推荐系统:从一次曝光到一张可上线的推荐列表
用户打开视频首页,系统并不是在回答“他会给每部视频打几分”。它真正要做的是:在此刻可展示的海量内容中,先找出一批候选,再按用户当前意图、内容质量和平台约束排好顺序,最后用十几条结果换取几百毫秒后的真实反馈。
这也是推荐系统比普通监督学习更绕的地方。训练数据不是自然落下来的标签,而是上一版推荐策略、页面位置、库存和用户选择共同留下的行为记录。用户没点某部电影,可能是不喜欢,也可能是根本没看见。模型输出的列表又会改变下一轮数据,于是训练、服务和产品形成了闭环。
这一章会沿着一条完整工程链路展开:先定义曝光与反馈,再搭建召回、排序和重排;接着实现内容推荐、邻域协同过滤和矩阵分解;最后处理冷启动、离线评估、近似最近邻、反馈环与线上 A/B 实验。我们会一直使用一个电影与短内容混合平台的案例,把公式放回真实决策中。
本章统一用用户 、物品 、已观察交互集合 和推荐长度 。评分预测记为 ,隐式反馈排序分数记为 。分数只负责比较候选,不天然等于点击概率;只有经过概率校准并在对应流量上验证后,才可以把它解释成概率。
先把任务写成“在什么曝光下预测什么动作”
推荐系统常见的第一张表是用户—物品矩阵。行是用户,列是电影,单元格里有评分、点击或观看次数。它很直观,却容易把最重要的信息藏掉:一个单元格为什么为空?
假设用户小林今晚打开首页,没有点击纪录片《海岸线》。至少有四种可能:
- 这部片没有进入候选集;
- 它进入候选集,却在重排时被过滤;
- 它展示在第 30 位,小林没有滚动到那里;
- 小林看见了,但当时只想找一部轻松喜剧。
这四种情况在一个稀疏矩阵里都可能显示为“空”。所以,可靠的数据建模应从曝光日志开始,而不是从“把空值补成 0”开始。
一条最小曝光记录可以包含:
显式反馈和隐式反馈不是同一种标签
显式反馈是用户直接表达的评分、喜欢、不喜欢或问卷答案。它的语义相对清楚,但数量少,而且愿意评分的人不是随机样本。极喜欢和极不喜欢的用户更可能留下评分,自选择偏差会进入数据。
隐式反馈来自点击、播放、停留、购买、跳过、分享或隐藏。它数量大、更新快,却只是在特定界面和曝光条件下观察到的行为。一次点击可能表示兴趣,也可能是误触;一次未点击更不能直接翻译成“不喜欢”。
可以把观测过程写成一个简单关系:
若训练数据只保留点击,不保留曝光、位置和页面,就把“有没有机会看见”与“看见后喜不喜欢”揉成了一个标签。这就是曝光偏差的来源之一。
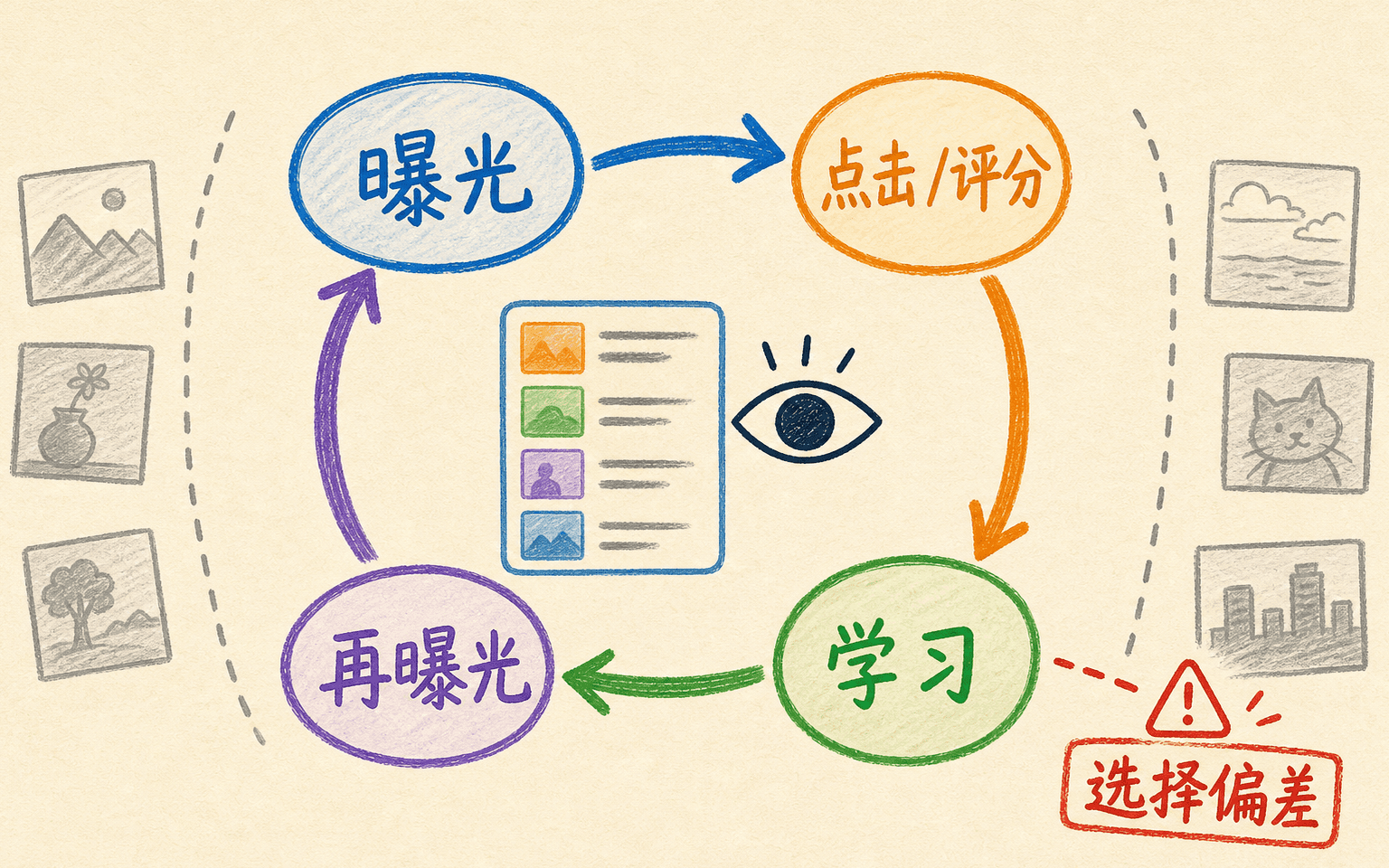
没有曝光就很难产生反馈;日志记录的是策略选择后的世界,不是完整偏好。
先选任务,再选损失函数
推荐问题至少可以分成以下几类:
如果产品目标是“给首页选 20 部电影”,只把 RMSE 做低并不保证前 20 名更好。评分误差会平等计算大量中间分物品,而用户真正看到的是列表顶部。任务、标签窗口和评估指标必须一起定义。
1
用户没有点击排在第 28 位的电影。最稳妥的解释是什么?
用召回、排序和重排搭起系统骨架
在一个只有几千部电影的练习数据集里,我们可以给每部电影打分再排序。真实内容库可能有百万到十亿级物品,复杂排序模型不可能在一次请求里逐个计算。因此,大型推荐系统通常是一只逐层收窄的漏斗。
![]()
召回追求不漏掉好候选,精排估计相关性,重排负责列表级约束。
召回要有多条互补通道
单一召回器会留下单一盲区。电影首页可以并行产生这些候选:
- 近期热门:服务新用户,也承接突发热点;
- 内容相似:从用户最近看完的悬疑片找题材、导演或文本向量相近的电影;
- 物品协同过滤:找“看过这部片的人还看过什么”;
- 用户兴趣向量:用双塔模型或矩阵分解召回与用户向量接近的物品;
- 继续观看与关注更新:用明确产品规则保证强意图内容进入候选;
- 探索通道:给新片、长尾内容或不确定兴趣保留受控流量。
不同召回器的原始分数通常不可直接比较。余弦相似度 0.83、热门分 12000 和规则通道的布尔值不在同一尺度。正确做法是合并并去重候选,把“来自哪些通道、各通道名次”等作为排序特征,再由统一排序模型比较。
排序优化的是动作价值,不是一个孤立点击
精排可以预测多个目标,例如点击率、有效观看率、收藏概率和负反馈概率,然后按预先定义的效用组合:
权重不是“模型自己会懂”的价值判断。只优化点击,可能学会夸张标题;只优化观看时长,可能偏爱天然更长的内容。目标函数要和产品希望改善的用户结果对应,并通过线上实验校验。
重排面对的是整张列表
排序模型逐项打分,重排器则看项目之间的关系。假设分数最高的十项都是同一系列的预告片,逐项相关性很高,整页体验却很单调。重排可以执行:
- 删除重复、已失效和不满足资格的物品;
- 对同系列、同创作者或同主题设置连续出现上限;
- 在相关性损失可控的前提下增加题材与创作者多样性;
- 插入需要时效保证的继续观看、直播或新上架内容;
- 输出每次规则命中的原因,方便复盘“好候选为何没展示”。
2
关于多阶段推荐架构,下列哪些说法正确?
内容推荐先回答“这件物品是什么”
内容推荐不需要等待很多用户共同评分。它根据物品本身的类别、文本、图片、作者、价格或时长建立向量,再从用户过去喜欢的物品推导兴趣向量。这对新物品尤其有用。
假设电影 的内容向量为 。向量可以由类型多热编码、简介的 TF-IDF、文本嵌入和数值特征拼接而成。对用户 ,用近期正反馈的加权平均构造兴趣向量:
其中 是用户历史集合, 可以反映动作强度与时间衰减。例如完整观看和收藏的权重可以高于一次短暂停留,近期行为可以高于很久以前的行为。候选分数可用余弦相似度:
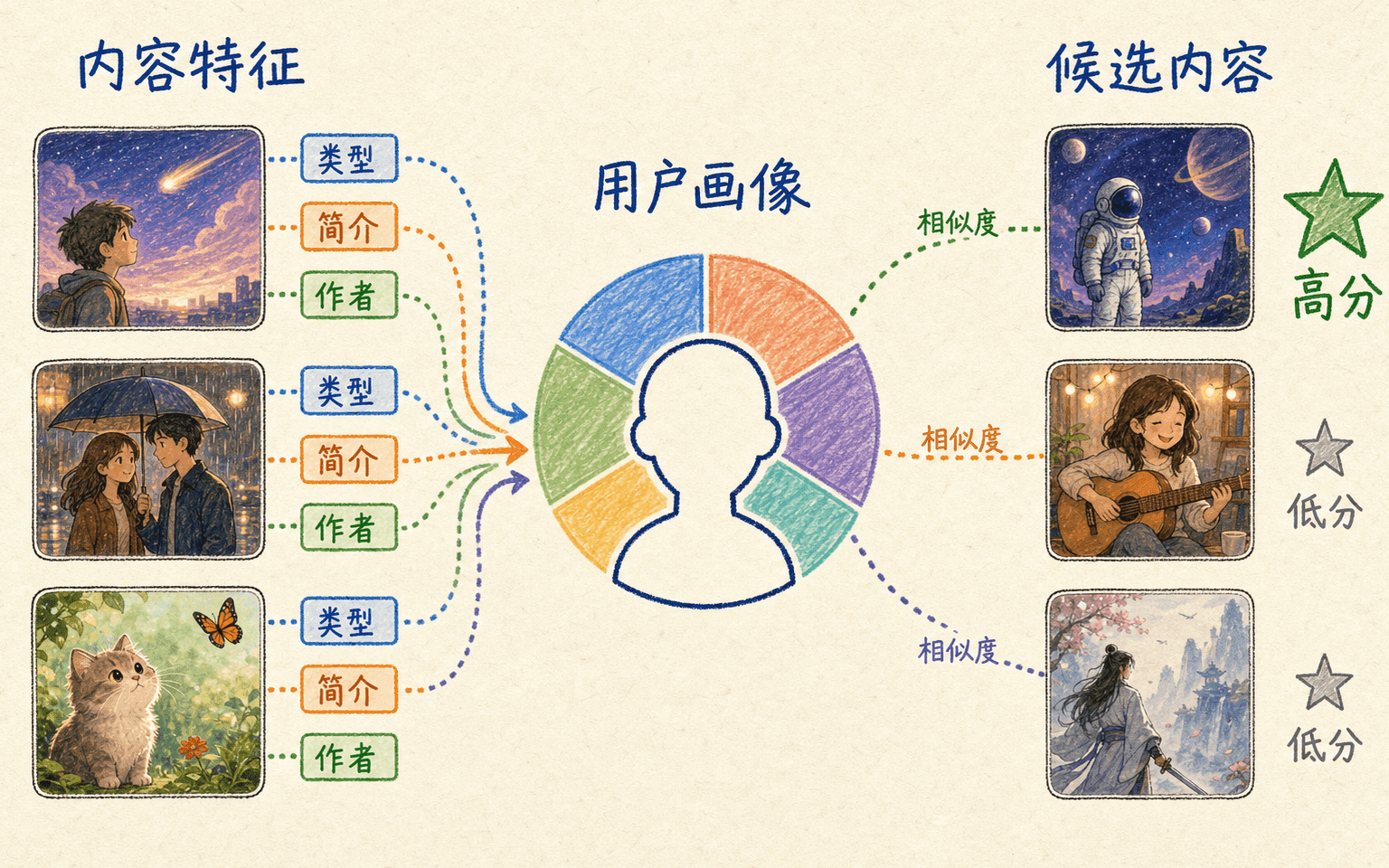
内容模型回答物品是什么以及用户曾偏好哪些属性,能服务新物品但受特征上限约束。
一个可复算的内容案例
为了看清计算,先只保留“悬疑、喜剧、科幻”三个类型维度。小林最近收藏了两部电影:
若两次收藏等权,未归一化的用户向量为:
候选 会得到较高相似度,候选 与当前画像正交。这并不表示小林永远不喜欢喜剧,只表示现有内容证据没有支持它。为了避免兴趣越推越窄,后续仍要加入探索与多样性。
内容特征也会泄漏未来
如果用电影上映一个月后才积累的热门标签训练“首日推荐”模型,离线结果会偷看未来。文本、标签、价格、库存和质量分都要按请求时间做快照。用户画像也只能使用当时已发生的行为。
内容推荐的主要边界包括:
- 过度相似:一直推荐历史内容的近邻,很难产生惊喜;
- 特征不等价于偏好:两部电影都叫“科幻”,叙事节奏可能完全不同;
- 尺度问题:未归一化的高维或高频特征会主导点积;
- 用户冷启动仍存在:新物品有内容,新用户却还没有兴趣历史;
- 跨模态质量依赖表示:文本和图像嵌入是否适合当前领域,需要离线与人工检查,而不是只看向量维数。
3
内容推荐只依赖物品属性,因此能缓解新物品冷启动;但如果新用户没有历史或主动选择,它仍缺少个性化依据。
邻域协同过滤从共同选择里找近邻
内容推荐问“物品像不像”,协同过滤问“人群是否以相似方式选择”。邻域方法直接在历史交互上寻找相似用户或相似物品,不必先训练低秩模型。
用户近邻与物品近邻
用户—用户协同过滤先找与目标用户偏好相近的人,再汇总这些人的反馈。它容易解释成“与你口味相近的用户喜欢了什么”,但用户兴趣变化快,用户数量也可能很大,近邻需要频繁更新。
物品—物品协同过滤根据共同交互用户计算物品相似度,再从用户已喜欢的物品扩展候选。物品关系往往比用户关系稳定,也便于离线预计算,所以常用于“看过 A 的人还看过”。
对显式评分,可以先扣除用户平均分,再计算共同评分集合上的相似度。设 是用户 与 都评分过的物品:
然后由已评价目标物品的近邻用户预测:
分母使用相似度绝对值,避免正负权重互相抵消后产生极小分母。工程实现还要处理“没有近邻”“所有相似度为 0”以及预测超出评分范围。
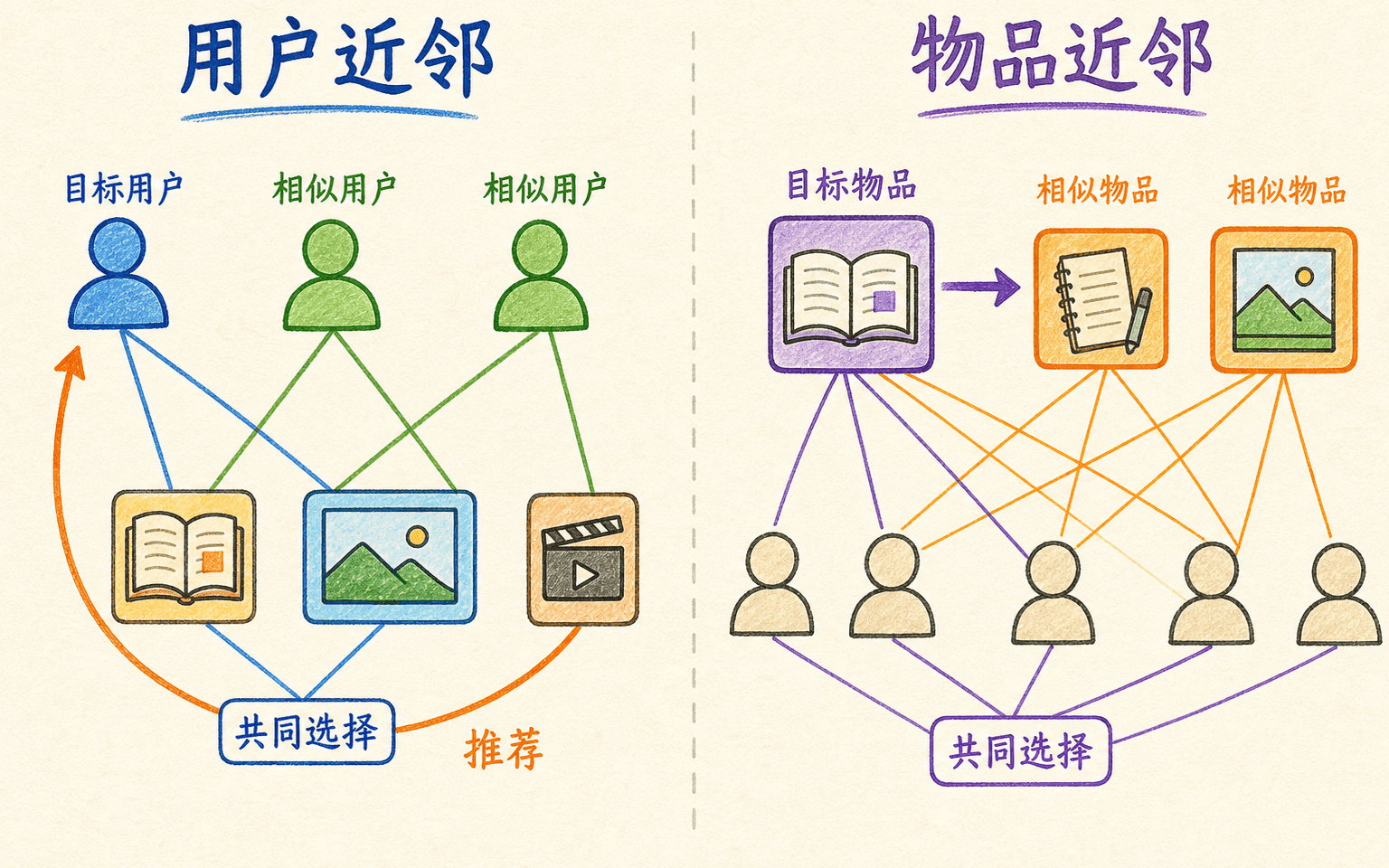
邻域方法依赖重叠行为;相似度、共同样本量和基线校正必须一起看。
共同样本太少时,相似度会虚高
两个用户只共同评过一部电影且都给了五星,不能据此认定口味完全相同。可以给相似度加收缩:
越大,对小重叠集合越保守。也可以设置最小共同交互数,并按活跃度采样,避免极活跃用户支配结果。
对隐式二值行为,常用 Jaccard 或余弦相似度。若 表示用户交互过的集合,则:
热门物品会让许多用户看起来相似。可以降低热门物品的权重,或者在相似度之外加入共现显著性、时间衰减和最小支持度。相似度是一种统计线索,不等于因果关系,也不保证两件物品在语义上相似;它们可能是互补关系。
4
用户甲和乙只有 1 部共同评分电影,相关系数为 1;用户甲和丙有 40 部共同评分电影,相关系数为 0.82。哪种处理更合理?
矩阵分解只在已观察评分上拟合低秩结构
邻域方法把相似度保存在大量用户或物品关系中。矩阵分解则给每个用户和物品学习一个较短的向量,让两者的内积近似已观察反馈。
设全局平均评分为 ,用户偏置为 ,物品偏置为 ,用户向量为 ,物品向量为 。预测写成:
偏置先解释“这个用户习惯打高分”和“这部电影普遍得分高”,低秩向量再解释剩余的个性化差异。若没有偏置,向量不得不同时承担总体流行度和个性偏好,通常更难学。
对显式评分,最常见的正则化平方损失是:
这里最关键的是求和范围 :只对真正观察到的评分计算误差。未知评分不是 0 分。若把稀疏矩阵先补零再做普通 SVD,成千上万个人为的 0 会压倒少量真实评分,模型学到的是“几乎所有东西都为零”。
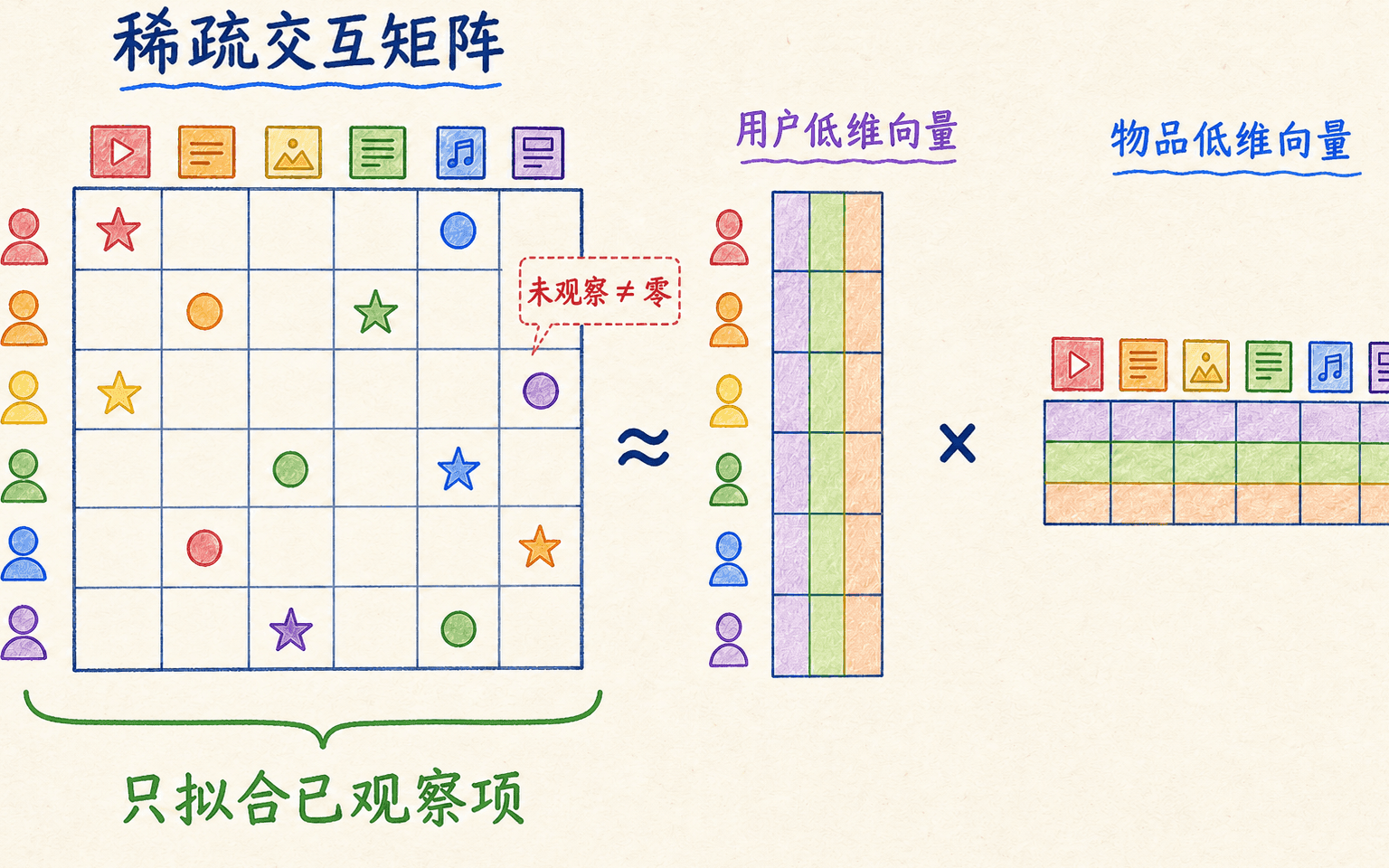
矩阵分解在低维空间学习匹配关系;未观察条目不是自动的负反馈。
低秩不等于每一维都有可读语义
我们常用“动作—文艺”“轻松—沉重”解释二维示意图,但真实模型的潜在维度通常会混合多种统计模式。即使只对用户与物品向量做相互匹配的正交旋转,内积与 L2 正则项也可以保持不变;同一维的符号还可能随初始化翻转。因此,不能看到第 7 维为正就直接命名为“喜欢科幻”。
若业务需要解释,应额外检查近邻、代表物品、特征相关性和解释稳定性,或者直接引入可读的内容特征与解释模型。低秩向量擅长压缩预测结构,不保证自动产出人类语义轴。
秩和正则化控制的是不同东西
秩 决定表示容量, 控制参数幅度。增大 可以表达更细的偏好,也增加过拟合与服务成本;增大 会把向量和偏置向 0 收缩。它们要在按时间构造的验证集上联合选择,不能只看训练损失。
5
关于显式评分矩阵分解,下列哪些说法正确?
均值中心化有用,但不能越过数据语义
评分数据里有两种常见基线:有些用户习惯打高分,有些电影普遍受欢迎。均值中心化可以先去掉这种水平差异,让相似度或低秩部分关注相对偏好。
对用户 ,只用训练期已观察评分计算:
其中 。中心化残差为:
模型预测残差后,再把用户均值加回来。物品中心化同理;更完整的基线会同时估计 ,并对样本很少的偏置做正则化收缩。
三条容易漏掉的边界
第一,均值只能由训练期数据计算。若用验证期或测试期评分参与用户均值,就提前看到了未来标签。
第二,新用户没有历史评分, 不存在。此时不能声称“中心化后自然解决冷启动”,只能退回全局均值、物品偏置、内容特征或入门偏好。
第三,隐式行为矩阵不是一张星级表。对点击 0/1 随手减用户均值,会把“未观察”当成大量确定的负反馈,也让结果依赖候选全集大小。隐式反馈应使用曝光感知的分类、排序或置信加权目标,而不是机械套用评分中心化。
下面的实现用 NaN 保留缺失语义,只中心化已观察单元格:
python
import numpy as np
def center_observed_ratings(ratings: np.ndarray):
"""ratings 的缺失值必须是 np.nan,而不是 0。"""
observed = ~np.isnan(ratings)
counts = observed.sum(axis=1)
sums = np.nansum(ratings, axis=1)
# 冷用户没有均值,单独标记;不能静默把它当成正常用户。
user_mean = np.divide(
sums,
counts,
out=np.full(ratings.shape[0], np.nan, dtype=float),
where=counts > 0,
)
centered = ratings.copy().astype(float)
rows, cols = np.where(observed)
centered[rows, cols] -= user_mean[rows]
return centered, user_mean6
为了避免测试泄漏,用户评分均值应只使用训练期内该用户已观察到的评分计算;冷用户则需要单独的回退策略。
SGD 与 ALS 是两条不同的矩阵分解训练路线
目标函数写出来后,还要决定怎样优化。显式反馈矩阵分解常用随机梯度下降(SGD)或交替最小二乘(ALS)。两者都不要求构造完整稠密评分矩阵,但更新方式不同。
SGD 按已观察交互逐条更新
对一个已观察评分 ,定义残差:
一次梯度更新可以写成:
实现最后两式时,要保存更新前的 ,避免 使用已经修改过的向量。每轮应打乱交互顺序,并根据验证集指标早停。
python
import numpy as np
def fit_explicit_mf(events, n_users, n_items, rank=16,
lr=0.01, reg=0.05, epochs=20, seed=7):
"""events: (user_id, item_id, rating);只传入已观察评分。"""
rng = np.random.default_rng(seed)
mu = float(np.mean([rating for _, _, rating in events]))
user_factors = rng.normal(0, 0.05, size=(n_users, rank))
item_factors = rng.normal(0, 0.05, size=(n_items, rank))
user_bias = np.zeros(n_users)
item_bias = np.zeros(n_items)
order = np.arange(len(events))
for _ in range(epochs):
rng.shuffle(order)
for index in order:
user, item, rating = events[index]
prediction = (
mu + user_bias[user] + item_bias[item]
+ user_factors[user] @ item_factors[item]
)
error = rating - prediction
old_user = user_factors[user].copy()
user_bias[user] += lr * (error - reg * user_bias[user])
item_bias[item] += lr * (error - reg * item_bias[item])
user_factors[user] += lr * (
error * item_factors[item] - reg * user_factors[user]
)
item_factors[item] += lr * (
error * old_user - reg * item_factors[item]
)
return mu, user_bias, item_bias, user_factors, item_factors这段代码用于解释更新,不是生产训练器。它没有验证早停、学习率调度、稀疏批处理、冷实体回退、数值监控和检查点。真正训练时还应记录每轮验证指标,而不是只盯着训练目标下降。
ALS 交替求解两组最小二乘
若固定所有物品向量 ,每个用户向量都是一个正则化最小二乘问题;固定 后,物品向量同理。忽略偏置以简化记号,用户 的更新为:
实际实现不显式求逆,而是解线性方程。各用户在固定 时相互独立,便于并行;但每一步要解 系统。隐式反馈 ALS 会使用另一套置信加权目标,不能把显式评分公式原样套过去。
7
固定物品向量后逐个求解用户向量,再固定用户向量求解物品向量,这种训练方法简称为 ____。
隐式反馈要区分偏好、置信度和采样机会
大多数线上系统没有足够的星级评分,只有观看、点击、购买和跳过。这里最危险的简化是:“交互过就是 1,其余全是 0,而且 0 都表示不喜欢。”
更准确的说法是:观察到的正行为提供了不同强度的偏好证据;未观察项通常只是低置信度未知。有些模型会在数学上把未观察偏好记为 0,但同时给它很低的权重,这个 0 是建模基准,不是已观察到的负面评价。
置信加权矩阵分解
对隐式行为次数 ,可以定义二值偏好:
再定义置信度:
置信加权目标为:
这里会考虑未观察项,但它们的基础置信度较低;行为越多,对 的信心越强。重复次数是否应该线性增加置信度,要根据业务决定,常见做法是对次数做对数压缩,避免循环播放或批量购买支配训练。
负采样是计算策略,也是数据假设
全量用户—物品对太多,分类或双塔召回常从未观察项中采一小部分负例。采样方式会改变模型看到的世界:
- 均匀采样覆盖长尾,但会抽到大量太容易的物品;
- 按流行度采样提供更有竞争力的负例,却可能强化热门倾向;
- 曝光未点击采样语义更接近“有机会但没选”,仍要处理位置与可见性;
- 难负例采样从当前模型高分但未互动的物品中选,学习效率高,也更容易放大错误或抽到用户其实喜欢的假负例。
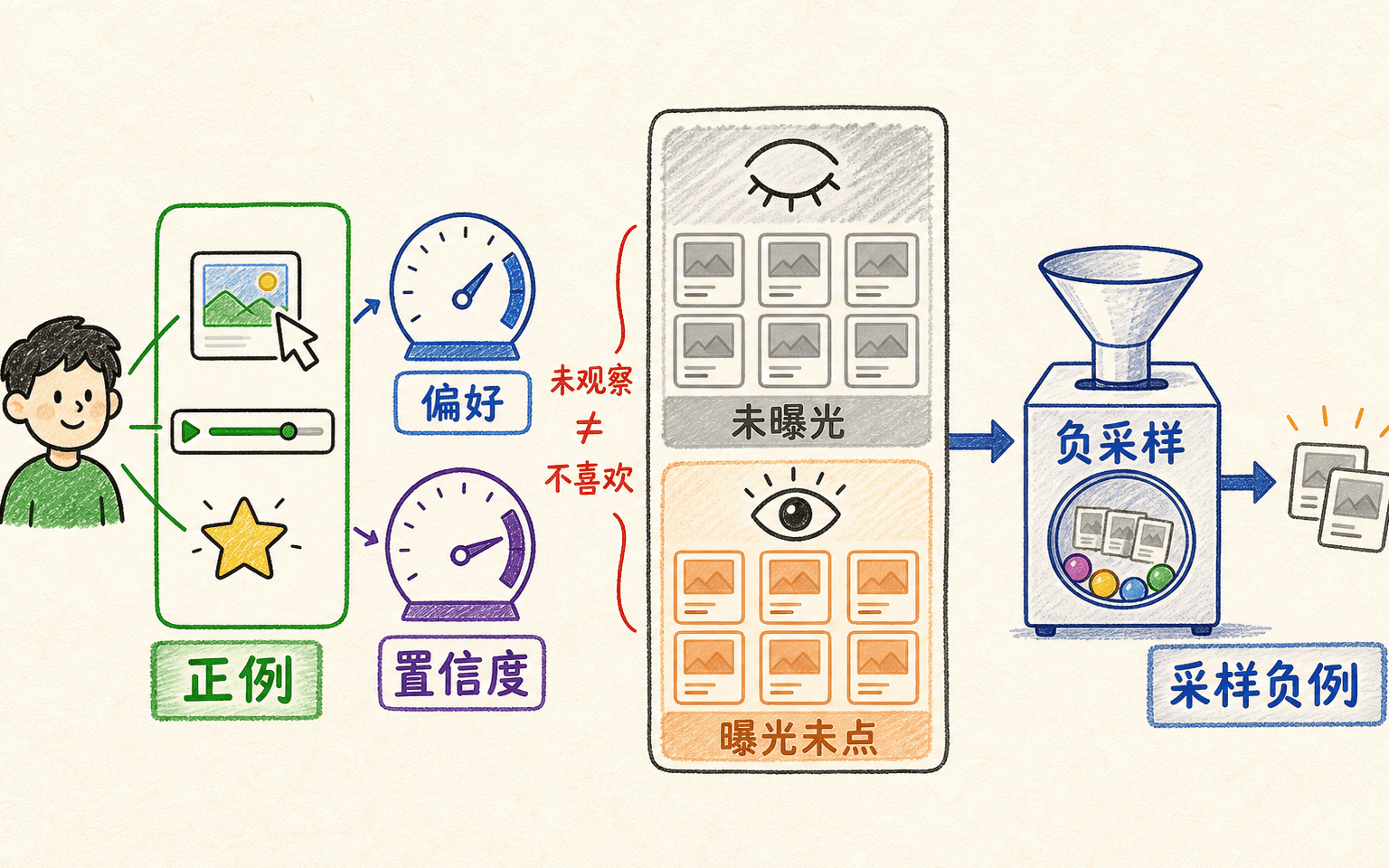
未点击可能是不喜欢,也可能根本没看见;负采样必须承认曝光机制。
如果训练时每个正例只配 20 个采样负例,模型输出的 sigmoid 一般不能直接当作全库点击概率。采样改变了正负比例,需要校准或按采样分布修正。离线评估也应说明是全库评估还是采样候选评估,因为两者的 Recall@K 不可直接比较。
Pairwise 排序直接学习“正例排在未观察项之前”
BPR 一类方法从三元组 学习,其中 是用户观察到的正例, 是采样未观察项:
它优化相对顺序,不要求预测星级。但“ 应排在 前”仍是从观测行为推断出的训练偏好,不是用户亲口表达的完整顺序。曝光偏差、采样分布和延迟转化仍会影响结果。
标签窗口也要写清楚。例如“曝光后 30 分钟内播放超过 5 分钟”与“曝光后 7 天内完成购买”不是同一个目标。窗口太短会漏掉延迟行为,太长则可能把别的入口带来的转化归因给当前推荐。
8
为隐式反馈模型构造负例时,下列哪些做法合理?
冷启动需要把内容、上下文和探索接起来
协同过滤依赖历史共同选择。新用户没有历史,新物品没有交互,新平台甚至连稳定的热门榜都没有,这三种冷启动要分别处理。
新用户先给一个可解释的默认列表
匿名用户进入“周末电影”页面时,地区版权、设备类型、时间和页面主题已经提供了上下文。系统可以先返回当前场景的高质量热门内容,而不是随机电影。用户开始点击、搜索、收藏后,会话画像可以快速覆盖默认画像。
入门兴趣选择也有代价。让用户先选 20 个喜欢的类型会增加流失;只选 3 个类型又可能过粗。需要通过实验比较完成率、后续推荐质量与用户控制感。
新物品不能等它“自然变热门”
纯协同模型对无交互物品无法学习可靠向量。可以用内容编码器生成初始表示,进入内容或双塔召回;再划出有上限的探索流量,收集早期反馈。探索应设置质量与安全门槛,不能把“新”当作免审理由。
混合系统可以把协同分、内容分、热门分和上下文特征一起交给排序器:
还应显式记录实体年龄与交互数,让排序器知道某个协同分“不可靠”,而不是用一个默认 0 混同“确实不匹配”。
9
一部刚通过审核的新纪录片还没有任何观看记录。哪种上线策略更合理?
离线切分必须模拟“用过去推荐未来”
推荐日志有明确时间顺序。若把同一用户两年的行为随机分到训练和测试,训练集可能看到他在测试事件之后的兴趣、物品热度和标签,得到过于乐观的结果。更贴近上线的方式是按时间切分。
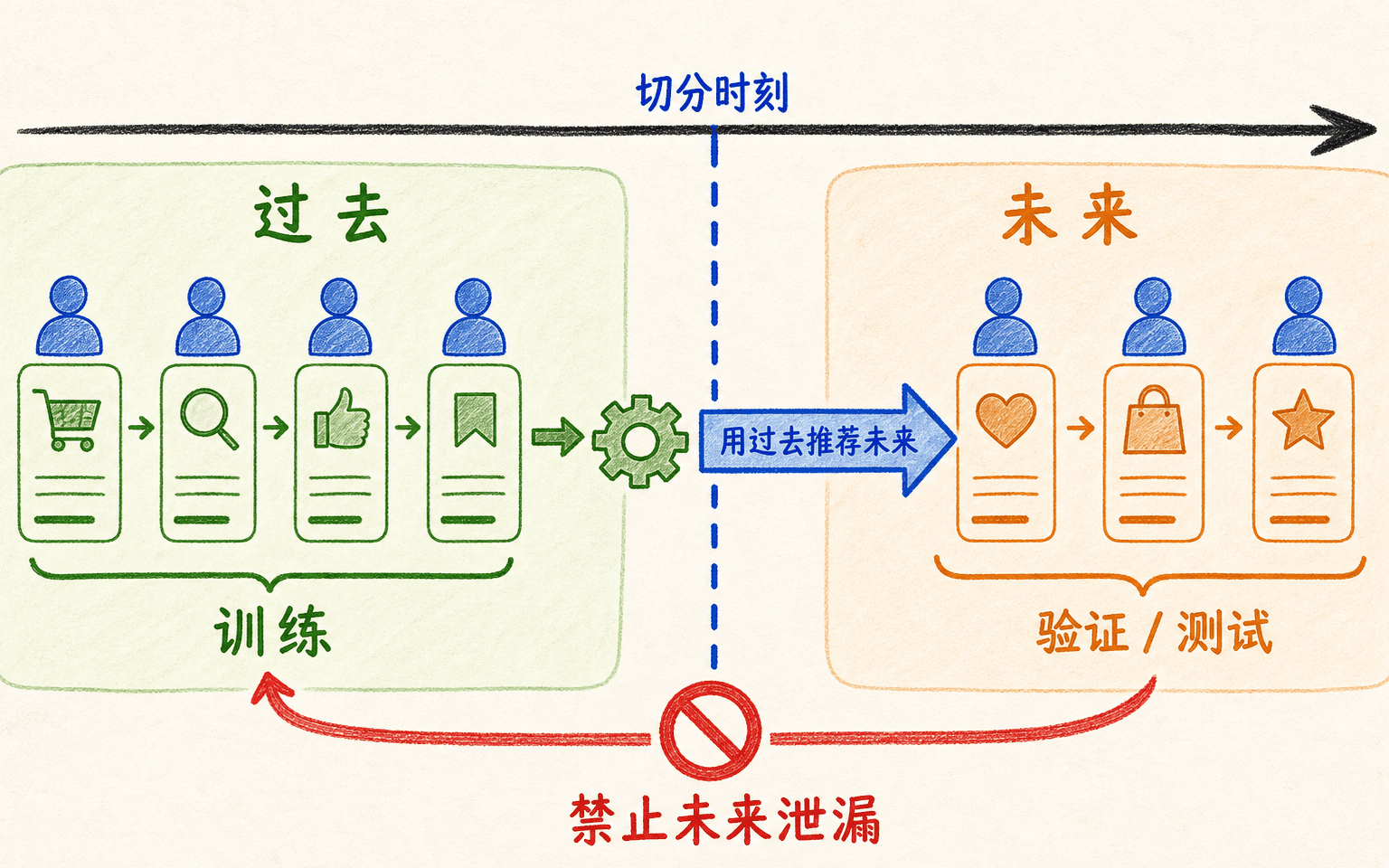
离线切分要模拟上线时的信息边界,不能让未来行为进入历史特征。
三种问题对应三种切分
- 全局时间切分:在时间 前训练, 到 验证, 到 测试。它最接近定期重训后面向未来流量的场景。
- 用户内时间切分:对每个用户保留最后一次或最后几次交互测试,其余更早行为训练。它适合“已知用户的下一项推荐”,但要保证测试时物品当时可用。
- 用户留出:把一批完整用户只放到测试,用于评估新用户或跨用户泛化。若模型只靠用户 ID 嵌入,这个测试会暴露它无法服务冷用户。
不能笼统规定某一种永远最好。关键是切分协议要和部署问题一致,并保持时间、用户和物品资格不泄漏。
特征也要做时间旅行检查
对测试时刻 的请求,只能使用 之前可获得的信息。需要逐项检查:
- 用户历史是否截断到 ;
- 物品热度是否只统计 前窗口;
- 文本标签和质量分是否当时已经存在;
- 训练负例是否混入未来才上架的物品;
- 测试候选集是否遵守当时版权、库存与审核状态;
- 归一化均值、词表、编码器和超参数是否只在训练/验证阶段拟合。
测试集合不是“所有没点的东西”
对每位用户,可以把测试窗口内的真实正行为作为相关集合 ,再从当时有资格的目录构造候选。训练期已看物品是否排除,要按产品语义决定:连续剧、音乐和日用品可能允许重复推荐,电影首看场景通常会排除已看完内容。
测试还应按用户活跃度、新老用户、热门/长尾物品和设备分层报告。一个总体均值可能掩盖模型只改善了高活跃用户,却让冷用户更差。
python
def global_time_split(events, train_end, valid_end):
"""每条事件至少有 timestamp;边界应在看测试结果前固定。"""
train = events[events["timestamp"] < train_end]
valid = events[
(events["timestamp"] >= train_end)
& (events["timestamp"] < valid_end)
]
test = events[events["timestamp"] >= valid_end]
return train, valid, test10
目标是评估模型每周重训后对下一周用户行为的推荐效果。哪种切分最贴近部署?
用 Recall、NDCG、MAP 与列表指标一起评估
设用户 在测试窗口的相关物品集合为 ,模型返回的前 个物品为 。推荐评估关心的是列表,而不只是单点误差。
Recall@K 看找回了多少真实相关项
如果真实相关集合有 4 部电影,前 10 名命中 3 部,Recall@10 为 。它适合召回阶段,因为召回漏掉的物品无法进入后续排序。若每个用户测试期只有一个正例,Recall@K 就退化成命中率。
NDCG@K 奖励把相关项放得更靠前
对位置 的相关度记为 :
把同一组相关度按理想顺序排列得到 ,再归一化:
二值相关时 ;有星级或行为强度时可以使用分级相关度,但必须事先定义。若某用户 ,应明确是排除该用户还是把指标记为 0,不能让库函数默认值悄悄决定。
MAP@K 同时看多次命中的前缀精度
用户的平均准确率可以写为:
再对可评估用户求平均得到 MAP@K。它会奖励相关项连续出现在列表前部。不同工具对分母、重复物品和无正例用户的约定可能不同,团队应先用一个手算小例子锁定定义。
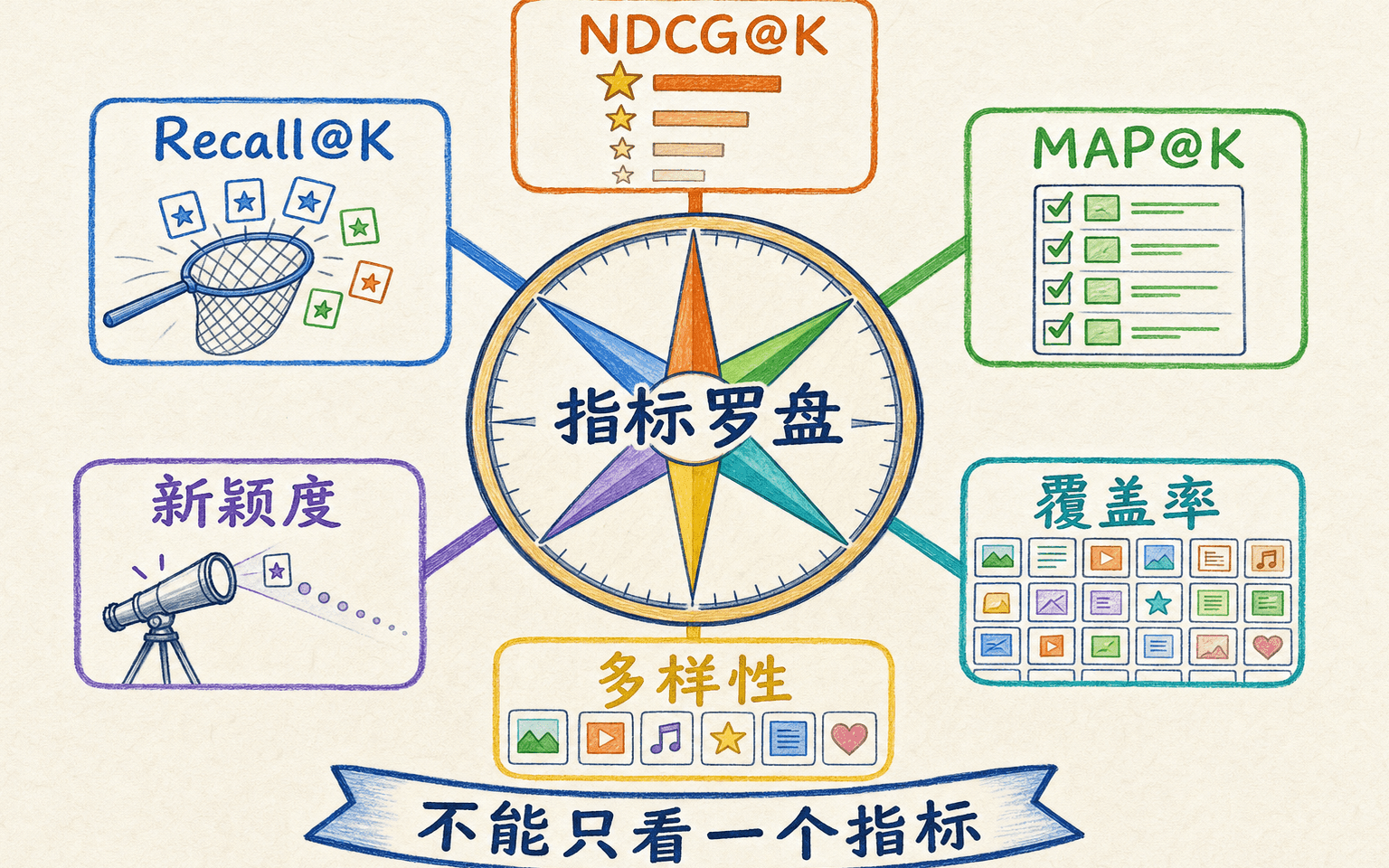
单个相关性指标无法代表整个推荐列表,需要同时检查顺序、覆盖与体验。
相关性之外,还要看列表和目录
只优化相关性容易让所有人看到少数热门物品。至少还可以报告:
- 目录覆盖率:评估期内至少被推荐一次的物品数占合格目录比例;
- 用户内多样性:同一列表内物品两两不相似度的平均值;
- 流行度/新颖度分布:推荐是否集中于头部,用户是否接触到较少见但相关的内容;
- 创作者或供应方曝光:曝光是否过度集中,且是否满足产品定义的机会约束;
- 负反馈与质量:隐藏、举报、快速跳出等不能被点击提升掩盖。
覆盖率高不自动代表体验好,随机推荐就能覆盖全库;多样性高也不自动代表相关。正确做法是报告相关性—覆盖—多样性的权衡,并设定可接受边界。
离线指标还受候选协议影响。若每个正例只配 99 个随机负例,任务比从百万目录检索容易得多。报告必须写清 、候选范围、已看过滤、相关标签、宏/微平均和负采样方式。
11
关于 Top-K 离线评估,下列哪些说法正确?
ANN 解决召回速度,不替代精排质量
若用户向量为 、物品向量为 ,全库内积召回需要对 个物品计算:
每次请求的朴素复杂度约为 。当 很大时,可以把物品向量建成近似最近邻(ANN)索引,牺牲少量检索精度换取显著延迟和成本改善。
为什么双塔适合向量检索
双塔模型分别编码用户与物品:
物品向量可以离线计算并放进索引;请求到来时只计算用户塔,再做最近邻搜索。这种可分解结构带来速度,也限制了召回阶段:用户—物品的复杂交叉特征不能在预计算物品向量时逐对使用。精排面对数百候选后,才有预算加入交叉网络、实时上下文和更重模型。
ANN 有自己的验收指标
不能只看端到端 NDCG。索引层至少要监控:
小目录或离线相关物品可以先用精确检索,它更简单,也是评估 ANN 召回损失的基准。只有延迟或成本确实成为瓶颈时,才需要调索引的图连接数、探测范围、量化精度等参数。
ANN 返回的是向量分数近似最高的一批物品,不是最终最优列表。资格过滤、业务约束、复杂排序和列表重排仍要在后续完成。若索引漏掉关键候选,精排再强也无法恢复。
12
把精确向量检索换成 ANN 后,只要请求延迟下降,就可以省略 ANN Recall、索引新鲜度和模型版本一致性检查。
流行度偏差与反馈环要靠受控探索打断
推荐系统会改变自己未来的训练数据:模型展示某些内容,用户只能在这些曝光中产生大部分行为;下一版模型再从这些行为学习,于是已有优势可能被不断放大。
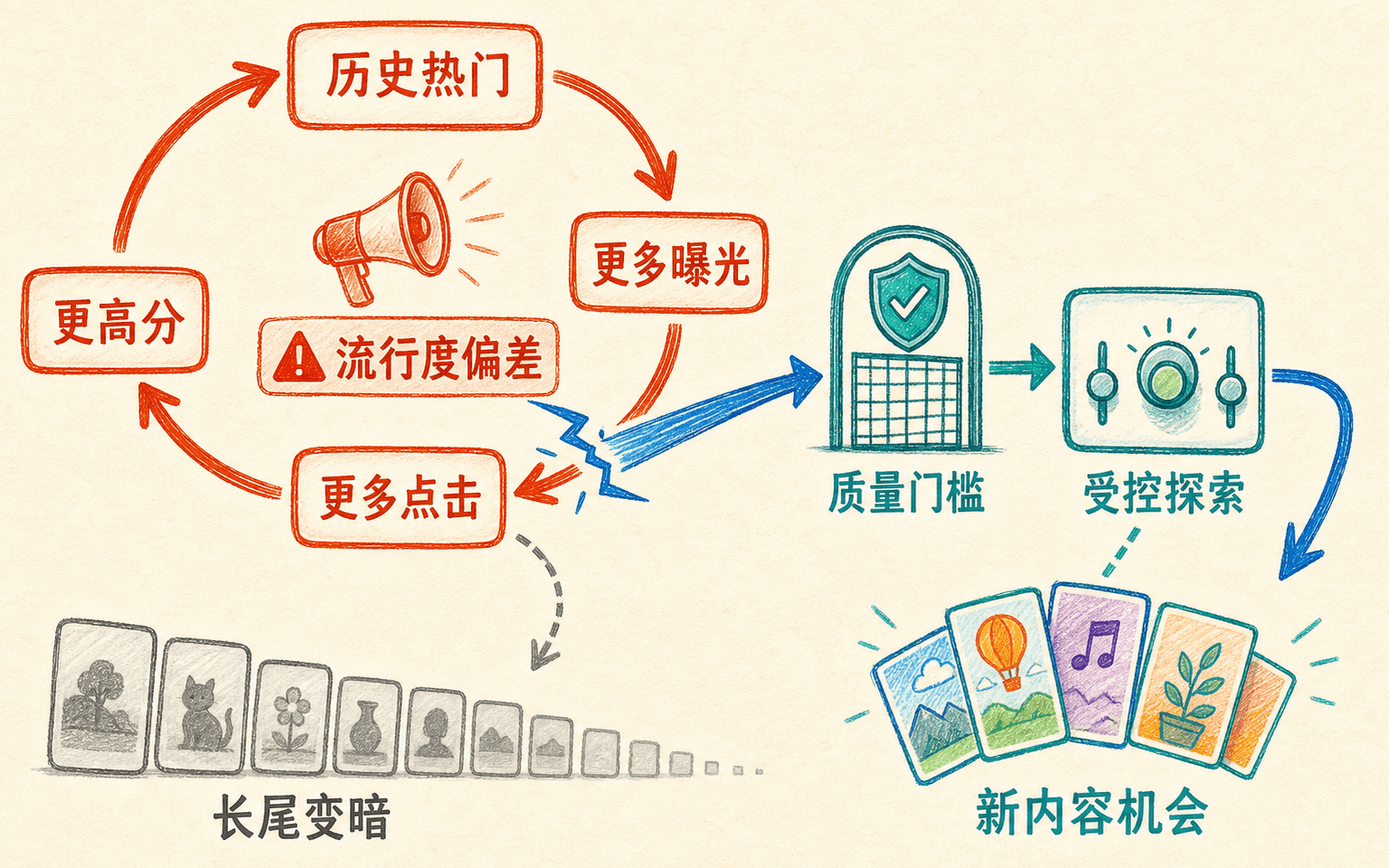
反馈环会把既有流行度不断放大;受控探索为系统补充反事实证据。
一个典型循环是:
- 热门物品因历史交互多而获得高分;
- 高分让它得到更多靠前曝光;
- 靠前位置带来更多点击;
- 新点击被当作更强偏好证据;
- 模型进一步提高它的分数,长尾与新物品更难获得数据。
这不表示热门内容不该推荐。问题在于模型无法仅凭观察日志区分“本来更受欢迎”和“因为得到更多机会而更受欢迎”。位置、候选来源、策略版本和展示概率等日志能让我们分析曝光机制;随机或受控探索则提供不同于旧策略的数据。
探索不是把差内容随机塞给所有人
一种简单做法是在满足质量、安全和资格门槛的候选里,给少量流量使用不同于当前最优分的选择策略。探索比例应受场景风险约束:娱乐内容和医疗建议显然不能使用同一规则。
可以采用:
- 在同等质量候选间做小比例随机化;
- 对不确定度高的新物品给受限曝光预算;
- 使用上下文 bandit 在收益和不确定性之间取舍;
- 为用户提供“减少此类内容”“换一批”等显式控制,并把反馈纳入模型;
- 按创作者、主题和流行度分层监控曝光,发现某一群体被系统性挤出。
探索数据也要带上策略概率或分桶信息。没有这些记录,就很难在离线反事实评估中还原“某个候选当时被选中的机会”。但记录倾向概率不等于自动消除偏差;极小概率会让逆倾向加权方差很大,模型设定与日志质量仍需检查。
多样性与覆盖是约束,不是装饰
重排时可以使用最大边际相关性一类思想,在相关性和与已选列表的相似度之间权衡:
是已经选入列表的物品。 越大越重相关性,越小越鼓励差异。参数不能只凭审美决定,应结合离线权衡、人工检查和线上长期指标。
13
哪些措施有助于识别或缓解推荐反馈环?
线上 A/B 实验验证真实因果效果
离线评估能快速淘汰明显较差的模型,却不能回答“把新策略上线会不会让用户体验变好”。历史日志来自旧策略,用户还会对新列表作出新的行为。随机对照 A/B 实验才是验证线上因果效果的主要工具。
实验前先写可证伪假设
一个合格假设应说明改变、目标人群、主要指标、预期方向和护栏。例如:
对有至少 5 次历史观看的首页用户,将单路矩阵分解召回换成多路召回,预计 7 日有效观看用户率提高;同时首屏加载 P95、隐藏率、举报率和崩溃率不得超过预设退化边界。
主要指标只回答核心决策,护栏负责阻止“用别处的损失换一个漂亮数字”。推荐实验可考虑:
点击率可以是诊断指标,却不一定适合单独做北极星。按钮位置变化可能提高点击而不改善观看;更激进的封面可能提高点击,同时增加快速退出。
以用户为随机单元并保持粘性
如果同一用户今天进实验组、明天进对照组,历史状态和模型反馈会交叉污染。多数个性化推荐实验会按用户稳定分桶;未登录场景则要评估设备或会话分桶的跨端问题。
实验还应检查:
- 样本比例失配(SRM):实际组间人数是否偏离配置比例;
- 实验功效:流量和周期能否检测业务关心的最小变化;
- 周期效应:是否覆盖工作日、周末和内容更新周期;
- 新奇效应:短期好奇是否会在几天后消退;
- 干扰与共享数据:两组是否共享会被彼此行为更新的热门榜、索引或训练数据;
- 触发口径:全量用户与真正触发新策略的用户要分别解释,不能事后挑有利口径。
从影子流量到逐级放量
高风险改动不必一步放到 50%。常见上线顺序是:离线回放和单元检查、影子请求验证延迟与稳定性、内部流量、1% 小流量、逐级扩大、达到预定周期后决策。每一级都应有自动停止条件,例如错误率或举报率越过护栏。
统计显著不等于业务值得上线。还要看效应大小、置信区间、实验成本、分群一致性和护栏变化。反过来,“没有显著差异”也不等于两方案等价,可能只是样本不足。
14
新排序器让点击率显著上升 2%,但快速退出率和 P95 延迟都超过预设护栏。最合理的决策是什么?
把电影案例从日志一路接到上线
现在把前面的部件组装起来。假设平台有 200 万用户、30 万部电影与短内容,希望为首页返回 20 项。事件包括曝光、点击、播放时长、完成、收藏、隐藏和举报;物品特征包括类型、简介、演员、时长、上映时间、地区版权与质量状态。
数据协议
先保留原子事件,再派生标签:
text
曝光表:request_id, user_id, item_id, position, source,
policy_version, eligible, timestamp
行为表:request_id, user_id, item_id, action,
watch_seconds, timestamp
物品快照:item_id, genres, text_embedding, duration,
publish_time, region_rights, quality_state, snapshot_time定义一次“有效观看”为曝光后 24 小时内播放至少 10 分钟,或短内容观看比例达到 60%。收藏是更强正反馈,隐藏和举报是负反馈。这个定义要按内容长度分层验证,避免长片天然更难达到完成比例、短片天然更容易完成。
先建立三条可以解释的基线
第一条是按地区、时间窗口和内容质量过滤后的热门榜;第二条是从最近正反馈物品出发的内容相似;第三条是带最小共现与收缩的物品协同过滤。基线的价值不是“先进”,而是让团队知道复杂模型到底改善了哪一部分。
接着训练带偏置的显式矩阵分解处理星级数据,或使用置信加权/Pairwise 目标处理隐式行为。矩阵分解向量可以提供一条个性化召回通道,但不把它当作唯一通道。
一次请求的完整路径
先根据地区版权、年龄、审核、设备支持和用户屏蔽列表确定当时合格的物品集合。过滤规则要版本化,否则无法复现历史请求。
并行调用热门、继续观看、内容相似、物品协同过滤、个性化向量与新内容探索通道。每个通道返回物品、通道内分数、名次和生成原因。
合并去重候选。一个物品由多个通道召回时保留全部来源特征,而不是随意只留第一条来源。
粗排先用轻量模型把几千项缩到几百项,精排再加入用户—物品交叉、实时会话、内容质量和多目标预估。训练特征与在线特征必须共享定义并监控漂移。
重排删除失效和重复内容,控制同系列连续出现,加入多样性、新鲜度、创作者频控与受控探索,最终返回 20 项。
记录进入过哪一阶段、在哪一阶段被淘汰、最终位置和策略概率。用户行为通过同一 request_id 回连,形成可审计的训练样本。
下面的伪代码强调边界,而不是某个框架的 API:
python
def recommend_home(user, context, k=20):
eligible = eligibility_service.snapshot(context)
pools = [
popular_retriever.fetch(user, context, eligible, limit=300),
continue_watching.fetch(user, context, eligible, limit=100),
content_retriever.fetch(user, context, eligible, limit=400),
item_cf_retriever.fetch(user, context, eligible, limit=400),
ann_user_retriever.fetch(user, context, eligible, limit=800),
exploration_retriever.fetch(user, context, eligible, limit=100),
]
candidates = merge_with_all_sources(pools)
candidates = coarse_ranker.top(candidates, user, context, limit=300)
candidates = fine_ranker.score(candidates, user, context)
result = rerank_with_constraints(candidates, user, context, k=k)
log_request_and_stage_outcomes(user, context, pools, candidates, result)
return result离线验收表
按全局时间切分训练、验证和测试,同时单独做新用户留出。每次实验固定并报告:
- 召回阶段的真实正例 Recall@100、Recall@500 与各通道贡献;
- 最终列表的 Recall@20、NDCG@20、MAP@20;
- 热门/长尾分层、冷/暖用户分层和新/旧物品分层;
- 目录覆盖、用户内多样性、创作者曝光集中度;
- ANN 对精确检索的召回、索引新鲜度、P95/P99 延迟;
- 隐藏、举报等负标签的排序表现;
- 和热门、内容、物品协同过滤基线的同协议比较。
离线通过后,先验证线上特征一致性与日志完整性,再按用户稳定分桶做 A/B。主要指标可以是 7 日有效观看用户率,护栏包括快速退出、隐藏、举报、延迟、错误率和生态覆盖。只有收益、护栏和数据质量同时满足预先标准,才逐级放量。
最后用四个问题做上线前自检
- 我们有没有记录物品获得反馈之前的曝光机会?
- 召回漏掉的正例,究竟是模型、索引、资格规则还是新鲜度造成的?
- 离线测试是否只使用了请求当时可获得的特征和物品?
- 线上主要指标改善时,用户负反馈、系统稳定性和内容生态有没有付出不可接受的代价?
推荐系统做到这里,已经不再是一条矩阵分解公式,而是一套持续产生数据、做决策并接受验证的系统。下一章讨论大规模机器学习时,我们会继续处理其中的训练吞吐、流式更新与分布式计算问题。
15
电影首页准备上线新推荐链路。哪些项目应同时进入最终验收?