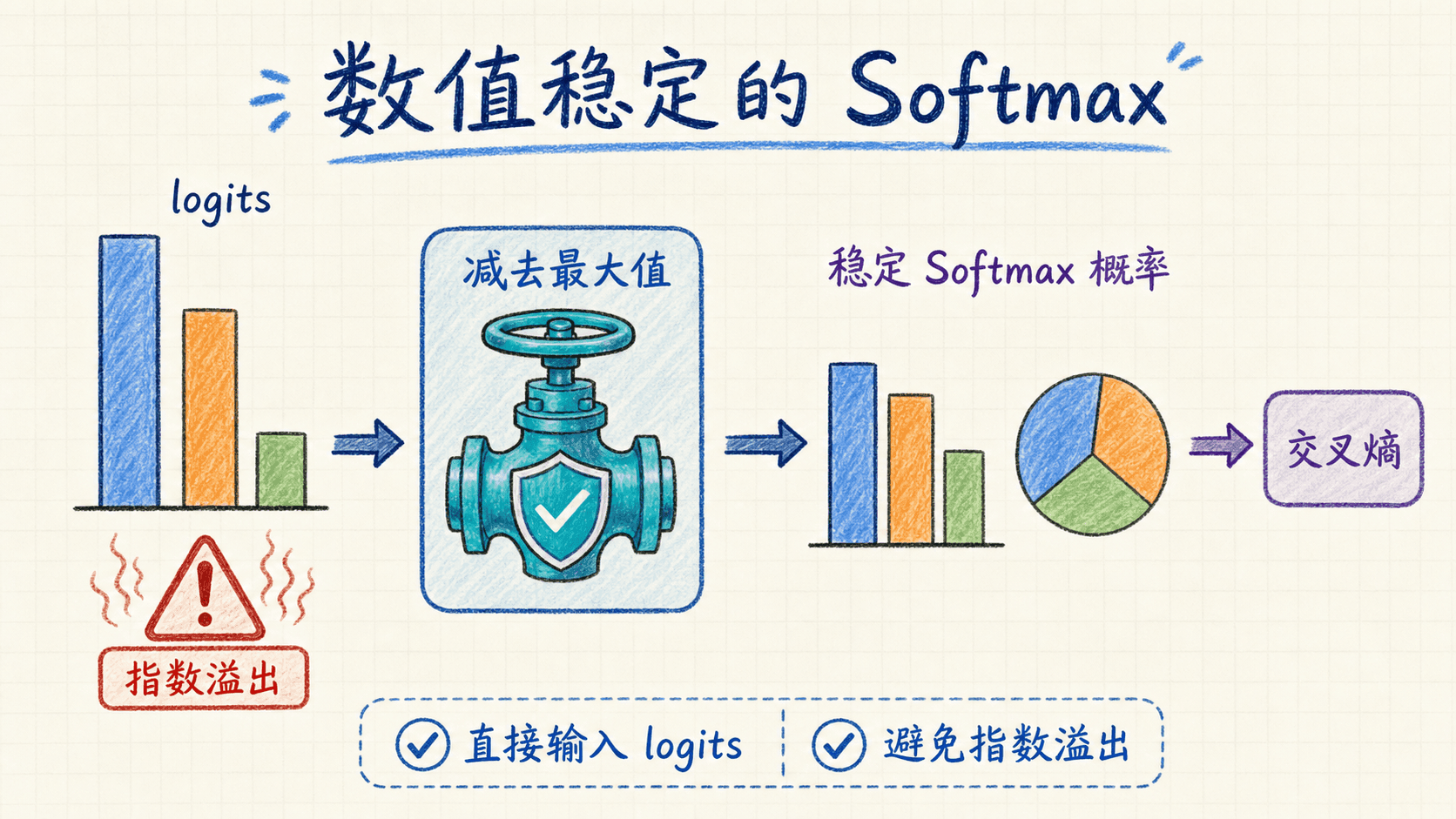
交叉熵最好直接接 logits
把 Softmax 和交叉熵合并,可以写成 log-sum-exp 形式:
稳定实现同样会减最大值:
PyTorch 的 log_softmax 文档明确说明,分开计算 log(softmax(x)) 更慢且数值不稳定;CrossEntropyLoss 文档则要求输入未归一化 logits,并说明类别索引形式等价于 LogSoftmax 加 NLLLoss。
python
import torch
import torch.nn.functional as F
logits = model(inputs) # shape: [batch, classes]
loss = F.cross_entropy(logits, targets)
probabilities = logits.softmax(dim=1) # 只在推理或展示概率时显式计算
predictions = probabilities.argmax(dim=1)不要先 softmax 再把概率传给 cross_entropy。那会重复应用变换,破坏损失的预期输入并降低数值稳定性。若一个样本可以同时属于多个类别,问题也不再是互斥 Softmax 分类,通常应对每个类别使用 sigmoid,并把 logits 交给融合的二元交叉熵实现,例如 BCEWithLogitsLoss。
对于单样本独热标签,Softmax 交叉熵对 logits 的梯度是:
这个简洁结果不意味着实现时要手写全部数值步骤。成熟框架的融合损失通常更稳定,也能利用优化内核。
17
为了避免指数溢出,稳定 Softmax 通常会先让所有 logits 减去其中的 ____。
18
在 PyTorch 中使用 CrossEntropyLoss 时,应先对模型输出调用 softmax,再把概率传入损失。
按约束选择框架而不是追榜单
框架选择很容易变成“谁最流行”的讨论,但项目真正付出成本的是迁移、调试、部署和维护。先做一个最小垂直切片:读取真实数据,跑一次训练与评估,导出模型,并在目标设备上完成一次推理。这个小实验比只比较 API 示例更能暴露问题。
先问清楚六个实际问题
- 现有资产:团队已有模型、数据管线、监控和部署平台用什么?重写成本是否值得?
- 算子与模型支持:目标架构、稀疏算子、量化或自定义算子能否稳定运行?
- 调试体验:形状、梯度、数值异常和性能瓶颈是否容易定位?
- 训练规模:单机、多机、容错、检查点和混合精度是否满足实际规模?
- 部署目标:服务端、浏览器、移动端或嵌入式的导出链路是否可验证?
- 维护边界:版本生命周期、社区支持、依赖冲突和团队招聘成本如何?
PyTorch、TensorFlow/Keras 和 JAX 都有成熟用途,但它们的强项和限制会随版本、硬件与生态变化。可以分别从 PyTorch 官方教程、TensorFlow 指南和 JAX 文档开始验证,不要把旧文章里的“研究框架”或“生产框架”标签当成永久结论。
用同一张验收表做短测
给候选框架设置相同任务和预算,记录:达到基线指标所需时间、峰值显存、数据吞吐、编译或启动开销、分布式扩展难度、导出后数值误差、目标硬件延迟,以及团队修改一处模型逻辑所需时间。
如果一个框架训练快 8%,却需要额外维护一套没人熟悉的部署链路,这 8% 未必能覆盖长期成本。反过来,如果项目确实受训练规模限制,分布式与编译能力就可能比 API 熟悉度更重要。选择标准必须从项目约束里来。
走完这一章,下一次模型表现不理想时,我们就不必从“再换一个框架”或“再加一层网络”开始。先确认评估边界,再查看训练曲线和试验记录;需要调参时设计空间与预算,需要 BN 时检查统计轴和模式,需要多分类损失时直接从 logits 使用稳定实现。这样每一次实验都会留下可复用的信息。
19
选择深度学习框架时,哪些因素通常比单一流行度榜单更值得验证?
20
比较候选框架时,最有信息量的第一步通常是什么?