多元线性回归:从一条直线走向可用的预测模型
如果只用一个特征预测房价,我们可以画出一条直线:横轴是面积,纵轴是价格。可现实里的价格不会只由面积决定。地段、房龄、楼层、交通条件都可能影响结果。把这些信息一起放进模型,就是多元线性回归最直接的用途。
它的名字容易让人误会。“多元”并不代表输出也有很多个,而是说我们用多个输入特征预测一个连续结果;“线性”也不要求数据只能排成直线,它真正限制的是参数以线性方式进入模型。只要参数仍然是“系数乘特征再相加”,特征本身可以是平方项、对数或两个变量的乘积。
这一章会从一元模型出发,逐步走到设计矩阵、梯度下降、特征缩放、共线性、交互项、正规方程、残差诊断和完整的 Python 流程。读完后,你应该不只会写出公式,还能判断一个回归结果是否可信、代码是否泄漏了测试集信息,以及什么时候不该直接解释某个系数。
本章默认有 个样本、 个原始特征。样本编号写在上标,例如 表示第 个样本的第 个特征;这里的上标是索引,不是乘方。
多一个特征,模型究竟多了什么
先从熟悉的一元模型开始。只有房屋面积 时,预测房价可以写成:
现在再加入距地铁站的距离 、房龄 和楼层 ,模型自然扩展为:
是截距,其他参数分别控制一个特征对预测值的贡献。若房价以万元计、面积以平方米计,并且拟合结果是 ,那么在这个模型里,面积多一平方米对应的预测价格平均增加 万元——但要加上一句很重要的限定:其余已进入模型的特征保持不变。
这句限定正是多元回归与一元回归解释上的差别。假如大房子通常也更新、离市中心更远,只看面积与房价的关系,会把房龄和地段的影响混进面积系数。多元回归试图在给定其他变量的条件下,分离出面积与结果之间的线性关联。
系数是条件关联,不自动等于因果作用
把其他变量放进模型,并不意味着我们已经完成了一次严格的因果实验。遗漏变量、选择偏差、测量误差和反向因果都可能影响系数。比如模型发现“装修预算越高,成交价越高”,不等于随意多花一万元装修就一定能带来同样幅度的涨价;高预算可能同时代表更好的地段或更高的房屋档次。
所以,预测任务和解释任务要分开想:
“线性”指的是对参数线性
下面这个模型仍然是线性回归:
虽然预测曲线对 而言是弯的,但 、、 都只以一次幂出现,并且没有彼此相乘。我们可以把 与 看成两个输入特征,再用同一套最小二乘方法估计参数。
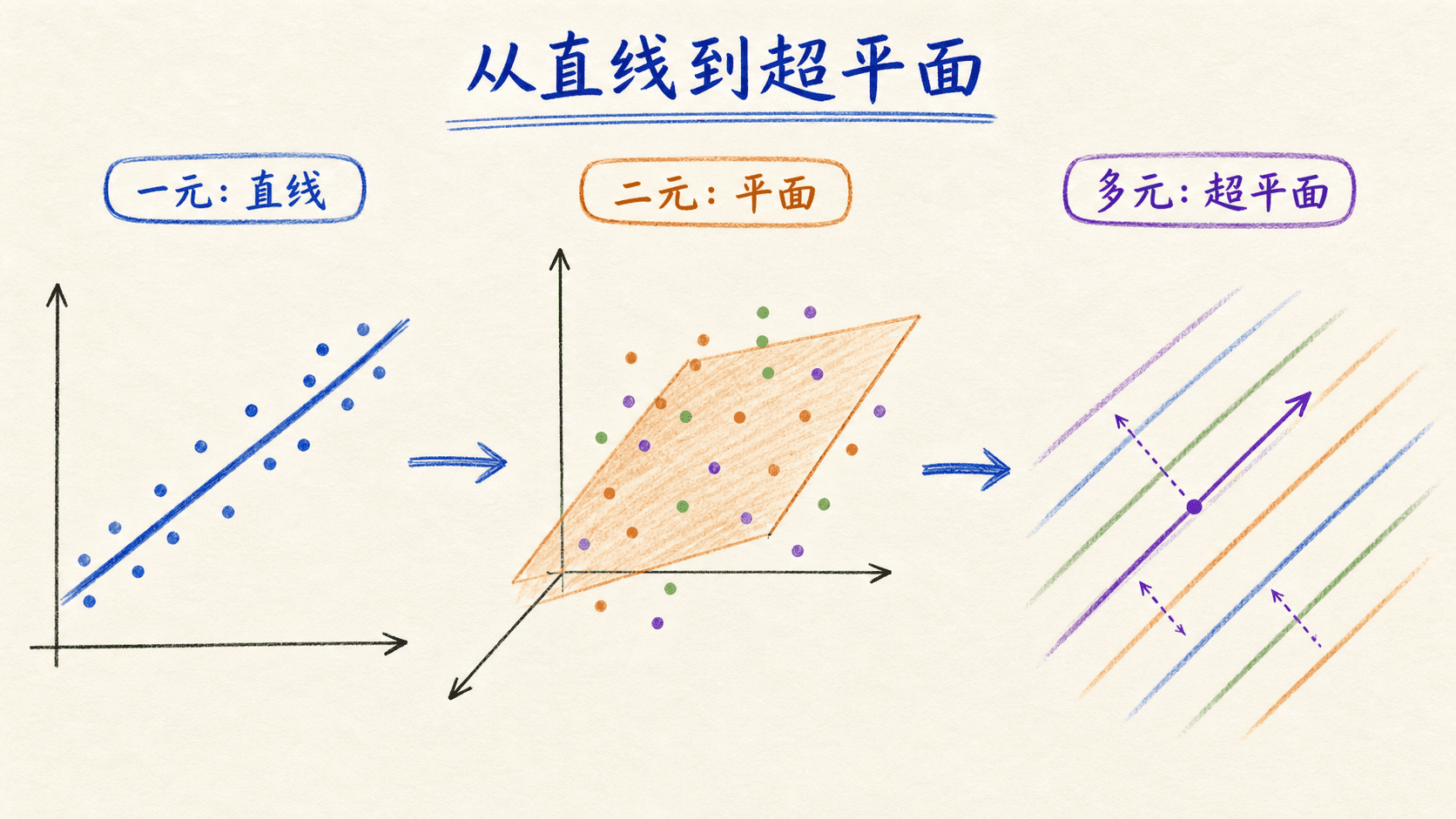
“多元线性回归”通常指多个预测变量对应一个连续目标。若同时预测多个目标,更准确的说法是多输出或多响应回归。两者不要只凭“多元”二字混在一起。
1
在模型 房价 = θ₀ + θ₁×面积 + θ₂×房龄 中,θ₁ 最准确的解释是什么?
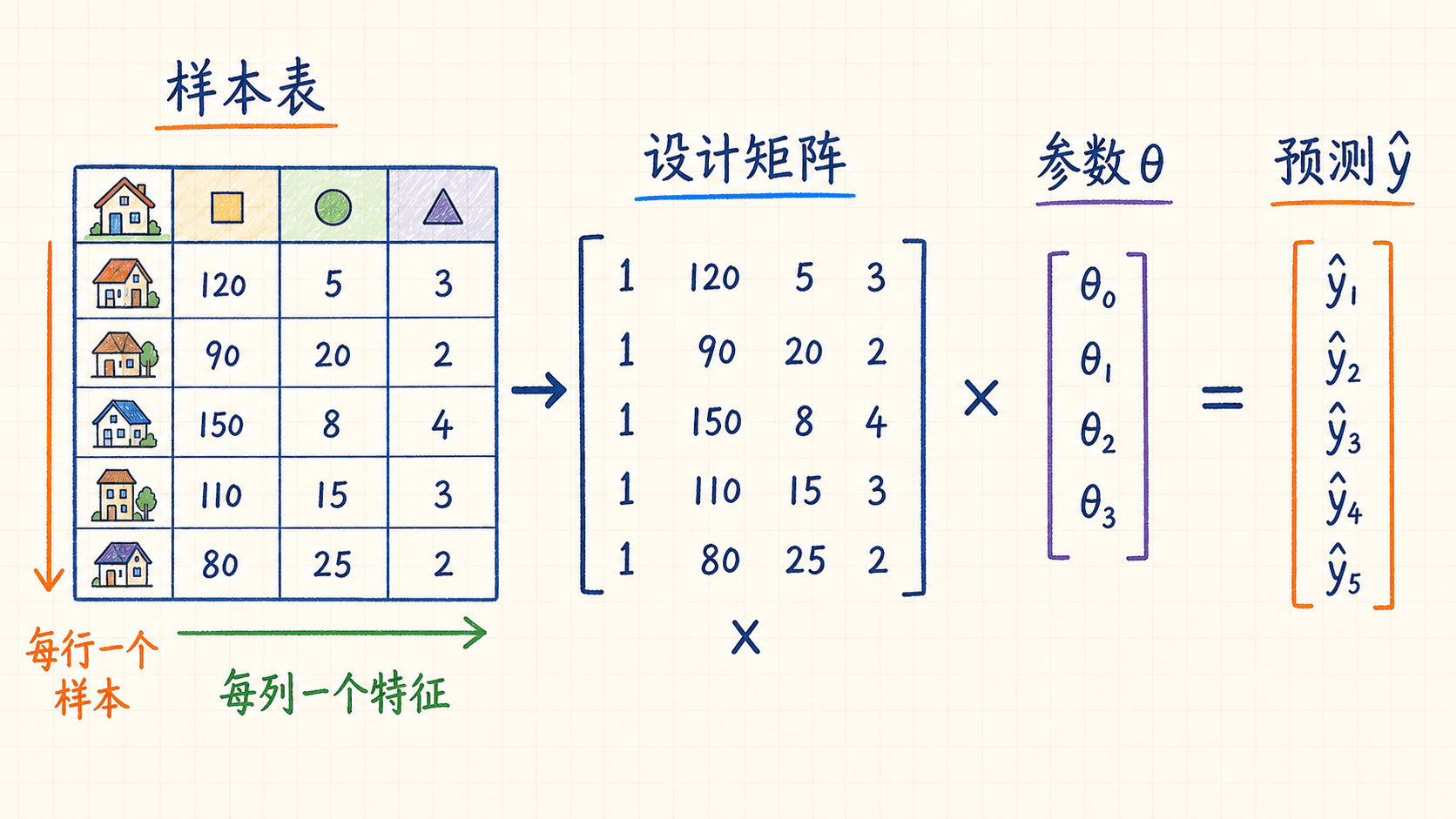
设计矩阵把所有样本放进同一个公式
逐个样本写方程当然可以,但样本一多就很难读。矩阵表达的价值,是让“对一条样本做预测”和“对整批数据做预测”用同一个运算完成。
从单个样本到向量内积
我们先人为增加一个恒等于 的特征 ,把截距并入参数向量:
单个样本的预测就是两个向量的内积:
这里两个向量都有 个元素。第一项 负责截距,后面的项分别对应原始特征。
每行一个样本,每列一个特征
把 个样本横着排成 行,就得到设计矩阵 :
它的形状是 。目标值组成列向量:
整批样本的预测可以一次写完:
维度也能帮我们检查公式: 的矩阵乘 的参数向量,结果是 ,恰好对应 个预测值。
残差与目标函数
第 个样本的残差定义为真实值减预测值:
普通最小二乘选择一组参数,让残差平方和尽可能小。为了让求导更整齐,我们常把损失写成:
矩阵形式是:
前面的 不会改变最小值位置,只是抵消平方项求导时出现的 ;除以 则让不同样本量下的损失更容易比较。若代码里的均方误差没有 ,它与这里的参数最优点仍然相同。
先看输入。若有 200 个样本和 4 个原始特征,加上截距列后, 的形状是 。
参数向量必须与列数匹配,因此 的形状是 。
2
有 80 个样本、6 个原始特征,并在设计矩阵中显式加入截距列。设计矩阵 X 一共有 ____ 列。
梯度下降怎样在多维参数空间里前进
最小二乘损失对参数是一个凸二次函数。只要计算和数据没有异常,批量梯度下降不会遇到“坏的局部最小值”;真正麻烦的通常是走得太慢、步长太大,或者特征尺度让参数空间变得非常狭长。
每个参数都在为同一批误差负责
对第 个参数求偏导,可得:
这条式子可以这样理解:先看每个样本预测高了还是低了,再用该样本第 个特征的大小加权,最后对所有样本取平均。若某个方向上的加权误差持续为正,参数就该往反方向移动。
把全部参数合在一起,梯度为:
一次向量化更新是:
是学习率。等号右边要使用同一轮的旧参数整体计算,不能先更新 ,再拿更新后的 去算 。
一个可复查的 NumPy 实现
python
import numpy as np
def mse_half(X, y, theta):
error = X @ theta - y
return (error @ error) / (2 * len(y))
def batch_gradient_descent(X, y, alpha=0.05, max_iter=10_000, tol=1e-10):
"""X 已包含截距列;返回参数与损失历史。"""
m, p = X.shape
theta
这个版本用参数改变量作为停止条件。实际项目还可以同时监控梯度范数、验证集误差和最大迭代次数,避免只凭训练损失的微小变化就过早下结论。
怎么从损失曲线判断学习率
- 损失平稳下降,但很久都没有接近平坦区:学习率可能太小,也可能特征尺度很差。
- 损失上下震荡甚至越来越大:学习率通常太大,更新反复越过谷底。
- 一开始下降,随后出现
nan:检查学习率、异常值、溢出以及输入中是否已有缺失值。 - 训练损失持续下降、验证误差却反弹:这不是“没有收敛”,而更像模型开始过拟合。
向量化不是把数学换成一种更花哨的写法。它让维度更清楚,也把大量 Python 循环交给底层数值库处理。先写清 和 的形状,很多实现错误会在运行前就暴露出来。
3
关于批量梯度下降,下列哪些说法正确?
特征缩放不是装饰,而是在改造优化地形
假设房屋面积大约在 到 之间,卧室数大约在 到 之间。两个特征数值尺度差很多时,同一个学习率要同时照顾两个方向,损失函数的等高线往往像一条狭长山谷。梯度方向虽然指向最陡下降处,却不一定直接指向谷底,于是更新路径会左右折返。
标准化把第 个特征变为:
其中 和 分别是训练集上第 个特征的均值和标准差。变换后,训练数据该列的均值接近 、方差接近 。
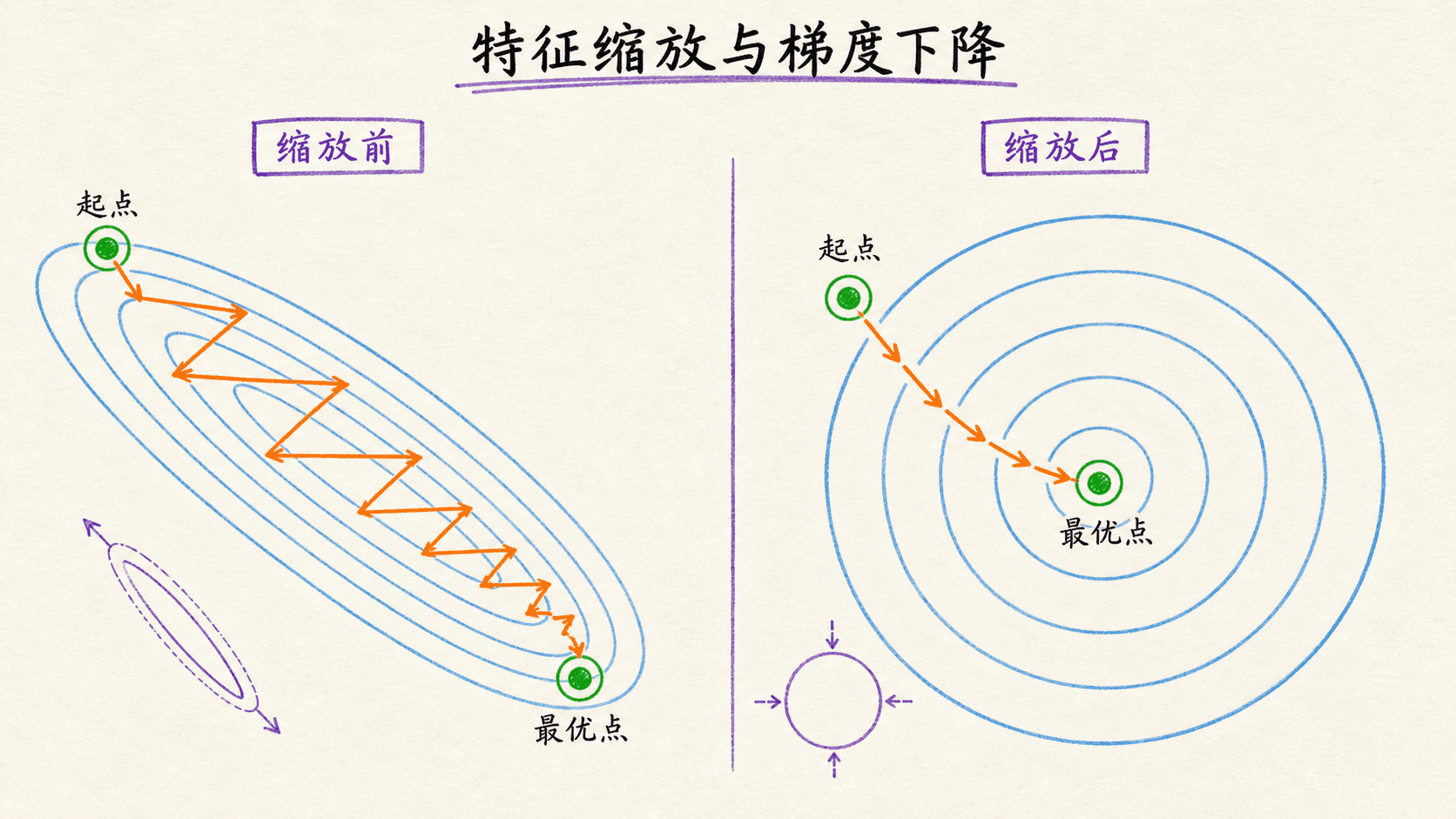
标准化不会把数据“变成正态分布”
减均值、除标准差只改变中心和尺度,不会改变分布的基本形状。一个明显右偏的收入变量标准化后仍然右偏;带有两个峰的变量也不会凭空变成钟形曲线。标准化后的“标准”指均值和方差,不是保证服从标准正态分布。
先拆分,再学习缩放参数
正确顺序是:
先把原始数据拆成训练集、验证集和测试集,或先保留测试集,再在训练集内部做交叉验证。
只用训练集计算每列的 与 。
如果先在全体数据上算均值和标准差,测试集的分布信息就提前进入训练流程。它看起来只是两个统计量,仍然属于数据泄漏。
还要处理三个边角问题
- 常数列:若某列标准差为 ,它没有区分样本的能力。不要手动除以 ;应删除、单独处理,或交给能识别常数列的预处理器。
- 异常值:均值和标准差对极端值敏感。先核对数据错误,再根据业务考虑稳健缩放、变换或合适的损失函数,不要看到极端点就机械删除。
- 截距列:手写设计矩阵时,恒为 的截距列不需要标准化。使用
LinearRegression(fit_intercept=True)时也不要再手动重复添加它。
对于普通最小二乘的稳定直接求解器,缩放不是得到数学解的必要条件;但它仍能改善条件数和系数比较。对于梯度下降、岭回归等对尺度敏感的方法,缩放通常更直接地影响优化速度与惩罚的公平性。
4
可以先用完整数据集计算标准化所需的均值和标准差,再拆分训练集与测试集,因为标准化并没有使用目标值 y。
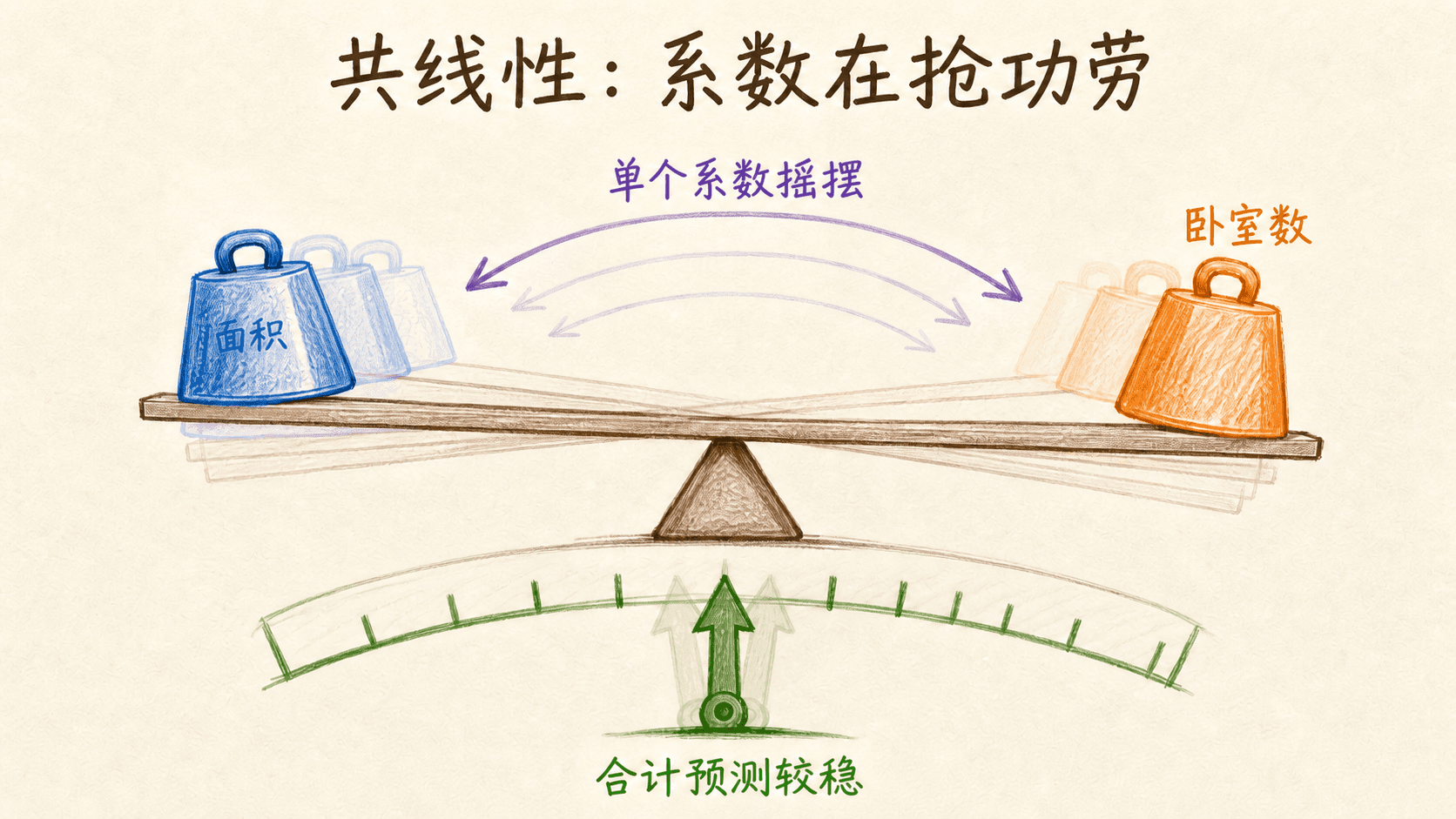
共线性会让系数看起来像在互相抢功劳
房屋面积用平方米记录一列,又换算成平方英尺记录一列,这两列存在精确线性关系。更常见的是近似关系:总面积与卧室数通常高度相关,收入与消费额也可能一起上升。预测变量之间存在精确或近似线性组合,就是共线性。
精确共线与近似共线
若设计矩阵某一列能被其他列精确表示, 不满列秩,普通最小二乘可能有多组同样好的参数。模型可以把贡献从一列挪到另一列,而预测值不变。
近似共线更隐蔽。最优解可能仍然唯一,但数据中的一点小扰动就会让系数明显变化。你会看到这些信号:
- 单个系数绝对值很大,符号与常识相反,换一次抽样又翻转;
- 训练拟合和整体预测尚可,但某些系数的标准误很大;
- 加入或删除一个相关特征后,其他系数剧烈变化;
- 设计矩阵的最小奇异值很小,条件数很大。
为什么只看两两相关系数不够
即使任意两列的相关性都不夸张,某一列也可能由多列组合近似得到。例如 。因此,散点图矩阵和相关矩阵适合初筛,但不能覆盖所有共线结构。
方差膨胀因子(VIF)提供了另一个视角。把第 个特征当目标,用其余特征去回归,得到 ,则:
其余特征越能解释第 列, 越接近 ,VIF 越大。VIF 是诊断信号,不是自动删变量的开关;阈值应结合样本量、任务目标和领域知识判断。
处理方式取决于你要预测还是解释
- 先排查重复单位、总量与分量同时进入、虚拟变量全编码等设计错误。
- 若两个变量表达同一事实,可保留更可靠、成本更低或更易解释的一个。
- 若解释需要保留两者,增加覆盖更广的数据往往比在原数据上反复调参有效。
- 若主要目标是预测,可用交叉验证检查共线性是否真的伤害新数据表现。
- 岭回归通过惩罚大系数,让相关特征的解更稳定,但系数含义也随之改变。
岭回归的目标可以先写成:
通常不惩罚截距。 越大,系数被压得越强。它能缓和方差和共线性,却引入偏差,所以不能只看训练误差挑 ;后面应通过验证集或交叉验证选择。
5
下列哪些现象可能由严重共线性造成?
交互项和多项式让线性模型拥有弯曲能力
基础加法模型默认每个特征的作用彼此独立:面积增加一平方米带来的预测变化,不随地段或房龄改变。现实中这个假设经常太强。地铁距离对市中心住宅和郊区住宅的影响可能不同,广告曝光的效果也可能随折扣力度变化。
交互项描述“一个特征的作用取决于另一个”
考虑带交互项的模型:
固定 时, 每增加一个单位,预测值的变化为:
所以有交互项后, 不再是 在所有情况下的统一作用,它只对应 时的斜率。如果 不在 的合理范围内,可以先把连续变量中心化,让主效应更容易解释。
一般建议保留交互项涉及的低阶主效应。若只放 却删掉 和 ,模型就被迫假设:当任一变量为 时,另一个变量完全没有作用。除非领域理论明确支持,这种限制通常很难解释。
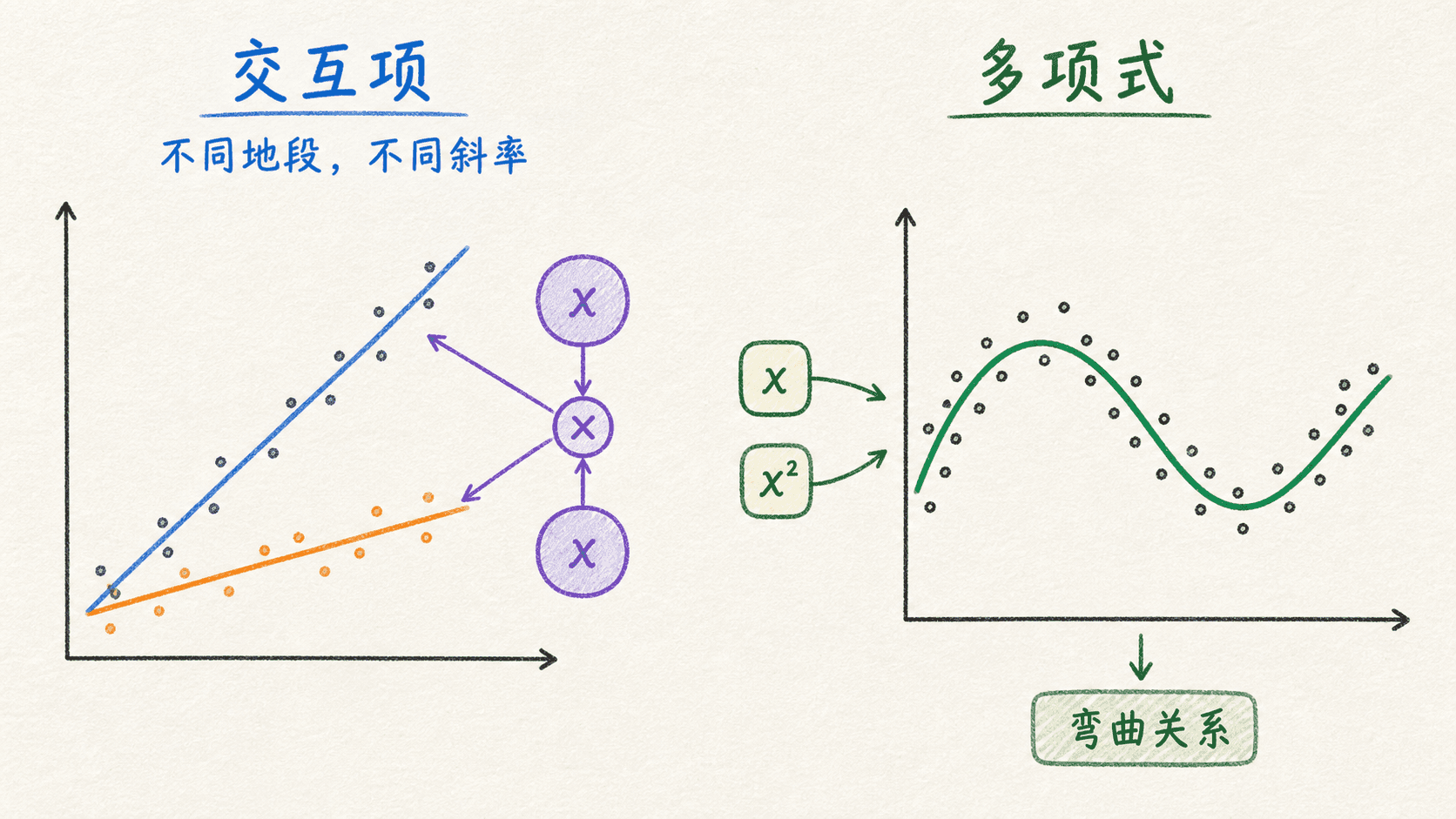
多项式特征仍然属于线性回归
两个原始特征做二阶扩展,可以得到:
模型对原始输入已经可以弯曲,但对这些展开后的特征系数仍是线性的。需要留意的是,特征数量会迅速增长。原始特征多、次数高时,模型更容易过拟合,也更容易出现共线性和数值问题。
类别变量也要变成设计矩阵的列
若“区域”有东区、西区、南区三个类别,并且模型含截距,通常只需要两个指示变量,把一个类别作为基准。若把三个指示列和截距列全部放入,就有:
这会造成精确共线性,也就是常说的虚拟变量陷阱。使用成熟的独热编码器时,可以指定删除一个基准类别,并把编码器放进训练管道,避免手工列名在训练和预测时错位。
python
from sklearn.preprocessing import PolynomialFeatures
poly = PolynomialFeatures(degree=2, include_bias=False)
X_poly = poly.fit_transform(X_train)
print(poly.get_feature_names_out())include_bias=False 是因为后续回归器通常会自己估计截距。特征生成器也必须只在训练流程中拟合;若其中包含数据驱动的筛选或统计量,更不能在拆分前先处理全体数据。
多项式次数不是越高越好。训练误差会随模型变复杂而不升高,但验证误差可能先降后升。次数、交互项和正则化强度都应通过训练集内部的验证流程选择。
6
模型 ŷ=θ₀+θ₁x₁+θ₂x₂+θ₃x₁x₂ 中,x₁ 对预测值的边际变化是什么?
闭式解的重点不在背逆矩阵公式
梯度下降通过反复更新接近最优点。线性最小二乘还有一条直接路线:令梯度为零。
整理后得到正规方程:
若 满列秩,教材里常写成:
这条公式有助于理解最小二乘,却不等于代码应该先算逆矩阵。显式计算 通常更慢、更占计算量,也会放大浮点误差;而且 的条件数大致是 条件数的平方,原本不太稳定的问题可能变得更糟。
几何上,它在寻找一个投影
预测向量 位于 的列空间中。最小二乘要找列空间里离 最近的点。最优解处,残差方向与 的每一列正交:
这正是正规方程的另一种写法。它说明最小二乘不是在让每个残差都为零,而是在让残差无法再沿任何已有特征方向被线性解释。
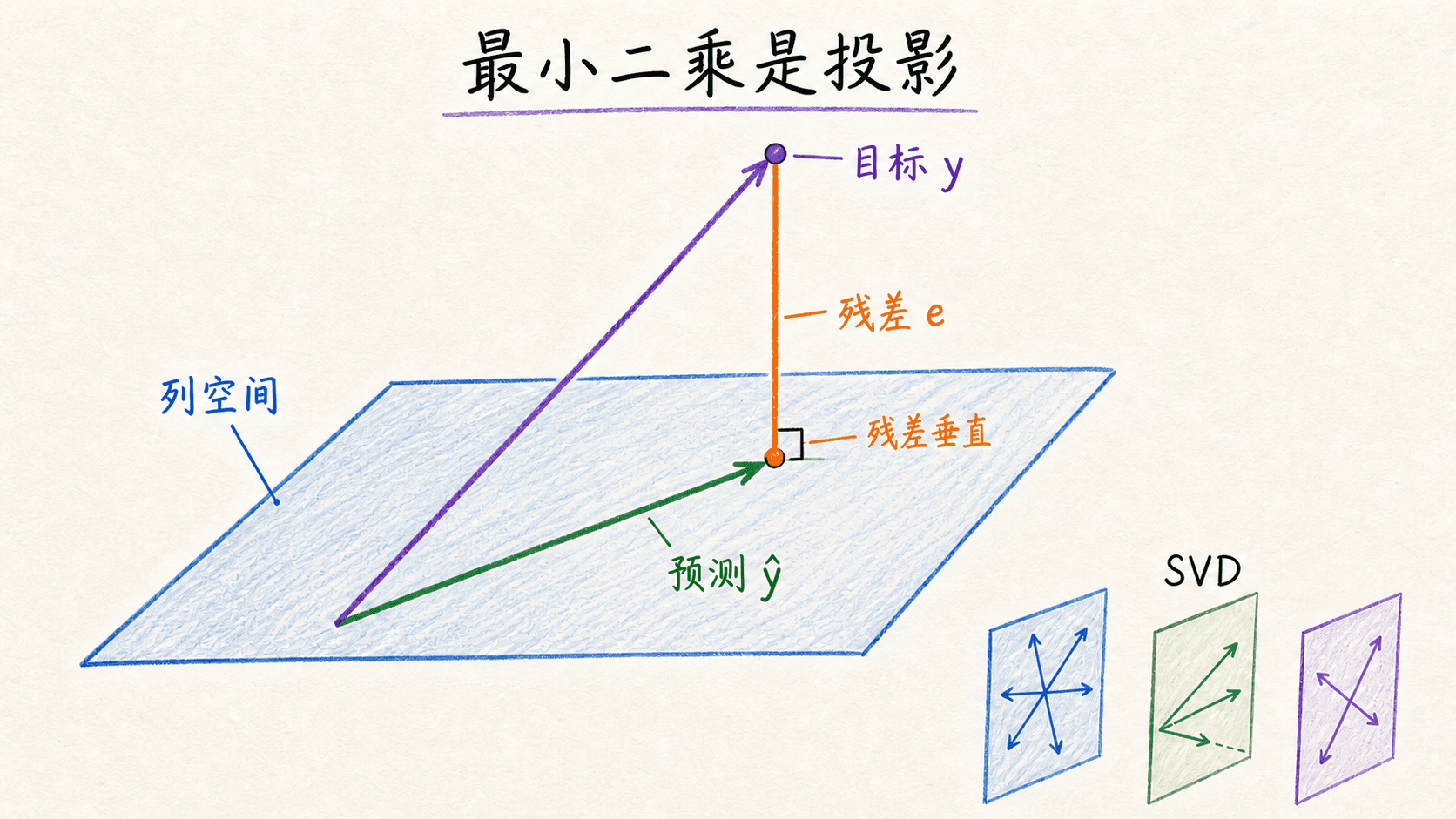
伪逆与最小范数解
当 不满列秩时,普通逆矩阵不存在,但最小二乘预测仍然可能有定义。Moore–Penrose 伪逆给出:
若有多组参数达到同样小的残差平方和,伪逆通常返回欧几里得范数最小的那一组。它解决了“如何得到一个数值解”,却不会自动恢复唯一、可靠的系数解释;共线性造成的信息不足依然存在。
实际代码优先交给稳定的最小二乘求解器
python
import numpy as np
# X_design 已包含截距列
theta, residual_sum, rank, singular_values = np.linalg.lstsq(
X_design,
y,
rcond=None,
)
print("参数:", theta)
print("矩阵秩:", rank)
print("奇异值:", singular_values)np.linalg.lstsq 可以处理超定、恰定和欠定系统,并报告秩与奇异值。若确实需要伪逆,可以写 np.linalg.pinv(X_design) @ y。相比之下,下面这种写法不应作为默认实现:
python
# 不推荐作为通用数值实现
theta = np.linalg.inv(X_design.T @ X_design) @ X_design.T @ y直接求解与梯度下降怎么选
小中型稠密问题,用成熟库的最小二乘实现通常省心;样本或特征巨大、数据按批到达时,迭代方法更容易扩展。真正的选择依据是数据形状、稀疏性、内存和后续是否加入正则化,而不是死记某个特征数阈值。
7
实现普通最小二乘时,显式计算 (XᵀX)⁻¹Xᵀy 是任何情况下都最稳定的做法。
评价模型要同时看新数据误差和残差形状
训练集上拟合得好,只说明模型记住或解释了已见数据的一部分。我们真正关心的是:面对来自同一任务的新样本,误差是否仍在可接受范围内;残差里是否还藏着系统结构。
三个常用回归指标回答不同问题
平均绝对误差(MAE)是误差绝对值的平均:
它与目标使用相同单位,容易翻译成业务语言。均方根误差(RMSE)为:
平方会让大误差获得更高权重,因此 RMSE 对极端误差更敏感。决定用哪个指标,要看大错是否真的比多个小错更昂贵。
决定系数 比较模型与“始终预测该数据均值”的基线:
在未见数据上, 可以小于 ,表示模型比均值基线还差。它没有目标变量的单位,也不应跨目标尺度和不同数据集随意横比。
训练集 会在加入特征后不下降,所以有人用调整 对参数数量做修正。但它仍属于样本内统计量,不能替代验证集或交叉验证。
残差图是一张模型体检表
令残差 。理想的“残差对拟合值”图通常是在 附近没有明显结构的水平点带。不同形状提示不同问题:
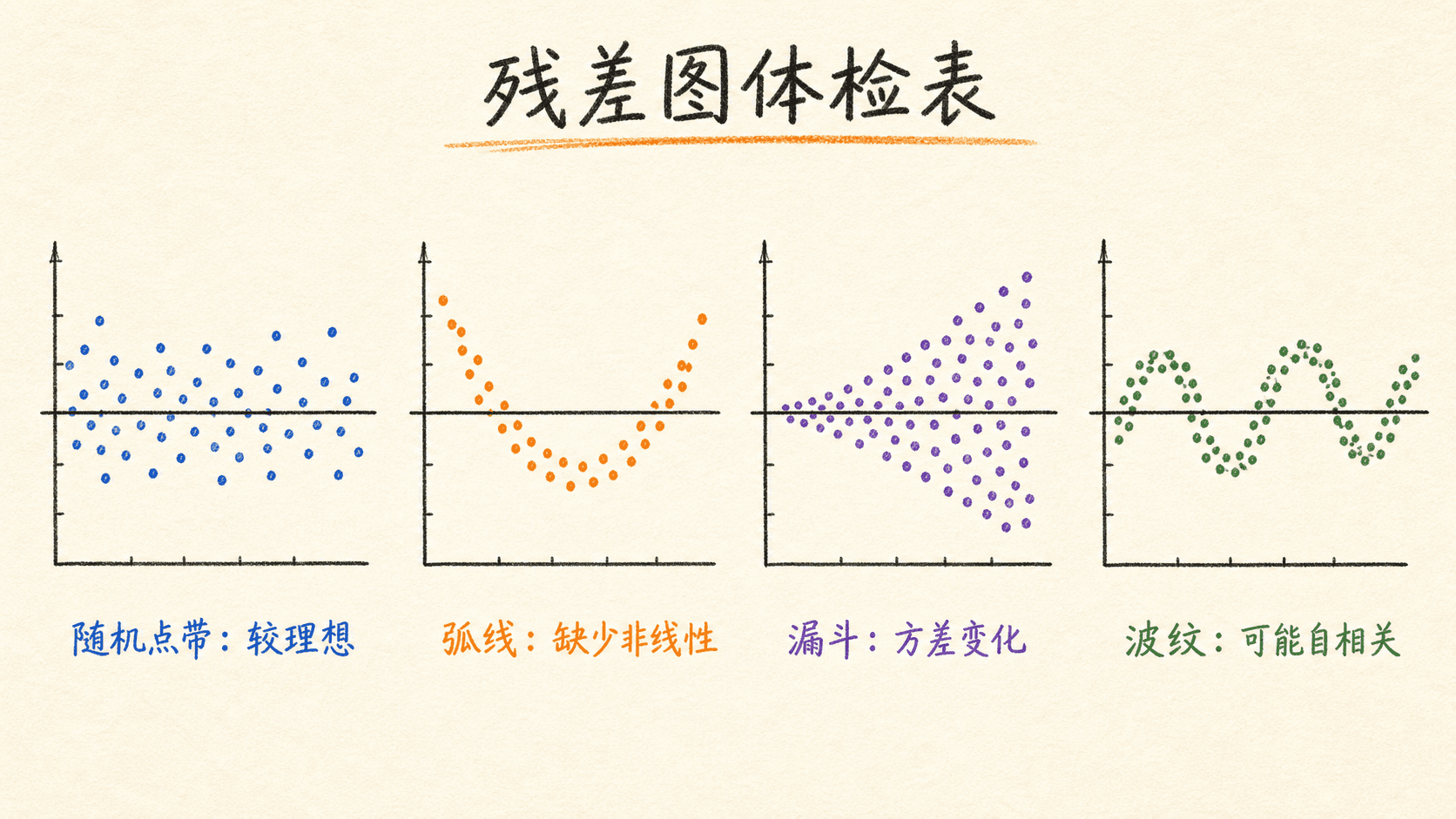
正态 Q-Q 图主要帮助检查残差分布是否与正态假设相容。普通最小二乘系数的计算本身不要求残差完美正态;正态性更多关系到小样本下的检验、置信区间和预测区间。样本很大时也不要只因 Q-Q 图尾部有一点偏离就推翻整个模型,应结合任务和误差后果判断。
不要看到一个影响点就直接删除。它可能是录入错误,也可能是模型最需要学会处理的真实少数情况。先核对数据,再分别报告保留与排除该点时结果是否改变,最后说明处理依据。
8
残差对拟合值图呈明显漏斗形时,哪些判断更合理?
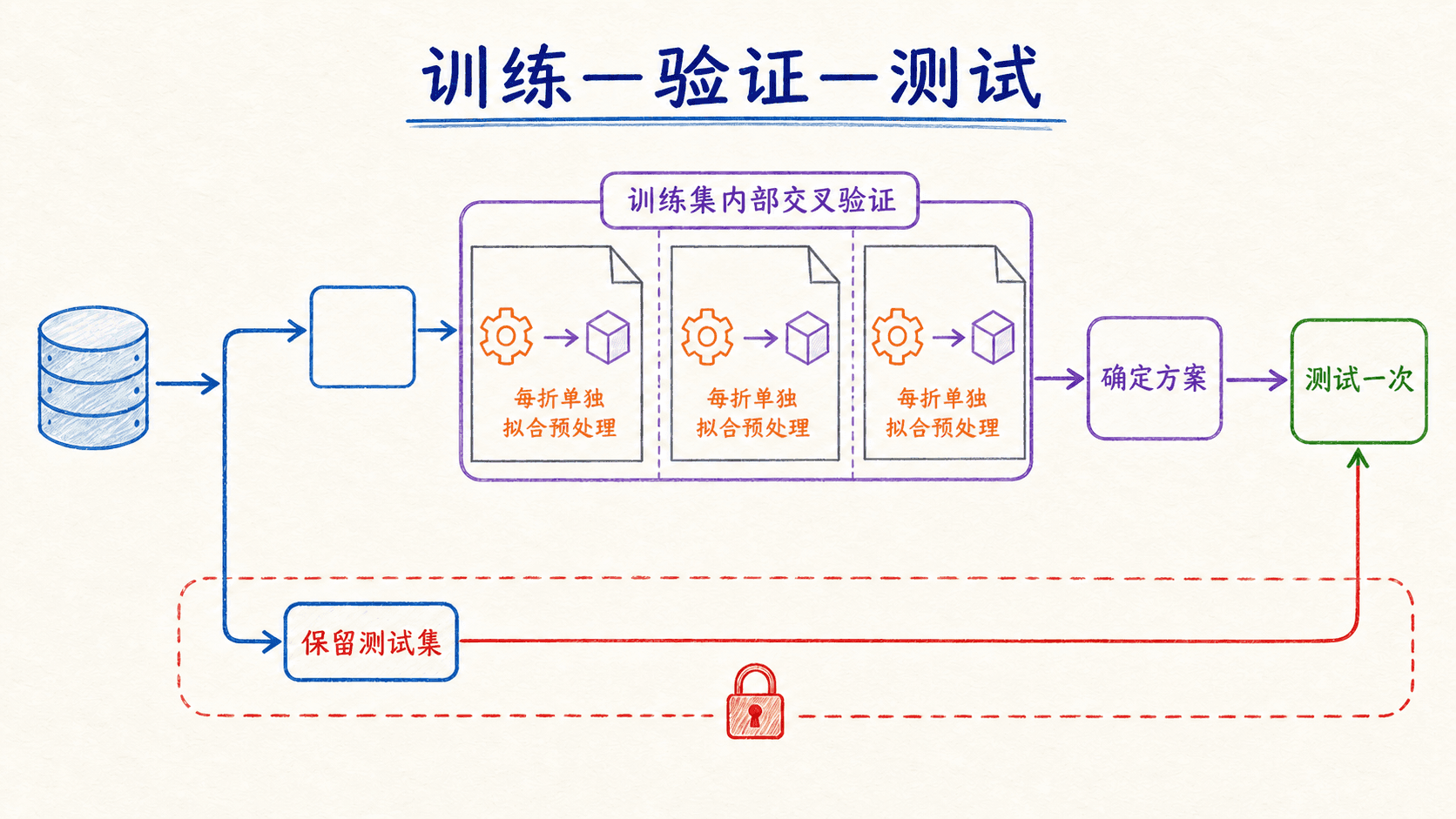
训练、验证、测试要各守自己的边界
一个可靠的回归流程不是“拟合一次,再看一个分数”。数据拆分决定了每个分数能回答什么问题,也决定预处理是否泄漏。
三份数据分别做什么
- 训练集:估计回归系数,也用于拟合缩放、缺失值填补、类别编码等预处理参数。
- 验证集:比较多项式次数、正则化强度、特征组合等方案。
- 测试集:所有方案确定后,只做一次接近最终的泛化评估。
如果反复根据测试分数改模型,测试集就事实上变成了验证集。最终报告的分数会越来越乐观,却不再是独立评估。
数据不多时,可以先保留一份最终测试集,再在训练部分做 折交叉验证。每一折都重新拟合整条预处理与建模管道,不能先在全部训练数据上标准化,再把标准化结果送进交叉验证。
拆分方式要尊重数据是怎么产生的
随机拆分只适合样本近似独立同分布的情况。下面这些任务需要换一种方式:
- 同一个用户有多条记录:按用户分组,避免同一人的信息同时出现在训练和测试中。
- 预测未来销量:按时间先后拆分,不能用未来月份帮助预测过去。
- 多家医院或多台设备:若目标是推广到新医院、新设备,应按实体或站点留出。
- 空间数据:相邻区域高度相似时,普通随机拆分可能高估跨区域泛化能力。
Pipeline 把顺序写进代码
python
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import Ridge
model = Pipeline([
("scale", StandardScaler()),
("regressor", Ridge(alpha=1.0)),
])
model.fit(X_train, y_train)
y_pred = model.predict(X_test)Pipeline 不只是少写几行代码。它确保调用 fit 时,缩放器只学习当前训练数据;交叉验证时,每一折也会得到独立拟合的缩放器。相同管道还能直接用于预测,减少上线时漏做或错做变换的风险。
明确预测时点和样本单位,先排除预测当时不可能获得的特征。
按时间、群组或随机规则保留最终测试集,不让它参与方案比较。
把填补、编码、缩放、特征生成与回归器放进同一管道,在训练部分交叉验证。
选定方案后用完整训练部分重新拟合,最后在测试集上报告 MAE、RMSE、 和关键残差图。
9
你要比较 1 次、2 次和 3 次多项式模型。哪种流程最合适?
用 Python 跑通一个可复查的房租基线
下面用一份可重复生成的模拟房租数据,把前面的步骤连起来。模拟数据不是为了证明模型在真实市场有效,而是为了让你能在任何环境里复现实验,并清楚看到每一步的职责。
生成带业务含义的数据
python
import numpy as np
import pandas as pd
rng = np.random.default_rng(42)
m = 600
X = pd.DataFrame({
"面积": rng.uniform(35, 160, size=m),
"距地铁公里": rng.uniform(0.2, 12, size=m),
"房龄": rng.uniform(0, 35
这里故意让房租由多个特征的线性组合加噪声生成。真实数据往往还有缺失值、类别变量、偏态、时间变化与更复杂的交互,因此这个模型只是一个基线。
先拆分,再让管道拟合
python
from sklearn.model_selection import train_test_split
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LinearRegression
X_train, X_test, y_train, y_test = train_test_split(
X,
y,
test_size=0.2,
random_state=42,
)
ols = Pipeline([
("scale", StandardScaler()),
(
这里的 StandardScaler 只会在 X_train 上学习均值和标准差。LinearRegression 的稳定直接求解并不依赖标准化才能找到解,但把缩放放进管道有三个教学价值:统一后续岭回归的尺度、改善条件数,并明确预测时必须复用同一变换。
同时报告误差和基线
python
from sklearn.metrics import mean_absolute_error, mean_squared_error, r2_score
mae = mean_absolute_error(y_test, y_pred)
rmse = mean_squared_error(y_test, y_pred) ** 0.5
r2 = r2_score(y_test, y_pred)
baseline_pred = np.repeat(y_train.mean(), len(y_test))
baseline_mae = mean_absolute_error(y_test, baseline_pred)
print(f"MAE: {mae:.1f}")
print(f"RMSE: {rmse
单独看 MAE 数字很难判断好坏。把它与“总是预测训练集平均房租”的基线比较,至少能确认模型是否学到了比常数预测更多的信息。真实项目还要与业务当前方法、可接受误差和不同群体的表现比较。
用交叉验证观察结果是否依赖一次拆分
python
from sklearn.model_selection import cross_validate
scores = cross_validate(
ols,
X_train,
y_train,
cv=5,
scoring={
"mae": "neg_mean_absolute_error",
"r2": "r2",
},
return_train_score=True,
)
cv_mae = -scores["test_mae"]
print
scikit-learn 的评分约定是“越大越好”,所以损失类评分会返回负数;转回 MAE 时要加负号。各折差异很大时,应检查样本量、拆分策略、群体差异和异常点,而不是只报告平均数。
把标准化系数换回原单位
标准化后模型的系数表示“特征增加一个训练集标准差”时的预测变化。如果想恢复到原始单位,可以做代数换算:
python
scaler = ols.named_steps["scale"]
reg = ols.named_steps["regressor"]
coef_original = reg.coef_ / scaler.scale_
intercept_original = (
reg.intercept_
- np.sum(reg.coef_ * scaler.mean_ / scaler.scale_)
)
coef_table = pd.Series(coef_original, index=X.columns, name="原单位系数")
print("原单位截距:", intercept_original)
恢复单位并不会自动赋予因果含义。它只让系数回到“面积增加一平方米”“距离增加一公里”等更易读的尺度。
最后画残差,而不是打印分数就结束
python
import matplotlib.pyplot as plt
residuals = y_test - y_pred
fig, axes = plt.subplots(1, 2, figsize=(11, 4))
axes[0].scatter(y_pred, residuals, alpha=0.65)
axes[0].axhline(0, color="black", linewidth=1
如果残差图出现弧线,可以尝试有理论依据的非线性项;出现漏斗形,要检查方差是否随房租水平变化;某个区域的点整体偏正或偏负,则可能漏掉区域信息。每一次修改都回到训练集内部验证,最终测试集不要跟着反复试。
如果你想给这个基线增加二阶项,可以把 PolynomialFeatures(degree=2, include_bias=False)、StandardScaler() 和 Ridge() 依次放进同一个 Pipeline,再在训练集内部交叉验证多项式次数与 alpha。不要先对完整数据生成二阶特征,也不要因为训练误差下降就宣布模型更好。
10
一个回归模型在独立测试集上的 R² 为 -0.18,最合理的含义是什么?