神经网络知识回顾
前面两篇里,我们已经把词变成了向量。可是,词向量只回答了“输入如何表示”,还没回答“这些表示怎样变成预测”。例如,“例子很具体”和“例子太空洞”都可以被表示成一组数字,但情感标签不会自动从向量里跳出来。
这一篇做的事,就是把中间的桥搭好:我们先回到统计学习的基本问题,再从线性分类器走到多层前馈网络,然后把激活函数、交叉熵、优化和正则化串成一个能够实际运行的训练闭环。下一篇再专门拆解:这个闭环里的梯度,究竟怎样通过反向传播被计算出来。
本篇中的“神经元”可以当成一个可学习的数学函数。这个名称来自启发式类比,不意味着工程中的前馈网络在精确模拟大脑。
先把学习问题说清楚
神经网络不是一个脱离统计学习的孤立工具。它仍然在处理同一个基本问题:给定带标签的样本 ,学到一个参数化函数 ,让它对没见过的输入也能作出合理预测。
在文本分类里, 可以是词袋、字符 n-gram、词向量的聚合,也可以是更复杂的句子表示; 可以是“正向/负向”、主题类别,或者每个词的词性标签。数据表示决定模型能看见什么,学习算法则决定它如何从这些可见信号里调整参数。
得分、分界面与间隔
先看二分类。线性模型为输入计算一个实数得分:
得分大于 时预测正类,小于或等于 时预测负类。 是决策边界;在两维特征空间里是一条直线,在更高维里是一个超平面。
如果多条边界都能分开训练样本,我们不只关心“现在分对了没有”,还关心样本离边界有多远。对 ,带符号的得分 越大,该样本分对且离边界越远。更大的间隔通常对输入中的小扰动更稳定。这就是为什么“训练集全对”仍然不足以选出一条好边界。
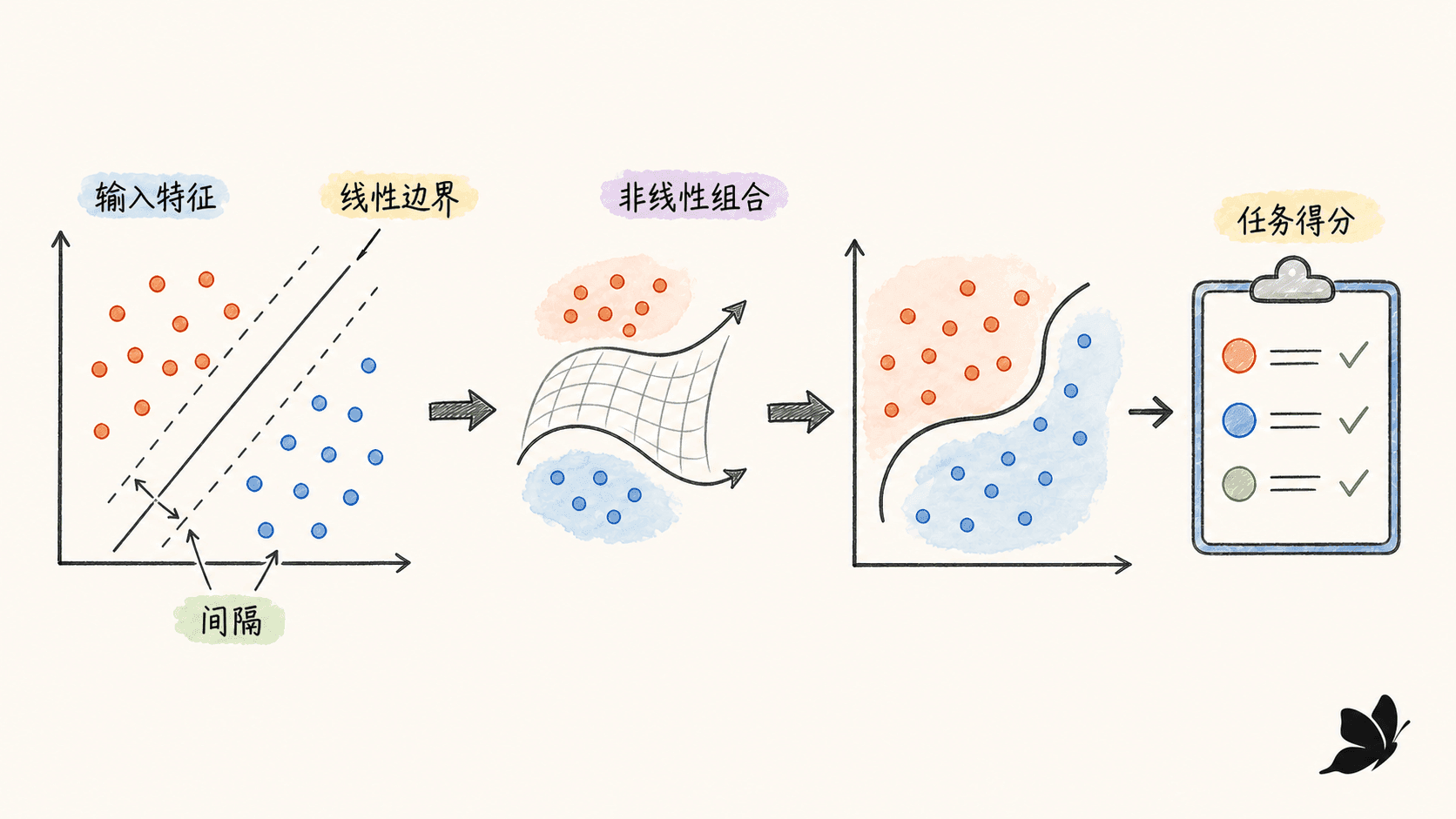
训练集、验证集和测试集不能混用
训练集用来估计 ;验证集用来选学习率、正则强度、隐藏层宽度等超参数;测试集只在方案确定后评估一次。如果我们根据测试结果反复修模型,测试集就已经间接参与了训练,最终分数会过于乐观。
文本数据还有一个容易被忽略的问题:随机切分不一定足够。同一用户的高度相似文本、同一新闻事件的转载,如果同时出现在训练集和验证集,会造成数据泄漏。更接近真实上线环境的做法是按用户、时间或来源分组切分。
生成式与判别式:建模对象不同
生成式模型通常分解联合分布:
它先描述每个类别怎样“产生”输入,再用贝叶斯公式得到 。朴素贝叶斯文本分类就是一个典型例子:它会估计不同类别下各个词的出现概率。
判别式模型直接学 或一个能排序类别的得分函数。逻辑回归、大多数文本分类神经网络属于这个视角。它们不必为输入本身建立完整概率模型,而是集中处理决策。
两者不是“旧与新”的区别。当输入生成机制的假设合理、标注少或需要处理缺失变量时,生成式视角很有用;当特征复杂、最终目标就是预测 时,直接的判别式训练往往更方便。
MLE 与 MAP:损失函数背后的概率视角
假设样本独立,最大似然估计(MLE)选择让观测数据最可能出现的参数:
最大后验估计(MAP)还加入参数先验 :
如果对权重使用以 为中心的高斯先验, 会导出与 同形的惩罚。所以“概率估计”和“正则化损失”并不是两套互不相干的语言。
试着拖动实验台里的 、 和 。你会看到:“训练点分对”只是一个条件,边界轻微旋转就可能让最近样本翻转。间隔显示的正是这种对扰动的缓冲空间。
1
两条直线都能正确分开训练样本时,为什么通常更偏好最小间隔更大的那一条?
2
下列哪些操作会让测试分数变得过于乐观?
从感知机到多层前馈网络
感知机做了两件事
感知机先用仿射变换将多个输入压成一个得分,再用阈值函数作决策:
它分错一个样本时,可以沿着让该样本得分变正确的方向更新:
这个规则非常直接:如果正样本被分错,就把 向 推一点;如果负样本被分错,就往反方向推。但它的决策边界仍是一个超平面。当任务需要 XOR 这样的弯曲或分段边界时,一个线性得分不够用。
多层不是简单地“多乘几个矩阵”
一个单隐藏层前馈网络可以写成:
其中 ,,,,。 里的 个数是各类别的 logits,也就是尚未归一化的得分。
如果拿掉 ,那么两层只是:
它仍然可以合并成一次仿射变换。隐藏层之所以有意义,关键是层与层之间的非线性函数 。它让不同隐藏单元在输入空间中响应不同区域,后一层再将这些局部响应组合起来。
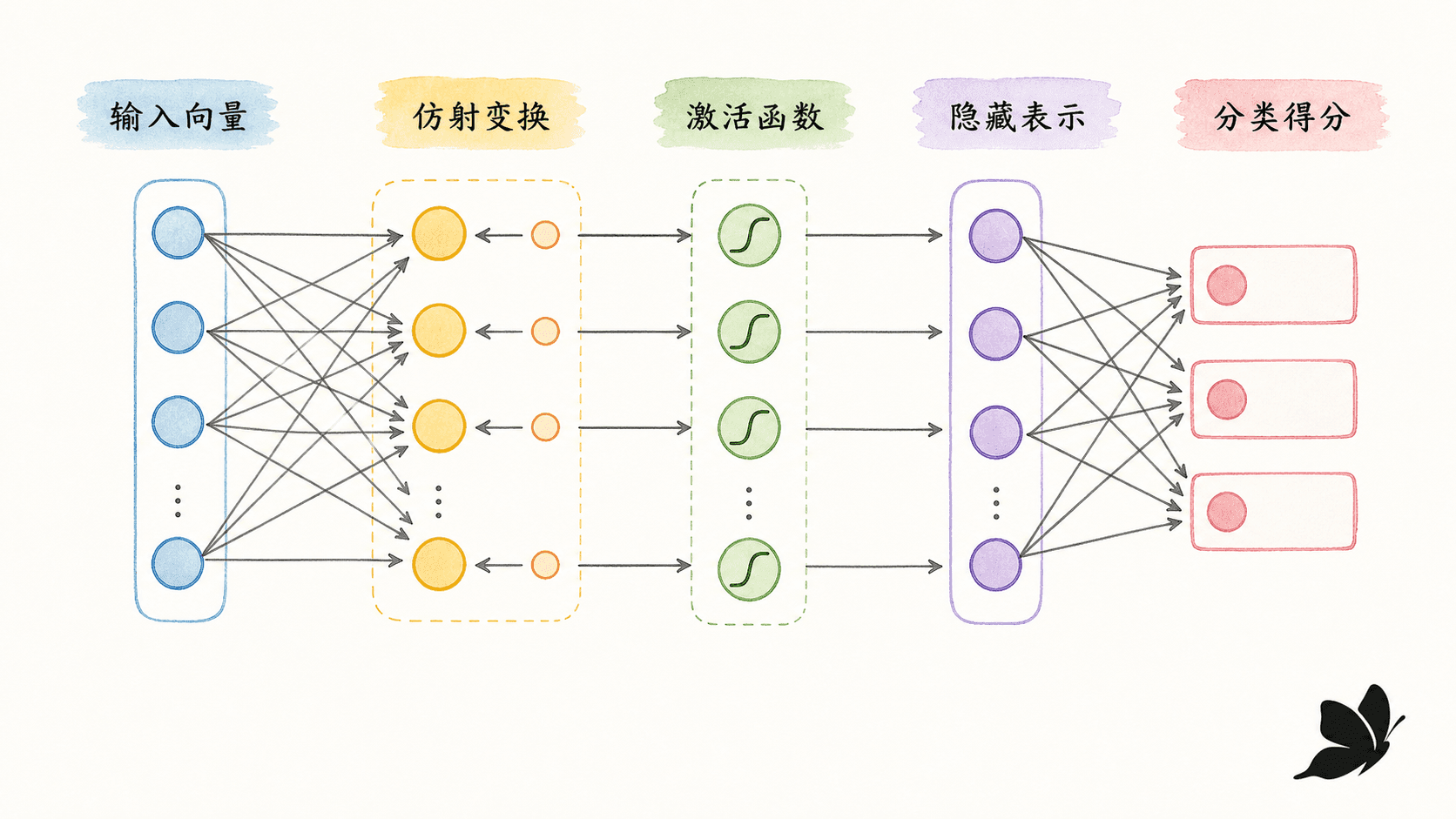
在 NLP 里,隐藏层学的是任务所需的组合
假设我们把一句话的词向量平均后作为 。隐藏层中的一些单元可能对正面用语响应,一些对否定线索响应,还有一些对领域词响应。这种解释只是直观,真正的隐藏维度常常是分布式的,不会每一维都对应一个干净的人类概念。
语音识别也能看到同一框架。输入是连续的声学特征,网络可以为音素或状态输出得分;这些得分再与语言模型和搜索结合,得到词序列。文本分类、序列标注和语音识别的输入形式不同,但都在学习“表示 任务得分”这个映射。
更宽或更深不会自动带来更好的测试效果。网络容量增加后,训练误差可能下降,但数据量、初始化、优化和正则化没有跟上时,验证误差反而会上升。
3
在多层前馈网络中,只要堆叠足够多的线性层,即使不使用激活函数,也能得到任意弯曲的决策边界。
4
一个输入维度为 100、隐藏维度为 32 的线性层,按 PyTorch Linear(out, in) 权重存储约定,权重矩阵的形状是 ____。
激活函数决定信号怎样穿过网络
激活函数有两个同时发生的作用。向前看,它改变模型能表示的函数形状;向后看,它的导数会进入链式法则,决定梯度被保留、放大还是压小。
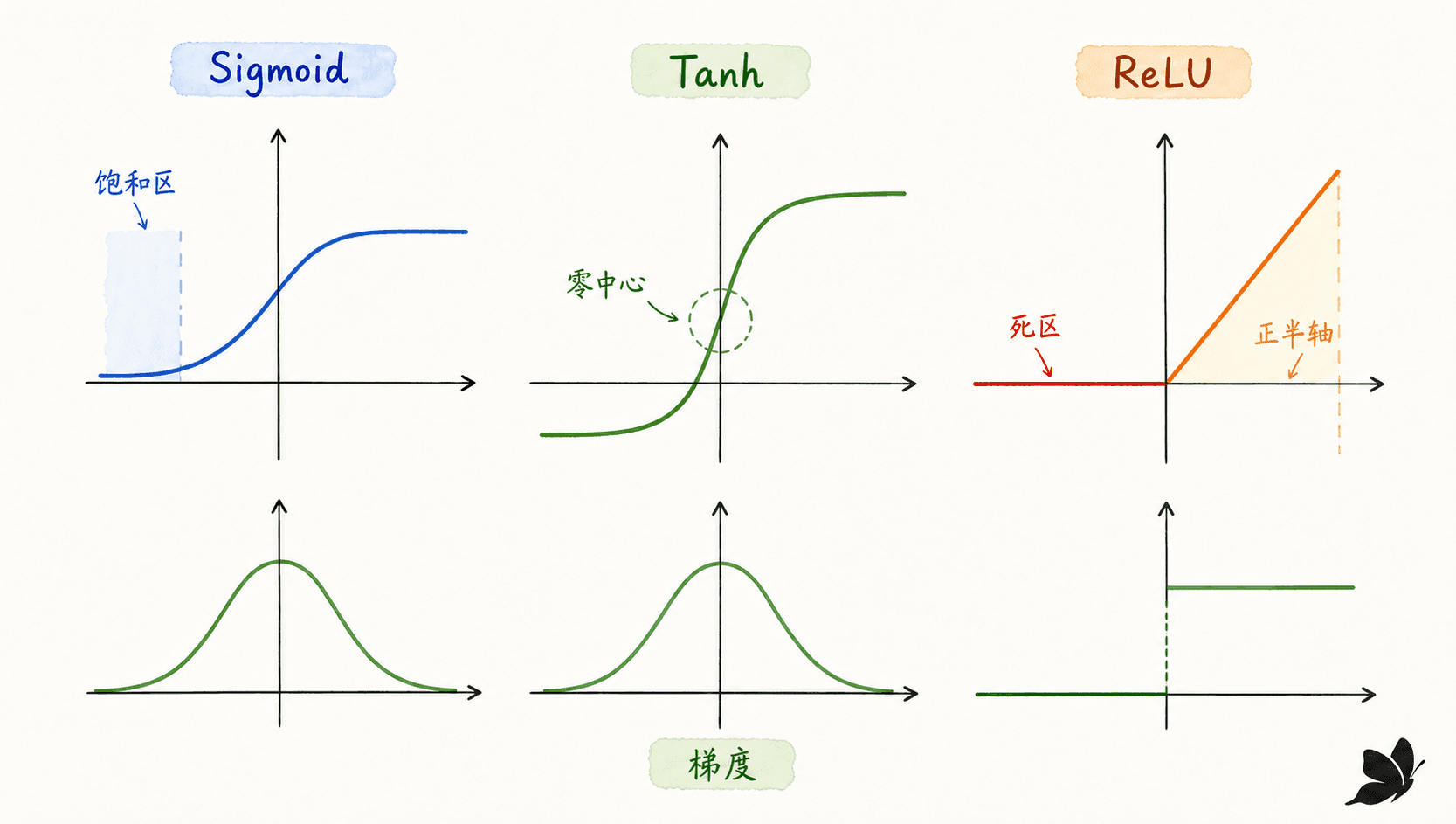
Sigmoid:适合概率门,不是默认隐藏层
Sigmoid 把实数压到 ,因此很适合表示一个二元门值或二分类概率。但当 很大时,输出接近 或 ,导数接近 。深层网络中连续相乘这些小导数,前面层得到的更新信号就会非常弱。
Tanh 把输出改到 ,零中心性比 Sigmoid 更好,但两端同样会饱和。所以这两个函数仍然常出现在需要有界门值的地方,却通常不是普通前馈隐藏层的首选。
ReLU:简单、分段线性,但有死区
当 时,ReLU 的导数为 ,不会像饱和函数那样不断压小正半轴上的梯度。当 时,输出和导数都为 。这会产生稀疏激活,也可能让一个单元长期停在负半轴,得不到更新,俗称“死 ReLU”。
Leaky ReLU 在负半轴保留一个小斜率;GELU 则用平滑门控根据输入大小调节通过比例。在普通小型 MLP 里,ReLU 仍然是很好的默认起点;当负区域信号很重要或发现大量单元长期为零时,再考虑变体。
输出层要由任务决定
“二分类”和“多标签”容易混淆。如果每个样本只能在猫、狗、鸟中选一个,这是单标签多分类,类别之间竞争;如果一篇文档可以同时属于“科技”和“财经”,每个标签是独立二元判断,应用多个 sigmoid 语义。
初始化要尽量保住各层的尺度
如果初始权重太小,信号和梯度逐层缩小;如果太大,激活值可能爆炸,或把 Sigmoid/Tanh 推入饱和区。Xavier 初始化根据输入和输出单元数量调整方差,常用于双侧近线性的激活;Kaiming 初始化显式考虑 ReLU 截断负半轴的特点。
对标准正态分布的简化表达是:
这些规则是一个更可控的起点,不是“用了就一定能训好”的保证。网络结构、归一化、学习率和数据尺度仍然会影响信号传播。
把输入拖到很大的正值或负值,比较 Sigmoid、Tanh 和 ReLU 的导数。这个实验能把“饱和”从一个词变成可观察现象:函数曲线越平,局部导数越小,向前层传的学习信号也越弱。
5
下列哪些现象可能让深层网络前面层的梯度变得很小?
6
一个隐藏层使用 ReLU 的前馈网络,哪个初始化通常是更匹配的起点?
交叉熵把分类错误变成可优化的数字
网络前向计算最后得到 logits 。logit 只表示相对偏好,它可以是负数,也不要求总和为 。Softmax 把它们变成条件概率:
给所有 logits 同时加上同一常数,softmax 结果不变。因此实现时可以先减去 ,避免对很大正数求指数而溢出:
交叉熵关心正确类别被分配了多少概率
对 one-hot 标签 ,单个样本的多分类交叉熵是:
模型给正确类别的概率越接近 ,损失越接近 ;如果它极度自信地选错, 接近 , 会变得很大。这个性质让“自信的错误”收到更强信号。
把所有样本的交叉熵加起来,就是分类条件分布的负对数似然。最小化交叉熵,等价于最大化正确标签在训练数据上的条件似然。这也把前面的 MLE 和神经网络损失连到了一起。
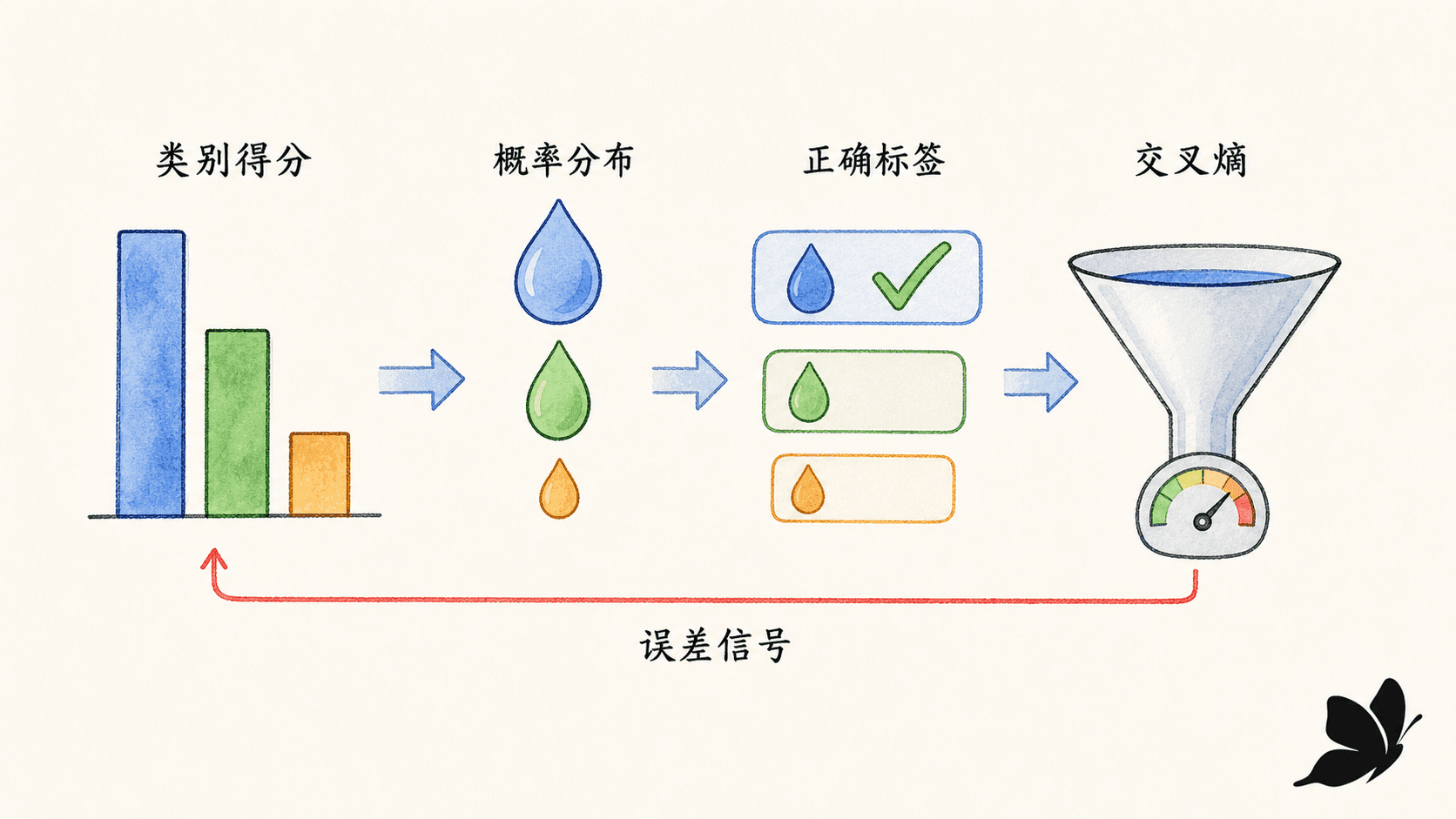
Softmax 和交叉熵组合后,梯度有很直观的形式
对每个 logit :
正确类别上,,梯度 会把它的 logit 向上推;其他类别上,,梯度 会把过高的错误 logit 向下压。预测越错且越自信,这个差异越大。
这也解释了为什么分类问题通常不直接对 softmax 概率使用均方误差。MSE 不是绝对不能用,但它与分类的似然结构不如交叉熵直接,且梯度还会受到概率变换导数的额外缩放。
PyTorch 中要把原始 logits 交给损失函数
nn.CrossEntropyLoss() 等价于数值稳定的 LogSoftmax + NLLLoss。模型的 forward 应返回 logits,不要先手动调用 softmax。在单一 logit 的二分类中,BCEWithLogitsLoss 同样把 sigmoid 和二元交叉熵合并起来,用 log-sum-exp 技巧提高数值稳定性。
不要将 softmax(model(x)) 传给 CrossEntropyLoss。这会把已经压缩过的概率再当成 logits 处理,既改变优化问题,又失去融合实现的数值稳定性。推理或展示概率时,再对 logits 做 softmax。
试着保持正确类别不变,只拉大两个 logits 的差。你会看到概率变得更尖锐;如果尖锐方向与标签一致,损失下降,反之则快速上升。然后同时给所有 logits 加同一个数,验证概率和损失都不变。
7
模型对三个类别输出 logits。使用 CrossEntropyLoss 训练时,forward 最后一步应该怎样做?
8
给每个 logit 同时加上 100,softmax 概率与交叉熵都不会改变。
优化器如何把梯度变成参数更新
到这里,我们已经有了一个可微的损失 。梯度 指向局部增长最快的方向,所以最基本的梯度下降沿负梯度走:
是学习率。太小时每次只移动一点,训练缓慢;太大时可能跨过低谷,在两侧震荡甚至发散。学习率不是“步数越大走得越快”那么简单,因为每步方向只是当前位置的局部信息。
为什么用 mini-batch
全批量梯度每次使用全部训练数据,方向稳定,但数据大时一步很贵。单样本 SGD 每看一条数据就更新,噪声大,却能频繁移动。Mini-batch 每次取 个样本,是并行计算、内存占用和梯度噪声之间的折中:
批量大小改变后,梯度噪声、每轮更新次数和适合的学习率都可能改变。因此不应只为了占满内存而无限放大 batch。
动量用历史方向平滑震荡
当一个方向连续保持一致,动量会积累速度;当另一个方向来回改变符号,正负分量会相互抵消。在狭长损失峡谷里,这能减少横向摇摆,加快沿峡谷的前进。
Adam 为不同参数维度调整步长
Adam 同时维护梯度的一阶矩和二阶原点矩的指数移动平均:
初期 和 都从 开始,因此需要做偏差修正:
平方梯度历史较大的维度,分母更大,实际步长被压小;稀疏或长期梯度较小的维度,则能保留较大的相对更新。这对大词表、稀疏特征很常见的 NLP 任务很方便。
但“Adam 前期损失下降快”不等于“它在每个任务上都泛化最好”。优化速度与最终测试效果是两个问题,仍需用验证集比较。
PyTorch 训练四步要理解顺序
python
optimizer.zero_grad(set_to_none=True) # 清掉上一轮累积的梯度
logits = model(features) # 前向计算
loss = criterion(logits, labels) # 得到标量损失
loss.backward() # 为参数计算梯度
optimizer.step() # 用优化规则更新参数PyTorch 默认会把梯度累加到 .grad 中,所以普通训练每轮需要先清梯度。有意设计的梯度累积是例外,但那时也必须同时处理损失缩放和更新频率。
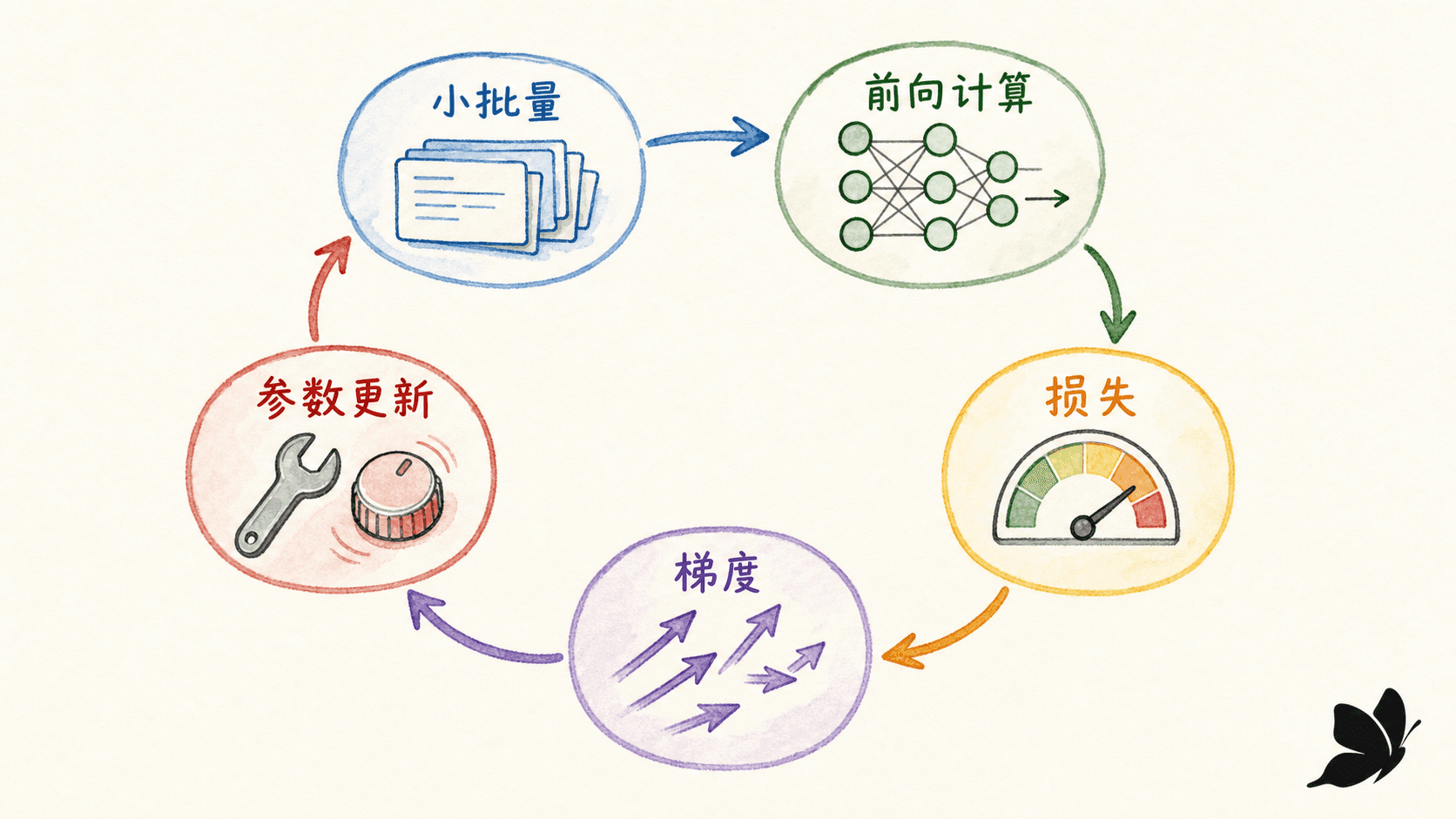
把学习率调到较大,比较 SGD、动量和 Adam 的轨迹;再打开梯度噪声,观察历史平滑如何改变路径。这个实验不用来证明哪个优化器“永远最好”,而是帮你看到:优化器除了当前梯度,还可以携带哪些历史状态。
9
为什么普通 PyTorch 训练循环需要在每次 backward 前清理梯度?
10
学习率过大时,下列哪些现象是合理的诊断信号?
正则化与泛化:不要只把训练集背下来
一个参数很多的网络,可以将小型训练集拟合到几乎零损失。这只说明它有足够的容量记住已见样本,不说明它学到了新样本上稳定的规律。
泛化问题不只由模型容量决定。标签噪声、重复样本、领域变化、训练与上线的时间差异,都可以让验证指标失真。正则化能缓解其中一些问题,却不能修复错误的数据切分或严重的领域偏移。
权重惩罚与权重衰减
一个常见目标是在数据损失上加 惩罚:
这会鼓励模型使用较小权重,降低对某些单一特征的极端敏感性。 太小时约束不足,太大时参数被过度拉向零,训练与验证表现都可能变差。正确问题不是“要不要正则”,而是“当前数据量和模型容量下,约束多强”。
对普通 SGD,在适当缩放下,把 惩罚的梯度加到更新里,与每步直接缩小权重可以对应。对 Adam 这类自适应优化器,两者不再等价,因为惩罚梯度会进入一阶、二阶状态。AdamW 将权重衰减从梯度的自适应更新中解耦:
这是文本模型中常选 AdamW 而不是把“Adam + L2”当成完全同义词的原因。
Dropout 在训练和推理时行为不同
训练时,Dropout 以概率 将激活置零。PyTorch 使用 inverted dropout:保留下来的激活同时除以 ,使训练期的期望尺度与推理期接近。评估时 model.eval() 关闭随机丢弃,使用完整网络。
这个噪声机制让模型不能始终依赖同一组隐藏单元,但 Dropout 不是越大越好。在小网络、小数据或已经有强正则的场景中,过大 会直接丢掉过多信号,导致欠拟合。
早停要看验证指标,不是看训练损失
一个典型过拟合轨迹是:训练损失继续下降,验证损失却已经回升。早停会保存验证指标最好的参数,并在连续若干轮没有改善后停止。这个“容忍轮数”很重要,因为 mini-batch 噪声会让验证指标短暂波动。
验证时要同时做两件事:调用 model.eval() 切换 Dropout 等模块的行为,并在 torch.no_grad() 中运行,避免为不需要反向传播的计算保留图。二者作用不同,不能相互替代。
文本分类的失败边界常在数据而不在网络层数
情感分类特别容易受否定、转折和领域影响。“画面不可预测”对电影可能是表扬,对方向盘却是严重批评;“并不难用”含有负面字词,整体却是正向。如果训练数据没有这些结构,只增加隐藏层宽度,往往只是更有能力记住已见模式。
11
调用 torch.no_grad() 就会自动关闭 Dropout,因此验证时不再需要 model.eval()。
12
训练准确率接近 100%、上线表现却很差时,哪些是应优先检查的原因?
实操:训练一个微型中文情感分类器
下面的实验故意保持小规模,让你能在 CPU 上快速跑完,也能看清整条链路。它使用字符 unigram 和 bigram 建词表,把每条文本变成一个多热向量,再交给带单隐藏层的 MLP。
这里不依赖额外的分词包或已弃用的文本教程 API。字符 n-gram 不能完整理解句法,但它能保留“解释清楚”这类局部片段,比单纯字符计数多一点组合信息。
完整代码
python
import random
from collections import Counter
import torch
from torch import nn
SEED = 7
random.seed(SEED)
torch.manual_seed(SEED)
train_data = [
("课程讲得清楚容易跟上", 1),
("这个工具稳定又省时间", 1),
("界面简洁操作顺手", 1),
如何运行与观察
将代码保存为 train_tiny_sentiment.py,在已安装 Python 3.10+ 和 PyTorch 的隔离环境中运行 python train_tiny_sentiment.py。先看第 1 轮与后续轮次的损失,确认优化器确实改变了参数。
比较 train_acc 和 valid_acc。训练集很小,训练准确率很快达到 1.00 并不意外;真正应关心的是验证样本是否保持正确,以及换一批表达方式后是否仍然稳定。
观察两条自定义文本。第一条复用了“解释清楚”和“例子具体”等已见局部模式,通常容易判为正向。第二条含有“难用”和“慢”,但它们都被否定;小模型很可能仍判为负向。
实际结果应该怎样解读
在固定随机种子的 CPU 运行中,这份代码的训练和验证准确率都达到了 1.00,第一条自定义文本被判为正向。但否定句“并不难用,响应也不慢”被判为负向,输出的正向概率约为 0.006。
这个结果比一个完美的演示更有教学价值。它说明三件事:
- 代码链路运行正常,不代表任务已经解决。
- 四条验证样本全对,不代表验证集覆盖了真实语言变化。
- 网络只能利用输入表示中保留的线索。字符 n-gram 看得见“不难”,却不自动拥有一套稳定的否定作用域机制。
你可以继续做三个对照实验:去掉隐藏层,看线性模型的边界;把 ReLU 换成 Tanh,比较收敛速度;把 weight_decay 设为 0,再扩大隐藏层,比较训练与验证曲线。每次只改一个因素,否则无法判断结果变化来自哪里。
下一步:打开 loss.backward()
现在我们已经能解释前向计算、交叉熵和优化器,但训练循环里还有一个黑箱:loss.backward() 如何为每一层的矩阵和偏置计算梯度?
下一篇会从计算图和链式法则出发,手算一次两层网络的局部导数,再把它们与 PyTorch 自动求导的 .grad 对上。到那时,“训练”就不再是五行代码的固定仪式,而是一条能够逐节检查的数学链路。
13
微型分类器在四条验证样本上全部正确,却把‘并不难用,响应也不慢’判为负向。最合理的结论是什么?
14
为了让这个教学实验更可信,下列哪些改造是有意义的?