用 Octave / MATLAB 把机器学习公式真正跑起来
学机器学习时,我们经常遇到一种落差:纸上已经能写出 、梯度和损失函数,真正打开编程环境,却会卡在“这个向量到底该横着还是竖着”“这里为什么要加一个点”“为什么结果尺寸突然变了”。Octave 和 MATLAB 很适合跨过这道坎,因为它们把矩阵放在语言中心,代码通常和线性代数公式长得很接近。
GNU Octave 是自由软件,MATLAB 是商业产品。两者共享大量基础语法,但并不是完全相同的软件。这一章使用二者都容易运行的核心写法;遇到文件导入、工具箱或较新的界面功能时,我会明确说明差别。即使你最终使用 Python 和 NumPy,这一章也不会白学:形状、广播、向量化、数值稳定性和可复现实验,换一门语言仍然成立。
我们不会把 Octave / MATLAB 当成一台只能临时算题的计算器。目标是走完一条完整路径:先在命令窗口验证小算式,再把实验写成脚本和函数,读入数据、检查形状、训练一个模型、画诊断图,最后保存可以复用的参数。
先建立“数组驱动”的心智模型
Octave / MATLAB 最有用的地方,不是少写几个循环,而是让你直接对一整批数据表达意图。假设 个样本各有 个特征,我们通常把数据排成矩阵:
每一行是一个样本,每一列是一个特征。若参数向量为 ,一次矩阵乘法就能得到全部样本的预测:
这段公式同时告诉了我们三件事:数据怎么摆、乘法为什么合法、结果应该是什么形状。以后看到报错,不要只盯着运算符,先在纸上或注释里写出每个对象的形状。
一份机器学习实验通常会在四个位置之间流动:
好的学习节奏是“小处交互验证,大处脚本复现,核心计算函数化”。比如先在命令窗口确认 X * theta 的尺寸,再把训练流程写进脚本,把损失和梯度写成函数。
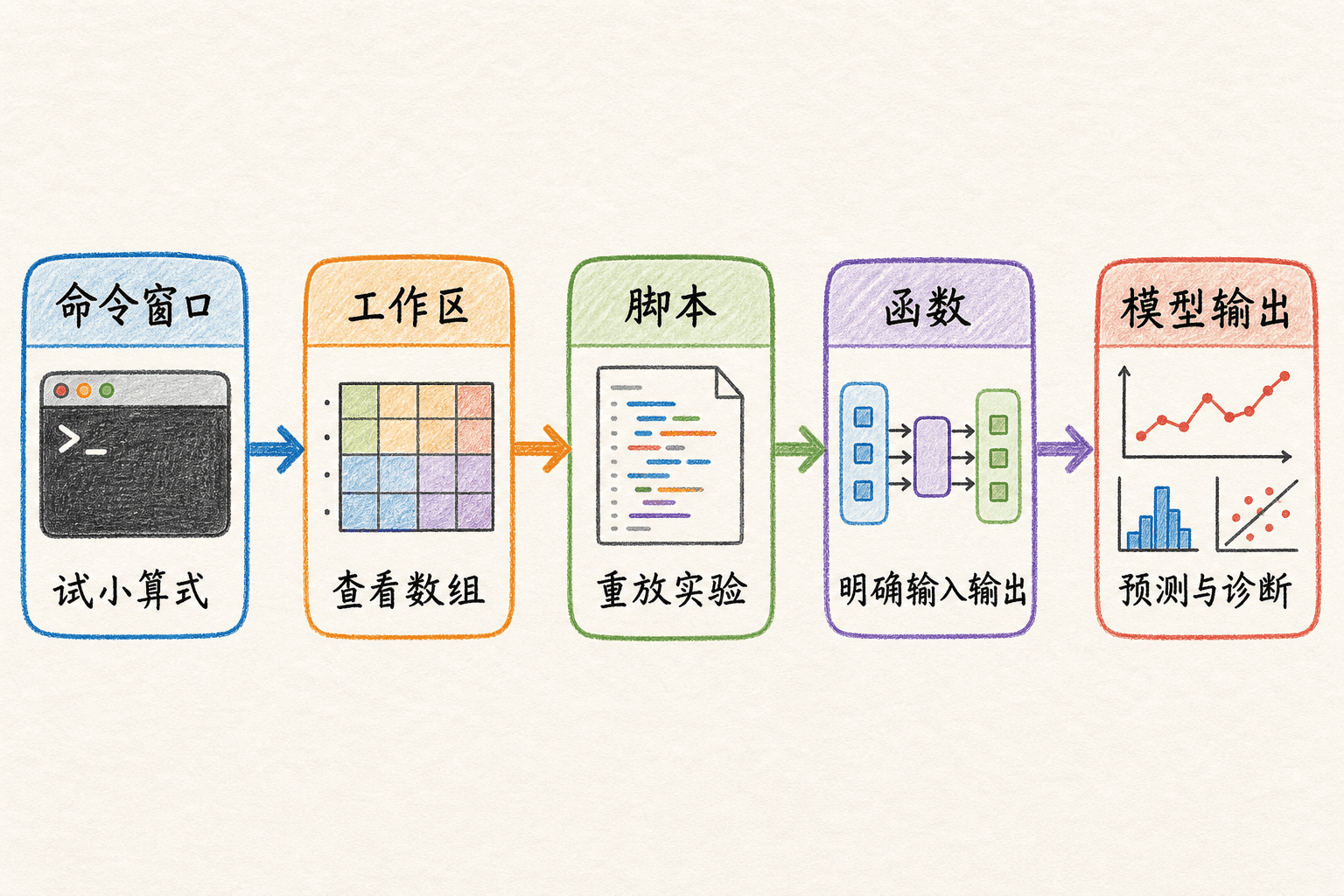
从试小算式到预测与诊断:用数组驱动的实验工作流。
Octave 与 MATLAB 的核心数组语法高度相似,但“相似”不等于任何代码都能无修改运行。课程示例会优先使用共同语法;涉及专用工具箱、表格类型、图形界面或新版本函数时,应分别查看当前软件的帮助页。
1
数据矩阵 X 有 80 行、6 列,参数 theta 是 6×1 列向量。X * theta 的形状是什么?
命令窗口和工作区是实验台,不是仓库
打开 Octave 或 MATLAB 后,可以先把它当成一个能保存变量的计算器:
octave
2 + 3 * 4
radius = 2.5;
area = pi * radius^2;
fprintf('面积 = %.3f\n', area);没有接收输出时,系统常把结果放进 ans。它适合临时查看,不适合写进正式程序,因为下一次未赋值计算就会覆盖它。语句末尾的分号会抑制输出;处理大矩阵时尤其要加,否则命令窗口会被数字刷满。
常用的会话命令如下:
octave
pwd % 当前文件夹
dir % 列出当前文件夹内容
who % 只列变量名
whos % 同时列出形状、字节数和类型
clear theta % 删除指定变量
clear % 删除当前工作区变量
clc % 清理命令窗口显示,不删除变量
close all % 关闭所有图窗
format long g % 改变显示精度,不改变内存中的数值format 只改变“怎么看”,不会改变“存的是什么”。例如 1/3 显示为 0.3333,不代表内部只保留四位小数。遇到看似相等却比较失败的浮点数,应该使用容差,而不是继续增加显示位数。
帮助系统比凭记忆猜函数参数可靠:
octave
help mean
help plot
which mean
lookfor regression % 按描述搜索,结果取决于安装内容which 还能帮助排查“同名文件遮住内置函数”的问题。如果你在当前文件夹放了一个 mean.m,后续调用的可能不再是系统自带的 mean。
不要把变量命名为 sum、mean、plot、size 等常用函数名。变量和函数发生重名时,代码可能报出很绕的错误。已经重名可以先执行 clear sum,再用 which sum 检查解析到哪里。
2
依次执行 a = 3; b = a + 2; clc;,再执行 clear a。下列哪些说法正确?
脚本和函数让实验可以从头再来
当命令超过几行,就应该保存到 .m 文件。脚本像一份可重放的操作清单,在当前工作区执行;函数有自己的局部工作区,通过参数接收输入,通过返回值给出输出。
下面是一份脚本 inspect_data.m:
octave
clear;
clc;
close all;
X = [80 3 5; 95 4 8; 70 2 3; 100 4 10];
y = [168; 196; 149; 205];
fprintf('样本数:%d\n', size(X, 1));
fprintf('特征数:%d\n', size(X, 2));
fprintf('标签数:%d\n', numel(y));在当前文件夹中输入 inspect_data 即可运行。脚本会直接创建或覆盖调用者工作区里的 X 和 y。这对探索方便,却也容易让旧变量影响新实验。核心计算更适合写成函数,例如把标准化放进 standardizeFeatures.m:
octave
function [Xz, mu, sigma] = standardizeFeatures(X)
mu = mean(X, 1);
sigma = std(X, 0, 1);
sigma(sigma == 0) = 1;
Xz = (X - mu) ./ sigma;
end文件名与主函数名保持一致。这里 mu 和 sigma 都是 1×n 行向量,输出 Xz 与 X 同形。把零标准差替换为 1,是为了让常数列标准化后变成 0,而不是除以 0 得到 NaN。
调用时显式接收输出:
octave
[Xz, mu, sigma] = standardizeFeatures(X);一开始可以采用很朴素的项目布局:
text
house-demo/
├── run_experiment.m
├── standardizeFeatures.m
├── fitLinearGD.m
├── data/
│ └── housing.csv
└── output/文件路径用 fullfile 拼接,比手写斜杠更稳妥:
octave
data_file = fullfile('data', 'housing.csv');
assert(exist(data_file, 'file') == 2, '找不到数据文件');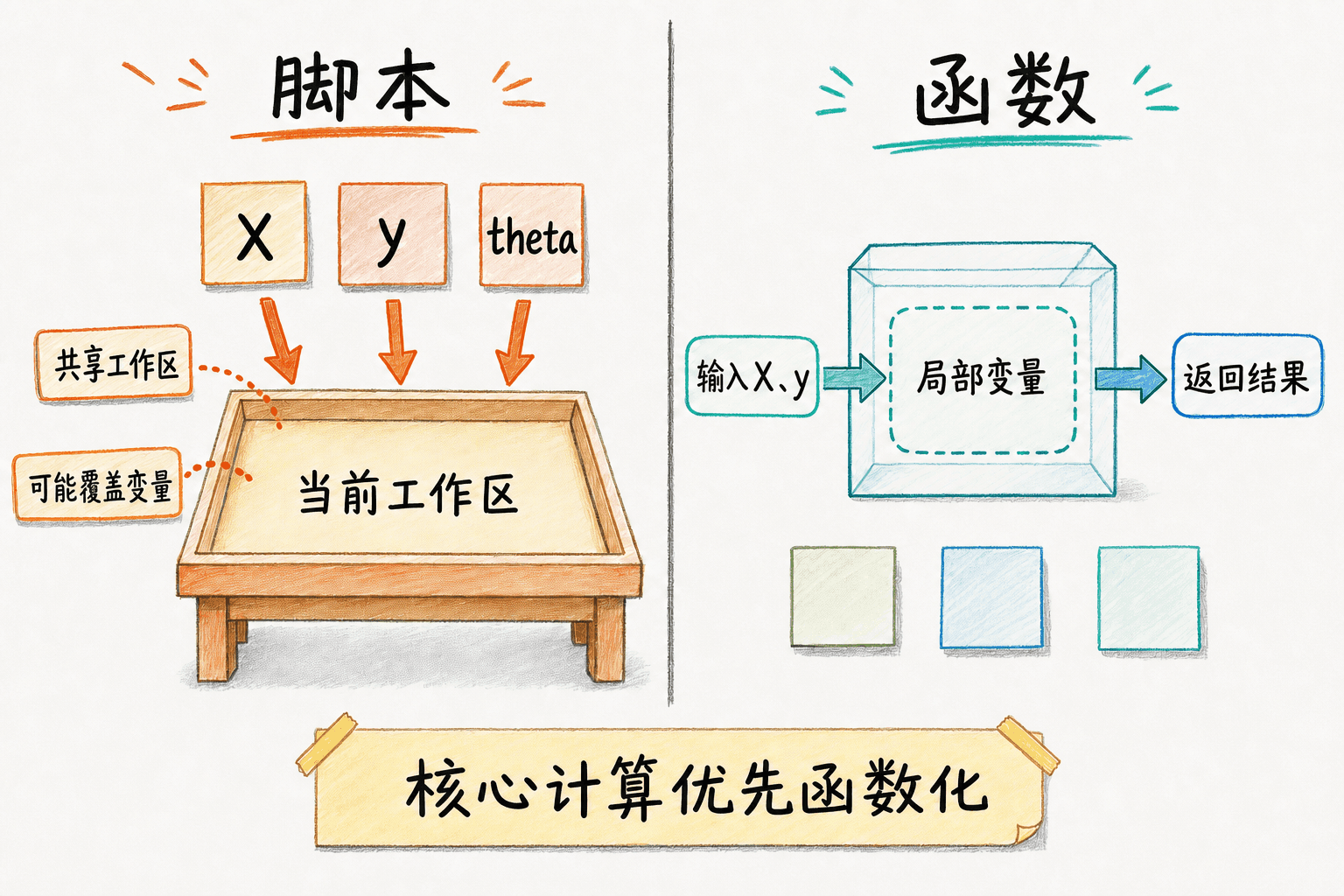
脚本共享当前工作区,函数把局部状态收在边界内;核心计算优先函数化。
3
脚本和函数都会把内部新建的变量直接写入调用者的工作区。
数组、形状和索引决定数据取对了没有
Octave / MATLAB 的数值世界以数组为中心。常见创建方式如下:
octave
A = [1 2 3; 4 5 6]; % 2×3 矩阵
row = [10 20 30]; % 1×3 行向量
col = [10; 20; 30]; % 3×1 列向量
Z = zeros(4, 3);
O = ones(2, 5);
I = eye(3);
u = rand(5, 1);
g = randn(5, 1);
grid = 0:0.25:1;
points = linspace(-2, 2, 9);矩阵用分号换行,空格或逗号分列。索引从 1 开始:
octave
A(2, 3) % 第 2 行第 3 列,结果为 6
A(1, :) % 第 1 行全部列
A(:, 2) % 第 2 列全部行
A(:, 2:end) % 第 2 列到最后一列
A([1 2], [1 3]): 表示该维度上的全部位置,end 表示该维度的最后一个合法索引。切片的两端都包含在结果中,所以 2:4 会取第 2、3、4 个位置。
逻辑索引适合按条件筛数据:
octave
prices = [168; 196; 149; 205];
large = A > 3;
A(large) % 取出所有大于 3 的元素
expensive = prices >= 180;
prices(expensive)单下标按“先沿列向下,再移到下一列”的顺序访问数组,这叫列优先线性索引:
octave
A = [1 2 3; 4 5 6];
A(3) % 结果是 2,不是 3
A(:) % 得到 [1; 4; 2; 5; 3; 6]修改和拼接也使用索引:
octave
A(2, 1) = 40;
A(:, 2) = []; % 删除第 2 列
B = [A, ones(size(A, 1), 1)];
C = [A; A];最容易被滥用的函数是 length。它返回最大维度的长度,对矩阵并不等于样本数。机器学习代码应明确写 size(X, 1)、size(X, 2) 或 numel(y):
octave
[m, n] = size(X);
assert(size(y, 1) == m, 'X 和 y 的样本数不一致');
assert(size(y, 2) == 1, 'y 应为列向量');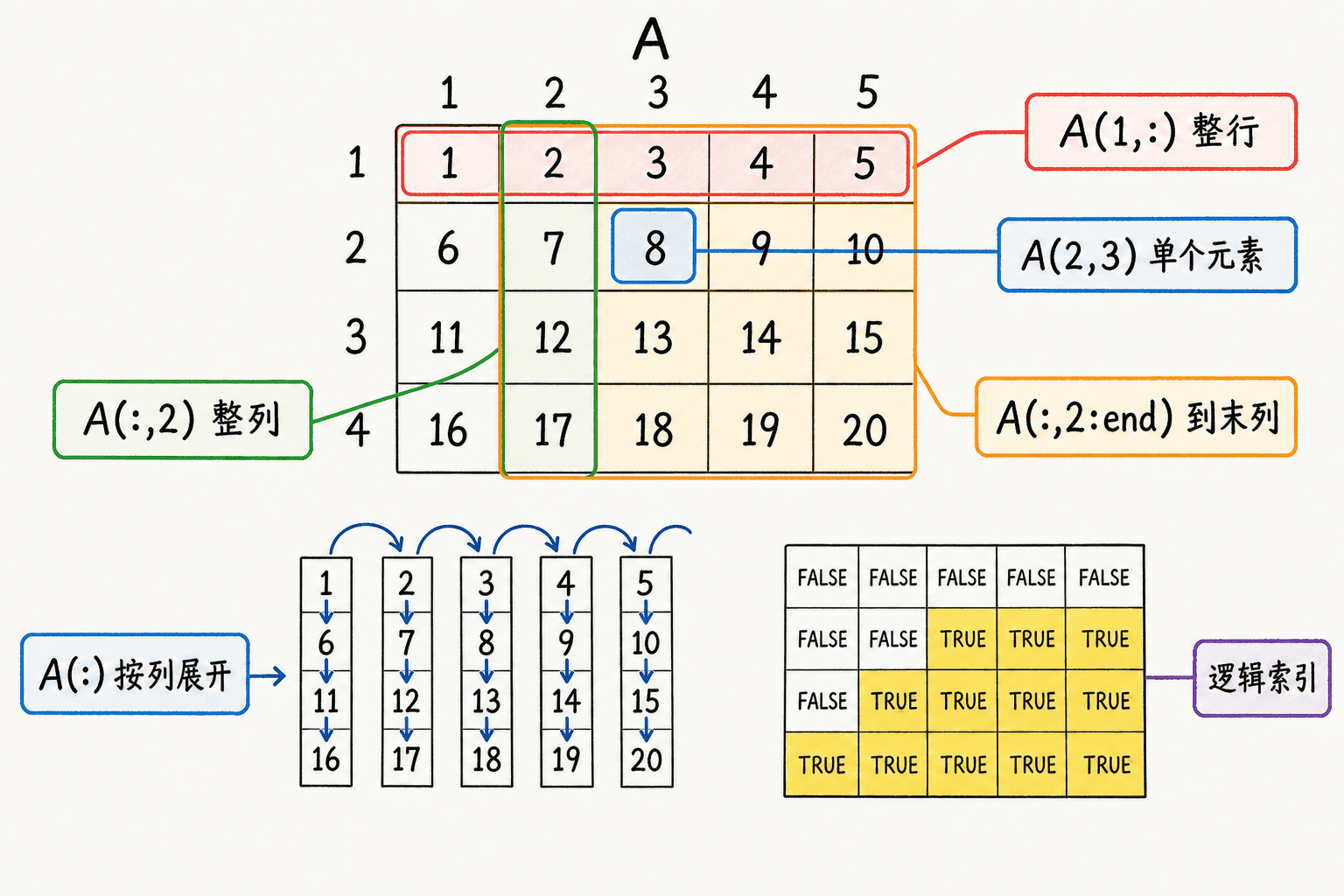
数组索引从 1 开始;冒号选取行列,逻辑掩码按条件筛选元素。
你可以用下面的交互实验切换矩阵形状和索引方式,观察行列索引、逻辑掩码与线性索引各自返回什么。
4
对于一个 100×4 的数据矩阵 X,下列哪些表达式会保留 100 个样本?
矩阵运算和逐元素运算必须分清
Octave / MATLAB 同时服务线性代数和数组计算,因此同一类符号常有两套版本。点号不是装饰,它是在声明“每个位置分别计算”。
看一个最小例子:
octave
A = [1 2; 3 4];
B = [5 6; 7 8];
C_matrix = A * B;
C_element = A .* B;
sq_element = A .^ 2;A * B 的左上角是 ;A .* B 的左上角只是 。机器学习里的批量线性预测用 X * theta,均方误差里的逐项平方用 errors .^ 2。
转置也有一个容易忽略的细节:
octave
A' % 共轭转置
A.' % 只交换维度,不做复共轭实数数据中二者结果相同;复数数据中不同。普通实数机器学习代码常见 X' * errors,但写数值库时要知道 ' 的完整含义。
求解 时,优先使用左除:
octave
x = A \ b;它表达的是“解这个线性系统”,不必先显式计算逆矩阵。对合适的非方阵,左除也可计算最小二乘解。下面这种写法通常更慢、数值误差也可能更大:
octave
x_bad = inv(A) * b;pinv 有自己的用途,例如明确需要 Moore–Penrose 伪逆或研究最小范数解,但不应看到非方阵就机械调用。先问清楚问题是在解方程、做最小二乘,还是确实需要伪逆。
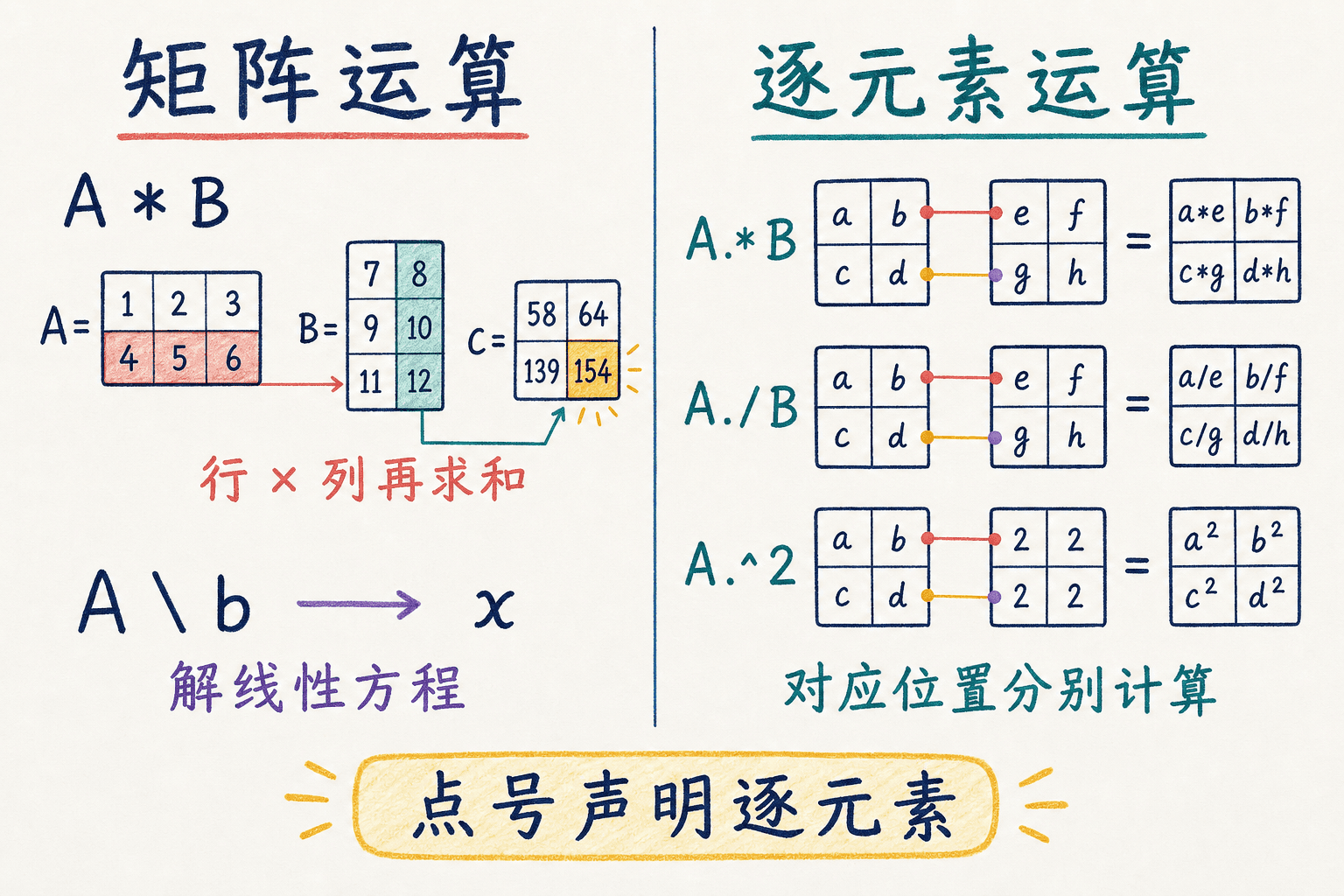
矩阵运算按行与列组合;点号运算符声明逐元素计算。
5
要对矩阵 Z 的每个元素计算 sigmoid:1 / (1 + exp(-z)),应写成 g = 1 ____ (1 + exp(-Z))。
广播和向量化把一批样本一起算完
广播解决的是“形状不完全相同,但某些维度可以重复使用”的问题。基础规则很简单:对应维度要么相等,要么其中一个为 1。
例如 X 是 m×n,每列均值 mu 是 1×n。执行 X - mu 时,mu 会沿样本轴重复使用,相当于每一行都减去同一组特征均值:
octave
mu = mean(X, 1);
sigma = std(X, 0, 1);
sigma(sigma == 0) = 1;
Xz = (X - mu) ./ sigma;这里没有真的要求我们手工构造一个 m×n 的均值矩阵。较老的 MATLAB 版本没有现代隐式扩展时,可以使用 bsxfun;当前 Octave 和较新的 MATLAB 通常支持上面的写法。
向量化是把逐元素或逐样本循环,改写成数组运算。线性回归预测就是最典型的例子:
octave
% 循环写法
m = size(X, 1);
pred_loop = zeros(m, 1);
for i = 1:m
pred_loop(i) = X(i, :) * theta;
end
% 向量化写法
pred = X * theta;均方误差和梯度也能直接写成:
octave
errors = X * theta - y;
J = (errors' * errors) / (2 * m);
gradient = (X' * errors) / m;向量化不等于“代码里绝不能出现循环”。梯度下降仍然需要迭代;某些分支逻辑也更适合循环。应优先消掉的是样本级、特征级的重复标量计算:
octave
J_history = zeros(num_iters, 1); % 先分配,避免反复扩容
for iter = 1:num_iters
errors = X * theta - y;
gradient = (X' * errors) / m;
theta = theta - alpha * gradient;
J_history(iter) = (errors' * errors) / (2 * m);
end广播也可能制造巨大的中间数组。若一个表达式会把两个十万行向量扩展成十万乘十万矩阵,语法虽然合法,内存却承受不了。先估算结果形状,再决定是否广播、分块或使用更直接的矩阵乘法。
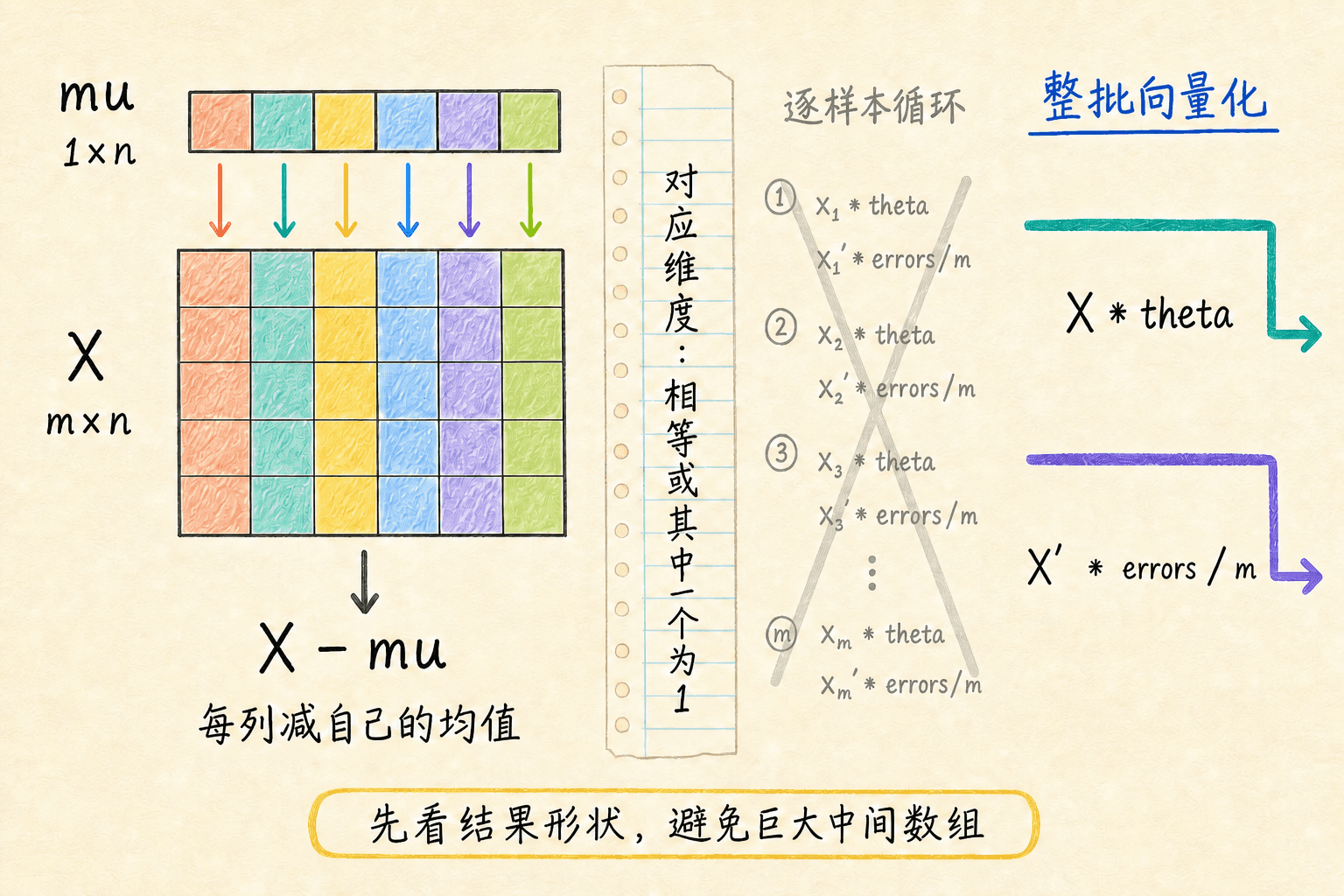
广播要求对应维度相等或其中一个为 1;向量化前仍要先判断结果形状。
下面的运算实验会同时显示输入形状、广播后的逻辑形状和结果,帮助你区分 *、.*、./ 与隐式扩展。
6
X 是 200×5,mu 是 1×5。表达式 X - mu 的含义是什么?
文件读写要同时保护数据和实验状态
真实实验不会把所有数据手写在代码里。读文件后第一件事也不该是训练,而是确认路径、形状、缺失值和列含义。
若 CSV 第一行是表头,其余内容全是数值,可以用两边都常见的 dlmread:
octave
data_file = fullfile('data', 'housing.csv');
assert(exist(data_file, 'file') == 2, '数据文件不存在');
raw = dlmread(data_file, ',', 1, 0); % 跳过一行表头
assert(size(raw, 2) == 4, '预期 3 列特征和 1 列标签');
assert(all(isfinite(raw(:))), '数据含 NaN 或 Inf');
X = raw(:, 1:3);
y = raw(:, 4);现代 MATLAB 更推荐 readmatrix、readtable 等导入函数;Octave 可根据文件复杂度使用 importdata、textscan 或相关扩展包。CSV 混有文字、日期、引号和缺失标记时,不要强行把它当纯数值矩阵读入。无论使用哪个函数,都应在导入后验证结构。
划分训练集和验证集时固定随机种子,才能复现实验:
octave
rng(42);
m = size(X, 1);
order = randperm(m);
n_train = floor(0.8 * m);
train_idx = order(1:n_train);
val_idx = order(n_train + 1:end);
X_train = X(train_idx, :);
y_train = y(train_idx, :);
X_val = X(val_idx, :);
y_val = y(val_idx, :);均值和标准差只能从训练集计算,再应用到验证集:
octave
[X_train_z, mu, sigma] = standardizeFeatures(X_train);
X_val_z = (X_val - mu) ./ sigma;如果把验证集也拿来计算 mu 和 sigma,就让训练流程提前看到了验证集信息,形成数据泄漏。
实验参数适合保存为 MAT 文件:
octave
save(fullfile('output', 'house_model.mat'), ...
'theta', 'mu', 'sigma');
model = load(fullfile('output', 'house_model.mat'));
pred = [ones(size(X_val, 1), 1), ...
(X_val - model.mu) ./ model.sigma] * model.theta;用返回值接住 load 会得到结构体,访问时写 model.theta。这比把文件中所有变量直接倒进工作区更安全,因为它不会悄悄覆盖已有同名变量。
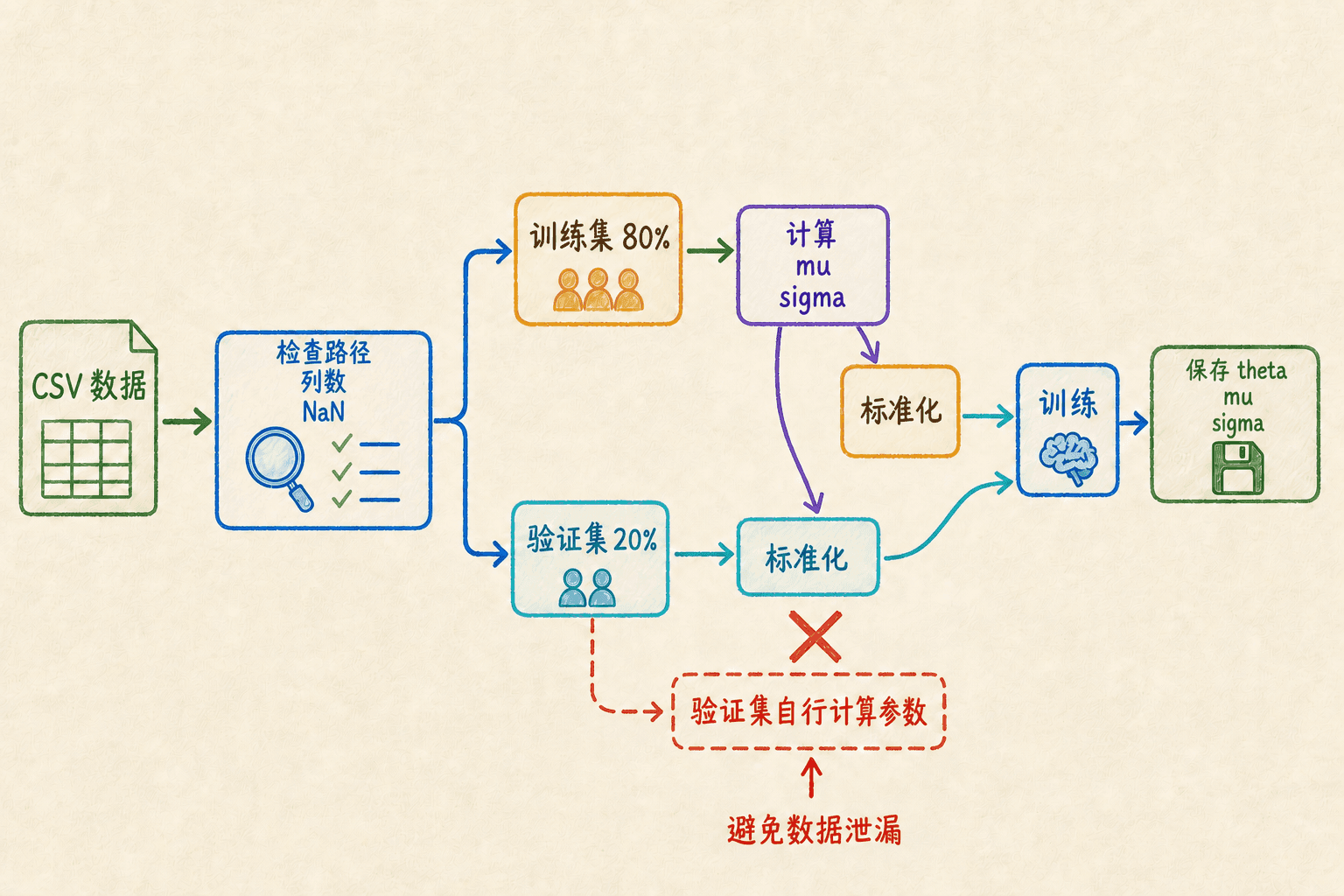
标准化参数只由训练集计算,再复用于验证集;theta、mu、sigma 应随模型一起保存。
7
为了让验证集标准化得更准确,可以分别用训练集和验证集各自的均值、标准差进行标准化。
绘图不是美化结果,而是检查模型
一个损失数字很难告诉你模型错在哪里。至少画三类图:原始关系、训练过程、预测残差。
先看单个特征与标签:
octave
figure('Color', 'w');
scatter(X(:, 1), y, 36, 'filled');
xlabel('面积');
ylabel('价格');
title('面积与价格');
grid on;训练时画损失曲线:
octave
figure('Color', 'w');
plot(1:numel(J_history), J_history, 'LineWidth', 1.8);
xlabel('迭代次数');
ylabel('训练损失 J');
title('梯度下降轨迹');
grid on;损失持续下降说明当前学习率至少没有立刻发散;剧烈振荡或快速变成 Inf / NaN,通常要先降低学习率并检查数据尺度。损失下降也不保证泛化良好,还要看验证集。
预测—真实值图和残差图能暴露更多问题:
octave
pred = X_design * theta;
residual = pred - y;
lims = [min([y; pred]), max([y; pred])];
figure('Color', 'w');
subplot(1, 2, 1);
scatter(y, pred, 30, 'filled');
hold on;
plot(lims, lims, 'k--', 'LineWidth', 1.2);
xlabel('真实值');
ylabel('预测值');
title('预测与真实值');
grid on;
subplot(1, 2, 2);
scatter(pred, residual, 30, 'filled');
hold on;
plot(lims, [0 0], 'k--', 'LineWidth', 1.2);
xlabel('预测值');
ylabel('残差');
title('残差诊断');
grid on;
print(gcf, fullfile('output', 'diagnostics.png'), '-dpng', '-r150');理想残差不会随预测值呈明显弧线或漏斗形。弧线可能提示线性关系不足;漏斗形常说明误差波动随预测尺度改变;少数远离主体的点值得回到原始数据检查。
画图前先确认横纵轴对应的变量和单位。图形函数能忠实画出错误数据;轴写反、训练集和验证集混用、单位不一致,都可能产生“看起来很合理”的假象。
8
训练损失突然变为 NaN 时,哪些检查最直接?
控制流和函数句柄处理真正需要变化的部分
向量化适合批量数值运算,控制流适合“下一步取决于当前状态”的逻辑。Octave / MATLAB 的常用写法是:
octave
if alpha <= 0
error('alpha 必须为正数');
elseif alpha > 1
warning('alpha 可能过大');
else
fprintf('alpha = %.4g\n', alpha);
end
for iter = 1:num_iters
% 迭代更新
end
while change > tolerance
% 满足停止条件前继续
endif 应接收一个明确的标量逻辑值。若 mask 是逻辑向量,要说清楚你想判断“全部成立”还是“至少一个成立”:
octave
if all(isfinite(theta))
disp('参数都是有限数');
end
if any(abs(theta) > 1e6)
warning('参数绝对值过大');
end&& 和 || 用于标量条件并具有短路行为;& 和 | 对数组逐元素运算。不要依赖软件对非标量 if 条件的特殊处理,否则代码在不同环境里可能表现不同。
函数句柄让“函数也能当作数据传递”。@mean 指向已有函数,@(x) ... 创建匿名函数:
octave
square = @(x) x .^ 2;
square([-2 -1 0 1 2])
loss_fn = @(theta) mean((X * theta - y) .^ 2) / 2;
J0 = loss_fn(zeros(size(X, 2), 1));优化器、积分器和绘图工具经常接收函数句柄。例如用无约束搜索演示“把损失交给优化器”:
octave
theta0 = zeros(size(X, 2), 1);
theta_opt = fminsearch(loss_fn, theta0);匿名函数适合短小表达式。若要做参数验证、保存多个中间量或写多段逻辑,应改成有名字的函数文件,便于断点调试和测试。
9
theta 是参数向量。若只要有一个参数不是有限数就立即报错,if 应使用哪个条件?
数值调试要沿着数据流逐站检查
机器学习代码最常见的错误可以分成三类:形状不对、数值不有限、问题本身病态。最有效的排错方式不是盯着最后一行,而是沿数据流检查每个边界。
先确认原始输入。打印 size、class、最小值和最大值,检查标签是否为列向量、样本是否一一对应。
再确认关键运算前后的形状。把 X * theta、errors、gradient 的预期形状写成注释,并用 assert 固定下来。
接着查找 NaN 和 Inf 第一次出现的位置。重点检查除以零、对非正数取对数、指数溢出和过大的参数更新。
把不变量写进程序,比每次手工查看更可靠:
octave
assert(isnumeric(X), 'X 必须是数值数组');
assert(size(X, 1) == size(y, 1), '样本数不一致');
assert(size(y, 2) == 1, 'y 必须是列向量');
assert(all(isfinite(X(:))), 'X 含 NaN 或 Inf');
assert(all(isfinite(y(:))), 'y 含 NaN 或 Inf');
pred = X * theta;
assert(isequal(size(pred), size(y)), '预测和标签形状不一致');比较浮点结果要使用容差:
octave
actual = 0.1 + 0.2;
expected = 0.3;
assert(abs(actual - expected) < 1e-12);对线性系统或设计矩阵,可以用条件数作为预警信号:
octave
kappa = cond(X);
fprintf('cond(X) = %.3e\n', kappa);条件数很大不等于程序一定错误,它表示输入中的小扰动可能被解放大。此时可以检查特征尺度、重复或近似重复的列,考虑更稳定的求解器、正则化或重新设计特征。不要简单地“多保留几位小数”来解决病态问题。
Octave 的命令行调试器支持 dbstop、dbstep、dbcont、dbstack 和 dbquit。一个实用起点是:
octave
dbstop if error也可以在函数指定行设置断点,再在暂停状态查看局部变量。MATLAB 编辑器提供相同思路的断点与调用栈界面;具体命令和可用事件随版本略有差别。
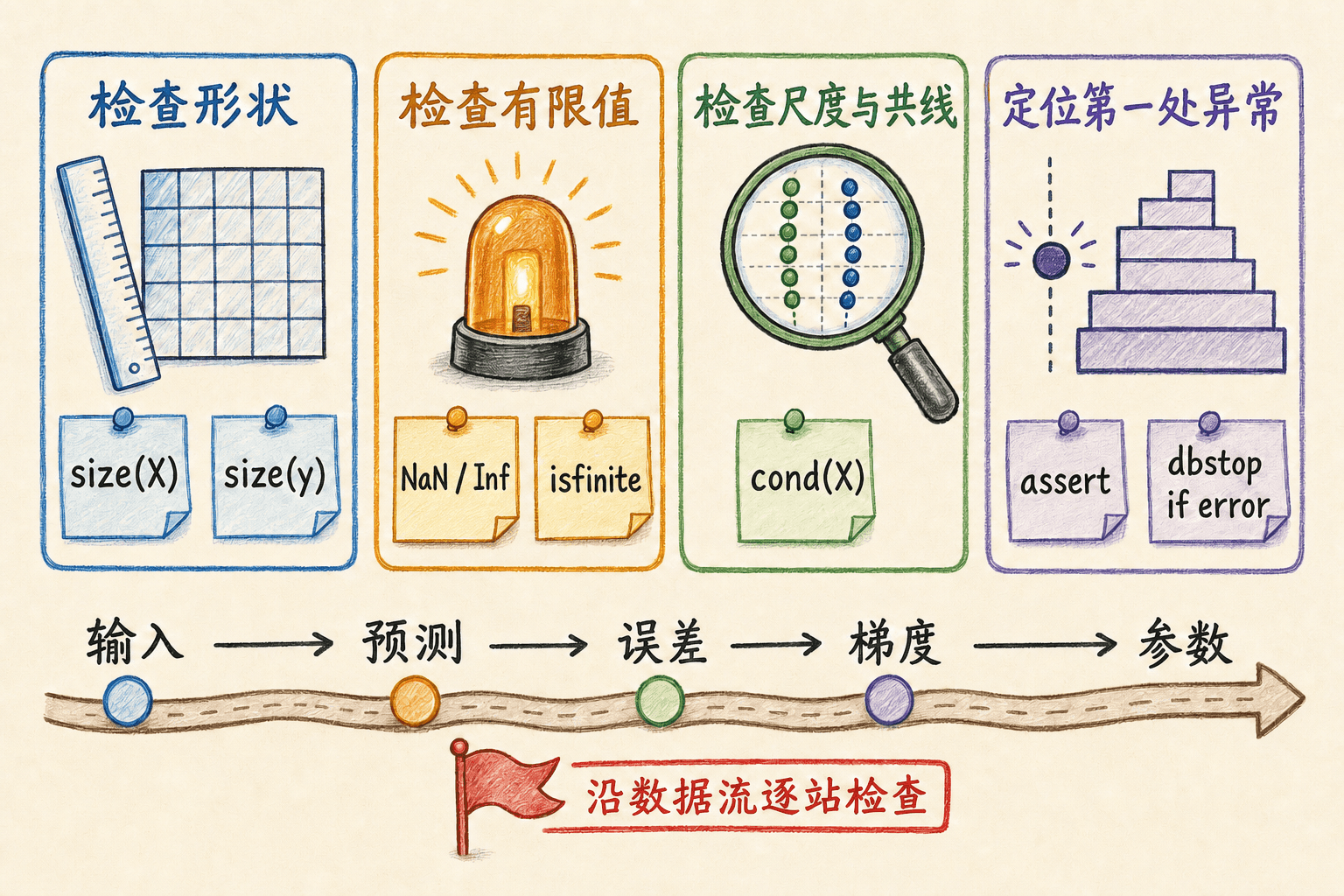
沿“输入 → 预测 → 误差 → 梯度 → 参数”的数据流逐站检查数值异常。
下面的调试实验允许你改变学习率、特征尺度和共线程度,观察损失曲线、条件数以及 NaN 出现的位置。
10
代码能运行,但 theta 对数据的微小改动非常敏感。下一步最有针对性的检查是什么?
从 Octave / MATLAB 切换到 NumPy 时别逐字符翻译
三者都能做数组计算,但默认约定不同。迁移代码时应翻译“数学意图”,而不是只替换括号和运算符。
还要留意五个概念差别。
一维数组没有自动的行列方向
Octave / MATLAB 的 [1 2 3] 是 1×3,[1;2;3] 是 3×1。NumPy 的 np.array([1,2,3]) 形状是 (3,),对它做 .T 仍是 (3,)。需要二维列向量时要写 v[:, None] 或 v.reshape(-1, 1)。
乘号的默认含义相反
在 Octave / MATLAB 中,* 优先表达线性代数矩阵乘法;NumPy 的 * 是逐元素乘,矩阵乘法使用 @。这是迁移模型代码时最危险的静默差异之一,因为某些形状下两种写法都能运行,却算的是不同问题。
索引起点和切片终点不同
Octave / MATLAB 从 1 开始,区间终点包含在内;Python 从 0 开始,切片终点不包含在内。A(2:4,:) 对应 A[1:4,:]。
广播要看具体形状
Octave / MATLAB 中行向量和列向量方向明确。NumPy 广播从尾部维度对齐,(n,) 很容易和 (m,n) 对齐,但 (m,) 通常不能直接按行加到 (m,n),需要变成 (m,1)。
切片是否共享数据不同
Octave / MATLAB 的普通数组表现为值语义,并在内部做写时复制优化。NumPy 很多切片返回视图,修改切片可能同时改动原数组;需要独立副本时显式调用 .copy()。
NumPy 还会根据输入推断数据类型:纯整数列表常得到整数数组;Octave / MATLAB 的普通数值字面量通常是双精度。涉及除法、存储和模型精度时,要检查 dtype 或 class,不要凭外观判断。
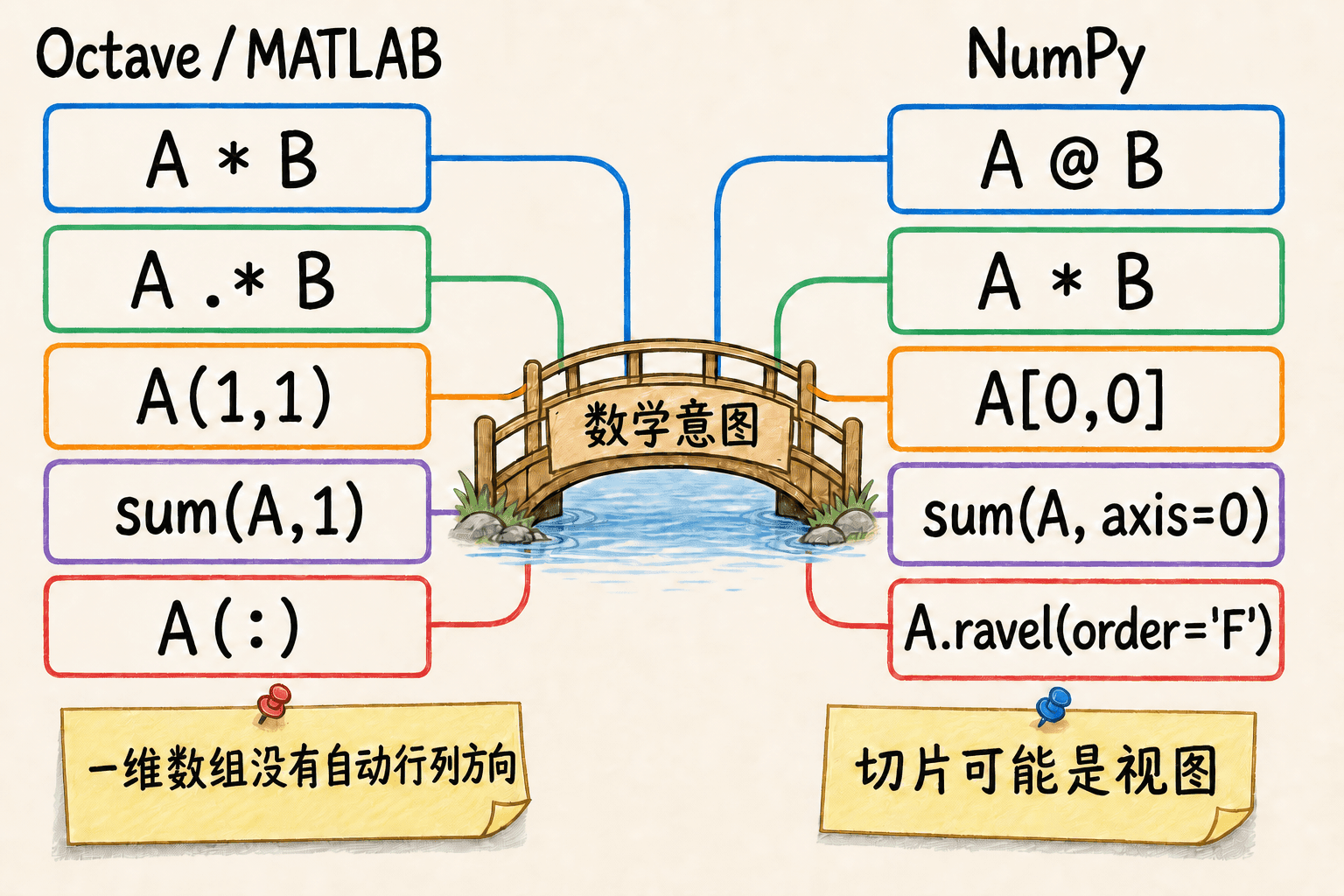
跨过“数学意图”之桥,对照矩阵运算、索引、求和与展平写法。
11
把 Octave 代码 pred = X * theta 迁移到 NumPy 时,哪些写法或检查是正确的?
用一个小项目串起完整实验
最后把前面的知识放进一个可运行的线性回归小项目。为避免依赖外部文件,演示脚本先生成带噪声的房价数据;把生成部分替换为前面的 CSV 导入代码,就能处理自己的数据。
先创建 fitLinearGD.m:
octave
function [theta, J_history] = fitLinearGD(X, y, alpha, num_iters)
assert(size(X, 1) == size(y, 1), 'X 和 y 的样本数不一致');
assert(size(y, 2) == 1, 'y 必须是列向量');
assert(alpha > 0, 'alpha 必须为正数');
assert(num_iters >= 1, 'num_iters 必须至少为 1');
assert(all(isfinite(X(:))) && all(isfinite(y(:))), ...
'输入含 NaN 或 Inf');
m = size(X, 1);
theta = zeros(size(X, 2), 1);
J_history = zeros(num_iters, 1);
for iter = 1:num_iters
errors = X * theta - y;
gradient = (X' * errors) / m;
theta = theta - alpha * gradient;
new_errors = X * theta - y;
J_history(iter) = (new_errors' * new_errors) / (2 * m);
if ~isfinite(J_history(iter))
error('第 %d 次迭代出现非有限损失', iter);
end
end
end这里在更新参数后重新计算损失,让 J_history(iter) 与当前 theta 对应。对于大型数据集,可以权衡额外计算成本;教学和调试阶段,清楚的一致性更重要。
standardizeFeatures.m 使用前面已经给出的函数。然后创建主脚本 run_house_demo.m:
octave
clear;
clc;
close all;
rng(42);
% 生成数据:面积、卧室数、房龄
m = 160;
area = 45 + 110 * rand(m, 1);
rooms = randi([1, 5], m, 1);
age = 30 * rand(m, 1);
X = [area, rooms, age];
noise = 8 * randn(m, 1);
y = 35 + 1.25 * area + 7 * rooms - 0.8 * age + noise;
% 固定随机划分
order = randperm(m);
n_train = floor(0.8 * m);
train_idx = order(1:n_train);
val_idx = order(n_train + 1:end);
X_train = X(train_idx, :);
y_train = y(train_idx);
X_val = X(val_idx, :);
y_val = y(val_idx);
% 只用训练集估计标准化参数
[X_train_z, mu, sigma] = standardizeFeatures(X_train);
X_val_z = (X_val - mu) ./ sigma;
% 添加截距列
X_train_d = [ones(size(X_train_z, 1), 1), X_train_z];
X_val_d = [ones(size(X_val_z, 1), 1), X_val_z];
% 训练与验证
alpha = 0.08;
num_iters = 500;
[theta, J_history] = fitLinearGD( ...
X_train_d, y_train, alpha, num_iters);
pred_val = X_val_d * theta;
rmse_val = sqrt(mean((pred_val - y_val) .^ 2));
fprintf('验证集 RMSE = %.3f\n', rmse_val);
% 基线:总是预测训练集均值
baseline = mean(y_train) * ones(size(y_val));
rmse_baseline = sqrt(mean((baseline - y_val) .^ 2));
fprintf('均值基线 RMSE = %.3f\n', rmse_baseline);
运行后,不要只看“程序是否结束”,还要做一次实验验收:
J_history是否下降并趋于平稳;- 验证集 RMSE 是否明显好于均值基线;
- 散点是否大致围绕对角线,而不是出现系统弯曲;
theta、mu、sigma是否一起保存;- 换一个随机种子后,结论是否仍大致成立。
一份可复现的机器学习程序,不只保存最后的 theta。任何预测时仍会用到的预处理参数、特征顺序和输入约定,都属于模型的一部分。少保存一个 sigma,就可能让完全正确的参数产生错误预测。
12
已加载 model.theta、model.mu 和 model.sigma,新样本 x_new 应是包含面积、卧室数和房龄的单行数组。下列哪些做法正确?