循环神经网络与语言模型 | 自在学
循环神经网络与语言模型
输入法看到“今天下午去”,要在“开会”、“下雨”、“一下”之间分配概率;语音识别遇到发音相近的候选,要判断哪个词序列更像人会说的话;文本生成则要反复做同一件事:根据已有前缀,预测下一个符号。
这就是语言模型的核心工作。问题在于,语言的可能序列远超训练数据能覆盖的范围。n-gram 用固定长度的历史换来可统计性,循环神经网络则把已读前缀压进一个连续隐状态。本篇会把这条路线拆开:从概率链式分解出发,先做一个可解释的 n-gram 基线,再进入 RNN 状态递推、时间反向传播、截断训练和梯度诊断,最后用一个真正跑过的字符级小实验收尾。
语言模型估计的是数据分布下的序列概率,不是“句子是否绝对正确”的真理分数。一句话概率高,可能只因为它常见;概率低,也可能是领域、时代、分词方式或词表不匹配。
语言模型到底在计算什么
从整句概率到下一词预测
把一个已经分成词元的序列写成 w 1 , w 2 , … , w T w_1,w_2,\ldots,w_T w 1 , w 2 , … , w T
P ( w 1 , w 2 , … , w T ) = ∏ t = 1 T P ( w t ∣ w 1 , … , w t − 1 ) P(w_1,w_2,\ldots,w_T)=\prod_{t=1}^{T}P(w_t\mid w_1,\ldots,w_{t-1}) P ( w 1 , w 2 , … , w 这个等式没有做任何马尔可假设,只是把一个联合概率拆成一连串条件概率。语言模型真正需要学的,是每个位置上的分布 P ( w t ∣ w 1 : t − 1 ) P(w_t\mid w_{1:t-1}) P ( w t ∣ w 1 : t − 1 )
L = − 1 N ∑ t = 1 N log P ( w t ∣ w < t ) \mathcal{L}=-\frac{1}{N}\sum_{t=1}^{N}\log P(w_t\mid w_{<t}) L = − N 1 t = 1 ∑ N log 乘法改成对数下的加法,有两个实际好处。第一,很多小概率相乘容易下溢,对数域更稳定;第二,一个位置若给真实词极低概率,− log p -\log p − log p
句界和词表也属于模型定义
为了让第一个词有前缀,通常在句首加 <bos>;为了让模型学会停止,在句尾加 <eos>。句子“今天下雨”的概率因此包括下面几步:
P ( 今天 ∣ <bos> ) P ( 下雨 ∣ <bos> , 今天 ) P ( <eos> ∣ <bos> , 今天 , 下雨 ) P(\text{今天}\mid \texttt{<bos>})
P(\text{下雨}\mid \texttt{<bos>},\text{今天})
P(\texttt{<eos>}\mid \texttt{<bos>},\text{今天},\text{下雨}) P ( 今天 ∣ <bos> ) P ( 下雨 ∣ <bos> , 今天 ) P ( <eos> ∣ <bos> , 今天 , 下雨 ) 如果遗漏 <eos>,模型学到的只是“前缀后面接什么”,却没有学习什么时候句子已经完整。同理,字级、词级和子词级模型的每一步意义不同,困惑度也不能跨这些设定直接比较。
困惑度是平均负对数似然的指数
若对数使用自然底数,困惑度为:
PPL = exp ( L ) \operatorname{PPL}=\exp(\mathcal{L}) PPL = exp ( L ) 它可以粗略理解为“模型在每一步像是在多少个等概率候选中犹豫”。例如,每个位置的真实词概率都是 0.25 0.25 0.25 − log 0.25 -\log 0.25 − log 0.25
在实验台中先选“四步都自信”,再选“一步犹豫”。你会看到,单个低概率会明显拉高平均损失与困惑度。这正是使用负对数似然的原因:模型对真实答案过度自信地判错时,会收到更大惩罚。
1 语言模型对序列使用概率链式分解时,每一项直接表示什么?
A 整个词表的大小 B 给定已有前缀时下一词的条件概率 C 句子的绝对真实性 D 隐藏状态的维度
2 两个模型的困惑度要直接比较,哪些条件应保持一致?
n-gram 是可靠基线,不是过时笑话
用有限历史换取可估计性
完整历史 w 1 : t − 1 w_{1:t-1} w 1 : t − 1 n − 1 n-1 n − 1
P ( w t ∣ w 1 , … , w t − 1 ) ≈ P ( w t ∣ w t − n + 1 , … , w t − 1 ) P(w_t\mid w_1,\ldots,w_{t-1})\approx P(w_t\mid w_{t-n+1},\ldots,w_{t-1}) P ( w t ∣ w 1 , … , w 对 trigram 而言,当前词只条件于前两词,这相当于二阶马尔可假设。最大似然估计直接来自计数:
P M L ( w t ∣ w t − 2 , w t − 1 ) = C ( w t − 2 , w t − 1 , w t ) C ( w t − 2 , w t − 1 ) P_{\mathrm{ML}}(w_t\mid w_{t-2},w_{t-1})=
\frac{C(w_{t-2},w_{t-1},w_t)}{C(w_{t-2},w_{t-1})} P ML ( w t ∣ 这个基线的优点很实在:训练就是计数,可以直接查看某个概率的证据,推理延迟低,在领域窄、语句模板稳定或需要有限状态解码时仍很有用。神经网络应该证明自己超过了这个基线,而不是默认计数模型一定很弱。
零概率不是“真的不可能”
假设训练集没见过“雨后 / 校园 / 安静”,未平滑的 trigram 会给该组合概率 0。一个因子为 0,整句概率也会变成 0,负对数似然则无穷大。这只说明样本有限,不说明语句在语言中不可能。
平滑的一般思路是:从已见事件释放一部分概率质量,再分给未见事件。加 α \alpha α
P α ( w ∣ h ) = C ( h , w ) + α C ( h ) + α ∣ V ∣ P_{\alpha}(w\mid h)=\frac{C(h,w)+\alpha}{C(h)+\alpha |V|} P α ( w ∣ h ) = C ( h ) + α ∣ V ∣ 它能消除零概率,却会把概率质量平均分给整个词表,大词表下往往过于粗糙。插值或回退则会在高阶证据弱时向更短历史借力。Kneser–Ney 的关键还多一步:低阶分布不只看一个词总共有多常见,还看它能跟多少种不同前文连接。“上海”在“大”后面出现很多次,不代表它在任意未见前文后都应获得高概率。
一个实用的 n-gram 检查表
3 trigram 语言模型使用的是二阶马尔可假设,因为预测当前词时保留两个前文词。
4 Kneser–Ney 回退分布为什么不直接使用普通一元词频?
A 因为一元词频不能归一化 B 因为回退更关心词在多少种不同前文中出现 C 因为它不允许使用计数 D 因为所有词都应该等概率
RNN 用隐状态压缩已读前缀
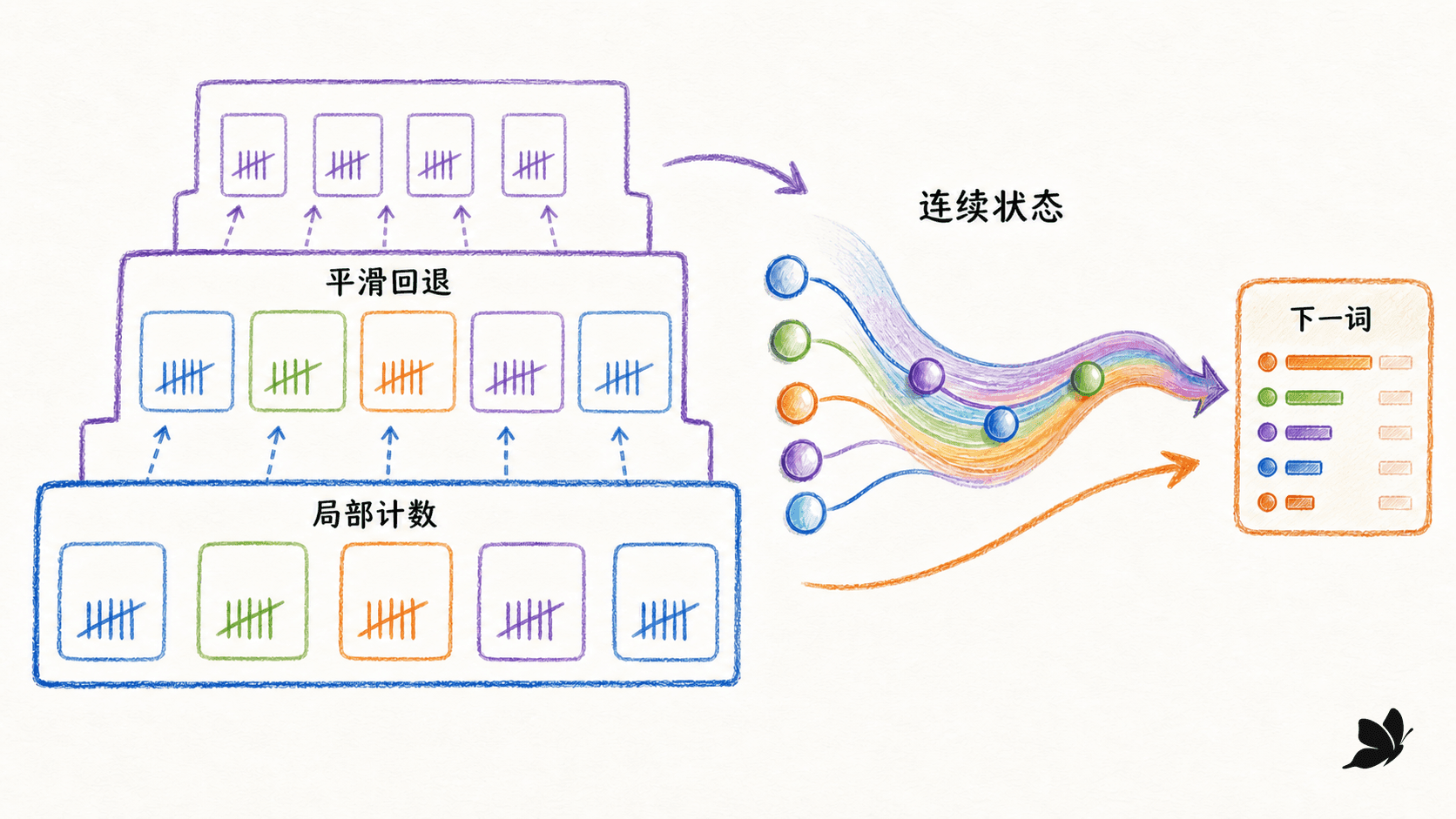
从离散历史表走向连续状态
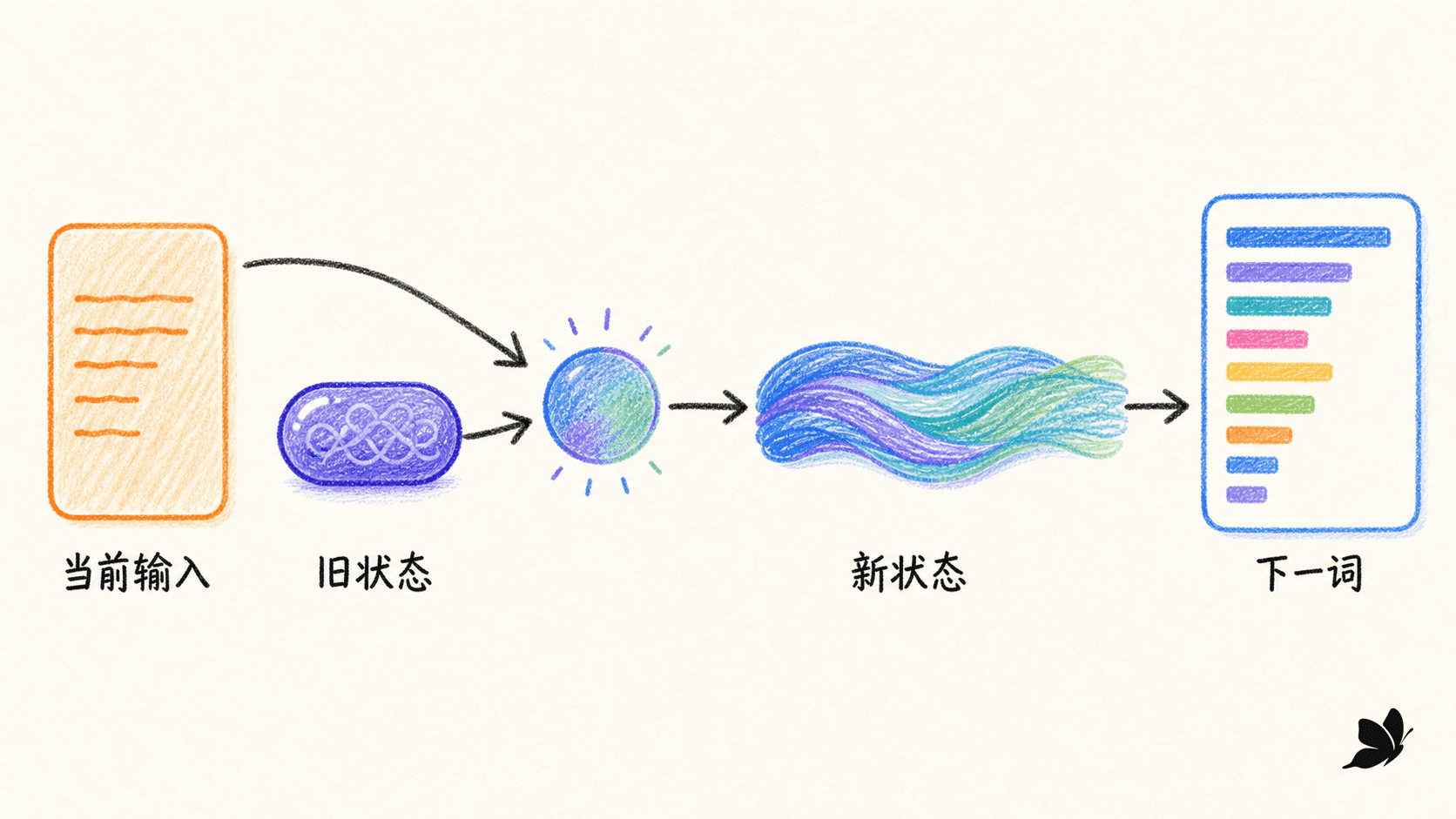
n-gram 把每种前文当作离散键值。“学生打开”和“同学翻开”即使语义相近,计数表中也是两个键。神经语言模型先把词映射到连续向量,让相似词共享一部分统计强度。简单循环网络再把前一隐状态馈入当前计算:
h t = tanh ( W x h x t + W h h h t − 1 + b h ) h_t=\tanh(W_{xh}x_t+W_{hh}h_{t-1}+b_h) h t = tanh ( W x h x t + z t = W h y h t + b y z_t=W_{hy}h_t+b_y z t = W h y h t + b P ( w t + 1 ∣ w ≤ t ) = softmax ( z t ) P(w_{t+1}\mid w_{\le t})=\operatorname{softmax}(z_t) P ( w t + 1 ∣ w ≤ t ) = softmax ( z x t x_t x t h t − 1 h_{t-1} h t − 1 z t z_t z t
隐状态是有损压缩,不是句子存档
理论上,h t h_t h t tanh \tanh tanh
这个区别也解释了为什么隐状态维度太小时会容量不足,维度太大时又可能记住训练细节、增加计算和过拟合风险。我们要通过验证集、长距离依赖切片与隐状态诊断选容量,不能只看训练损失。
把“记忆权重”调到 0.2,早期输入的影响会很快被新输入覆盖;调到接近 1,状态保留更久,但连续同号输入容易把 tanh \tanh tanh
5 RNN 在不同时间步共享参数,直接带来了哪些性质?
6 简单 RNN 中,连接上一隐状态 h_(t-1) 与当前隐状态 h_t 的参数矩阵通常记为 ____。
教师强制和序列批处理决定了训练语义
输入与目标只错一位
对自回归语言模型,一个句子的训练样本不是“整句输入、整句输出”两份无关数据,而是同一序列错一位:
输入: <bos> 今天 下午 去 图书馆 目标: 今天 下午 去 图书馆 <eos> 训练时,第 t t t w t w_t w t
对标准下一词语言模型来说,“teacher forcing 比例”并不像翻译解码器那样总是一个必调超参数:把整段真实前缀并行计算损失,本身就是最大似然训练。需要分清“自回归语言模型的移位目标”和“序列到序列解码器的按步输入策略”。
批处理不能打乱时间对齐
一批序列通常组织成 [batch, time, feature]。对应的词元 ID 是 [batch, time],RNN 输出是 [batch, time, hidden],投影到词表后是 [batch, time, vocab]。计算交叉熵时,可把前两维展平,但目标必须使用完全相同的顺序展平,否则会把不同位置的答案错配。
变长句子有两种常见处理:
填充到同一长度,然后用 mask 不计算填充位置的损失。
按长度打包,让 RNN 跳过无效时间步,减少空转。
隐状态是否跨批传递取决于数据切法。若后一片段真是前一片段的连续文本,可以携带状态,但要在截断边界切断梯度图。若两个批次来自无关文档,则应该重置状态,否则上一文档的残留会污染下一文档。
7 训练下一词语言模型时,输入序列与目标序列最关键的关系是什么?
A 两者完全相同 B 目标相对输入向后移一位 C 目标要倒序 D 输入只保留最后一词
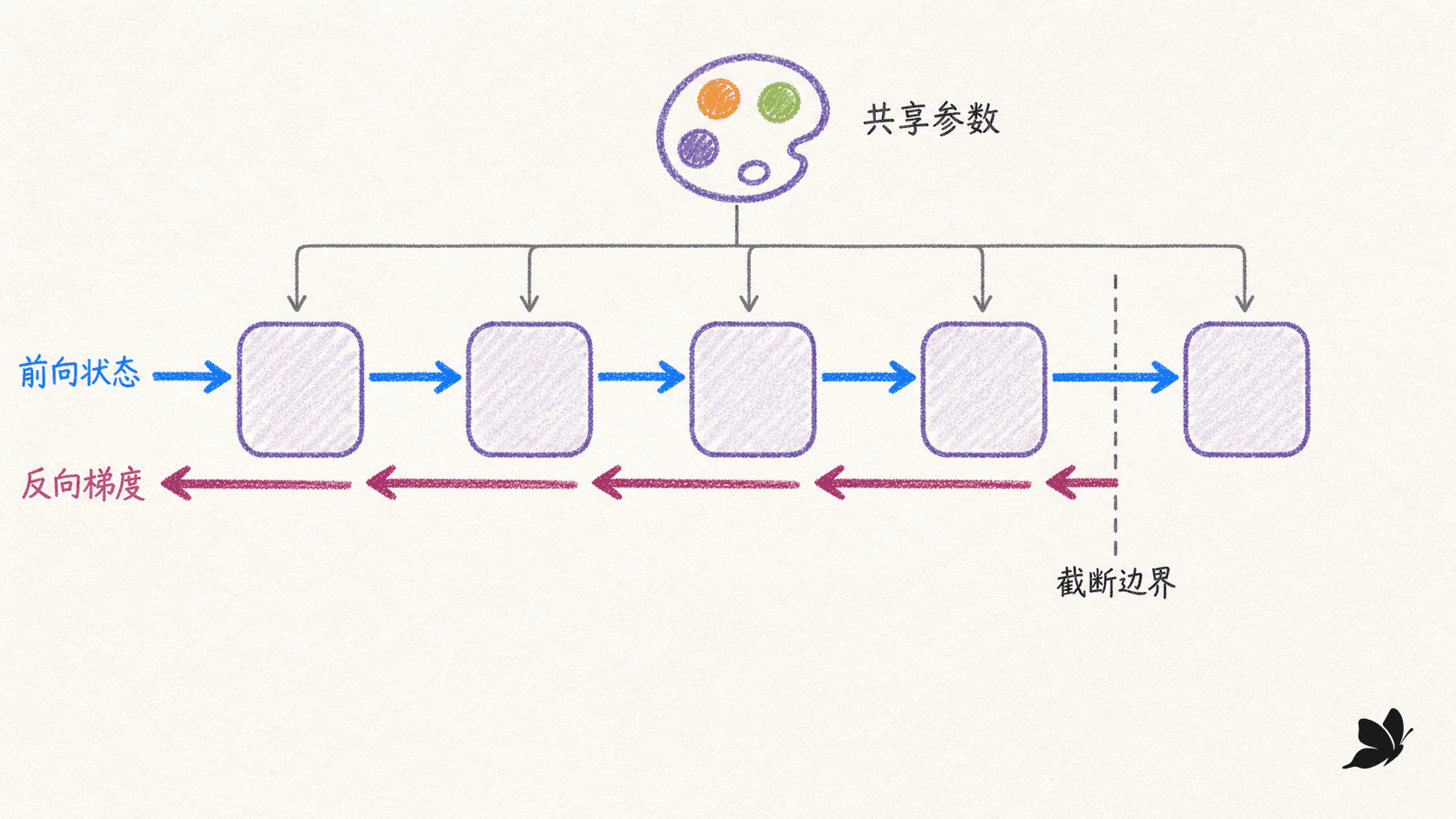
BPTT 把循环展开成一条共享参数的深链
前向是递推,反向是沿时间汇总梯度
把 RNN 的循环连接沿时间展开,可以看成很多个使用同一组参数的单元。第 t t t h t h_t h t h t + 1 , h t + 2 , … h_{t+1},h_{t+2},\ldots h t + 1 , h
∂ L ∂ h t = ∂ L t ∂ h t + ∂ L ∂ h t + 1 ∂ h t + 1 ∂ h t \frac{\partial \mathcal{L}}{\partial h_t}=
\frac{\partial \mathcal{L}_t}{\partial h_t}+
\frac{\partial \mathcal{L}}{\partial h_{t+1}}
\frac{\partial h_{t+1}}{\partial h_t} ∂ h t ∂ L = 第一项来自当前位置的预测误差,第二项来自未来状态。由于 W h h W_{hh} W hh
截断 BPTT 限制优化视野,不一定清空数值记忆
如果一次展开整篇长文,每个时间步的中间状态都要留给反向传播,内存和计算随序列长度线性增长。截断 BPTT 把长流切成长度 K K K
用上一片段结尾的隐状态作为新片段初始值,因此前向数值仍能携带更早的信息。
在片段边界把隐状态从旧计算图分离,让当前损失不再沿梯度路径追溯到更早片段。
在当前 K K K
这个细节很容说错:“截断梯度”不等于“每段把隐状态置零”。前者限制参数更新能直接追溯的距离,后者连前向状态也丢掉。当然,即使数值状态携带了早期信息,若损失的梯度永远不能跨过边界,模型也很难通过直接信号学到超过 K K K
9 BPTT 中,某时刻隐状态的梯度为什么包含来自未来时刻的项?
A 因为参数每步都不同 B 因为当前隐状态会影响后续隐状态与损失 C 因为词表必须倒序 D 因为 softmax 只能从右向左计算
10 截断 BPTT 在片段边界切断梯度图后,必须同时把隐状态的数值全部置零。
梯度消失与爆炸是雅可比连乘的两个方向
同一条乘法链,可能越乘越小,也可能越乘越大
从较后状态回传到较早状态时,会出现局部雅可比矩阵的连乘:
∂ h t ∂ h k = ∏ i = k + 1 t ∂ h i ∂ h i − 1 \frac{\partial h_t}{\partial h_k}=
\prod_{i=k+1}^{t}
\frac{\partial h_i}{\partial h_{i-1}} ∂ h k ∂ h t = 对 tanh \tanh tanh W h h W_{hh} W hh tanh \tanh tanh
试着把局部增益从 0.8 改到 1.2,再逐渐增加回传步数。简化模型使用 g k g^k g k
范数裁剪防止爆炸,但不会修复消失
设所有参数梯度连接成一个向量 g g g
g ← g ⋅ min ( 1 , τ ∥ g ∥ 2 ) g\leftarrow g\cdot\min\left(1,\frac{\tau}{\lVert g\rVert_2}\right) g ← g ⋅ min ( 1 , ∥ g ∥ 2 τ ) 当范数不超过阈值 τ \tau τ
裁剪解决的是“这一步更新太大”,不是“距离很远的学习信号已经接近零”。如果训练几乎每步都触发裁剪,不要只继续降低阈值;还应该检查学习率、状态初始化、序列长度、损失归一化和异常样本。反过来,从不触发裁剪也不代表没有梯度消失。
12 训练中几乎每步都触发梯度裁剪,最合理的下一步是什么?
A 只把裁剪阈值改得更小 B 联合检查学习率、序列长度、损失缩放与异常样本 C 删除验证集 D 将所有梯度直接设为零
亲手训练一个字符级 RNN 语言模型
为什么这个实验只用标准库
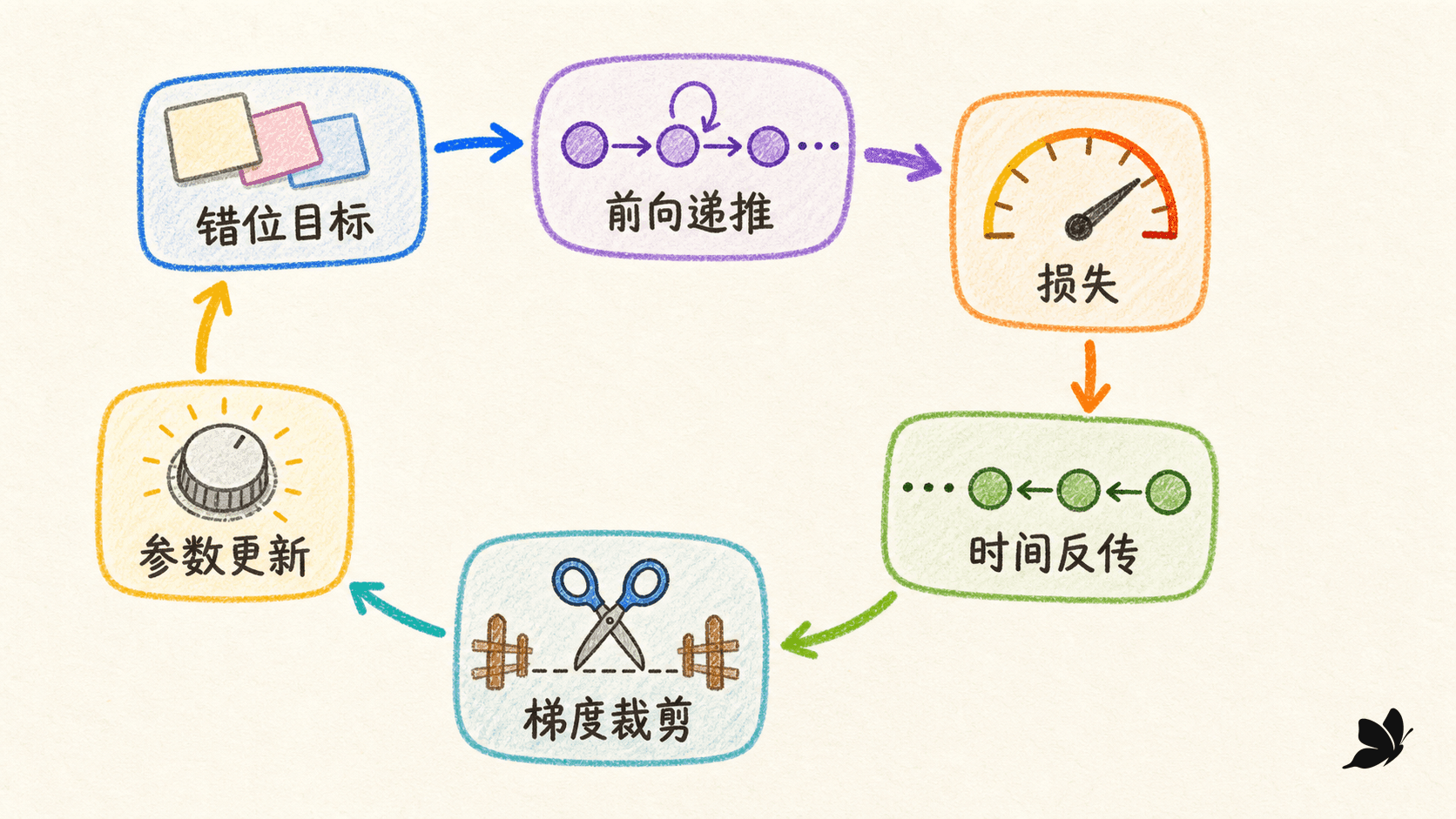
我们想验证的不是某个高层 API 能否调用,而是五个关键环节确实连在一起:当前字符与旧状态生成新状态,softmax 给下一字符概率,负对数似然累积损失,BPTT 沿片段回传,全局范数在必要时裁剪。因此实验使用 Python 3 标准库和手写列表运算,避免依赖安装状态遮住核心逻辑。
实验数据是四句中文校园短句的重复组合,词表有 44 个字符,隐状态 16 维,截断长度 24,固定随机种子 20260715。数据故意很小,因为我们需要快速观察学习、裁剪与过拟合,不需要伪装成通用中文模型。
可复现的训练核心
下面代码保留了单个截断片段的完整前向与反向逻辑。矩阵是普通二维列表,因此能直接在 Python 3 中运行。为了节省篇幅,数据循环与 AdaGrad 更新使用与前章普通参数更新相同的写法;最需要核对的是梯度如何从后向前累积。
import math import random
def zeros (rows, cols): return [[ 0.0 for _ in range (cols)] for _ in range (rows)]
def softmax (logits): peak = max (logits) exps = [math.exp(x - peak) for x in logits] total = sum (exps) return 循环在每个 24 步片段上调用 loss_and_grads,若全局范数超过 5.0 就统一缩放,再用 AdaGrad 更新参数。片段末的 hs[-1] 会作为下一连续片段的初始状态,但函数只返回数值列表,没有把旧片段的求导历史一起带过去,因此自然形成截断 BPTT。
真实结果与诊断
训练 900 步后,得到以下输出:
seed=20260715 vocab=44 hidden=16 steps=900 bptt=24 eval_before nll=3.7831 ppl=43.95 eval_after nll=0.6400 ppl=1.90 last_train_chunk_nll=0.0069 max_grad_norm_before_clip=48.5013 clip_threshold=5.0 clipped_steps=91 sample=春风吹过校园,学生走进教室。↵雨后空气清新,学生打开课本。↵老师提出问题,学生认真思考。…… 评估困惑度从 43.95 降到 1.90,说明参数确实学到了小语料中的字符转移和句式。裁剪前最大梯度范数达到 48.5013,共有 91 步触发阈值,证明裁剪在这次训练中不是装饰代码。
但训练末块 NLL 只有 0.0069,远低于包含新组合的评估集 NLL 0.6400。模型已经很擅长复述重复模板,却没有因此变成通用中文模型。这个差距比生成样本“看起来很顺”更值得关注:样本太小、句式重复时,低损失很可能是记住了模板。
13 这个小型 RNN 实验同时记录训练末块 NLL 和包含新组合的评估 NLL,能帮助发现什么?
从一个跑通的模型走到可信评估
训练、验证与生成要分开看
语言模型的工作流不应只有一条 loss 曲线。一个完整检查至少包括:
训练监控 :记录 token 加权的 NLL、梯度范数、裁剪比例、学习率和每秒处理 token 数。独立验证 :使用不参与参数更新的时间段、作者或文档计算困惑度,避免近重复句跨分割。基线对比 :与平滑 n-gram、更小隐层、不同截断长度比较,否则无法判断复杂度是否真的换来收益。切片评估 :分别看长句、低频词、领域外文本、句界、数字和专名,不让高频短句掩盖失败。样本诊断 :生成文本用于发现重复循环、过早结束、标点崩坏与主题漂移,但不用少量顺眼样本代替定量评估。
困惑度对真实词元的概率敏感,却不直接衡量事实准确、无害性、多样性或任务效果。在语音识别中,低困惑度通常能减少语言候选分支,但最终还要看词错率;在输入法中要看候选召回和首选命中;在生成中则要结合任务完成度与人工审核。
温度改变采样分布,不改变模型已学参数
生成时常把 logits 除以温度 τ \tau τ
P τ ( w ) = softmax ( z w τ ) P_{\tau}(w)=\operatorname{softmax}\left(\frac{z_w}{\tau}\right) P τ ( w ) = softmax ( τ z w τ < 1 \tau<1 τ < 1 τ > 1 \tau>1 τ > 1
为什么下一步要学 LSTM 和 GRU
简单 RNN 的隐状态每步都被整体重写,梯度又需要穿过雅可比连乘。理论上它可以使用长历史,优化上却很难稳定学会“哪些信息要保留很久、哪些现在就可以忘掉”。
LSTM 与 GRU 的出发点正是把这个决策显式化:用门控路径调节旧信息、新输入与输出之间的流动,给信息和梯度提供更容易维持的通道。下一篇会继续沿用本篇的诊断方法:不只画出门的公式,还要看状态路径、梯度路径以及它们在实际序列上保留了什么。
15 评估一个 RNN 语言模型时,哪些做法比只看几条生成样本更可靠?
16 在不重新训练模型的情况下降低采样温度,会让分布更集中,但不会给模型添加新知识。
T
)
=
t = 1 ∏ T P ( w t ∣
w 1 , … , w t − 1 )
P
(
w t
∣
w < t )
t − 1
)
≈
P ( w t ∣
w t − n + 1 , … , w t − 1 )
w
t − 2
,
w t − 1
)
=
C ( w t − 2 , w t − 1 ) C ( w t − 2 , w t − 1 , w t )
C ( h , w ) + α
W hh
h t − 1
+
b h )
y
t
)
W x h
t + 2
,
…
∂ h t ∂ L t
+
∂ h t + 1 ∂ L ∂ h t ∂ h t + 1
i = k + 1 ∏ t ∂ h i − 1 ∂ h i
[x
/
total
for
x
in
exps]
def loss_and_grads (ids, h0, Wxh, Whh, Why, bh, by):
H, V = len (bh), len (by)
hs = [h0[:]]
probs = []
loss = 0.0
# 前向:真实字符 ids[t] 预测 ids[t + 1]
for t in range ( len (ids) - 1 ):
x = ids[t]
prev = hs[ - 1 ]
h = []
for i in range (H):
recurrent = sum (Whh[i][j] * prev[j] for j in range (H))
h.append(math.tanh(Wxh[i][x] + recurrent + bh[i]))
logits = [
sum (Why[k][j] * h[j] for j in range (H)) + by[k]
for k in range (V)
]
p = softmax(logits)
loss -= math.log( max (p[ids[t + 1 ]], 1e-12 ))
hs.append(h)
probs.append(p)
dWxh, dWhh, dWhy = zeros(H, V), zeros(H, H), zeros(V, H)
dbh, dby = [ 0.0 ] * H, [ 0.0 ] * V
dh_next = [ 0.0 ] * H
# 反向:从片段末尾回到起点
for t in reversed ( range ( len (ids) - 1 )):
dy = probs[t][:]
dy[ids[t + 1 ]] -= 1.0
for k in range (V):
dby[k] += dy[k]
for j in range (H):
dWhy[k][j] += dy[k] * hs[t + 1 ][j]
dh = [
sum (Why[k][j] * dy[k] for k in range (V)) + dh_next[j]
for j in range (H)
]
draw = [( 1.0 - hs[t + 1 ][j] ** 2 ) * dh[j] for j in range (H)]
for i in range (H):
dbh[i] += draw[i]
dWxh[i][ids[t]] += draw[i]
for j in range (H):
dWhh[i][j] += draw[i] * hs[t][j]
dh_next = [
sum (Whh[i][j] * draw[i] for i in range (H))
for j in range (H)
]
return loss, [dWxh, dWhh, dWhy, dbh, dby], hs[ - 1 ]
def global_norm (grads):
total = 0.0
for grad in grads:
values = (x for row in grad for x in row) if isinstance (grad[ 0 ], list ) else iter (grad)
total += sum (x * x for x in values)
return math.sqrt(total)
def clip_by_global_norm (grads, threshold):
norm = global_norm(grads)
scale = min ( 1.0 , threshold / max (norm, 1e-12 ))
for grad in grads:
if isinstance (grad[ 0 ], list ):
for row in grad:
for j in range ( len (row)):
row[j] *= scale
else :
for j in range ( len (grad)):
grad[j] *= scale
return norm
def matrix (rows, cols, scale = 0.0 ):
return [[random.uniform( - scale, scale) for _ in range (cols)] for _ in range (rows)]
def update (params, grads, memories, learning_rate):
for param, grad, memory in zip (params, grads, memories):
if isinstance (param[ 0 ], list ):
for i in range ( len (param)):
for j in range ( len (param[i])):
memory[i][j] += grad[i][j] ** 2
param[i][j] -= learning_rate * grad[i][j] / math.sqrt(memory[i][j] + 1e-8 )
else :
for i in range ( len (param)):
memory[i] += grad[i] ** 2
param[i] -= learning_rate * grad[i] / math.sqrt(memory[i] + 1e-8 )
def evaluate (text):
ids = [stoi[ch] for ch in text]
loss, _, _ = loss_and_grads(ids, [ 0.0 ] * H, Wxh, Whh, Why, bh, by)
nll = loss / ( len (ids) - 1 )
return nll, math.exp(nll)
def sample (seed, length = 52 , temperature = 0.75 ):
h, current, result = [ 0.0 ] * H, stoi[seed], [seed]
for _ in range (length - 1 ):
h = [math.tanh(Wxh[i][current] + sum (Whh[i][j] * h[j] for j in range (H)) + bh[i]) for i in range (H)]
logits = [( sum (Why[k][j] * h[j] for j in range (H)) + by[k]) / temperature for k in range (V)]
probabilities = softmax(logits)
draw, running, next_id = random.random(), 0.0 , V - 1
for k, probability in enumerate (probabilities):
running += probability
if draw <= running:
next_id = k
break
result.append(itos[next_id])
current = next_id
return "" .join(result).replace( " \n " , "↵" )
random.seed( 20260715 )
sentences = [
"春风吹过校园,学生走进教室。 \n " ,
"雨后空气清新,学生打开课本。 \n " ,
"老师提出问题,学生认真思考。 \n " ,
"课堂保持安静,学生记录要点。 \n " ,
]
train_text = "" .join(sentences * 45 )
eval_text = "春风吹过校园,学生打开课本。 \n 老师提出问题,学生记录要点。 \n "
chars = sorted ( set (train_text + eval_text))
stoi, itos = {ch: i for i, ch in enumerate (chars)}, {i: ch for i, ch in enumerate (chars)}
V, H, bptt, lr = len (chars), 16 , 24 , 0.08
Wxh, Whh, Why = matrix(H, V, 0.08 ), matrix(H, H, 0.08 ), matrix(V, H, 0.08 )
bh, by = [ 0.0 ] * H, [ 0.0 ] * V
params = [Wxh, Whh, Why, bh, by]
memories = [zeros(H, V), zeros(H, H), zeros(V, H), [ 0.0 ] * H, [ 0.0 ] * V]
before_nll, before_ppl = evaluate(eval_text)
pointer, h, clipped, max_norm, last_nll = 0 , [ 0.0 ] * H, 0 , 0.0 , None
for step in range ( 900 ):
if pointer + bptt + 1 >= len (train_text):
pointer, h = 0 , [ 0.0 ] * H
ids = [stoi[ch] for ch in train_text[pointer:pointer + bptt + 1 ]]
loss, grads, h = loss_and_grads(ids, h, Wxh, Whh, Why, bh, by)
norm = clip_by_global_norm(grads, 5.0 )
max_norm = max (max_norm, norm)
clipped += int (norm > 5.0 )
update(params, grads, memories, lr)
last_nll = loss / bptt
pointer += bptt
after_nll, after_ppl = evaluate(eval_text)
print ( f "eval_before nll= { before_nll :.4f } ppl= { before_ppl :.2f } " )
print ( f "eval_after nll= { after_nll :.4f } ppl= { after_ppl :.2f } " )
print ( f "last_train_chunk_nll= { last_nll :.4f } " )
print ( f "max_grad_norm= { max_norm :.4f } clipped_steps= { clipped } " )
print ( "sample=" + sample( "春" ))
)