子词模型:在词与字符之间找到可用的边界
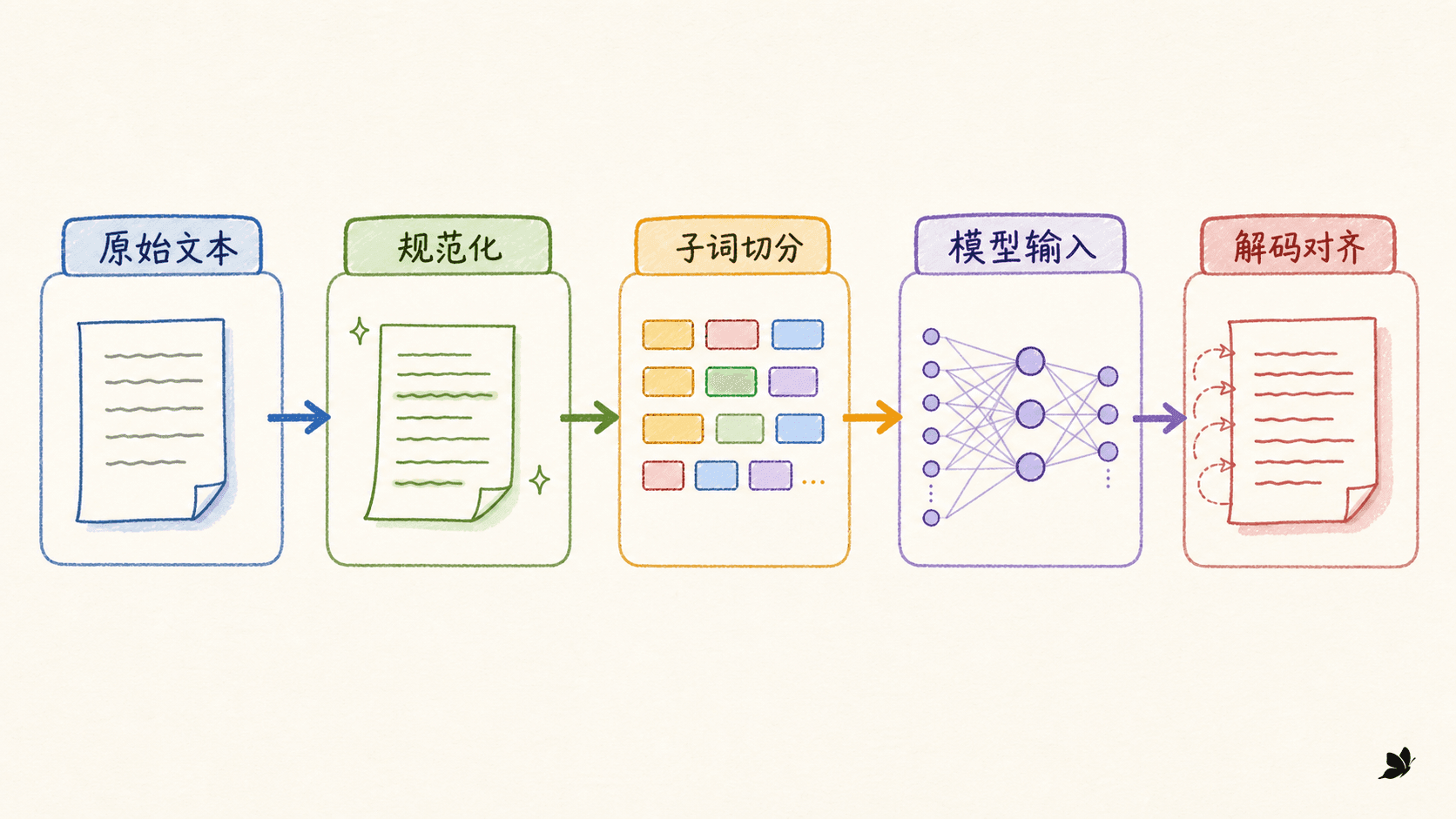
如果把一句话交给神经网络,网络看到的并不是“词义”,而是一串整数 ID。决定这些 ID 的分词器看起来只是预处理工具,实际上它同时决定了词表参数量、序列长度、未知字符的处理方式、文本能否还原,以及标签如何映射回原文。
子词模型要解决的核心矛盾很朴素:完整词太多,字符序列又太长。它在两者之间学习一组可复用片段,让高频组合尽量短,让低频组合仍能拆开。真正困难的地方不在于背下 BPE、WordPiece 或 Unigram 的名字,而在于知道每种方法优化了什么、没有保证什么,以及怎样验证它适合自己的数据。
为什么“词”不是一个稳定的模型单位
先看两个极端。假设词表只收录最常见的 20,000 个完整词,那么人名、产品型号、领域缩写、新造词和拼写变体很快会落到 <unk>。多个完全不同的词被压成同一个 ID 后,信息已经丢失,后面的网络再强也无法恢复差异。
如果反过来收录所有见过的词,词表会随着语料增长。词表大小为 、隐藏维度为 时,仅一张输入嵌入矩阵就有 个参数;若输出投影不共享权重,还要再付一次近似相同的成本。低频词占着一整行参数,却可能只得到几次更新。
字符级方案能缩小词表,却会拉长序列。英文单词会变成多个字母,中文字符在 UTF-8 下还可能对应多个字节。对上下文长度固定的模型来说,token 越碎,同一窗口能容纳的语义内容越少;对自注意力来说,序列增长也会提高计算与显存成本。
子词的思路是让频率决定粒度:常见词或常见片段可以成为一个 token,罕见词退回到更小的片段。这里有三点必须先说清楚。
- 子词不等于词素。 “自然语言”可能因为高频而合并,也可能被切成“自然 / 语言”;统计目标并不保证边界符合语言学上的词根、前缀或后缀。
- 从字符开始不等于永远没有 OOV。 如果基础字符表只来自训练语料,推理时出现新的 Unicode 字符,字符级 BPE 和 Unigram 仍可能产生未知符号。byte fallback 才能把覆盖闭合到 UTF-8 字节。
- 空格也不是天然真值。 中文没有显式词界;英文的连字符、缩写、数字表达和多词短语也让“按空格切词”失效。预切分规则必须和任务一起设计。
一个完整 tokenizer 通常包含五层:规范化、预切分、子词模型、特殊 token 后处理和解码。只比较“BPE 还是 Unigram”,却没有冻结其余四层,实验结论往往不可复现。
评估 tokenizer 时,我们关心的不是“切得像不像人工分词”,而是四个可测目标:覆盖是否闭合、序列是否紧凑、编解码与 offset 是否可靠、下游任务是否受益。四者有冲突,不能用一个平均 token 数替代。
1
某个词级模型把所有未登录人名都编码成同一个 <unk>。最直接且不可逆的损失是什么?
2
设计子词器时,哪些项目需要和子词算法一起冻结并记录?
BPE:把最高频的相邻片段逐步粘起来
BPE 的训练可以从一个按词频加权的词典开始。把每个词拆成字符,并加入词尾标记,词尾标记用于阻止规则无意跨过词边界。对当前所有符号序列统计相邻对:
其中 是词 的频次, 是它当前的第 个符号。每轮选择计数最大的 ,在整个词典中把它替换成新符号 。一轮只增加一个词表项,执行多少轮就直接控制词表增长多少。
以一个小语料为例,前几轮真实统计得到:
text
01 处 + 理 → 处理 频次 22
02 需 + 要 → 需要 频次 16
03 机 + 器 → 机器 频次 13
04 学 + 习 → 学习 频次 9
05 然 + 语 → 然语 频次 9
06 然语 + 言 → 然语言 频次 9
07 自 + 然语言 → 自然语言 频次 9第五轮的“然语”并不是一个自然词素,但它是通往高频片段“自然语言”的中间状态。这正好说明:BPE 学的是压缩路径,不是形态学分析。
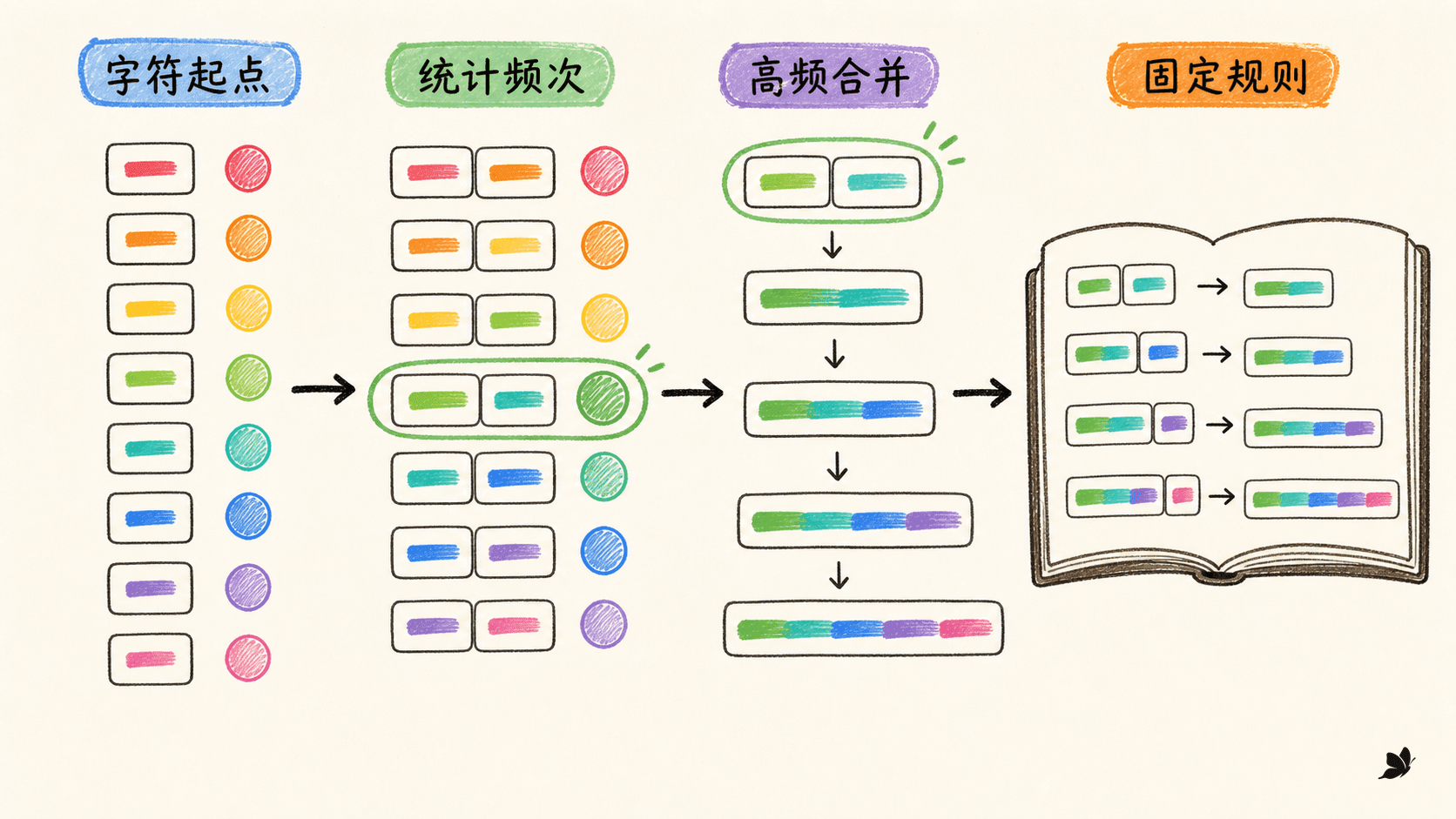
编码新文本时,不再重新统计频率,而是按训练时的优先级应用冻结的合并规则。规则顺序不能丢,因为较早合并会改变较晚规则能否匹配。工程实现通常维护 pair 索引或优先队列,避免每轮全量扫描,但结果必须与所定义的并列决策一致。
下面是一段可运行的最小实现。它保留词尾边界,也给同频 pair 规定了稳定的字典序决策,便于测试复现。
python
from collections import Counter
def pair_counts(vocab):
counts = Counter()
for pieces, freq in vocab.items():
for pair in zip(pieces, pieces[1:]):
counts[pair] += freq
return counts
def merge(seq, pair):
out, i = [], 0
while i < len(seq):
if
在同一压力集上,把合并次数从 12 增至 36,可覆盖样本的平均 token 数从 5.67 降到 4.67。这个结果说明更多合并确实提高了压缩率;它没有证明下游质量一定更好,也没有修复训练字符表之外的字符。含新字符的名字样本仍产生 <unk>,这是后面引入 byte fallback 的理由。
3
BPE 中某个中间 token 看起来没有完整语义,说明这轮合并一定训练错了。
4
训练结束后编码新文本时,为什么必须保留合并规则的优先级?
WordPiece:用关联分数造词表,用最长匹配做编码
WordPiece 和 BPE 都从较小单元扩充词表,但两者不能简单写成“一个看频率,一个看互信息”的绝对定义。WordPiece 的早期目标是用有限词表提高语言模型似然;它的原始训练实现没有形成一份唯一公开规范。常见复现会用下面的分数挑选候选 pair:
这个分数会压低“两个部分各自到处出现”的组合,优先保留彼此绑定更强的 pair。它和点互信息有关,但少了对数与统一概率归一化;把它直接称为严格互信息并不准确。不同实现也可能直接比较加入候选后语料似然的增量。
WordPiece 编码阶段最鲜明的特点是从左到右做最长匹配。以 BERT 风格词表为例,词首片段可以写成 play,非词首片段写成 ##ing。编码 playing 时,算法在当前位置选择词表中最长可用片段,得到 play / ##ing。## 只是边界标记,不属于原文。
如果一个预切分后的词在某个位置找不到任何合法片段,经典 WordPiece 往往把整个词变成 [UNK],而不是像 byte fallback 那样继续退到字节。因此“WordPiece 是子词模型”也不能推出绝对无 OOV。
BERT 风格的实际路径还包括:
先把空白统一,并依据 cased 或 uncased 配置决定是否小写、是否去重音。这个步骤已经可能改变原始表面形式。
再按标点和部分 Unicode 类别做预切分。WordPiece 不会跨越这些预切分边界。
对每个片段做最长匹配,非词首候选带
##,无法覆盖时产生 [UNK]。最后由模板添加
[CLS]、[SEP] 等控制 token。它们不是普通文本片段,offset 通常应标为无原文区间。所以,迁移预训练模型时必须沿用原 tokenizer。即使重新训练的 WordPiece “切得更漂亮”,ID 已经和预训练嵌入矩阵错位,模型看到的是另一套语言。
5
关于常见 WordPiece 复现中的 pair 分数,哪些说法正确?
6
给已经预训练好的 BERT 更换一套新 WordPiece 词表,最直接的问题是什么?
Unigram:先准备很多候选,再按删除代价瘦身
BPE 是自底向上不断增加符号;Unigram 的方向相反:先准备一个较大的候选词表,再删掉不重要的片段。给定词表 ,它假设一条切分路径 中各片段独立:
一个字符串通常有多条合法路径。例如“自然语言”可能是“自然语言”“自然 / 语言”或逐字切分。最优路径是:
所有切分可以表示成一个有向无环图:位置是节点,词表中能覆盖某段文本的 piece 是边。Viterbi 动态规划求最高分路径;前向—后向算法则能计算每条边的期望使用次数。
训练时先固定候选集合,用 EM 更新 ;再估计删掉每个候选会让语料似然下降多少。删除代价小的候选可以批量裁剪,然后重新跑 EM。单字符通常必须保留,否则某个位置可能没有任何路径。
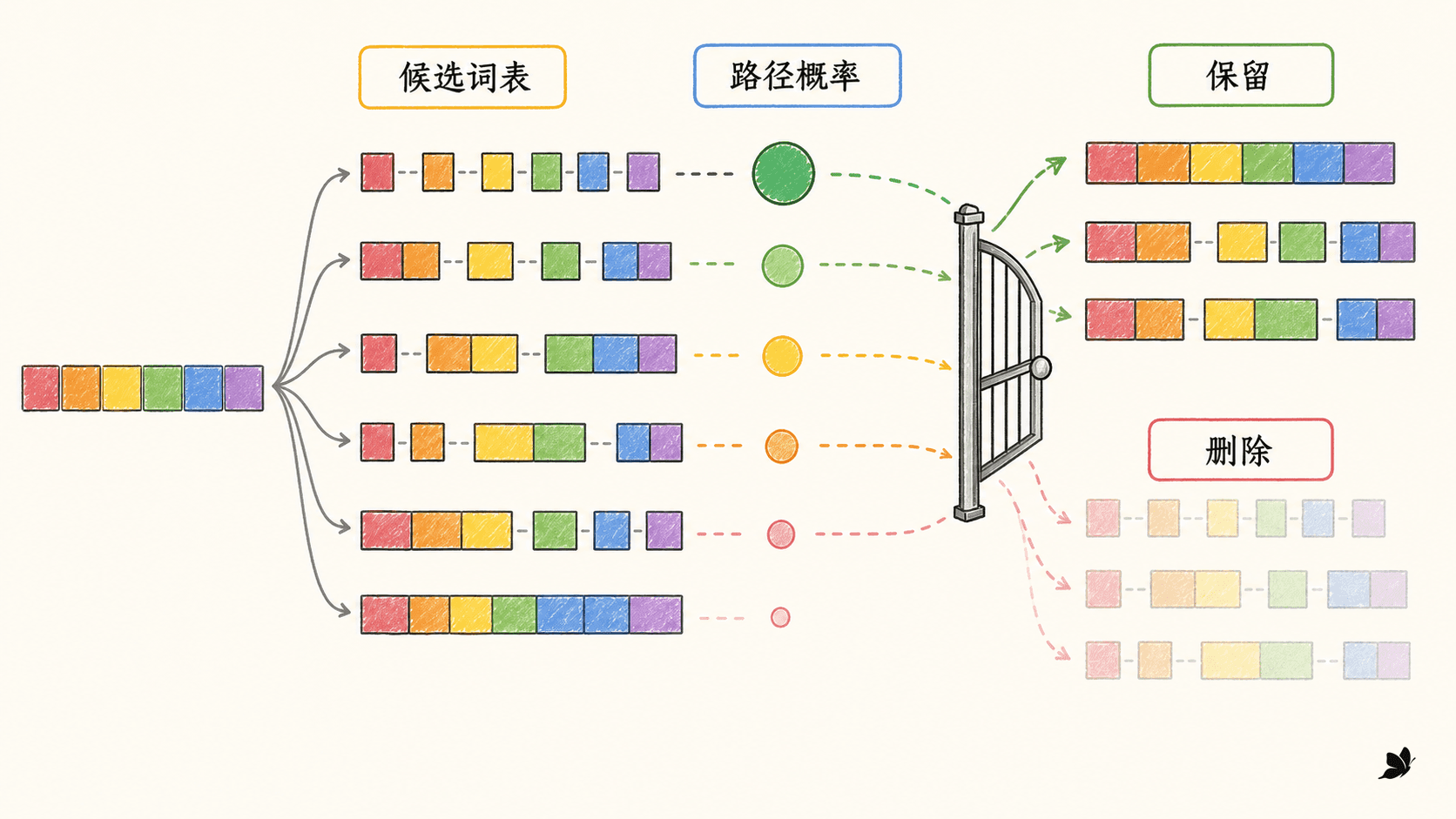
一个小型实验从 484 个候选片段开始,按批次裁剪为:
text
484 → 388 → 311 → 249 → 200 → 160 → 140最终语料对数似然为 -482.0579,最高概率片段包括“自然语言”“机器翻译”“处理”。在三个可覆盖压力样本上,最优路径平均使用 3.67 个 token。未出现字符组成的新名字仍然没有路径,说明保留“训练语料中的所有单字符”和“覆盖任意输入”是两回事。
Unigram 的概率结构还允许子词正则化。训练时不总选 Viterbi 路径,而是从多条合法路径中采样:
小时分布更平,切分更有变化; 大时更接近最优路径。这样做让模型反复看到表面等价但边界不同的输入,减少对单一路径的过拟合。推理时仍可使用最优路径,保持确定性。
7
Unigram 裁剪时为什么通常不能删除所有单字符候选?
8
子词正则化要求推理时也随机采样,否则训练目标无效。
SentencePiece:把原始文本、空格和解码放进同一套契约
SentencePiece 不是与 BPE、Unigram 并列的第三种合并准则。它是一套从原始文本训练、编码到解码的框架,内部模型可以选择 BPE 或 Unigram。这个区分很重要:当两次实验都写“使用 SentencePiece”时,如果 model_type、规范化和字符覆盖率不同,实际 tokenizer 仍可能完全不同。
它把空格转义成可见元符号 ▁(U+2581),再像普通字符一样参与切分。原文:
text
自然语言 processing可能编码成:
text
▁自然 语言 ▁process ing解码时拼接 piece,再把 ▁ 还原为空格。这样不需要先为中文、日文或英文分别提供人工分词器,词首和词中也能被统一建模。默认的 dummy prefix 会在句首补一个空格元符号,使句首词与句中词的边界行为更一致。
“可逆”也需要准确描述。SentencePiece 保证的典型关系是:
如果规范化把全角数字 100 变成 100,解码可以还原规范化结果,却不能凭空恢复原来的全角形式。需要逐字保留原始文本的任务,必须另外存原文,并维护 normalized offset 到 original offset 的映射。
几个常被忽略的训练参数会直接改变边界:
character_coverage决定多少训练字符直接进入基础集合。字符集大的语种若设得过低,低频字会落到未知或 fallback。byte_fallback在字符无法覆盖时退到 UTF-8 字节,关闭 OOV,但可能显著增加少数语种、emoji 或生僻字符的 token 数。normalization_rule_name或自定义规则决定 NFC、NFKC 类兼容折叠以及空格处理。- control symbol、user-defined symbol 和普通 piece 的行为不同;它们的 ID 与解码策略应进入模型接口文档。
原始文本直训并不意味着没有预处理。规范化本身就是预处理,而且可能有损。上线时应保存训练配置、模型文件与规范化版本的校验值,不能只保存 vocab.txt。
9
下面哪些配置会影响 SentencePiece 的实际编码结果?
10
只要 SentencePiece 解码成功,就能保证得到规范化前完全相同的原始字符串。
Byte-level BPE:用 256 个字节封闭覆盖空间
Unicode 字符集合很大,而且会继续扩展;UTF-8 则把任何合法 Unicode 字符串表示成 0–255 的字节序列。byte-level BPE 以这 256 个字节为基础符号,再对高频字节片段做 BPE 合并。它把“基础字符表没见过新字符”的问题变成一个封闭覆盖问题。
实际长度并不等于肉眼字符数:
如果“中”对应的三个字节组合在训练中足够常见,它们可能被合并成一个 token;若某个生僻字符从未见过,仍能用三个或四个基础字节表示。覆盖有了保证,压缩效率却取决于语料分布。训练数据偏向某种语言时,其他文字可能长期停留在字节粒度,承担更高的 token 成本。
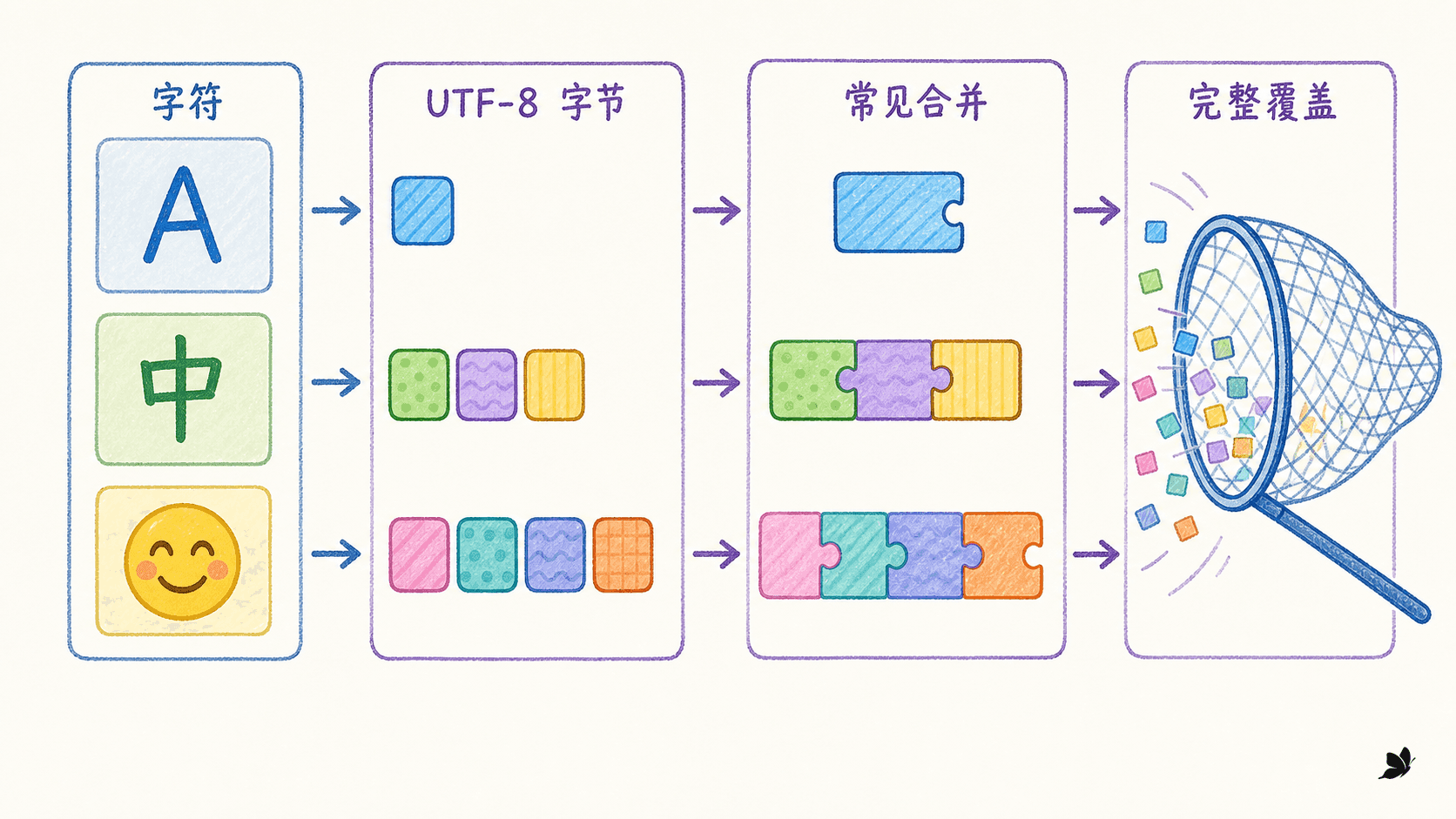
有些实现先把不可打印字节映射到一组可显示的 Unicode 字符,再执行普通字符串形式的 BPE。界面里出现 Ġ 等符号时,它通常是在表示空格或字节映射,不代表原文真的含有这个字符。调试应同时查看 token、ID、原始字节和 decoder,不能根据显示文本猜含义。
byte-level 也不该被理解为“直接任意合并所有字节”。如果跨标点、字母类别或边界无限制合并,词表会存入大量 word.、word!、word? 变体,浪费容量。预切分正则、空格是否并入后词,以及能否跨字符类别,都是模型定义的一部分。
offset 还会出现单位差异:同一个 emoji 的范围可以是 4 个 UTF-8 字节、1 个 Unicode 码点或 2 个 UTF-16 code unit。后端、浏览器和标注工具若混用单位,实体高亮就会错位。接口必须明确 offset 的坐标系。
11
byte-level BPE 能覆盖训练时未见过的 emoji,最根本的原因是什么?
12
byte-level 方案仍需要重点评估哪些代价?
中文、多语言与规范化:边界必须服从数据和任务
中文没有空格标出的词界,“研究生命起源”既要区分“研究 / 生命 / 起源”,也要防止在别的语境里把“研究生”错误拆开。更深一层的问题是,什么算一个词本来就会随标注规范与任务变化。检索可能接受细粒度字符片段,命名实体希望稳定保留专名,机器翻译更关心源目标之间能否形成一致映射。
因此,中文子词模型不应先假定某个外部分词器是唯一真值。可以比较三条路线:
- 先人工词切分,再学子词。 边界可解释,但错误会传递,词表不能跨预切分边界学习。
- 直接从原始中文学习。 让统计目标决定片段,流程统一,但高频片段不一定符合语言学词边界。
- 把任务信号纳入选择。 用实体 F1、翻译质量或检索召回验证边界,而不是只比较分词准确率。
多语言共享词表又增加一层资源分配。高资源语言的频率会占据大量词表槽;低资源语言、复杂文字系统或丰富形态语言可能被切得更碎。共享片段有利于跨语言迁移,但语言专属片段不足会伤害词级任务。两者不存在统一最优点。
建议按语言、文字系统和领域分别计算:
参考单位可以是字符、空格词或标注词,但报告必须写清分母。只报全局平均值会让大语种淹没小语种的异常。
规范化也不能一刀切。NFC 主要处理标准等价序列;NFKC 还会做兼容折叠,例如全角拉丁字母与半角形式可能合并。搜索与去重常受益于折叠,代码、用户名、密码、法律文本或版式敏感任务却可能因此丢失差异。中文繁简转换更不是 Unicode 标准规范化的一部分,需要独立、可追踪的策略。
训练和推理必须使用同一套规范化。若训练前做 NFKC,线上却直接编码原文,同一可见字符串可能产生不同 ID;若标签仍以原始 offset 保存,还会同时出现边界错位。
13
为中文翻译系统选择切分方案时,为什么不能只看人工分词准确率?
14
多语言 tokenizer 的分层评估至少应包含哪些切片?
特殊 token、offset 与可逆解码是一份接口契约
子词器输出的不只是 tokens。生产接口至少要同时返回 input_ids、attention_mask、特殊 token 掩码,以及每个内容 token 对应原文的 offset。分类任务可能只使用 ID;问答、命名实体、文本高亮和内容审核则离不开可靠对齐。
特殊 token 要分清三类:
- 控制 token:如
<bos>、<eos>、[CLS]、[SEP],由模板插入,不应当作普通用户文本解释。 - 未知与回退 token:
<unk>表示无法覆盖;byte fallback 则用若干字节 token 保留原信息。 - 用户定义原子片段:领域标记可能要求不拆分,但它仍需规定是否参与规范化、能否从用户输入直接触发。
一个常见安全错误是把用户输入里的字符串 [SEP] 直接识别为控制 token。这样用户文本可以提前终止一个片段或改变句对结构。安全做法不是简单删除方括号,而是在 tokenizer API 层区分“可信模板插入的特殊 ID”和“普通输入中长得相同的字符序列”。
offset 也不能在规范化后随手重算。假设原文的 A 经 NFKC 变成 A,表面长度碰巧一样;组合附加符、连字或某些兼容字符则可能改变长度。快速 tokenizer 会维护规范化前后的对齐映射,这比对最终 token 文本做 find() 更可靠,因为重复词、大小写折叠和空格合并都会让反向搜索产生歧义。
建议为每版 tokenizer 写下四个不变量:
- 对所有可接受输入,编码必须终止,并明确是否允许
<unk>。 decode(encode(normalize(x)))应等于所声明的规范化结果。- 每个内容 token 的 offset 切片应覆盖它对应的原文区间;特殊 token 使用统一空区间或空值。
- 截断、padding 和句对模板不能改变未截断内容 token 的 offset。
15
用户输入中出现字符串 [SEP] 时,它必然应该获得预训练模型的 [SEP] 特殊 ID。
16
从规范化后的 token 文本恢复原文 offset,哪种做法最可靠?
词表大小不是越大越好,要看它把成本移到了哪里
增大词表通常会缩短序列,却同时扩大嵌入和输出投影。若输入输出权重共享,词表从 32K 增至 64K、维度为 768,新增参数约为:
如果不共享,参数增量还会接近翻倍。另一方面,过小词表会增加 token 数,让训练吞吐下降、上下文窗口容纳的文本变少,并让实体或数字被拆成很多片段。
我建议把选择过程写成一张证据表,而不是凭经验拍一个 32K:
训练候选时保持语料、规范化、抽样和随机种子一致,只改变算法或词表大小;至少比较小、中、大三个点。然后对开发集按中文/英文/混排、普通词/专名/数字/URL、干净文本/噪声文本分层。若大词表只改善高频新闻,却让新产品名和低资源语言更碎,就不是一个可靠升级。
下游模型也会改变结论。固定预训练模型不能更换 tokenizer;从头预训练时才有完整选择空间。给现有模型扩词表是一项模型改造:新 token 的嵌入需要初始化与继续训练,旧 token 的切分稳定性也要回归验证。
17
把词表从 32K 增至 64K,可能同时出现哪些变化?
18
为什么 99 分位 token 长度比只看平均长度更有价值?
从最小实验到上线审计:让每个边界都可解释
一套可交付的 tokenizer 至少要经过覆盖、质量和安全三层测试。下面的最小实验特意加入中文、英文混排、emoji 和未见名字,而不是只用训练语料里的干净句子。
真实运行结果如下:
text
BPE-12 覆盖 3/4,可覆盖样本平均 5.67 token
BPE-36 覆盖 3/4,可覆盖样本平均 4.67 token
Unigram 候选 484 → 140,最终 log-likelihood = -482.0579
Unigram 覆盖 3/4,可覆盖样本平均 3.67 token
UTF-8 字节数:A=1,中=3,🙂=4为什么这组结果有用?12 到 36 次 BPE 合并验证了“更多词表容量换更短序列”;三种字符基础方案都在新名字上失败,验证了覆盖不能从算法名称推断;字节计数则说明 byte fallback 虽能闭合覆盖,但不同文字会付出不同长度代价。
上线前还要加入以下压力项:
- Unicode 等价与兼容字符:NFC/NFKC 前后 token、ID、offset 和解码是否符合声明。
- 不可见与双向控制字符:是否能记录、显示或按业务策略拒绝,不能让它们悄悄改变边界。
- 混合脚本形似字符:
paypal与含西里尔а的相似字符串不能仅凭肉眼视为同一标识符。 - 特殊 token 字面量:用户文本不能未经授权变成控制 ID。
- 长串与重复文本:最大长度、截断侧、stride 和批处理上限要有确定行为。
- 领域符号:URL、邮箱、金额、日期、化学式、代码标识符和产品型号要有单独错误集。
最后给一个可执行的选型顺序:若必须兼容现有预训练模型,直接使用它冻结的 tokenizer;若从头训练单语系统,先用 BPE 与 Unigram 做三档词表对照;若处理无空格或多语言原始文本,可用 SentencePiece 统一编解码;若输入字符集合开放,加入 byte fallback 或 byte-level 方案。每一步都要用同一压力集验证覆盖、分层 fertility、offset、解码、下游指标和吞吐。
19
压力测试发现普通中文都能还原,但一个新名字含未见字符并产生 <unk>。最合理的下一步是什么?
20
一版 tokenizer 达到可上线状态前,哪些证据应该同时保留?