神经网络学习:把预测程序变成可训练系统
上一章解决的是“给定参数,网络怎样从输入算出预测”。这一章要解决更难也更实用的问题:预测错了以后,怎样知道每一个参数该往哪里改、改多少,以及怎样确认这套训练程序真的写对了。
初学者最容易把三个动作揉成一句“反向传播训练网络”。其实它们分工很清楚:前向传播计算预测与损失;反向传播计算损失对参数的梯度;优化器读取梯度,再更新参数。反向传播本身不会偷偷修改任何权重,优化器也不会替我们推导梯度。把这条边界记牢,后面的公式和代码会顺很多。
本章使用一个全连接分类网络贯穿讲解。我们会从计算图和链式法则出发,逐层推导批量反向传播,再处理稳定 Softmax、梯度检查、Xavier/He 初始化、梯度消失与爆炸、mini-batch 训练、正则化和训练/评估模式。最后会把这些零件装成一份可运行的 NumPy 小网络,并给出一套定位训练故障的顺序。
本章把批量大小记为 ,输入维度记为 ,隐藏单元数记为 ,类别数记为 。权重与偏置分开写,不再把偏置塞进一列恒为 的特征,这更接近现代深度学习框架的接口。
一次训练步骤里其实有三件事
先看最小的可训练单元。假设输入是 ,参数是 ,神经元先做线性变换,再经过 ReLU,最后用平方损失衡量预测与目标 的距离:
这三行已经构成一张计算图。前向传播从上到下代入数值,得到 、 和标量损失 。之所以强调“标量”,是因为训练通常需要把一批样本的误差汇总成一个目标,才方便讨论某个参数变化时目标怎样变化。
反向传播从 出发,沿计算图反方向应用链式法则。它最终给出:
若 ,那么 ,于是梯度是 ;若 ,ReLU 的局部梯度为 ,这条路径上的梯度也变成 。到这一步,参数还没有变化,我们只是算出了“如果轻微改变 ,损失会怎样变化”。
最后才轮到优化器。最朴素的梯度下降按学习率 更新参数:
负号来自下降方向:梯度指向局部上升最快的方向,所以要反着走。学习率控制步幅,而不是改变梯度本身。
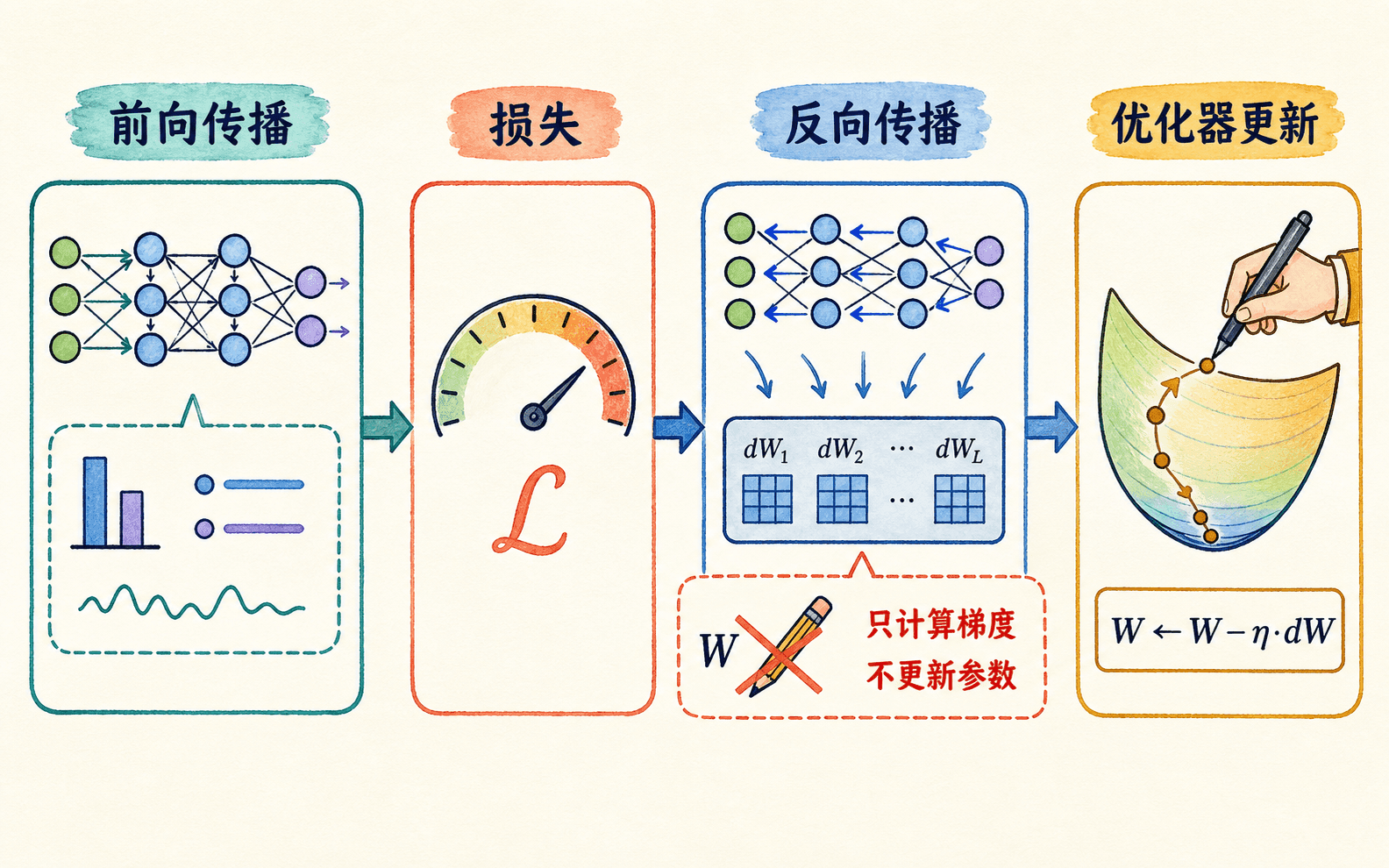
反向传播负责计算梯度,优化器才负责修改参数。
“调用 backward”与“调用 optimizer.step”是两件事。前者把梯度写入参数对应的梯度缓冲区,后者才依据这些梯度修改参数。调试时把两步分开观察,通常比盯着最终准确率更容易找到问题。
1
在一次标准训练步骤中,哪项描述最准确?
多分类输出要把 Softmax 和交叉熵一起看
一个 类分类网络的最后一层通常输出 个实数,记为 logits:
logit 不是概率,可以为负,也不要求总和为 。Softmax 把它们变成同一组类别上的概率分布:
每个 都在 到 之间,并且 。这意味着类别之间相互竞争:提高某一类的 logit,不只提高它自己的概率,也会通过分母压低其他类别的概率。
如果真实类别用 one-hot 向量 表示,单个样本的交叉熵是:
因为 one-hot 向量只有真实类别 的位置为 ,上式等价于:
预测给真实类别的概率越接近 ,损失越接近 ;若真实类别概率很小,负对数会给出较大的惩罚。实际框架通常允许直接传类别索引,不需要手工生成 one-hot 矩阵。
为什么要减去最大 logit
直接计算 有数值风险。浮点数能够表示的范围有限,logit 稍大时指数会溢出,稍小时又可能下溢到 。Softmax 有一个不改变结果的性质:所有 logit 同时减去任意常数 ,概率不变。
取 后,最大的指数变成 ,其余指数不超过 。这就是稳定 Softmax 的核心。
python
import numpy as np
def log_softmax(logits):
shifted = logits - np.max(logits, axis=1, keepdims=True)
log_sum_exp = np.log(np.sum(np.exp(shifted), axis=1, keepdims=True))
return shifted - log_sum_exp
def cross_entropy_from_logits(logits, labels):
log_probs = log_softmax(logits)
代码直接在 log 概率上取真实类别,而不是先算概率、再对可能已经下溢成 的数取对数。成熟框架里的交叉熵接口也通常接收原始 logits,并在内部融合 log_softmax 与负对数似然。
Softmax 与交叉熵配对后,输出层对 logits 的梯度会化简为一个很干净的结果:
它不是“凭经验写出来的误差项”,而是 Softmax 的导数与交叉熵的导数相乘后抵消得到的。这个化简既减少计算,也避免显式构造 的 Softmax 雅可比矩阵。
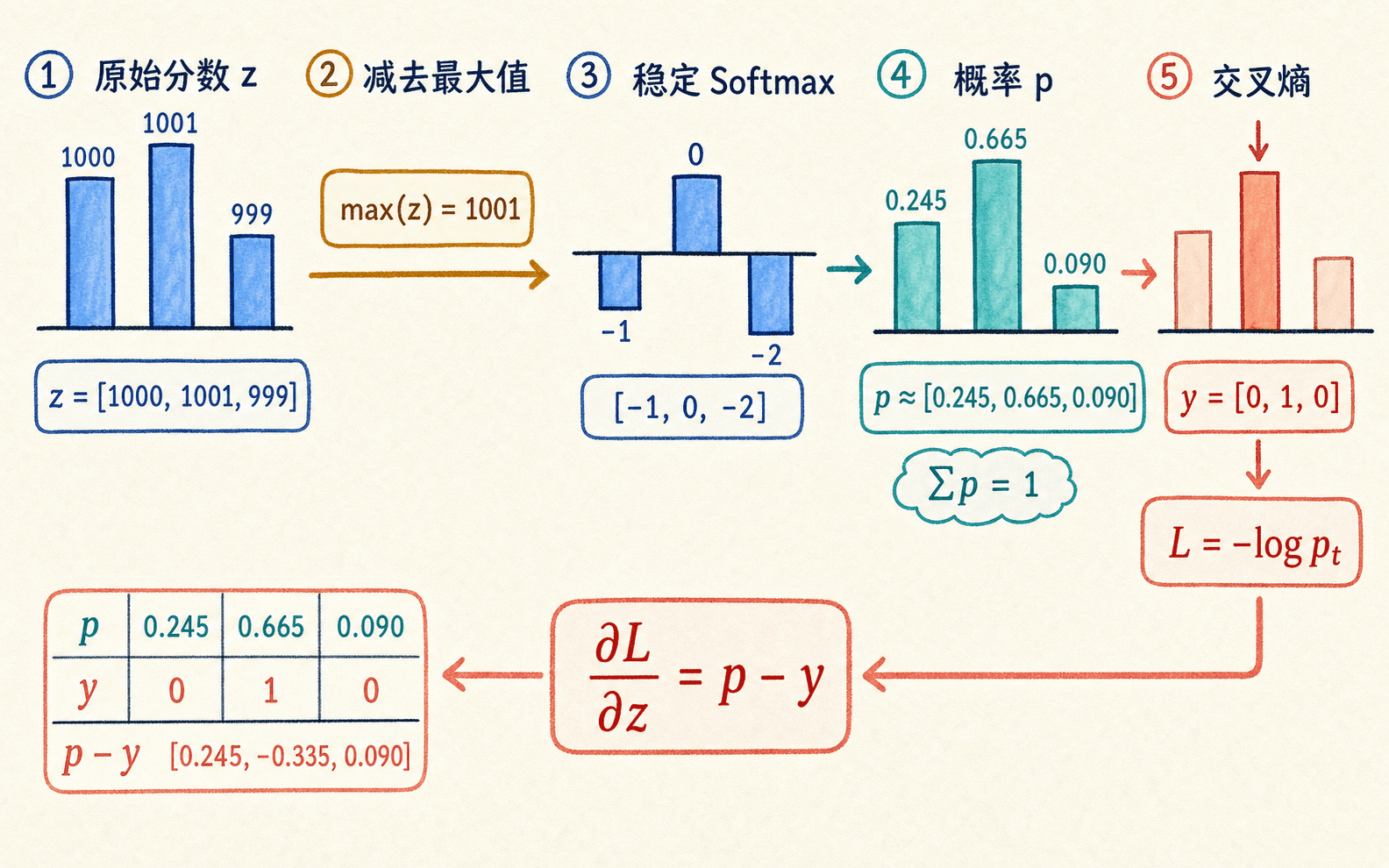
先整体平移 logits,不改变概率,却能换来数值安全。
2
某个样本的 logits 是 [1000, 1001, 999]。稳定 Softmax 最合适的第一步是什么?
链式法则在计算图里只做局部记账
复杂网络的公式看起来很长,但反向传播并不需要某个节点理解整张网络。每个运算只做两件事:前向时根据输入算输出,反向时把上游梯度乘上自己的局部梯度,再传给输入。
把某个节点写成 ,最终损失写成 ,那么传回 的梯度是:
是从后续节点传来的上游梯度, 是当前运算自己能算出的局部梯度。两者相乘,就是当前节点要继续向前传递的梯度。
几个常见运算可以形成很实用的直觉:
- 加法 会把上游梯度原样分给两个输入,因为两个局部梯度都是 。
- 乘法 会把上游梯度乘以“另一个输入”,因为 。
分叉路径的梯度要相加
若同一个变量 同时流向两个分支 、,最终损失同时依赖两个分支,那么:
这解释了为什么自动微分框架里的梯度默认会累积。一个参数可能在计算图中被使用多次,每条使用路径都对总损失有贡献,最终必须把贡献相加。训练循环里清空梯度,是为了避免把“上一个 mini-batch 的路径贡献”也混进当前批次,而不是因为链式法则要求每次只能保留一条路径。
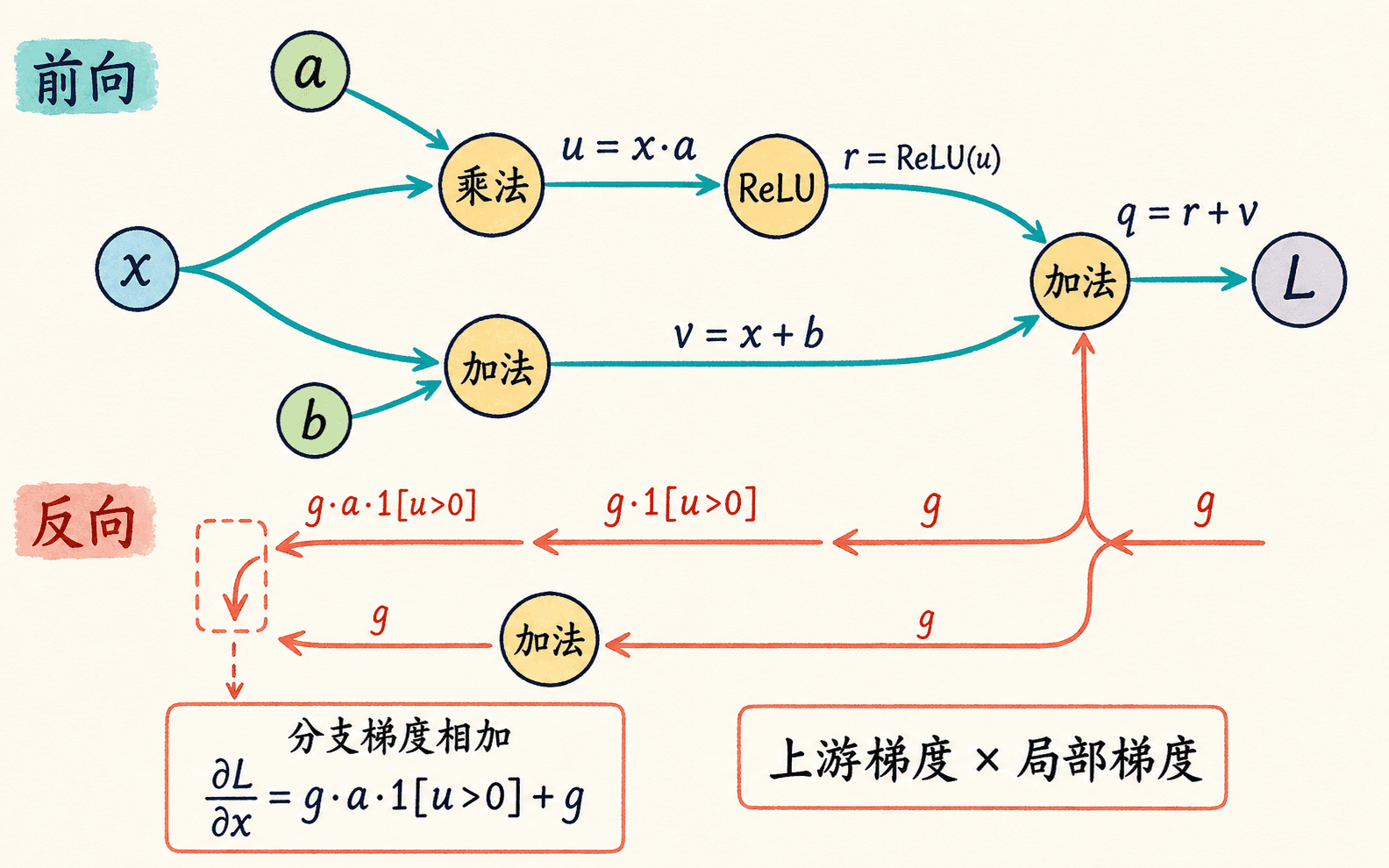
每个节点只处理上游梯度与局部导数,分叉贡献在汇合处相加。
3
关于计算图中的反向传播,下列哪些说法正确?
单隐藏层网络的反向传播可以逐层推出来
现在把局部规则应用到一个批量全连接网络。先只看单个样本,输入 ,隐藏层有 个单元,输出有 个类别:
这里 的形状是 , 的形状是 。损失使用交叉熵。反向传播从输出层 logits 开始:
我更建议把 明确定义成“损失对第 层预激活值 的梯度”,而不是含糊地叫“第 层的误差”。有了这个定义,每一步的形状和求导对象都能核对。
输出层参数的梯度为:
再把梯度传回隐藏层激活值:
穿过 ReLU 后,得到隐藏层预激活值的梯度:
表示逐元素乘法,指示函数在对应预激活值为正时取 ,为负时取 。最后得到第一层参数梯度:
这就是“一层一层向后”的含义。我们不是从输出猜测哪些权重该变,而是从明确的标量损失出发,把导数按计算路径传回每个参数。
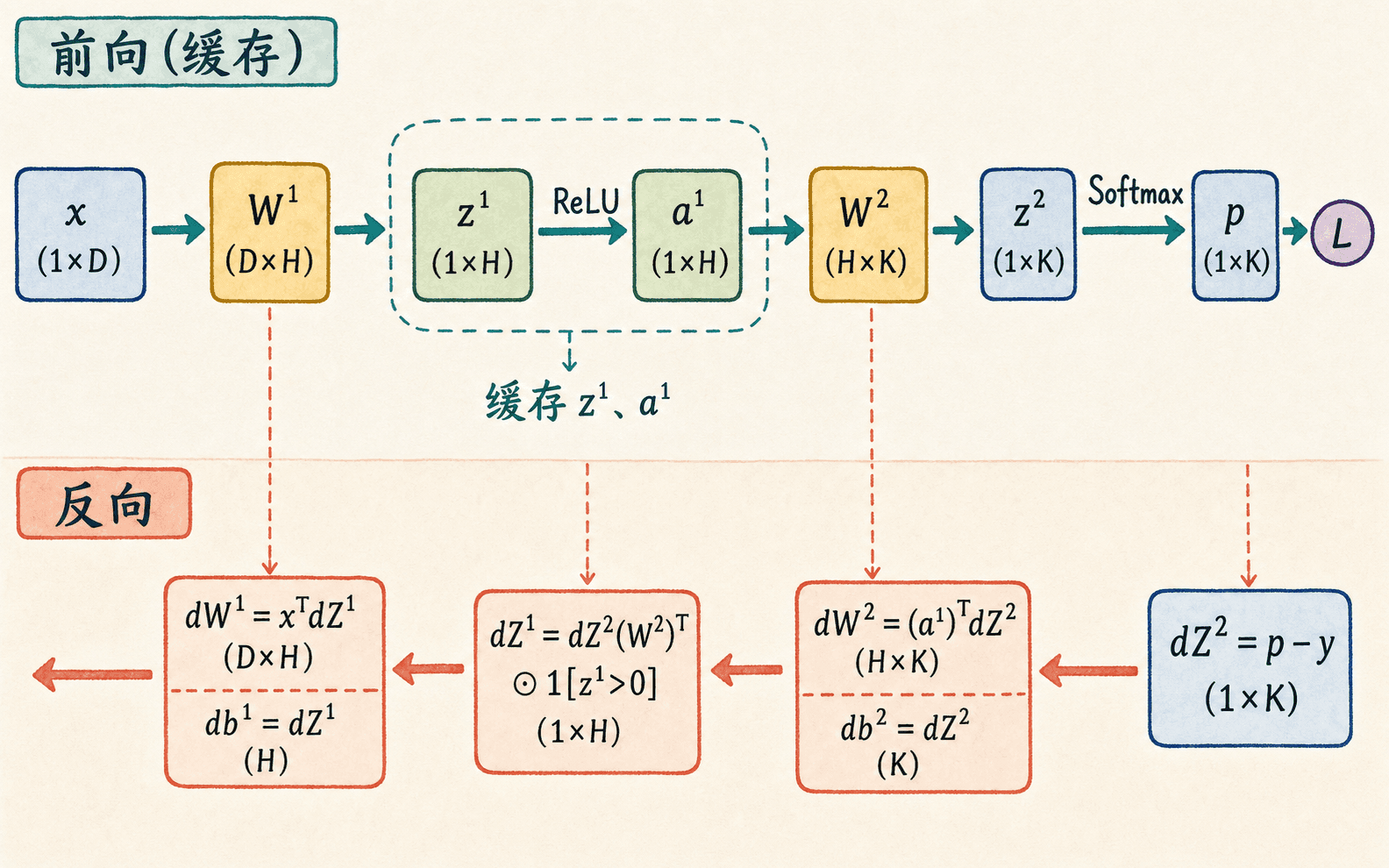
保存必要的前向中间量,反向时才能逐层复用链式法则。
前向传播需要保存一部分中间结果,例如 和 ,反向传播会用到它们。自动微分框架所谓的“保留计算图”,本质上就是记录运算关系和求导所需的上下文;它不会把所有变量都无限期保存。
4
在使用 ReLU 隐藏层、Softmax 加交叉熵输出层的网络中,δ⁽²⁾ 最准确的定义是什么?
批量反向传播的难点通常是形状而不是微积分
真实训练不会只处理一个样本。设一个 mini-batch 含 个样本,每行一个样本,则各变量的形状如下:
前向传播写成:
偏置会沿批次轴广播:同一个 维偏置向量加到 行隐藏表示上。反向传播时,广播的逆操作是沿批次轴求和,所以偏置梯度不是矩阵乘法:
若损失取批次平均,输出层梯度要带上 :
其余梯度为:
单样本时的外积,在批量形式里变成“激活矩阵转置乘当前层梯度矩阵”。这是向量化反向传播的核心模式。
python
def assert_shapes(X, W1, b1, W2, b2):
B, D = X.shape
D2, H = W1.shape
H2, K = W2.shape
assert D == D2
assert H == H2
assert b1.shape == (H,)
assert b2.shape == (K,)
return B, D, H, K形状断言很朴素,却能在训练前拦住一大类错误。特别要警惕 NumPy 把形状为 (B,) 的一维数组静默广播到意外的方向;标签最好明确约定为类别索引 (B,) 或 one-hot (B,K),不要在同一函数里来回猜。

微积分没有变,批量实现最常见的错误来自转置与求和轴。
5
一个批次有 B=32 个样本,隐藏层有 H=64 个单元,类别数 K=10。矩阵 ∂L/∂W⁽²⁾ 的形状是 ____。
参数展开只是接口适配,不是神经网络的必经步骤
一些经典课程作业会把所有权重矩阵拼成一个长向量,再交给通用优化函数。这很容易让人产生误解,好像“展开参数”是反向传播算法的一部分。其实网络的自然表示仍是按层组织的矩阵与偏置;展开只在某些接口需要单一参数向量时有用,例如:
- 使用只接收一维变量的通用数值优化器;
- 对参数向量做有限差分梯度检查;
- 把教学作业里的多组参数交给同一个代价函数;
- 实现某些需要统一向量操作的研究原型。
现代框架的优化器可以直接接收参数张量列表,不要求开发者手工拼接。即便确实需要展开,也要同时保存每个张量的形状、切片范围、数据类型和展开顺序,否则还原后数值相同、位置却可能错层。
python
import numpy as np
def pack(parameters):
flat_parts = []
spec = []
offset = 0
for name, value in parameters.items():
array = np.asarray(value)
size = array.size
flat_parts.append(array.ravel(order="C"))
spec.append((name, array.shape, offset, offset + size))
offset += size
梯度也必须按完全相同的顺序展开。若参数按 W1, b1, W2, b2 拼接,而梯度按 W1, W2, b1, b2 拼接,向量长度仍然正确,优化器却会把每段梯度施加到错误参数上。这类 bug 很隐蔽,因为代码不会必然报错。
不要为了“统一”而在训练主循环里反复展开和还原参数。这样会增加复制、索引和顺序错误的机会。只在接口边界转换一次,并用往返测试确认 unpack(pack(params)) 与原参数逐项一致。
6
反向传播必须先把所有参数矩阵展开成一个长向量,才能计算梯度。
梯度检查是在给反向传播做独立验算
反向传播速度快,但手写时容易出现转置、缩放、正则化和广播错误。梯度检查用一个更慢、思路独立的数值近似来核对解析梯度。对参数 使用中心差分:
中心差分需要对每个被检查参数计算两次损失,但截断误差通常比单边差分小。 也不是越小越好:太大会让近似粗糙,太小会被浮点舍入误差淹没。双精度下可以从 左右尝试,再观察不同 下的结果是否稳定。
只看绝对差不够。两个梯度都在 量级时, 的差异非常严重;两个梯度在 量级时,同样的绝对差异几乎可以忽略。逐参数相对误差可以写成:
对于平滑的小网络,误差在 左右通常很理想;若包含 ReLU 这类不可导折点,有限差分可能跨过折点,阈值要结合具体位置判断。不要把某个固定阈值当成脱离上下文的定理。
一套更可靠的检查方式
先把输入和参数转为双精度,只取两三个样本和很小的网络,避免检查一次就要计算数百万次前向传播。
关闭 dropout、随机数据增强和随机采样,或者在正负扰动与解析梯度计算前重置同一个随机种子,保证三次计算面对同一函数。
先关闭正则化检查数据损失,再单独检查正则化项,防止简单的正则化梯度掩盖数据梯度错误。
不必遍历所有参数,但每一组参数都要抽样,包括数量很少的偏置;只在一个巨大向量里均匀随机抽样,可能一次也抽不到偏置。
python
def relative_error(a, b, floor=1e-12):
return abs(a - b) / max(floor, abs(a), abs(b))
def check_one_coordinate(loss_fn, params, analytic_grad, index, h=1e-5):
original = params[index]
params[index] = original + h
loss_plus = loss_fn(params)
params[index] = original - h
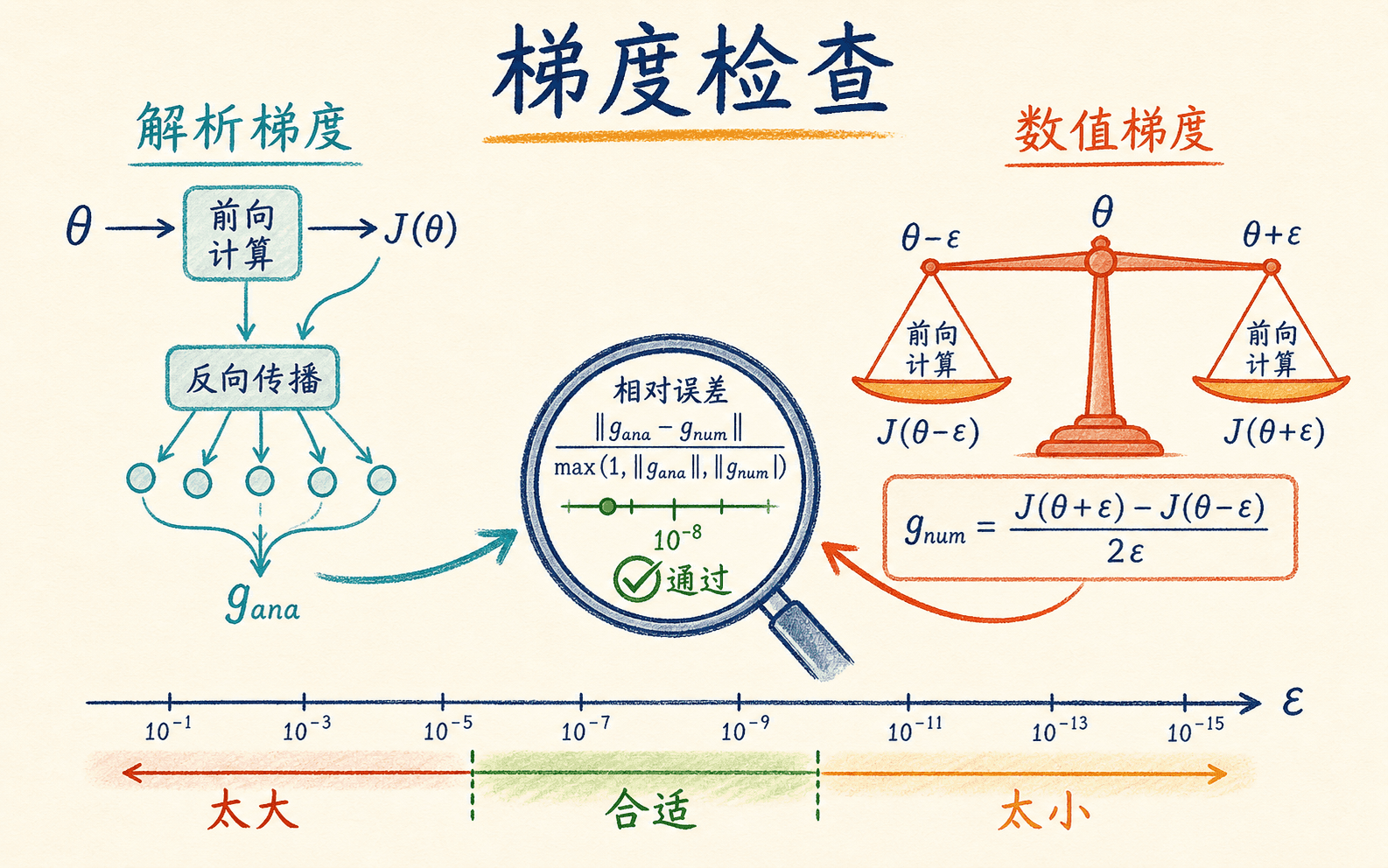
数值差分是反向传播的验算器,不是训练算法。
7
进行梯度检查时,哪些做法能让结果更可信?
初始化先要打破对称性,再考虑方差怎样穿过网络
如果同一隐藏层的所有权重都初始化为相同值,那么这些神经元会得到相同输出、相同梯度和相同更新。训练很多步后,它们仍然彼此相同,多个神经元等价于重复复制一个神经元。这就是对称性没有被打破。
因此,隐藏层权重不能全部设为零。偏置通常可以初始化为零,因为随机权重已经让各神经元看到不同的线性组合。注意“随机”只解决神经元分工问题,随机值的尺度仍然需要设计。
假设某层有 fan_in 个输入,它们大致独立、均值接近零。线性组合的方差会随输入项数量和权重方差增长。粗略地看:
权重尺度过大,激活与梯度可能逐层放大;尺度过小,它们又可能逐层衰减。初始化方法的目标之一,是让信号在网络开始训练时不要立刻失控。
Xavier 与 He 初始化的适用边界
Xavier,也叫 Glorot 初始化,常用于 tanh 或近似线性的对称激活。常见正态版本让权重方差取:
也有只根据 fan_in 设为 的版本,具体公式会随分布形式和希望优先保持前向还是反向方差而变化。
ReLU 会把大约一部分负值截为零,He 初始化据此使用更大的方差:
对应正态采样的标准差是 。这两个公式不是“Xavier 永远配 sigmoid、He 永远配所有 ReLU 变体”的死规则。激活函数的斜率、残差结构、归一化层、网络深度和框架默认实现都会影响选择。最实用的做法是先选与激活匹配的合理初始化,再观察各层激活和梯度分布。
python
import numpy as np
rng = np.random.default_rng(42)
def he_normal(fan_in, fan_out):
scale = np.sqrt(2.0 / fan_in)
return rng.normal(0.0, scale, size=(fan_in, fan_out))
def glorot_normal(fan_in, fan_out):
scale = np.sqrt(2.0 / (fan_in + fan_out))
return rng.normal(0.0, scale, 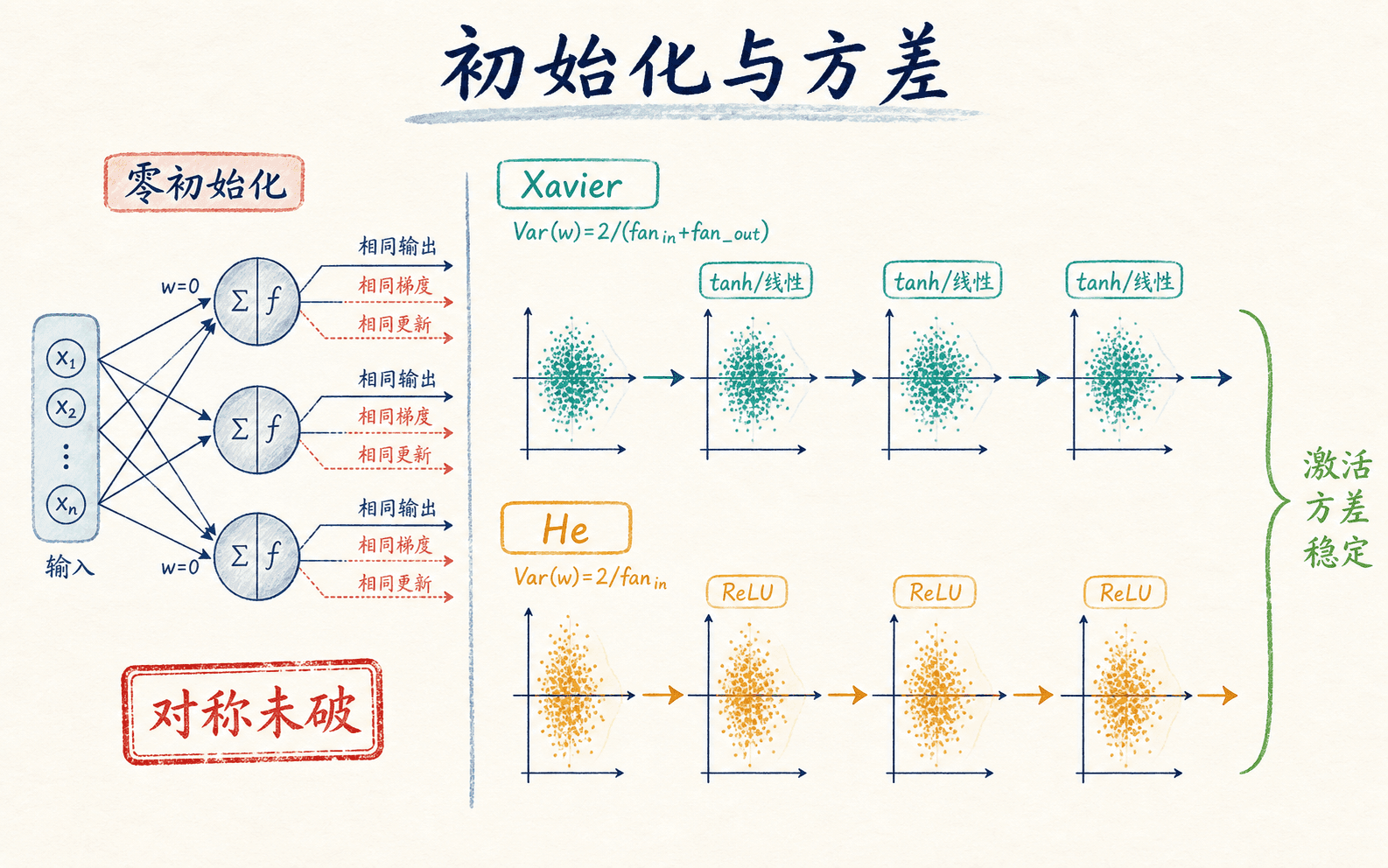
初始化既要打破单元对称,也要让信号方差合理穿过网络。
8
一个使用 ReLU 的全连接隐藏层有 fan_in=200。按常见 He 正态初始化,权重标准差最接近哪项?
梯度消失与爆炸来自许多局部导数的连乘
深层网络的梯度要穿过很多层。以简化的一维表达为例,早期层的梯度包含后续权重和激活导数的乘积:
如果许多因子的绝对值都小于 ,乘积会快速接近 ,前面层几乎收不到学习信号;如果许多因子大于 ,乘积可能快速增大,更新变得不稳定甚至出现 inf、NaN。
Sigmoid 的导数为:
它的最大值只有 。当 很大,输出接近 或 ,导数更接近 ,这就是激活饱和。把许多这样的导数连乘,梯度很容易消失。ReLU 在正半轴的导数为 ,缓解了饱和问题,但负半轴导数为 ,若一个单元长期落在负区间,它也可能停止更新。
先看症状,再选处理方式
梯度消失常表现为前面层梯度范数远小于后面层、损失下降很慢、早期特征几乎不变。梯度爆炸则常见于损失突然跃升、梯度范数骤增、权重变得异常大或出现非有限数。
可以按问题来源处理:
- 使用与激活匹配的 Xavier/He 初始化,先让训练起点的方差合理;
- 选择 ReLU、Leaky ReLU 等较少饱和的激活,但仍要监控“死亡单元”;
- 使用归一化层或残差连接,缩短有效梯度路径并稳定中间分布;
- 在序列模型或确有爆炸迹象时使用梯度裁剪,限制单步更新信号;
- 调低学习率只能减小参数更新,不能修复一个数学上已经错误或全部为零的梯度。
梯度裁剪的位置也说明了三个阶段的边界:先由反向传播得到原始梯度,再裁剪梯度,最后优化器更新参数。
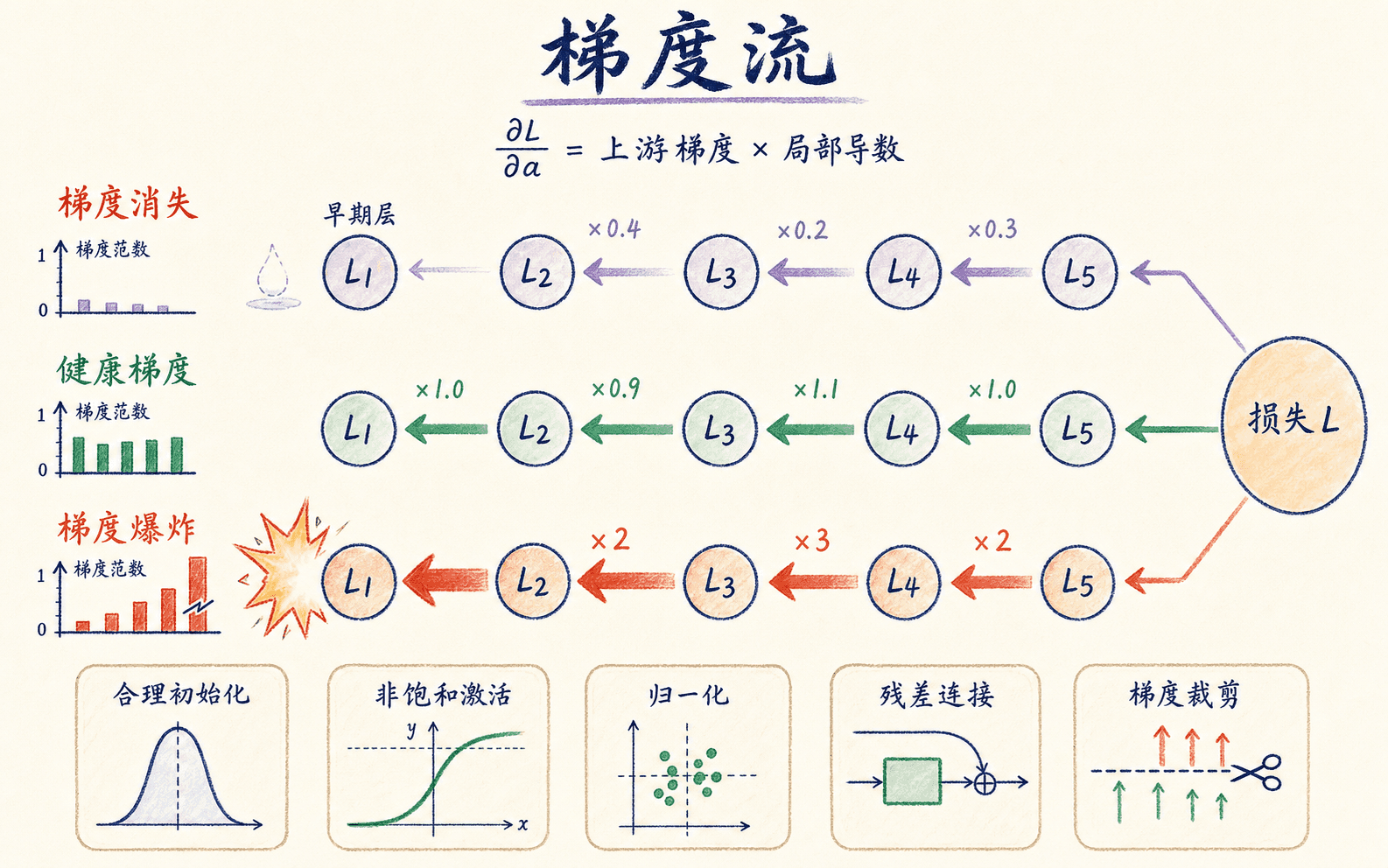
许多局部导数连乘,会让梯度逐层衰减或放大。
9
只要把学习率调得足够小,就能从根本上解决梯度消失。
Mini-batch 训练把数据顺序、梯度和更新串成循环
全量梯度每一步都使用整个训练集,估计稳定但计算和内存成本高;单样本随机梯度更新频繁,却非常噪声。mini-batch 在两者之间取一个实用折中:每次用一小批样本估计梯度,并用高效矩阵运算完成计算。
一个 epoch 表示按当前采样规则让每个训练样本平均被看到一次;一个 step 表示使用一个 mini-batch 完成一次参数更新。批量大小改变后,每个 epoch 的 step 数也会改变,所以比较训练过程时要先说清横轴是 step 还是 epoch。
标准训练循环的顺序是:
在每个 epoch 开始时打乱训练样本或使用带随机采样的数据加载器,避免固定顺序让相邻批次长期带有同一偏差。
取出一个 mini-batch,清空上一步遗留的参数梯度,再执行前向传播并计算标量损失。
对损失执行反向传播,让每个可训练参数得到当前批次的梯度;若需要梯度裁剪,就在此时处理。
调用优化器更新参数。到这里才改变权重,然后进入下一个 mini-batch。
python
for inputs, labels in train_loader:
optimizer.zero_grad()
logits = model(inputs)
loss = loss_fn(logits, labels)
loss.backward()
optimizer.step()这段框架式伪代码故意把四步写开。梯度默认累积,因此如果忘了 zero_grad(),第二个批次的梯度会叠加到第一个批次上。梯度累积有时是有意设计,用多个小批次模拟更大的有效批量;但那时需要明确累积多少次、损失是否按累积步数缩放,以及何时才执行一次更新。
优化器改变怎样用梯度,不改变梯度从哪里来
SGD 直接按当前梯度前进;动量法积累一段时间的方向,减少狭长谷底里的来回摆动;Adam 对一阶矩和二阶矩做自适应估计,为不同参数调整有效步幅。它们都建立在同一批反向梯度之上。Adam 有时更容易得到可用起点,但不会自动修正错误标签、数值溢出或写错的反向传播。
学习率常常比优化器名称更影响训练。过大时,损失会震荡、发散或突然变成非有限数;过小时,损失平滑却下降得极慢。实践中可以先用对数尺度试探学习率,再根据验证集表现设置衰减、分段降低或其他调度策略。调度器修改的是后续更新的步幅,不应根据测试集反复调参。
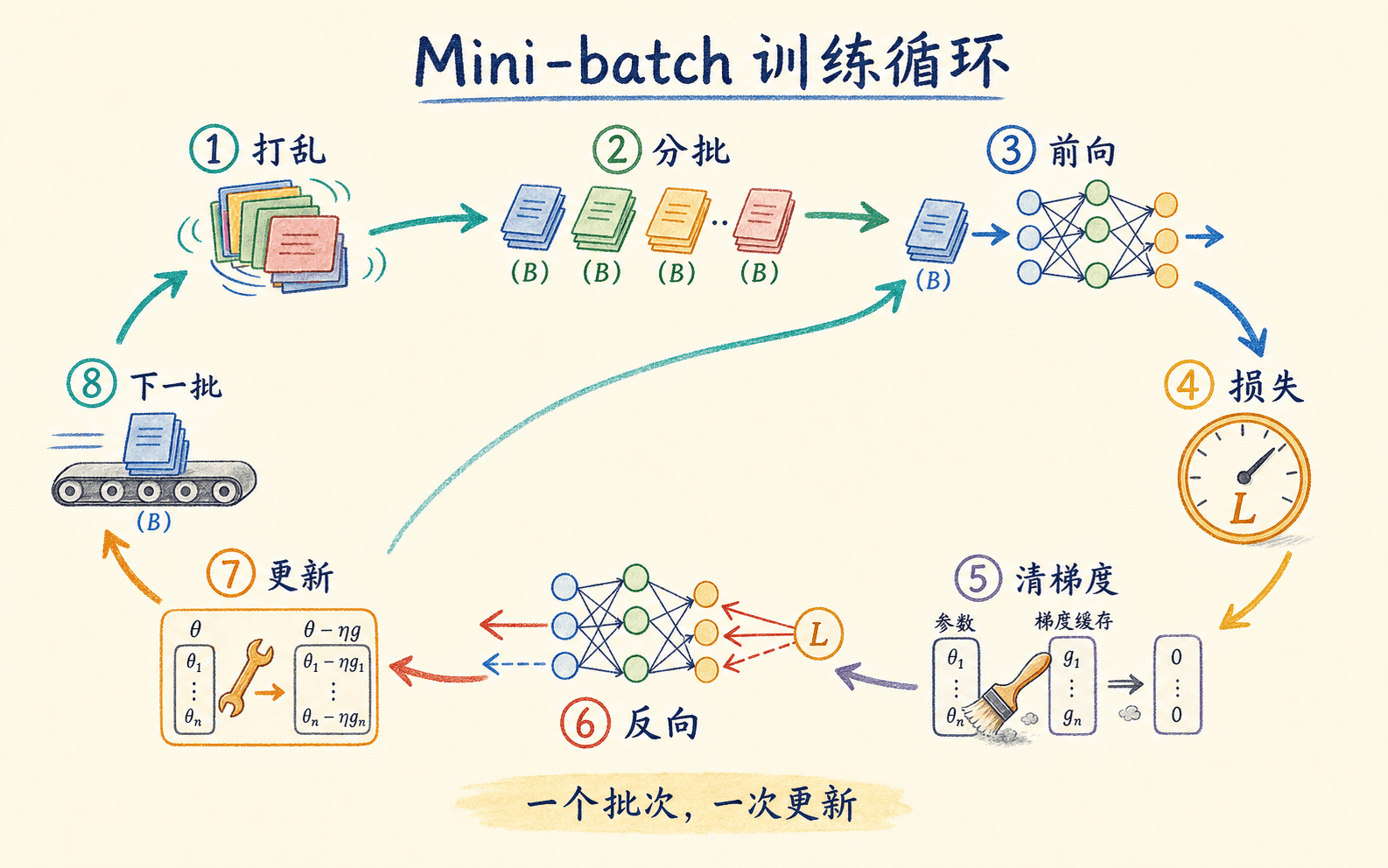
每个批次都应遵循清梯度、前向、反向、更新的明确次序。
10
在默认会累积梯度的框架中,标准 mini-batch 训练为何通常在每步开始时清空梯度?
正则化与训练模式会改变训练时计算的函数
最常见的参数正则化是在数据损失之外加入 惩罚:
对应的权重梯度多出一项:
偏置常常不做权重衰减,因为它不控制输入方向上的敏感程度,而且数量通常远少于权重;但这是一种常用约定,不是数学强制要求。实现时还要看优化器的 weight_decay 是直接把 梯度并入目标,还是使用与梯度更新解耦的权重衰减,两者在自适应优化器中不一定等价。
Dropout 是另一类正则化。训练时,它随机屏蔽部分激活,并对保留激活做相应缩放;评估时则关闭随机屏蔽。批归一化也有训练与评估差异:训练阶段使用当前批次统计量并更新运行统计,评估阶段通常使用已经积累的统计量。
这就是为什么验证前要显式切换模型模式:
python
model.train()
for inputs, labels in train_loader:
optimizer.zero_grad()
loss = loss_fn(model(inputs), labels)
loss.backward()
optimizer.step()
model.eval()
with no_grad():
for inputs, labels in validation_loader:
logits = model(inputs)
update_metrics(logits, labels)model.eval() 与“关闭梯度记录”不是同一件事。前者让 dropout、批归一化等有模式差异的模块采用评估行为;no_grad() 则告诉自动微分系统不记录求导图,降低验证时的内存和计算开销。一个改变模块行为,一个改变梯度追踪,实际验证通常两者都要做。
不要在验证集上调用优化器更新,也不要让批归一化用验证数据继续更新运行统计。前者直接训练了验证集,后者也会让验证信息进入模型状态,都会使评估失去原本的独立性。
11
含 Dropout 和批归一化的模型做验证时,哪些操作通常是正确的?
用 NumPy 从头训练一个两层分类网络
下面的例子只依赖 NumPy,生成三类二维螺旋数据,并训练一个“全连接层—ReLU—全连接层—Softmax”网络。代码把前向、损失、反向和更新分开,方便逐段检查。
python
import numpy as np
def make_spiral(points_per_class=100, classes=3, seed=7):
rng = np.random.default_rng(seed)
total = points_per_class * classes
X = np.zeros((total, 2), dtype=np.float64)
y = np.zeros(total, dtype=np.int64)
for class_id in
这份代码有几个刻意保留的教学边界。第一,它用普通 SGD,更新规则一眼可见;换成动量或 Adam 只会改变更新部分,不会改变 loss_and_gradients 的链式法则。第二,训练和评估用了同一份数据,只为了证明反向传播能让非线性小网络拟合数据;真实项目必须另设验证集和测试集。第三,ReLU 在零点不可导,代码采用常见约定,把零点导数设为 。
你可以先把 hidden_dim 改成 1,观察模型容量不足时的结果;再把学习率改成 8.0 或 0.008,比较损失曲线。这样的对照比只背“学习率要合适”更容易形成判断。
12
在端到端代码中,把优化规则从 SGD 换成 Adam 时,哪部分原则上仍负责产生同一目标函数的梯度?
调试神经网络要从可证伪的小检查开始
训练失败时,最浪费时间的做法是同时改网络宽度、优化器、学习率和数据增强。一次改四个地方,即使结果变好,也不知道是哪一项起作用。更稳妥的顺序,是从有明确预期的小检查开始,把问题范围一层层缩小。
训练前先建立数值基线
若 类模型刚初始化时给各类近似均匀概率,交叉熵应接近:
例如 10 类任务的初始数据损失大约是 。若一开始就是几十、负数或 NaN,先检查标签、损失接口、是否错误地把概率再次传入需要 logits 的函数,以及数值稳定实现。
用极小数据验证“能不能学会”
关闭数据增强和大部分正则化,只取十几个样本,尝试把训练误差降到很低。小网络连这点数据都拟合不了,通常说明实现、数据管道或优化设置有问题;此时增加更多数据不会修复 bug。反过来,小数据能拟合也不代表能泛化,它只是排除了部分“根本没在学习”的故障。
按数据流逐段看证据
可以依次记录这些量:
- 输入的形状、数据类型、最小值、最大值和缺失值数量;
- 标签范围与类别计数,确认类别索引没有越界或错位;
- 每层激活的均值、标准差、零值比例与非有限数;
- 每层梯度范数,比较前后层是否相差多个数量级;
- 参数更新量与参数量级的比值,确认参数确实在动且没有一步跳飞;
- 训练损失、验证损失和对应指标,避免只看单一准确率;
- 训练/评估模式、随机种子和数据划分,确认复现实验时状态一致。
若损失在下降但准确率不动,可能是类别极不平衡、阈值不合适或指标实现错误;若准确率上升但损失持续变差,模型可能对少数错误样本越来越自信。不同观测量回答的是不同问题,不要期待一条曲线包办诊断。
一份可执行的排查顺序
先固定随机种子,保存当前配置与一个原始批次,保证每次复现的是同一个问题。
核对输入、标签和损失接口,确认分类损失收到的是 logits,标签形状和取值范围符合接口约定。
检查初始损失是否接近可解释基线,再对小网络做梯度检查,先验证数学实现。
尝试过拟合极小批次,并逐层观察激活、梯度和参数更新;若失败,就沿第一次出现异常的位置向前追。
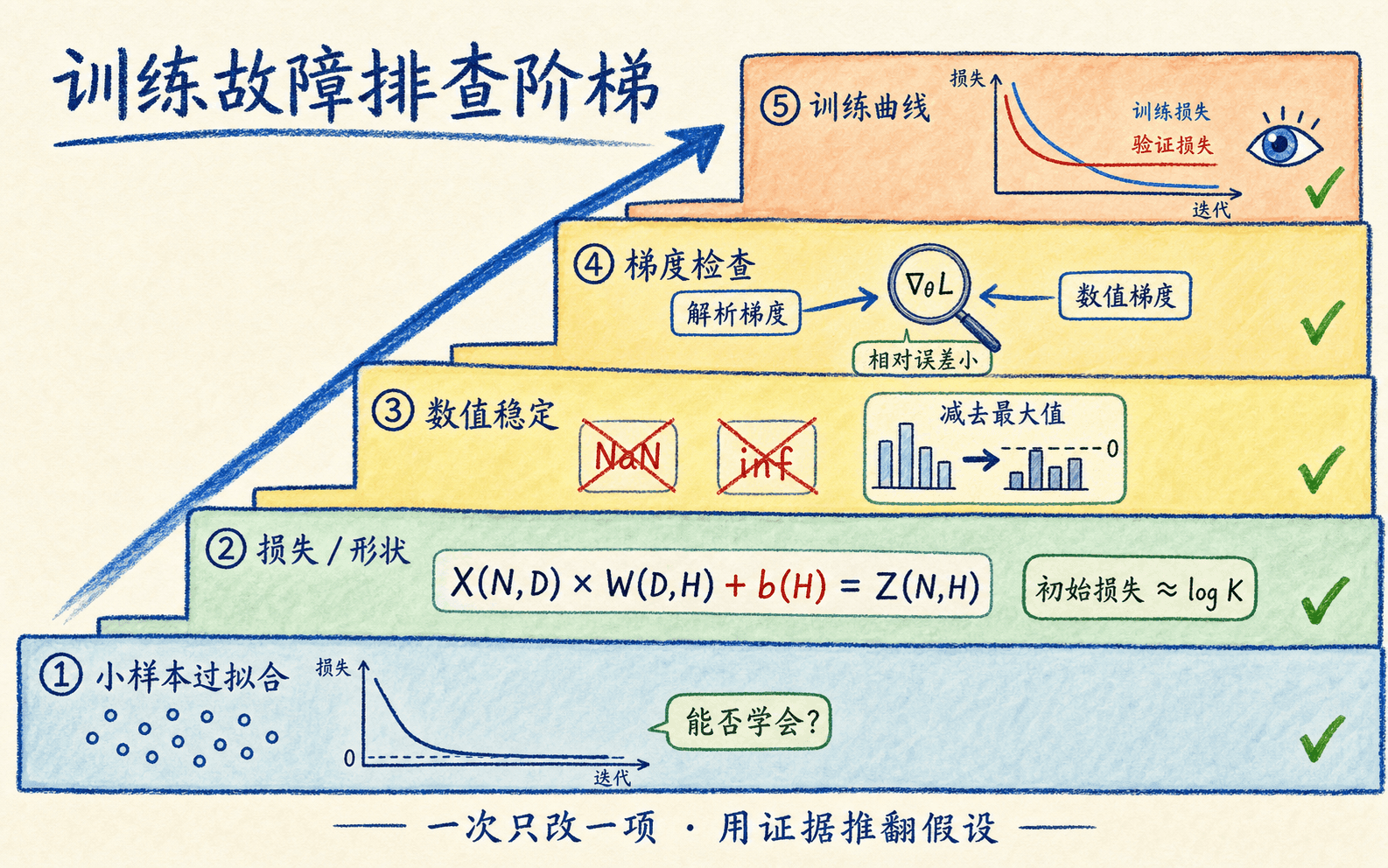
从可证伪的小检查开始,远比盲目调学习率有效。
一个可信的训练结果不只是“最后准确率不错”。你还应该能解释初始损失为何合理、梯度检查怎样通过、小批量为何能被拟合、验证阶段是否没有更新状态,以及每次改动依据了哪条可观测证据。
13
一个 5 类分类网络刚初始化就出现 NaN。下列哪些是合理的优先检查项?