逻辑回归 - 分类问题的经典算法 | 自在学
逻辑回归:从概率模型走到可执行的分类决策
前面的线性回归给了我们一套很熟悉的语言:把特征组合成一个分数,再用损失函数学参数。但很多问题的目标不是一个连续数值,而是一个事件:设备会不会在一周内故障,一封邮件是不是垃圾邮件,一笔交易是否需要人工复核。
逻辑回归保留了线性分数,却改变了对输出的建模方式。它假设二元标签服从伯努利分布,用 sigmoid 把任意实数分数映射成 0 0 0 1 1 1
这一章会把整条链路走完:从 logit 的概率解释,推到伯努利似然和交叉熵,再落到数值稳定的 NumPy 实现、阈值选择、PR/ROC、概率校准和多分类。你最后得到的不只是一个会输出 0 0 0 1 1 1
先把概率估计和分类行动拆开
二分类通常把标签写成 y ∈ { 0 , 1 } y\in\{0,1\} y ∈ { 0 , 1 } y = 1 y=1 y = 1 y = 0 y=0 y = 0
对一个特征向量 x x x
p ( x ) = P ( Y = 1 ∣ X = x ) p(x)=P(Y=1\mid X=x) p ( x ) = P ( Y = 1 ∣ X = x ) 条件符号很重要。输出 0.8 0.8 0.8 80 % 80\% 80%
从概率到行动,还要加一个阈值 t t t
y ^ = 1 [ p ( x ) ≥ t ] \hat{y}=\mathbb{1}[p(x)\ge t] y ^ = 1 [ p ( x ) ≥ t ] 默认的 t = 0.5 t=0.5 t = 0.5 0.5 0.5 0.5
直接用线性回归拟合 0 / 1 0/1 0/1 0.5 0.5 0.5
线性输出没有限制,可以小于 0 0 0 1 1 1
均方误差隐含的噪声视角与伯努利标签不匹配;
极端自变量可以明显改变最小二乘直线,连带改变人为阈值的交点。
开始训练之前,还要定好标签时间窗口、特征截止时刻和数据划分。用故障发生后才能知道的维修记录去预测故障,无论模型叫什么都已经数据泄漏。训练集用来学参数,验证集用来选特征、阈值和超参数,测试集只在方案锁定后做一次最终检查。
模型负责估计概率,阈值负责把概率变成行动。
分类器实际上做了两件事:先估计概率或连续分数,再根据阈值采取行动。换阈值不会重新训练模型,却会改变误报、漏报和业务成本。
1 一个故障预警模型对某设备输出 0.72。下列哪个解释最严谨?
A 该设备有 72% 的部件已经损坏 B 这次预测有 72% 的概率是正确的 C 在模型与数据条件合理时,它对一周内故障的条件概率估计为 0.72 D 只要输出大于 0.5,就证明故障一定会发生
logit 和 sigmoid 把线性分数转成概率
概率 p p p 0 0 0 1 1 1 p p p
odds ( p ) = p 1 − p \operatorname{odds}(p)=\frac{p}{1-p} odds ( p ) = 1 − p p 概率 p = 0.8 p=0.8 p = 0.8 4 4 4 4 : 1 4:1 4 : 1
logit ( p ) = log p 1 − p \operatorname{logit}(p)=\log\frac{p}{1-p} logit ( p ) = log 1 − p p logit 的取值范围是整条实数轴。逻辑回归的核心假设是:在其他特征不变时,正类的对数几率是特征的线性函数。给特征补一列常数 1 1 1 x ~ = [ 1 , x 1 , … , x n ] T \tilde{x}=[1,x_1,\ldots,x_n]^T x ~ = [ 1 , x 1 , … , x n
z = θ T x ~ = log p 1 − p z=\theta^T\tilde{x}=\log\frac{p}{1-p} z = θ T x ~ = log 1 − p p 解出 p p p
p = σ ( z ) = 1 1 + e − z p=\sigma(z)=\frac{1}{1+e^{-z}} p = σ ( z ) = 1 + e − z 1 这是一对互为反函数的变换:sigmoid 把实数 z z z ( 0 , 1 ) (0,1) ( 0 , 1 ) ( 0 , 1 ) (0,1) ( 0 , 1 ) z = 0 z=0 z = 0 p = 0.5 p=0.5 p = 0.5
参数也可以用几率解释。保持其他特征不变,x j x_j x j 1 1 1 θ j \theta_j θ j e θ j e^{\theta_j} e
阈值 t t t
p ( x ) ≥ t ⟺ θ T x ~ ≥ log t 1 − t p(x)\ge t
\quad\Longleftrightarrow\quad
\theta^T\tilde{x}\ge \log\frac{t}{1-t} p ( x ) ≥ t ⟺ θ T x ~ ≥ log 1 当 t = 0.5 t=0.5 t = 0.5 0 0 0 t = 0.8 t=0.8 t = 0.8 z ≥ log 4 ≈ 1.386 z\ge\log 4\approx1.386 z ≥ log 4 ≈ 1.386
logit 把有限概率区间展开到整条实数轴。
2 当模型给出正类概率 p=0.8 时,正类对负类的几率 odds 是 ____。
伯努利似然自然导出交叉熵
对于一个二元标签,伯努利分布可以用一行同时写下两种情况。记 p i = σ ( θ T x ~ i ) p_i=\sigma(\theta^T\tilde{x}_i) p i = σ ( θ T x ~ i )
P ( y i ∣ x i ; θ ) = p i y i ( 1 − p i ) 1 − y i P(y_i\mid x_i;\theta)=p_i^{y_i}(1-p_i)^{1-y_i} P ( y i ∣ x i ; θ ) = p 当 y i = 1 y_i=1 y i = 1 p i p_i p i y i = 0 y_i=0 y i
L ( θ ) = ∏ i = 1 m p i y i ( 1 − p i ) 1 − y i L(\theta)=\prod_{i=1}^{m}p_i^{y_i}(1-p_i)^{1-y_i} L ( θ ) = i = 1 ∏ m p i y 直接连乘很多小于 1 1 1
J ( θ ) = − 1 m ∑ i = 1 m [ y i log p i + ( 1 − y i ) log ( 1 − p i ) ] J(\theta)
=-\frac{1}{m}\sum_{i=1}^{m}
\left[y_i\log p_i+(1-y_i)\log(1-p_i)\right] J ( θ ) = − m 1 i = 1 ∑ 这就是二元交叉熵,也叫 log loss 或 logistic loss。这几个名字在二分类语境里指向同一个核心目标,但“交叉熵”还可以用在多分类和更一般的概率分布上。
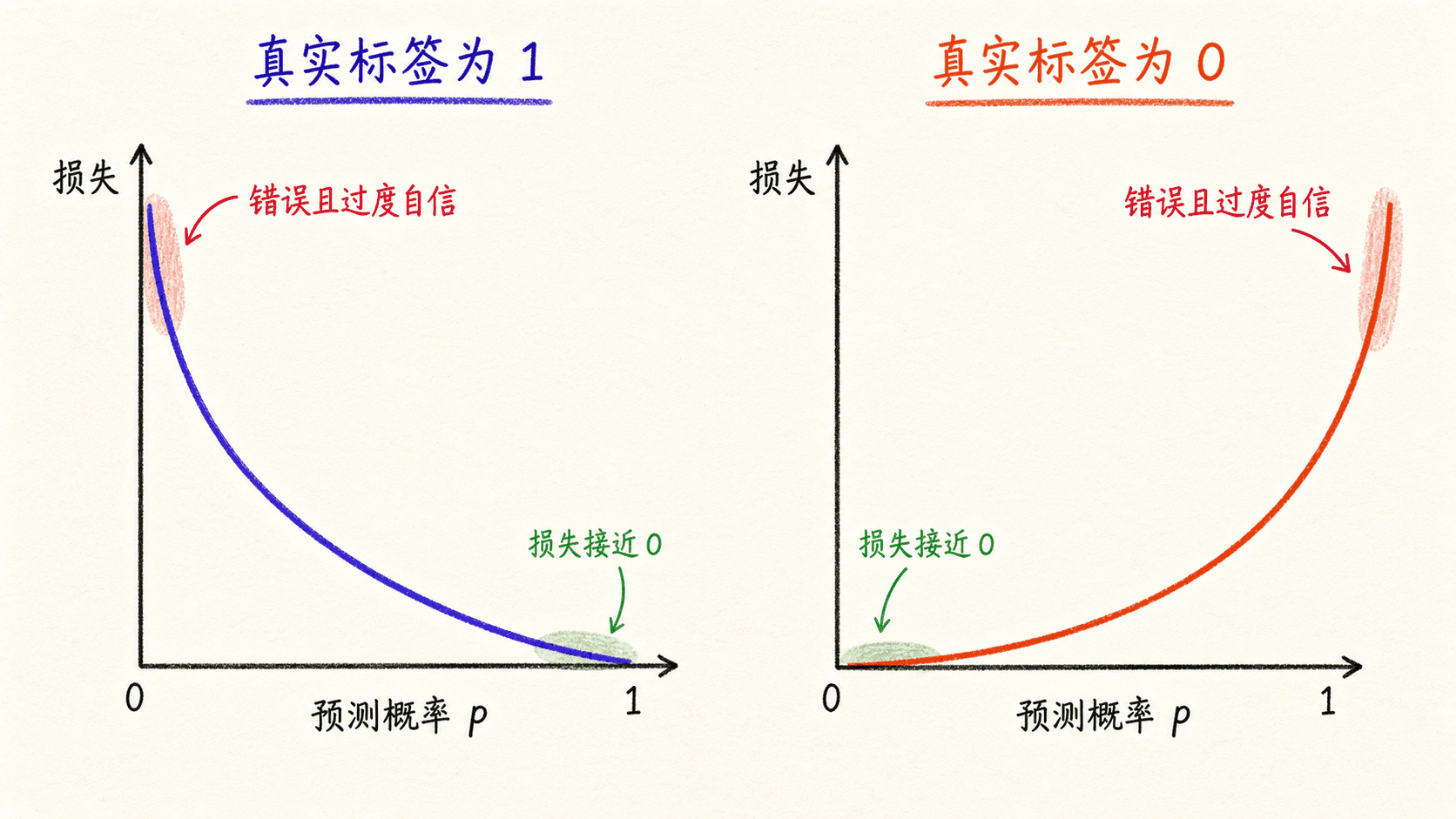
看单个样本就能理解它的惩罚方式:
ℓ ( p , y ) = { − log p , y = 1 − log ( 1 − p ) , y = 0 \ell(p,y)=
\begin{cases}
-\log p, & y=1 \\
-\log(1-p), & y=0
\end{cases} ℓ ( p , y ) = { − log p , − log ( 1 − p ) 真实标签是 1 1 1 p p p 0.9 0.9 0.9 0.6 0.6 0.6 p p p 0.001 0.001 0.001
把 p = σ ( z ) p=\sigma(z) p = σ ( z )
ℓ ( z , y ) = log ( 1 + e z ) − y z \ell(z,y)=\log(1+e^z)-yz ℓ ( z , y ) = log ( 1 + e z ) − y z log ( 1 + e z ) \log(1+e^z) log ( 1 + e z ) z = X θ z=X\theta z = X θ θ \theta θ
交叉熵同时检查分类方向和置信程度。
3 真实标签 y=1 时,下列哪个预测的交叉熵损失最大?
A p=0.95 B p=0.70 C p=0.20 D p=0.01
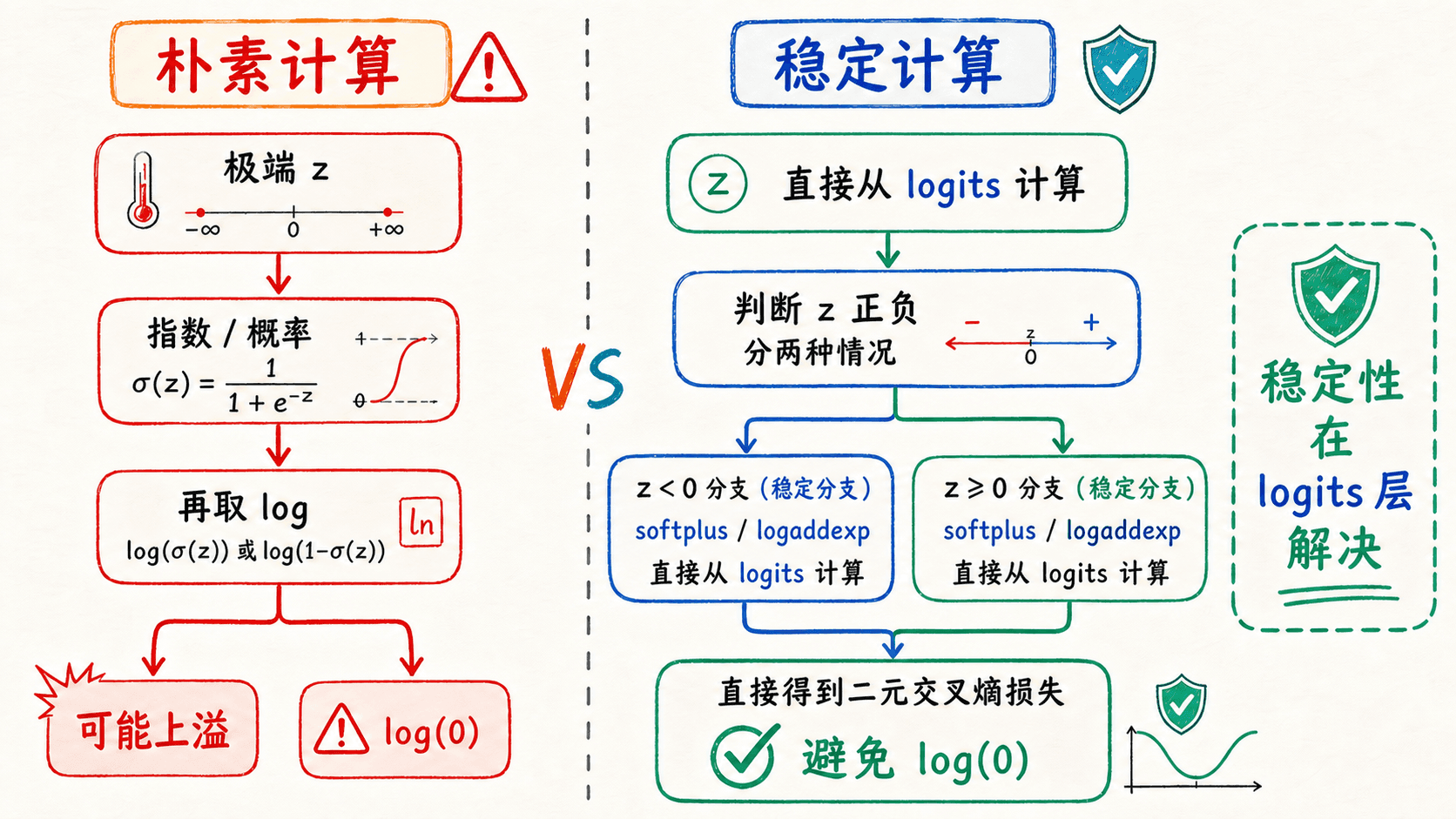
数值稳定要从 logits 开始设计
数学公式里的 sigmoid 只有一行,直译成浮点运算却可能溢出。如果 z = − 1000 z=-1000 z = − 1000 e 1000 e^{1000} e 1000 0 0 0 inf。
一个稳定的 sigmoid 会按 z z z
σ ( z ) = { 1 1 + e − z , z ≥ 0 e z 1 + e z , z < 0 \sigma(z)=
\begin{cases}
\dfrac{1}{1+e^{-z}}, & z\ge0 \\
\dfrac{e^z}{1+e^z}, & z<0
\end{cases} σ ( z ) = ⎩ ⎨ 正分支里 e − z ≤ 1 e^{-z}\le1 e − z ≤ 1 e z < 1 e^z<1 e z < 1
import numpy as np
def stable_sigmoid (z): """对任意形状的浮点数组逐元计算 sigmoid。""" z = np.asarray(z, dtype = np.float64) out = np.empty_like(z) nonnegative = z >= 0 out[nonnegative] = 1.0 / ( 1.0 + np.exp( - z[nonnegative])) exp_z = np.exp(z[ ~ nonnegative]) out[ ~ nonnegative] 损失也不要先算概率,再直接调用 log(p) 和 log(1-p)。当概率在浮点精度下被舍入成精确的 0 0 0 1 1 1 np.logaddexp(0, z) 计算 softplus,可以避免这条脆弱路径:
def binary_cross_entropy_with_logits (logits, y): """返回平均二元交叉熵,logits 与 y 均为 (m,)。""" logits = np.asarray(logits, dtype = np.float64) y = np.asarray(y, dtype = np.float64) if logits.ndim != 1 or y.ndim != 1 : raise ValueError ( "logits 和 y 必须是一维数组" ) if logits.shape != y.shape: raise ValueError ( "logits 和 y 的形状必须相同" ) if 给概率加一个很小的 epsilon 能避免 log(0),某些指标 API 也会在输入边界做裁剪。但对训练目标而言,从 logits 使用稳定恒等式更清楚:它不会人为改写极端概率处的目标,也不需要猜 epsilon 的大小。成熟的科学计算库还提供 expit、log_expit 或“with logits”版本的损失,实际项目应优先复用这些经过测试的实现。
形状错误往往比溢出更隐蔽。本章统一使用下列约定:
如果 y 是 (m, 1) 而 p 是 (m,),p-y 可能广播成 (m, m),程序不一定立即报错,却会学一个完全不同的东西。进入训练循环前就用 assert 固定维数,比在损失变成 NaN 后再猜强得多。
稳定性应在 logits 层解决,而不是事后掩盖无穷值。
梯度告诉我们每个样本在推动什么
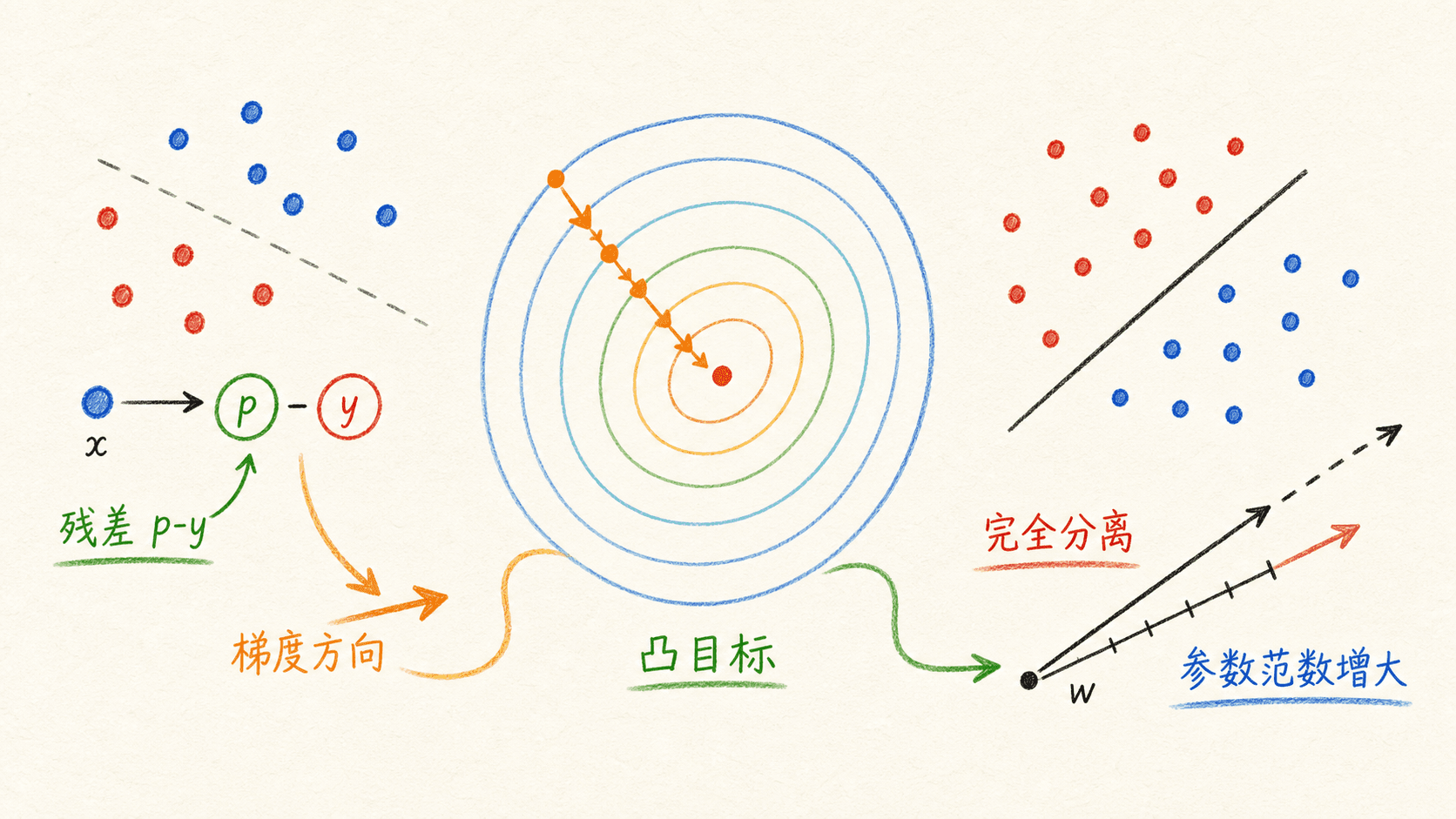
对平均交叉熵求导,会得到一个和线性回归外形相似的梯度。记设计矩阵 X ∈ R m × d X\in\mathbb{R}^{m\times d} X ∈ R m × d θ ∈ R d \theta\in\mathbb{R}^{d} θ ∈ R d z = X θ z=X\theta z =
∇ J ( θ ) = 1 m X T ( p − y ) \nabla J(\theta)=\frac{1}{m}X^T(p-y) ∇ J ( θ ) = m 1 X T ( p − y ) 这个式子可以逐层对形状:
X T ∈ R d × m , p − y ∈ R m , ∇ J ∈ R d X^T\in\mathbb{R}^{d\times m},
\quad p-y\in\mathbb{R}^{m},
\quad \nabla J\in\mathbb{R}^{d} X T ∈ R d × m , p − y ∈ R 对单个样本,残差 p i − y i p_i-y_i p i − y i y i = 1 y_i=1 y i = 1
批量梯度下降更新为:
θ ← θ − α 1 m X T ( p − y ) \theta\leftarrow\theta-\alpha\frac{1}{m}X^T(p-y) θ ← θ − α m 1 X T ( p − y ) 二阶信息也有简洁形式。令 W W W i i i p i ( 1 − p i ) p_i(1-p_i) p i ( 1 − p i )
H = 1 m X T W X H=\frac{1}{m}X^T W X H = m 1 X T W X 因为 p i ( 1 − p i ) ≥ 0 p_i(1-p_i)\ge0 p i ( 1 − p i ) ≥ 0 H H H
选优化器之前,先把下列基础做好:
仅用训练集的均值和标准差缩放数值特征,再复用到验证集和测试集;
同时监测有限损失、梯度范数和验证集损失,不要只看迭代次数;
用少量参数做有限差分梯度检查,再扩到完整数据;
对库实现检查是否默认启用正则化、截距如何处理,以及求解器是否真正收敛。
还有一个容易误判成“优化器太慢”的情况:数据可能被一条边界完全分开。在无正则的完全分离下,把参数沿分界方向不断放大,对数似然仍可以逼近更好的极限,却没有有限的最大似然解。表现上就是系数越来越大,损失还在缓慢下降。下一章的正则化会给这种参数膨胀加上约束。
损失下降不总等于已经得到稳定的有限参数。
5 训练一个二元逻辑回归时,损失持续缓慢下降,但参数范数不断增大。哪些排查方向合理?
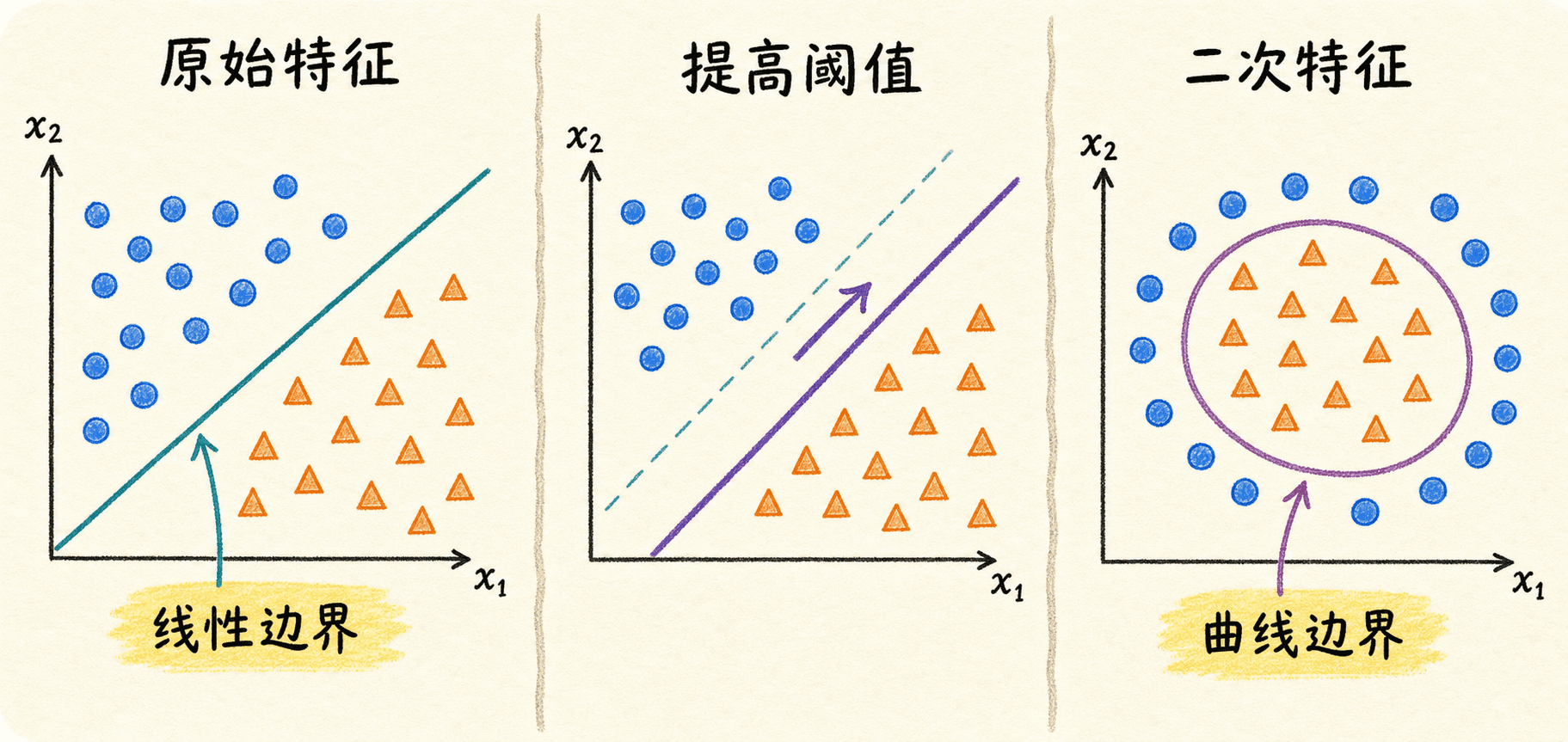
决策边界由特征空间和阈值共同决定
在 t = 0.5 t=0.5 t = 0.5 z ≥ 0 z\ge0 z ≥ 0 x 1 , x 2 x_1,x_2 x 1 , x 2
θ 0 + θ 1 x 1 + θ 2 x 2 = 0 \theta_0+\theta_1x_1+\theta_2x_2=0 θ 0 + θ 1 x 1 + θ 只要 θ 1 \theta_1 θ 1 θ 2 \theta_2 θ 2 0 0 0 z z z z z
一旦阈值改成任意 t t t
θ T x ~ = logit ( t ) \theta^T\tilde{x}=\operatorname{logit}(t) θ T x ~ = logit ( t ) 因此“模型的决策边界”这句话应该同时说明特征变换和阈值。同一组参数在 t = 0.3 t=0.3 t = 0.3 t = 0.8 t=0.8 t = 0.8
逻辑回归对“输入给定的特征”是线性分类器,但特征本身可以是非线性变换。例如把二维输入映射为:
ϕ ( x ) = [ 1 , x 1 , x 2 , x 1 2 , x 1 x 2 , x 2 2 ] T \phi(x)=
[1,x_1,x_2,x_1^2,x_1x_2,x_2^2]^T ϕ ( x ) = [ 1 , x 1 , x 2 , x 在这个特征空间里仍然只算 θ T ϕ ( x ) \theta^T\phi(x) θ T ϕ ( x )
− 1 + x 1 2 + x 2 2 = 0 -1+x_1^2+x_2^2=0 − 1 + x 1 2 + x 2 2 = 0 对应单位圆。这种做法很直观,也要付出代价:高次组合会迅速增加特征数,带来共线性、尺度差异和过拟合。特征映射必须在训练、验证和预测时完全一致,同时配合正则化与未见数据评估。
模型对映射后的特征线性,不代表原空间边界只能是直线。
6 逻辑回归永远只能在原始输入平面上得到直线决策边界。
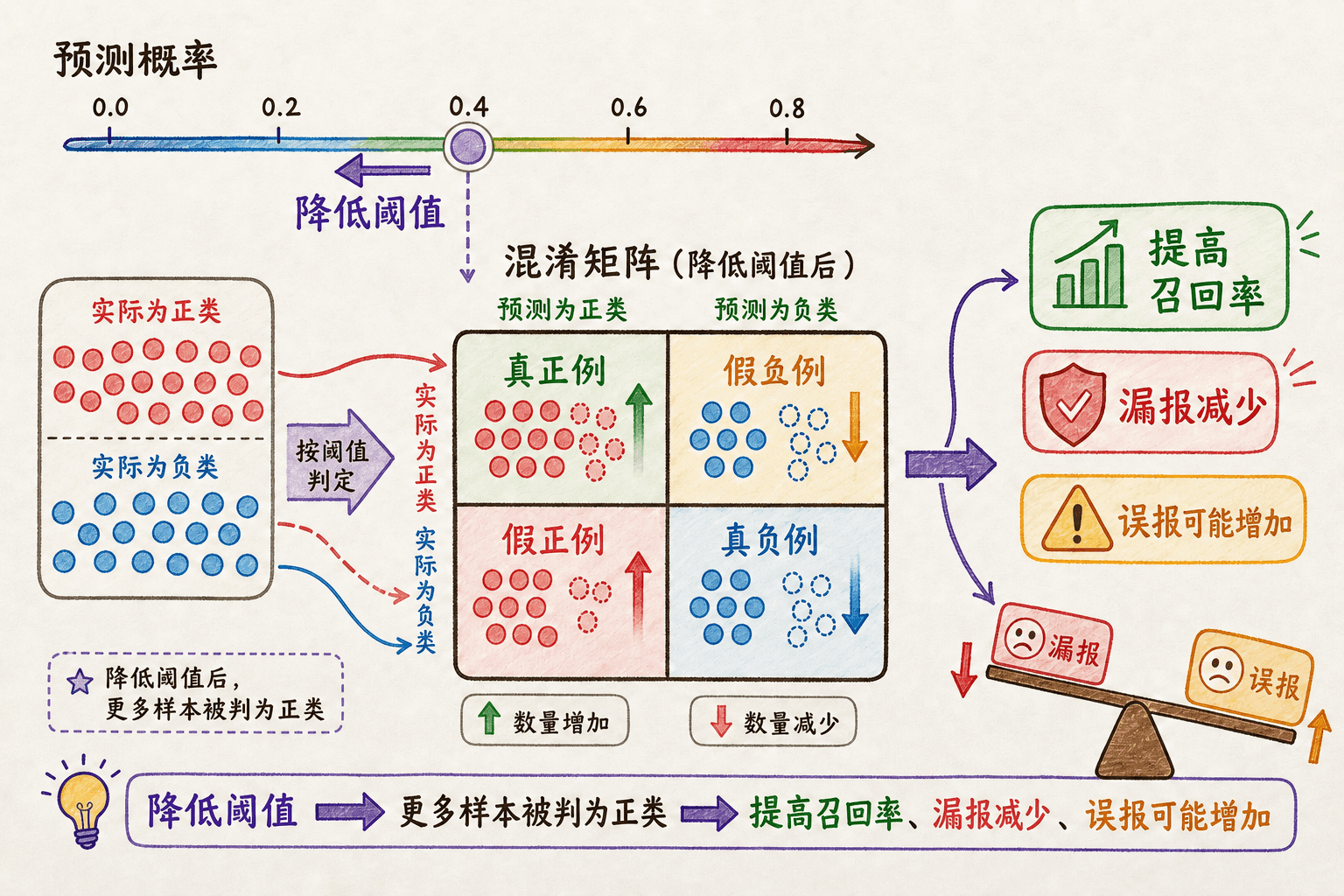
阈值一移动,混淆矩阵就跟着变
设备故障模型输出一列概率后,阈值 t t t
四个计数能组合出常用指标:
precision = T P T P + F P \text{precision}=\frac{TP}{TP+FP} precision = T P + F P T P recall = T P T P + F N \text{recall}=\frac{TP}{TP+FN} recall = T P + F N T P specificity = T N T N + F P \text{specificity}=\frac{TN}{TN+FP} specificity = T N + F P T N F 1 = 2 ⋅ precision ⋅ recall precision + recall F_1=2\cdot\frac{\text{precision}\cdot\text{recall}}{\text{precision}+\text{recall}} F 1 = 2 ⋅ precision + recall precision ⋅ recall precision 回答“被我报成正类的样本中,真正为正的比例是多少”;recall 回答“全部真正类中,我找到了多少”。二者的分母不同,不能只凭中文名字记忆。F 1 F_1 F 1
阈值降低时,更多样本会被报为正类。TP 和 FP 都可能增加,FN 不会增加,所以 recall 不会下降;precision 的变化则取决于新加入的样本里真正类和假正类的比例,并不保证每一步都单调下降。
如果能把误报和漏报的代价近似数字化,可以在验证集上比较:
C ( t ) = c F P F P ( t ) + c F N F N ( t ) C(t)=c_{FP}\,FP(t)+c_{FN}\,FN(t) C ( t ) = c F P F P ( t ) + c F N 也可以设定约束,例如“recall 至少为 0.95 0.95 0.95
阈值不是模型常数,而是业务代价对应的操作点。
7 某阈值下 TP=36、FP=12、FN=4、TN=148。precision 和 recall 分别是多少?若任务强调‘尽量不漏掉正类’,应优先关注哪个指标?
A precision=0.90,recall=0.75,应优先关注 precision B precision=0.75,recall=0.90,应优先关注 recall C precision=0.75,recall=0.90,应优先关注 specificity D precision=0.90,recall=0.75,应优先关注 accuracy
PR 和 ROC 曲线检查的是一整段阈值
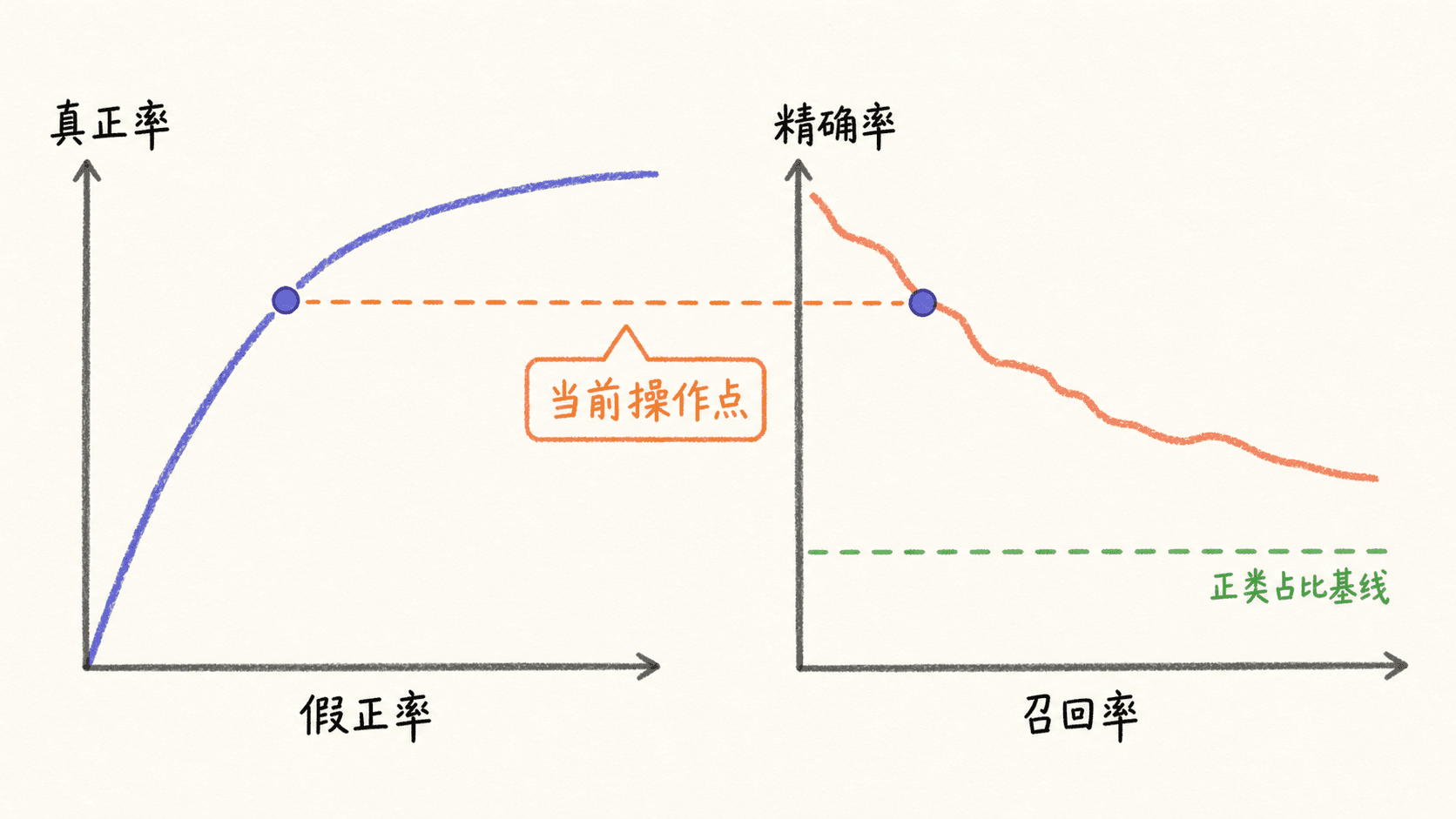
单个混淆矩阵只是某个阈值下的快照。把阈值从高到低扫过所有候选位置,就能观察模型是否把正类总体排在负类前面。
ROC 曲线的纵轴是真正率,也就是 recall;横轴是假正率:
T P R = T P T P + F N TPR=\frac{TP}{TP+FN} T P R = T P + F N T P F P R = F P F P + T N FPR=\frac{FP}{FP+TN} F P R = F P + T N F P PR 曲线则用 recall 做横轴,precision 做纵轴。两条曲线都来自同一列未切分的概率或决策分数,只是对错误结构的投影不同。
ROC 能同时展示正类覆盖与负类误报比例,适合比较整体排序能力。当正类极少、并且实际关心“报出的一堆样本中有多少真的”时,PR 曲线通常更直接。在随机排序的理想基准下,PR 的 precision 基线接近正类占比;当正类只占 1 % 1\% 1% 10 % 10\% 10%
ROC-AUC 可以解释为随机抽一个正类和一个负类时,模型把正类排在负类之前的概率,并对并列情况做相应处理。Average Precision 常用来摘要 PR 曲线,它按 recall 的增量对各阶段 precision 加权,不必然等于用梯形法直接积分出的面积。
不要把 AUC 当成已部署阈值的效果。两个模型可以有相近的 ROC-AUC,却在你需要的“recall 至少 0.95 0.95 0.95 0.8 0.8 0.8
AUC 摘要整体排序,部署仍需检查目标区域的具体操作点。
8 只要两个分类器的 ROC-AUC 相同,它们在任意业务阈值下的误报数和漏报数就一定相同。
会排序不等于概率已经校准
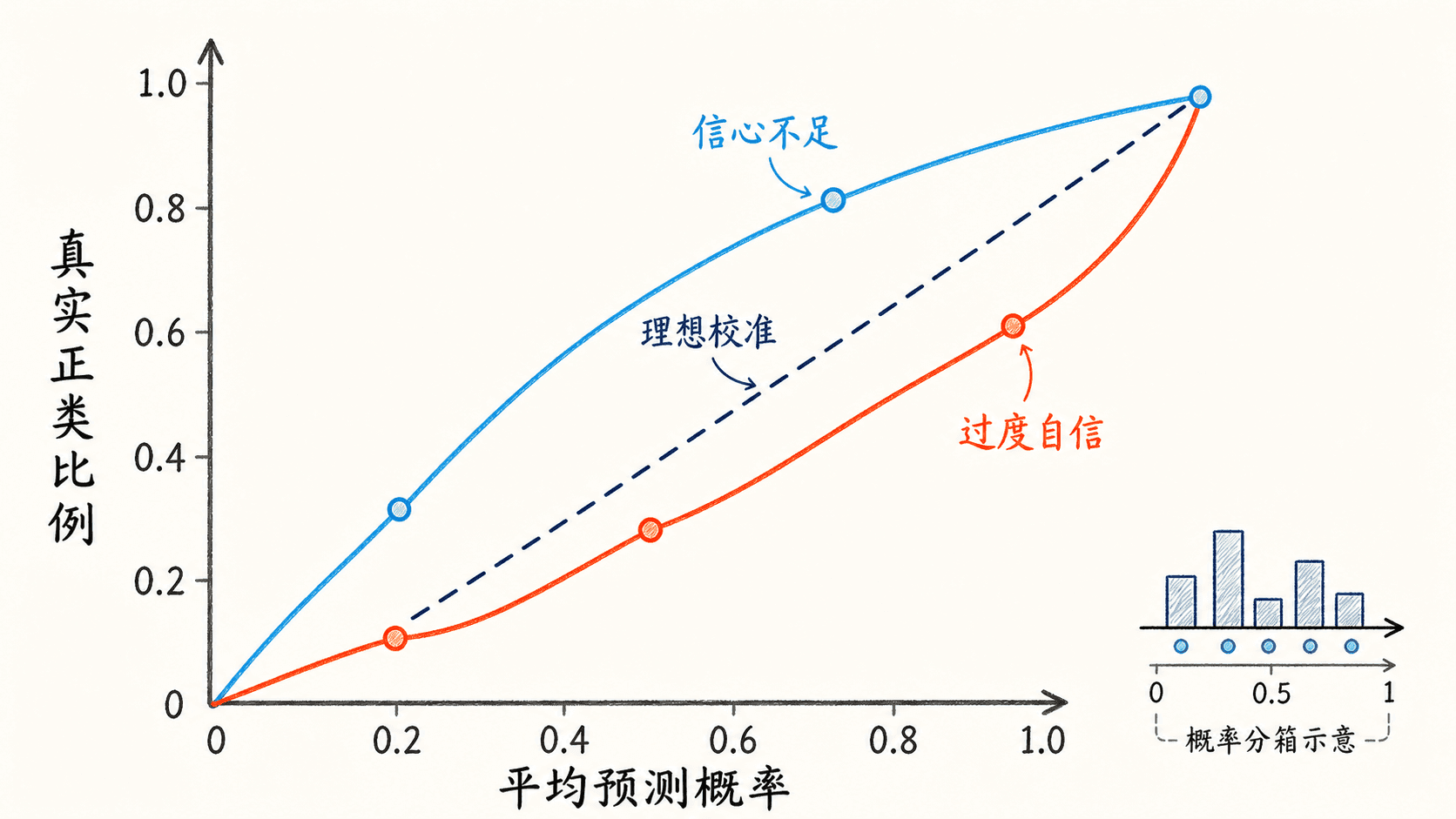
如果模型把 1000 1000 1000 0.7 0.7 0.7 70 % 70\% 70%
可靠性图(reliability diagram)是最直观的检查。它把样本按预测概率分箱,每箱的横坐标是平均预测概率,纵坐标是真实正类比例。理想情况下各点落在 y = x y=x y = x
这里要把两个能力分开:
区分或排序能力 :正类是否通常得到比负类更高的分数,可用 ROC-AUC、PR 曲线等观察;校准能力 :说 0.7 0.7 0.7 70 % 70\% 70%
log loss 和 Brier 损失都是概率评分规则,但它们同时受校准、区分能力和数据本身不确定性影响。因此“Brier 损失更低”不能单独证明校准更好,最好与可靠性图和排序指标一起看。
逻辑回归因为直接用 log loss 和 logit 链接建模,在模型设定接近真实、正则强度合理时常能产生较好的概率,但绝不是自动保证。漏掉非线性关系、过强正则、类别采样比例被改动、使用类权重,或上线后基准率变化,都可能让概率偏离实际频率。
需要后处理校准时,可以在未参与基模型拟合的数据上学一个从分数到概率的映射,例如 sigmoid 校准、保序回归或多分类的温度缩放。样本少时可以用交叉验证式的校准流程减少浪费。不能在同一批数据上既拟合基模型、又拟合校准器、还报告最终效果,否则三次都会向这批数据过拟合。
会排序和概率数值可信是两个不同问题。
多分类时要分清 OvR 和 softmax 在拟合什么
如果每个样本只能属于 K K K 0 0 0 9 9 9
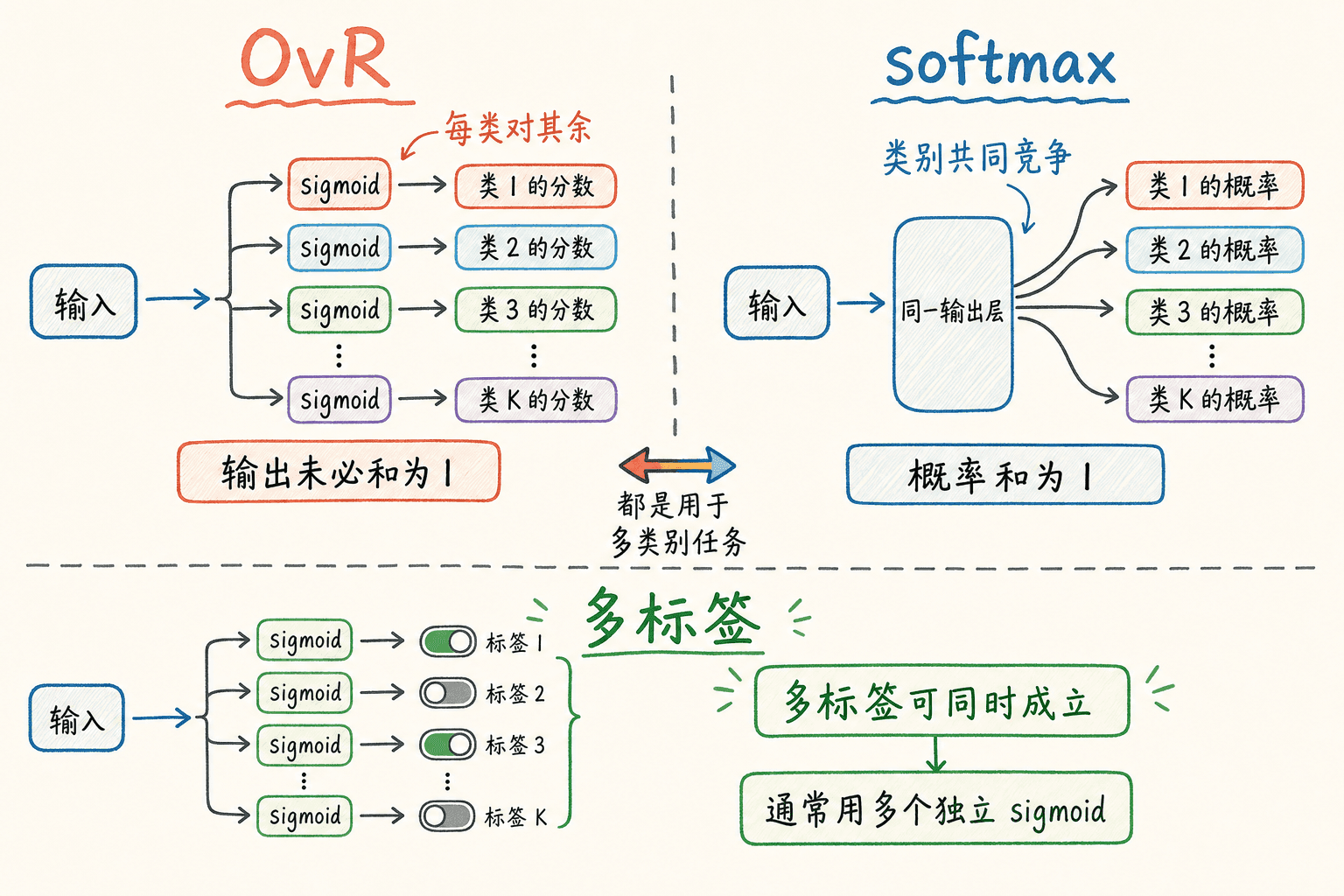
OvR:每一类对其余所有类
One-vs-Rest(OvR)为每个类别 k k k
p k ( x ) = σ ( θ k T x ~ ) p_k(x)=\sigma(\theta_k^T\tilde{x}) p k ( x ) = σ ( θ k T x ~ ) 训练第 k k k k k k 1 1 1 0 0 0
y ^ = arg max k p k ( x ) \hat{y}=\arg\max_k p_k(x) y ^ = arg k max p k ( x ) 这 K K K 1 1 1 predict_proba 层面做归一化,但这不会把它的训练目标变成联合的多项似然。OvR 便于复用只支持二分类的学习器,也容易查看“某一类对其余”的特征系数。
softmax:所有互斥类别共同归一化
多项逻辑回归为每个类别计算一个 logit z k z_k z k
P ( Y = k ∣ x ) = e z k ∑ j = 1 K e z j P(Y=k\mid x)=
\frac{e^{z_k}}{\sum_{j=1}^{K}e^{z_j}} P ( Y = k ∣ x ) = ∑ j = 1 K 所有类别概率之和严格为 1 1 1 e 1000 e^{1000} e 1000
def stable_softmax (logits): """logits 形状为 (m, K),按行返回类别概率。""" logits = np.asarray(logits, dtype = np.float64) if logits.ndim != 2 : raise ValueError ( "logits 必须是 (m, K) 二维数组" ) shifted = logits - np.max(logits, axis = 1 , keepdims = True ) exp_shifted = np.exp(shifted) return exp_shifted / np.sum(exp_shifted, 减去同一行的常数不改变 softmax 结果,因为分子和分母会同时乘上相同因子。训练时使用多类交叉熵:
J = − 1 m ∑ i = 1 m log P ( Y = y i ∣ x i ) J=-\frac{1}{m}\sum_{i=1}^{m}\log P(Y=y_i\mid x_i) J = − m 1 i = 1 ∑ m log P 互斥多分类问题中,softmax 直接建模类别之间的竞争;OvR 则把问题拆成 K K K 1 1 1
先确定标签是否互斥,再决定输出层结构。
10 一张图片可以同时带有‘户外’、‘人像’和‘夜景’多个标签。最合适的输出结构是什么?
A 对所有标签使用 softmax,强制概率和为 1 B 每个标签使用一个独立 sigmoid,分别设定阈值 C 只预测频率最高的一个标签 D 把三个标签编成连续数值后做线性回归
用一个可运行实验串起训练、选阈值和调试
下面的例子只依赖 NumPy,以便把每个数组的形状和每一步数学运算暴露出来。它先生成一批来自真实 logistic 机制的二维数据,做分层的训练/验证/测试划分,只用训练集拟合标准化参数,然后用稳定交叉熵训练。验证集用来选 F 1 F_1 F 1
import numpy as np
def stable_sigmoid (z): z = np.asarray(z, dtype = np.float64) out = np.empty_like(z) nonnegative = z >= 0 out[nonnegative] = 1.0 / ( 1.0 + np.exp( - z[nonnegative])) exp_z = np.exp(z[ ~ nonnegative]) out[ ~ nonnegative] = exp_z 这份代码刻意不用测试集选阈值,也不用整个数据集计算标准化参数。best_theta 根据验证交叉熵保存,而阈值根据验证 F 1 F_1 F 1 choose_threshold_by_f1 换成最小化验证集成本的函数。
手写实现出错时,不要立即换优化器。按数据流逐站检查,通常更快:
标签 :确认只有 0 / 1 0/1 0/1 划分 :检查同一实体、相邻时间片或重复记录是否跨越数据集造成泄漏。特征 :打印各集的形状、有限值比例、均值和标准差,确保验证/测试复用训练参数。前向计算 :用 z = 0 z=0 z = 0 z = 1000 z=1000 z = 1000 z = − 1000 z=-1000 z = − 1000 梯度 :在十几个样本上做有限差分检查,确认符号、平均因子和截距处理。优化 :绘制训练与验证损失,同时查看梯度范数和参数范数。评估 :在验证集选阈值,展示混淆矩阵与所需的 PR/ROC 区域,再检查校准。交付 :连同 theta、mu、sigma、特征顺序、正类定义和阈值一起保存。
逻辑回归的“完整模型”不只是一个 theta。标准化参数、特征顺序、正类定义、概率校准步骤和决策阈值,都会改变最终输出。部署时漏掉其中任何一项,都可能让一组正确系数产生错误决策。
当这条链路跑通后,下一个真实问题是特征越来越多、边界越来越灵活时,如何阻止参数只记住训练样本。这就是下一章正则化要处理的事:它不会替代数据划分、指标和校准,而是在当前损失上增加对参数复杂度的明确约束。
11 先用全部数据计算均值和标准差,再划分训练集和测试集;随后反复调整阈值,直到测试 F1 最高,并把该结果当作上线表现。下列哪些修改能消除流程中明确的评估污染?
] T
θ j
θ j = 0.7 \theta_j=0.7 θ j = 0.7
−
t
t
i
y i
(
1
−
p i ) 1 − y i
=
0
i
(
1
−
p i ) 1 − y i
m
[ y i log p i + ( 1 − y i ) log ( 1 − p i ) ]
,
y = 1 y = 0
⎧
1 + e − z 1 , 1 + e z e z , z ≥ 0 z < 0
=
exp_z
/
(
1.0
+
exp_z)
return out
not
np.all((y
==
0.0
)
|
(y
==
1.0
)):
raise ValueError ( "y 只能包含 0 和 1" )
losses = np.logaddexp( 0.0 , logits) - y * logits
return float (np.mean(losses))
X
θ
m
,
∇
J
∈
R d
p i
2
x 2
=
0
z
1
2
,
x 1
x 2
,
x 2 2
] T
F
N
(
t
)
e z j
e z k
axis
=
1
,
keepdims
=
True
)
(
Y
=
y i ∣
x i )
/
(
1.0
+
exp_z)
return out
def loss_from_logits (logits, y):
logits = np.asarray(logits, dtype = np.float64)
y = np.asarray(y, dtype = np.float64)
if logits.shape != y.shape or logits.ndim != 1 :
raise ValueError ( "logits 与 y 必须是同形的一维数组" )
return float (np.mean(np.logaddexp( 0.0 , logits) - y * logits))
def make_dataset (n = 900 , seed = 7 ):
rng = np.random.default_rng(seed)
X = rng.normal( size = (n, 2 ))
true_logits = - 0.65 + 1.35 * X[:, 0 ] - 0.95 * X[:, 1 ]
p = stable_sigmoid(true_logits)
y = rng.binomial( 1 , p).astype(np.float64)
return X, y
def stratified_split (y, seed = 11 ):
rng = np.random.default_rng(seed)
train_parts, val_parts, test_parts = [], [], []
for label in ( 0.0 , 1.0 ):
idx = np.flatnonzero(y == label)
rng.shuffle(idx)
n_train = int ( 0.60 * len (idx))
n_val = int ( 0.20 * len (idx))
train_parts.append(idx[:n_train])
val_parts.append(idx[n_train:n_train + n_val])
test_parts.append(idx[n_train + n_val:])
train_idx = np.concatenate(train_parts)
val_idx = np.concatenate(val_parts)
test_idx = np.concatenate(test_parts)
rng.shuffle(train_idx)
rng.shuffle(val_idx)
rng.shuffle(test_idx)
return train_idx, val_idx, test_idx
def fit_standardizer (X_train):
mu = X_train.mean( axis = 0 )
sigma = X_train.std( axis = 0 )
if np.any(sigma == 0.0 ):
raise ValueError ( "训练集存在零方差特征" )
return mu, sigma
def transform_and_add_intercept (X, mu, sigma):
X_scaled = (X - mu) / sigma
return np.column_stack([np.ones(X.shape[ 0 ]), X_scaled])
def fit_logistic_gd (X_train, y_train, X_val, y_val,
learning_rate = 0.2 , steps = 2500 ):
if X_train.ndim != 2 or X_val.ndim != 2 :
raise ValueError ( "X_train 和 X_val 必须是二维矩阵" )
if y_train.shape != (X_train.shape[ 0 ],):
raise ValueError ( "y_train 必须与 X_train 样本数对齐" )
if y_val.shape != (X_val.shape[ 0 ],):
raise ValueError ( "y_val 必须与 X_val 样本数对齐" )
if X_train.shape[ 1 ] != X_val.shape[ 1 ]:
raise ValueError ( "训练和验证特征数不一致" )
theta = np.zeros(X_train.shape[ 1 ], dtype = np.float64)
best_theta = theta.copy()
best_val_loss = np.inf
history = []
for step in range (steps):
train_logits = X_train @ theta
train_p = stable_sigmoid(train_logits)
gradient = X_train.T @ (train_p - y_train) / len (y_train)
theta -= learning_rate * gradient
if step % 50 == 0 or step == steps - 1 :
train_loss = loss_from_logits(X_train @ theta, y_train)
val_loss = loss_from_logits(X_val @ theta, y_val)
grad_norm = float (np.linalg.norm(gradient))
if not np.isfinite(train_loss + val_loss + grad_norm):
raise FloatingPointError ( "训练中出现 NaN 或 Inf" )
history.append((step, train_loss, val_loss, grad_norm))
if val_loss < best_val_loss:
best_val_loss = val_loss
best_theta = theta.copy()
return best_theta, history
def confusion_counts (y, p, threshold):
pred = (p >= threshold).astype(np.float64)
tp = int (np.sum((pred == 1.0 ) & (y == 1.0 )))
fp = int (np.sum((pred == 1.0 ) & (y == 0.0 )))
fn = int (np.sum((pred == 0.0 ) & (y == 1.0 )))
tn = int (np.sum((pred == 0.0 ) & (y == 0.0 )))
return tp, fp, fn, tn
def classification_metrics (y, p, threshold):
tp, fp, fn, tn = confusion_counts(y, p, threshold)
precision = tp / (tp + fp) if tp + fp else 0.0
recall = tp / (tp + fn) if tp + fn else 0.0
f1 = ( 2.0 * precision * recall / (precision + recall)
if precision + recall else 0.0 )
accuracy = (tp + tn) / len (y)
return {
"threshold" : threshold,
"tp" : tp, "fp" : fp, "fn" : fn, "tn" : tn,
"precision" : precision,
"recall" : recall,
"f1" : f1,
"accuracy" : accuracy,
}
def choose_threshold_by_f1 (y_val, p_val):
candidates = np.linspace( 0.05 , 0.95 , 181 )
reports = [classification_metrics(y_val, p_val, t)
for t in candidates]
return max (reports, key =lambda report: report[ "f1" ])
def calibration_table (y, p, bins = 5 ):
edges = np.linspace( 0.0 , 1.0 , bins + 1 )
rows = []
for left, right in zip (edges[: - 1 ], edges[ 1 :]):
include_right = right == 1.0
mask = ((p >= left) & (p <= right) if include_right
else (p >= left) & (p < right))
if np.any(mask):
rows.append({
"range" : f "[ { left :.1f } , { right :.1f } ]" ,
"count" : int (mask.sum()),
"mean_probability" : float (p[mask].mean()),
"positive_rate" : float (y[mask].mean()),
})
return rows
X, y = make_dataset()
train_idx, val_idx, test_idx = stratified_split(y)
X_train, y_train = X[train_idx], y[train_idx]
X_val, y_val = X[val_idx], y[val_idx]
X_test, y_test = X[test_idx], y[test_idx]
mu, sigma = fit_standardizer(X_train)
Xd_train = transform_and_add_intercept(X_train, mu, sigma)
Xd_val = transform_and_add_intercept(X_val, mu, sigma)
Xd_test = transform_and_add_intercept(X_test, mu, sigma)
theta, history = fit_logistic_gd(
Xd_train, y_train, Xd_val, y_val
)
p_val = stable_sigmoid(Xd_val @ theta)
best_val_report = choose_threshold_by_f1(y_val, p_val)
chosen_threshold = best_val_report[ "threshold" ]
p_test = stable_sigmoid(Xd_test @ theta)
test_report = classification_metrics(y_test, p_test, chosen_threshold)
test_log_loss = loss_from_logits(Xd_test @ theta, y_test)
print ( "参数:" , np.round(theta, 4 ))
print ( "验证集选中阈值:" , round (chosen_threshold, 3 ))
print ( "测试集交叉熵:" , round (test_log_loss, 4 ))
print ( "测试集分类指标:" , test_report)
for row in calibration_table(y_test, p_test):
print (row)