机器翻译不是查词:从概率分解到注意力与束搜索
如果把“我把合同发给她了”逐字替换成英语,词都可能查对,句子仍然不对。中文的“把”字结构要改写成英语的主谓宾次序;“了”表达的完成状态要落到动词时态;“她”与“合同”的角色不能颠倒。真正的翻译必须同时回答两类问题:源句到底说了什么,目标语言怎样说才自然。
这也是机器翻译最容易制造错觉的地方。一个输出可以读起来很顺,却漏掉否定词、数字或施受关系;也可以逐项忠实,却像词典条目拼起来的句子。我们需要把充分性与流畅性一起检查,不能只凭“像不像人话”判断系统是否可靠。
下面从一个可计算的目标开始:给定源序列,怎样给整条目标序列赋概率。然后我们会把编码器、解码器、教师强制、注意力、掩码和束搜索一件件接起来。每个公式都要能落到张量与搜索状态上,每个工程技巧也会说明它究竟在修哪一种错误。
从双语数据到翻译概率
把源句写成 ,目标句写成 。机器翻译要找的是给定 后概率最高的目标序列:
序列的候选数会随长度指数增长,无法把所有句子先列出来再比较。自回归模型利用概率链式法则,把整句概率拆成逐词决策:
这里的 是已经生成的目标前缀。<BOS> 给第一步一个统一起点,<EOS> 把“什么时候停止”也变成模型要学习的决策。训练时通常最小化正确目标序列的负对数似然:
对数把连乘变成求和,也避免大量小概率直接相乘造成下溢。批量训练时还要排除 <PAD> 位置;否则模型会因预测人造填充符而获得损失,等于学习了一个任务中不存在的目标。
平行语料不是两列天然整齐的词
模型的监督信号通常来自成对的源句与目标句。句对需要先在文档中找准对应关系,句内又可能出现一对多、多对一、调序与省译。例如“自然语言处理”可以对应三个英文词,一个英文冠词也可能没有单独的中文词与之对应。中文没有空格标记词界,切成“研究生命起源”还是“研究生|命题……”会直接改变后续对齐与翻译单元。
因此,数据准备至少要核对四件事:
- 两侧是否真在表达同一内容,而不是主题相近却并非翻译;
- 数字、日期、专名和否定是否完整保留;
- 分句与句界是否一致,是否混入标题、脚注或 OCR 噪声;
- 切分粒度是否适合任务,是否把固定搭配和命名实体拆坏。
经典统计系统常把目标端自然度与双语对应分开:
可以理解为“这个目标句生成当前源句是否合理”, 则偏好目标语言中常见的句子。现代神经模型往往直接学习 ,但两种错误来源并没有消失:漏译和角色错位更接近充分性问题,搭配生硬和语法不顺更接近流畅性问题。错误分析时继续保留这两个视角,往往比只看总分更有用。
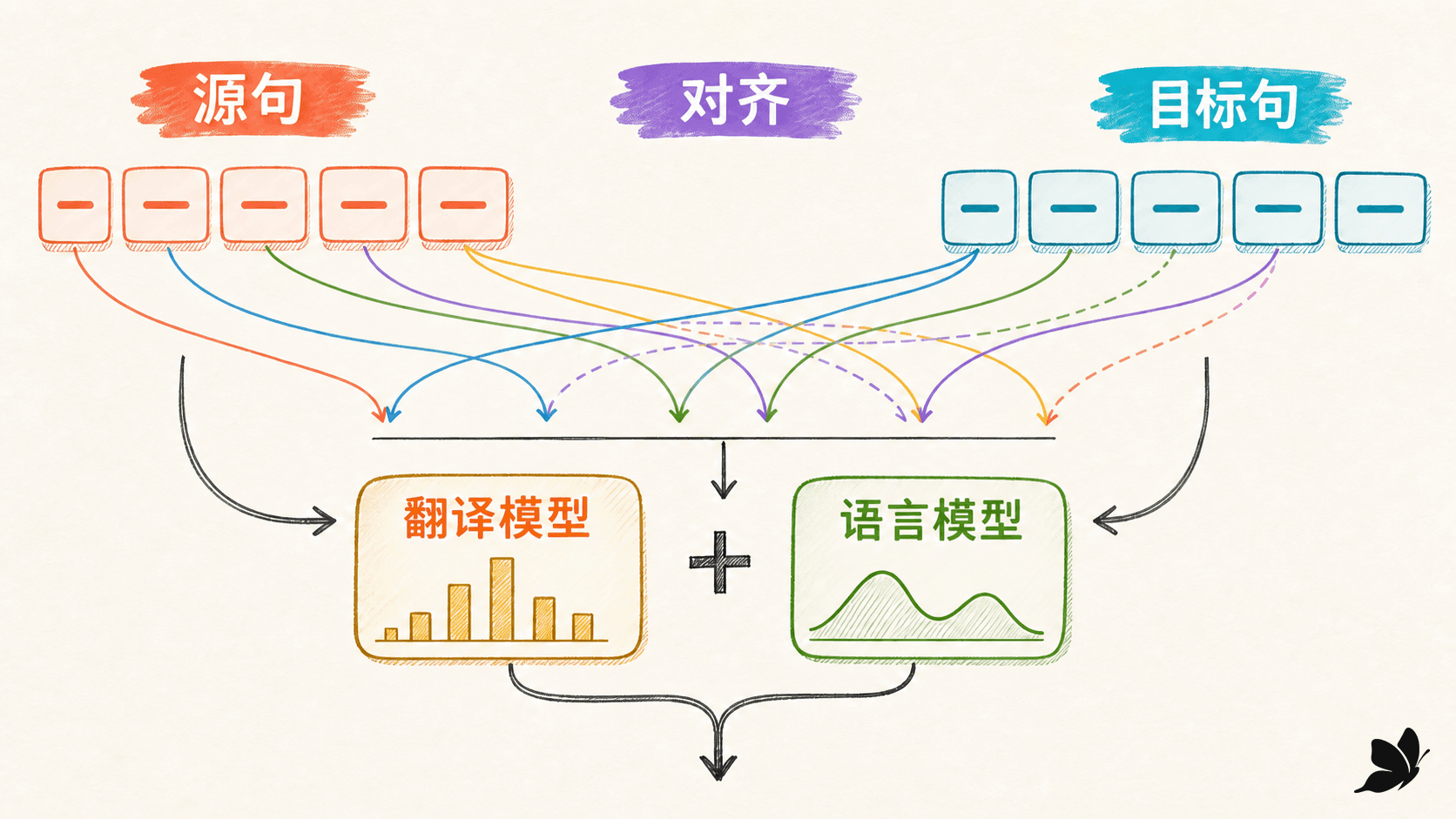
句对相同不代表词必须一一对应。把“对齐”强行理解成逐词连线,会把调序、固定搭配和省略现象都当成错误。训练数据真正需要的是语义对应可靠、边界清楚,而不是表面长度相等。
1
为什么自回归模型要把 <EOS> 当成普通预测目标之一?
2
构造中英平行语料时,哪些问题会直接破坏翻译监督信号?
编码器—解码器怎样把变长序列接起来
最基本的 seq2seq 使用两个循环网络。编码器从左到右读取源序列:
无注意力的版本只把最后状态压成一个固定维度的上下文 ,再用它初始化解码器:
解码器从 <BOS> 开始,结合上一步状态与前一个目标词,给下一个词分配概率:
编码器与解码器的隐藏维度可以不同,此时 负责投影;双向编码器还要把正向、反向终态正确拼接或变换,不能随手取一个方向。输入批次长度不同时,pack、长度张量或掩码必须和原句一一对应。
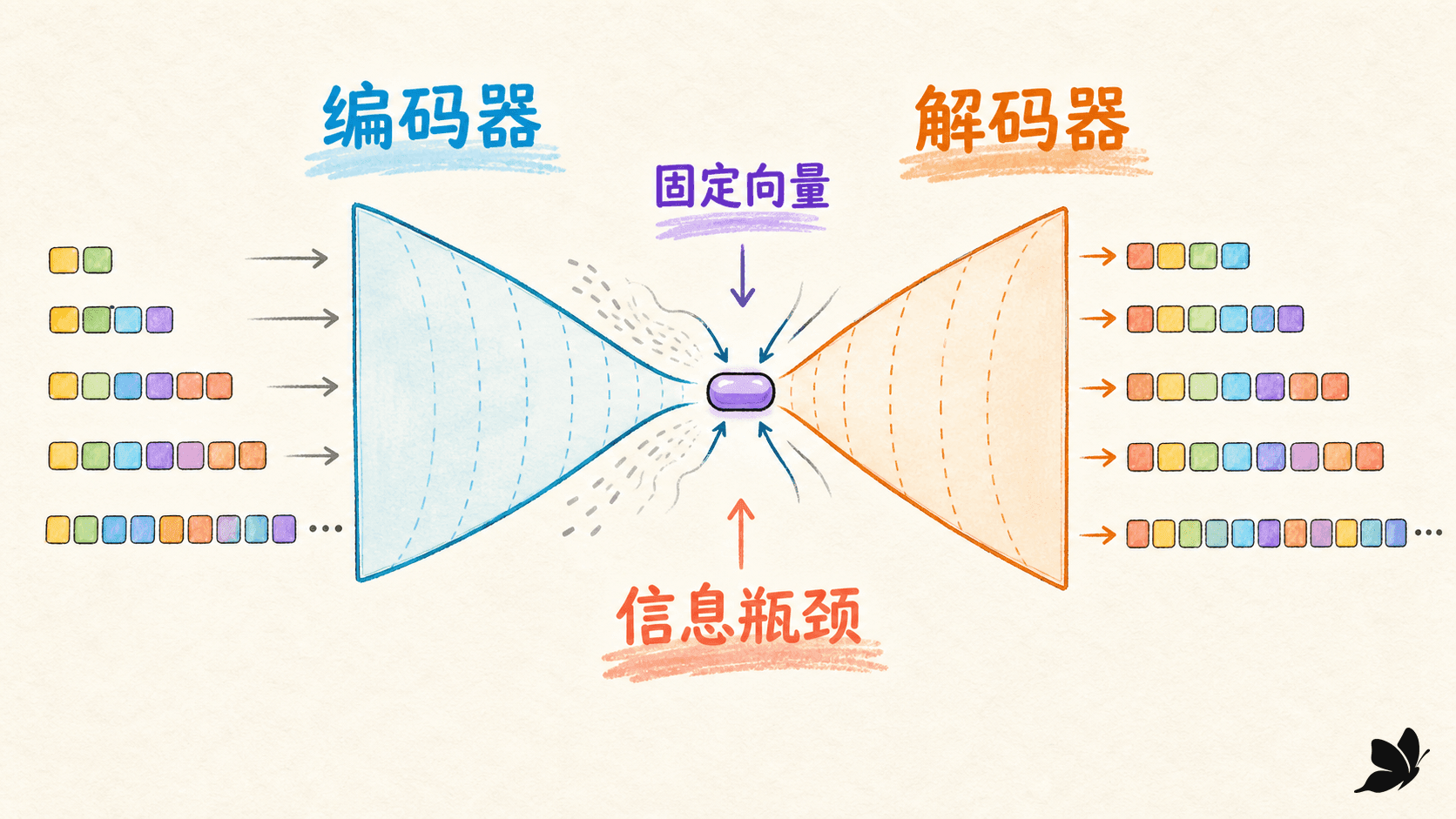
固定向量的问题不只是“维度不够”
把所有源信息都交给 ,意味着解码第一个词和最后一个词都只能读同一份摘要。长句中的早期实体、稀有术语、多个并列关系会争夺有限的表示与梯度通路。实际退化通常同时来自三件事:
- 编码器要把不同长度的细节压到同一接口;
- 解码损失到早期源位置的路径很长,优化更难;
- 解码器没有显式位置可以回看,只能指望 预先保留所有以后可能需要的细节。
这里不宜说“一个固定向量在数学上绝不可能表示长句”。实数向量的理论容量不是实验瓶颈的直接证明。更准确的说法是:在有限参数、有限精度和梯度训练下,单一接口形成了明显的表示与优化瓶颈。长句退化、漏掉句首实体,都是这个设计需要改造的信号。
反转源句为什么曾经有效
在同语序较强的语言对中,把源序列反转,会让源句开头与目标句开头在计算图上离得更近。例如原本第一个源词要穿过整个编码器,再影响第一个目标词;反转后它靠近编码结束位置。这个技巧缩短了一部分最小时间距离,帮助优化,却没有让解码器获得任意位置的直接访问能力。遇到复杂调序或很长输入,它仍然依赖同一个 。
3
只要把固定上下文向量的维度从 512 增加到 4096,信息瓶颈就一定消失。
4
双向编码器输出维度为每向 256、解码器隐藏维度为 512 时,最稳妥的初始化做法是什么?
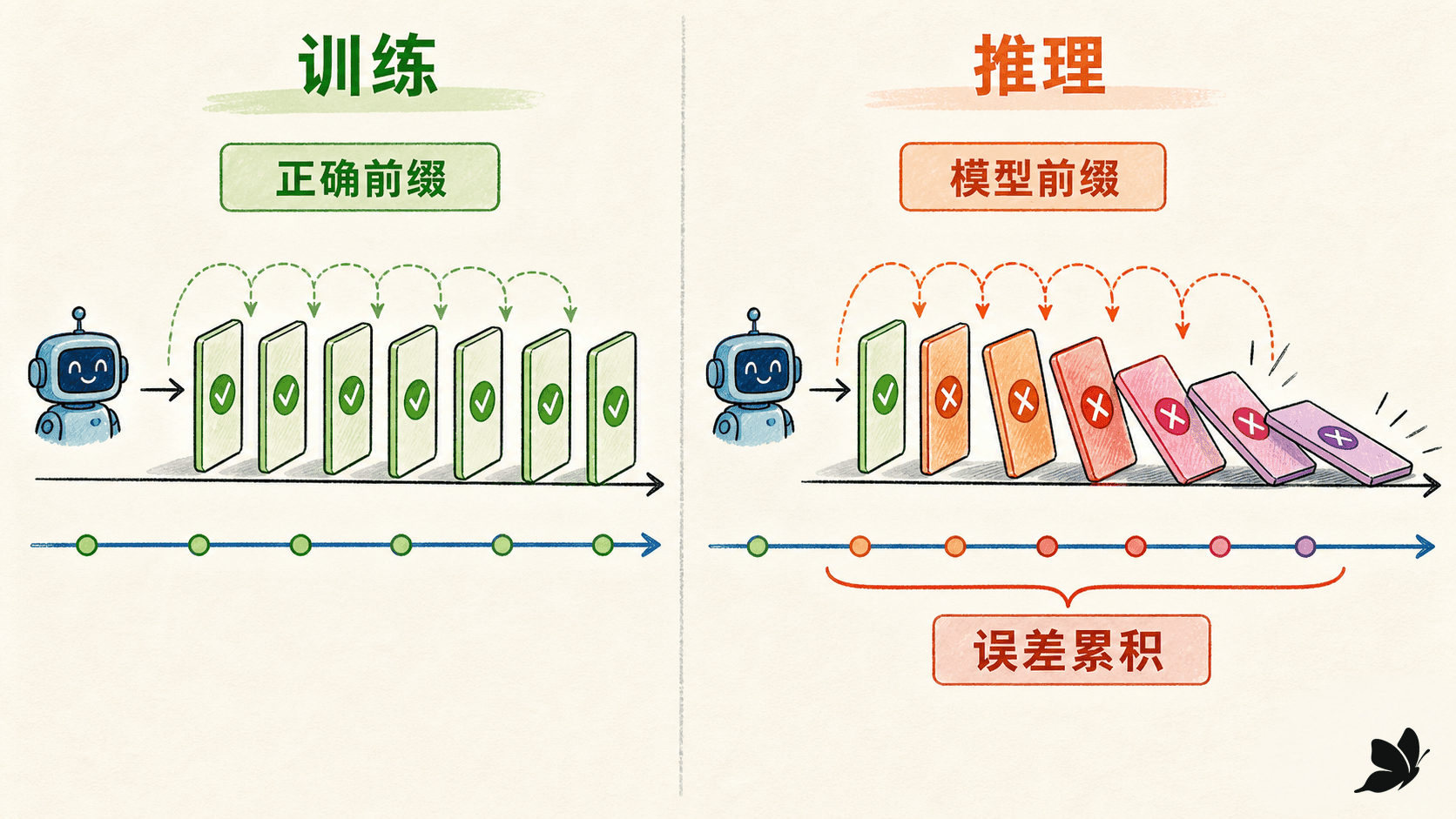
教师强制为什么让训练和推理走上两条路
训练时目标句已经知道。教师强制把真实的 喂给第 步解码器,再要求它预测 。这会让每一步都在“正确前缀”上学习条件分布,损失清楚、收敛通常更快。
python
decoder_input = target[:, 0] # <BOS>
for t in range(1, target.size(1)):
logits, state = decoder.step(decoder_input, state, encoder_outputs, src_mask)
loss = loss + cross_entropy(logits, target[:, t], ignore_index=PAD_ID)
decoder_input = target[:, t] # 教师强制:下一步仍喂真实词到了推理阶段,真实目标不存在,下一步输入只能来自模型自己的预测:
python
decoder_input = logits.argmax(dim=-1)假设第二步把“没有”误成“已经”,第三步看到的前缀就不再属于训练时常见分布。后续错误可能滚动累积,这种训练条件与推理条件的错位通常称为暴露偏差。
先别把问题简化成一个比例
训练时可以按概率选择真实词或模型预测,形成部分教师强制。scheduled sampling 还会随训练推进逐渐降低真实词比例,让模型见到更多自身前缀。它确实针对了分布错位,但会带来新的选择:
- 早期模型预测近乎随机,过早大量采样会让监督上下文过于嘈杂;
- 采样出的序列与参考序列可能发生位置错位,同一步不再代表同一语义单元;
- 改变前缀分布也改变了优化目标,可能让模型在本来正确的前缀上退化;
- 单次离散采样不可微,当前步选了哪个 token 不会通过普通反向传播得到梯度。
因此,教师强制比例应该与验证集的自由运行表现一起调。还可以用标签平滑、序列级训练、噪声前缀、最小风险训练等方法改善鲁棒性,但没有一个开关能保证消除所有生成错误。
RNN 解码器即使使用教师强制,隐藏状态仍按时间步递推,不能把所有解码状态完全并行计算。可以预先准备整条真实输入,真正的目标位并行属于后面 Transformer 的掩码自注意力训练方式。
5
教师强制较高时,训练损失很好而自由生成不稳,合理的排查方向有哪些?
6
scheduled sampling 越早把教师强制比例降到 0,模型就越接近真实推理,训练效果也必然越好。
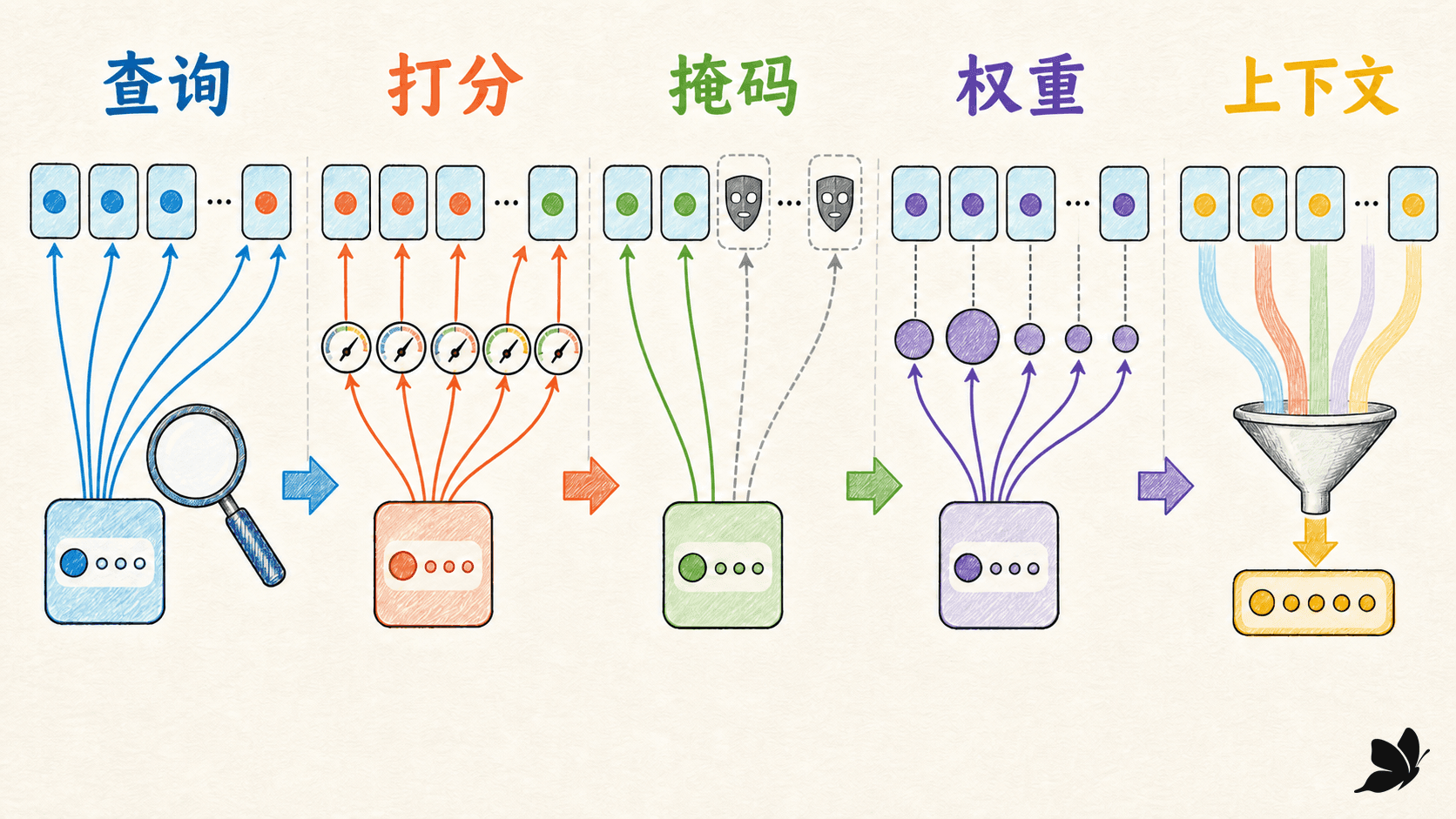
注意力把一份摘要改成逐步查阅
注意力保留编码器的全部状态 。解码第 个词时,用上一解码状态 分别和每个源状态计算匹配分数:
再将分数归一化为权重:
最后对源状态加权求和,得到这一解码步专用的上下文:
生成“合同”时, 可以偏向源句中的名词;生成时态或介词时,又可以组合谓词和角色信息。上下文不再是一份从头用到尾的摘要,而是随目标位置变化的可微读取结果。
Bahdanau 与 Luong 差在哪里
常用加性打分先把查询和源状态投到同一注意力空间,再经过非线性:
它允许编码器与解码器维度不同,参数更灵活。乘性家族更直接:
如果维度已经相同,还可以令 ,退化为点积。乘性打分便于矩阵乘法,通常更省计算。
名称并不能替你决定代码顺序。不同实现会调整查询时机、把 拼到 RNN 输入或输出,甚至加入上一时刻上下文的 input-feeding。读实现时要沿着张量问:谁是查询,哪些状态被打分,归一化在哪个轴,上下文在哪一步进入预测。
注意力热图能看,但不能过度解释
常呈现出近似双语对齐的条带,适合发现漏看、重复关注与 padding 泄漏。然而,权重是模型为了降低翻译损失学出的内部路由,不是人工对齐标签,也不自动等于因果解释。多个源状态已经混入上下文信息,低权重位置仍可能通过编码器影响高权重状态。热图应该与删词、遮挡、梯度或错误样本一起检查。
7
为什么上下文向量 cₜ 会随目标位置 t 改变?
8
比较加性与点积注意力时,哪些说法成立?
掩码决定模型看见的是内容还是填充
一个批次的句子通常被补到同样长度。若在 softmax 后才处理 padding,高分的 <PAD> 已经吃掉了归一化质量;直接把它清零又会让剩余权重之和小于 1。正确顺序是先把无效位置的分数设成负无穷,再做 softmax:
这样 padding 的指数为 0,有效位置重新归一化为 1。数值实现还要先减去每行最大分数,避免 exp 溢出。若某个样本整行都是 padding,softmax 会遇到没有有效分母的情况;数据管道应提前拒绝空源句,或为它定义明确的特殊 token。
一个形状清楚的加性注意力
下面约定查询为 [B, D_dec],编码状态为 [B, S, D_enc],有效位置掩码为 [B, S]。softmax 必须沿源长度 归一化。
python
import torch
from torch import nn
class AdditiveAttention(nn.Module):
def __init__(self, enc_dim, dec_dim, attn_dim):
super().__init__()
self.key_proj = nn.Linear(enc_dim, attn_dim, bias=False)
self.query_proj = nn.Linear(dec_dim, attn_dim, bias=False)
self.energy = nn.Linear(attn_dim,
三个断言很适合放进单元测试:有效行权重和接近 1,padding 权重等于 0,上下文形状为 [B, D_enc]。再补一个“所有有效分数都加同一常数,权重不变”的测试,可以检查实现是否真按 softmax 的相对分数工作。
受控数值实验
我们在隔离沙盒中用标准库计算分数 [2.0, 0.5, 1.0, 9.0],最后一个位置标为 padding。稳定 masked softmax 的真实输出是:
text
masked_weights [0.628532, 0.140244, 0.231224, 0.0]
weight_sum 1.000000000000
context (0.859756, 0.371468)padding 故意给了最高分 9.0;结果仍严格为 0,说明测试真正触发了掩码,而不是因为 padding 原本分数低。上下文使用前三个二维值的加权和,这个结果同时核对了归一化与 bmm 对应的数学含义。实验只证明这一小段机制正确,不代表完整翻译模型已经学会合理对齐。
9
为什么 padding 掩码应在 softmax 之前施加?
10
只要注意力权重之和等于 1,就能证明 mask、归一化轴和上下文计算都实现正确。
束搜索是在有限预算内保留后路
贪心解码每一步只选当前概率最大的 token。它快,却会永久丢掉暂时排第二、后来更好的路径。束搜索维护 条候选前缀:每轮扩展所有未结束前缀,累加对数概率,再只保留分数最高的 条。
实现时每条候选至少要保存 token 序列、解码状态、累计分数和结束标记。已经生成 <EOS> 的候选不能继续扩展;批量实现还要按候选重排隐藏状态与注意力缓存。最终选择应在完成候选中进行,并设置最大长度和可证明不会被未完成路径超越的停止条件。
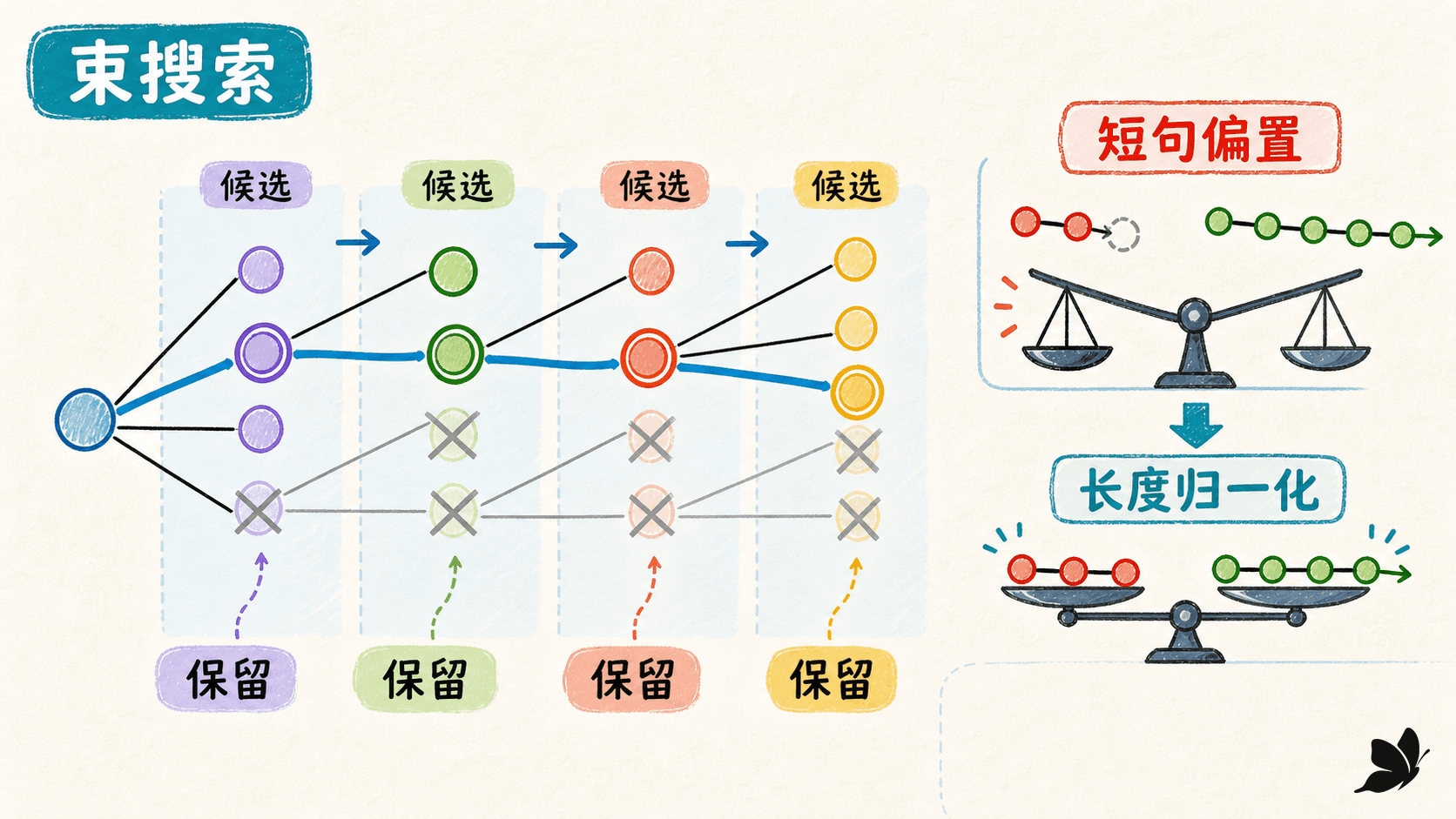
为什么原始概率偏爱短句
每多生成一个 token,就再乘一个不大于 1 的概率,或再加一个不大于 0 的对数概率。未经修正的累计分数容易偏向过早输出 <EOS>。一种简单长度归一化是:
就是原始分数;增大 会减轻长度惩罚,但过大也可能鼓励冗长。另一类平滑长度惩罚使用 。这些都是验证集上要调的解码超参数,并没有改变模型训练出的条件概率。
漏译还可以用覆盖项检查各源位置累计获得的注意力。如果某个实体几乎从未被关注,就降低候选分数。不过,注意力覆盖只是信号,不等同于语义已经完整翻译;重复关注也不必然代表重复输出。
受控搜索树的真实结果如下:
text
beam_1 ('很', 0.275)
beam_2 ('天气 很好', 0.324)
raw_short_long -0.967584 -1.021651
normalized_short_long -0.638367 -0.444700宽度 1 在第一步选择“很”,随后过早结束;宽度 2 保留“天气”,最终找到概率更高的“天气 很好”。最后两行用两个候选隔离长度效应:原始分数偏向短候选, 后长候选排序更高。这只是说明评分规则可以改变排序,不能据此断言所有任务都该用 。
11
beam 从 1 增加到 5 后,哪项结论最可靠?
12
实现束搜索时,哪些细节会直接影响结果正确性?
评估要把“像参考答案”与“翻对了”分开
BLEU 的核心是比较候选与一个或多个参考译文的 n-gram 重合。为了防止同一个词重复很多次刷高精确率,它使用截断计数:候选中某个 n-gram 的有效次数不能超过参考中的最大次数。把整个测试集的匹配数累加,可得到修正精确率 。
候选过短时,再乘简短惩罚:
是候选总长度, 是相应参考长度。最终把不同阶的修正精确率做几何平均:
这套设计适合在相同数据、相同切词与相同参考下快速比较系统。单句上某一阶没有重合,未平滑 BLEU 就可能直接为 0;译文使用了合理同义词,也可能因表面不重合失分。反过来,n-gram 很像参考并不保证否定、角色和数字都正确。
一份比总分更能定位问题的检查表
实际评估可以按长度、领域、实体密度和句法现象分桶;自动指标负责发现整体变化,人工抽样负责确认变化来自哪里。若系统用于合同、医疗或跨语言检索,还应单独给数字、否定、实体和关键关系设硬性测试,因为这些错误的业务代价不会被一个平均 BLEU 充分表达。
不要拿不同分词方案、大小写处理或参考数量下的 BLEU 直接横比。指标实现与预处理也是实验配置的一部分,报告分数时应一起固定并记录。
13
某系统 BLEU 上升 1 分后,仍需哪些检查才能判断是否真的更可用?
14
候选译文与参考用了不同但正确的同义表达时,BLEU 可能降低。
把训练、推理和下一代架构接成一条线
一个可运行的注意力 seq2seq 管线可以按下面的顺序对账:
先建立可靠句对并固定切词、词表与特殊 token。划分数据时防止同源文档泄漏到训练集和测试集;批处理同时返回源长度、源掩码与目标非 padding 掩码。
编码器输出所有源状态,而不只返回最终状态。若使用双向 RNN,明确拼接方向与层;解码器初始状态通过投影获得,不能依赖偶然相同的维度。
每个解码步用当前查询计算注意力,先应用源掩码,再沿源长度归一化。将上下文送入 RNN 更新或输出层,并记录权重供诊断,但不把热图当作唯一解释。
训练损失忽略目标 padding,分别记录教师前缀与自由运行表现。若调整教师强制比例,固定随机种子并比较长句、错误恢复与开发集指标,而不是只看训练损失。
注意力怎样通向 Transformer
RNN 注意力已经包含后来常说的三个角色:解码状态是查询,编码状态提供键和值,权重决定从值中读取多少。它缓解了固定向量瓶颈,却没有消除循环依赖:编码器与解码器状态仍需逐步计算,长路径也仍存在。
Transformer 往前再走一步。编码器用自注意力让源位置彼此读取;解码器用带因果掩码的自注意力读取目标前缀,再用交叉注意力读取源序列。训练时整条右移目标已知,因此所有目标位置可并行计算,同时用因果掩码防止看到未来词。推理仍然自回归,束搜索、停止条件、长度偏置与评估问题并不会自动消失。
在进入完整 Transformer 之前,还要处理词表边界。机器翻译中的专名、变形词与新词不可能全靠固定整词表覆盖,子词切分会把开放词表问题变成可组合单元。也就是说,这一讲解决的是“怎样读源序列并搜索目标序列”,下一步要解决“序列里的基本单位到底该多大”。
15
从 RNN 注意力迁移到 Transformer 交叉注意力时,最稳定的概念对应是什么?
16
Transformer 替换 RNN 后,哪些问题仍需要单独处理?