神经网络反向传播与计算图 | 自在学神经网络反向传播与计算图
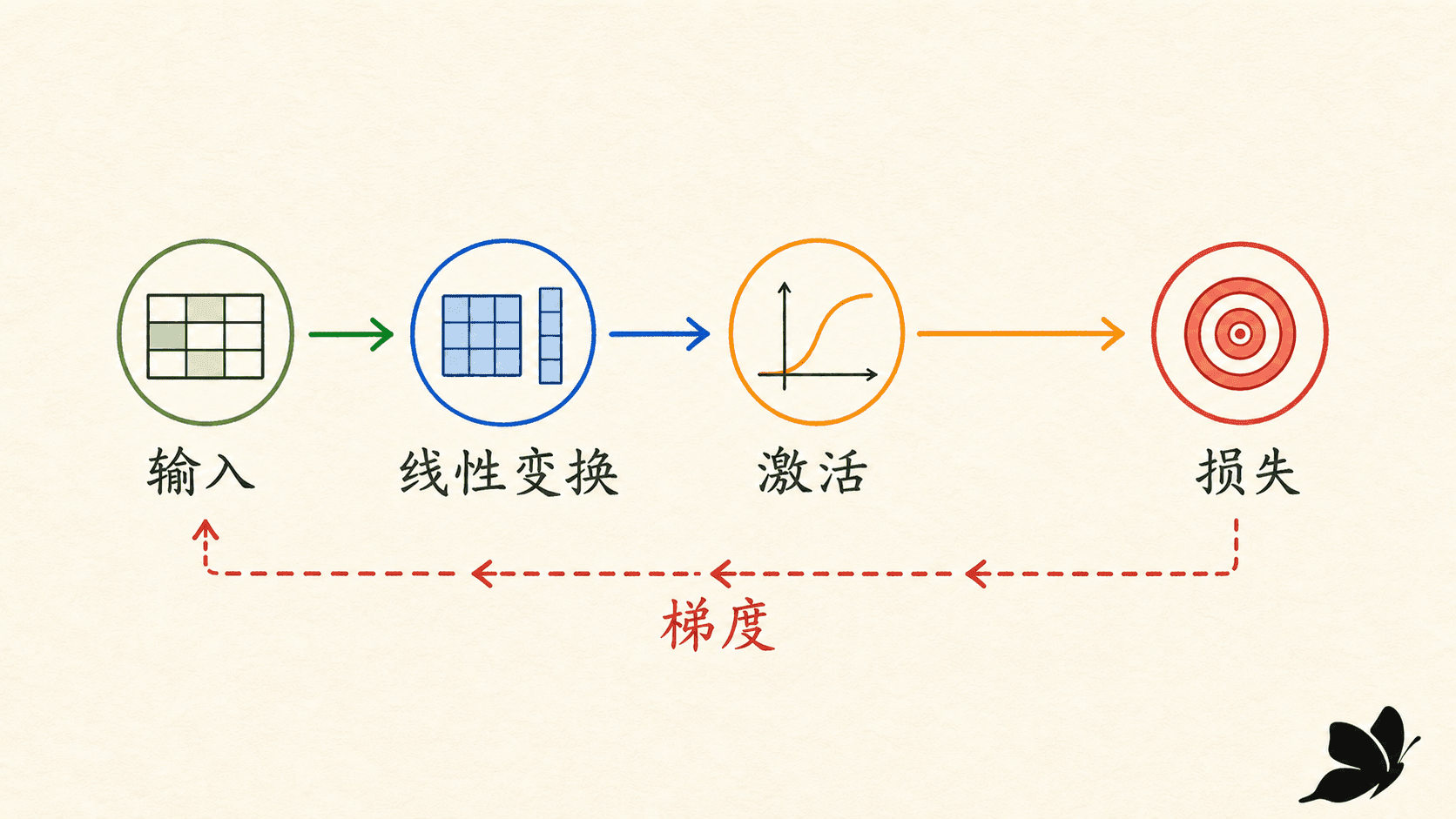
上一节已经把神经网络的前向过程搭起来了:输入经过线性变换和激活函数,变成分类分数;分类分数进入损失函数,得到一个数字。我们也知道优化器会按下面的方向更新参数:
θ←θ−η∇θL
真正缺的其实是等号右边:一个网络可能有几百万甚至更多参数,怎样一次算出损失对每个参数的偏导数?如果每改动一个参数就重新运行一遍网络,成本会随参数数目线性增加,而且得到的还只是有限差分近似。反向传播换了一种组织计算的方式:前向阶段保存必要的中间量,反向阶段从标量损失出发,沿已经执行过的计算路径逐步应用链式法则。
这篇内容会把三件容易混在一起的事分开:损失函数说明要优化什么,反向传播计算梯度,优化器使用梯度更新参数。读到最后,你将能手算一个两层网络的全部梯度,也能用中心差分检查自己的实现,并看清下一篇 RNN 中“沿时间反向传播”到底多了什么。
先把学习写成一个标量目标
反向传播并不决定模型应该学什么。它接受一个已经定义好的标量目标,再回答“这个目标对参数有多敏感”。所以第一步不是求导,而是确认目标函数。
给定训练样本 {(xi,yi)}i=1N、模型 fθ 和单样本损失 ℓ,常见训练目标可以写成:
J(θ)=N1i=1∑
第一项要求模型解释训练数据,第二项限制参数。比如 L2 正则取 Ω(θ)=21∥θ∥,它的梯度就是 。反向传播时,数据损失和正则项都在同一个计算目标里,因此参数实际收到的是:
∇θJ=N1i=1∑
这和线性模型的思路相通。线性最小二乘在条件合适时可以写出闭式解,加入二次正则还能改善病态矩阵带来的不稳定;多层神经网络含有非线性复合与大量参数,通常没有可直接套用的闭式解,于是我们改用“计算梯度—更新参数—再次计算”的迭代方式。
从最大似然到交叉熵
如果模型直接给出条件概率 pθ(y∣x),最大化独立样本的条件似然等价于最小化负对数似然:
θ∗=argθmin−i=1∑
多分类网络的 softmax 交叉熵正是这个目标的常见形式。若再给参数加入先验 p(θ),最大后验估计可以写成:
θ∗=argθmin[−
高斯先验的负对数与二次惩罚只差常数和比例系数,因此“最大后验”与“数据损失加 L2 正则”会落到同一种可微目标上。这也解释了为什么正则化不是训练结束后的补丁,而是梯度来源的一部分。
不要把不同的“反向”混成一个算法
有隐变量的混合模型常用 EM:先按当前参数估计隐变量的后验权重,再优化加权的完整数据目标。HMM 的前向—后向算法则利用链式序列结构,高效汇总不同隐藏状态路径的概率。神经网络反向传播做的是另一件事:沿数值程序的计算图累积导数。
三者都复用中间量,也都避免枚举所有组合,但对象不同:EM 交替优化隐变量分布与参数,HMM 前向—后向进行概率消息传递,反向传播传递的是导数。把边界划清,后面看到 RNN 的 BPTT 时就不容易被相似名字带偏。
1训练目标 J(θ)=数据损失+λ‖θ‖²/2 时,反向传播给参数的梯度应包含什么?
2关于最大似然、MAP 与反向传播,下列哪些说法成立?
计算图把复杂函数拆成局部账本
计算图是一个有向图:节点保存中间值,边表示一个值如何参与下一个操作。普通前馈网络在一次执行中形成有向无环图;前向按依赖顺序计算值,反向按相反顺序计算梯度。
先看一个足够小、但包含乘法、加法和复合的目标:
m=xy,u=m+z,L=21u
令 x=2、y=−3、z=1。前向得到 m=−6、、。反向从 开始:
平方节点的局部导数是 ∂u∂L=u,所以传到 u 的上游梯度为 。
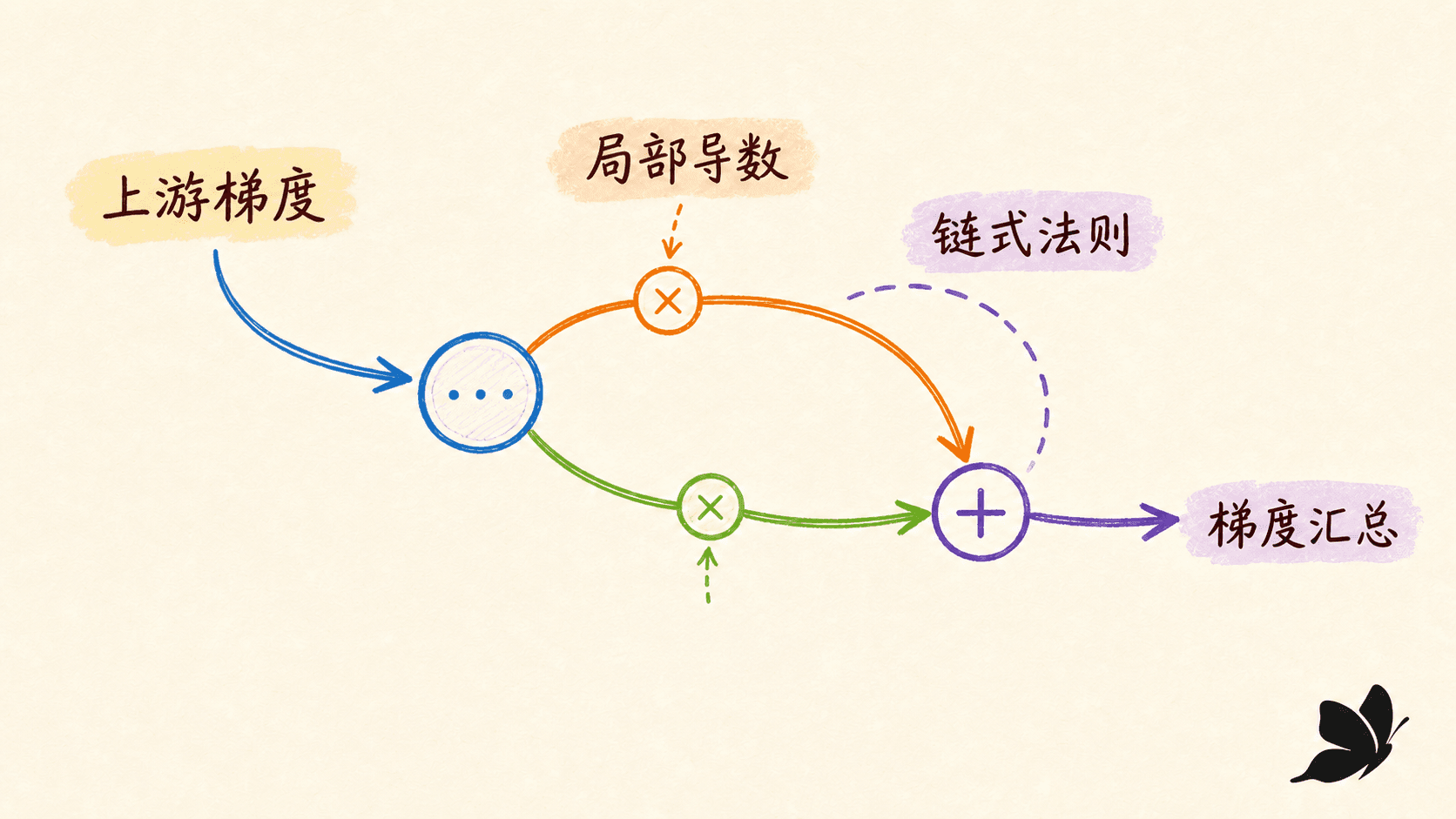
你可以把每个反向节点理解为一个小函数:它收到上游梯度,乘上自己的局部导数,把结果送给输入。节点不需要知道整个网络,只需要知道前向时的输入、输出,以及本操作的求导规则。
实验台把“值”和“梯度”放在同一张图里:先逐步推进前向节点,再沿红色虚线回退。改变任一输入后重新走一遍,你会看到局部导数规则没有变化,但具体梯度会跟着前向缓存改变。这比只记一串公式更容易发现“反向公式依赖哪些前向量”。
分支处为什么必须相加
如果一个变量被多次使用,计算图里会出现多条从它通往损失的路径。设:
q(x)=x2+3x
x 一路进入平方,一路进入乘以 3 的分支。总变化是两条路径贡献的和:
dxdq=∂x∂x
这条“分支求和”规则会在神经网络里反复出现:偏置广播到一个批次的所有样本,要把各样本贡献求和;一个参数在 RNN 的多个时间步共享,也要把各时间路径的梯度求和。梯度累积不是框架的偶然行为,而是多变量链式法则的直接结果。
ReLU 在 0、最大值操作在并列最大点等位置不可微。实现通常选择一个约定的次梯度或固定规则。梯度检查应避开这些拐点,否则很小的正负扰动可能落在不同分支,两种梯度不一致并不一定说明反向公式写错了。
3变量 x 同时进入两条分支时,只需选择绝对值较大的那条分支梯度。
4在反向传播中,一个普通操作节点最需要保存和使用的是什么?
链式法则升级为反向模式
标量复合函数的链式法则很熟悉:若 L=f(g(x)),则:
dxdL=dgdLdx
神经网络的中间量通常是向量或矩阵。设 y=g(x)、z=f(y),对应雅可比矩阵满足:
Jf∘g(x)=Jf(y)Jg
真正实现时,我们几乎从不显式构造每一层巨大的雅可比矩阵。对标量损失 L,反向传播维护的是“损失对当前中间量的梯度”,并计算向量—雅可比积(VJP):
xˉ=yˉJg(x)
这里上横线表示伴随量,也就是损失对该变量的导数。VJP 直接给出下一步需要的梯度,不必把 Jg 整张展开。前向模式则传播雅可比—向量积(JVP),它回答“输入沿某个方向变化时,输出怎样变化”。
为什么标量损失适合反向模式
假设程序有 n 个输入参数和 m 个输出。一次前向模式传播一个输入方向,适合 n 小、m 大的情形;一次反向模式传播一个输出方向,适合 m 小、n 大的情形。训练网络时,参数很多,而最终目标通常只有一个标量,所以从这个标量反向传播可以在一次反向遍历中汇总所有参数梯度。
自动微分计算的是解析链式法则在浮点程序中的结果,不是用有限差分猜导数。它避免了有限差分的截断近似,但仍会受到浮点舍入、上溢、下溢和非有限值影响。
用形状推导线性层
对一个批次,设:
- 输入 X∈RB×din;
- 权重 W∈R;
已知上游梯度 GZ=∂Z∂L,三个反向结果为:
∂W∂L=GZTX
∂b∂L=i=1∑BG
∂X∂L=GZW
形状是最便宜的第一道检查:GZTX 的形状为 dout×d,恰好与 相同;对批次维求和后得到 ,与 相同; 回到 ,与 相同。
单样本时,权重梯度退化为外积。若 z=Wa+b、δ=∂z∂L,那么:
∂W∂L=δaT
这条公式解释了很多“转置到底放哪边”的困惑:先保证结果形状和 W 相同,再用逐元素式 ∂Wij∂L=δ 对照,就不会只靠记忆猜公式。
5标量损失、海量参数的神经网络适合反向模式,主要原因有哪些?
6批量线性层 Z=XWᵀ+1bᵀ 中,若上游梯度为 G_Z,则权重梯度是 ____。
完整走通两层网络的反向传播
现在把局部规则拼成一个可训练的分类网络。对单个输入 x,定义:
z(1)=W(1)x+b(1)
h=ReLU(z(1))
o=W(2)h+b(2)
o 是 logits,也就是尚未归一化的类别分数。设真实类别的 one-hot 向量为 y,softmax 概率为:
pk=∑jeo
交叉熵损失为:
L=−k∑yklogpk
先把输出层化简
若真实类别索引是 c,one-hot 向量只有 yc=1,损失可改写为:
L=−oc+logj∑eo
对任意 logit ok 求导:
∂ok∂L=−1[k=
所以 softmax 与交叉熵合在一起时,输出层梯度非常紧凑:
δ(2)=∂o∂L=p−y
这不是“背出来的快捷公式”,而是负对数似然对 logits 的完整链式法则已经化简。若使用类别加权、标签平滑、软标签或不同 reduction,具体系数会变化,不能无条件照搬。
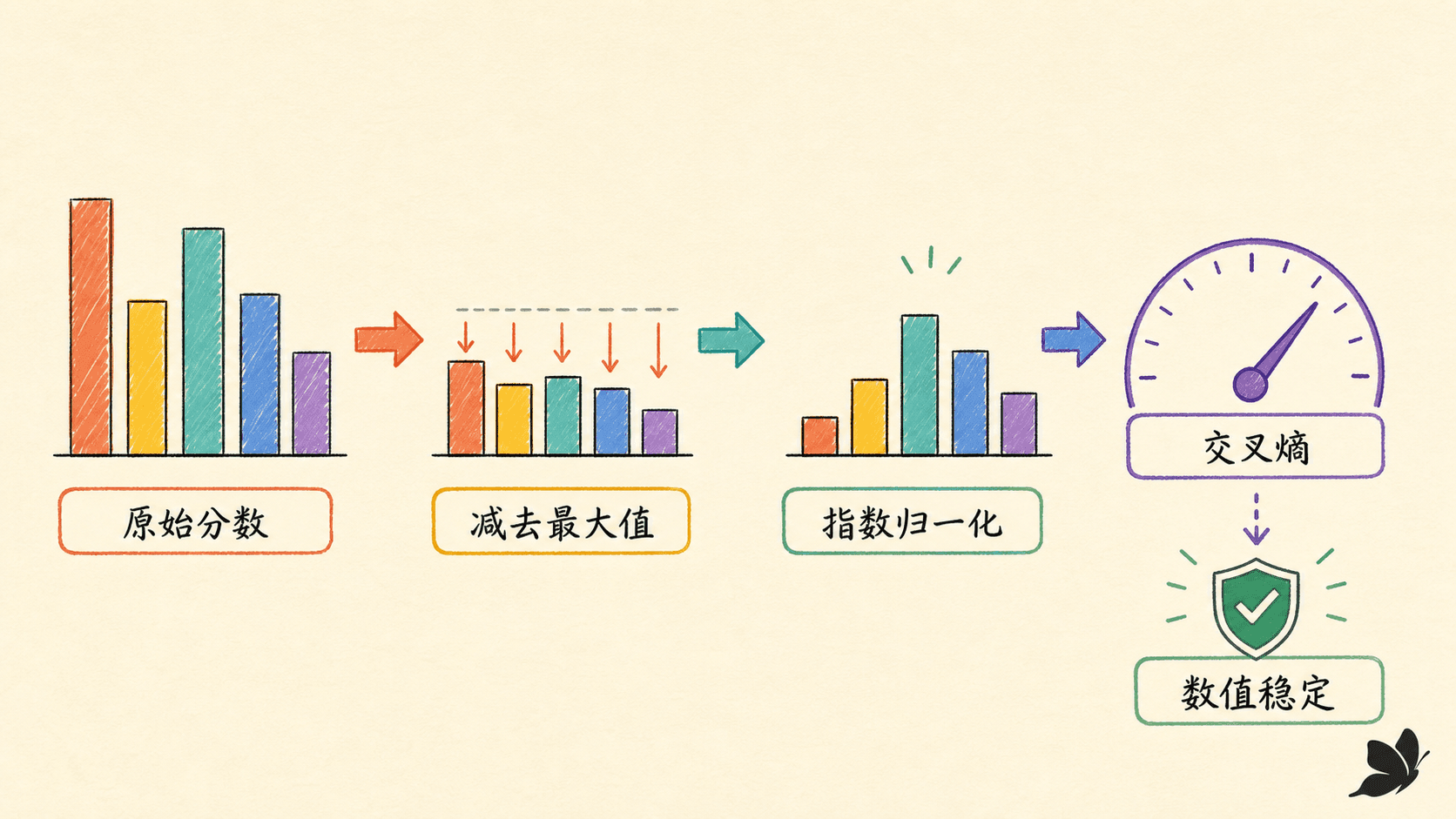
数值稳定的写法
直接计算 eok 可能上溢。令 a=maxjo,将所有 logits 平移:
pk=∑jeo
分子分母同时乘了 e−a,概率不变;同时每个指数的自变量都不大于 0,避免了正方向指数爆炸。实际代码更适合直接算 log-softmax:
logpk=(ok−a)−log
一层一层向前推回去
有了 δ(2),第二层参数与隐藏表示的梯度是:
∂W(2)∂L=δ(2)h
∂b(2)∂L=δ(2)
∂h∂L=(W(2))T
ReLU 的局部导数可用前向阶段保存的掩码表示。对 z(1)=0:
δ(1)=∂z(1)
于是第一层得到:
∂W(1)∂L=δ(1)x
∂b(1)∂L=δ(1)
若目标里有 2λ∥W(l)∥F2,最后再给相应权重梯度加上 。如果只在损失里加正则、却没有在反向实现中加入它的梯度,数值梯度检查会立刻报出系统性差异。
7one-hot 标签配合 softmax 交叉熵时,损失对 logits 的梯度是什么?
8计算 softmax 前给所有 logits 减去同一个最大值,会改变类别概率。
梯度为什么会消失或爆炸
链式法则的优势是把长计算拆成局部计算,它的风险也来自同一个地方:一条长路径上的局部导数要连乘。考虑标量化的深层链:
hl=ϕ(wlhl−1)
从第 L 层传回第 k 层时,会出现:
∂hk∂L=
若多数局部因子的绝对值小于 1,连乘随深度指数式缩小;若持续大于 1,连乘就迅速增大。在向量网络里,标量绝对值要换成雅可比矩阵的谱性质,但直觉相同。
- sigmoid 的导数最大为 0.25,进入饱和区后更接近 0;
- tanh 的导数最大为 1,饱和区同样会缩小;
- ReLU 在正区间导数为 1,但负区间为 0;
- 权重矩阵会进一步旋转和缩放梯度,不能只盯着激活函数。
实验台允许你把深度、权重尺度、预激活值和激活函数分开调节。这样可以验证:梯度问题不是由“层数多”单独决定,而是由每层局部因子的连乘共同决定;预设按钮则让消失和爆炸在同一坐标尺度上直接对照。
处理方法要对准原因
合理初始化让每层前向值和反向梯度保持可用尺度;残差连接给梯度提供更短路径;归一化方法能改善激活与优化尺度;对爆炸梯度进行范数裁剪可以限制单次更新。梯度裁剪主要控制爆炸,不能凭空恢复已经消失的信号。
还有一个常见误解:只要训练损失下降,梯度就一定健康。实际上,靠近输出的层可能仍在学习,而早期层的梯度已经接近零。调试时应按层观察梯度范数、非有限值比例和激活分布,而不是只看一个总损失。
提前看一眼时间展开
RNN 会在每个时间步重复使用同一组循环权重:
ht=ϕ(Whhht−1+
把时间步展开后,它就是一张很深、而且参数共享的计算图。早期状态的梯度要经过多个时间步的雅可比连乘,因此消失与爆炸更明显;共享参数 Whh 在多个时间点出现,最终梯度还要把每个时间路径的贡献相加。这正是 BPTT 的核心结构。
10RNN 的共享循环权重在多个时间步被使用,它的总梯度应怎样得到?
自动微分框架到底记录了什么
先把四种求导方式分清:
PyTorch 的 autograd 属于反向模式自动微分。张量操作执行时,系统同时记录产生结果的操作关系;带 grad_fn 的非叶子张量指向相应反向节点。调用标量损失的 backward() 后,引擎从输出沿图反向执行 VJP。
图是按实际执行路径建立的
动态计算图不是先把所有可能的 Python 分支都画好。每轮前向运行了哪些操作,这一轮就记录哪些操作;下一轮会重新建立新的图。因此依赖输入的控制流可以改变本轮图结构。
某些反向公式需要前向中间量。例如 y=x2 的反向需要 x,ReLU 的反向需要知道哪些输入大于 0。框架会按需保存这些张量。缓存让反向高效,也解释了训练通常比纯推理占用更多内存。
import torch
x = torch.tensor([2.0, -1.0], requires_grad=True)
w = torch.tensor([0.5, 3.0], requires_grad=True)
score = (x * w).sum()
loss = score.square()
loss.backward()
print(w.grad) # tensor([-8., 4.])
这里 score=−2,∂score∂L=2score=−4,而 ,所以 。手算只用了两个局部规则,却能给框架输出提供一条清楚的核对路径。
叶子梯度、累积与清零
默认情况下,只有 requires_grad=True 的叶子张量把梯度累积到 .grad。连续两次调用反向而不清零,第二次看到的是两次贡献之和。这支持梯度累积训练,但普通每步更新前通常要显式清零:
optimizer.zero_grad(set_to_none=True)
loss.backward()
optimizer.step()
torch.no_grad() 适合参数更新或不应记录梯度的计算;detach() 返回与原张量共享数据但脱离当前求导历史的视图。它们都会切断梯度路径,不能为了“省内存”随意插在训练主干中。
就地操作可能覆盖反向所需的值,框架会使用版本计数做正确性检查。除非确实受到内存压力并理解该操作的反向约束,优先使用非就地写法。另一个细节是 model.eval() 与 no_grad() 解决不同问题:前者切换 Dropout、BatchNorm 等模块行为,后者决定是否记录求导历史。
11自动微分就是自动选择一个很小的 ε,对每个参数做有限差分。
12下列哪些情况可能让 PyTorch 训练得到意外梯度?
实操:手写反传,再用有限差分对账
下面的程序只依赖 Python 标准库。它实现一个 3→4→3 的两层分类网络,使用 ReLU、稳定 log-softmax、交叉熵和 L2 正则;随后把 31 个参数逐个做中心差分,与手写反向传播逐项比较。
为什么要保留这样一个小例子?因为自动微分能替你执行反向规则,却不能证明你定义的自定义算子、损失归一化或广播方向符合意图。有限差分来自函数值,是一条与手写反传相对独立的验证路径。
import math
import random
random.seed(7)
x = [0.2, -1.0, 0.7]
target = 2
D, H, C = 3, 4, 3
sizes = (H * D, H, C * H, C)
theta = [random.gauss(0.0, 0.25) for _
把代码保存为 backprop_gradcheck.py 后运行:
python3 backprop_gradcheck.py
在固定随机种子和双精度 Python 浮点数下,实际运行结果为:
loss=1.279235671739
parameter_count=31
max_absolute_error=1.578e-11
relative_error=1.683e-11
worst_index=10, analytic=4.133203160459e-01, numeric=4.133203160617e-01
相对误差约为 1.68×10−11,远小于这个小例子设定的 10−8 阈值。误差没有等于零,是因为中心差分仍包含截断误差,浮点减法也会舍入。
epsilon 不是越小越好
中心差分为:
∂θi∂L≈2ϵ
ϵ 太大时,有限差分跨过了较宽区间,曲率带来截断误差;太小时,两个非常接近的损失相减会丢失有效数字。实际检查还要做到:使用双精度;关闭 Dropout 等随机性;避开 ReLU 拐点;同时看绝对误差和相对误差;对自定义高阶导数继续做二阶检查。
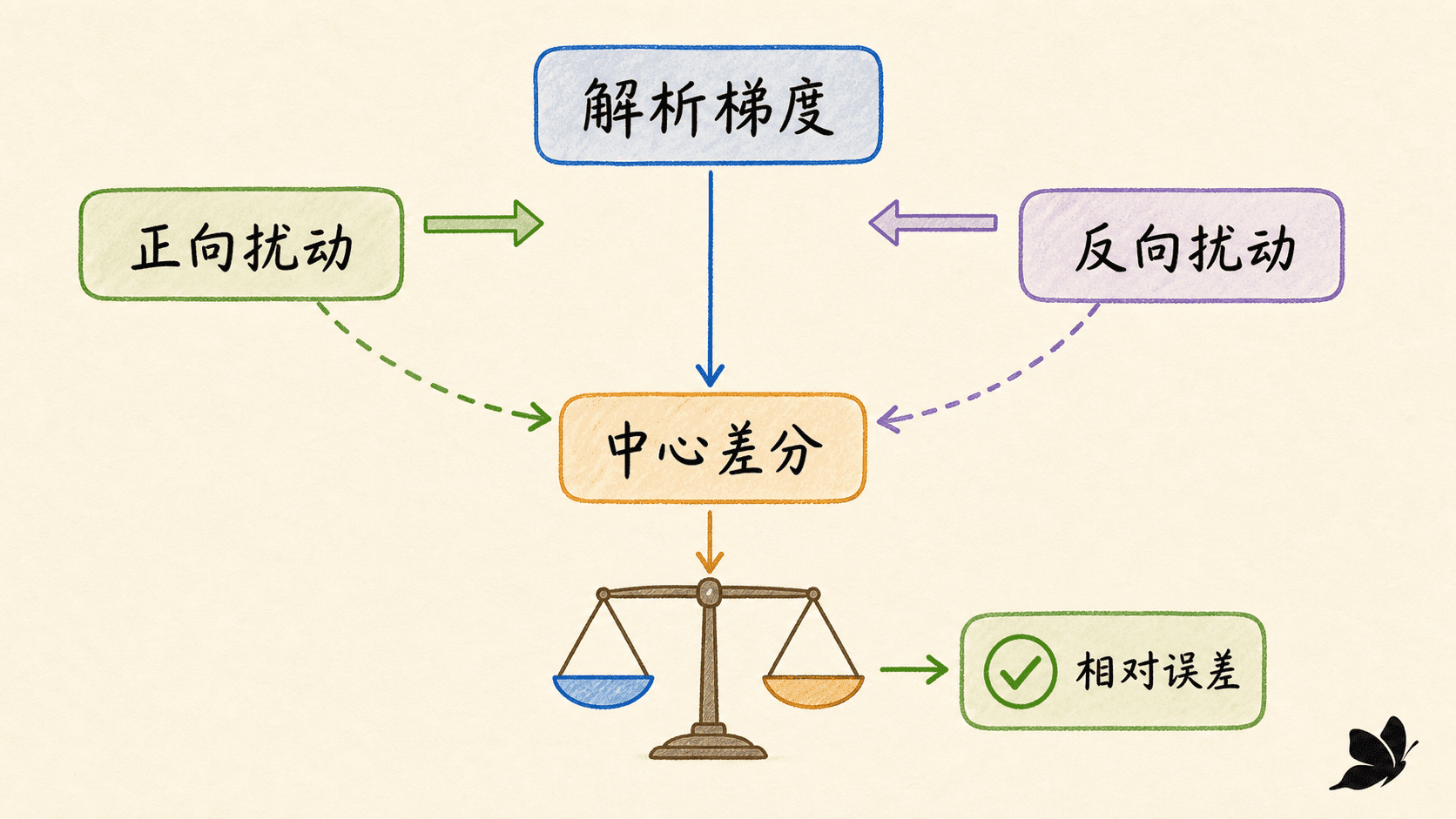
实验台的“注入错误”会故意漏掉 tanh 的局部导数。解析梯度立刻与中心差分分离,再取消错误即可恢复一致;同时拖动 ϵ 能看到步长过大与过小的两端风险。它把梯度检查从“输出一个布尔值”变成了能定位错误类型的对照实验。
13中心差分的 ε 取得极小时,误差为什么可能反而增大?
把反向传播带进时间轴
到这里,我们可以用一份固定流程排查大多数反向实现:
- 先确认优化的标量目标,尤其是 reduction、掩码、类别权重与正则项;
- 对每个操作写清输入、输出、局部导数和形状;
- 分支处求和,广播处沿被广播的维度求和;
- softmax 与交叉熵使用稳定的 log-sum-exp 形式;
- 用小规模、双精度、确定性输入做中心差分;
- 再检查每层梯度范数、非有限值和是否被意外
detach。
常见症状可以直接映射到原因:
下一篇进入 RNN 时,不需要发明一套新的微积分。把循环按时间展开,前向仍然是逐节点计算,反向仍然是 VJP 和分支求和。变化在于图更深、参数跨时间共享、总损失可能来自多个时间步:
L=t=1∑TLt
因此共享循环权重的梯度是:
∂Whh∂L=t=
每个 Lt 还可能通过后续隐藏状态间接依赖更早的 Whh。BPTT 做的正是沿这张时间展开图反向累积。截断 BPTT 则主动限制回传跨度,用更低的计算与存储成本换取对长距离梯度的近似。
15BPTT 的基本求导规则与普通反向传播不同,所以不能用计算图解释。
16同一个循环权重 W_hh 在多个时间步共享时,总损失对它的梯度需要把各时间路径的贡献 ____。
N
ℓ
(
fθ
(
xi
)
,
yi
)
+
λΩ(θ)
22
N
∇θ
ℓi
+
λθ
N
log
pθ
(
yi
∣
xi)
i=1
∑
N
log
pθ
(
yi
∣
xi
)
−
log
p
(
θ
)
]
2
u
=
−5
∂L∂L=1 −5
u=m+z 的两个局部导数都为 1,因此 ∂m∂L=−5,∂z∂L=−5。
m=xy 对 x 的局部导数是 y,对 y 的局部导数是 x。于是 ∂x∂L=(−5)(−3)=15,∂y∂L=(−5)(2)=−10。
2
+
∂x∂3x=
2x+
3
dg
(
x
)
dout×din
偏置 b∈Rdout; 输出 Z=XWT+1bT∈RB×dout。 Z,i:
in
B×din i
aj
j
eok
j
c]+
∑jeojeok=
pk−
yk
j
j
−
a
eok−a
j
∑
eoj−a
T
δ(2)
∂L
=
∂h∂L⊙
1[z(1)>
0]
T
λW(l)
∂hL∂L
l=k+1∏L
[wlϕ′(wlhl−1)]
Wxhxt+
b)
∂w∂score
=
x
∂w∂L=−4x=[−8,4] in
range
(
sum
(sizes))]
def matrix(flat, rows, cols):
return [flat[r * cols : (r + 1) * cols] for r in range(rows)]
def unpack(vector):
p0 = sizes[0]
p1 = p0 + sizes[1]
p2 = p1 + sizes[2]
return (
matrix(vector[:p0], H, D),
vector[p0:p1],
matrix(vector[p1:p2], C, H),
vector[p2:],
)
def loss_and_grad(vector, l2=1e-3):
W1, b1, W2, b2 = unpack(vector)
z1 = [sum(W1[j][i] * x[i] for i in range(D)) + b1[j] for j in range(H)]
hidden = [max(value, 0.0) for value in z1]
logits = [sum(W2[k][j] * hidden[j] for j in range(H)) + b2[k] for k in range(C)]
maximum = max(logits)
shifted = [value - maximum for value in logits]
log_normalizer = math.log(sum(math.exp(value) for value in shifted))
log_probs = [value - log_normalizer for value in shifted]
loss = -log_probs[target]
loss += 0.5 * l2 * (
sum(v * v for row in W1 for v in row)
+ sum(v * v for row in W2 for v in row)
)
dlogits = [math.exp(value) for value in log_probs]
dlogits[target] -= 1.0
dW2 = [
[dlogits[k] * hidden[j] + l2 * W2[k][j] for j in range(H)]
for k in range(C)
]
db2 = dlogits[:]
dh = [sum(W2[k][j] * dlogits[k] for k in range(C)) for j in range(H)]
dz1 = [dh[j] if z1[j] > 0.0 else 0.0 for j in range(H)]
dW1 = [
[dz1[j] * x[i] + l2 * W1[j][i] for i in range(D)]
for j in range(H)
]
db1 = dz1
grad = (
[v for row in dW1 for v in row]
+ db1
+ [v for row in dW2 for v in row]
+ db2
)
return loss, grad
def central_difference(vector, eps=1e-5):
numeric = []
for index in range(len(vector)):
plus, minus = vector[:], vector[:]
plus[index] += eps
minus[index] -= eps
numeric.append(
(loss_and_grad(plus)[0] - loss_and_grad(minus)[0]) / (2.0 * eps)
)
return numeric
loss, analytic = loss_and_grad(theta)
numeric = central_difference(theta)
absolute = [abs(a - n) for a, n in zip(analytic, numeric)]
numerator = math.sqrt(sum((a - n) ** 2 for a, n in zip(analytic, numeric)))
denominator = (
math.sqrt(sum(a * a for a in analytic))
+ math.sqrt(sum(n * n for n in numeric))
)
relative = numerator / max(denominator, 1e-12)
worst = max(range(len(theta)), key=absolute.__getitem__)
print(f"loss={loss:.12f}")
print(f"parameter_count={len(theta)}")
print(f"max_absolute_error={max(absolute):.3e}")
print(f"relative_error={relative:.3e}")
print(
f"worst_index={worst}, "
f"analytic={analytic[worst]:.12e}, numeric={numeric[worst]:.12e}"
)
assert relative < 1e-8
L(θ+ϵei)−L(θ−ϵei)
1
∑
T
∂Whh∂Lt