优化算法:让每一步更新都算数
反向传播回答的是“参数往哪个方向改”,优化器处理的则是“这一步走多远、要不要参考过去、不同参数是否走同样的距离”。这两件事常被揉成一句“用 Adam 训练”,结果一旦损失不降,我们就不知道应该查数据、梯度、学习率,还是优化器状态。
这一章从一次参数更新开始,把 mini-batch、指数移动平均、Momentum、RMSProp、Adam 与 AdamW 串成一条线。学习率调度和梯度裁剪会放在这条线的末端:它们不替代优化器,却会改变每一步实际发生的事。
本文统一用 表示优化器更新次数,用 表示第 次更新采用的学习率。不同教材和框架的“velocity”“momentum buffer”定义可能相差一个学习率或 系数;判断两段公式是否等价时,要连同参数更新式一起看。
从一批样本走出一步
设训练集有 个样本,单个样本的损失为 。如果每次都用整个训练集计算平均梯度,就是 batch gradient descent:
它给出的是当前训练集目标的精确梯度,但一次更新要遍历全部样本。数据很大时,等到“最准确的一步”算完,时间和显存带宽可能已经花掉很多。
另一端是 stochastic gradient descent,也就是每次只抽一个样本。单步便宜,梯度噪声却很大,而且逐样本运算往往无法充分利用现代硬件的并行能力。实践里更常见的是中间方案:从当前数据顺序中取 个样本组成 mini-batch ,用它们的平均梯度更新一次。
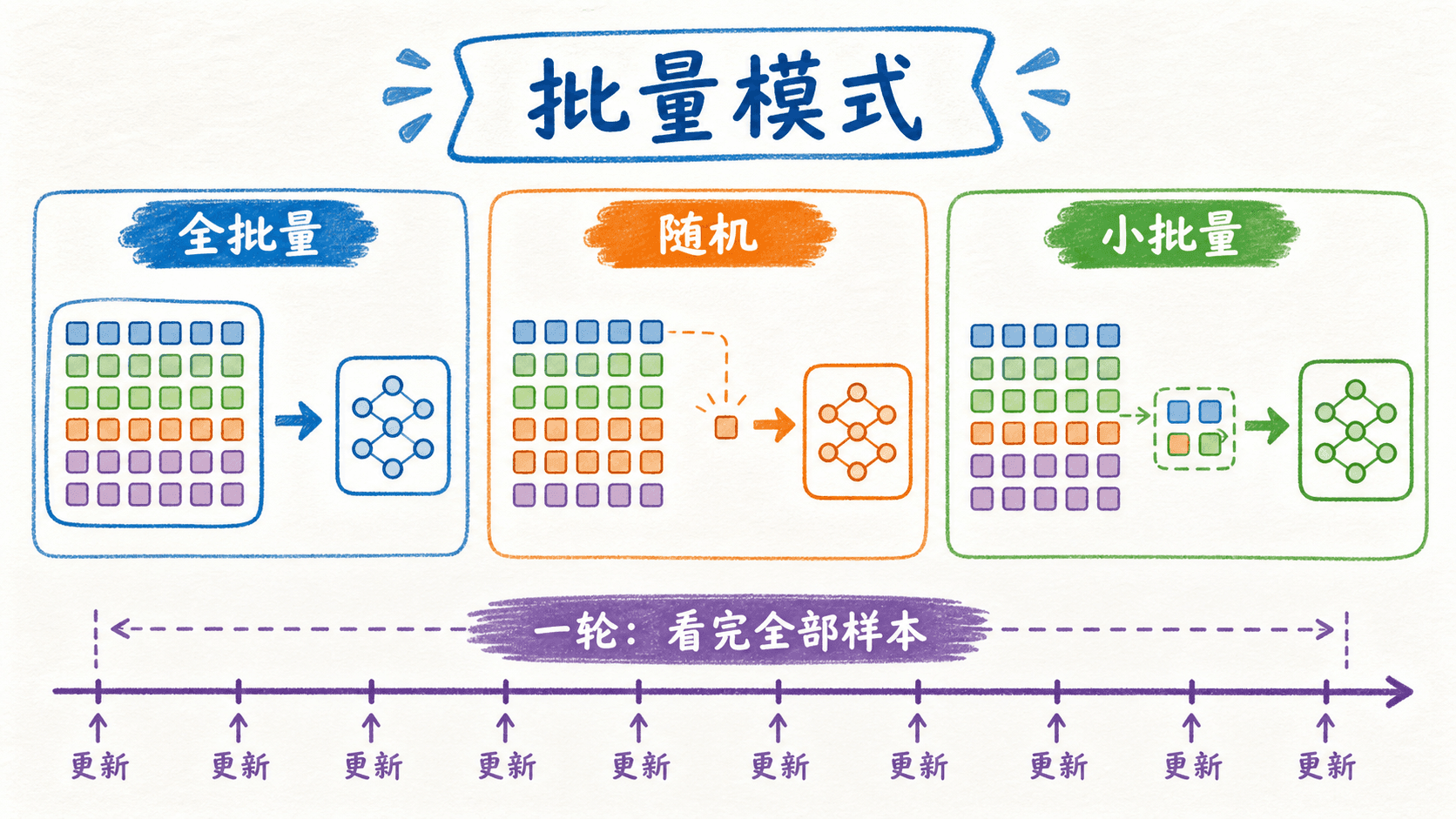
这里有三个容易混淆的计数:
- batch size 是一次前向、反向计算包含的样本数。
- step 通常指一次
optimizer.step(),也就是参数真正更新一次。使用梯度累积时,多个 micro-batch 才对应一个 step。 - epoch 是训练流程把训练集遍历一遍。若不丢弃最后不足 的批次,一个 epoch 大约有 个 step;若开启
drop_last=True,则是 个。
批量大小不是越大越好
增大 batch size 通常能降低梯度估计的波动,并提高设备吞吐,代价是更高的显存占用。更大的 batch 还会减少每个 epoch 的参数更新次数,所以只比较“训练了多少个 epoch”并不总公平。小 batch 更新更频繁、梯度更嘈杂,但吞吐可能偏低;它是否带来更好的泛化取决于任务、学习率、归一化方法与训练预算,不能当成无条件结论。
选择 batch size 时,我更建议按这个顺序来:先找到不会溢出显存且吞吐合理的范围,再把学习率和调度器一同调节,最后用验证集判断。若 batch size 改了,至少记录每个 epoch 的 step 数和总样本数,否则实验表面上训练了同样久,实际更新预算不同。
每轮为什么通常要打乱
如果样本按类别、来源或时间排序,连续 mini-batch 可能长期偏向某一部分数据。每个 epoch 重新打乱索引,能让 mini-batch 更接近从训练集抽样的估计。时间序列、因果序列和有状态采样是例外:顺序本身携带信息时,不能为了“随机”破坏任务定义。
下面的 NumPy 版本只打乱索引,不复制整份数据,并保留最后一个不完整批次:
python
import numpy as np
def iterate_minibatches(X, y, batch_size, rng):
indices = rng.permutation(len(X))
for start in range(0, len(X), batch_size):
batch_indices = indices[start:start + batch_size]
yield X[batch_indices], y[batch_indices]
rng = np.random.default_rng(42)
for X_batch, y_batch in iterate_minibatches(X, y, batch_size=
小测
1
训练集有 1000 个样本,batch size 为 128,保留最后一个不足 128 的批次。一个 epoch 有多少次参数更新?
2
比较不同 batch size 的实验时,哪些信息应该一同记录?
指数移动平均:给最近的历史更大权重
Momentum、RMSProp 和 Adam 都在保存“过去梯度的摘要”。理解它们之前,先看指数移动平均(exponential moving average,EMA):
把递推式展开,当前观测 的权重是 ,前一个观测的权重是 ,越久远的项会再多乘一个 。因此 越接近 1,曲线越平滑,响应新变化也越慢。 常被用作“有效窗口长度”的粗略直觉,但它不是一个硬截断窗口。
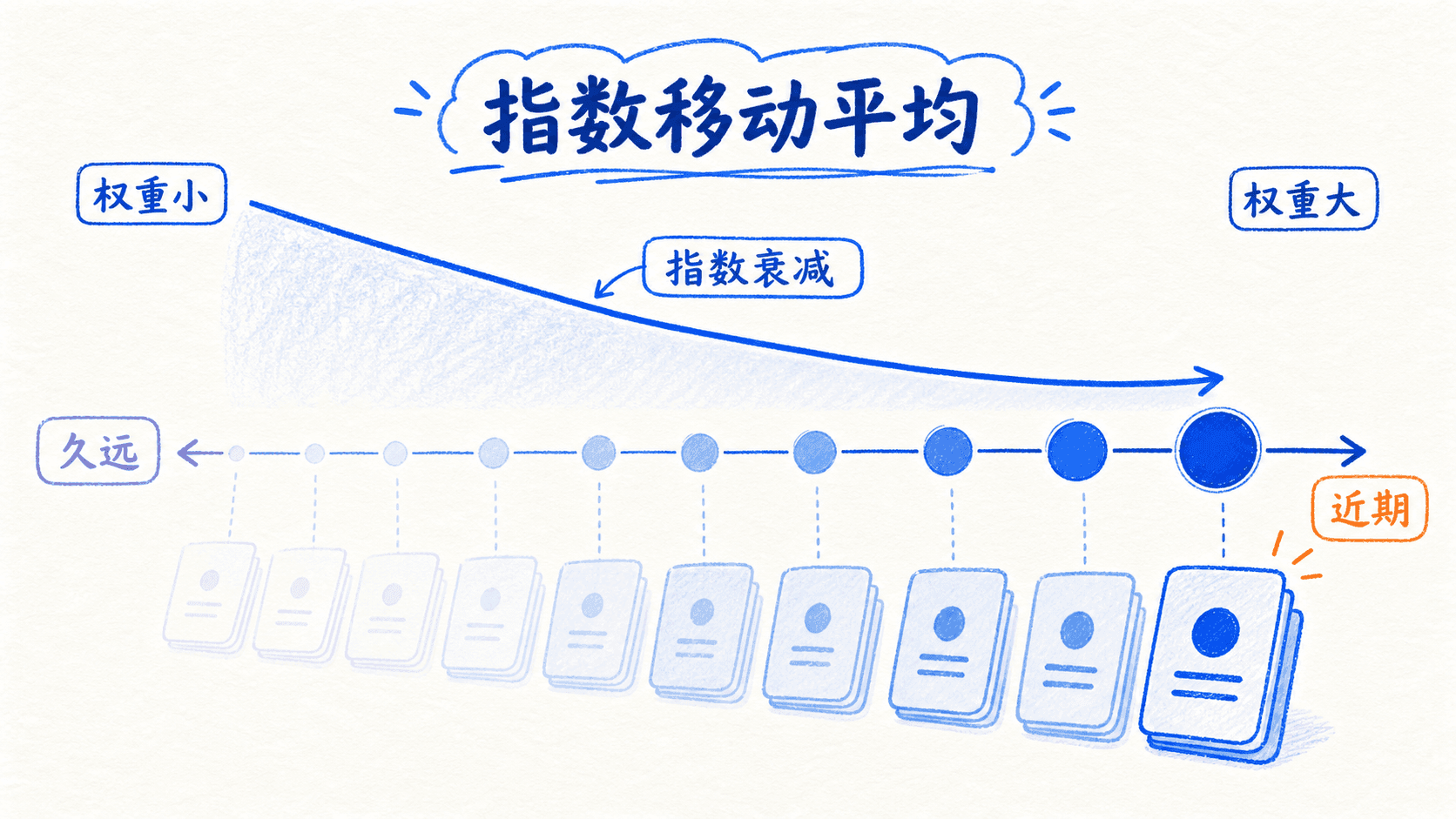
如果初始化 ,训练刚开始时,尚未积累足够历史, 会被零初始化向下拉。对均值近似稳定的序列,可以除以 做零初始化偏差修正:
这个修正只针对“从零开始导致权重和不足 1”。它不会让带噪声的 mini-batch 梯度变成真实梯度,也不能消除训练过程中分布不断变化带来的误差。
不要把 EMA 状态和模型参数的 EMA 混为一谈。本章公式里的状态服务于优化器更新;有些训练流程还会另存一份模型权重的移动平均用于评估,那是另一套状态。
小测
3
只要对 EMA 做了除以 1-β^t 的修正,它就等于完整训练集上的精确统计量。
4
在其他条件相同时,把 β 从 0.9 调到 0.99,EMA 通常会怎样变化?
Momentum 与 Nesterov:让方向具有连续性
普通 SGD 只看当前梯度。在狭长的损失曲面里,梯度可能在陡峭方向来回换号,却在平缓方向长期保持相近方向,于是轨迹呈锯齿状。Momentum 把过去梯度累进一个缓冲区:一致的方向会持续累积,频繁换号的分量会部分抵消。
一种常见写法是:
其中 是动量系数。也有教材把当前梯度写成 ,或者把学习率放进 ;它们的数值尺度和最佳学习率并不相同。PyTorch 的 SGD 使用上面这类 momentum buffer 定义,而且第一步会把缓冲区初始化为当前梯度。复现其他框架时,不能只对照参数名。
Nesterov 多看了哪里
经典动量先在当前位置算梯度,再把惯性和梯度相加。Nesterov 的直觉是先沿惯性方向看一个“预估位置”,再在那个位置计算梯度:
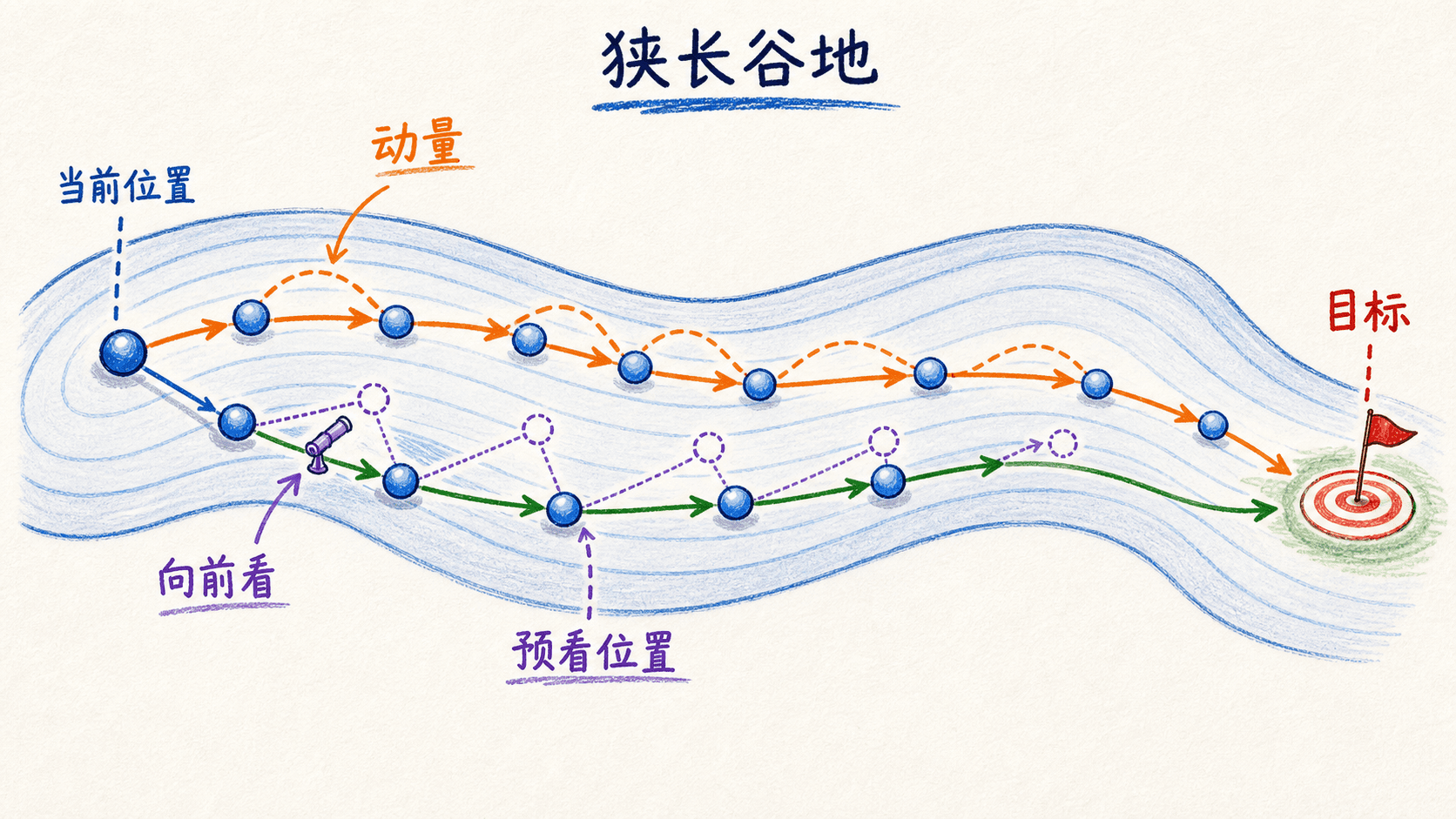
“向前看”允许梯度更早纠正惯性可能造成的过冲。不过,深度学习框架会用代数等价或近似等价的形式实现 Nesterov;实际代码应以框架文档为准。在 PyTorch 中,nesterov=True 还要求 momentum 非零且 dampening 为 0。
小测
5
Nesterov 与经典 Momentum 最核心的直觉差别是什么?
6
复现一组 Momentum 实验时,哪些差异可能让同名超参数产生不同轨迹?
RMSProp:按坐标缩放当前梯度
Momentum 主要处理“方向是否持续一致”。RMSProp 关注另一件事:某个参数坐标最近的梯度平方是否一直很大。它维护梯度平方的 EMA:
这里的平方、开方和除法都按元素进行。更新式为:
如果某个坐标近期梯度平方较大,分母随之变大,这个坐标的有效步长会被压低;近期梯度平方较小的坐标则受到较少压缩。它可以缓解不同坐标尺度差异造成的更新失衡,但不意味着每个方向都会自动获得正确学习率。
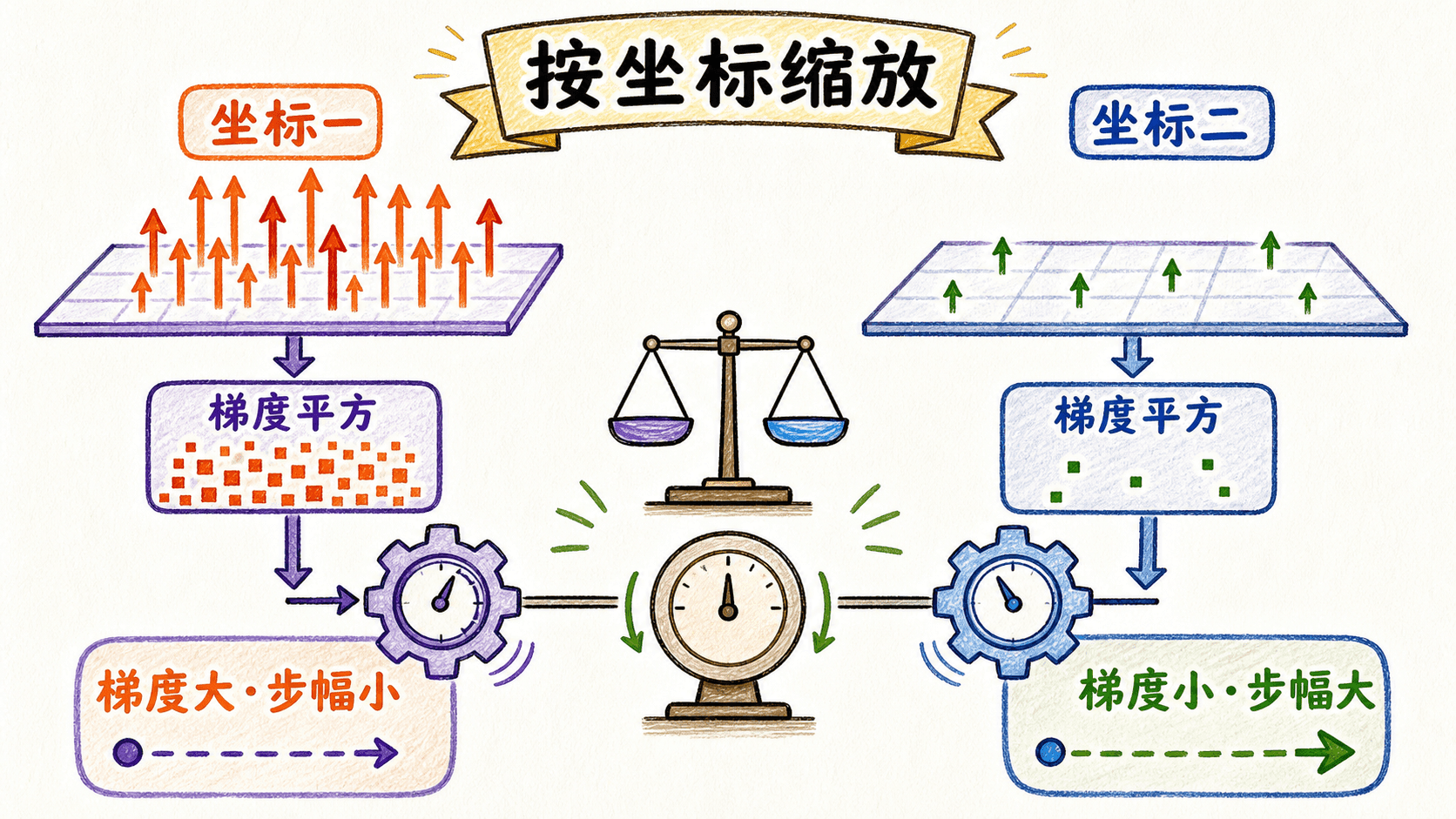
epsilon 的位置要写清楚
用于数值稳定。本文采用 PyTorch 的形式 ,也就是先开方再加 epsilon。TensorFlow 的 RMSProp 公式约定可能把 epsilon 放进平方根。两种写法在 很小时并不相同,因此复现实验要同时核对框架、版本和 。
标准 RMSProp 通常不对零初始化的 做 Adam 式偏差修正。训练最初几步的缩放会受初始化影响,这也是实现细节的一部分,而不是可以随手补上的“缺失步骤”。
小测
7
RMSProp 的状态 v_t 累积的是梯度的 ____ 的指数移动平均。
8
本文和 PyTorch RMSProp 采用的分母是 sqrt(v_t + epsilon)。
Adam:同时保存一阶矩与二阶原始矩
Adam 把两条线合到一起:用梯度的 EMA 保存方向信息,用梯度平方的 EMA 保存逐坐标尺度信息。论文把它们称为一阶矩和二阶原始矩(uncentered second moment)的估计:
注意, 不是方差。方差需要考虑均值,而这里直接平均梯度平方。由于 ,论文对两者都做零初始化偏差修正:
最终更新为:
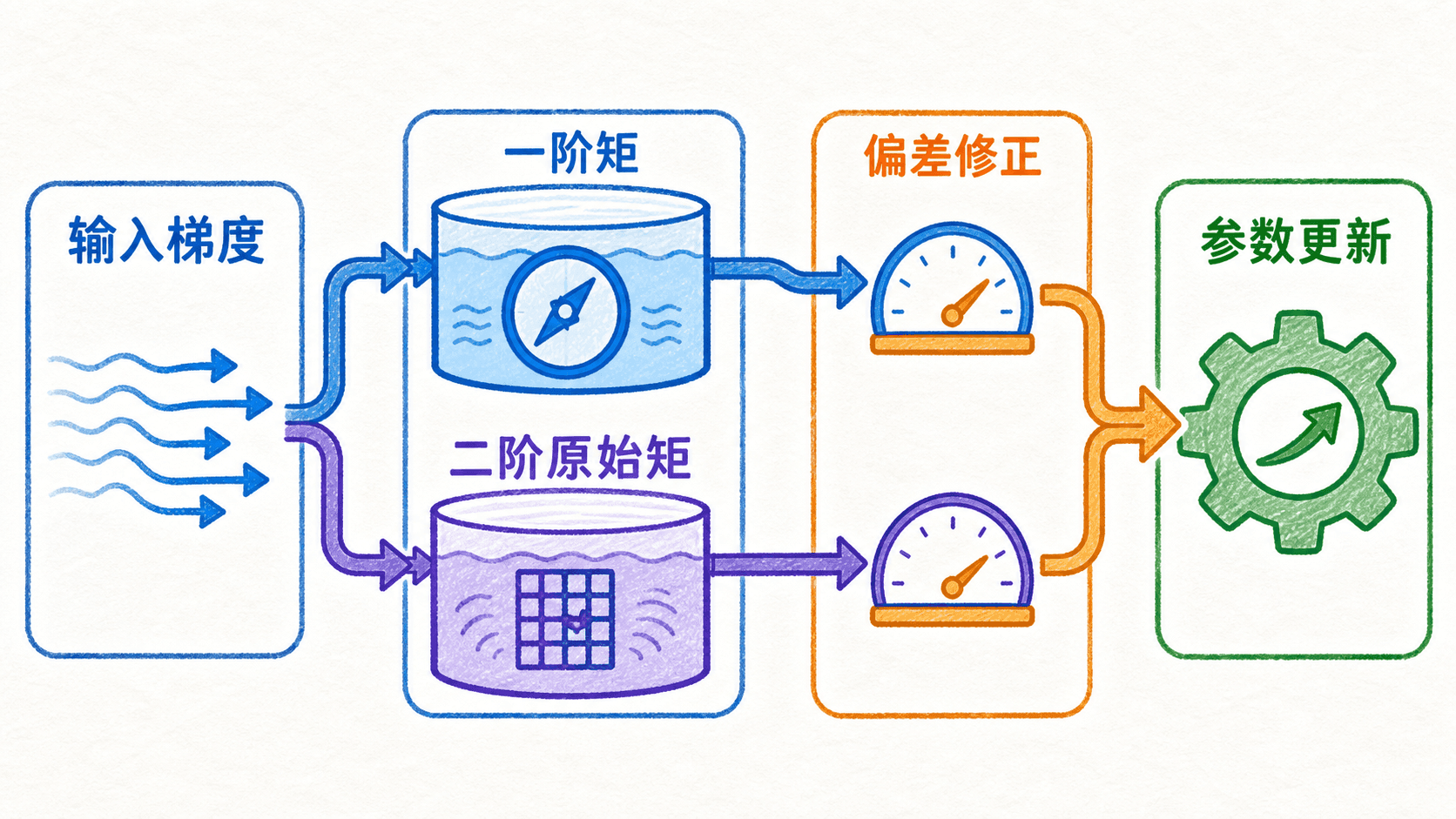
偏差修正为什么在开头显眼
当 很接近 1 时,未修正的 在最初几步尤其接近零。如果直接拿它做分母,更新尺度会被零初始化扭曲。除以 后,状态的权重和被校正。随着 增大, 接近零,修正因子逐渐接近 1。
论文给出的常用默认值是 、、,并以 为建议步长。它们是起点,不是“通常无需调整”的保证。模型规模、归一化、batch size、训练时长和权重衰减都会改变合适的学习率。
用 NumPy 对照一次更新
python
import numpy as np
def adam_step(theta, grad, state, step, lr=1e-3,
beta1=0.9, beta2=0.999, eps=1e-8):
"""step 从 1 开始;所有平方和除法均为逐元素运算。"""
m, v = state
m = beta1 * m + (1.0 - beta1) * grad
v = beta2 * v +
Adam 保存的“矩”是随训练变化的梯度统计摘要。把 叫作真实梯度均值、把 叫作真实方差都会过度解释这些量。
小测
9
Adam 中 v_t 更准确的称呼是什么?
10
关于 Adam 的偏差修正,哪些说法正确?
AdamW:把权重衰减移出自适应梯度
“在损失中加入 惩罚”和“每步直接缩小权重”在普通 SGD 中经过系数换算可以等价,但放进 Adam 这类自适应优化器后,两条路径不同。
如果把 项加到目标函数,优化器接收到的梯度是:
Adam 会把 同时送入一阶矩和二阶原始矩。正则项因此也会被动量累积,并被逐坐标分母缩放。
AdamW 的思路是让矩状态只处理数据损失的梯度,再单独对参数做衰减。省略矩更新细节后,可以写成:
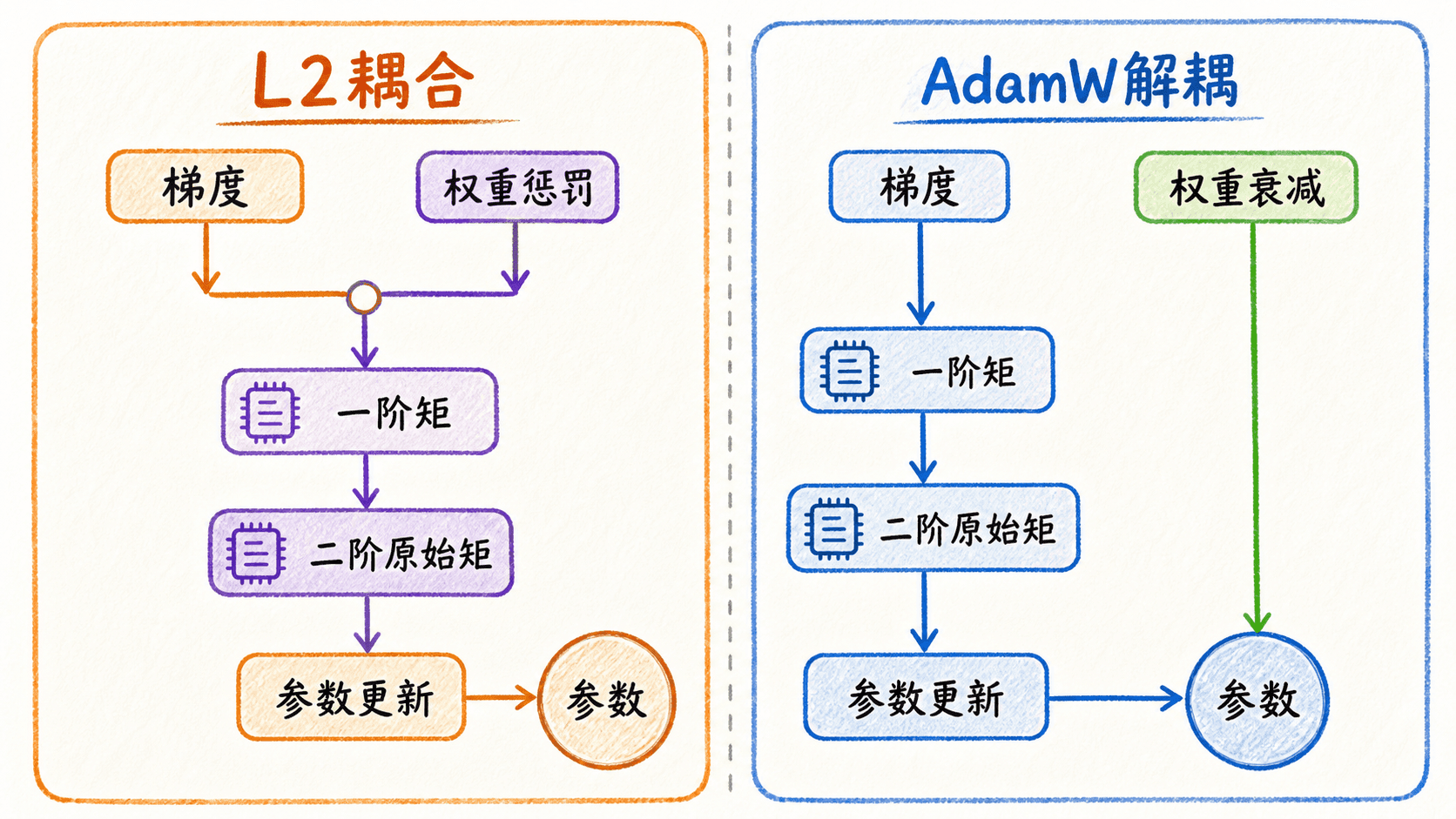
这就是“decoupled weight decay”里的解耦:衰减项不进入 momentum 和 variance buffer。它并不表示权重衰减与学习率完全无关;上式里单步缩小因子仍含 。论文讨论的是把正则化梯度从自适应更新通路中移开,使超参数作用更容易区分。
哪些参数应该衰减
是否对 bias、归一化层的缩放与偏移参数应用衰减,要根据模型和已有训练配方决定。常见做法是为它们建立 weight_decay=0 的参数组,但这不是 AdamW 公式自动替你完成的事。要公平复现实验,参数分组规则也应进入配置和日志。
看到 API 参数叫 weight_decay,不能直接推断它是 梯度还是解耦衰减。PyTorch 的 AdamW 明确使用解耦形式;其他优化器和旧实现需要查对应文档。
小测
11
对 Adam 来说,在损失中加入 L2 项与使用 AdamW 的解耦权重衰减总是等价。
12
AdamW 的‘解耦’主要指什么?
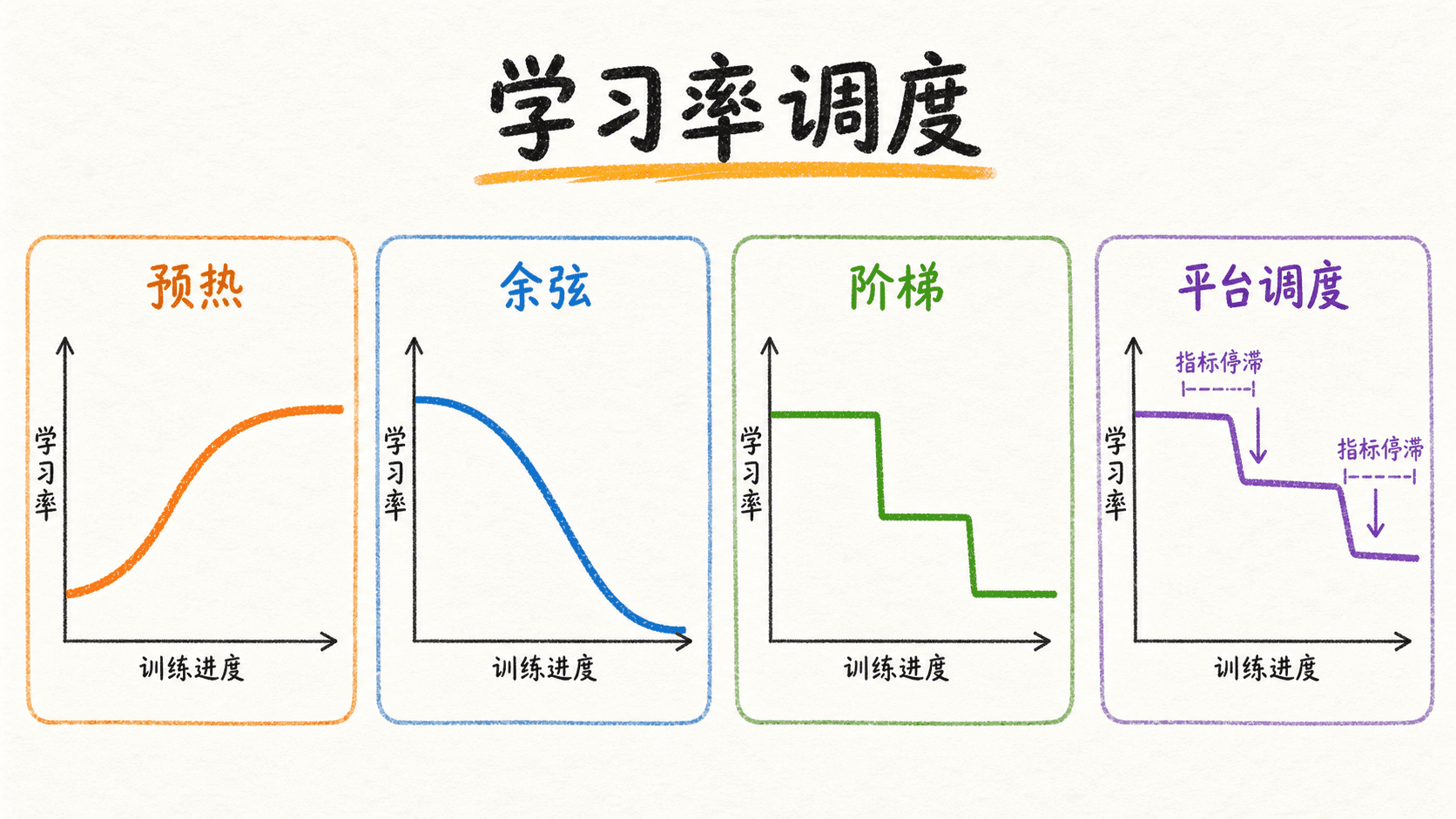
学习率调度:决定训练不同阶段的步幅
优化器给出方向和坐标缩放,学习率 仍控制整体步幅。固定学习率并非错误;当训练预算短、目标稳定或我们还在定位问题时,固定值反而便于解释。调度器适合解决明确的阶段需求。
预热:先从小步幅升到目标值
线性 warmup 可以写成:
它常用于大 batch、深网络或训练初期状态尚不稳定的配方。warmup 不是修复任意发散的胶带:如果数据有 NaN、损失实现错误或目标学习率本身过大,延长预热只会推迟问题出现。
衰减:在给定训练预算内逐渐缩小步幅
余弦衰减的一种闭式写法是:
它要求我们大致知道衰减阶段长度 。阶梯衰减、指数衰减也属于按时间表前进的调度:无论验证集是否改善,到指定 step 或 epoch 都会改变学习率。这类方案容易复现,适合训练预算事先固定的实验。
平台调度:让验证指标决定何时降速
ReduceLROnPlateau 监控一个指标,在连续若干次评估没有达到改善阈值后降低学习率。它适合训练轮数不易事先确定、但验证指标可靠的任务。指标噪声很大时,需要设置合理的 patience、threshold 和评估频率,避免把随机波动误判成平台。
scheduler.step() 的语义
PyTorch 文档建议常规 scheduler 在 optimizer.step() 之后调用。若按每个 mini-batch 调一次,T_max、total_iters 等计数就是优化器 step;若每个 epoch 调一次,它们就是 epoch。ReduceLROnPlateau 则要在验证完成后把监控指标传给 scheduler.step(metric)。代码能运行不代表计数单位正确,日志里应记录实际学习率。
小测
13
下列哪些场景与调度策略的匹配是合理的?
14
PyTorch 的 ReduceLROnPlateau 通常应在完成验证后,把监控的 ____ 传给 scheduler.step(...)。
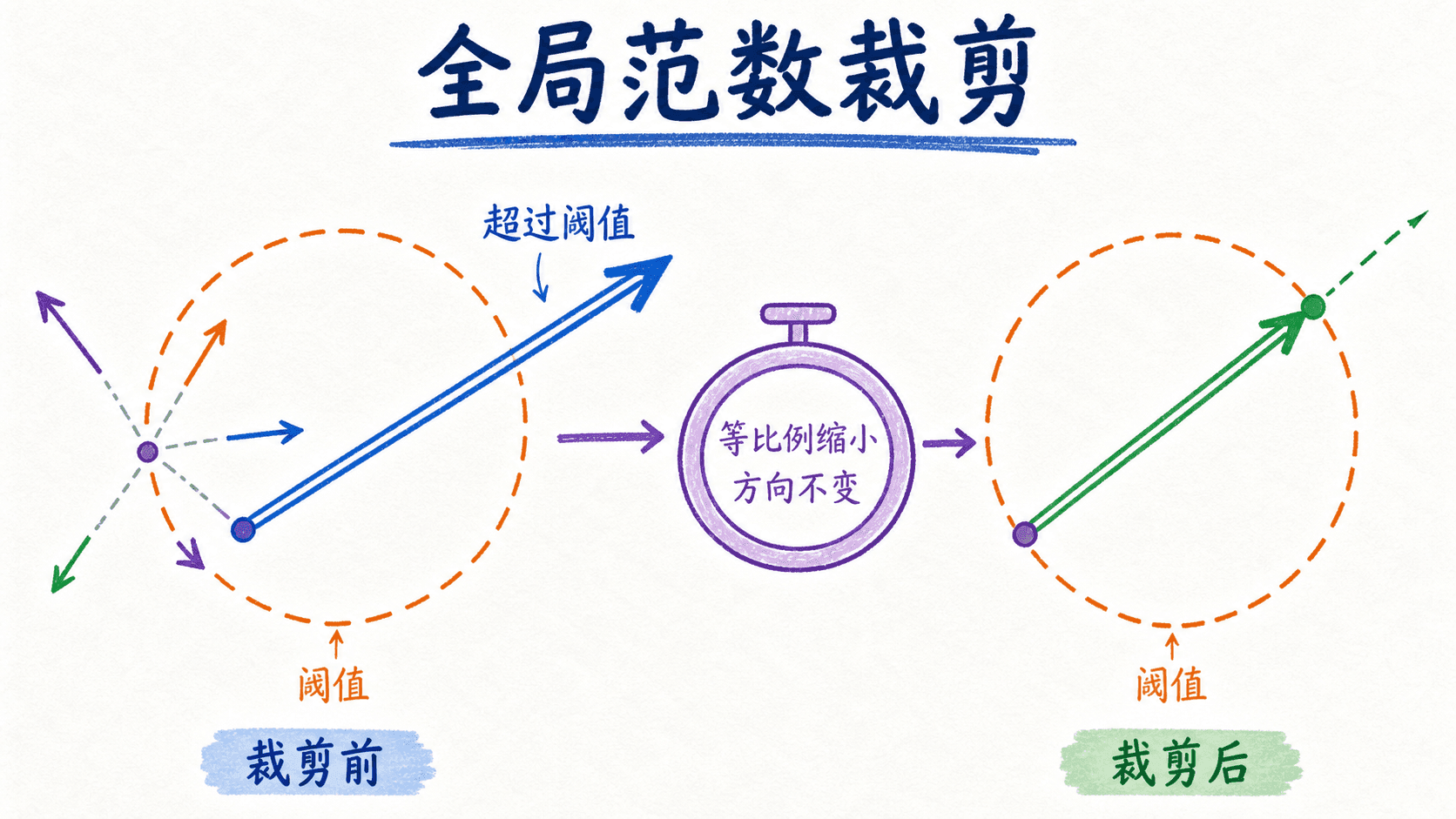
梯度裁剪:限制异常更新,不掩盖异常来源
当循环网络、很深的网络或不稳定批次产生极大的梯度范数时,一次更新就可能把参数推到数值危险区。全局范数裁剪把所有参数梯度视为一个长向量,计算其 范数。以二范数阈值 为例:
若范数没有超过阈值,梯度保持不变;超过阈值时,所有分量按同一比例缩小,因此全局范数裁剪保留整体方向。逐元素 value clipping 会分别截断分量,可能改变方向,两者不能混称。
正确放进训练顺序
普通精度训练常见顺序是 loss.backward()、裁剪、optimizer.step()。使用自动混合精度和梯度缩放时,应先 unscale,再裁剪,否则阈值比较的是被放大的梯度。使用梯度累积时,通常对累积完成、即将更新的梯度裁剪,而不是每个 micro-batch 各裁一次。
裁剪阈值太低,会让大部分 step 都被缩放,训练实质上长期受阈值控制。阈值太高则几乎不触发。建议同时记录裁剪前梯度范数、触发比例以及非有限值;clip_grad_norm_ 不会让已经是 NaN 的梯度恢复正常。
如果梯度突然变成 NaN 或 Inf,先检查输入、损失、除零、溢出和学习率。裁剪主要限制有限但过大的梯度;它不是数值错误的修复器。
小测
15
只要调用 clip_grad_norm_,NaN 梯度就会被变成有限值。
16
使用混合精度梯度缩放时,范数裁剪通常应放在哪里?
选择优化器,也要设计公平实验
不存在脱离任务的“最强优化器”。AdamW 常是现代深度模型的实用起点,因为它对不同坐标做自适应缩放,并把权重衰减移出矩状态;SGD 加 Momentum 状态更少、行为容易解释,在一些成熟视觉配方中也常被精细调优。RMSProp 仍可用于已有可靠配方或需要其特定更新行为的任务。最终选择应该来自验证集和资源预算,而不是算法流行度。
一个可执行的选择顺序
先用一个小而真实的数据子集确认损失会下降,检查标签、前向、反向和评估代码。此时保持优化设置简单,便于定位错误。
选择一个基线优化器,并先搜索学习率。对 AdamW 还要单独搜索权重衰减;不要把另一个优化器的学习率原样搬来后就宣布胜负。
固定训练/验证划分、模型初始化、数据顺序、增强、总 step 或总样本预算,并明确是否允许每个优化器采用各自调优后的调度器。
同时比较训练损失、验证指标、耗时、峰值显存和稳定性。至少重复若干随机种子,再报告均值与波动,而不是挑最好的一次。
日志要能还原一次更新
建议按 optimizer step 记录:训练损失、验证指标、学习率、梯度范数、参数范数、裁剪是否触发、吞吐与耗时。出现异常时,再查看 Adam 的矩状态是否爆炸或长期接近零。若使用梯度累积,还要记录 micro-step 与 optimizer step 的对应关系。
公平对比不等于所有算法使用同一组超参数。更合理的做法是给每个优化器相近的调参预算、相同的数据与计算预算,并公开各自找到的配置。否则“相同学习率”只是表面一致,因为不同更新式里的有效步长含义本来就不同。
PyTorch 训练骨架
下面示例按 optimizer step 做线性 warmup 和余弦衰减,并在更新前记录裁剪前梯度范数。warmup_steps 和 decay_steps 都以参数更新次数为单位。
python
import torch
optimizer = torch.optim.AdamW(
model.parameters(),
lr=3e-4,
betas=(0.9, 0.999),
eps=1e-8,
weight_decay=1e-2,
)
warmup_steps = 500
decay_steps = 9_500
total_steps = warmup_steps + decay_steps
warmup =
若训练使用 AMP,需要把示例中的更新部分换成 scaler.unscale_(optimizer)、裁剪、scaler.step(optimizer)、scaler.update() 的顺序。若使用 ReduceLROnPlateau,也不能沿用逐 step 的无参数调用,而应在验证后传入指标。
接到下一章:把调参变成可复现的搜索
这一章先建立了可观察的更新过程。下一章做超参数调优时,不要把优化器名字当作一个孤立开关,而要把学习率、batch size、权重衰减、调度器、warmup 长度和裁剪阈值视为一组相互作用的配置。先定义预算和评价指标,再决定搜索空间,实验结论才有可比性。
小测
17
做优化器公平对比时,哪些做法合理?
练习 18: 某次实验把 batch size 从 64 改成 512,仍训练 20 个 epoch,并沿用原学习率与调度器。验证结果变差。请列出在归因给“大 batch 泛化差”之前至少要核对的四项信息。