从词串到语法树:句法分析的结构、算法与排错
“我看见了拿望远镜的人”并不只是一串按顺序排开的词。我们还会自然地追问:拿望远镜的是“我”还是“人”?“拿望远镜的人”能不能整体替换成“他”?“我”和“人”分别跟哪个谓词发生关系?这些问题都在寻找同一件东西:词序背后的结构。
句法分析把一个词序列映射为结构化结果。结果可以是嵌套的成分树,也可以是词与词之间的依存树。真正困难的地方不只是画出一棵树,而是同时处理三件事:输入边界可能有歧义,同一句话可能允许多种结构,模型输出还必须满足全局约束。
这一节我们从切分边界出发,依次走过成分、依存、CFG、PCFG、CKY、移进归约、依存图校验和错误分析。你会看到,现代神经网络改变了“怎样给结构打分”,却没有消除“什么结构才合法”和“怎样判断它错在哪里”这两个问题。
分词一变,句法问题就换了
解析器通常接收词元序列 。这个写法很容易让人误以为 已经客观存在,只等算法来连接。实际不是这样。中文没有天然空格边界,英文缩写、连字符、多词表达也可能改变 token 的定义。边界一变,树的节点数、候选跨度、父节点编号都会跟着变。
看一句有意制造歧义的话:
乒乓球拍卖完了
可以切成“乒乓球拍 / 卖 / 完 / 了”,此时“乒乓球拍”是被卖完的东西;也可以切成“乒乓球 / 拍卖 / 完 / 了”,此时“拍卖”被当作谓词。后续解析器面对的已经不是同一道题:前一种切分要寻找名词短语与“卖”的关系,后一种切分要以“拍卖”为谓词组织论元。
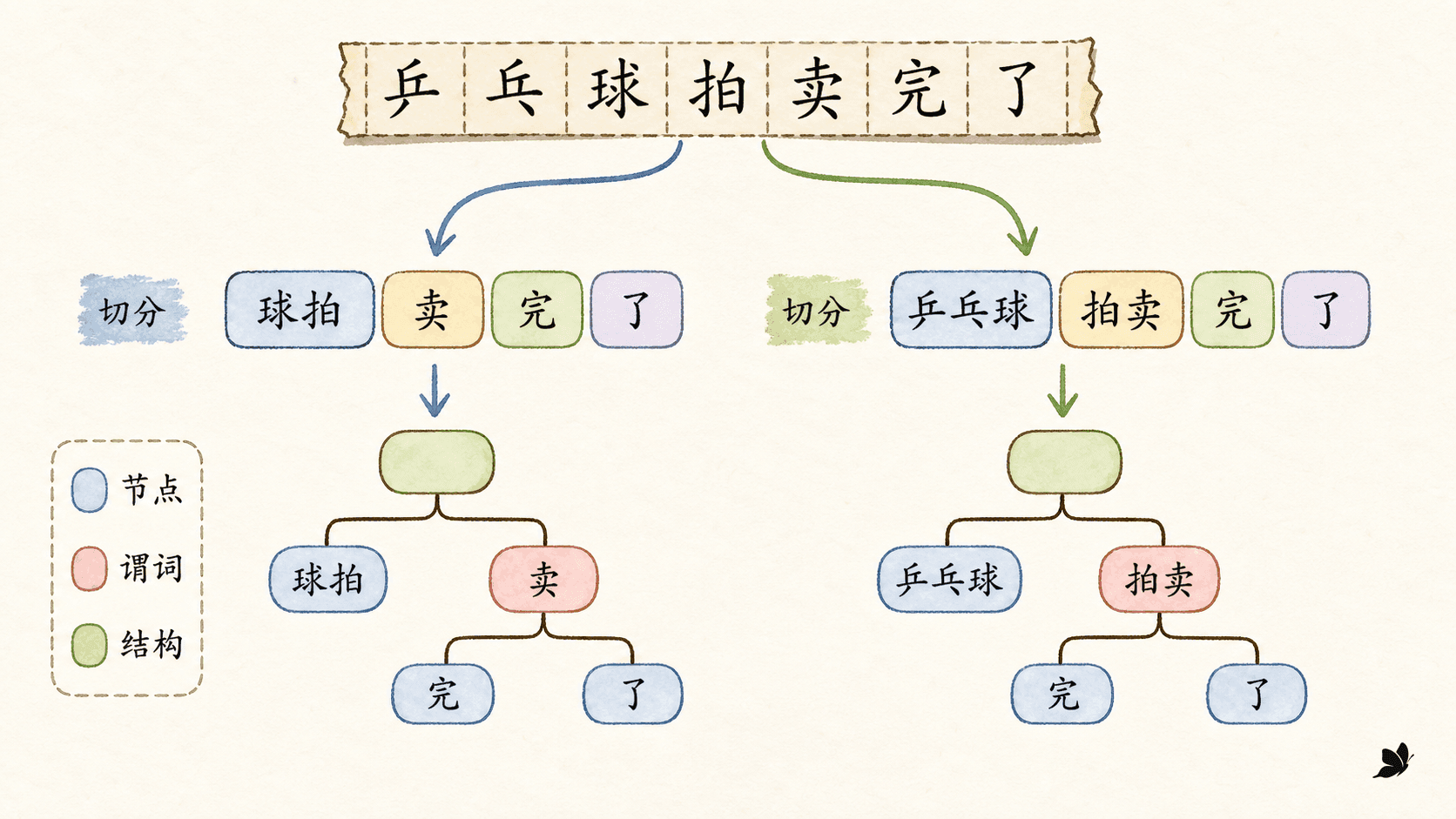
这也解释了为什么错误分析应当从输入开始。假如最终宾语挂错了,先别急着把责任全部推给依存解码器。应按顺序检查:
- 句界是否正确,两个句子有没有被粘在一起。
- 分词是否符合任务定义,多词表达有没有被错误拆开。
- 词性和形态特征是否合理,因为它们常被解析器直接使用。
- 在输入边界正确的前提下,再看跨度、父节点和关系标签。
这种检查顺序有一个实际好处:上游边界错位会让后续所有 token 编号错位。此时逐条修依存弧只是在修症状,无法恢复可比较的结构。
金标准分词下的解析分数和原始文本端到端分数回答的是两个问题。前者主要衡量结构模型,后者还包含句界、分词、词性和形态分析的误差。比较系统时必须先确认输入条件相同。
1
把‘乒乓球拍卖完了’从‘乒乓球拍 / 卖 / 完 / 了’改成‘乒乓球 / 拍卖 / 完 / 了’,最先发生的结构变化是什么?
2
端到端依存解析出现大量父节点错位时,哪些项目应在分析解码器前检查?
成分树和依存树在回答不同问题
成分分析问的是“哪些连续片段组成更大的单位”。在“那只黑猫追鱼”里,“那只黑猫”可以整体替换成“它”,内部又能分成限定成分和中心名词。成分树用 NP、VP、S 等非终结符把这种嵌套关系显式写出来:叶子是词,内部节点是片段类别,根节点覆盖整句。
判断一段词是不是成分时,常用替换、移动、省略、并列等检验。例如,“那只黑猫追鱼”中的“那只黑猫”可以替换为“它”;“追鱼”可以与“喝水”并列。这些检验提供证据,却不是跨语言、跨句式都成立的机械判据。口语省略、固定搭配或语序限制都可能让单一检验误导我们。
依存分析换了一个坐标系。它不增加 NP、VP 这样的短语节点,而是给每个词寻找中心词,并给连接标上语法功能。以“那只黑猫追鱼”为例,“追”可作句根,“猫”通过 nsubj 依赖“追”,“鱼”通过 obj 依赖“追”,“黑”则修饰“猫”。
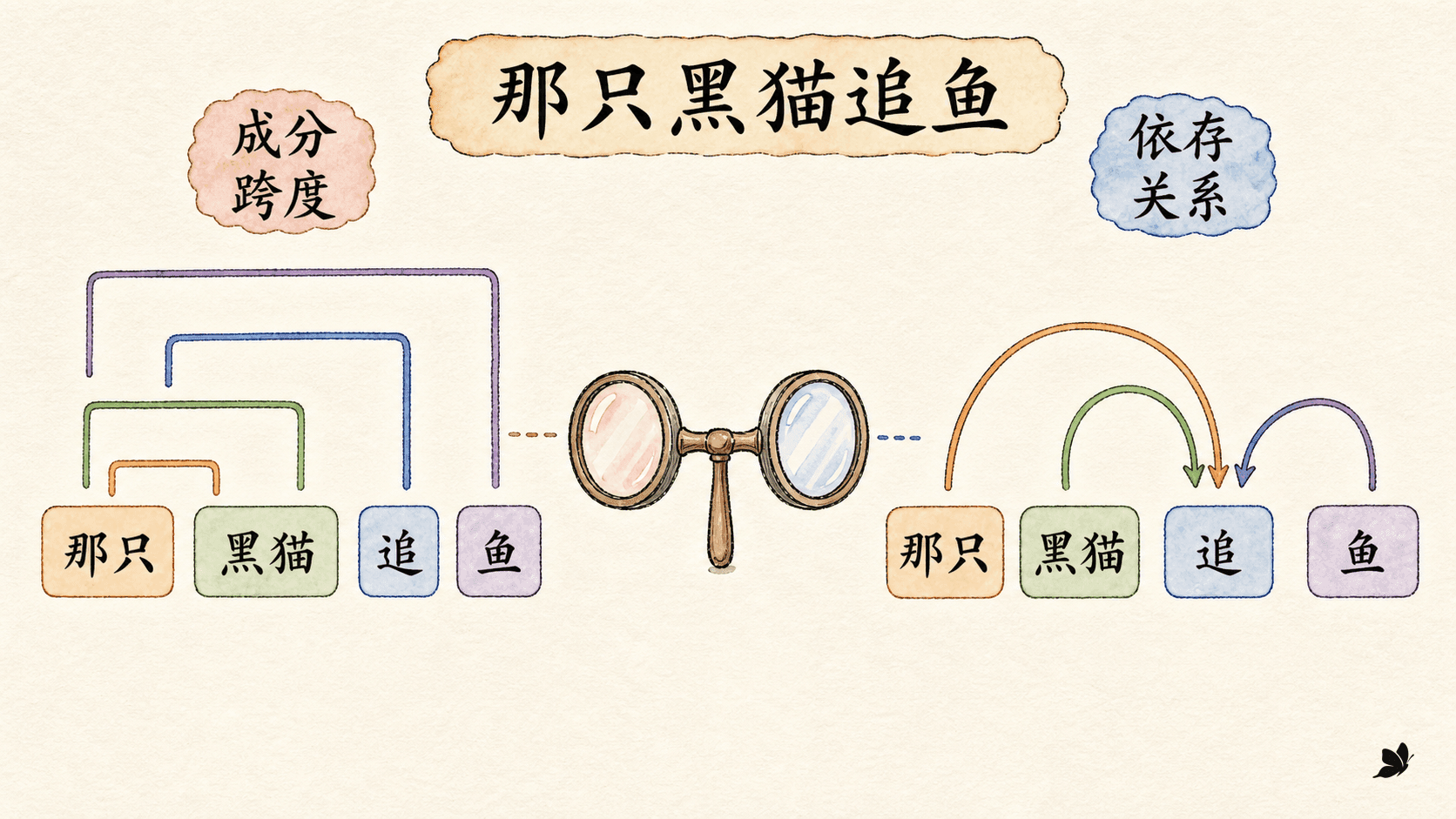
两种表示适合回答不同问题:
在 Universal Dependencies 的基本表示中,恰有一个词连接到抽象 ROOT,其余每个词都依赖句中另一个词,因而得到一棵树。增强依存会为省略、共享论元或并列传播补充边,这时结果可以是一般有向图。看到“依存表示”四个字时,要先确认讨论的是基本树还是增强图。
成分树和依存树不是“旧表示”与“新表示”的关系。它们保留的信息不同。成分转依存需要中心词规则,依存转成分也要补回片段类别和层级;转换可以实用,但通常不是无损的。
3
依存分析不含 NP、VP 这类短语节点,所以它无法表示主语和宾语。
4
如果任务要精确抽取文本中所有名词短语的起止位置,哪种表示通常最直接?
CFG 给出合法空间,PCFG 负责排序
上下文无关文法把“什么结构允许出现”写成产生式。一个 CFG 可以记为 : 是非终结符集合, 是终结符集合, 是规则集合, 是开始符号。下面这组小规则能生成“这猫追那鱼”:
text
S → NP VP
VP → V NP
NP → Det N
NP → N
Det → 这 | 那
N → 猫 | 鱼
V → 追规则同时定义了搜索空间和树的解释。NP → Det N 表示限定词与名词能组合成名词短语;S → NP VP 表示句子由主语名词短语和谓语短语组成。若从 出发能推导出完整词串,句子就被这份文法接受。
问题在于,自然语言经常允许多个推导。“我看见拿望远镜的人”中的工具短语可以挂到“看见”,也可能属于“人”的修饰语。CFG 可以保留两种候选,却没有依据选出当前语境更合适的一个。
PCFG 为同一左部的每条规则加概率,并要求它们归一化:
一棵树的分数通常取所用规则概率的乘积:

在监督训练里,一个直接做法是统计树库中同一左部规则的相对频率。例如 NP 共展开 100 次,其中 70 次使用 NP → Det N,就可先估计为 0.7。这个方法简单,也能和动态规划自然结合。
但朴素 PCFG 有一个重要限制:某条规则的概率只看它的左部,默认不关心更高层父节点、词汇中心和更远的上下文。NP → N 在主语位置和宾语位置被当成同一个事件;介词短语偏向某个动词还是名词,也很难由粗粒度规则独自决定。词汇化、细分非终结符、判别模型和神经编码器,都是在补充这部分上下文。
5
CFG 与 PCFG 在句法分析中分别能直接提供什么?
6
朴素 PCFG 容易在介词短语附着上失误,最直接的原因是什么?
CKY 如何把指数搜索压进一张表
如果分别枚举每棵候选树,重复子结构会迅速淹没计算。CKY 的关键不是“更快地枚举”,而是把相同跨度的中间结果只算一次。对于 个词,它建立上三角表;单元格 保存能覆盖 的非终结符及其最佳分数。
标准 CKY 要求文法接近 Chomsky 范式:非词汇规则形如 ,词汇规则形如 。计算顺序必须先短跨度、后长跨度。Viterbi PCFG 的核心递推是:
这里的 是切分点。只要 覆盖左半段、 覆盖右半段,并存在规则 ,就能把它们组合成 。每个单元格还要保存回溯指针,最后才能从 还原整棵树。一元规则不能随便按文件顺序扫一遍,而要计算一元闭包,直到没有新类别或更优分数出现。
先把每个词能充当的词类放入长度为 1 的格子。例如“这”得到 Det,“猫”得到 N,并通过 NP → N 补上 NP。
再枚举长度为 2 的跨度和其中的切分点。Det + N 遇到 NP → Det N,于是“这猫”所在格子得到 NP。
按跨度长度继续扩展。已经算过的“这猫”和“那鱼”会被直接复用,不会因外层树不同而重新解析。
当覆盖全句的格子出现 S 时,文法接受该句;沿最佳回溯指针恢复概率最高的树。若没有 S,应区分输入错误、词典缺失和规则覆盖不足。
下面的实验台允许你逐个跨度推进,并调节两条 NP 规则的概率。注意:概率变化会改变分数,文法规则的有无才决定结构是否能生成。
为了确认递推、闭包和回溯不是纸上步骤,我们用零第三方依赖的实现解析“这 / 猫 / 追 / 那 / 鱼”。NP → Det N 的概率设为 0.7,NP → N 设为 0.3。隔离环境中的实际结果是:
text
CKY: success=True, score=0.490000, nonempty_cells=100.49 来自两个限定名词短语各使用一次 0.7 规则,其余结构规则概率均为 1。这个测试特意检查最终 S、数值分数和非空格子数:只看“程序没报错”无法发现循环顺序错误、概率漏乘或一元闭包遗漏。
7
CKY 可以先计算任意长跨度,再回头补短跨度,因为最后都会遍历所有格子。
8
Viterbi CKY 在每个类别和跨度中只保留最高分回溯路径,得到的是什么?
移进归约把造树拆成一连串动作
依存解析不一定要填跨度表。transition-based 方法把造树写成状态机,常见状态是三元组 : 是栈, 是尚未读取的缓冲区, 是已确认的依存弧。
以 arc-standard 为例,核心动作有三个:
SHIFT:把缓冲区第一个词压到栈顶。LEFT-ARC(r):让栈顶词成为次栈顶词的父节点,添加关系 ,再移除次栈顶依赖词。RIGHT-ARC(r):让次栈顶词成为栈顶词的父节点,添加关系 ,再移除栈顶依赖词。
解析“我 / 喜欢 / 句法”时,一条正确动作序列是:
text
SHIFT → SHIFT → LEFT-ARC(nsubj) → SHIFT
→ RIGHT-ARC(obj) → RIGHT-ARC(root)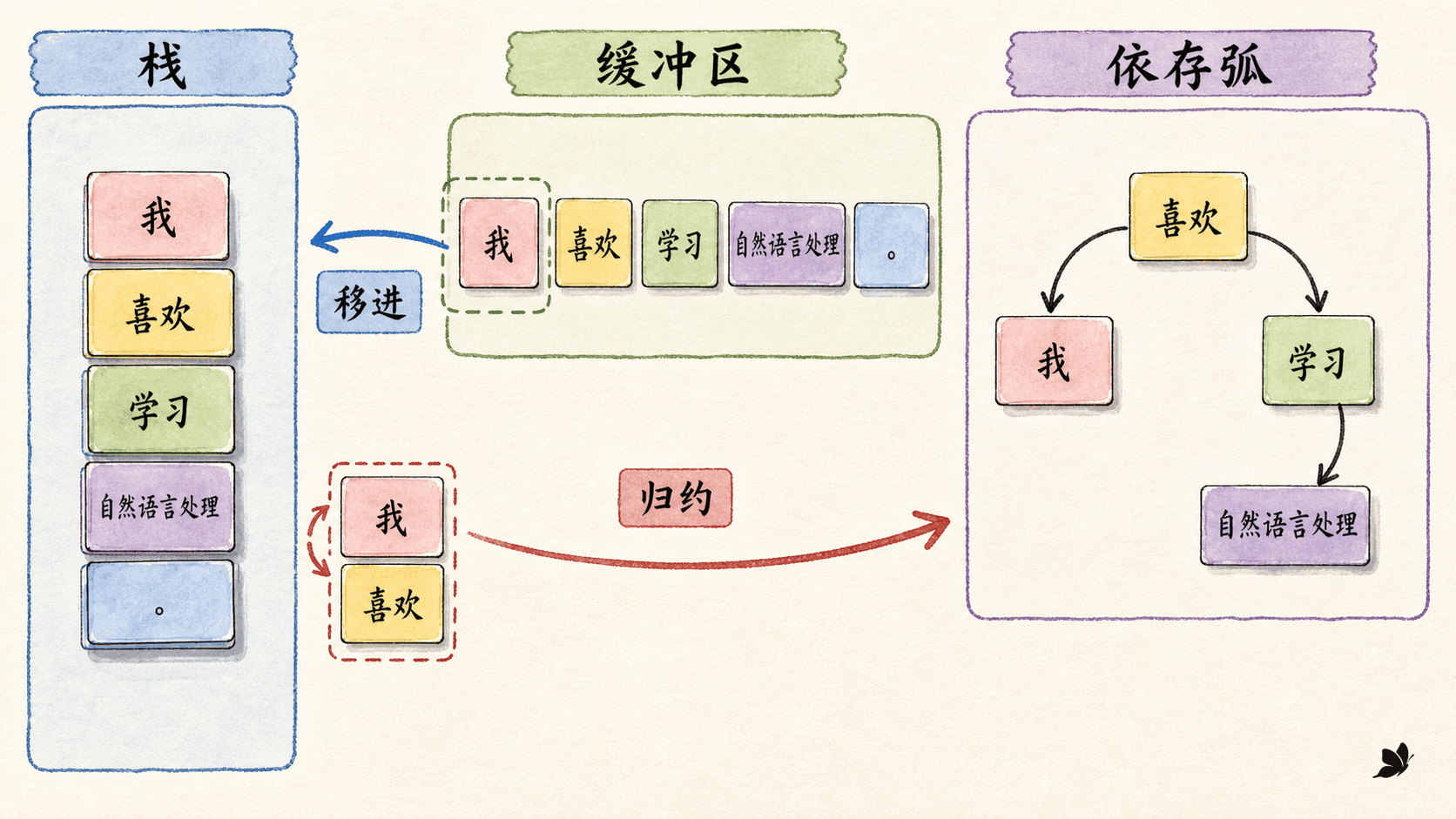
在隔离环境中执行这 6 个动作后,状态确实收敛到 stack=['ROOT']、buffer=[],并得到三条弧:喜欢→我(nsubj)、喜欢→句法(obj)、ROOT→喜欢(root)。
这类方法快,是因为每一步只在少量动作里选择。神经网络可以把栈顶、缓冲区首部、词性和已有子节点编码成向量,再给合法动作打分。结构系统仍需先做动作掩码:ROOT 不能成为普通依赖词,缓冲区为空时不能 SHIFT,栈里不足两个元素时也不能建弧。
局部决策的代价是误差传播。某个词一旦作为依赖词被弹出栈,它的父节点通常就无法修改。贪心搜索把每步最高分动作直接执行,速度快但容易因早期误判走进坏状态;束搜索同时保留若干条高分动作序列,计算更贵,却能推迟承诺。
9
arc-standard 中,一个依赖词在 LEFT-ARC 或 RIGHT-ARC 后被移出栈,意味着什么?
10
下列哪些动作需要被判为非法?
一组依存弧何时才是一棵树
“每个词都预测了一个 HEAD”还不等于得到合法依存树。对基本依存表示,至少要检查以下不变量:
- 唯一根:恰有一个词的 HEAD 为 0,它依赖抽象 ROOT。
- 单父:除根外,每个词恰有一个父节点。按行保存单个 HEAD 时,这个条件由格式部分保证。
- 父节点有效:HEAD 在合法编号范围内,词不能直接指向自己。
- 无环:沿父指针反复向上,不能回到已经访问过的词。
- 连通:每个词最终都能追溯到唯一根。
投射性是另一层约束。直观地说,如果把词按原顺序放在一条线上,树边不应交叉;更严格地说,每棵子树在词序中形成连续区间。非投射树可以完全合法,只是某些只支持投射结构的算法无法生成它。自由语序、长距离依赖或特定标注约定中,都可能出现非投射结构。
下面的实验台让你直接改 HEAD 和 DEPREL。试一试“环与断连”和“合法但非投射”两个预设:前者违反树定义,后者通过基本树约束,只在投射性检查中报警。
一个最小的无环检查不需要图算法库,只要沿每个词的父指针向上追踪:
python
def has_cycle(heads):
n = len(heads)
for start in range(1, n + 1):
seen = set()
node = start
while 1 <= node <= n:
if node in seen:
return True
seen.add(node)
node = heads[node -
我们对三组 HEAD 做了真实测试:正确树 [4,3,4,0] 的唯一根、范围、无环、连通、投射性全部通过;[2,1,4,0] 检出环并判为不连通;[3,4,4,0] 通过基本树检查,但正确识别为非投射。为什么要同时放这三例?只有正例会漏掉“检查函数永远返回真”,只有坏例又会漏掉“合法非投射树被误杀”。
11
只要恰有一个词的 HEAD=0,其他 HEAD 都在编号范围内,这个结构就一定是一棵依存树。
12
发现两条依存弧交叉时,最准确的判断是什么?
评估不是只看一个 LAS
成分解析通常把树转换为带标签跨度集合,再计算 precision、recall 和 F1。预测了 10 个成分,其中 8 个与金标准的标签和边界都一致,精确率是 0.8;金标准共有 12 个成分,召回率是 。F1 平衡两者,但仍应说明是否计入根节点、标点和一元链。
依存解析常用两个附件分数:
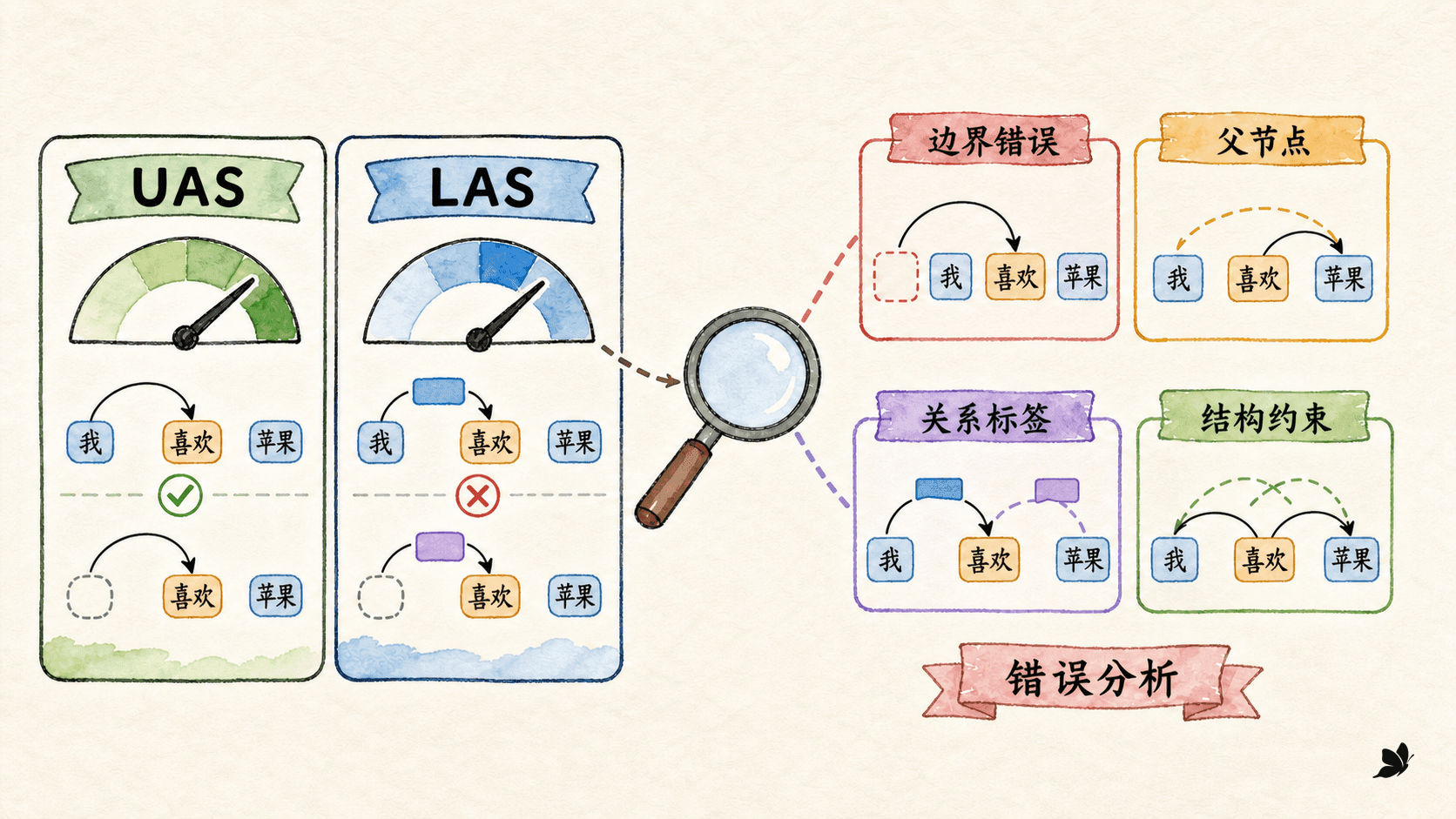
我们在测试中只把第一个词的关系从 nsubj 改成 obj,父节点保持不变,实际得到 UAS=1.00, LAS=0.75。这组结果很有诊断价值:结构连接全部正确,错误集中在关系分类。若把父节点也改错,同一个词会同时拉低 UAS 和 LAS。
一套可执行的错误分析可以按下面五层分桶:
- 边界错误:句界或 token 边界不同,先解决对齐问题。
- 词类错误:词性、形态或多词展开错误,检查流水线上游。
- 附着错误:HEAD 错,常见于介词短语、并列、从句和长距离关系。
- 标签错误:HEAD 对而 DEPREL 错,重点看相近标签的定义与样本不平衡。
- 全局错误:多根、环、断连或解码空间不支持非投射结构。
还要按句长、领域、体裁和语言分别统计。树库中的新闻句子表现好,不代表口语、客服对话或生物医学文本同样好。开发集用于选择模型和阈值,测试集只用于最后评估;反复根据测试集改模型,会让它悄悄变成开发集。
最有用的评估报告通常包括:端到端输入条件、UAS/LAS 或跨度 F1、结构合法率、按句长与领域的分组结果,再配一小批可复核的错误案例。一个总分适合排序,不适合解释。
13
一个词的父节点正确,但依存关系从 nsubj 错标为 obj,会影响哪些指标?
14
在开发过程中反复查看测试集并据此修改模型,只要最后仍报告同一测试集分数,评估就依然无偏。
Transformer 时代为什么还要懂句法
现代解析器常把两件事分开:编码器负责产生上下文化表示,结构解码器负责输出合法树。编码器可以是 Transformer;成分解码器仍可对跨度打分后用 chart search,依存解码器可以给候选弧打分后求最高分树,也可以逐步预测移进归约动作。
这种分工很重要。注意力矩阵本身不是依存树,弧分数表也不是依存树。若任务要求唯一根、单父和无环,就要用结构化解码或事后校验把分数变成合法输出。神经网络改善的是特征表示和评分函数,算法约束规定的是输出空间。
一些探针实验能从上下文表示中恢复树距离或节点深度,说明表示里含有可提取的句法信号。这个结论不能扩大为“模型在每个任务中都会使用正确句法”。探针能读出信息,只证明信息可恢复;它没有证明该信息造成了最终预测,也不保证长句、域外文本或罕见结构上的可靠性。
显式句法是否值得使用,可以按任务需要决定:
实际系统中还应保存解析版本、token 规范和标签集版本。相同句子在不同切分或不同 UD 细化标签下,HEAD 编号和关系可能都不同。没有这些元数据,离线树库、线上预测和错误报告很难对齐。
15
神经编码器已经为每条候选依存弧给出分数后,为什么还可能需要结构解码器?
16
能用一个线性探针从模型表示中恢复依存距离,就足以证明模型生成答案时因果地使用了这棵句法树。