机器学习里的线性代数:从形状、变换到最小二乘
第一次在机器学习代码里看到 X @ W + b,很多人会把它当成一条需要背下来的语法。这样学当然也能跑起来,但只要数据从一个样本变成一批样本,或者输出从一个数变成多个数,维度错误就会接连出现。
更稳妥的办法,是先把线性代数当成一门“描述数据形状和数据流向的语言”。矩阵的行、列各自代表什么?一次乘法把哪个空间里的向量送到了哪个空间?最小二乘为什么会出现转置?代码为什么应该用 lstsq,而不是照着公式手动求逆?这些问题一旦连起来,公式就不再是零散规则。
这一节默认在实数范围内讨论。数学推导中,向量默认写成列向量;在 NumPy 代码中,我们会同时说明一维数组与二维列向量的差别。读完后,你应该能做到三件事:看到公式先判断形状,看到矩阵乘法能说出它的几何或数据含义,遇到数值问题知道该检查哪里。
先看形状,再看矩阵里装了什么
线性代数里最基础的对象有三个:标量、向量和矩阵。它们的差别不只是“数字有多少”,还在于这些数字如何组织。
假设我们记录 4 套房子的面积、卧室数和房龄。按机器学习里常见的“每行一个样本、每列一个特征”约定,可以写成:
这里的 是样本数, 是特征数。为了后面不反复解释,我们约定:
- 表示样本数;
- 表示特征数;
- 表示输出数或某个中间表示的宽度;
- 表示第 个样本的第 个特征。
在数学里,索引通常从 1 开始,所以 。在 Python 中索引从 0 开始,同一个元素要写成 X[1, 2]。这类差一位的错误看起来很小,却经常让数据解释完全错位。
标签也要说明形状。若每套房子只有一个价格,可以把标签写成列向量:
数学记号 表示含 4 个分量的向量,默认把它理解为列向量。在 NumPy 中,np.array([168, 196, 149, 205]) 的形状却是 (4,),它既不是 (4, 1),也不是 (1, 4)。如果确实需要二维列向量,要显式写成 y.reshape(-1, 1) 或 y[:, None]。
形状不是写在公式旁边的装饰。它很像程序里的类型:先确认输入和输出的形状,往往能在计算前发现错误。尤其不要把数学里的“列向量”直接等同于 NumPy 的一维数组。
在线性回归中,我们有时会把常数项并入矩阵。给 左侧添加一列 1,就得到设计矩阵 ;参数向量也要增加一个截距参数:
这样做不是强制规则。有些代码把截距单独保存为 b,有些代码把它并入参数。真正需要保持一致的是:你采用了哪种约定,后面的形状就必须跟着它走。
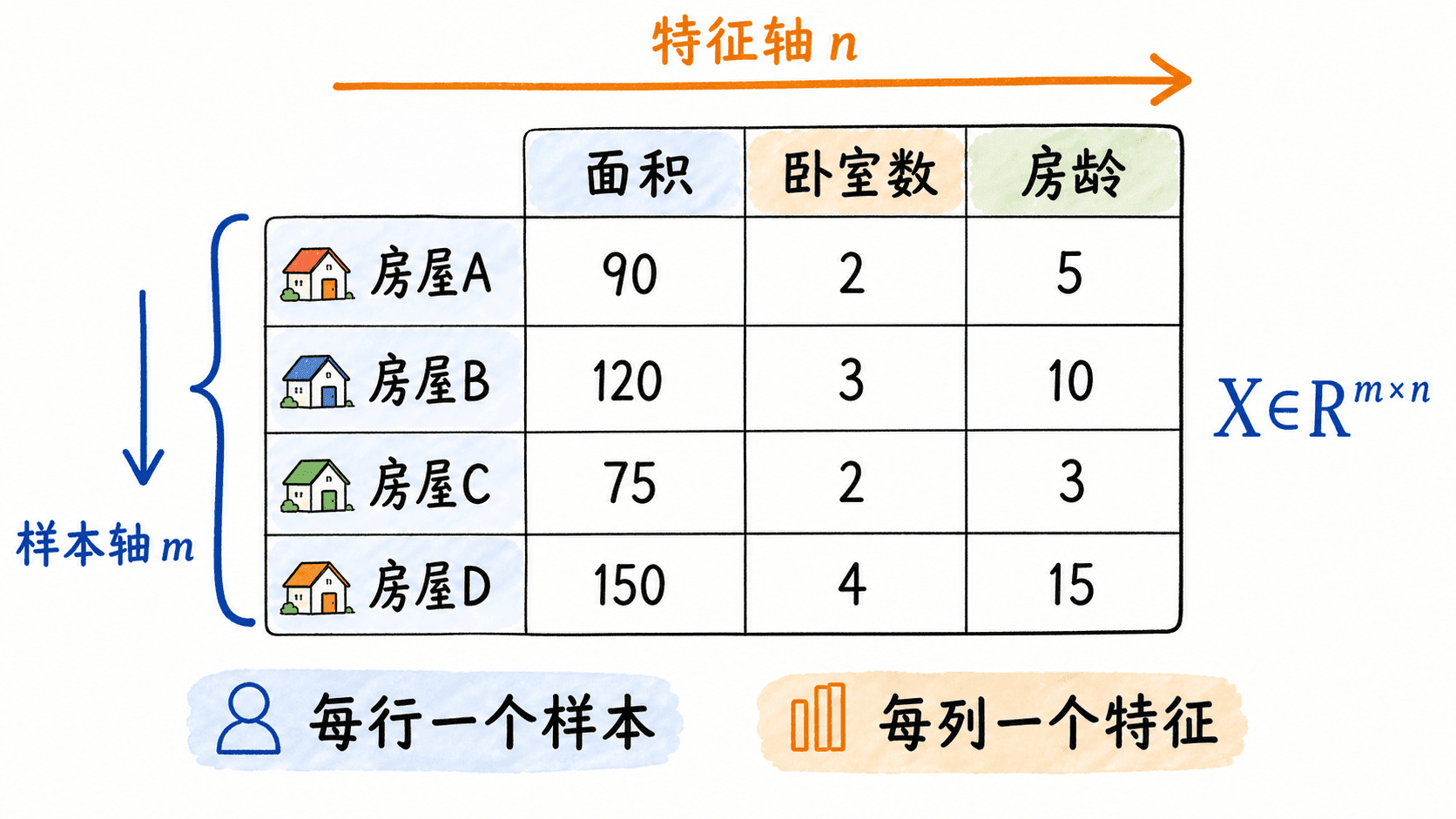
数据矩阵的形状:每行代表一个样本,每列代表一个特征。
如果你对“样本轴、特征轴、输出轴”还没有形成直觉,可以在下面的形状实验里切换批量大小和特征数,观察每个对象怎样随之变化。
1
一个数据集有 120 个样本,每个样本有 5 个特征。按每行一个样本的约定,数据矩阵 X 的形状是什么?
向量运算把长度、方向和相似度变成数字
向量可以表示一个样本,也可以表示一个方向。对两个同维向量做加法,是把对应位置相加;乘以标量,则是把每个分量按同一比例放大或缩小。
这两种运算看似简单,却已经能描述梯度下降的一步:
梯度给出参数空间里的一个方向,学习率 控制沿这个方向走多远。
点积是加权求和
给定两个 维向量 和 ,点积定义为:
从计算角度看,它就是“对应元素相乘,再全部相加”。从模型角度看,它是一次加权求和。比如用户的三个特征为 ,模型权重为 ,那么评分是:
同一个点积还有几何解释:
是两个向量之间的夹角。因此,点积为正通常表示夹角小于 ,点积为零表示正交,点积为负表示大致指向相反方向。
范数和距离回答“相差多远”
最常见的欧几里得范数,也叫二范数:
两个样本之间的欧几里得距离,就是差向量的范数:
如果我们更关心方向,而不是绝对大小,可以使用余弦相似度:
零向量的范数是 0,因此不能直接放进分母。实际代码通常会先检查范数,或加上一个很小的稳定项,但这个稳定项会轻微改变原公式,不能把它当作纯数学等价变形。
内积和外积不要混在一起
若 、,那么:
- 只有在二者维度相同时才有定义,结果是标量;
- 总能构造,结果是 矩阵;
x * z在 NumPy 中通常是逐元素乘法,不会自动表示上面任意一种乘积。
外积的第 个元素是 。协方差、低秩分解和注意力机制里都会遇到这种“由两个方向铺成一张矩阵”的操作。
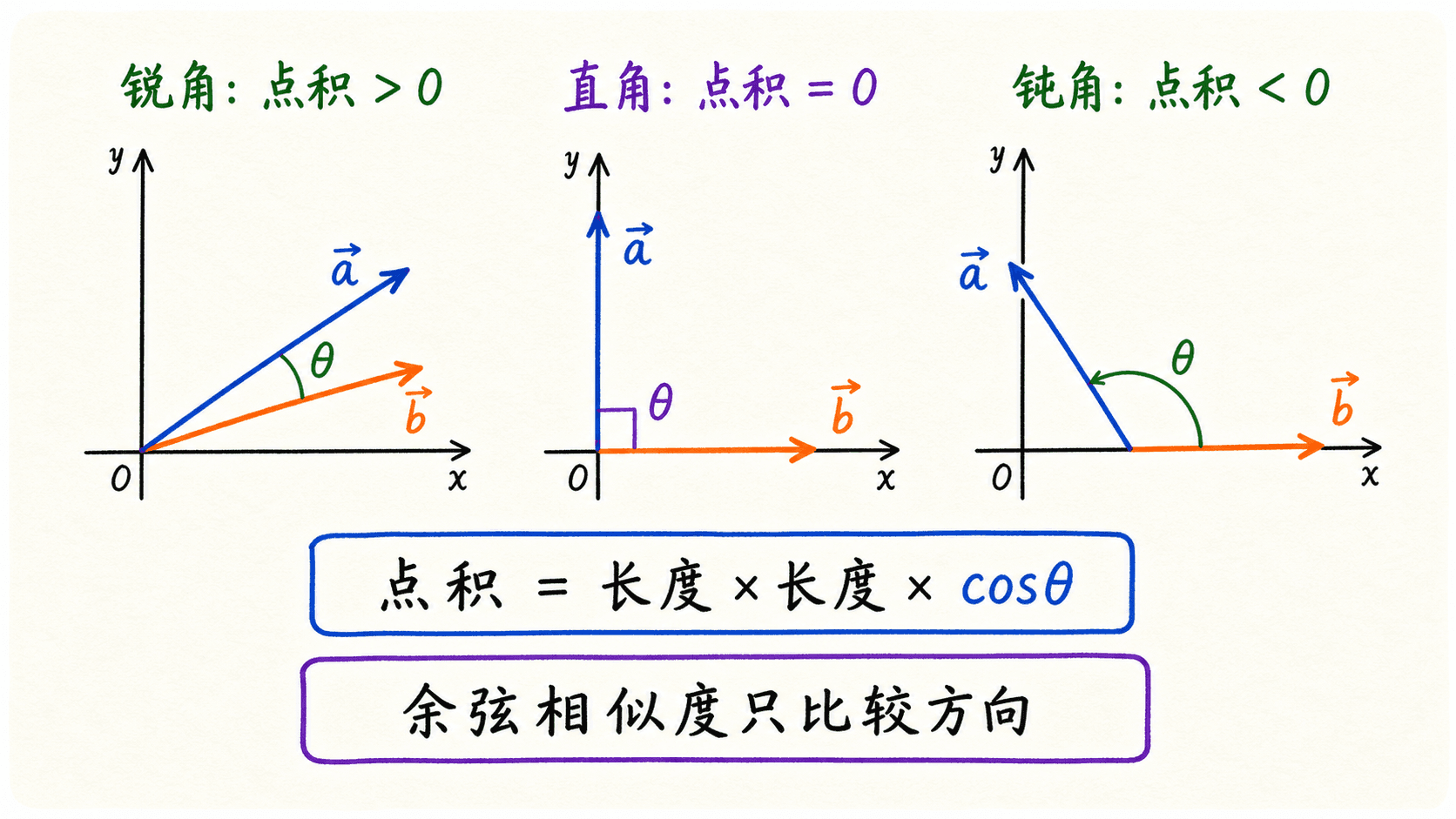
点积的符号由两向量夹角决定;余弦相似度通过归一化长度,只比较方向。
2
关于两个非零同维向量 x 和 z,下列说法哪些正确?
矩阵乘法先匹配中间维度
矩阵乘法最容易学成一套机械步骤。其实只要同时抓住形状和含义,规则会简单很多。
设 ,,那么:
左矩阵的列数必须等于右矩阵的行数。结果保留外侧两个维度,可以把它记成:
这个规则能回答“能不能乘”和“结果多大”,但还没有回答“结果里的数从哪里来”。 的第 行第 列,是 的第 行与 的第 列的点积:
矩阵乘向量:一次算完一批加权和
设某个线性模型有 3 个参数,数据矩阵包含 3 个样本:
的形状是 , 的形状是 ,所以预测结果是 :
每个预测值都是对应样本那一行与参数向量的点积。把样本堆成矩阵之后,一次矩阵乘法就代替了逐样本计算。
矩阵乘矩阵:同时处理多个输出
如果每个样本有 个输入特征,模型要输出 个数,可以令:
那么:
的每一列可以理解为一个输出对应的参数向量, 就是把 组预测并排算完。神经网络中的全连接层,本质上也是这件事,再加上偏置和非线性函数。
一个格子是怎样算出来的
计算下面两个矩阵的乘积:
先看形状。 是 , 是 ,中间维度都是 3,因此乘法有定义,结果是 。
A * B 与 A @ B 在 NumPy 中含义不同。前者是逐元素乘法,通常要求形状相同或可广播;后者才是矩阵乘法。两种写法有时都不报错,却会给出完全不同的结果。
矩阵乘法满足结合律与分配律,但通常不满足交换律:
不交换的原因不只是数值可能不同。有时 有定义, 根本没有定义。计算长矩阵链时,结合顺序也会影响中间矩阵的大小和运算量。
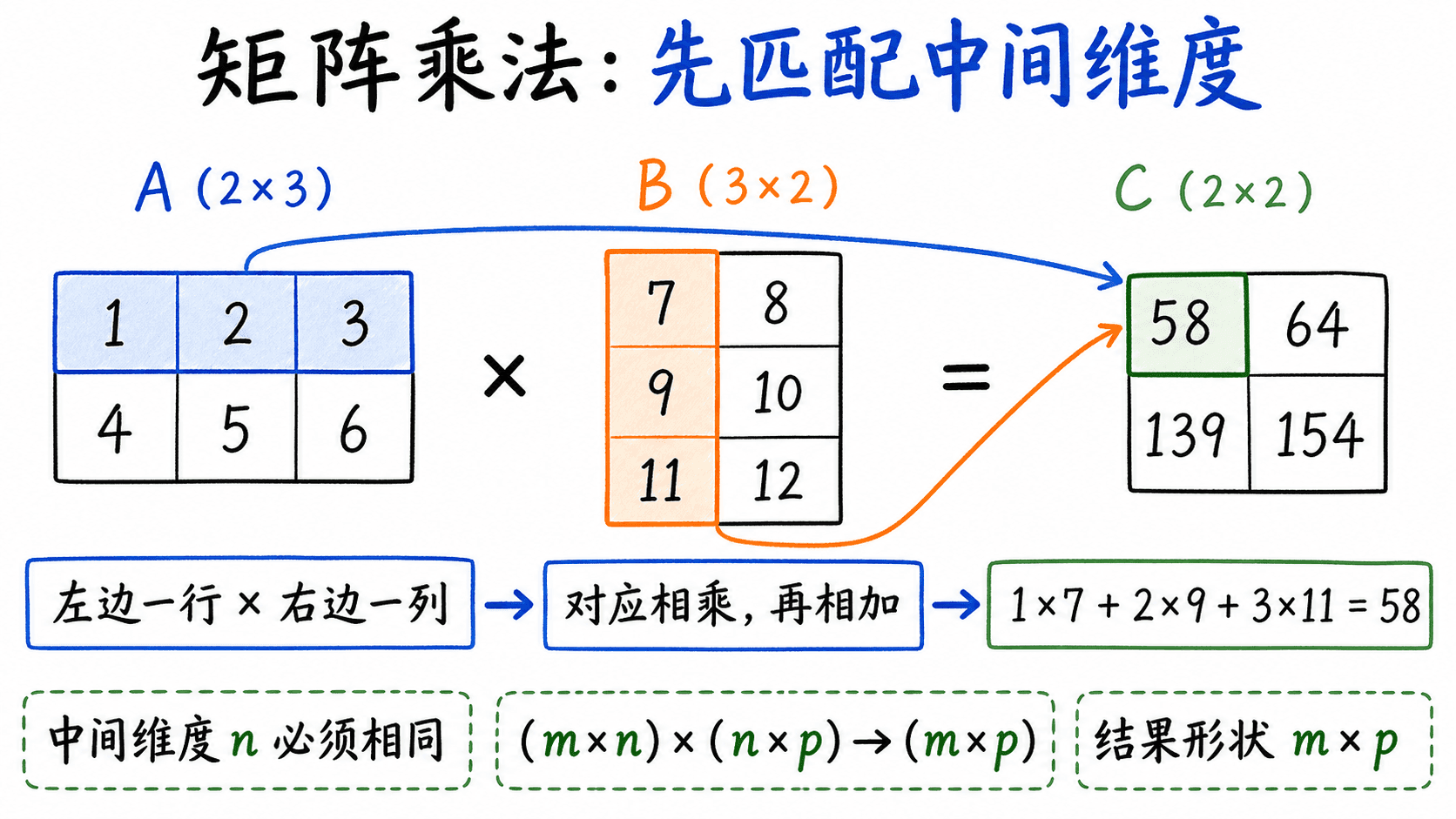
矩阵乘法需先匹配中间维度:左边一行与右边一列对应相乘再相加,结果形状为 m×p。
下面的交互会逐格高亮“左边一行 × 右边一列”,并同步显示形状流向。
3
若 A 的形状是 m×n,B 的形状是 n×p,那么 AB 的形状是 ____。
线性变换是矩阵真正做的事
把矩阵只理解成二维表格,会错过一个很有用的视角:矩阵还代表一个函数。若 ,它定义了从 到 的映射:
输入向量有 个分量,输出向量有 个分量。矩阵的列数决定它接收什么维度,行数决定它输出什么维度。
这个映射之所以叫线性变换,是因为它保留加法和数乘:
把 代入可知,纯线性变换一定把原点送到原点。
矩阵的每一列记录一个基向量的去向
二维空间的标准基向量是:
令:
那么 ,恰好是 的第一列;,恰好是第二列。任意向量 的输出,因此是两列的线性组合:
这也解释了为什么矩阵乘向量可以看成“用向量的分量,对矩阵各列做加权组合”。
变换的复合对应矩阵相乘
先做变换 ,再做变换 :
因此乘法顺序与操作顺序相反:表达式里右侧矩阵先作用。旋转、缩放、剪切和投影都可以这样组合。
加上偏置后是仿射变换
神经网络常写:
当 时,这不再是严格意义上的线性变换,因为原点会被送到 。更准确的名字是仿射变换。工程文档经常仍把它简称为“线性层”,读代码时要知道这层名字与数学定义之间的差别。
若一批样本按行存放,单样本公式 常会改写成:
这里 ,,所以 。在 NumPy 中,形状为 的 可以通过广播加到每一行。
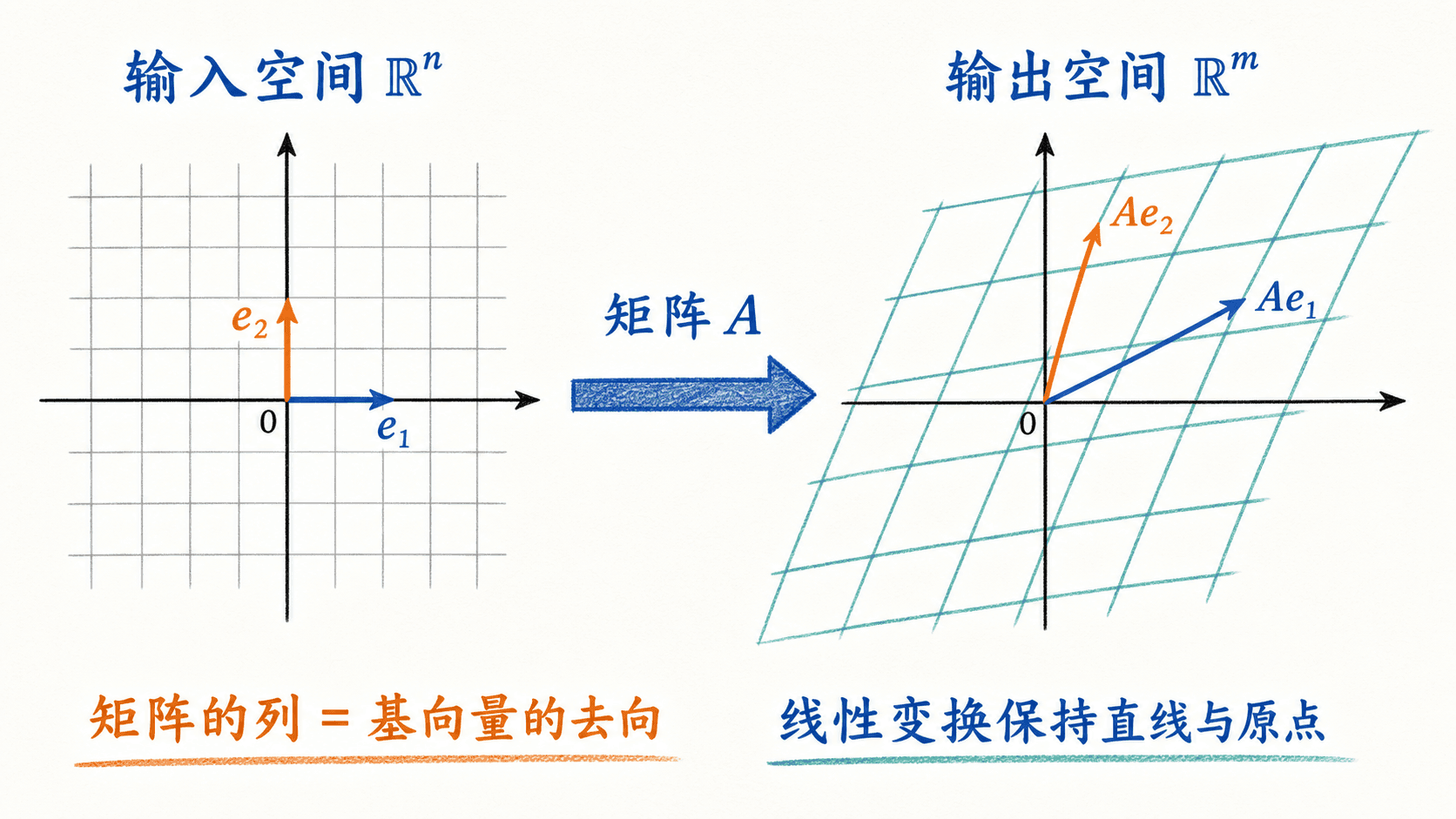
矩阵的列记录标准基向量在线性变换后的去向;变换后的网格仍由直线构成,且原点保持不变。
4
只要 W 是矩阵,映射 T(x)=Wx+b 就一定是线性变换。
转置、秩和逆描述信息能否被保留下来
矩阵转置把行列互换。若 ,则 ,并且:
例如:
常用性质包括:
最后一个公式必须反转顺序。可以用形状检查:如果 是 、 是 ,那么 是 ;只有 能得到同样形状。
为什么机器学习里经常出现
若 ,那么 。它的第 个元素是第 列特征与第 列特征的点积,因此会汇总特征列之间的关系。
一定是对称矩阵:
但“对称”不等于“可逆”。如果某一列是另一列的倍数,两列带来的方向重复, 仍然对称,却会失去满秩。
秩表示独立方向的数量
矩阵的秩可以理解为:它的列向量最多能提供多少个线性无关方向。对 :
若秩等于 ,称为满列秩;若秩等于 ,称为满行秩。机器学习数据中,重复特征、完全线性组合的特征,都会让设计矩阵降秩。
普通逆只属于方阵中的一部分
对方阵 ,如果存在 使:
那么 可逆。它需要同时满足“方阵”和“满秩”。从几何上看,可逆变换没有把某个非零方向压成零,因此输出仍然保留足够信息,可以唯一恢复输入。
例如:
解 时,纸面上可以写 。但在数值代码里,更好的表达是直接求解线性方程组:
python
import numpy as np
A = np.array([[2.0, 1.0],
[1.0, 1.0]])
b = np.array([5.0, 3.0])
x = np.linalg.solve(A, b)
print(x) # [2. 1.]
print(np.allclose(A @ x, b)) # Truesolve 直接利用矩阵分解求解,避免先构造完整逆矩阵。它要求系数矩阵是方阵且满秩;非方阵或最小二乘问题要换别的工具。
5
关于 XᵀX,下列哪项一定成立?
伪逆处理非方阵和不唯一的解
真实数据矩阵通常不是方阵。样本数往往大于特征数,有时特征数又大于样本数;特征之间还可能相关。此时普通逆不存在,但我们仍然希望回答“哪个参数最能解释这些数据”。这正是 Moore–Penrose 伪逆 的用途。
如果 恰好是可逆方阵,那么:
一般情况下,伪逆通过四个条件刻画:
这些条件保证伪逆与原矩阵的输入空间、输出空间保持一致的投影关系。
用奇异值分解理解伪逆
设矩阵的奇异值分解为:
和 负责旋转或换基, 沿若干独立方向缩放。构造伪逆时,把非零奇异值取倒数,再交换两侧方向:
如果某个奇异值是 0,说明对应方向已经被压扁,无法从输出中恢复。伪逆不会对 0 取倒数,而是保留为 0。数值计算中,极小奇异值也常按阈值视为 0,否则它的倒数会把噪声放得很大。
三种常见情形
NumPy 可以直接计算伪逆:
python
A = np.array([[1.0, 0.0],
[0.0, 1.0],
[1.0, 1.0]])
b = np.array([1.0, 2.0, 2.7])
x_from_pinv = np.linalg.pinv(A) @ b
x_from_lstsq = np.linalg.lstsq(A, b, rcond=None)[0]
print(np.allclose(x_from_pinv, x_from_lstsq)) 如果目的只是解最小二乘问题,优先使用 np.linalg.lstsq。它会直接返回解、残差、秩和奇异值等信息。只有确实需要把伪逆保存下来并反复作用于多个右端向量时,才更有理由显式计算 pinv(A)。
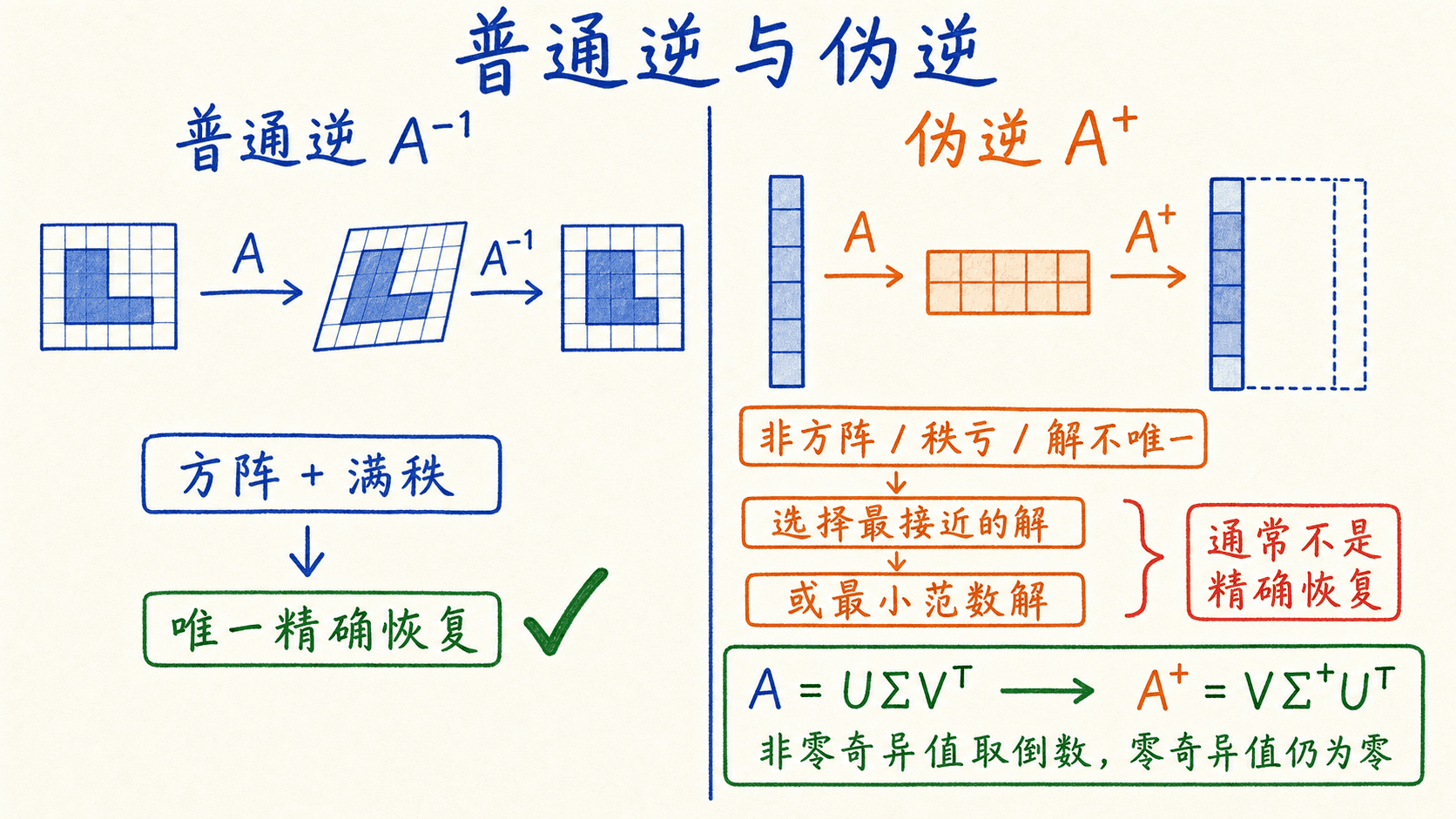
普通逆适用于满秩方阵;伪逆在非方阵、秩亏或解不唯一时给出最佳近似或最小范数解,通常不代表精确恢复。
6
关于 Moore–Penrose 伪逆,下列说法哪些正确?
投影把最小二乘变成一幅几何图
我们先从投影到一条直线开始。给定非零方向 和目标向量 ,希望在所有 中找到离 最近的向量。投影结果是:
投影后的残差 与 正交:
最小二乘只是把“一条线”推广到“矩阵各列张成的子空间”。给定 和 ,我们寻找:
位于 的列空间中。它是列空间里离 最近的向量,所以残差 必须与 的每一列正交:
把残差代入,就得到正规方程:
如果 满列秩,纸面上可写:
更一般地,可以直接写:
手算一条最小二乘直线
有三个点 、、,拟合 。设计矩阵和标签为:
先确认形状: 是 ,参数 是 ,预测 是 ,能与标签相减。
正规方程适合推导和建立几何直觉,不等于代码里应该先算 再求逆。后面会看到,这样做会放大条件数带来的误差;NumPy 中直接调用 np.linalg.lstsq(A, b, rcond=None) 通常更稳妥。
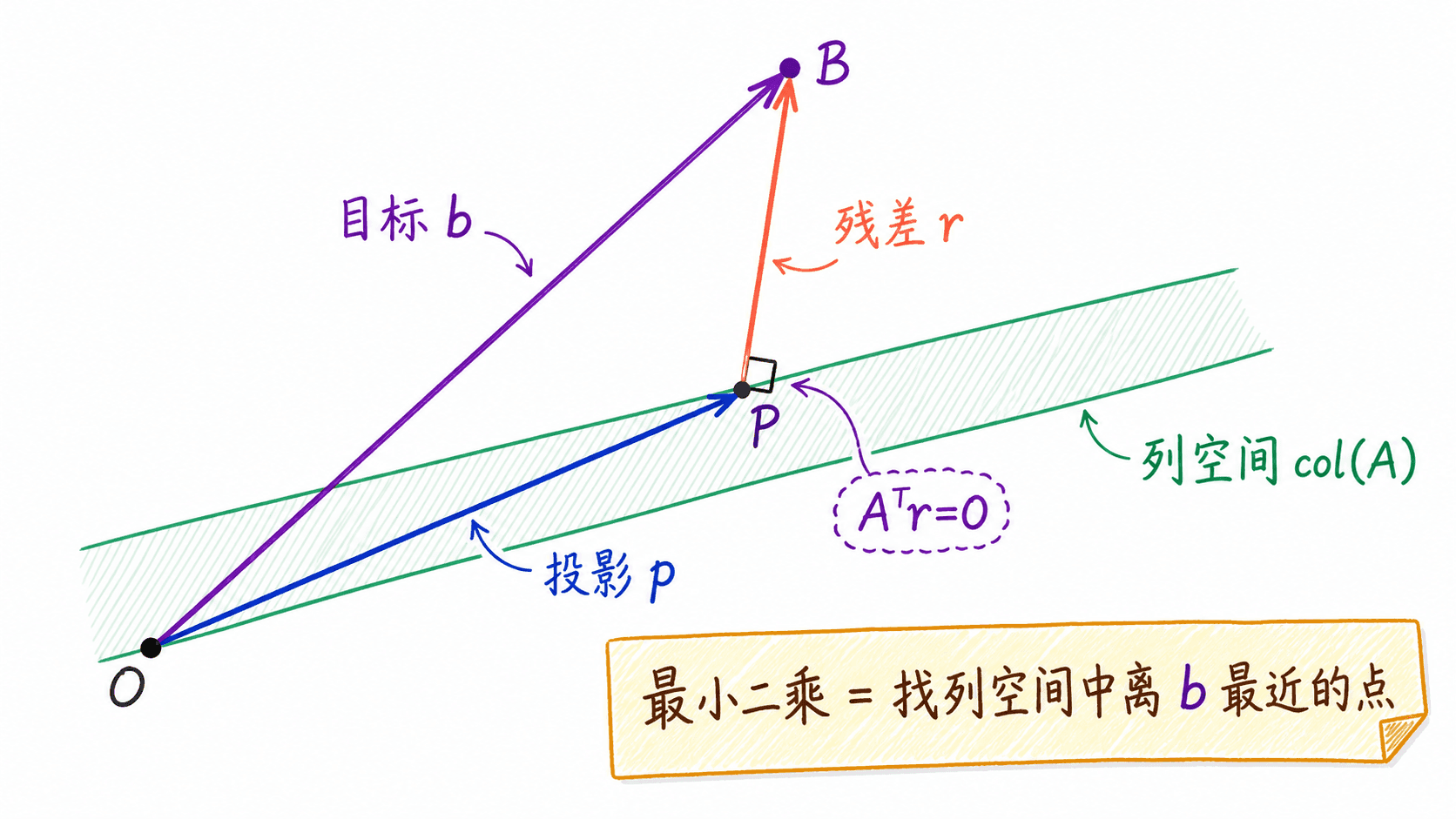
最小二乘把目标向量投影到矩阵 A 的列空间;投影 p 是离 b 最近的点,残差 r 与列空间正交。
下面的交互允许拖动目标向量,观察投影、残差和“残差垂直于列空间”如何同时变化。
7
把向量 b = [3, 1]ᵀ 投影到 a = [1, 1]ᵀ 张成的直线上。下列哪组投影 p 和残差 r 正确?
向量化把单样本公式提升到整批数据
所谓向量化,不是把循环简单藏起来,而是先找出一批数据共享的运算结构,再用数组操作一次表达出来。
单个样本的线性预测可以写成:
把 个样本按行堆成 后,整批预测变成:
均方误差的一半可以写成:
它的梯度为:
逐项检查形状,会发现公式本身已经完成一次校验:
代码可以直接跟随这个结构:
python
def gradient_step(X, y, theta, learning_rate):
"""完成一次向量化的线性回归梯度更新。"""
m, n = X.shape
assert y.shape == (m,)
assert theta.shape == (n,)
prediction = X @ theta
error = prediction - y
gradient = X.T @ error / m
return theta - learning_rate * gradient广播适合表达“每一行做同一件事”
例如,对每个特征减去各自均值:
python
feature_mean = X.mean(axis=0) # (n,)
X_centered = X - feature_mean # (m, n) - (n,) -> (m, n)NumPy 从末尾维度开始比较形状。两个维度相等,或其中一个为 1,才可以广播。这里 (n,) 会沿样本轴复用,相当于每一行都减去同一个特征均值向量。
广播通常不会真的复制小数组,因此方便而高效。但它也可能掩盖错误:若你本来想按列缩放,却把数组整理成 (m, 1),代码仍可能运行,只是做成了“每一行使用不同系数”。所以广播前仍然要说清楚每条轴的含义。
向量化不等于永远创建最大中间数组
矩阵运算通常能调用底层优化库,减少 Python 循环开销。但如果一次性构造巨大的两两距离矩阵,内存反而可能成为瓶颈。实际项目会在“表达清楚”“计算高效”和“中间结果大小”之间取平衡,必要时按批次向量化。
8
X 的形状是 (64, 20),theta 的形状是 (20,)。执行 X @ theta 后结果形状是什么?
NumPy 代码要忠实表达数学意图
掌握公式后,真正容易出错的是“同一个符号在 NumPy 里到底是哪种数组”。下面这组习惯能减少大多数维度问题。
先固定数组类型和精度
python
import numpy as np
X = np.asarray(X, dtype=np.float64)
y = np.asarray(y, dtype=np.float64)
print(X.ndim, X.shape)
print(y.ndim, y.shape)线性代数计算优先使用普通 ndarray。不要新写依赖 np.matrix 的代码;它会让 * 的语义与 ndarray 不同,混用时很难判断到底做了逐元素乘法还是矩阵乘法。
一维数组转置后还是一维
python
x = np.array([1.0, 2.0, 3.0])
print(x.shape) # (3,)
print(x.T.shape) # (3,),没有变化
print(x[:, None].shape) # (3, 1)
print(x[None, :].shape) # (1, 3)只有二维数组才有可交换的两条轴。若公式真的依赖列向量与行向量的区别,就先把形状写成 (n, 1) 或 (1, n)。
区分四类常见乘法
python
x = np.array([1.0, 2.0, 3.0])
z = np.array([4.0, 5.0, 6.0])
A = np.arange(6.0).reshape(2, 3)
elementwise = x * z # (3,),逐元素乘法
inner = x @ z # 标量,内积
outer = np.outer(x, z) # (3, 3),外积
让形状断言靠近运算
python
def linear_predict(X, W, b):
X = np.asarray(X, dtype=float)
W = np.asarray(W, dtype=float)
b = np.asarray(b, dtype=float)
assert X.ndim == 2
assert W.ndim == 2
assert b.ndim == 1
assert X.shape[1] == W.shape[
这里 X @ W 的形状是 (m, k),b 的形状是 (k,),广播方向清晰:每个样本加同一个输出偏置。
根据问题选择求解函数
从报错反推是哪条轴不对
最隐蔽的一种错误是:预测形状 (m,),标签形状 (m,1)。两者相减不会得到 (m,),而会广播成 (m,m)。代码可能继续运行,损失值却已经不是你想算的东西。
9
在 NumPy 的 ndarray 中,表示矩阵乘法最清楚的运算符是 ____。
数值稳定性决定公式能不能可靠落地
纸面推导默认数字可以无限精确地保存,计算机使用的浮点数却只有有限精度。矩阵接近奇异时,输入中很小的误差可能在求解中被大幅放大。
条件数衡量问题对扰动有多敏感
在二范数下,满秩矩阵的条件数可以由最大、最小奇异值之比表示:
条件数接近 1,说明不同方向的缩放比较均衡;条件数很大,说明至少有一个方向被压得很扁。此时数据中的测量误差和浮点舍入误差都会更明显地影响解。
python
singular_values = np.linalg.svd(X, compute_uv=False)
condition_number = np.linalg.cond(X)
rank = np.linalg.matrix_rank(X)
print(singular_values)
print(condition_number)
print(rank, X.shape[1])matrix_rank 也依赖数值阈值。它不是在宣判一个永恒的数学事实,而是在当前精度和容差下判断哪些奇异值可以视为 0。
为什么不建议手动构造正规方程
若 满列秩,在二范数条件数下有:
也就是说,先构造 会把条件问题平方放大。再显式计算逆矩阵,还会引入额外运算与误差。正规方程依旧适合解释“残差为什么正交”,但数值实现通常优先 QR、SVD 或封装了这些分解的最小二乘接口。
特征尺度和共线性是常见来源
一个特征以米计,另一个以微米计,数值尺度可能相差几个数量级。即使它们在业务上都合理,计算也会变得更难。训练前常对特征做中心化和缩放:
另一类问题是共线性。例如“厘米身高”和“米制身高”同时进入数据,二者几乎携带相同方向。模型可能仍能给出稳定预测,但单个系数会剧烈变化,很难解释。
正则化可以缓解部分问题。岭回归把正规方程改为:
会抑制参数沿不稳定方向无限放大。它改变了优化目标,因此不是单纯的数值技巧;选择它时要知道自己加入了对参数大小的偏好。

病态矩阵会放大数据扰动;构造 AᵀA 还会将二范数条件数平方。特征缩放有帮助,但不能修复秩亏。
一套可复用的排错顺序
先打印每个核心数组的 shape、ndim 和 dtype,并检查是否出现 NaN 或无穷值。很多所谓“数学错误”其实只是标签多了一条轴。
在纸上为公式逐段标形状。不要只看最终结果能否广播,要确认每条轴在业务上分别代表样本、特征还是输出。
再检查秩、奇异值和条件数。若特征列重复或近似线性相关,先处理数据问题,再决定是否需要正则化。
按问题选算法:方阵满秩用 solve,最小二乘用 ,秩亏且需要广义逆时用 。不要把 当成通用模板。
下面是一段紧凑但信息完整的最小二乘实现:
python
def fit_least_squares(X, y):
X = np.asarray(X, dtype=np.float64)
y = np.asarray(y, dtype=np.float64)
if X.ndim != 2:
raise ValueError("X 必须是二维数据矩阵")
if y.ndim != 1 or y.shape[0] != X.shape[0]:
raise ValueError("y 必须是一维数组,且长度等于样本数")
这段代码没有把公式写得更花哨,只是把“形状正确、数据有限、算法匹配、结果可检查”四件事放在了同一个流程里。以后看到更复杂的模型,也可以沿用同一思路:先给每个张量标形状,再追踪变换,最后检查数值尺度和残差。
10
当最小二乘设计矩阵条件数很大时,下列做法哪些更合理?