异常检测:从低密度分数到可运营的告警系统
异常检测听起来像一道简单的二选一题:正常,还是异常。真正做过一次线上告警,你很快就会发现,算法只负责其中一小段。我们还得回答:什么变化值得调查,训练数据能不能代表“正常”,分数该怎样变成阈值,每天能处理多少告警,以及设备升级后的一片高分究竟是故障还是分布漂移。
这一章从一个设备监控场景出发。假设我们持续收到 CPU 使用率、请求延迟、丢包率、错误率和网络流量,希望找出需要工程师复核的设备。我们会先实现对角高斯和多元高斯基线,再比较 Isolation Forest、One-Class SVM 与 LOF,最后把时间切分、阈值选择、人工复核和漂移监控接成一条完整流程。
本章把“异常分数”统一写成 ,并约定分数越大越异常。不同算法原始输出的方向可能相反,接入评估前要先统一。除非经过额外校准并验证,否则异常分数不是“故障概率”。
先定义异常,再选择算法
“出现得少”只是异常的一个线索,不是定义。某台服务器每周日凌晨运行全量备份,流量峰值很少见,却是计划内行为;另一台服务器的平均 CPU 只有 45%,看起来很普通,但它在没有请求时仍持续占用 CPU,这可能才值得调查。
更实用的定义是:在给定业务上下文中,某个观测与可接受的正常机制明显不一致,且这种不一致值得触发某种动作。 这里有三个不能省略的限定。
- 上下文决定比较对象。工作日中午的 2000 QPS 可能正常,凌晨三点同样的流量可能异常。
- 机制决定模型假设。一个多租户平台本来就有多种正常工作模式,不能强行用单峰高斯描述全部租户。
- 动作决定阈值。用于自动关机的告警需要极低误报率;用于分析师候选队列的告警可以更宽松。
异常还可以按形态分成三类:
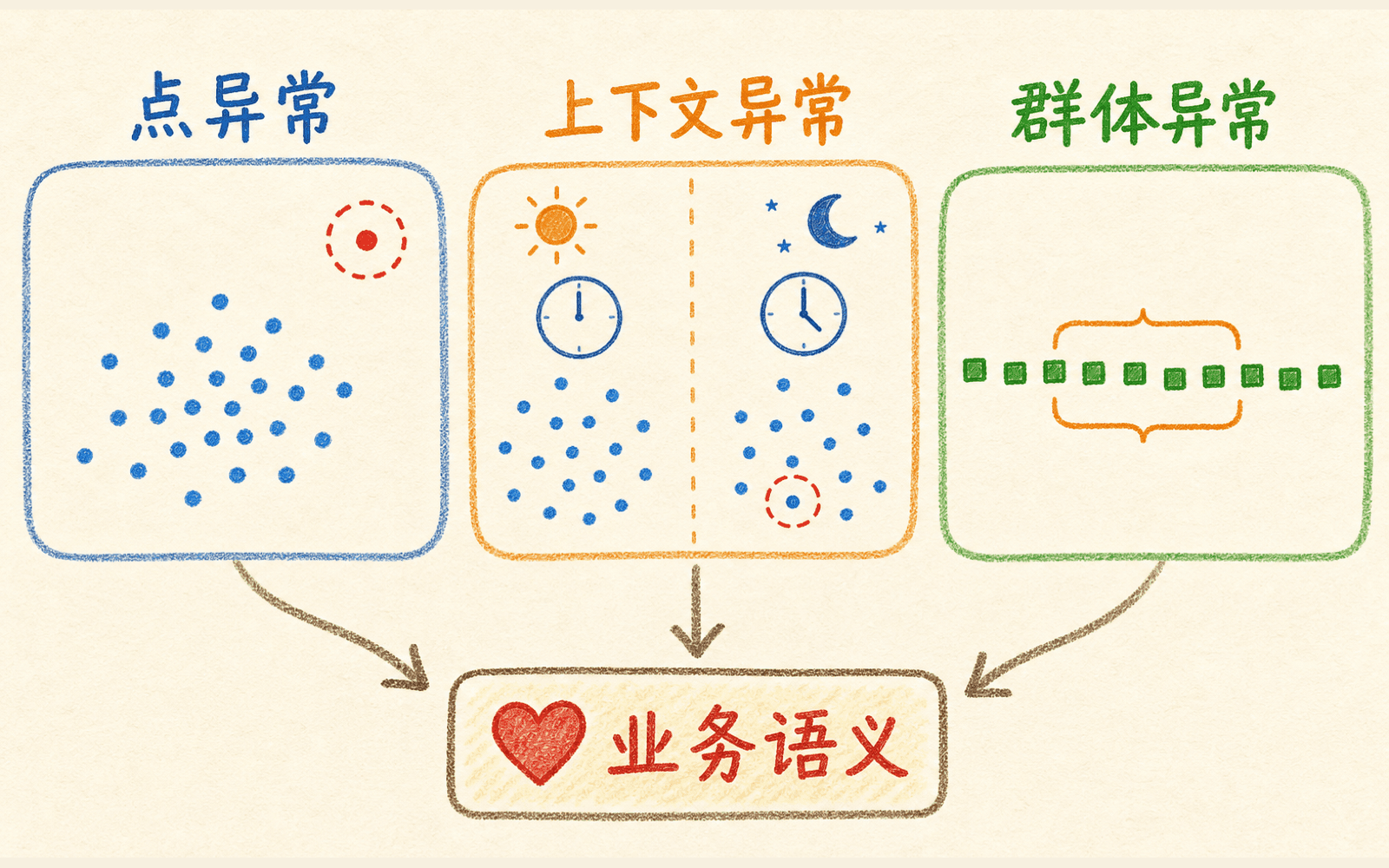
异常不是“离中心远”的同义词,必须先说明相对什么情境、会造成什么后果。
还有一组词要分清。离群点描述数据几何上的偏离;故障、欺诈、入侵描述业务标签;新颖点描述相对训练时正常分布的新样本。一个离群点可能只是测量错误,也可能是新产品上线后的合法流量。模型先提供调查线索,业务证据再决定它是什么。
不要看到最低密度的 1% 就写“发现了 1% 的故障”。你只知道模型把这 1% 排在最可疑的一端。它们是否真是故障,还要靠标签、规则、日志和人工复核确认。
1
关于“异常”的定义,下列哪些判断正确?
数据协议比模型名字更早决定结果
异常检测常见两种训练语义。第一种是新颖点检测:训练集尽量只放正常样本,模型学习正常支持区域,再判断未来新样本是否偏离。第二种是离群点检测:训练数据本身可能已混入少量异常,算法要从受污染的数据中找出偏离主体的点。
这两种语义不能只靠参数名字切换。若你能从历史工单中找出一段确认健康的设备数据,优先建立干净的正常训练基线;若日志从未清洗过,就要承认训练集受污染,并比较稳健协方差、Isolation Forest 等能容忍少量污染的方法。
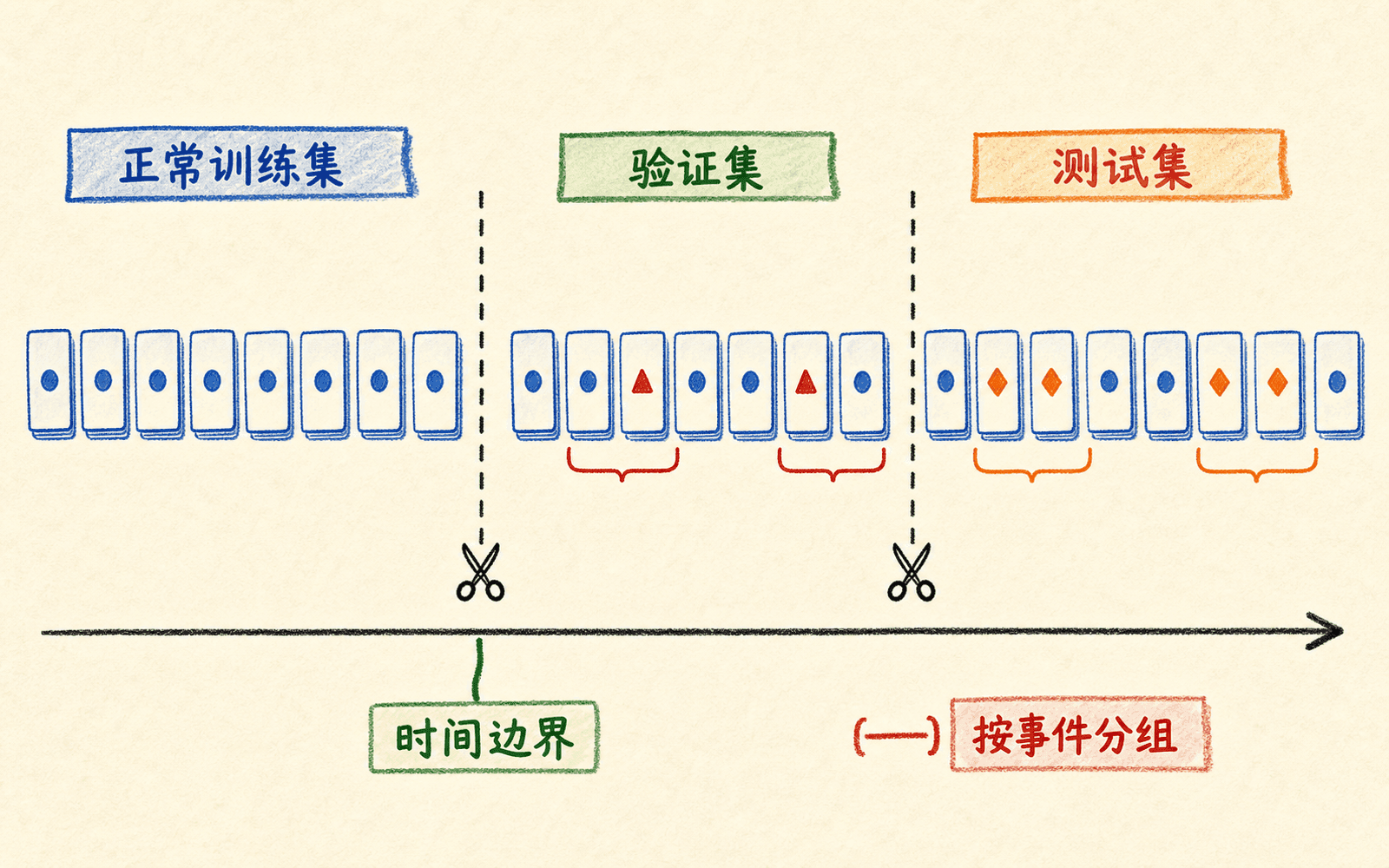
一个可复查的数据协议通常分成三部分:
模型可以只从正常数据学习,但阈值和最终评估仍需要独立异常证据。
异常事件要按事件划分,而不是把记录随机打散
假设一次网络入侵持续 30 分钟,产生 360 个五秒窗口。若把这些窗口随机分到验证集和测试集,两边会出现几乎相同的攻击片段,结果异常乐观。应先按事件编号、设备或用户分组,再切分;时序部署还要按时间先后切分,让测试期真正晚于训练期。
标签少时,宁可让验证集和测试集各包含较少但彼此独立的异常事件,也不要把同一个事件复制到两边。测试集太小会带来很宽的不确定区间,这不是通过重复使用测试集就能解决的,只能靠积累更多独立事件、时间窗口或专家复核样本改善。
“正常训练集”也可能藏着异常
训练集出现少量异常并不一定让模型完全失效,但会改变参数。高斯模型的均值和方差对极端点敏感;异常点可能把方差拉大,反过来让自己看起来没那么异常,这叫掩蔽。可以先做数据质量规则、已知故障剔除和稳健统计对照,但不能为了得到漂亮分数而删除所有“不顺眼”的正常变化。
2
一次设备故障产生了连续 500 个相似窗口。怎样划分最能减少验证集与测试集之间的泄漏?
单变量高斯先建立一条透明基线
高斯模型适合拿来学习异常检测的第一条基线,因为每一步都能解释。设某个正常特征 近似服从高斯分布:
它的概率密度函数是:
给定 个正常训练样本,最大似然估计为:
这里方差分母是 ,因为我们在写高斯最大似然估计。统计软件用于无偏样本方差时常用 ;两种约定回答的问题不同,代码和推导要保持一致。
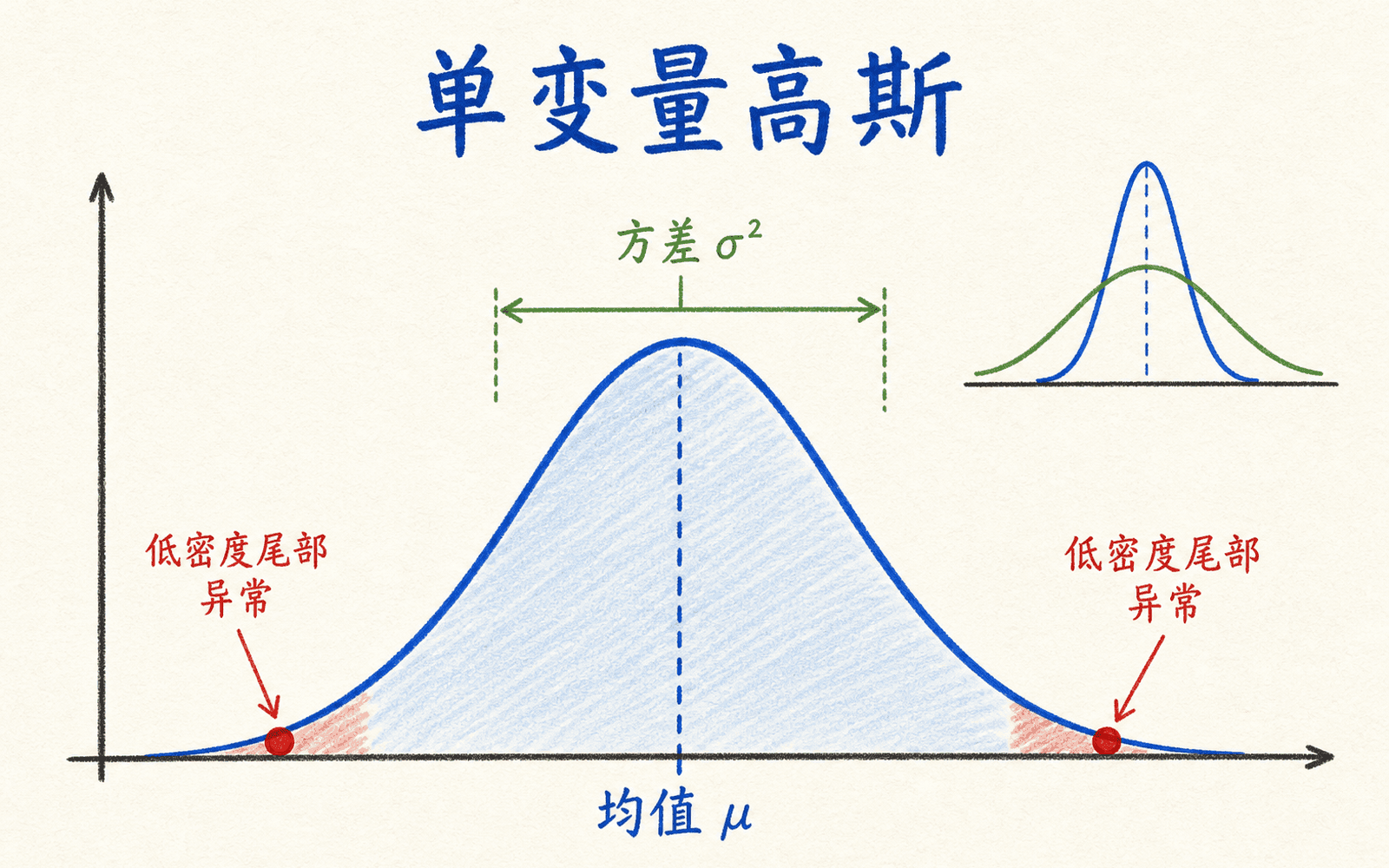
高斯基线把“常见”写成概率密度,把异常候选放在低密度区域。
密度不是区间概率
是某一点的概率密度,不是“这个样本正常的概率”。连续变量恰好取某一个值的概率为 0;只有对区间积分,才得到概率。密度值还依赖单位:把米换成厘米后,数值密度会变化,观测本身却没变。
因此,我们可以用同一模型、同一特征定义下的密度或对数密度给样本排序,却不能说“密度 0.8 表示 80% 正常”。不同版本改变了单位、特征或维数后,旧阈值通常也不能直接沿用。
单边异常与双边异常也要由业务定义
高斯密度会把远离均值的两端都打成低密度。对“温度过高或过低都危险”的传感器,这很合适;对“请求延迟只有过高才有害”的指标,单边规则或经过业务定义的特征可能更直接。数学上的尾部对称,不代表业务代价对称。
3
某样本在高斯模型下的密度为 0.7,因此可以直接解释为它有 70% 的概率是正常样本。
多特征乘积要在对数空间里计算
若先假设各特征条件独立,可以把每一维的高斯密度相乘:
这相当于协方差矩阵只保留对角元素。它不能表达“CPU 和请求量应该一起升高”这种相关结构,但参数少、计算快,也便于定位是哪一维贡献了异常分数。
维数一多,许多小密度连乘会下溢成 0。正确实现不直接算乘积,而是累加对数密度:
为了统一“越大越异常”的方向,定义:
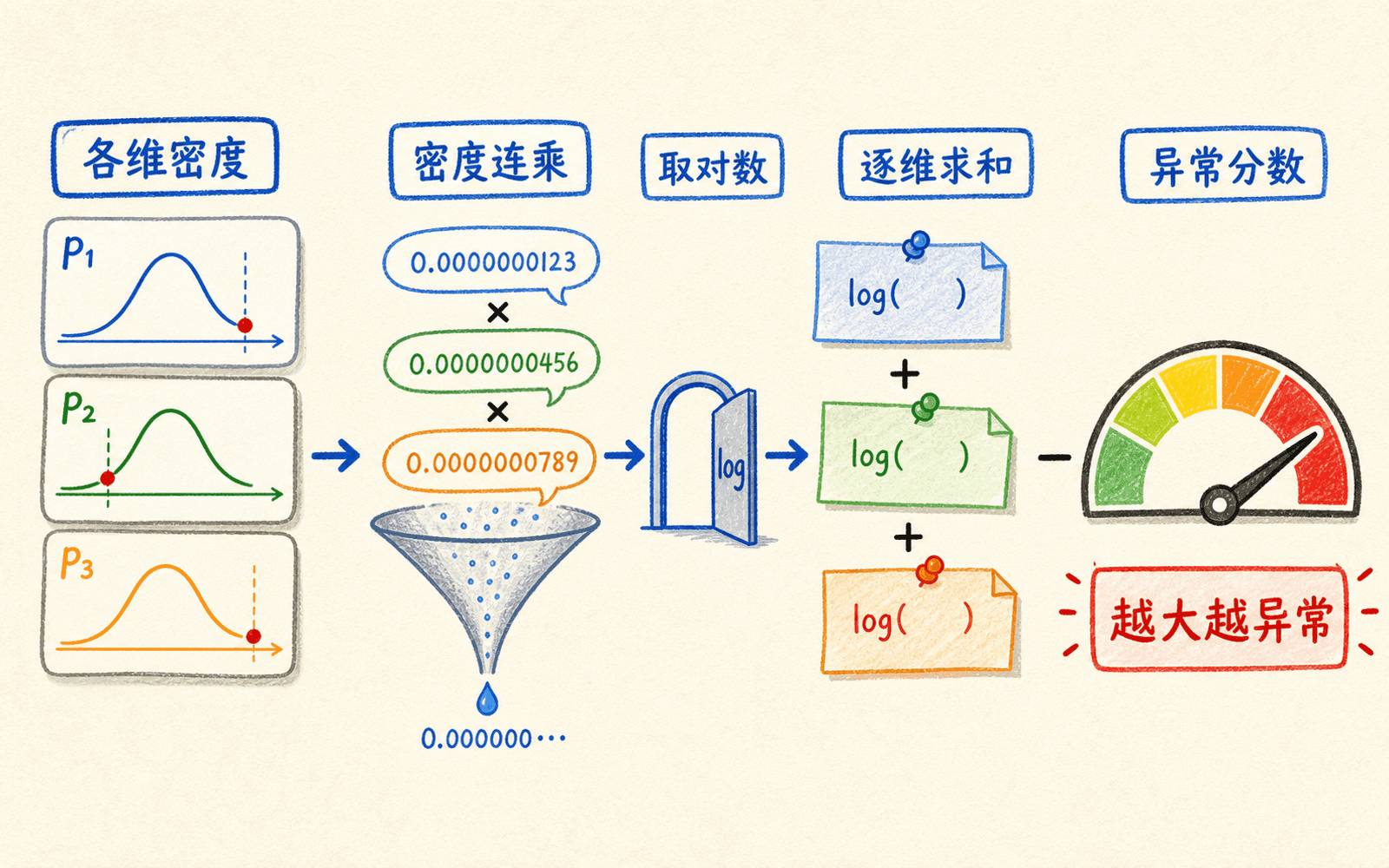
在对数空间相加既避免数值下溢,也能看清哪些特征主导告警。
零方差会让整条公式失效
若某列在训练期恒定,,除法与对数都会出错。先核对这列是否是无信息常量、采集故障,还是训练窗口太短。对有意义但变化极小的特征,可以设置基于训练尺度的方差下限:
是数值保护,不应悄悄掩盖数据问题。它的取值要记录并在验证集上检查。
下面的实现返回异常分数,而不是把密度误称为概率:
python
import numpy as np
class DiagonalGaussianDetector:
def __init__(self, variance_floor=1e-8):
self.variance_floor = float(variance_floor)
def fit(self, X_normal):
X = np.asarray(X_normal, dtype=float)
if X.ndim != 2 or len(X) < 2:
raise ValueError
4
若各维密度相乘得到 $p(x)$,并约定异常分数越大越异常,那么稳定的分数可写为 $s(x)=$ ____。
阈值不是公式附赠的答案
模型输出连续分数 ,阈值 才把它变成告警:
其中 表示告警。降低阈值会召回更多异常,也会增加误报;提高阈值则相反。不存在脱离场景的“最佳阈值”。
有少量标签时,用验证集选择工作点
对每个候选阈值,计算:
准确率在异常稀少时很容易骗人。若 10000 个样本中只有 10 个异常,全部预测正常也有 99.9% 准确率,却没有发现任何异常。PR 曲线展示不同阈值下精确率与召回率的交换,比单看准确率更有用。
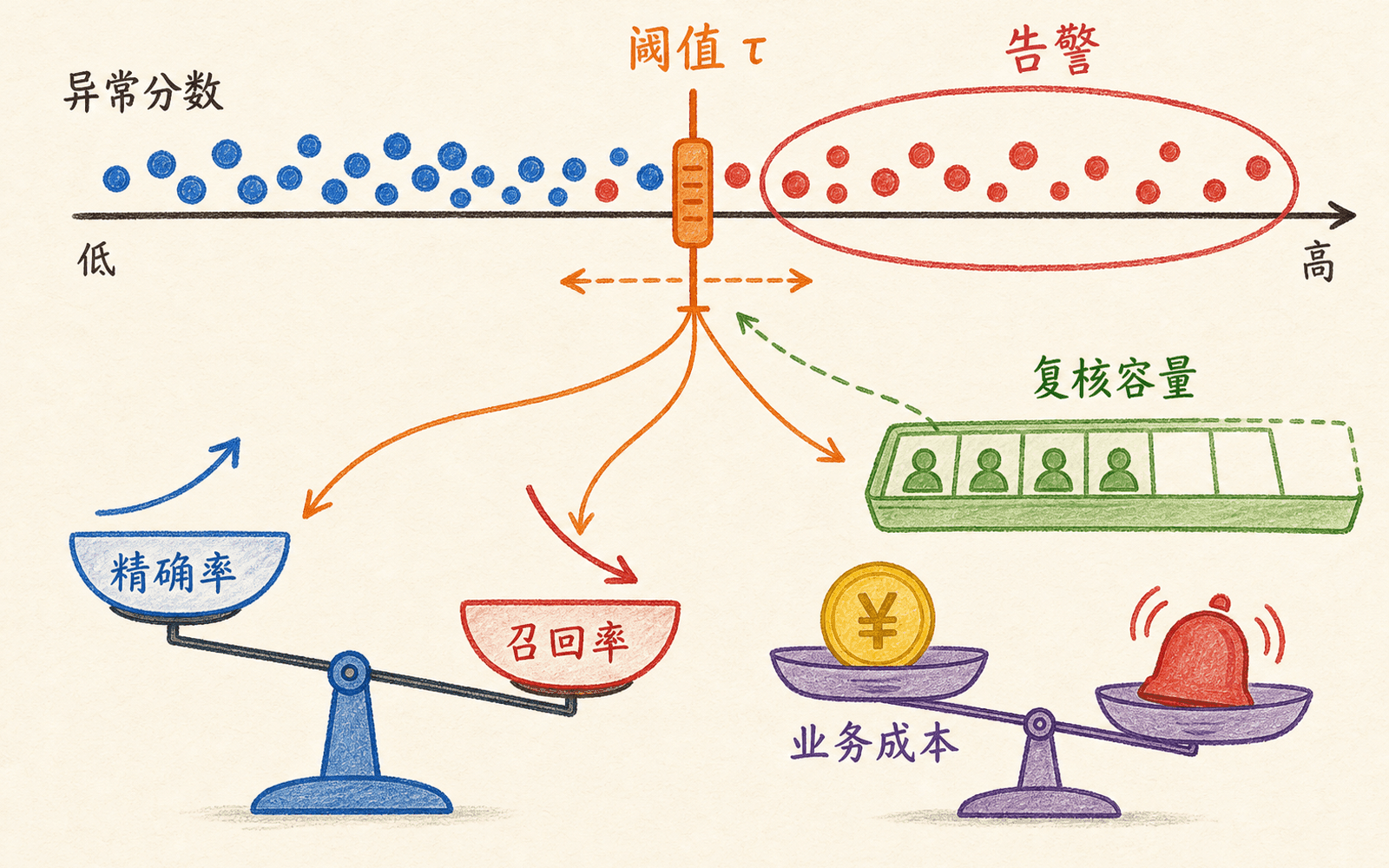
阈值是成本和容量约束下的决策,不是密度公式附赠的常数。
F1 默认同等重视精确率和召回率。漏掉一次入侵比多看一条告警严重得多时,可以使用更重召回的 ,或者直接最小化验证集上的业务成本:
成本参数应来自处置流程,而不是为了让某个模型获胜临时设置。若分析师每天最多复核 200 条,还要检查阈值在不同日期能否满足容量约束,并报告 Precision@200、召回率和积压量。
没有标签时,分位数只是在规定告警量
把训练分数的 99.5% 分位数设为阈值,意思是按该参考分布大约切出最极端的 0.5%。它不证明这 0.5% 是真实异常,也不保证未来仍是 0.5%。这个工作点可以启动人工采样,但随后要用复核标签和线上容量校正。
阈值、特征和算法只能在训练集与验证集上选择。根据测试集 F1 反复调 ,测试集就已经变成了验证集,最终分数不再是独立评估。
5
团队每天最多复核 100 条告警,漏报代价又明显高于误报。最合理的阈值选择方式是什么?
特征变换是在修正模型假设
高斯方法表现不好时,先别急着换成更复杂的算法。画出训练期正常数据的直方图、分位数图和时间序列,看看问题出在偏态、重尾、多峰,还是上下文没有进入特征。
右偏的正值特征常适合对数变换
网络字节数、文件大小和响应时长常有长右尾。对非负特征可尝试:
它会压缩大值之间的距离,让主体更接近对称。若数据含负值,可比较 Yeo–Johnson 之类允许非正数的幂变换。Box–Cox 只适用于正值,不能未经检查直接套用。
变换参数、偏移量、插补值都只能在正常训练数据上拟合,再原样应用于验证、测试和线上数据。看到测试分布后选择最漂亮的变换,同样是泄漏。
重尾不一定能被一次变换治好
真实系统可能天然产生比高斯更重的尾部。强行把长尾值当异常,会产生大量合法告警。可以比较 Student-t 分布、经验分位数、稳健尺度或树模型;也可以按业务状态拆分基线。标准化只改变位置和尺度,不会自动把重尾分布变成高斯。
好特征常在表达关系和变化
单看 CPU=70% 与网络流量=500 Mbps 都可能正常,但“几乎无请求时 CPU 仍为 70%”就可疑。可构造:
- 错误率:失败请求数除以总请求数,并对小分母设置最小支持量;
- 变化率:当前值相对过去窗口的增量;
- 条件残差:观测延迟减去同工作负载下的预测延迟;
- 比率特征:CPU 使用率除以请求量,但要处理分母接近 0;
- 实体相对量:设备值相对同型号、同区域正常群体的偏差。
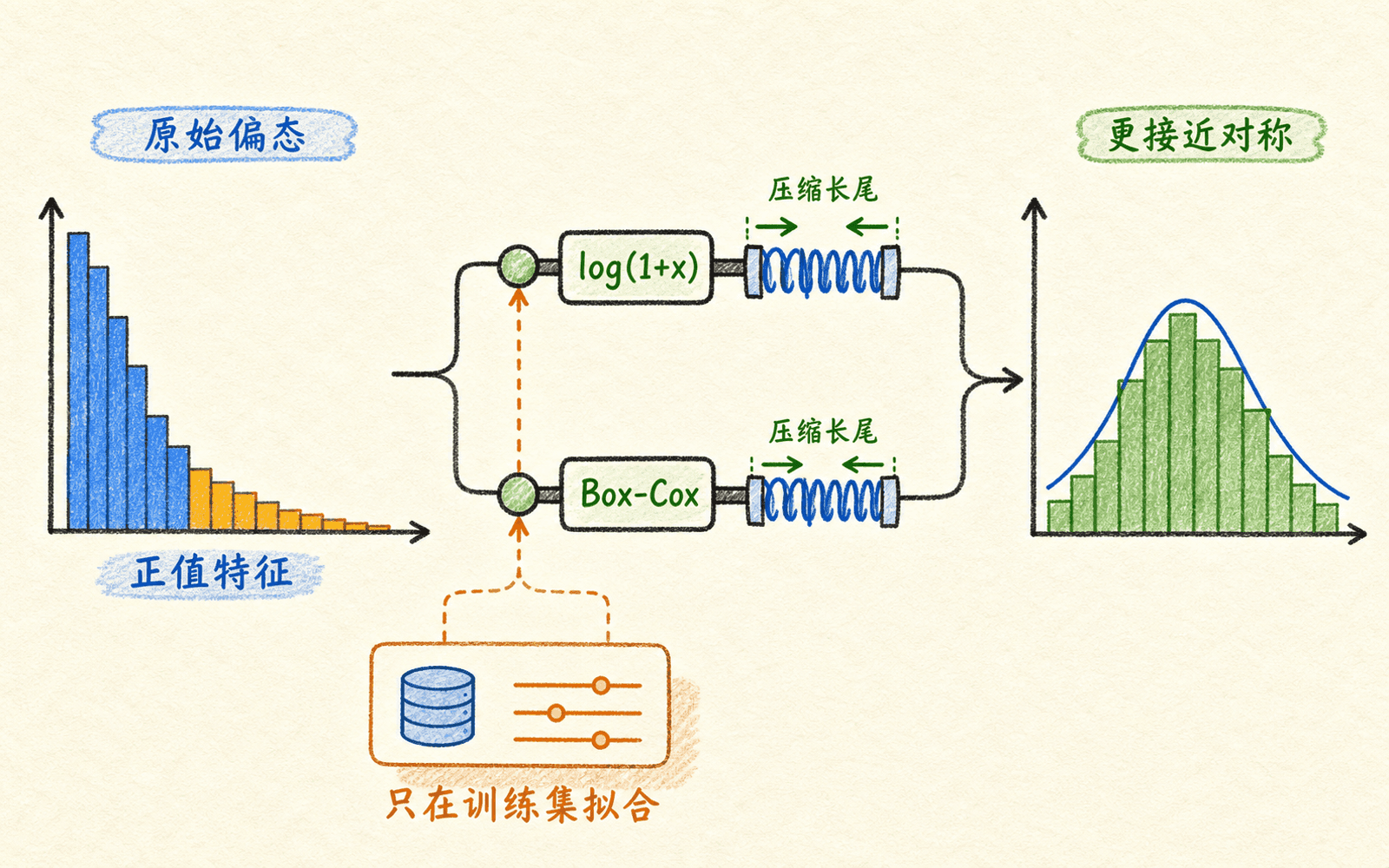
特征变换不是装饰数据,而是在修正模型关于分布形状的假设。
特征越多不一定越好。无关维度会让密度估计更难,也会让近邻距离趋同。每个新特征都应回答一个具体问题,并在验证事件和业务切片上证明它增加了可用信号。
6
关于异常检测中的特征处理,下列哪些做法合理?
多元高斯把相关性写进协方差
对角高斯把各特征分开建模。若正常数据沿着“请求越多,CPU 越高”的斜带分布,两个单变量都在常见范围内的点,也可能违反它们的联合关系。多元高斯用协方差矩阵表达这种线性相关结构:
其中:
二次型:
叫马氏距离平方。它按正常数据的协方差调整方向:沿着正常点云伸展方向移动较远,可能仍不异常;横穿很窄的方向移动一点,分数就会明显上升。
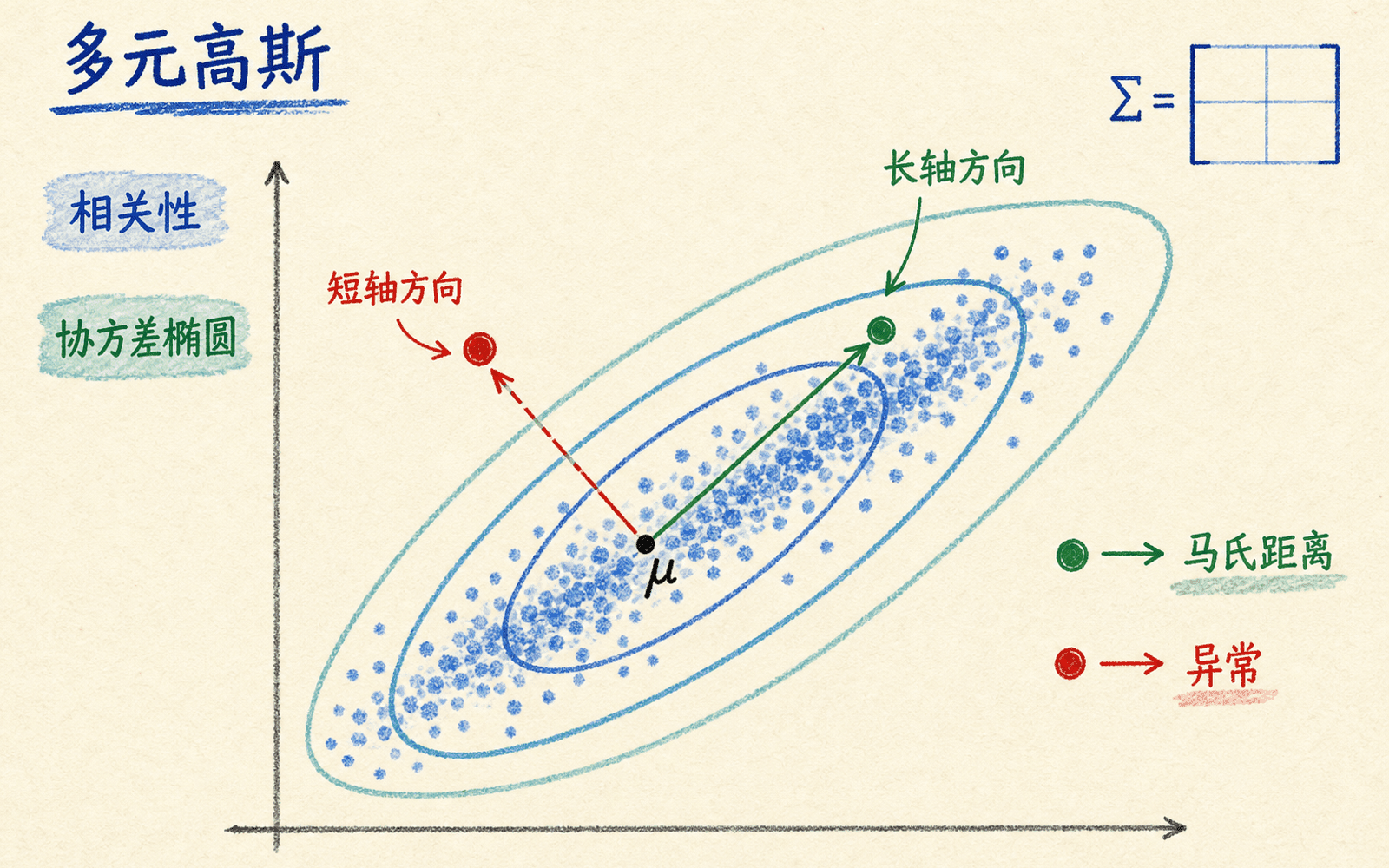
协方差让“沿常见相关方向的远”与“偏离相关结构的远”得到不同分数。
协方差奇异时,不要直接求逆
若特征线性重复、常量列未删除,或样本数不大于特征数,经验协方差可能不可逆或条件数很差。工程实现中应使用 Cholesky 分解或线性方程求解器计算二次型,并用对数行列式计算对数密度,不要显式调用矩阵求逆。
常见的正则化形式是:
也可以把经验协方差向对角矩阵或单位矩阵收缩。 增大时,模型会降低对不稳定相关性的依赖。它不是越大越安全,仍要在验证集上选择并检查不同切片。
单个椭圆不能描述所有正常模式
多元高斯仍是假设一个椭圆形主体。白天与夜间、空闲与高负载、不同设备型号若形成多个正常团块,一个大椭圆可能把团块之间的空白区域也视为正常。可以先按已知状态建条件模型,或比较高斯混合、局部密度与树方法。
训练集含污染时,普通均值和协方差会被极端点拉动。稳健协方差能减弱少量离群点影响,但仍依赖椭圆主体假设,并不适合任意多峰、高维数据。
7
特征数接近样本数,且两列几乎线性重复,多元高斯的协方差矩阵很不稳定。最合理的处理是什么?
有稳定正类时,监督分类往往更合适
“异常样本很少”不等于必须使用无监督方法。真正的判断标准是:已有正类能否代表未来想识别的正类。
更适合异常检测的情形通常是:
- 正常数据多,已确认异常极少;
- 异常机制很多,未来异常可能与历史正类完全不同;
- 目标是发现偏离正常机制的新情况;
- 正类标签严重延迟,但能找到较可信的正常训练区间。
更适合监督分类的情形通常是:
- 已积累足够多且独立的正类事件;
- 正类定义稳定,例如某种已知恶意流量或固定缺陷;
- 能让训练、验证和测试覆盖未来会出现的主要正类;
- 需要学习哪些变化与风险有关,而不仅是哪些变化少见。
不要用“20 个正例”之类固定数字代替判断。20 个来自 20 个独立攻击家族的事件,可能比 20 万个来自同一次事故的窗口更有信息。还要检查标签是否有选择偏差:只有模型告警后的样本才被人工审核,会让训练数据看不到历史漏报。
两类方法可以分工
实践中常用异常检测做候选生成,再用规则或监督模型判断已知风险类型。另一种方式是把异常分数当作监督模型的一个输入,但要在交叉验证折内重新拟合异常检测器,避免表示泄漏。
8
只要正类比例低于 1%,监督分类就一定不适用,必须改用无监督异常检测。
不同算法是在寻找不同形状的“正常”
方法选择可以看成选择一组几何假设,而不是比较名字的新旧。
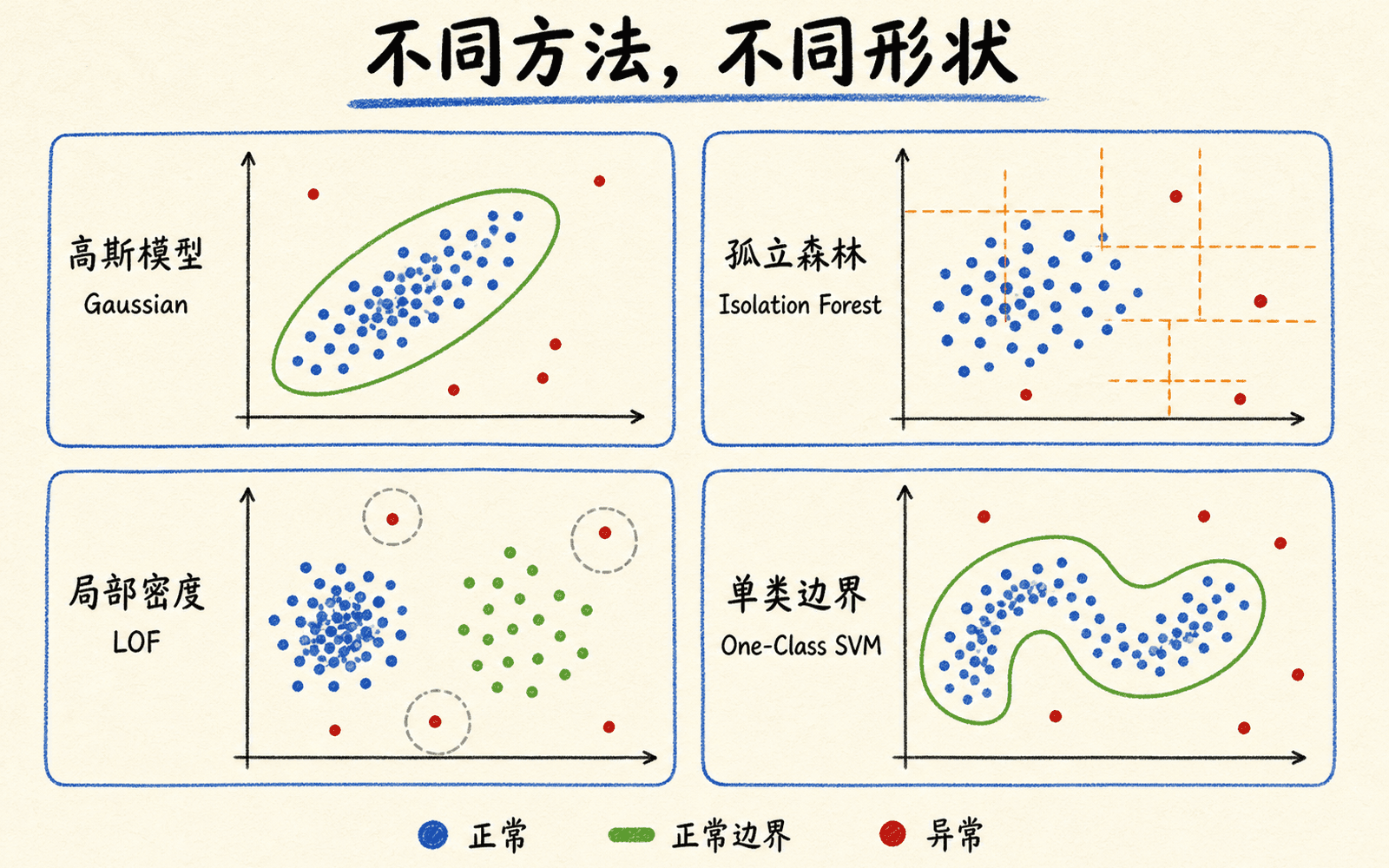
不同算法寻找的是不同形状的“正常”,选择应从数据结构和告警语义出发。
Isolation Forest:异常通常更容易被随机切开
Isolation Forest 反复随机选择特征和切分点,把样本递归隔离。异常点稀少且与主体不同,通常用较短路径就能单独分离;森林中的平均路径长度因此形成异常分数。
它不显式估计密度,能处理非椭圆结构,训练和评分也较快。但随机轴对齐切分仍会受表示影响。大量无关特征、粗糙类别编码和非常小的异常簇都可能改变结果。固定随机种子便于复现,还要用不同种子检查排序稳定性。
One-Class SVM:在核空间学习正常支持区域
One-Class SVM 试图找到一个包围大部分正常训练样本的边界。RBF 核可以形成非线性轮廓,但结果对特征尺度、核宽度 和 很敏感。 与允许训练样本落在边界外的比例、支持向量比例有关,却不能直接解释成真实污染率或故障概率。
核方法在样本很多时成本较高。若训练集受污染,边界也可能被异常点拉扯。它适合中等规模、经过缩放、正常训练相对干净,并且能认真验证核参数的场景。
LOF:比较点与邻居的局部密度
Local Outlier Factor(LOF)不要求所有正常区域密度相同。它比较一个点的局部可达密度与邻居密度:若该点比自己的邻居稀疏得多,LOF 就高。这对“一个稠密正常簇旁边还有一个稀疏但合法的正常簇”很有帮助。
代价是邻居数 、距离度量和缩放会明显影响结果。高维空间的距离可能失去区分度;异常形成一个内部稠密的小簇时,它们彼此会把对方当正常邻居。默认 LOF 更偏向在现有数据中找离群点,给未来新样本评分时要使用明确的新颖点模式。
椭圆包络:稳健协方差的现成基线
当正常数据确实接近单个高斯椭圆时,稳健协方差和马氏距离通常透明、有效。若数据多峰、强非线性或高维小样本,就不要因为它实现方便而坚持。
9
关于常见异常检测算法,下列哪些说法正确?
污染率、新颖点和离群点是三件事
许多库提供 contamination 参数,用来估计训练数据中异常比例或把连续分数切成标签。最容易犯的错,是把它当作模型自动发现的真实故障率。
若设置 contamination=0.01,常见行为是在训练分数上选择一个偏移,使大约 1% 的训练样本位于异常侧。它主要在定义工作点。真实异常比例如果是 0.1% 或 5%,参数不会凭空把事实改正确;分布漂移后,未来告警比例也不一定保持 1%。
新颖点检测只给未来新样本评分
新颖点检测假设训练集代表正常分布,问题是“一个新观测是否仍像训练时的正常样本”。预处理、模型和阈值都在训练与验证数据上确定,线上只做 transform 和 score。
离群点检测是在当前数据里找偏离者
离群点检测允许当前训练批次受污染,目标是在这批数据内部找出偏离主体的观测。某些算法对训练样本的评分方式和对新样本的评分方式不同。以 LOF 为例,默认的 fit_predict 用训练邻域找当前离群点;要给未见新样本评分,需要在拟合前开启 novelty 模式,而且不应把新颖点模式的 predict 再用于训练样本并期待与 fit_predict 一致。
分数方向和 API 也要做适配
有的实现返回值越大越正常,有的返回值越大越异常;有的 predict 用 1 表示正常、-1 表示异常。接入统一评估前,应写一个很小的方向测试:构造一个明显远离主体的点,确认它的标准化异常分数更大。模型升级后也要重复这项测试。
污染率可以用来启动一个告警预算,但不能替代验证标签。报告中应分别记录原始分数、阈值来源、预计告警率和人工确认率。
10
把 contamination 设为 0.02,最稳妥的解释是什么?
时间依赖、季节性和漂移不能塞进静态散点图
监控数据不是一袋可交换的独立样本。相邻分钟高度相关,白天和夜间有不同基线,节假日、促销、固件升级会改变分布。把所有时刻混在一个静态模型里,模型可能把每天固定出现的峰值反复报成异常。
更合理的思路是先建模上下文,再对残差做异常检测。若 是根据时间、负载和历史得到的期望值,残差为:
然后对 、绝对残差、标准化残差或一段残差序列评分。这样模型问的是“偏离此时此地的预期多少”,而不是“数值在全年是否少见”。
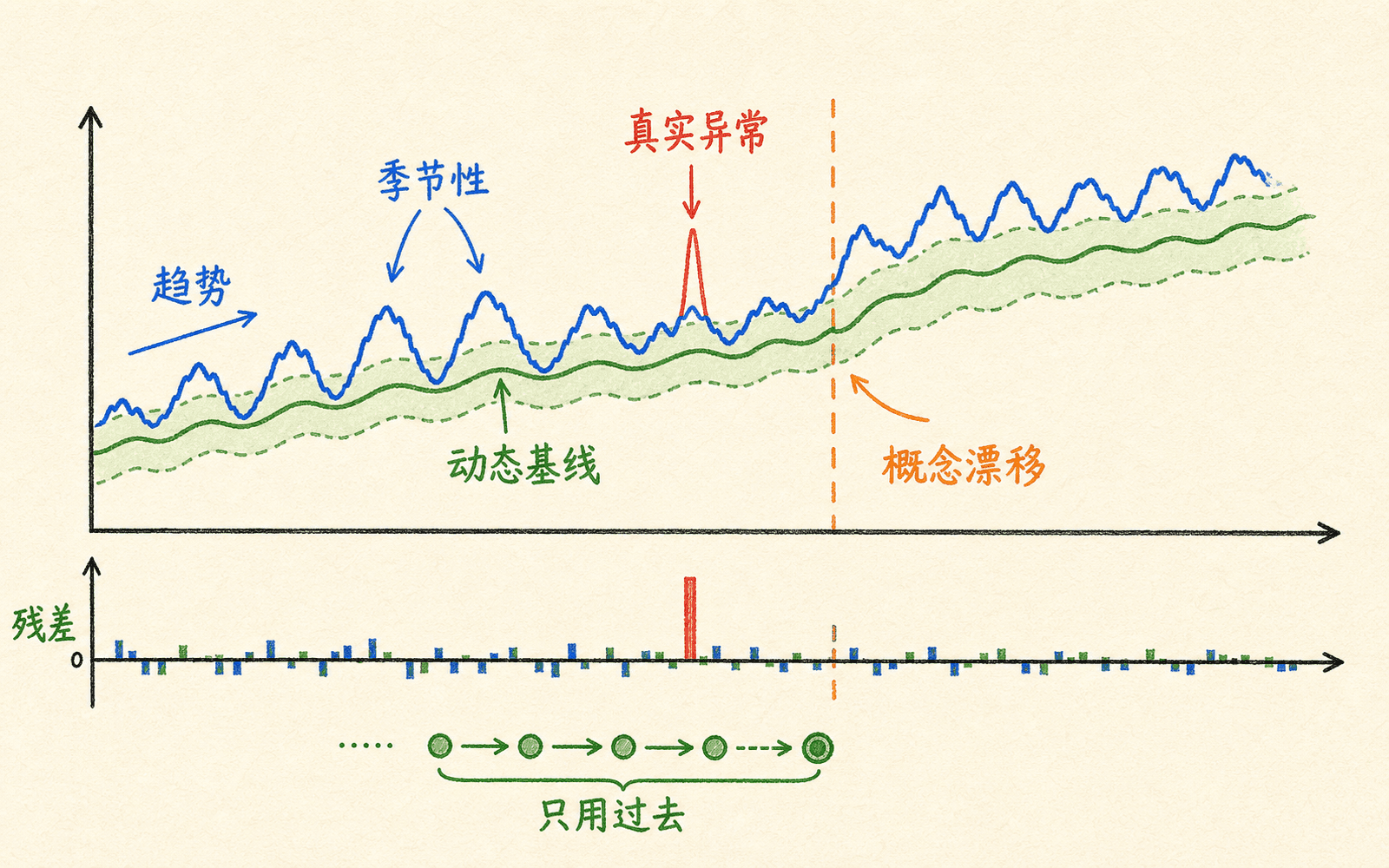
时间依赖数据要先建模趋势与季节,再判断残差是否异常。
所有滚动特征只能使用当时可见的过去
线上可用的 60 分钟均值应写成过去窗口:
以 为中心、同时使用未来 30 分钟的居中滑窗,离线图很好看,线上却无法计算。随机切分还会把未来状态泄漏到训练数据。时间任务通常要使用扩展窗口或滚动窗口验证。
季节性需要条件基线
小时、星期、节假日和班次都可能定义正常模式。可以按时段建多个简单基线,也可以用预测模型吸收趋势和季节性,再监控残差。周期性不清楚时,可用运行序列、季节子序列和自相关图检查;发现周期不代表每个峰值都安全,仍要结合业务状态。
漂移是“正常机制变了”,不一定是一次异常
固件发布后所有同型号设备的内存基线永久上升,这更像分布漂移;单台设备突然上升后恢复,则更像点异常。若把漂移当作许多独立告警,队列会被淹没。
上线后至少监控:
- 分数分布的分位数与均值;
- 每日、每设备、每型号的告警率;
- 缺失率、常量率和特征范围;
- 人工确认率与检测延迟;
- 模型版本、数据版本和阈值变更;
- 关键业务切片中的召回与误报。
漂移触发后先定位是采集变化、业务变化还是模型退化,再决定重训。直接用最新数据自动重训,可能把尚未解决的故障吸收到“新正常”中。
11
关于时序异常检测,下列哪些做法正确?
评估要覆盖切片、事件和复核容量
一个全局 F1 无法说明系统能不能用。假设总体精确率 80%,但新型号设备的精确率只有 10%,上线后该型号仍会淹没告警队列。至少要按设备型号、地区、时间段、负载档位、异常类型和数据质量状态做切片。
点级指标与事件级指标回答不同问题
一次持续 30 分钟的事故可能触发 360 个窗口告警。点级召回会把每个窗口都算一次,容易让长事件主导结果。事件级评估可规定:事故窗口内至少一次告警就算检出,同时记录首次告警延迟:
还可以报告每设备日误报数、每周告警数、重复告警压缩率、Precision@K 和未处理积压。自动阻断场景还要评估错误动作的风险,而不只是离线曲线。
人工复核不是“真值自动生成器”
复核员可能信息不足、标准不一致或只看到被模型挑出的样本。应提供上下文日志和明确标签规范,记录“确认异常、确认正常、信息不足、计划内变化”等状态。对争议样本可双人复核并保留分歧。
只复核高分样本无法估计漏报。可以从未告警区域按分数层和业务切片抽样,得到对假阴性的有限估计。若标签需要几天才能确认,评估窗口也要等待标签成熟,避免把尚未调查的告警一律算错。
阈值上线要有告警预算
先估计每天的事件量,再把点告警聚合为事件,按设备和时间设置冷却窗口,最后才与人工容量比较。阈值、聚合规则和去重规则共同决定最终工作量,不能只验证模型那一列分数。
12
一个故障持续半小时并产生大量连续告警。为了评价真实处置价值,应补充哪些指标?
深度模型仍然绕不开分数和阈值
当输入是图像、波形、长序列或高维日志表示时,手工高斯特征可能不够。自编码器是常见基线:编码器把输入压到潜在表示,解码器尝试重建,重建误差成为异常分数:
它依赖一个额外假设:模型能重建正常模式,却难以重建异常模式。这个假设并不自动成立。容量过大的自编码器可能把异常也重建得很好;正常训练数据中混入异常时,网络可能直接学会它;像素级均方误差还可能忽略业务上很小却危险的局部缺陷。
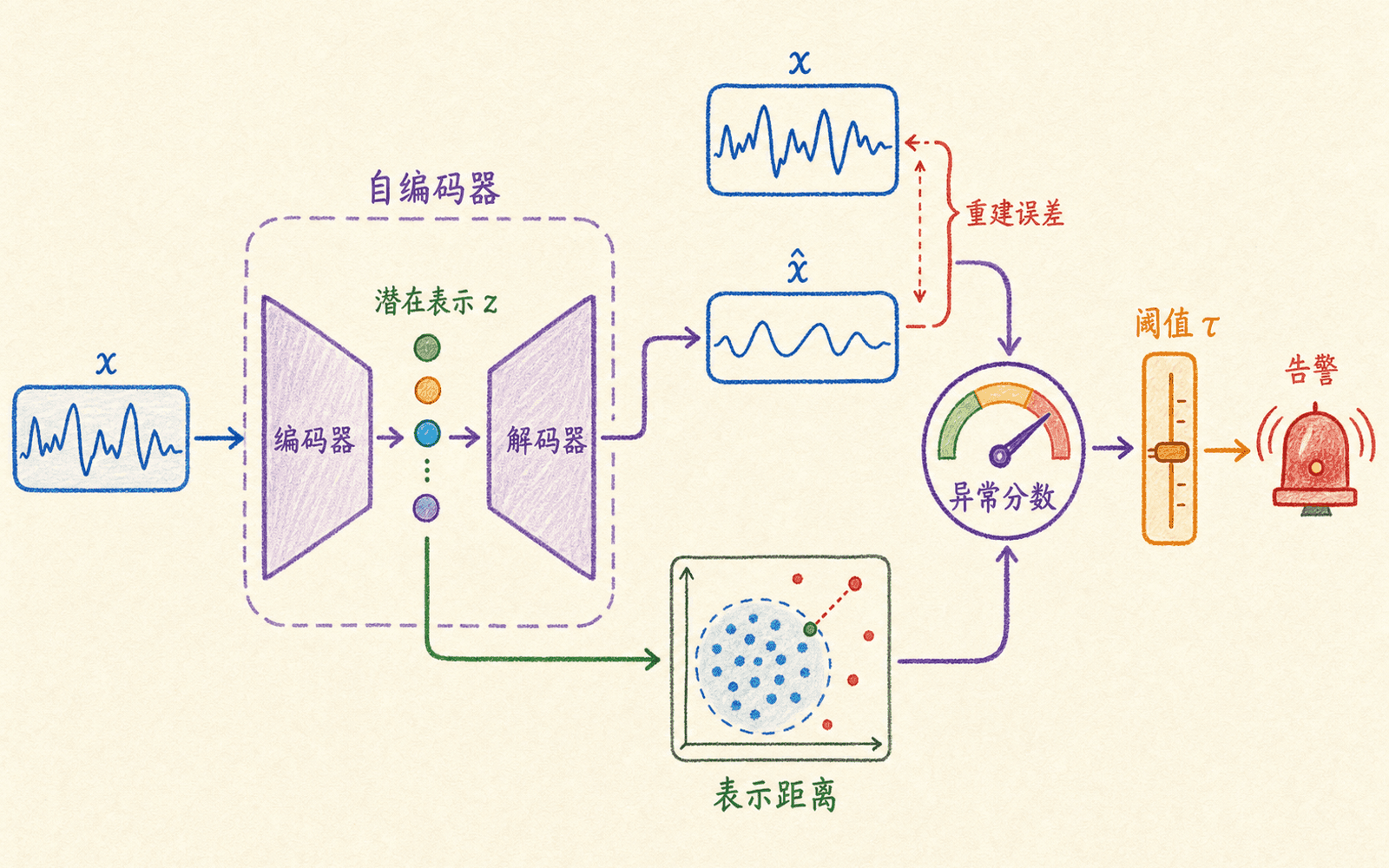
深度模型改变了分数的来源,却没有绕开验证集、阈值与运营闭环。
深度表示和检测规则要分开验收
可以在正常数据上训练编码器,再对潜在表示使用高斯、One-Class SVM 或 kNN 分数;也可以同时使用重建误差和潜在距离。无论哪种组合,都要分别记录:
- 输入预处理与训练样本范围;
- 网络结构、随机种子和停止条件;
- 分数的数学定义与方向;
- 验证集上的模型和阈值选择;
- 测试事件的切片表现;
- 线上延迟、吞吐与漂移监控。
深度模型不会让无监督分数自动变成概率。若要给运营人员显示风险概率,需要用独立标注数据做校准,并检查校准在时间和切片上的稳定性。标签极少时,展示分位等级或“进入复核队列的原因”通常更诚实。
先赢过透明基线
对数变换后的对角高斯、稳健协方差和 Isolation Forest 通常能很快建立下限。深度模型只有在独立测试事件上改善了召回、误报、检测延迟或资源成本,才值得承担更高的调试和维护成本。
13
自编码器在正常数据上训练后,重建误差就必然等于样本为故障的概率,而且所有异常都会有较大重建误差。
把设备案例接成一条可调试的流水线
现在把前面的判断落到一个网络设备案例。目标不是“找出最奇怪的点”,而是每天给值班工程师一份最多 200 个事件的候选队列,并尽量提前发现丢包、异常扫描和资源泄漏。
先写清楚样本和标签
每个样本是某台设备的五分钟窗口。原始指标包括请求数、失败数、CPU、内存、上下行字节、连接数和丢包数。特征可以包括:
- 失败率与丢包率,并保留分母规模;
- 当前值相对过去一小时中位数的偏差;
- 与同型号、同区域设备同期中位数的偏差;
- CPU 与请求量的条件残差;
- 连接数在过去五分钟的增长率;
- 缺失比例与采集间隔,防止数据故障伪装成业务异常。
训练期选择确认健康且早于验证期的窗口。验证和测试按事故、设备与时间分组,避免同一事故跨集合。标签以事故为单位,窗口标签只是事件区间的映射。
用共同的分数接口公平比较
先拟合对角高斯和 Isolation Forest。Isolation Forest 的 score_samples 通常越大越正常,因此取负号后统一为越大越异常。不要直接使用库的 predict 来替代业务阈值:
python
import numpy as np
from sklearn.ensemble import IsolationForest
from sklearn.impute import SimpleImputer
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import RobustScaler
preprocess = Pipeline([
("impute", SimpleImputer(strategy="median")),
("scale", RobustScaler()),
])
X_train_prepared = preprocess.fit_transform(X_train_normal)
阈值函数只接触验证集
下面用验证集估计误报、漏报和复核成本。真实项目还应先把连续窗口聚合为事件,再计算成本。
python
def choose_threshold(
y_val,
scores,
cost_fp=1.0,
cost_fn=20.0,
review_cost=0.2,
max_alerts=None,
):
y = np.asarray(y_val, dtype=int)
scores = np.asarray(scores, dtype=float)
if y.shape != scores.shape:
测试集只使用已经确定的预处理、检测器和阈值。报告测试结果后,不根据这些结果回头改变参数;下一轮改动要建立新的验证协议和新的保留测试期。
排错时先看现象,再决定改哪里
最后把可交付记录固定下来:数据时间范围、设备覆盖、特征版本、正常训练规则、模型参数、分数方向、阈值来源、验证成本、测试事件、切片指标、告警聚合规则、人工标签状态和重训条件。这样一次异常告警才有完整证据链:我们知道它为什么高分、在哪个版本下高分、谁会处理,以及处理结果如何回到下一轮评估。
14
设备异常检测上线后,所有设备在同一分钟分数一起暴涨。最合理的第一轮排查顺序是什么?