从固定词向量到预训练语言模型:让表示跟着语境走
“苹果发布了新芯片”与“苹果切片后很脆”里的“苹果”,字面完全相同,我们却不会混淆。前一句里的“发布”和“芯片”指向企业,后一句里的“切片”和“脆”指向水果。意义并不只存在于当前词中,而是由当前词、局部搭配、句法关系和整句话共同决定。
这一章要解决的问题是:如何让模型为每一次 token 出现生成一个语境专属的表示,再把从大量无标注文本中学到的能力迁移给具体任务。我们会从 TagLM、ELMo 和 ULMFiT 开始,再比较 2018 年 GPT 与 BERT 的预训练目标,最后把 MLM 批次构造、迁移方式选择、领域偏移和评估边界落到可执行的检查清单上。
静态向量错在哪里
静态词向量是一张查找表。只要 token ID 相同,无论出现在什么句子里,取出的向量都是同一行:
这对学习大致语义和相似度很有用,但它把一个词的所有用法压到一个中心点。语料中若有 70% 的“苹果”指水果、30% 指企业,静态向量往往成为两类语境的折中。下游分类器只看这一行时,不能知道当前究竟是哪种用法。
上下文表示把查表结果当作起点,再用整段输入重新计算当前位置:
因为 同时看到序列和位置,同一 token 在不同句子里可以得到不同的 。这个变化是连续的:“苹果股价”和“苹果手机”也会不同,它们不需要被强制分到两个完全离散的词典编号。
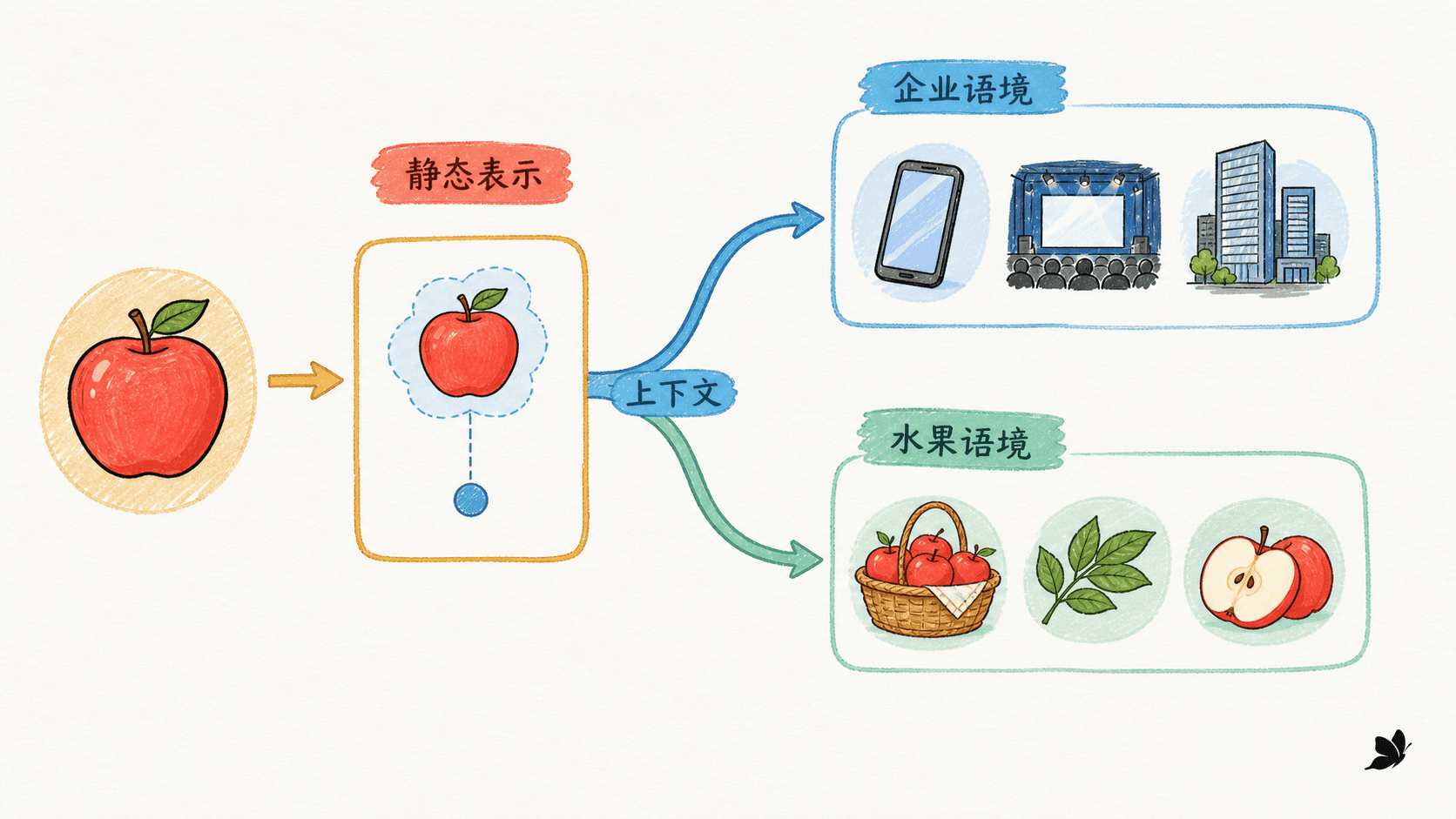
这和传统词义消歧有关,但不是同一件事。词义消歧通常先给定一份词义清单,再为每个语境选一个标签。上下文表示先生成向量,下游任务可以用它做词义分类,也可以做命名实体识别、问答或情感分类。而且“金融机构”与“金融机构的建筑”是否要分成两个词义,也要看任务是翻译、检索还是地址抽取。
1
两个句子都含有同一 token“苹果”。静态查表对这两处的直接输出有什么特征?
2
下列哪些因素会影响“两种用法是否需要分开”的实际答案?
从 TagLM 到深层双向语言表示
语言模型给一段 token 序列分配概率。从左到右的模型用概率链式法则把整句拆成一串“根据左边预测当前词”:
与 n-gram 只保留固定数量的前文不同,循环神经网络把已读历史压进隐状态。为了让位置 也获得右边线索,还可以反向训练一个模型:
TagLM 的做法很直接:先在无标注文本上训练前向和后向语言模型,再把两个方向顶层的隐状态拼起来,作为序列标注器的附加输入。命名实体识别模型因此不再只看静态词向量,还能用已经从无标注文本中学到的双向语境特征。
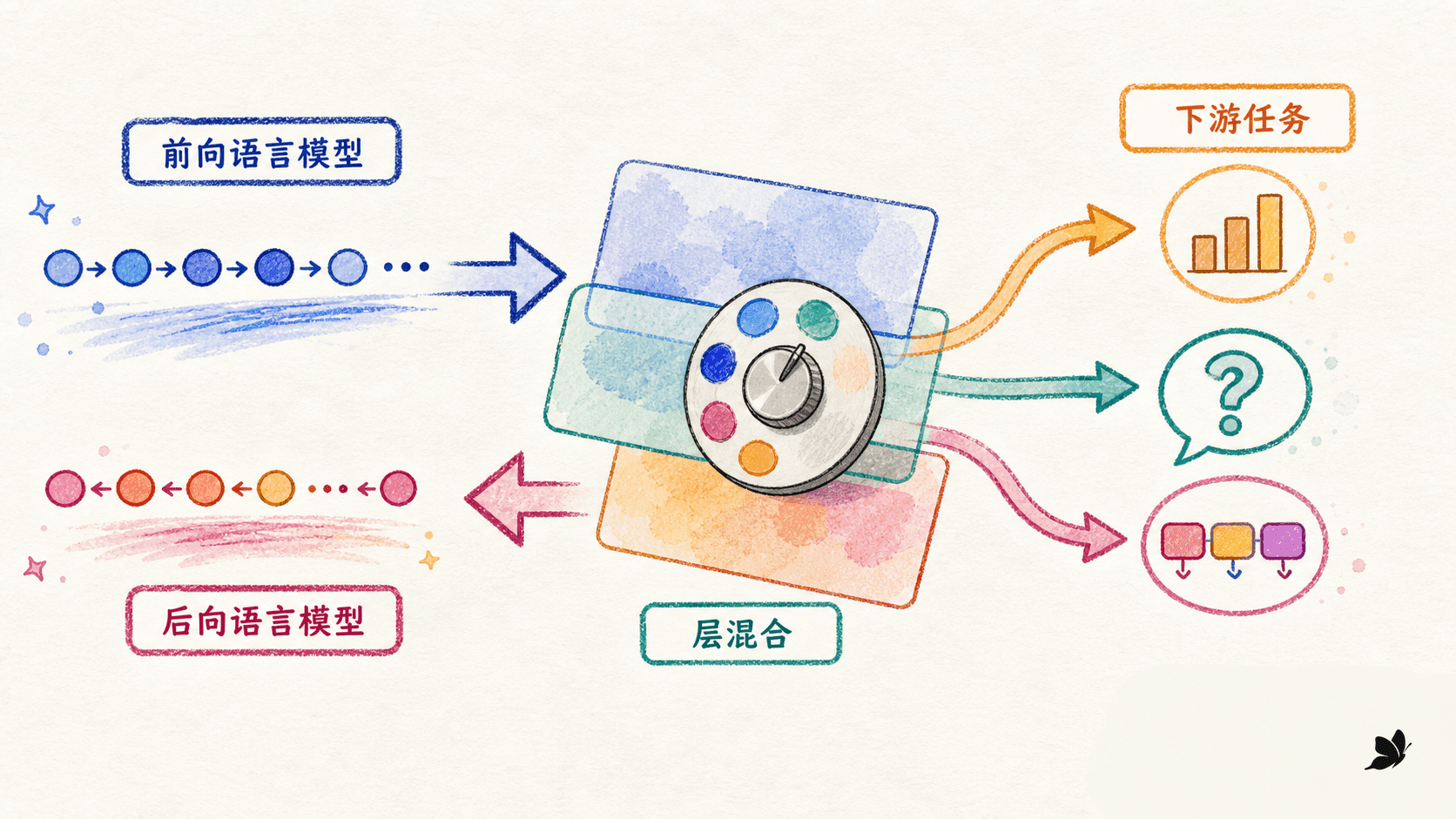
ELMo 继续沿用双向语言模型,但做了两个关键扩展。第一,输入不是只查词表,而是用字符卷积生成 token 表示,这让形态、词缀和未登录变体有机会共享信息。第二,下游任务不再只拿顶层,而是从输入层到每一层双向 LSTM 都取出表示。
ELMo 的“双向”是两个方向的语言模型分别训练,然后在同一位置拼接。左右信息会在表示中相遇,但不会在每一层中像 BERT 的自注意力那样反复双向交互。
3
TagLM 的主要迁移方式是把预训练双向语言模型的上下文隐状态添加到序列标注器。
4
相比固定历史长度的 n-gram,双向神经语言模型的表示目标包含哪些信息?
ELMo 为什么要混合所有层
一个深层语言模型的不同层面向不同的预测难度。靠近输入的层更容易保留字符形态、局部搭配和词性线索;更高层为了预测越来越受语境限制的 token,通常需要归纳词义和远距关系。这是经验趋势,不是“第一层只管句法、第二层只管语义”的硬分工。
对于位置 ,ELMo 先收集 token 层和 层双向 LSTM 的表示,再让当前任务学一组 softmax 权重:
其中 之和为 1, 是整个 ELMo 向量的任务级缩放因子。词性标注可以给低层更高权重,词义判别可以更依赖高层。下游任务不需要猜哪一层最好,而是直接在标注数据上学这个组合。
经典 ELMo 用法会冻结双向语言模型,只训练层权重、缩放因子和下游网络。好处是稳定且不容易破坏预训练参数,同一份上下文表示也能被多个任务复用。代价是主体网络不会为新领域改变,而且下游模型仍需要自己学一套任务编码器。这就引出另一条路:不只拿预训练特征,而是谨慎地改动预训练模型本身。
5
ELMo 为下游任务学习 softmax 层权重,最直接的目的是什么?
6
如果词义判别在某个 ELMo 实验中更依赖高层,就能推出所有模型、语言和数据集都必须使用相同层权重。
ULMFiT 如何把迁移变成可控的训练流程
ULMFiT 把“先学语言,再学任务”拆成三个清楚阶段。这个分解仍然适合今天的工程思考,即使主体架构已经从 LSTM 变成 Transformer。
通用域语言模型预训练:用大量无标注文本学序列规律。这一步成本高,但可以被多个任务复用。
目标域语言模型适配:继续用任务文本的语言模型目标训练,先学会该领域的术语、句式和文体,这一步不需要分类标签。
任务分类器微调:加上输出层,用标注数据更新分类器和逐步放开的语言模型层。
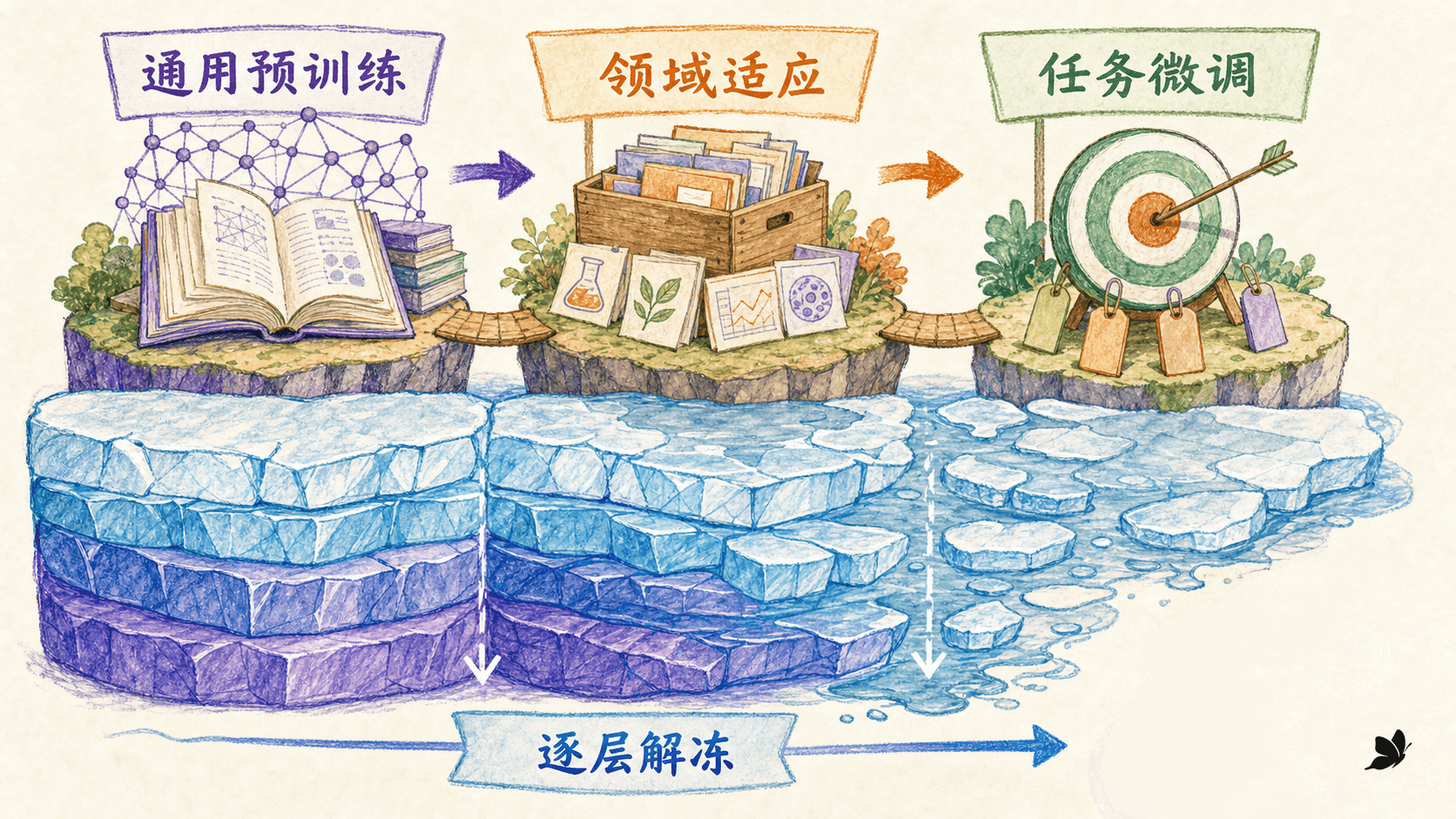
难点在第二、第三阶段。如果一开始就用较大学习率更新所有层,小数据集的噪声可能迅速覆盖预训练知识;如果所有层又都几乎不动,模型会保留原域偏好,新任务学不进去。ULMFiT 用三个细节控制这个平衡。
判别式微调为不同层设定不同学习率:
实验配置从顶层学习率开始,向下每层约除以 2.6。这个数是该方法的经验设置,不是通用常数。底层变得慢一些,顶层更快适应任务。
逐层解冻先只训顶层,然后每轮向下多解冻一层,直到所有需要的层都参与训练。它把“是否更新”也变成了时间上的调度。
倾斜三角学习率在开头的短区间快速升高学习率,让参数离开不适合新任务的区域;然后用更长的区间慢慢降低,做细致收敛。它和逐层解冻解决的是两个维度:前者控制“每一步走多远”,后者控制“哪些层可以走”。
7
ULMFiT 的目标域语言模型适配阶段,为什么能使用没有分类标签的文本?
8
逐层解冻与分层学习率的区别是什么?
2018 年 GPT 与 BERT:相同范式,不同预测角度
ELMo 代表的特征提取路线,和 ULMFiT 代表的整体微调路线,共同确立了一个可复用流程:先在无标注文本上学通用表示,再用少量任务信号适配。2018 年 GPT 和 BERT 都采用 Transformer,但它们对“预训练时允许看哪些词”给出了不同答案。
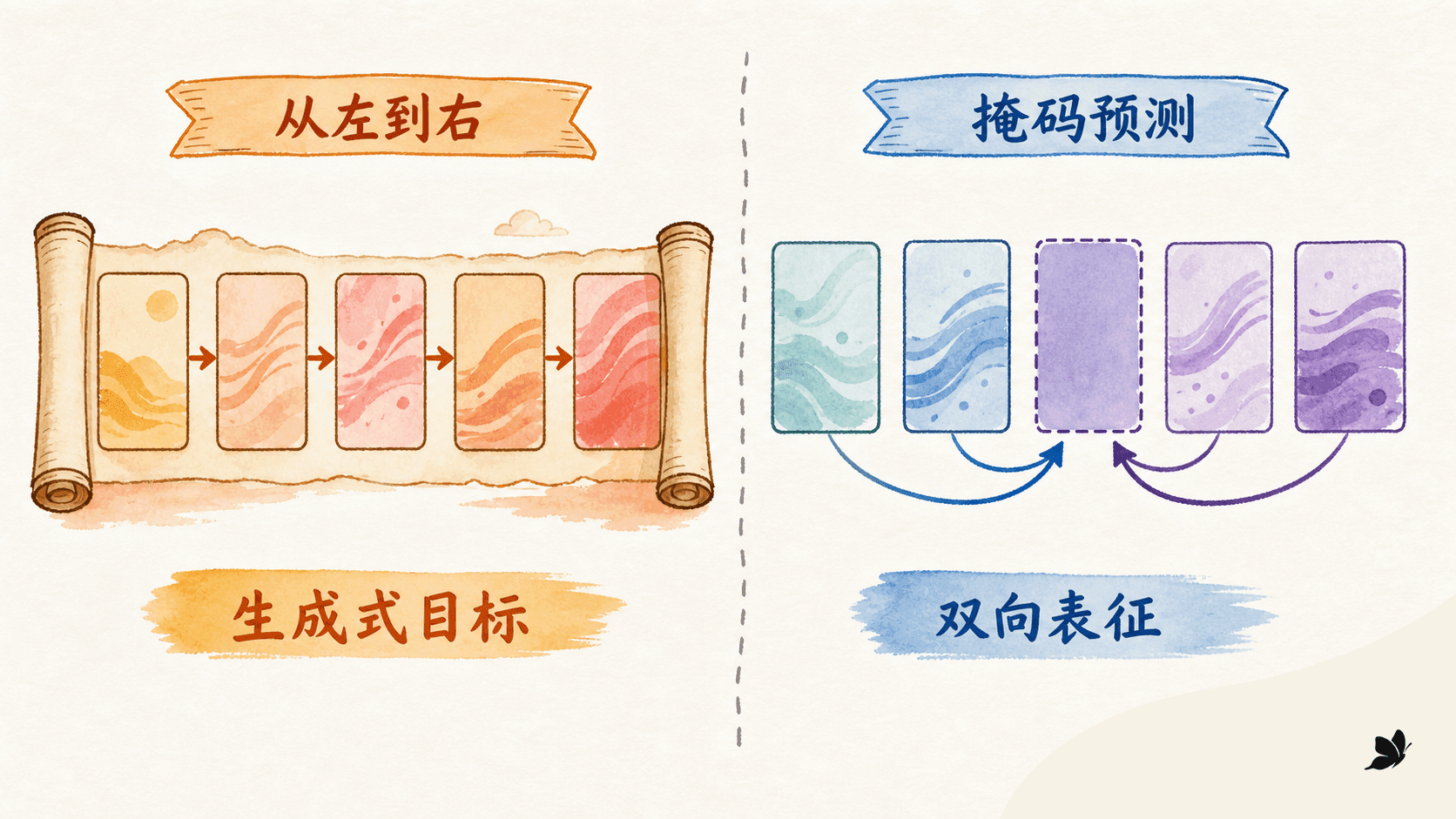
2018 年 GPT 使用 Transformer 解码器和因果遮罩。位置 只能看到自己与左边,再预测下一个 token。这个目标与文本生成的因果顺序一致,预训练和生成推理之间的形式差距小。做理解任务时,它把前提、假设、问题等重组成 token 序列,在预训练主体上加任务输出并微调。
BERT 使用 Transformer 编码器。它随机选中一部分 token,破坏这些位置的输入,再让每个目标位置同时使用左右上下文恢复原 token。因为输入端已经遮住答案,同一层自注意力里的左右 token 可以直接交互。原版 BERT 还同时使用了下一句预测(NSP);后续架构是否保留 NSP 属于另一个设计问题,不能把它和 MLM 绑成永远不变的组合。
9
为什么 BERT 的 MLM 能在同一层中使用目标位置两边的信息?
10
关于 2018 年 GPT 和 BERT 的预训练目标,哪些说法正确?
MLM 批次构造:输入破坏和预测标签必须分开
一个 MLM 样本有两份 token 序列:input_ids 是送给模型的已破坏输入,labels 保留预测目标的原 token ID。把两者混成一份数组,是最容易出现的实现错误。
原版 BERT 先从非特殊 token 中选约 15% 作为预测目标。对每个已选位置:
- 80% 把输入换成
[MASK]; - 10% 换成词表里的随机 token;
- 10% 输入保留原 token。
这三种变化只影响 input_ids。对所有已选位,labels 都是未破坏的原 token;对没选中的位置,工程上常用 -100 表示忽略。因此损失只在目标位置集合 上计算:
这里 是已破坏输入。“10% 保留原词”不是数据集泄漏,它是有意设计的训练噪声,用来减少模型只在看到 [MASK] 时才学习的输入差异。但如果你在评估集上把所有目标都保留原词,或者先复制、切块、随机遮罩后才分训练/验证,评估就可能过于乐观。
一个稳妥的批次构造顺序是:先按文档或来源分训练、验证与测试;再各自分词和切块;最后在进入批次时动态构造遮罩。这样既能让同一段训练文本在不同 epoch 看到不同遮罩,又能避免同源相邻块跨分割泄漏。[CLS]、[SEP]、padding 与其他控制 token 应从候选目标中排除。
11
某个位置被选为 MLM 目标,但属于 10% 的“输入保留原词”情况。它的 label 应如何处理?
12
哪些做法有助于防止 MLM 评估泄漏或偏乐观?
用一个最小实验核对“同词异境”与目标损失
为了只验证机制,不把结论混入下载权重、数据集和训练随机性,下面的实验用纯 Python 构造一个最小自注意力汇总,再用固定 logits 核对 MLM 损失。它不会证明未训练模型已学会“银行”的两个词义;它要证明两件更基础的事:架构的输出确实依赖语境,忽略位置确实不进入损失。
python
import math
import random
random.seed(20260715)
dim = 8
vocab = ["[PAD]", "[MASK]", "苹果", "发布", "芯片", "公司",
"切片", "很", "脆", "水果", "今天", "手机"]
def vec(seed):
r =
实际运行使用两句长度相同的 token 序列,“苹果”都位于第一个位置,token ID 和位置编码完全相同。输入查表的 L2 距离是 0.000000;经不同整句的自注意力汇总后,余弦相似度是 0.921599,L2 距离是 0.683745。唯一改变的是其余 token,因此这个对照说明相同输入行可以因语境不同而得到不同输出。
MLM 核对使用 8 个位置,只选 2 个目标,其他 6 个位置标为 -100。按忽略规则对整个矩阵计算得到 4.190685;只手工取两个目标位再平均,结果也是 4.190685,差值为 0.0000000000。这个对账能抓出两种隐蔽错误:把非目标 token 也算进损失,或在平均时错用全部序列长度当分母。
测试结束后,实验临时目录已删除。如果你把这个测试迁移到 PyTorch,可以用 CrossEntropyLoss(ignore_index=-100) 与手工抽取目标位的结果做同样对账。
13
未训练的最小自注意力层让同 token 在两句话中的输出不同,就足以证明它已经正确理解两个词义。
14
若整个 MLM 矩阵的 ignore-index 损失与手工抽取目标位的平均完全一致,它主要验证了什么?
特征提取、提示调用还是参数微调
当我们拿到一个预训练模型,首先要问的不是“怎么把所有参数都训一遍”,而是“任务需要多少可控改动”。方式越强,潜在适应能力越高,但数据、显存、训练管理和回归测试的成本也会上升。
如果你只有几百条标注,先跑冻结特征和提示基线通常更稳妥。如果域内未标注文本很多,可以先比较继续预训练前后的域内 MLM 损失,但最终决策必须看下游验证集。如果全参数微调改善平均分,却让不同随机种子的方差大幅上升,就不应只报最好一次。
15
哪些条件会让冻结特征提取成为合理的首个基线?
16
领域继续预训练使域内 MLM 损失降低,下一步最应该做什么?
领域偏移、评估边界与下一步
预训练模型学到的是训练分布中可用的规律,不是脱离数据分布的通用语言定律。当输入从新闻变成病历,“阳性”的搭配和标签意义会改变;当电商评论从正式文字变成短视频口语,句长、表情符号和反话比例也会改变。只看随机切分的总准确率,很容易把这些问题藏起来。
我们可以把评估拆成四层:
- 同分布基线:保留一份与训练来源一致的未见集,用来检查模型是否正常学习。
- 跨来源或跨时间测试:按网站、机构、用户或时间分割,防止近重复和模板从训练集渗到测试集。
- 切片评估:单独看多义词、否定、长句、罕见术语、新实体和不同人群,不让高频简单样本盖住失败。
- 稳定性与校准:跑多个随机种子,报平均与方差;除了 accuracy 或 macro-F1,还检查置信度是否和真实正确率匹配。
“已经预训练”不会自动消除偏见、过时知识、数据重复、标签歧义和对抗输入。它也不保证高相似度就是正确词义,或低 MLM 损失就是高业务价值。这些都需要独立数据和任务指标验证。
当失败集中在术语和文体时,可以尝试领域继续预训练;当失败集中在否定范围或句法关系时,要检查训练目标、标注和模型结构;当平均分上升而小群体切片下降时,不能用总分抵消风险。先定位失败类型,再选迁移方法,比反复更换更大模型更有信息量。
到这里,我们已经知道 BERT 需要在每一层中让任意位置交换信息,GPT 需要用遮罩保持因果顺序,而两者都需要在长序列中学会把信息分配给不同位置。下一章的自注意力会把这个“谁该看谁”写成一组可并行计算的权重,也会解释为什么 Transformer 能成为预训练的主要骨架。
17
一个模型在随机切分测试集上分数很高。还应做哪些检查才能判断它能否处理分布变化?
18
预训练模型在一个任务上的平均分提高,就可以不再检查领域外数据、置信度和关键子群体。