降维:从 PCA 几何直觉到可靠的工程流程
降维最容易被一句话说得太轻巧:把很多特征压成少数几个特征,同时尽量保留信息。真正动手时,问题全藏在“信息”两个字里。做图的人想保留邻近关系,做压缩的人关心重建误差,做分类的人只在意对标签有用的信号。它们不是同一个目标。
这一章以主成分分析(Principal Component Analysis,PCA)为主线。我们会从中心化后的数据矩阵出发,分别推导“投影方差最大”和“线性重建误差最小”两个视角,再把协方差矩阵的特征分解与 SVD 对齐。之后才进入工程问题:尺度怎么定、主成分数量怎么选、白化何时会放大噪声、怎样避免数据泄漏,以及高维、稀疏和流式数据该换什么实现。
PCA 的历史也能提示它的边界。Pearson 在 1901 年讨论的是点云的最佳拟合直线和平面,Hotelling 在 1933 年把统计变量写成按方差排序的主成分。它从一开始解决的就是线性子空间逼近,没有使用标签,也没有承诺找出因果因素或天然类别。
本章统一把数据写成 :每一行是一个样本,每一列是一个原始特征。目标维数为 ,且 。若你的库采用“样本在列”的约定,矩阵方向会相反,但几何结论不变。
先说清楚为什么降维
高维本身不一定是故障。一个包含一万个词项的稀疏文本向量,可能比十个含义模糊的手工特征更适合线性分类器。真正促使我们降维的,通常是下面几类具体成本:
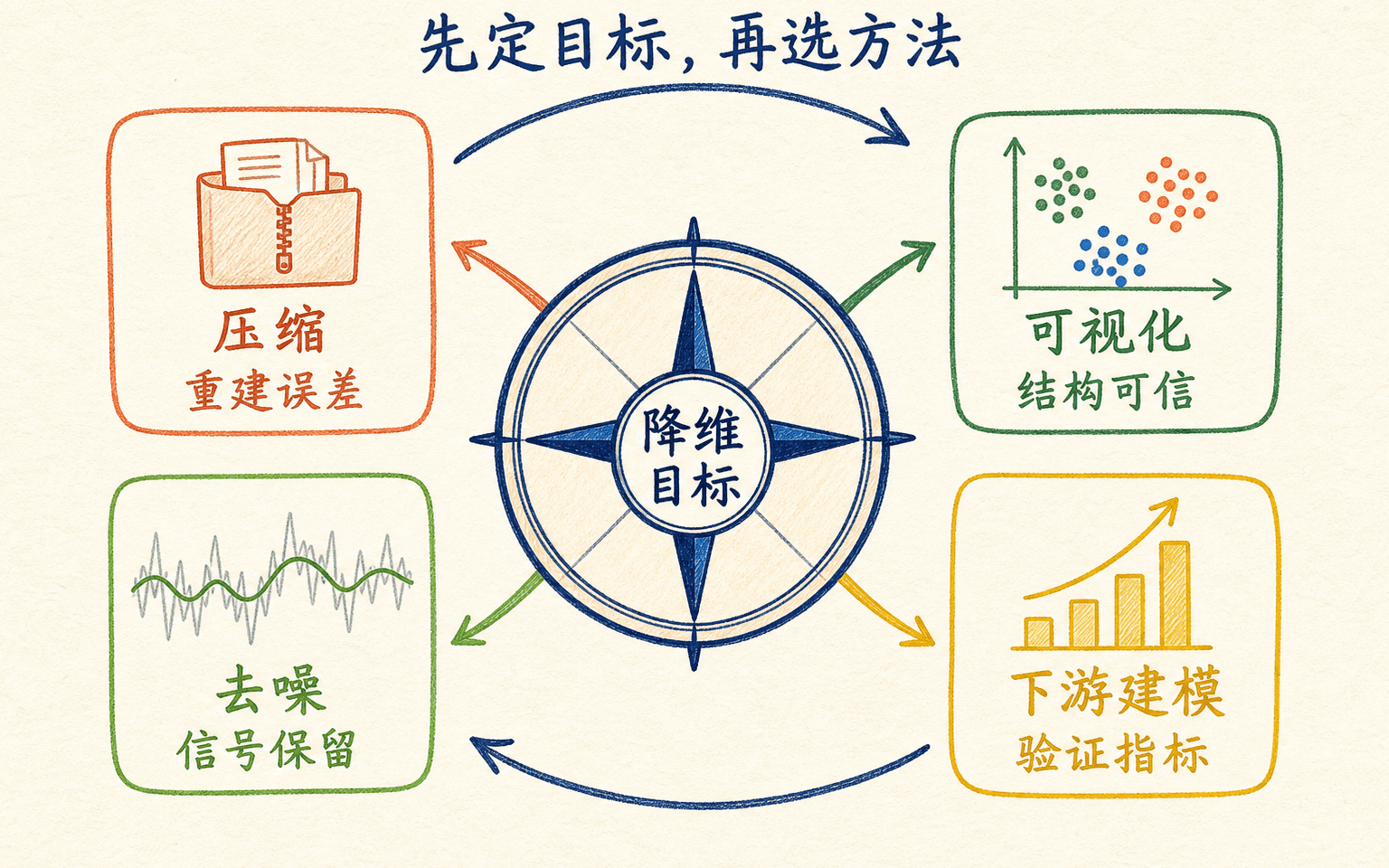
先明确降维要服务什么目标,才知道该保留哪类结构。
这里有三个常见误会。
第一,压缩成功不等于预测更准。假设标签只由一个总体方差很小的传感器偏移决定,PCA 可能最先丢掉的正是这个信号。PCA 优化的是 的变化,不是 的可预测性。
第二,二维图更清楚不等于原空间真的有几个簇。任何从高维到二维的投影都会丢失关系;非线性可视化还可能为了保留局部邻居而主动改变全局距离。
第三,去掉小方差方向不等于去掉噪声。只有在“信号集中于某个低秩子空间,噪声较弱且较均匀”这类假设近似成立时,截断主成分才像一个去噪器。
还要分清特征选择与特征提取。特征选择保留原列中的一部分,例如保留“年龄”和“收入”;PCA 生成的是原列的线性组合,例如 年龄加 收入。前者通常更容易解释,后者更擅长把相关方向合并。
1
关于使用 PCA 的动机,下列哪些判断正确?
中心化和尺度选择先定义了几何
PCA 寻找的是“数据相对中心怎样变化”。先计算每个特征的训练集均值:
再得到中心化矩阵:
若不中心化,原点到数据整体位置的偏移也会被当成主要变化方向。举个极端例子:所有二维点都紧挨着直线 ,但整团点位于 附近。直接对原矩阵分解,最大方向会同时受“离原点很远”和“点云沿哪条轴伸展”影响;中心化后才只看点云自身的形状。
是否标准化取决于单位和问题
中心化几乎是协方差 PCA 的必要步骤,标准化却是建模选择。若各列量纲不同,常把训练集中的每列除以标准差:
对 做 PCA 等价于研究协方差结构;对标准化后的矩阵做 PCA 等价于研究相关结构。两者回答的问题不同。
假设数据含“年收入(元)”与“满意度(1 到 5 分)”。未经缩放时,收入的数值波动很可能主导主成分。如果我们认为一元收入差异与一分满意度差异没有直接可比性,标准化是合理起点。反过来,若 12 个传感器使用相同单位并经过统一校准,真实振幅就是分析对象,强行把每列变成单位方差会抹掉有意义的能量差异。
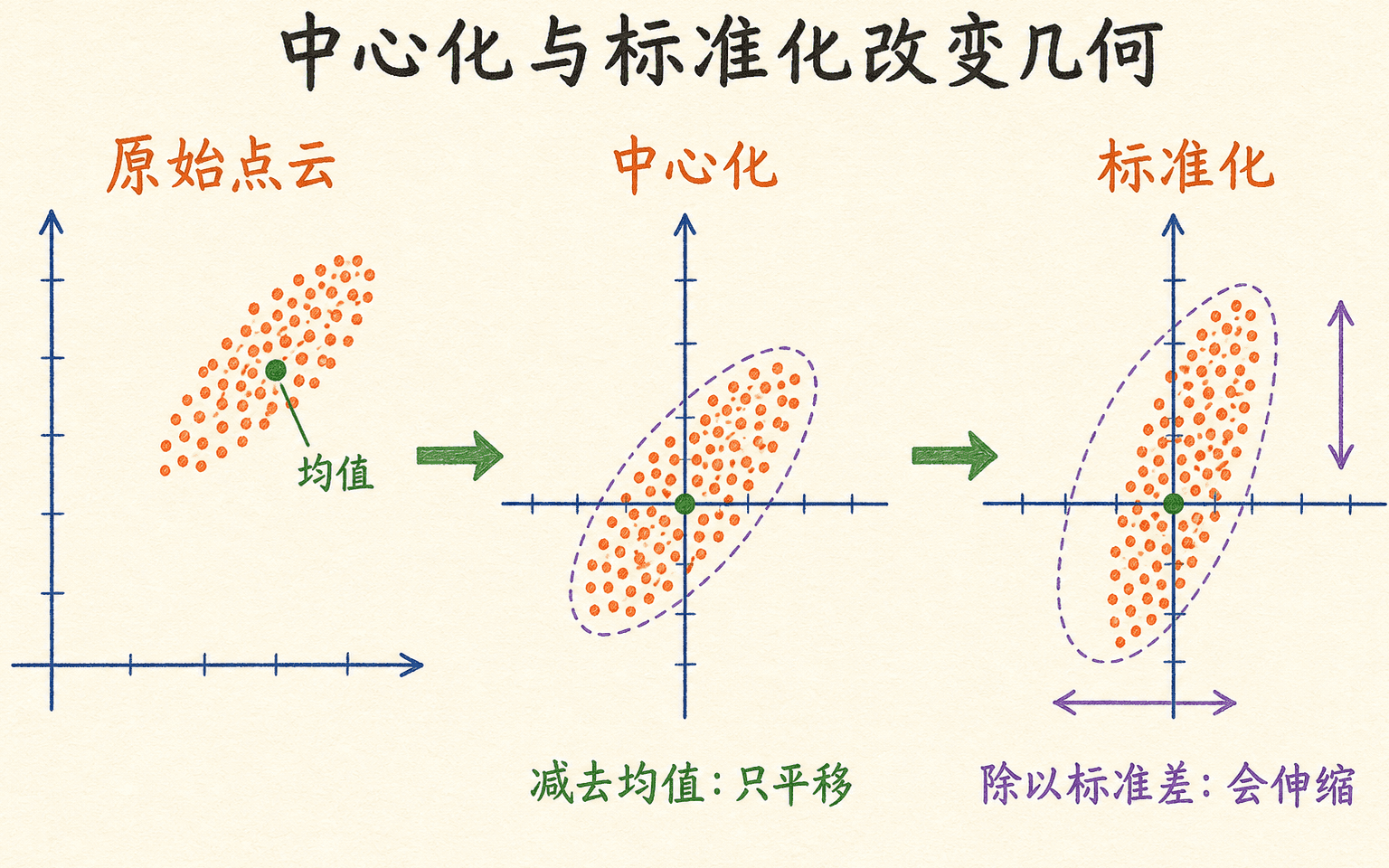
中心化定义参考原点,缩放决定哪些特征方向能主导方差。
缺失值、常量列和离群点不能交给 PCA 猜
- PCA 的常规实现不能直接解释缺失值。插补器也必须只在训练折中拟合。
- 标准差为 0 的常量列没有方向信息,应删除或明确保留为零,而不是直接除以 0。
- 类别编号不是连续距离。把城市编码为 1、2、3 后做 PCA,会凭空制造“城市 3 比城市 1 远两格”的几何。
- 经典 PCA 使用平方误差,极端点能显著旋转主轴。先核对离群点是录入错误、任务外样本还是真实稀有模式,再决定变换、稳健方法或保留。
不要在全量数据上先求均值、标准差或插补值,再切训练集和测试集。这些量也是从数据学到的参数。正确顺序是先划分,再只用训练部分拟合全部预处理步骤。
2
身高以厘米记录、体重以千克记录,研究目标是让两列的相对波动拥有可比较的起点。最合理的 PCA 前处理是什么?
最大方差视角找到点云最伸展的方向
先看一个主成分。取单位向量 ,满足 。每个中心化样本投影到这条轴后的坐标是:
整批样本的投影得分写成 。由于 已经中心化,投影均值也是 0。若样本协方差矩阵为:
投影后的样本方差就是:
第一主方向要解的问题是:
单位长度约束不能省。否则把 放大十倍,投影方差就能放大一百倍,目标没有上界。
拉格朗日乘子把方向连到特征向量
构造:
对 求梯度并令其为 0:
于是:
候选方向是 的特征向量,而该方向上的投影方差就是对应特征值 。选择最大特征值的单位特征向量,得到第一主方向。
第二主方向既要让投影方差尽量大,又要与第一方向正交。继续这个过程,得到一组单位正交方向 ,对应特征值满足:
这不是说现实世界的因素天然互相正交,而是 PCA 为了建立无重复的线性坐标系而施加的几何约束。
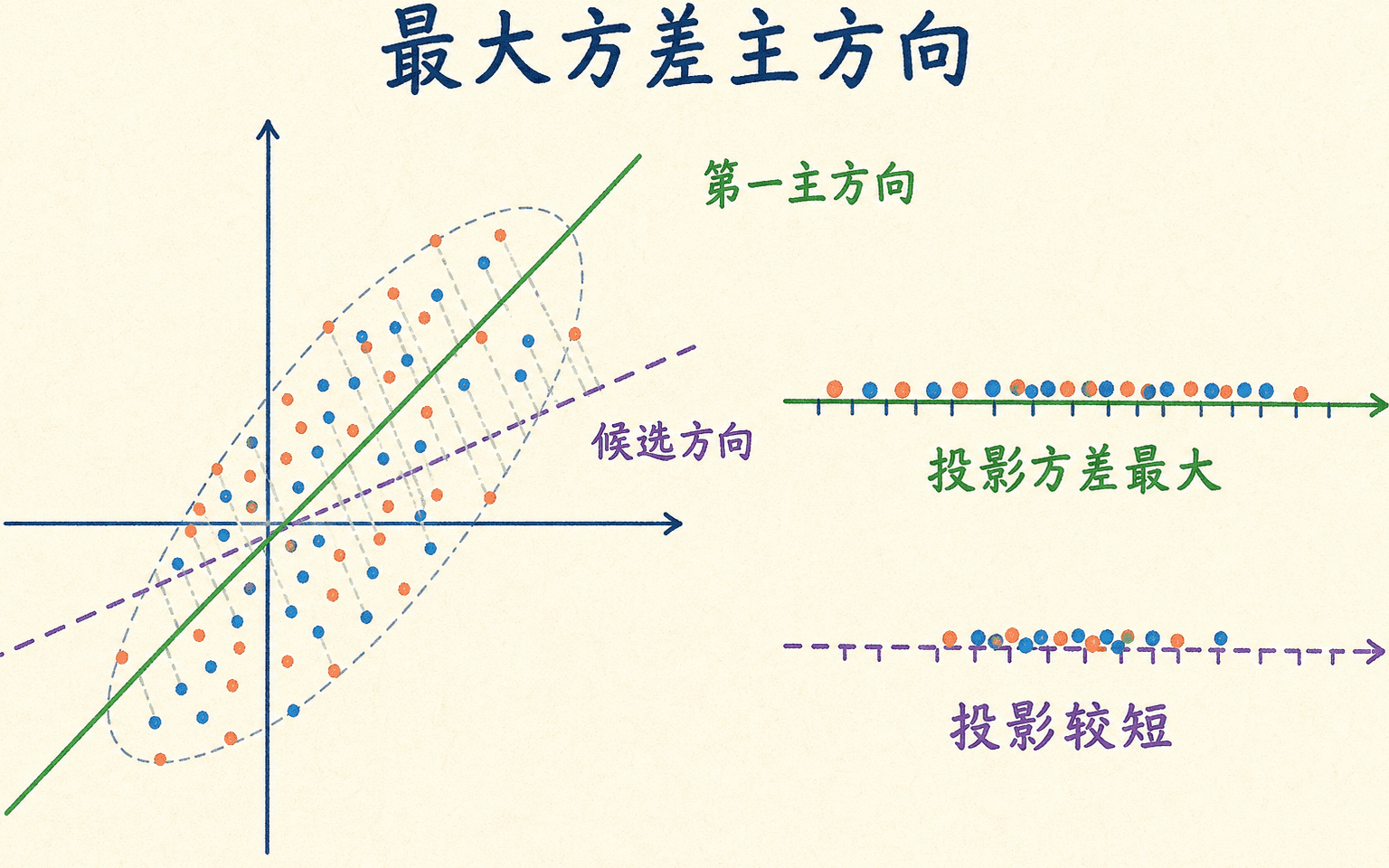
第一主成分是点云最伸展的方向,不等于最能区分类别的方向。
3
在中心化数据上寻找第一主方向时,为什么要约束 $w^\mathsf{T}w=1$?
最小重建误差视角解释“压缩后还能还原多少”
令 ,其列向量正交归一:
中心化样本在低维空间中的坐标为:
从低维坐标投回原特征空间:
是原空间里到这个 维子空间的正交投影矩阵。加回均值后,重建数据为:
PCA 选出的 也会让下面的平方重建误差最小:
为什么两个目标等价
对每个中心化样本,投影向量与残差正交。勾股关系给出:
左边的总能量对给定数据是常数。让投影部分尽量大,就等于让残差部分尽量小。把所有样本相加,“最大化保留方差”与“最小化正交重建误差”得到同一个主子空间。
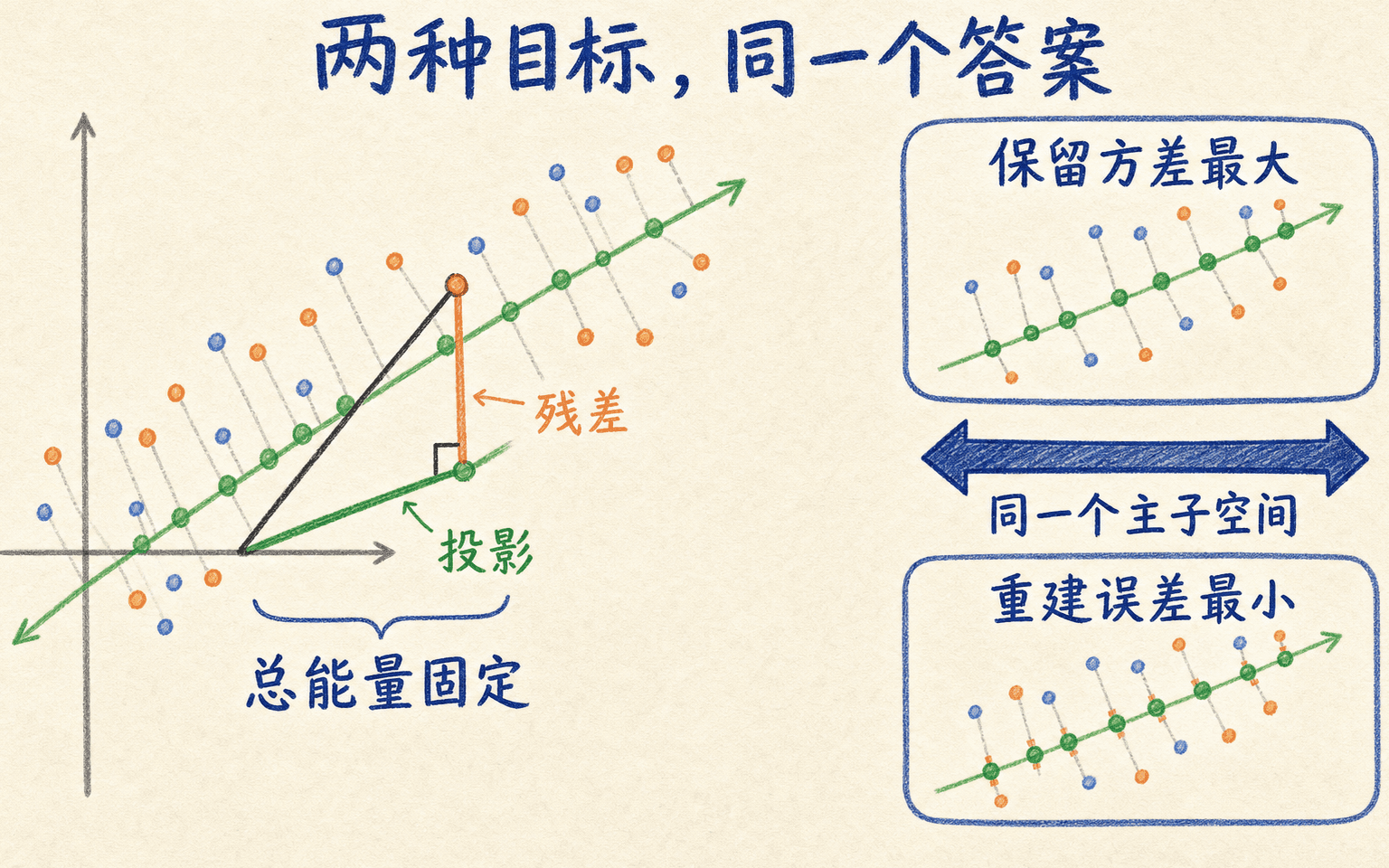
保留的能量越多,落在被舍弃正交方向上的重建误差就越小。
这项最优性有清楚范围:在线性、正交、平方误差的 rank- 近似中,截断 SVD 最优。换成绝对误差、感知相似度、非线性曲面或带业务权重的损失,最优解都可能改变。
4
某中心化矩阵的奇异值为 5、3、1。保留前两个方向时,最小平方 Frobenius 重建误差为 ____。
协方差特征分解与 SVD 是同一结构的两条计算路径
对中心化矩阵做薄 SVD:
设 ,则 、、。奇异值按 排列。
把它代入协方差矩阵:
于是三组量一一对应:
因此,直接对 做 SVD 不需要先显式构造 协方差矩阵。若 很大,构造协方差矩阵会占用 内存;而且从 求特征值会平方奇异值的条件数,对跨越很多数量级的数据更不稳定。
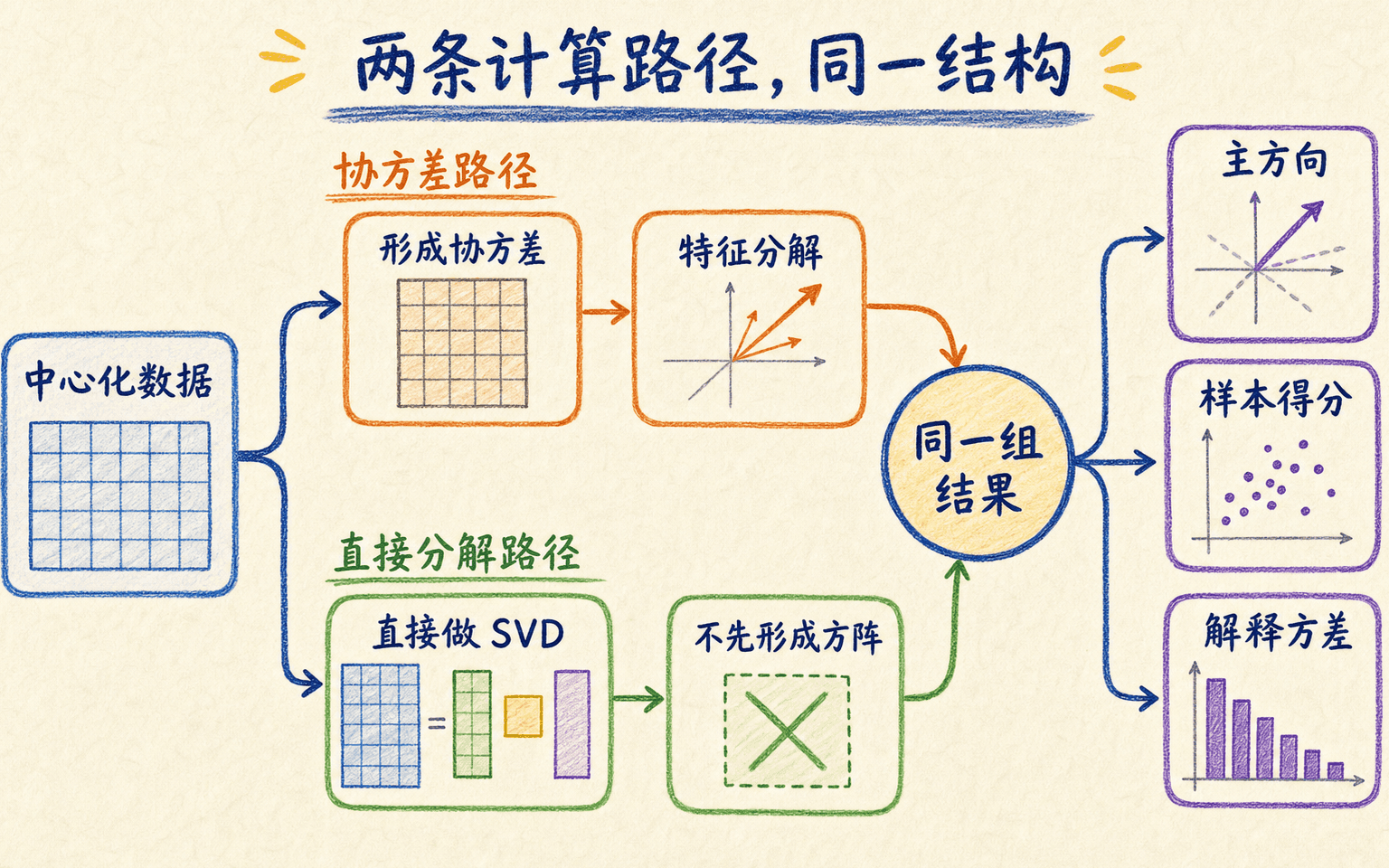
两条路径揭示同一结构;实际求解通常优先避免显式构造巨大协方差矩阵。
一个最小 NumPy 对照如下:
python
import numpy as np
X = np.asarray(X, dtype=float)
X_centered = X - X.mean(axis=0, keepdims=True)
U, singular_values, Vt = np.linalg.svd(
X_centered,
full_matrices=False,
)
k = 2
components = Vt[:k] # 形状:(k, d)
旧稿中常见一句错误是“NumPy SVD 返回的奇异值是协方差特征值的平方根”。更准确地说,NumPy 对 返回奇异值 ;协方差矩阵的特征值是 。分母取决于协方差使用的自由度约定,不能漏掉。
5
对中心化矩阵 $X_c=U\Sigma V^\mathsf{T}$,下列哪些关系正确?
主方向、得分和载荷要分开解释
PCA 的术语在不同教材和软件中略有差异,最稳妥的办法是先看对象和形状。
- 主方向或主轴:,说明低维坐标轴在原特征空间朝哪里。
- 得分:,说明每个样本沿第 条主轴的位置。
例如,标准化后的“阅读时长、文章数、收藏数”在第一主方向上的系数都较大且同号,我们可以说这个方向概括了三项指标的共同变化。不能直接把它命名为“学习能力”,因为这层语义需要外部证据;也不能把系数绝对值当成监督模型里的特征重要性,因为 PCA 根本没有看到标签。
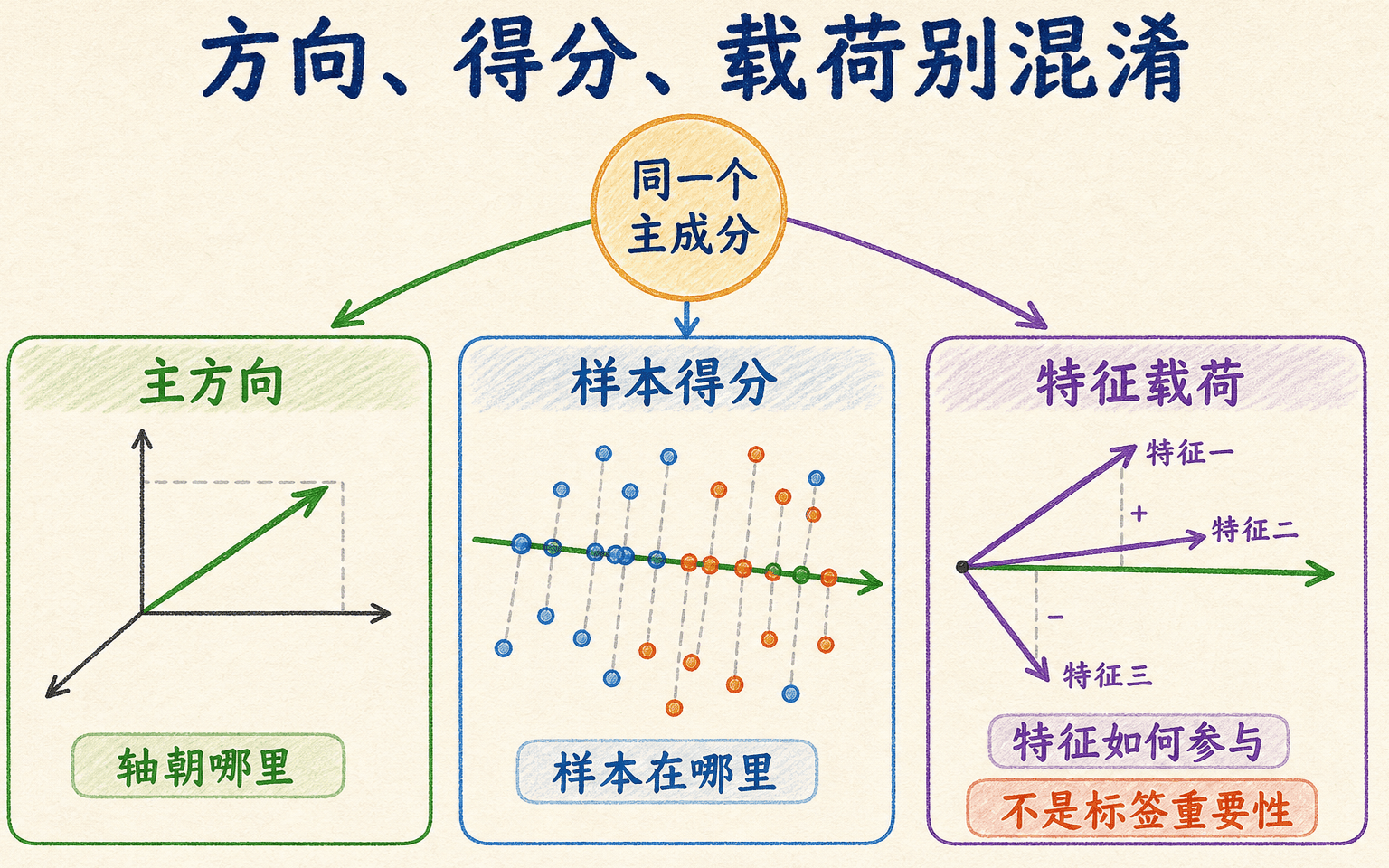
主方向描述新坐标轴,得分定位样本,载荷解释原特征怎样参与。
正负号没有固定身份
若 是特征向量, 也是同一特征值的特征向量。把方向翻转后,得分也随之翻转:
投影子空间、重建结果和解释方差完全不变。因此两次运行得到相反符号,不代表模型变了。若报告需要固定展示方向,可以按“绝对值最大的系数取正”之类规则统一符号,但要把它当作展示约定。
特征值相同或非常接近时,单根轴也不唯一
如果 ,对应二维子空间里的任何正交旋转都同样最优。特征值接近时,轻微数据扰动也可能让两根轴旋转或交换顺序。此时逐列比较 和 会显得很不稳定,但它们共同张成的子空间可能很稳定。
工程上可以比较投影矩阵 、主角度或重建结果,而不是强求每个分量逐元素相同。载荷解释也应报告这种不确定性。
6
同一批数据的两次 PCA 结果中,第一主方向及其得分都恰好整体变号,因此两次得到的投影子空间和重建一定不同。
选择 k 要把方差、误差和最终用途放在一起
第 个主成分的解释方差比例为:
前 个主成分的累计解释方差比例为:
在中心化数据上,丢弃部分的平方重建误差与被丢弃方差直接对应:
这让累计解释方差成为压缩任务的自然刻度,但“保留 95%”只是一个候选规则,不是统计定律。90%、95% 或 99% 对应不同成本;如果特征先标准化,比例描述的是标准化空间里的变化,不能直接当成原单位的误差。
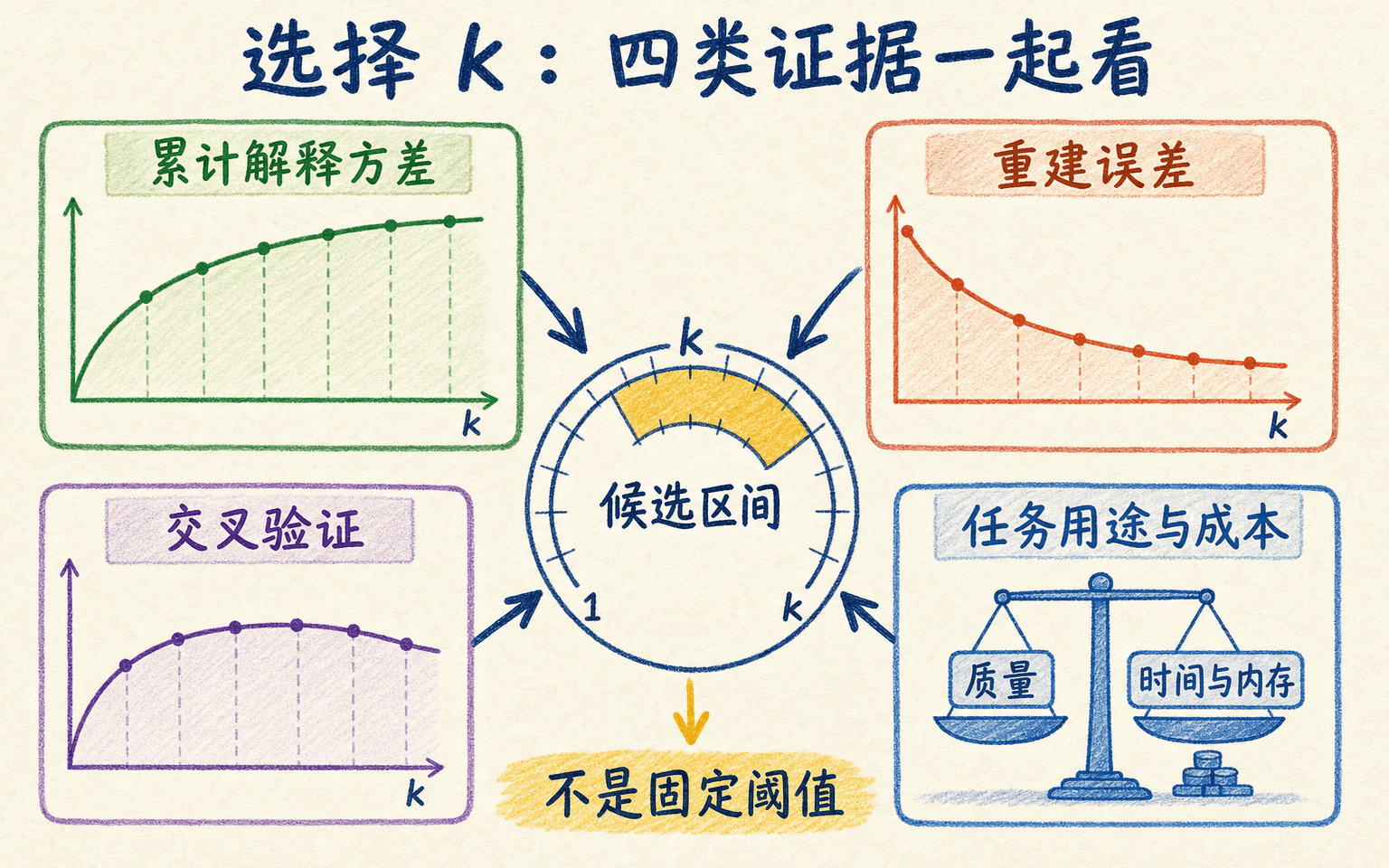
k 是压缩、误差和最终用途之间的权衡,95% 不是普适答案。
三种常用证据回答不同问题
- 碎石图和累计方差图:查看特征值下降、是否存在清楚的拐点,以及增加一个分量还能减少多少重建误差。真实曲线常常没有明显肘部,不要强行读出一个整数。
- 压缩预算:图像、传感器或通信任务可以先规定可接受误差、时延或字节数,再选满足约束的最小 。
- 下游交叉验证:若 PCA 服务于分类或回归,把 放进 Pipeline 的参数搜索,只在训练折中重新拟合 PCA,用验证指标和资源成本一起决定。
还应检查结果在重采样和时间窗口变化下是否稳定。若相邻的 与 性能几乎相同,通常没有必要假装 13 是唯一正确答案。可以选择成本更低、稳定性更好的方案,并记录可接受区间。
下面这个写法适合探索方差曲线,不应用测试集决定 :
python
import numpy as np
from sklearn.decomposition import PCA
pca_full = PCA(svd_solver="full")
pca_full.fit(X_train_prepared)
cumulative = np.cumsum(pca_full.explained_variance_ratio_)
k_95 = int(np.searchsorted(cumulative, 0.95) + 1)
print("95% 方差的候选 k:", k_95)
print("前 k 个累计比例:", cumulative[k_95 - 1])7
PCA 用于分类前处理,累计解释方差在 k=20 时达到 95%。下一步最合理的做法是什么?
投影、重建和白化是三个不同操作
拟合好的 PCA 模型至少要保存均值 和主方向 。若训练前还做了标准化,也要保存尺度 。新样本 的投影是:
用列向量约定写回原空间:
若 PCA 在标准化空间中拟合,重建后还要乘回训练尺度,再加训练均值。这里的“重建”是正交投影的近似,不是把丢掉的信息找回来。两个不同样本可能映射到同一个 ,因为它们只在被丢弃方向上不同。
重建误差要回到任务单位
在标准化空间里,温度误差 1 个标准差和压力误差 1 个标准差权重相同;回到原单位后,二者的业务代价可能完全不同。压缩项目除了报告标准化空间的均方误差,还应报告原单位逐特征误差、极端样本误差,以及真正关心的感知或业务指标。
截断 PCA 有时能去噪,是因为重建只保留前 个方向。但如果缺陷信号恰好出现在小方差方向,重建会把缺陷抹掉。这在异常检测和质量控制里尤其危险。
白化会进一步改变每条轴的尺度
普通 PCA 的各主成分互不相关,但方差仍分别是 。白化把第 个得分除以它的标准差:
得到近似单位方差的分量。这样会去掉“第一主成分比第二主成分波动更大”的相对尺度信息。白化可能适合某些假设输入各方向同尺度的后续模型,却不是默认更好。
还有两个边界。白化只保证样本协方差意义下的不相关和单位方差,不保证统计独立;只有在高斯等额外条件下,不相关才能推出独立。其次,除以很小的 会放大小方差方向中的噪声,所以通常先截断再白化,并用验证结果决定是否开启。
8
关于 PCA 重建与白化,下列哪些说法正确?
PCA 进入预测流程时必须和数据划分绑在一起
最隐蔽的错误不是公式写错,而是先在全量数据上拟合 PCA,再做交叉验证。虽然 PCA 没看标签,它仍看到了验证折的均值、协方差和主方向。验证数据参与了表示学习,分数会偏乐观。
正确顺序是:
先按照部署场景划分数据。独立同分布样本可随机划分;时间序列按时间切分;同一患者、用户或设备的记录要用分组切分,防止实体跨集合。
在每个训练折中依次拟合插补、缩放、PCA 和预测器。验证折只调用这些步骤的 transform 或 predict。
用训练折的交叉验证选择主成分数量、是否白化和预测器参数。不要根据测试集曲线回头调参。
参数确定后,在完整训练集上重拟合整条 Pipeline,再对保留测试集评估一次,并保存全部预处理参数。
scikit-learn 的 Pipeline 会让每个交叉验证折分别拟合变换器:
python
from sklearn.decomposition import PCA
from sklearn.impute import SimpleImputer
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import GridSearchCV, StratifiedKFold
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
pipeline = Pipeline([
("impute", SimpleImputer(strategy="median")),
("scale", StandardScaler()),
(
候选 必须小于每个训练折可用的样本数和特征数。若不同列需要不同处理,应在 Pipeline 中加入 ColumnTransformer,而不是先在全表外部编码。时间数据则应换用与时间顺序一致的交叉验证器。
先执行 pca.fit_transform(X),再把结果交给 cross_val_score,仍然发生了泄漏。Pipeline 的价值不是代码更短,而是让每个验证折在表示学习阶段保持不可见。
9
哪种做法能避免交叉验证中的 PCA 泄漏?
高维、稀疏和流式数据需要选择合适求解器
“用 SVD 做 PCA”仍然有多种实现。选择前先看三个数字:样本数 、特征数 、目标维数 ,再看矩阵是否稀疏、是否能装进内存。
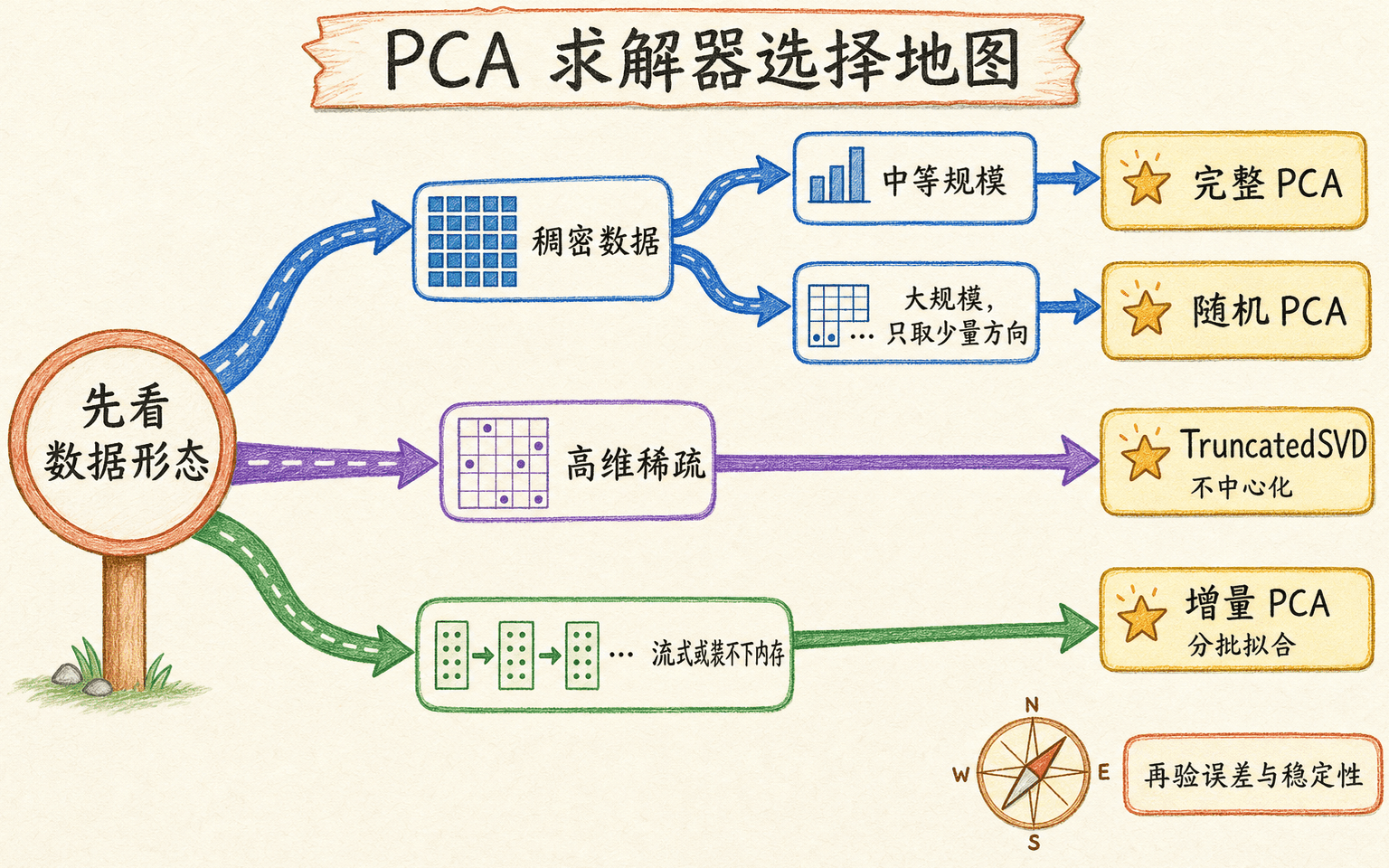
求解器选择取决于数据形态、内存和中心化可行性,不只看算法名字。
随机 SVD 先找近似子空间
随机化方法用少量随机向量探测矩阵的主要作用范围,再在压缩后的矩阵上求分解。当 远小于 且奇异值下降较快时,它常能显著节省时间。结果依赖随机种子、超采样数和幂迭代次数,应该比较解释方差、重建误差和重复运行稳定性,而不是只比较运行时间。
IncrementalPCA 按批更新均值和子空间
数据按批读取,可以避免同时保存全部样本:
python
import numpy as np
from sklearn.decomposition import IncrementalPCA
ipca = IncrementalPCA(n_components=40, batch_size=512)
for X_batch in stream_training_batches():
ipca.partial_fit(np.asarray(X_batch, dtype=float))
for X_batch in stream_prediction_batches():
Z_batch = ipca.transform(np.asarray(X_batch, dtype=float))
批次必须来自训练范围,预处理也要能以一致方式分批拟合。IncrementalPCA 是内存方案,不自动解决分布漂移;若后续月份的数据分布变化,应另做漂移监控和重训策略。
稀疏矩阵最怕中心化后变稠密
词袋矩阵中绝大多数值为 0。逐列减均值后,原来的 0 几乎都变成非零数,内存优势随即消失。TruncatedSVD 直接分解未中心化稀疏矩阵,在线性语义分析中很常见,但它的方向同时受整体均值影响,不能把结果无条件解释成中心化 PCA。
python
from sklearn.decomposition import TruncatedSVD
lsa = TruncatedSVD(
n_components=100,
algorithm="randomized",
random_state=42,
)
X_text_low_dim = lsa.fit_transform(X_tfidf_train)
X_text_test_low_dim = lsa.transform(X_tfidf_test)10
关于大规模和稀疏数据的降维,下列哪些说法正确?
二维可视化是观察窗口,不是高维真相
把 维样本投影到前两个主成分后,每个点的横纵坐标是:
坐标轴可以标注“PC1(解释 37%)”“PC2(解释 18%)”,让读者知道这张图一共展示了多少变化。若两轴累计只解释 23%,它仍可能有探索价值,但不能假装覆盖了数据的大部分结构。
PCA 没有使用类别标签。正确做法是先只用特征拟合投影,再用标签、时间或批次给点着色,观察它们在同一投影中的分布。若先按标签挑特征、筛样本或调参数,图已经混入监督选择,需要在说明中讲清楚。
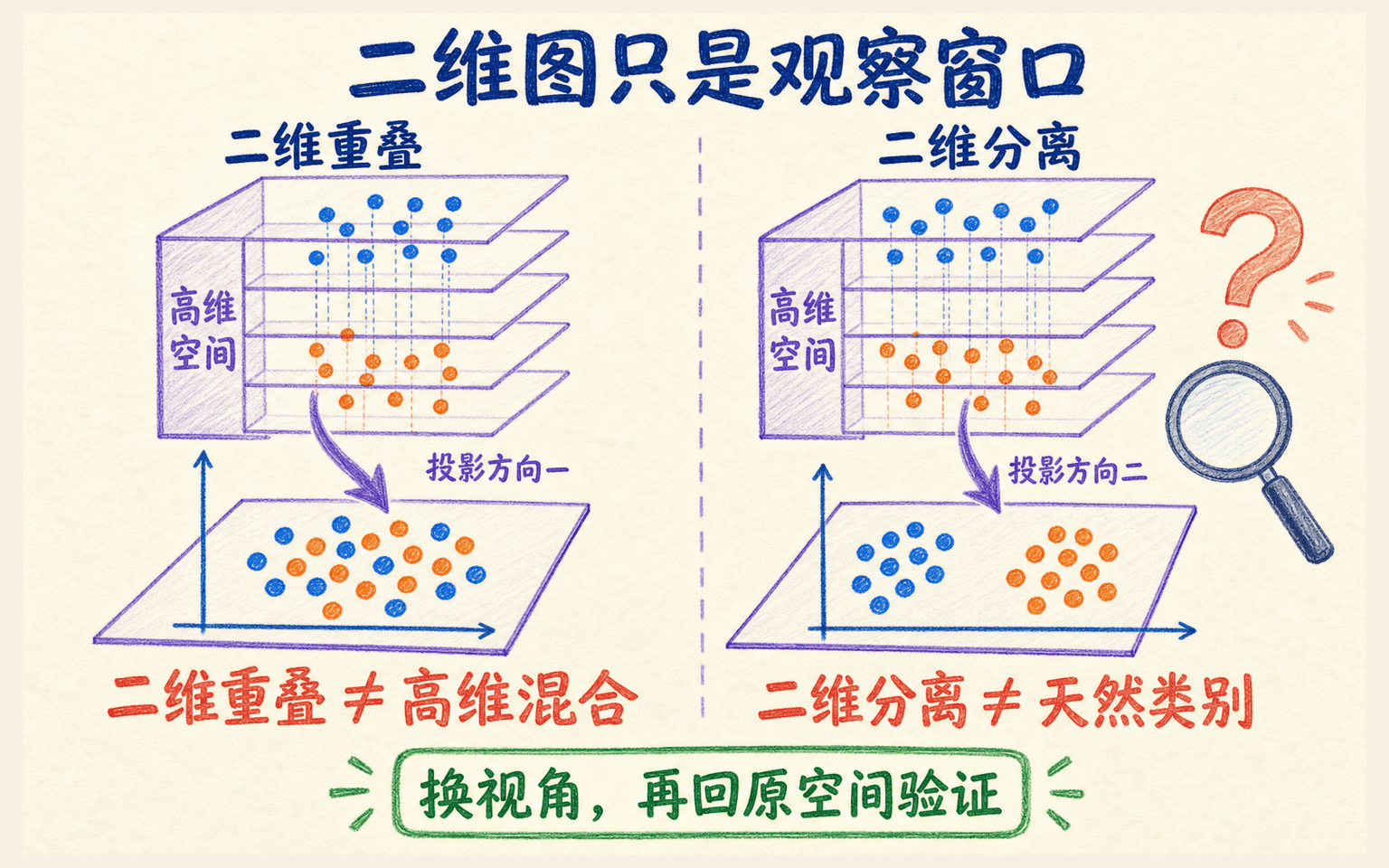
二维图只是一个观察窗口;重叠不证明高维混合,分离也不自动等于天然类别。
投影会压短距离,也会让不同点重叠
对任意两个中心化样本 和 ,正交投影满足:
所以二维图上很近的两点,在被省略方向上仍可能相距很远;重叠也不等于原空间不可分。相反,图上已经很远的点,在完整欧氏空间里的距离至少不小于这个投影距离,但这仍不能证明它们属于不同类别。
读图时逐项排除视觉错觉
展示时最好同时给出解释方差、载荷摘要和至少一个替代视角,例如 PC1–PC3、原始关键特征或重建误差。图形用于提出问题,结论仍应由原空间指标和独立数据支持。
11
两个样本在 PC1–PC2 图上几乎重合,因此它们在完整特征空间中也一定很接近。
图像压缩案例要区分“图像集合 PCA”和“单图 SVD”
图像常被用来展示 PCA,因为像素天然组成高维向量。一张 灰度图展平后有 784 个特征。若我们有许多同尺寸、已对齐的图像,可以把每张图作为一行,在训练图像集合上拟合 PCA。主方向重排成图像后常被称为“特征图像”,每张新图只需保存 个得分,就能近似重建。
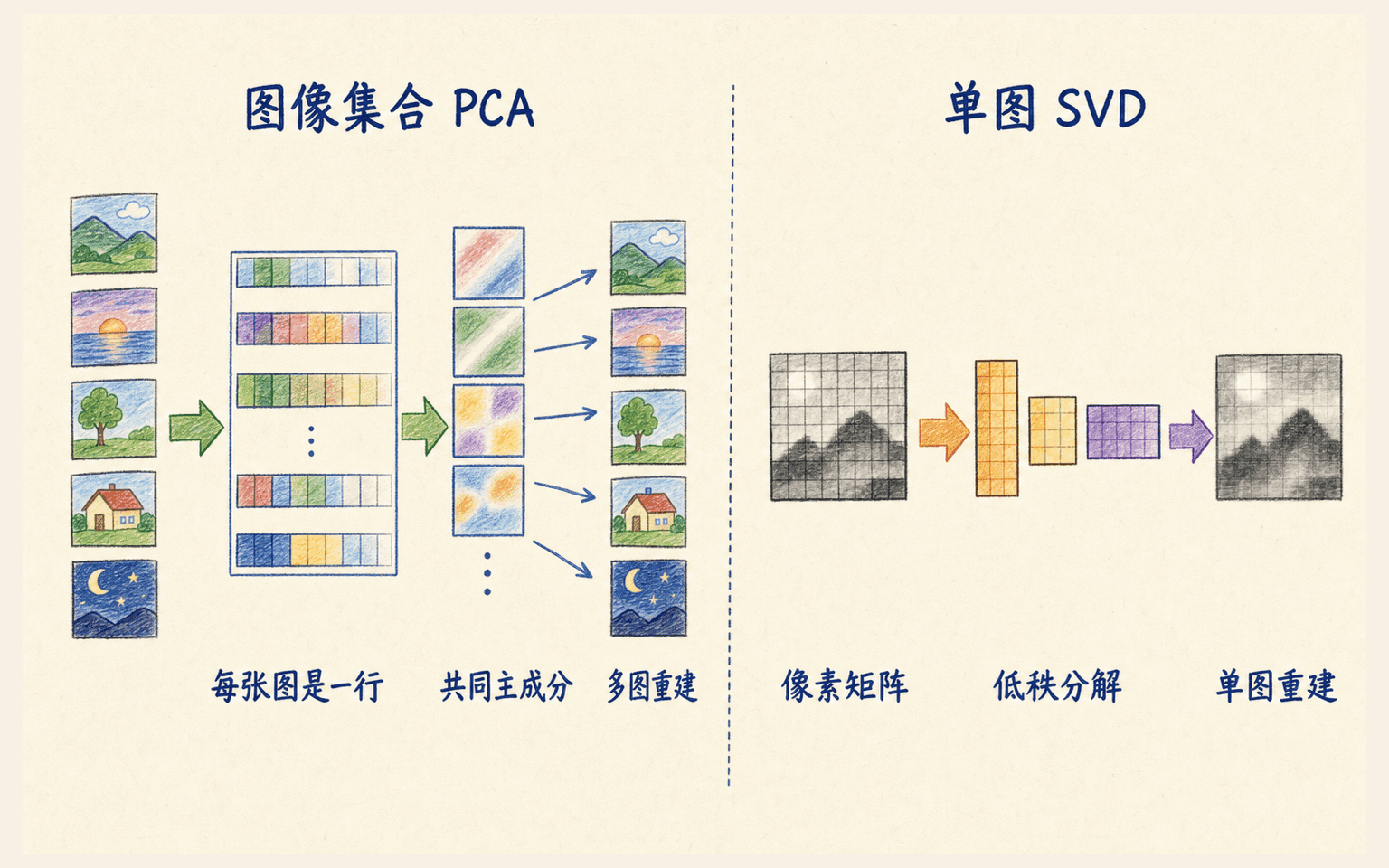 图像集合 PCA 学习跨样本共同方向;单图 SVD 压缩的是一张像素矩阵。
图像集合 PCA 学习跨样本共同方向;单图 SVD 压缩的是一张像素矩阵。
训练集有 张图、每张 个像素时,原始浮点矩阵需要存约 个数。低秩表示需存均值 、基矩阵 和训练得分 ,总计约:
只有当 足够小且样本足够多时,共享基的成本才会摊薄。实际文件大小还取决于量化精度、编码格式和元数据,不能用维数比直接宣称压缩率。
下面用手写数字数据演示训练集拟合、测试集重建。图像像素都在同一量纲,因此这里不额外标准化每个像素;逐像素标准化反而会放大几乎不变化的背景位置。
python
import numpy as np
from sklearn.datasets import load_digits
from sklearn.decomposition import PCA
from sklearn.model_selection import train_test_split
digits = load_digits()
X_train, X_test = train_test_split(
digits.data,
test_size=0.25,
random_state=42,
stratify=digits.target,
)
pca = PCA(
另一种常见演示是把一张灰度图当成高为 、宽为 的矩阵,做 rank- SVD:
这与 PCA 的低秩近似数学相通,但样本与特征的定义不同:它利用的是一张图内部行列结构,不是在图像数据集上学习共享主成分。写报告时应把两种任务分开称呼。
压缩验收也不只看平均 MSE。细小文字、医学影像病灶或产品缺陷可能只占少数像素,平均误差很小却把关键结构抹平。应加入局部误差、下游识别指标或领域审核。
12
1000 张图像,每张 400 个像素;共享 PCA 基取 k=20。忽略均值和基矩阵的一次性成本后,每张新图的表示需要保存 ____ 个得分。
分类案例必须和不降维基线公平比较
PCA 用于分类时,我们真正想知道的不是“前 个分量解释了多少方差”,而是它是否在可接受的精度下减少训练时间、推理延迟、内存或噪声敏感性。至少要比较两条使用相同划分、相同模型家族和相同调参预算的流程:
- 插补与缩放后直接分类;
- 同样预处理,再经 PCA 后分类。
一个很小的反例能说明原因。假设特征 的方差是 100,但与标签无关; 的方差只有 0.01,却几乎决定标签。保留一个主成分时,PCA 很可能选择 ,分类信号随即消失。最大方差不是最大判别力。
下面的代码把 PCA 和分类器都放进训练集内部的参数搜索。为了避免把测试集当调参面板,两条流程先在训练集交叉验证,最后各自只评估一次测试集。
python
from sklearn.datasets import load_digits
from sklearn.decomposition import PCA
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import GridSearchCV, train_test_split
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
digits = load_digits()
X_train, X_test, y_train, y_test = train_test_split(
digits.data,
digits.target,
test_size=0.25,
stratify
公平比较还应记录拟合时间、峰值内存、变换耗时和模型大小。PCA 自己也有拟合与推理成本;若原模型已经能高效处理稀疏高维数据,先降维可能反而变慢或破坏稀疏性。
误差分析要回到样本。检查哪些类别在 PCA 后更容易混淆、错误是否集中在低对比度图像、不同 的结论是否稳定。若降维只减少 5% 时间,却持续损失关键少数类召回率,就没有必要为了“流程更像机器学习”而保留它。
13
PCA 保留了 99% 的训练特征方差,但少数类召回率明显下降。最合理的解释与处理是什么?
特征选择和非线性方法各有清楚边界
当 PCA 的线性子空间假设不合适时,先问任务缺的是什么,再换工具。方法名字比目标次要。
Kernel PCA 不是给 PCA 加一个万能开关
Kernel PCA 通过核函数隐式把样本映射到高维特征空间,再做中心化特征分解。RBF 核能展开某些弯曲结构,但核宽度改变“谁与谁相似”,结果缺乏合适尺度时会完全不同。它的逆变换通常只是额外拟合的近似,不像线性 PCA 那样天然拥有正交重建公式。
t-SNE 和 UMAP 首先是可视化工具
t-SNE 把高维相似度与低维相似度写成概率分布并优化二者差异,目标非凸;同一数据在不同困惑度、初始化或种子下可形成不同布局。scikit-learn 的 t-SNE 没有通用的 transform 方法来稳定投影任意新样本,不应直接当线上特征管道。
UMAP 从近邻图构建低维表示,常比 t-SNE 更易扩展,并在常用实现中支持 transform。但支持新样本变换不等于二维欧氏距离成为真实业务距离。两种图都应跨参数和种子检查,并用原空间证据验证。
特征非常高时,可先用 PCA 或 TruncatedSVD 降到几十维,减少近邻搜索中的噪声与计算,再做 t-SNE 或 UMAP。这个预处理同样只能在允许的数据范围内拟合。
自编码器把线性子空间换成可学习的非线性映射
编码器 产生低维代码,解码器 尝试重建输入。足够复杂的网络能拟合弯曲结构,但也可能只记住训练样本。必须使用独立验证数据比较重建、下游任务和稳定性,并把网络大小、正则化和训练成本算进方案。
如果目标只是让几十个相关数值特征更紧凑,线性 PCA 往往是更透明的基线。只有当线性重建或投影明确失败,并且非线性方法的额外成本能换来可验证收益时,再升级复杂度。
14
下列方法选择中,哪些与任务边界相符?
从零实现和排错要围绕不变量
自己实现 PCA 的价值不是替代成熟线性代数库,而是把每一步的形状和不变量看清楚。下面这个版本只处理有限的稠密数值矩阵,支持可选标准化,并显式保存新数据变换所需参数。
python
from dataclasses import dataclass
import numpy as np
@dataclass
class PCAModel:
mean: np.ndarray
scale: np.ndarray
components: np.ndarray
explained_variance: np.ndarray
explained_variance_ratio: np.ndarray
def fit_pca_svd(X, n_components, standardize=False):
X = np.asarray(X, dtype=float)
if X.ndim != 2:
raise
用不变量验收实现
设 model 是上面拟合的结果,Z 是训练集得分,可以检查:
python
model = fit_pca_svd(X_train, n_components=5, standardize=True)
Z = transform_pca(model, X_train)
X_hat = inverse_transform_pca(model, Z)
gram = model.components @ model.components.T # 主方向应正交归一
assert np.allclose(gram, np.eye(5), atol=1e-10)
assert np.allclose(Z.mean(axis=0), 0.0, atol=
按现象定位问题
可交付记录至少包含
- 样本范围、时间窗口、数据版本与划分方式;
- 特征定义、缺失值、异常值、中心化和缩放规则;
- PCA 实现与软件版本、求解器、、白化和随机种子;
- 解释方差曲线、重建误差及选择 的依据;
- 与无降维基线的指标、时间、内存和误差样本比较;
- 载荷解释中的符号约定与近似相等特征值;
- 新样本 transform、版本发布和分布漂移监控方式。
做到这里,降维结果才是一条可复查的变换,而不只是一张好看的散点图。我们知道它在哪个数据范围上拟合、保留了哪种信息、丢掉了什么,并能在新数据上原样复现。
15
验收一个 PCA 实现时,下列哪些检查有直接诊断价值?